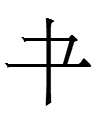
cf. Tangut

1tseʳw < *rʌ-tsik (*Tʌ-tsik?**) 'joint'
12.9.1.23:59: A MISMATCH-T STANCE
l learned to read Chinese characters in Japanese first. I started learning Mandarin readings at around age eight, and I figured out patterns of correspondence between Sino-Japanese and Mandarin such as
SJ h- : Md p- (not h-!)
SJ r- : Md l- (not r-!)
SJ -ki : Md zero
SJ -tsu : Md zero
So I wasn't surprised to learn that
匹 SJ hiki 'counter for animals*; equal**' corresponded to Md pi [phi]
立 SJ ritsu 'stand' corresponded to Md li
At fifteen I started learning Sino-Korean readings which seemed like a mix of Sino-Japanese and Mandarin characteristics plus many surprises: e.g.,
匹 SJ hiki corresponded to SK phil
SK phi is like Md pi [phi], but I would have expected SK *phik
SK -l < -rʔ normally corresponds to SJ -tsu < -tu (see below) and -chi < -ti
立 SJ ritsu corresponded to SK rip
SK rip has a ri- like SJ li, but I would have expected SK *ril
SK -p normally corresponds to SJ -fu < -pu
The Cantonese and Sino-Vietnamese readings I began to study at eighteen and about twenty-one had the final consonants I would have expected on the basis of Sino-Korean:
匹 Ct phat, SV thất (their -t corresponds to SK -l; the SV initial th- initially appears unusual and is beyond the scope of this post)
立 Ct lap, SV lập (with a -p like SK)
I later found out that the common SJ readings of 匹 and 立 are irregular from the perspective of the Middle Chinese lexicographical tradition, whereas their less common readings are regular:
| Sinograph | Middle Chinese | Irregular Sino-Japanese | Regular Sino-Japanese | Mandarin | Sino-Korean | Cantonese | Sino-Vietnamese |
| 匹 | *phit | hiki | hitsu | pi [phi] | phil | phat | thất |
| 立 | *lip | ritsu < ritu | ryuu < rifu < ripu | li | rip | lap | lập |
Are the irregular Sino-Japanese readings due to random errors? I cannot think of any analogical models for reading them with the wrong final syllables. I think those 'wrong' syllables would in fact be regular when compared to colloquial earlier Chinese.
As I explained in "Of Bodhisattvas and Books", Old Chinese *-ik became *-it. What if SJ 匹 hiki reflects an archaic classifier *phik that had kept the original *-k? Other archaic classifiers that have survived in Sinoxenic are SK 個 kae [kɛ] < *kai and SV cái from Old Chinese *kaih.
(9.2.1:10: Chaozhou 匹 phik is neither the source of SJ hiki nor even an archaism since all *-t became -k or -ʔ in Chaozhou, and -ʔ is probably from an older layer than -k. The best Chinese-internal modern evidence for -k in 匹 would be in a language that never shifted *-t to -k.)
On the other hand, SJ 立 ritsu could reflect a colloquial variety of Middle Chinese that had fronted *-p to *-t after front vowels: cf. modern Nanchang Gan 立 lit < *lip (though I do not think some early form of Gan is the source of SJ ritsu; the change is not exotic and could have occurred elsewhere in Chinese).
*SJ 匹 hiki < piki is used to count animals in Japanese: e.g., 一匹狼 ippiki ookami 'one (counter) wolf' = 'lone wolf'.
**As in SJ 匹敵 hitteki 'be comparable to' < hitsu 'match' + teki 'match' (also 'enemy', but not here).
敵 has a simplified form 敌 which I discussed in "From Exhaustion to Opposition".
12.8.31.23:51: OF BODHISATTVAS AND BOOKS
ln "From Exhaustion to Opposition", I wrote,
In theory a Chinese word could have had two different rhymes in the same epitaph inscription depending on whether it was in a Liao Chinese poem or a Sino-Khitan word in Khitan text [...] Could Sino-Khitan have been a mishmash of words borrowed from various northern Chinese dialects? This would account for the heterogenous Sino-Khitan spellings in chapter seven of Kane (2009). On the other hand, Liao poetry could have been based on a prestige dialect that was distinct from that of Song, judging from the rhymes in Kane (2009: 252).
Perhaps the Khitan situation has a parallel in Japan. When Japanese wrote poetry in Classical Chinese, they would presumably not rhyme 菩薩 'bodhisattva' with 冊 'volume of a book' because those words belonged to Middle Chinese rhyme categories ending in different final consonants (*-t and *-k). Yet 薩 and 冊 both have the Sino-Japanese reading satsu*:
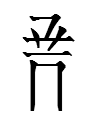
| Sinographs | Middle Chinese | Sino-Japanese |
| 菩薩 'bodhisattva' | *bo sat | bosatsu |
| 冊 'volume of a book' | *tʂhɛk | satsu |
It would be interesting to see if 漢詩 kanshi (Classical Chinese poetry written by Japanese) contain any rhyming 'errors' influenced by Sino-Japanese readings.
*12.9.1.2:31: Although Sino-Japanese 慣用音 kan'youon 'conventional readings' such as satsu for 冊 are irregular from the perspective of the Middle Chinese dictionary tradition, I suspect that some of them reflect actual nonstandard Chinese pronunciations, particularly if there is no obvious analogical model for a misreading. In this case, there is no common character with 冊 as a phonetic pronounced satsu to serve as a model to read 冊 as satsu in addition to the regular (but less common) reading saku, so I suspect that satsu is from a nonstandard Middle Chinese *tʂhæt with a final *-t from an earlier *-k that fronted after a front vowel:
*tʂhɛk > *tʂhɛt > *tʂhæt
Similar readings are
Nanchang Gan tshɛt < *-k
Southern Vietnamese sách [ʂat] < *-c
This does not mean that SJ satsu is from some ancestor of Gan or the source of Sino-Vietnamese. The shift of *-c to *-t occurred in southern Vietnamese after the borrowing of Sino-Vietnamese. The fronting of codas after front vowels is not an exotic change; it even occurred in Old Chinese: e.g.,
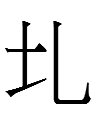
節 OC *Cʌ-tsik > *tsit > MC *tset 'joint'
cf. Tangut
1tseʳw < *rʌ-tsik (*Tʌ-tsik?**) 'joint'
Fronting of codas could have later occurred independently in different Middle Chinese dialects: e.g., the ancestor of Nanchang Gan and the source of SJ satsu.
**9.1.2:49: The large number of retroflex vowel syllables in Tangut could be partly due to a merger of various coronal-initial *TV- presyllables: e.g.,
*tV-CV, *rV-CV, *lV-CV > *r(V)-CV > *CVʳ
Original final *-r is another source of Tangut vowel retroflexion. But oddly medial *-r- isn't; it conditoned Grade II vowels and disappeared before *r on the edges conditioned retroflex vowels: e.g.,
| |
Presyllable *r- | Medial *-r- | Coda *-r |
| Pre-Tangut | *rV-Ca | *Cra | *Car |
| Grade II | *rV-Ca | *Cæ | *Car |
| Retroflexion | *r(V)-Caʳ | *Cæ | *Caʳ |
| Tangut | Caʳ (Grade I) | Cæ (Grade II) | Caʳ (Grade I) |
It is possible that both Early Old Chinese and pre-Tangut had inherited the same presyllable *Tʌ- from the Proto-Sino-Tibetan word for 'joint', but there are no Chinese-internal clues pointing toward a coronal initial for the lost presyllable. Written Tibetan tshigs 'joint' begins with the root initial (which has secondary aspiration) and has an -s not corresponding to anything in OC or Tangut. (WT -s should ideally correspond to OC -s and the Tangut 'rising tone' from pre-Tangut *-H, probably a merger of *-ʔ and *-s.)
12.8.30.23:59: FROM EXHAUSTION TO OPPOSITION
ln "Coarse Apricots", I transcribed Arabic -d as
in the Jurchen large script. Jin (1984: 88) derived that character and its variants
<di>
~
~
<di>
from 敌 which is a simplified form of 敵 dí [ti] 'enemy' in modern Mandarin. The graphic match is particularly convincing if one replaces the 攵 with its variant 攴. Case closed, right?
Maybe not. If Jin is correct, 敌 should have been read as *ti(ʔ) during the Liao and Jin Dynasties. (An unaspirated *t sounded like d to the Jurchen.) However, 敌 may be first attested in the Liao Dynasty Longkan Shoujian dictionary (997 AD) which lists its fanqie as
下刮
Middle Chinese *ɣæʔ + *kwæt = *ɣwæt (already obsolete by the 10th century)
Liao Chinese *xja + *kwaʔ = *xwaʔ
and the Jiyun dictionary (1037 AD) defined it as 盡 'exhaust' (LC *tsin) Could the definition 畫 'picture' (LC *xwa) in Guangyun (1008 AD) be an error for 盡 'exhaust', or was *xwaʔ a variant of *xwa 'picture'?* In any case, I can't find a premodern attestation of 敌 for *ti(ʔ) 'enemy, opponent' in the Dictionary of Chinese Character Variants. Was 敌 first used as a simplification of 敵 before the Jurchen character for <di> was created (or before the Jurchen assigned the reading <di> to a preexisting敌-like character)? If not, then the resemblance between Jurchen <di> and 敌 is a coincidence unless there was a Jurchen - or Parhae? - word for 'exhaust' or 'picture' that sounded like <di>:
敌 MC 'exhaust'/'picture' > borrowed for Parhae *di? 'exhaust' or 'picture' > Jurchen <di>
*The fanqie 下刮 may have been created in the 10th century and be based on Liao Chinese pronunciation, so it is not necessarily proof that 敌 had once been read with a final *-t. 敌 *xwaʔ 'picture' (?) could be from Middle Chinese *ɣwæk < Old Chinese *w(r)ek, a suffixless variant of
畫 LC *xwa < MC *ɣwæh < OC *w(r)ek-s
(See Schuessler 2009: 130 on reconstructing the 畫 phonetic series without *-r- in OC.)
Kane (2009: 59) reconstructed the Sino-Khitan equivalent of the Liao Chinese reflex of MC *-æk as -aɣ (-ah in his orthography), written as
in the Khitan small script. So perhaps the Khitan would have read 敌 as something like xwaɣ.
It is even possible that 刮 represented two unrelated words that had become homophones in Liao Chinese (and therefore had only one fanqie by the late 10th century):
*xwaʔ < *ɣwæt (with the final *-t implied by the phonetic 舌) 'exhaust'
*xwaʔ < *ɣwæk 'picture'
12.8.31.2:11: Although Beijing was the southern capital of the Liao, its reflexes of MC *-æk at first glance look quite different from those of Sino-Khitan:
| Early Middle Chinese | Late Middle Chinese | Sino-Khitan | Beijing |
| *-æt | *-æt | 察 <ca> | 察 chá |
| *-ɛt | |||
| *-æk | *-æk | 伯 <b.aɣ>, 冊 <c.aɣ>, 客 <x.aɣ> | 伯 bó, 冊 cè [tshɤ], 客 kè [khɤ], also 白 bái (Sino-Khitan reading unknown) |
| *-ɛk |
Kane (2009: 253) listed 滑 MC *ɣwɛt as having a Sino-Khitan transcription, but I cannot find the transcription in his book.
It is not clear that Kane's <aɣ> ended in a fricative or even a glottal stop, as it was used to transcribe 牌 that never had either coda as <p.aɣ> as well as <p.ai>. Kane (2009: 254) wrote,
It is quite possible that <ah> [= <aɣ>] may have been [ai], but it is generally distinguished from
<ai>.
There may have been some difference in the vowel.
<ah> <oh> and <uh> [= <aɣ>, <oɣ>, and <uɣ>]
are also commonly used to transcribe open syllables. Generally speaking there is no consistency in the use of the graphs used to transcribe syllables which ended in stops in MC and probably a glottal stop in Song Chinese [to the south of the Khitan Empire] This does not prove that Liao Chinese did not have a glottal stop in such words, just that the Kitan [= Khitan] transcription does not indicate it.
My guess is that Sino-Khitan might have had a single rhyme *-a(ʔ) corresponding to multiple MC and modern Beijing rhymes. But if I am reading Kane (2009: 252) correctly, he would reconstruct Liao Chinese *-oʔ and *-eʔ on the basis of poetry (as opposed to Sino-Khitan small script transcriptions).
| Early Middle Chinese | Late Middle Chinese | Liao Chinese | Sino-Khitan | Beijing |
| *-æt | *-æt | *-oʔ (< *-ɑt < *-at < *-æt?) | *-a(ʔ) | -a |
| *-ɛt | ||||
| *-æk | *-æk | *-eʔ | -ai, -e [ɤ], -o | |
| *-ɛk |
I would expect the Liao Chinese and Sino-Khitan vowels to line up - e.g.,
LC *-oʔ : SK *-oʔ (not *-a(ʔ))
LC *-eʔ : SK *-eʔ (not *-a(ʔ))
or
LC *-aʔ (not *-oʔ or *-eʔ) : SK *-a(ʔ)
- but that is not the case. Kane's LC *-aʔ corresponds to his Sino-Khitan <oh> (= <oɣ). Kane did not identify a Khitan small script character for <eʔ>.
Kane's Liao Chinese also does not line up with Beijing. I would expect the Liao ancestor of Beijing to have somewhat different vowels:
Liao *-aʔ (not *-oʔ) > modern Beijing -a
Liao *-aiʔ as well as *-eʔ > modern Beijing -ai, -o (after labials), -e (elsewhere)
(The mixture of -ai with -o ~ -e in modern Beijing probably reflects dialect mixture.)
So I am uncertain about whether my hypothetical *ɣwæt and *ɣwæk would have merged into LC *xwaʔ.
8.31.2:31: A mismatch between Liao/Sino-Khitan on the one hand and modern Beijing on the other is expected, not only because of the time difference, but also because the prestige Chinese dialect of the Khitan Empire was not necessarily similar or identical to Liao Beijing, the dialect of the southern capital as opposed to the supreme capital.
It is, however, hard to explain why Liao Chinese poetry and Sino-Khitan have such divergent rhymes. In theory a Chinese word could have had two different rhymes in the same epitaph inscription depending on whether it was in a Liao Chinese poem or a Sino-Khitan word in Khitan text. I would expect Sino-Khitan to have been based on the prestige dialect of Liao Chinese used in poetry.
8.31.2:59: Could Sino-Khitan have been a mishmash of words borrowed from various northern Chinese dialects? This would account for the heterogenous Sino-Khitan spellings in chapter seven of Kane (2009). On the other hand, Liao poetry could have been based on a prestige dialect that was distinct from that of Song, judging from the rhymes in Kane (2009: 252).
12.8.29.23:59: COARSE APRICOTS
Last night I found a Jurchen large script character
<muwa>
resembling the Jurchen small script character
<?>
from the block in my last two posts.
This does not mean that these two characters had similar readings. It does not even necessarily mean that the small script character is derived from its large script lookalike which is a variant of
the first half of
<muwa.r> 'coarse'
corresponding to Manchu muwa without -r*. I wonder if
originated as a logogram <muwar> for Jurchen muwar 'coarse' which was later spelled
<muwar.r>
with a suffixed phonetic clarifier <r> derived from 爾**. Jin (1984: 121) does not give any examples of <muwa(r)> in other words. I can't find any Manchu words with muwa that are not derived from muwa 'coarse', so it is unlikely that <muwa(r)> would have been used as a phonogram for a Jurchen word, though it could have been used to write a foreign word: e.g, Muwaḥḥid*** as something like
<muwa.hi.di>
assuming that a final d would be written with an echo vowel as <di>. There is no known Jurchen large script character for <d> without a vowel. This is not surprising since Manchu words cannot end in -d.
<muwa(r)> looks like the Khitan large script character
<?>
and Chinese 呆 which was a variant of Middle Chinese 保 *pauʔ 'maintain' according to Yupian (c. 543 AD) and came to be used for 'stupid' by the Yuan Dynasty. In modern Mandarin, it is read as either ái (< *ŋai?) or dāi. (It is not clear whether the two words are cognates or unrelated synonyms.) 呆 is also one of eighteen variants of 梅 'plum' which would have been read as *mui in Jin Chinese but was *mə in late Old Chinese. Here's a very flimsy scenario revolving around a single consonant: What if the Khitan and Jurchen 呆-lookalikes came through Parhae?
呆 OC *mə > borrowed as *ma in some Parhae language > recycled for Khitan <?> and Jurchen <muwa(r)>
Inverting the components of 呆 results in the Chinese character 杏 for 'apricot' which looks like the Khitan large script character
<gui> 'nation'
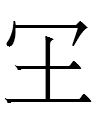
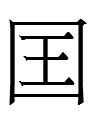
a borrowing from Liao Chinese 國 *gui. It is ironic that the Chinese word for 'nation' was written with a character unlike 國, whereas the non-Chinese (and native?****) word for 'nation' was written as
<gur>
which is identical to 囯, a simplified variant of 國. Does the use of 杏 for gui 'nation' indicate that the Khitan word for 'apricot' was (nearly?) homophonous with gui 'nation'? There is also a homophonous Khitan character
(a variant of
?)
<gui>
used to transcribe Liao Chinese 歸 *gui 'return'. Were both <gui> characters phonograms?
*8.30.3:59: Final -r is rare in Manchu and is only in loanwords
šabinar 'students' < Mongolian šabi-nar with a Mongolian plural suffix -nar < Chinese 沙彌 < Sanskrit śrāmaṇera-
and sound-symbolic vocabulary:
piyatar 'talky' with an atypical p-; most native p- became f- in late Jurchen.
Hence it seems that Jurchen muwar preserves a final -r lost in Manchu.
Late Jurchen ma in the Sino-Jurchen Vocabulary of the Bureau of Interpreters (Kane 1989: 337) is a contraction of muwar that has already lost -r.
**8.30.4:03: Jin (1984: 253) and I independently came up with the same derivation if I am reading his text correctly. The strokes of many characters in my copy have fused.
The use of a 爾-based character for -r may postdate the shift of *rɨ to syllabic *r̩ in northern Chinese. In any case, even if the Manchurian prototype of
existed long before the initial of 爾 had shifted from ̩*ɲ- to *ʒ- and later *r- in northern Chinese, an r-reading must be of relatively recent origin. There is no way that the Parhae could have known in the eighth century that 爾 would one day be read with initial r- in northern Chinese.
***8.30.4:33: Although I am not aware of any words of Arabic origin in the Jurchen scripts, Arabic names were written in the later Manchu script: e.g.,
Aḥmad as ᠠᡥᠠᠮᠠᡨ Ahamat (Manchu has no final -d; see above)
Ḥusayn as ᡝᠰᡝᠶᡝᠨ Eseyen
Ibrāhīm as ᡳᠪᠠᡵᠠᠶᡳᠮ Ibarayim
Sulaymān as ᠰᡠᠯᠠᡳᠮᠠᠨ Sulaiman
Yūsuf as ᠶᡠᠰᡠᠪ Yusub (Manchu has no final -f or -p)
****8.30.4:36: I wonder if the Khitan word gur (gür?) was borrowed from Xiongnu (via intermediaries?), just as Jurchen gurun (gürün?) was probably borrowed from Khitan gur (gür?).
12.8.28.23:43: LE-CUNAE?
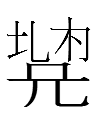
In "On Golden, Silver, and Wooden Tablets in the Jurchen Small Scripts", Aisin Gioro Ulhicun compared the first two components of what she regarded as a block of Jurchen small script characters on this paizi
to two Jurchen characters that I can't find in her father Jin Qizong's 1984 dictionary:
| Jurchen small script | Jurchen large script lookalikes I couldn't find in Jin 1984 | Jurchen large script lookalikes I found in Jin 1984 | Khitan small script lookalikes I found |
 from 朝鮮慶 源郡女眞國書碑 |
   <?>, <le>, <le> Jin (1984: 268) listed the first as the source of the other two, but I can't find an entry for it. |
 <ɣo> |
|
 from 女眞文字書 |
None found |  <en> |
|
| None listed |  <gin> |
 <?> See "Scientia alba" for more lookalikes |
Did I overlook the entries for ![]() and
and ![]() in Jin 1984, or
were these two characters discovered within the last three decades
(even though 朝鮮慶源郡女眞國書碑 and 女眞文字書 were both known by 1984)?
According to Aisin Gioro, the Jurchen large script had 1,364 characters
- nine more characters than the 1,355 in Jason Glavy's font based on
Jin 1984. The last Unicode Jurchen proposal I know of contains 1,376
characters which do not include
in Jin 1984, or
were these two characters discovered within the last three decades
(even though 朝鮮慶源郡女眞國書碑 and 女眞文字書 were both known by 1984)?
According to Aisin Gioro, the Jurchen large script had 1,364 characters
- nine more characters than the 1,355 in Jason Glavy's font based on
Jin 1984. The last Unicode Jurchen proposal I know of contains 1,376
characters which do not include ![]() or
or ![]() or even
or even ![]() which is
in Jin 1984.
which is
in Jin 1984.
8.29.7:59: The left sides of the first row of characters above resemble the Khitan large script characters
夫 <ś> (lookalike of Liao Chinese *fu 'man'; see "Whence Arrives the Sedentary Man"?)
天 <ten> (lookalike of Liao Chinese *tien 'heaven')
土 (function unknown; lookalike of Liao Chinese *tu 'earth')
12.8.27.23:59: TJK: THREE MYSTERIES OF DUALITY
Last night I realized that the biggest mysteries of the TJK (Tangut, Jurchen, and Khitan)* languages all involve enigmatic dichotomies:
Tangut: What is the difference between the two strata of vocabulary that could be described as frequent and infrequent (corresponding to Kepping's 'common' and 'ritual')? Andrew West has an interesting answer.
Figure 1. The frequent monosyllabic Tangut word for 'east' and its infrequent disyllabic synonym
<>

2vɨə** (frequent) <> 2zeʳw-2ləi (infrequent; known only from dictionaries)
Note how all three characters contain the same component
(function unknown), albeit in different positions.
I wonder if textual frequency does not reflect spoken frequency. What if the less frequent** vocabulary found only in dictionaries and songs turn out to be from the Tangut colloquial language? The vast bulk of premodern Korean writing was in classical Chinese, but the best evidence for Old Korean may be the roughly two dozen 鄉歌 hyangga 'local songs' which must be the tip of a lost iceberg.
Khitan: Why was the Khitan language written with two different scripts: the 'large' and the 'small'? Neither Andrew West nor I have an answer; his "The Mystery of Two Khitan Scripts" is a must-read article on the question.
Figure 2. 'East' in the Khitan large and small scripts
~
<>
The large script characters for 'east' are clearly cognate to Chinese 東 'east'; the first is completely identical. The small script character resembles <deu> 'younger brother' (visually cognate to Chn 弟 'younger brother'?) and may have been homophonous with <deu> 'younger brother'.
Jurchen: Like Khitan, Jurchen was a single language said to have been written with two different scripts: the 'large' and the 'small'. Yet all the extant material seems to be written with one script resembling the Khitan 'large' script. But wait ... has Aisin Gioro Ulhicun identified the elusive 'small' script at last?
Figure 3a. Jurchen (large script) characters
<le> (phonogram), <?>, <gin> (phonogram)
Figure 3b. A block of similar Jurchen small script characters
<?.?.?> (If the Jurchen small script was like the Khitan small scripts, the readings of its characters have no relationship to the readings of similar-looking large script characters.)
Figure 3c. A hypothetical block of similar Khitan small script characters
<ɣo.en.?>
*Andrew West coined this term; it's a play on CJK (Chinese, Japanese, and Korean).
Compared with Khitan and Jurchen, a wealth of Tangut manuscripts and printed texts have survived down to the present day, but this just highlights how much more must have been lost forever. We study Tangut through the distorted prism of the sands of Kharakhoto, only able to see a fraction of all the Tangut books that there must once have been. One lost book is all it takes to confuse us into believing in the myth of an ancient ritual language.
In theory it is possible that colloquial Tangut books full of disyllabic everyday words were excluded from preservation at Kharakhoto, so the 'less frequent' vocabulary might have been more frequent in writing as well as speech. The songs in colloquial Tangut that did survive were like the hyangga which sometimes came with literary Chinese paraphrases - whose literary Tangut counterparts have been ironically interpreted as 'common Tangut'! However, there is no reason to believe that Old Korean texts ever outnumbered Classical Chinese texts in ancient Korea. Similarly, perhaps colloquial Tangut texts never outnumbered literary texts. In any case, our sample of Tangut is simultaneously large and limited; we have no way of knowing for sure how representative it is until we find another treasure trove of texts.
12.8.26.23:59: SMALL STEP, GIANT LEAP
I wish to continue to honor the late Neil Armstrong by reexamining the uncommon disyllabic Tangut word for 'moon'
after having written about its more common monosyllabic synonym last night:
1ka 1ʔo
2lhị 'moon'
Both of the characters for 1ka 1ʔo consist of an abbreviated phonetic element plus another element of unknown function:
 |
 |
||
| 1ka | 1ʔo | ||
| first half of 'moon'; see "Red-Faced Oral Cavity" | second half of 'moon'; see "O Moon, O Sun!" | ||
 |
 |
 |
 |
| (no reading; not an independent character) | 1tsiə | (no readings; not independent characters) | |
| 'master' (Nishida 1966: 245); in
19 other tangraphs: e.g., 2dziee 'teacher; master' 2dziee 'to teach' 1ɣɛw 'to study' (< Chn 學 'id.') |
'also; small' (top of graph resembles Chn 小 'small' and 少 'few') | unknown; in 78 other tangraphs
without any obvious phonetic or semantic common denominator; its
presence does not guarantee a meaning like 'moon' or a reading like 1ʔo:
e.g., 2rioʳ 'to cover' and the first halves of 2ʒɨə-1lhiõ 'go unencumbered' and 1ŋwəi-2lɨị 'to be willing' |
also right side of both halves of 2zeʳw-2ləi 'east' and 1siə 'to die' see "Tangraphic Radicals 11" |
abbreviation of |
abbreviation of |
abbreviation of |
abbreviation of |
| 1za | 1ka | 1ʔo | 1lɨẽ |
| first half of 1za-1giẹ 'red-faced Tangut' and the constellation name 1za 1ŋiẹ |
'oral cavity' | 'the surname O' | second half of 1tiẽ-2lɨẽ 'sun' |
At least four of the five ![]() characters
involve the sun:
characters
involve the sun:
- 'sun'
- 'east' (where the sun comes from)
- 'to die' (the Tangraphic Sea equates the rising sun with tails and ends* - why?)
- 'moon' (the opposite of sun?)
I could gloss ![]() as 'sun', but that begs the question of why
it's not in other solar tangraphs: e.g.,
as 'sun', but that begs the question of why
it's not in other solar tangraphs: e.g.,
2bəi 'sun', 2niəə 'day' (< Chn 日 'sun', 'day'), 1die 'sun, day' (the resemblance to Eng day is coincidental!)
Could the components of '' represent parts of a phrase associated with the moon - the Tangut equivalent of "One small step ..."? Would Tangut-style characters for English 'moon' consist of parts of 'small', 'step', 'giant', and 'leap'?
8.27.3:40: These Tangraphic Sea definitions indicate a connection between 'east'/'sun' and 'tail'/'end':
1.16.263: '1ti is the east, the east, the end, the rising sun, the tail end, the tail end, the tail end, the tail end, the sun, the east.'
1.29.112: '1ʔia is the east, the east, the tail end, the east, the rising sun, the tail end, the end, the tail end, the end, a tail, the end.'
1.72.211: '1vɨị (< Chn 尾 'tail'?) is the tail end, the end, the rising sun, the tail end, where the sun emerges.'
1.85.271: '1riaʳ is the east, the rising sun in the east, the tail end, the tail end, the east, the east.'
3.15.243: '2dzəu is the tail end, the rising sun, the eastern tail end, where the sun rises.'
The definitions above are based on Li Fanwen's (2008: 150, 864) Chinese translations.
Repetitive definitions indicate synonyms in the original Tangut. As Grinstead (1972: 199) wrote forty years ago, "this richness of synonyms is worth further investigation." There are at least three types of synonyms:
1. native, common, and monosyllabic
2. native, uncommon, and disyllabic: Kepping's 'ritual' and Boxenhorn's 'odic'; see Andrew West's "The Myth of the Tangut Ritual Language"
3. Chinese loanwords
Examples of all three types appeared above:
| Native common | Native uncommon | Chinese |
|
|
|
|
| 2bəi 'sun' and 1die 'sun, day' | 1tiẽ-2lɨẽ 'sun' | 2niəə 'day' (< Chn 日 'sun', 'day') |
Note the absence of a common semantic grapheme to facilitate the identification of synonyms. There is also no graphic distinction between the three types of words: e.g., no grapheme is unique to any of the three types.