
12.8.25.23:41: THE SAGE'S BRILLIANCE
The passing of Neil Armstrong made me think about Tangut2lhị 'moon'
Since it appears as the seventh character in the Golden Guide primer, it must have been considered very important and it might have been among the first Tangut characters ever created. It was certainly among the first Tangut characters I learned sixteen years ago.
It consists of three parts:
 |
 |
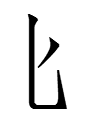 |
| 2ʃɨẽ | (never an independent character) | |
| 'sage' (borrowed from Chinese 聖 'id.'); also on the right side of 2bəi 'sun' |
'light, brilliance' (Kychanov
1964: 142); 'front' (Nishida 1966: 187) |
function unknown; only appears on the (bottom) right of 548 characters; cannot be phonetic |
The word 2lhị may go back to Pre-Tangut *s-kĭ-la-H:
The initial lh- (= hl-, phonetically a voiceless liquid [l̥] or lateral fricative [ɬ]?) is a fusion of *k-l-.
External cognates like
gDong-brgyad rGyalrong sla 'moon'
Written Tibetan zla-ba 'moon'
Written Burmese လ <la> 'moon'
and possibly
Old Chinese 'evening' (written as a drawing 夕 of the moon), reconstructed by Sagart (1999: 160) as *slak (now *s-N-rak in Baxter and Sagart 2011 which like Schuessler's [2009: 71] *sjak can't be related to the Tibeto-Burman *la-forms)
point to an earlier *a; I reconstruct a short unstressed *ĭ that conditioned 'brightening' before being lost:
*ĭ ... a > *ĭ ... æ > *ĭ ... ia > *iə > i
The tenseness (subscript dot) of the vowel reflects an earlier *s-.
The second 'tone' is from *-H. The creaky tone of Burmese la 'moon' suggests that Tangut *-H was a glottal stop *-ʔ.
12.8.24.23:59: GRAPHONETIC TREES
Both Karlgren (1957) and Schuessler (2009) catalogued Chinese characters by phonetic series in different layouts. Here are their listings for the 婁-graphs that were the subject of my last three posts.
Karlgren series 123: horizontal (mostly only one reading per character given below)
a 婁 *gli̯u, *glu b 僂 *glu c 膢 *glu d 摟 *glu e 蔞 *glu f 屢 *gli̯u g 瘻 *gli̯u h 縷 *gli̯u
i 鞻 *kli̯u j 塿 glu k 樓 *glu l 螻 *glu m 鏤 *glu n 髏 *glu o 窶 *g’li̯u p 寠 *g’li̯u q 屦 *kli̯u r 數 *sli̯u
Karlgren series 1207: horizontal
a 數 *sŭk, *ts’i̯uk b 籔 *suk* c 藪 *sug
Schuessler series 10-29: vertical (equivalent to Karlgren's 123 and 1207 combined; mostly only one reading per character given below; Schuessler recycles Karlgren's numbers within a series)
123a 婁 *ro(ʔ), rô(ʔ)
123j** 塿 *rôʔ
123b 僂 *rô
123c 膢 *rô
123d 摟 *rô
123e 蔞 *rô
123f 屢 *roh
123g 瘻 *ro
123h 縷 *roʔ
123i 鞻 *kroh
123k 樓 *rô
123l 螻 *rô
123m 鏤 *rô
123n 髏 *rô
123op 窶寠 *groʔ
123q 屦 *kroh
123r 數 *sroʔ
1207a 數 *srôk, *k-sok
1207b 籔 *sôʔ
1207c 藪 *sôʔ
Last night, I realized that a hierarchical 'tree' might be useful with the original phonetic at the top and its derivatives subgrouped by graphic and/or phonetic criteria at the bottom: e.g. (partial sample only; Early Old Chinese reconstructions are mine),
| 1.0 婁 *(Cɯ-)ro(ʔ) | |||
| 1.0.1 僂 *ro 1.0.2 膢 *ro 1.0.3 摟 *ro 1.0.4 蔞 *ro 1.0.5 螻 *ro 1.0.6 鏤 *ro 1.0.7 髏 *ro |
1.1 *Kɯ- | 1.2 數 *sɯ-roʔ, *srok, *kɯ-sok | |
| 1.1.1 *kɯ- | 1.1.2 *N-kɯ- | 1.2.1 籔 *soʔ 1.2.2 藪 *soʔ |
|
| 1.1.1.1 鞻 *kɯ-ros 1.1.1.2 屦 *kɯ-ros |
1.1.2.1 窶 *N-kɯ-ros 1.1.2.2 寠 *N-kɯ-ros |
||
*k-initial graphs (123i 鞻 and 123q 屦) are separated from each other in Karlgren and Schuessler, whereas I have clustered them in one 'branch' (1.1.1) without a head character since I cannot determine whether was created before, whereas I'm certain 1.0 predates 1.0.1 and 1.2 predates 1.2.1, etc.
zhongwen.com features sideways trees of characters that are graphically but not necessarily phonetically similar. Here is the tree for 女 *Tɯ-naʔ leading to 婁 *(Cɯ-)ro(ʔ) and its derivatives.
A similar tree could be drawn for the Tangut translation equivalent of 1.2 'number', though this tree based on the Tangraphic Sea is purely graphic:
1.0 2ŋeʳw 'number' |
||||
1.1 top left |
1.2 right |
|||
1.1.1 1riuʳ 'all' |
1.2.1 1dʒɨõ 'circle' |
1.2.2 1gɨəə 'nine' |
1.2.3 1dʒɨə̣ 'ten' |
1.2.4 1thəu 'to count' |
It is not clear whether the derivations from the Tangraphic Sea are valid or not.
8.25.2:36: I would try to make similar trees for the Khitan and Jurchen large script characters for 'number' if only I knew what they were. I'm skeptical that trees would even be possible because the components of those scripts generally do not seem to be combined in any transparently rational manner; their inner logic remains elusive. Just as I have proposed 'Tangut B' as a hypothetical language underlying the structure of some Tangut characters, I suspect that the language(s?) of Parhae underlie the structure of some Khitan and Jurchen large script characters.
*8.25.2:12: I would have expected *sug for 1207b 籔. The Middle Chinese fanqie 蘇后切 for 籔 in Guangyun or Jiyun should go back to Karlgren's *sug.
**8.25.2:20: Schuessler presumably listed 123a 婁 *rô(ʔ) next to 123j 塿 *rôʔ since they both meant 'mound': i.e., since they were alternate spellings of the same word.
12.8.23.23:59: A *SLO-LUTION TO THE P-RO-BLEM
I'm still troubled by three members of Schuessler's (2009: 151-152) phonetic series 10-29 (combining Karlgren 1957's 123 and 1207; see my last two posts). Here are the most straightforward reconstructions for Middle Chinese (MC) and Late, Middle, and Early Old Chinese (LOC, MOC, EOC) in my system:
數 'close-meshed'
MC *tshuok < LOC *tshuok < MOC *tshok < EOC *Cɯ-tshok or *kɯ-sok
籔 'container' and 藪 'marshland rich in game'
MC *səuʔ < LOC *soʔ < MOC *soʔ < EOC *soʔ
Why were they written with the *r-phonetic 婁 if they didn't have *r in Old Chinese?
What if they had a medial *-l- that was lost?
數: EOC *Cɯ-tshlok or *kɯ-slok籔 and 藪: EOC *sloʔ
*lo is not far from 婁 EOC *(Cɯ-)ro(ʔ).
The trouble is that if Sagart (1999: 69) is correct, 1OC *sl- should have become MC *dz- before OC *o. (EOC *tshl- might have become MC *tsh-, as I recall that Sagart told me circa 2000 that OC *stl- became MC *ts- in 酒 'wine'*.)Schuessler (2009: 152) reconstructed the three words without any liquid in OCM (Minimal Old Chinese):
數 OCM *k-sok 'close-meshed'
籔 OCM *sôʔ 'container'
藪 OCM *sôʔ 'marshland rich in game'
Perhaps their phonetic was 數 rather than just 婁:
數 OCM *k-sok sounded like 數 OCM *srôk 'frequent'
籔 and 藪 OCM *sôʔ sounded like 數 OCM *sroʔ 'to count'
*8.24.00:40: At the time I wanted to reconstruct 酒 'wine' as *tsluʔ (cf. its phonetic 酉 *luʔ, a drawing of a wine vessel) which became *s-t-luʔ after my discussion with Sagart. In his system, roots could not begin with *tsl-, so *l- became the root initial and *s- and *t- were prefixes with unknown functions. I can't remember the reasoning for *s-t- instead of *t-s-. In his system, OC *s- plus root inItial *t- became MC *tɕ-, not *ts-. Perhaps metathesis prevented *s-t-l- from also becoming a palatal affricate:
| Old Chinese | √*t- | *s- + √*t- | *s- + *t- + √*l- |
| metathesis before *l- | *t- | *st- | *tsl- |
| medial *l-loss | *t- | *st- | *ts- |
| affrication of *(s)t- | *tɕ- | *stɕ- | *ts- |
| Middle Chinese | *tɕ- | *ts- | |
Baxter and Sagart (2011) more recently reconstructed 酒 as *tsu with an initial *ts- very different from the *m.r- they reconstruct for its phonetic 酉 *m.ruʔ 'wine' (cf. Vietnamese rượu 'wine').
Schuessler (2009: 177) reconstructed 酒 as OCM *tsiuʔ and 酉 as OCM *juʔ (= *tsiuʔ without *ts-). The origin of the OCM *ts- ~ *j- alternations he discusses on pp. 96-97 of his 2007 etymological dictionary is unknown to me. (Could *ts- have been a fortition of *j-, or was *j- a lenition of a *ts-like affricate?) Vietnamese rượu 'wine' could be from Schuessler's (2009: 179) 醪 OCM *rû 'wine with dregs'. (The Vietnamese form seems to reflect an LOC *rauʔ; Chinese *-a- sometimes unpredictably corresponds to -ươ- in Vietnamese.) Perhaps some sort of *r- ~ *l- dialectal variation underlies a word family with all three of these 'wine'-words. For another view, see Pulleyblank (1991: 63-65) who reconstructed 酉 with OC *ɥ-.
8.24.0:48: According to Thesaurus Linguae Sericae, Pan Wuyun reconstructed 酒 as *skluʔ (cf. my *s-t-luʔ) and 酉 as *k-luʔ.
12.8.22.23:59: *-RO SYLLABLES *S(R)O-UGHT AND FOUND? (PART 2)
In part 1, I asked,An answer popped into my mind last night as I wrote the question.Why would *r-less 數 MOC [Middle Old Chinese]* *tshok be written with an *r-phonetic 婁?
Aspirated onsets in cognates found across modern Tai varieties developed mainly from
PT [Proto-Tai] clusters with medial *-r- , e.g. *pr-
PT uvular consonants, e.g. *q-
Loanwords, especially from Chinese
Similarly, could aspiration in Chinese be partly from uvular medial *-ʀ- (= emphatic / underlined *-r- in my usual MOC notation)?
I thought MOC *tshok might be an example of that, but it can't be because it's nonemphatic: i.e., it never had *-r- and its MC (Middle Chinese) reading *tshuok has a high vowel that resulted from that lack of emphasis.
Schuessler (2009: 152) proposed that its *tsh- is from *k-s- and reconstructed *k-sok its earliest Old Chinese form. I would reconstruct *k-sɯ-rok in Early Old Chinese (EOC) with
- a *k- that fused with the following *s-: *k-s- > *xs- > *tsh-
- a high vowel *-ɯ- to block the development of emphasis; EOC *ksrok would have become MOC emphatic *tshok
- *-r- to match the *r-phonetic 婁 (but why hasn't it left a trace?)
Its root *sɯ-rok is shared with the other readings of 數
EOC *sɯ-roʔ < *-k 'to count'
EOC *sɯ-rok-s 'number'
EOC *srok < *sɯ-rok 'frequently'
and its meaning 'close-meshed' (of nets) might be from 'having many threads'. (A net with relatively few threads would be open-meshed.) The *k- could be Sagart's (1999: 104-106) Old Chinese stative verb (here, adjectival) prefix *k-.
Maybe there was a uvular medial *-r- in these other words written with the *r-phonetic 婁:籔 'container'
MC *səuʔ < LOC *soʔ < MOC *soʔ < *sroʔ < EOC *sroʔ (< *sɯ-roʔ?)
related to its alternate reading 'a measure' (a member of the 'count' word family above?):
MC *ʂuəʔ < LOC *ʂuoʔ < MOC *sroʔ < EOC *sɯ-roʔ (< *-k?)
藪 'marshland rich in game'
MC *səuʔ < LOC *soʔ < MOC *soʔ < *sroʔ < EOC *sroʔ (< *-k?)
whose final *-k corresponds to the -g in Schuessler's (2009: 152) proposed Old Tibetan cognate sog 'grassland'
In those cases, *-r- became an *-h- that was lost after *s-.
Here, *-r- might have fused with the aspiration of *tsh-:
趨 in 趨馬 'groom'**
Md cǒu < MC *tshəuʔ < LOC *tshoʔ < MOC *tshoʔ < *tsroʔ < EOC *tsroʔ
with variant 騶Md zōu < MC *tʂu < LOC *tʂu < MOC *tsru < EOC *tsru***
the Mandarin initial is irregular and implies EOC *tsu; I would expect *zhōu
Although it is possible to reconstruct EOC 'groom' as *r-tso, I would rather reconstruct a medial *-r- since all the other characters in this phonetic series (Schuessler 10-36, Karlgren 132) had LOC retroflex initials, and I reconstruct LOC pure retroflex series with *Cr-clusters in earlier stages:
芻 'grass for fuel'
Md chú < MC *tʂhuə < LOC *tʂhuo < MOC *tshro < EOC *Cɯ-tshro
the Mandarin tone is irregular and implies EOC *Nɯ-tshro; I would expect *chū
the Mandarin reading may be by analogy with 雛~鶵 below
趨 ' to hasten'
Md qū < MC *tʂhuə < LOC *tʂhuo < MOC *tshro < EOC *Cɯ-tshro
the Mandarin initial is irregular and implies EOC *Cɯ-tsho; I would expect *chū
also cf. 趣 'id.'
Md qù < MC *tshuəh < LOC *tshuoh < MOC *tshoh < EOC *tshos
雛~鶵 'chicken'
Md chú < MC *dʐuə < LOC *dʐuo < MOC *dzro < EOC *Cɯ-dzro or *Nɯ-tsro
皺 'to wrinkle up' (cognate with 縐 below)
Md zhōu < MC *tʂu < LOC *tʂu (not attested before LOC)
縐 'crinkle'
Md zhòu < MC *tʂuh < LOC *tʂuh < MOC *tsruh < EOC *tsrus
齺 'teeth shutting against each other'
Md zōu < MC *tʂu < LOC *tʂu < MOC *tsru < EOC *tsru
the Mandarin initial is irregular and implies EOC *tsu; I would expect *zhōu
騶 'to run'
Md zòu < MC *dʐuh < LOC *dʐuh < MOC *dzruh < EOC *N-tsru-(ʔ-)s
the Mandarin initial is irregular; I would expect *zhòu
also cf. 走 'id.'
Md zǒu < MC *tsəuʔ < LOC *tsoʔ < MOC *tsoʔ < EOC *tso-ʔ
and 趨 and 趣 ' to hasten' above
However, the Mandarin readings with q- [tɕh] < *ts- and z- [ts] and *r-less cognates (趣, 走) make me wonder if these words actually had *T-tsU root structure and Mandarin sometimes preserved the bare roots: e.g.,
騶 Md zòu < MC *dzuh < EOC *N-tsu(-ʔ-)s
but MC *dʐuh < EOC *T-N-tsu-(ʔ-)s
*T- represents a range of coronals. See "The Great Grade II (and III) Merger?".
8.23.2:03: Maybe the EOC *-o ~ *-u alternation goes back to *-o(w) ~ *-əw. It can't be explained in terms of Pulleyblank's 1991 OC reconstruction in which the two rhymes have different final consonants:
| Old Chinese rhyme class | 侯 | 幽 |
| This site | *-o | *-u |
| Pulleyblank | *-aɥ | *-əw |
8.23.2:59: I don't like what I'll call my *-ro-ho hypothesis for two reasons:
First, why didn't *-r- become *-h- after vowels other than *o? What makes *o so special? The arbitrary is the less likely. Pittayaporn's *r-*h shift is not restricted to any specific vowel in Tai.
Second, why aren't there any examples of *-r- becoming *-h- after nonsibilants? Did *-ro merge with *-(r)o and/or *-o except after sibilants?
*8.23.1:21: I'm finally going to formally define my terms Late, Middle, and Old Chinese:
Late:
Before vowel reduction of MC: e.g., *-uo > -uə
Has *-ɕ from *-c or *-tɕ
Has rich vowel system after vowel bending conditioned by [±emphasis] and loss of emphasis
After loss of most initial clusters; only *Cw-clusters remain
Middle:
Has twelve-vowel system in main syllables
*a *i *u *ə *e *o
*a *i *u *ə *e *o
after emphasis conditioned by vowels and loss of many (most?) presyllabic vowels conditioning emphasis; similar to Schuessler's OCM (Minimal Old Chinese)
Has *-c or *-tɕ < *-ts; *-s shifted to *-h
Early
Has six-vowel system in main syllables:
*a *i *u *ə *e *o
No emphasis, but has all presyllabic vowels destined to condition it
Has *-s and *-C-s final clusters
**8.23.00:57: I found 趨馬 'groom' in Schuessler (2009: 152) but I can't find it at Scripta Sinica. Is it attested in Old Chinese? I wish I had my copy of Schuessler's Zhou Chinese dictionary with me.
***8.23.2:36: I don't understand why Schuessler (2009: 154) reconstructed the MC homophones 齺 and 騶 with different rhymes in Old Chinese:
齺 MC *tṣjəu < Later Han Chinese *tṣu < OCM (≅ my MOC) *tsru
騶 MC *tṣjəu < Later Han Chinese *tṣuo < OCM *tsro
I reconstruct both of them identically in Old Chinese, though they could have had different high-vowel presyllables that were lost without a trace: e.g., *kɯ-tsru and *pɯ-tsru, etc. They are unrelated words, so they could have originated from disyllabic or even trisyllabic words: e.g., *kitsadu and *putsətu. This is highly speculative. There is no way to reconstruct such a degree of complexity (or CV simplicity from another perspective) from the extant evidence.
12.8.21.23:59: *-RO SYLLABLES *S(R)O-UGHT AND FOUND? (PART 1)
In "Why No Final *-Ro?", I was uncertain about Starostin's reconstructions of 貿 and 裒 with his equivalent of Middle Old Chinese (MOC) emphatic *-ro. However, I still think MOC had emphatic *-ro syllables even though they lack a distinctive reflex in Middle Chinese (MC). But where can such syllables be found? One place to look is *r-phonetic series like Schuessler's (2009: 151-152) 10-29 (combining Karlgren 1957's 123 and 1207).
數 with the *r-phonetic 婁* has four MC readings (below; followed by their mechanically derived Late, Middle, and Early Old Chinese sources)
'to count': MC *ʂuəʔ < LOC *ʂuoʔ < MOC *sroʔ < EOC *sɯ-roʔ
'number': MC *ʂuəh < LOC *ʂuoh < MOC *sroh < EOC *sɯ-rok-s
'frequently': MC *ʂɔk < LOC *ʂɔk < MOC *srok < EOC *srok
'close-meshed': MC *tshuok < LOC *tshuok < MOC *tshok < EOC *Cɯ-tshok
I initially thought that the first three were cognates that were all emphatic (underlined) in MOC, though the first two lost their emphasis and merged with nonemphatic *-roʔ and *-roh:
LOC *ʂuoʔ < *ʂuɔʔ < *ʂɔʔ < MOC *sroʔ < *s-roʔ
LOC *ʂuoh < *ʂuɔh < *ʂɔh < MOC *sroh < *s-rok-s
However, now I think even the first two were always nonemphatic as in the first set of derivations above. Moreover, 'frequently' might have had the same high presyllabic vowel as 'to count' and 'number', but this vowel was lost, so it could not prevent the resulting monosyllable from acquring emphasis:
MOC *srok < EOC *srok < *sɯ-rok
I reconstruct all three numerical words with a common EOC root *sɯ-rok (whose final *-k became *-ʔ in 'to count')**.
The real mystery is the fourth reading. Why would *r-less 數 MOC *tshok be written with an *r-phonetic 婁? I'll post a tentative solution in part 2.
*8.22.8:01: The phonetic 婁 has four readings:
'to drag': MC *luə < LOC *luo < MOC *ro < EOC *Cɯ-ro
'to bind': MC *luəʔ < LOC *luoʔ < MOC *roʔ < EOC *Cɯ-roʔ
'empty': MC *ləu < LOC *lo < MOC *ro < EOC *ro
'mound': MC *ləu(ʔ) < LOC *lo(ʔ) < MOC *ro(ʔ) < EOC *ro(ʔ)
I reconstruct *Cɯ- for 'to drag' and 'to bind' to account for their absence of emphasis in MOC. Nonemphatic MOC *o partly 'bent' upwards, becoming LOC *uo.
'Empty' and 'mound' might also have had a presyllable *Cɯ- that was lost without a trace.
The initial consonant of the presyllable *Cɯ- could have been *k- (cf. MOC 樓蘭 *kʌ-ro ran for Kroraina) or *s- (cf. MOC 數 MOC *sroʔ ~ *sroh ~ *srok) or something else entirely.
**8.22.8:25: The final *-ʔ of 'to count' may be a simplification of root-final *-k plus a suffix *-ʔ or may be due to "a phonological confusion of -k and -ʔ" (Sagart 1999: 134).
I am reminded of Huffman's (1970: 22) phonological analysis of Khmer in which
/k/ could only be a coda after vowels other than /a ɑ ə/
/ʔ/ could only be a coda after /a ɑ ə/ and short vowels (e.g., /u/ but not long /uu/)
His modern Khmer /k/ is always from earlier Khmer *-k, but his modern Khmer /ʔ/ is from both *-ʔ and *-k:
| After | non-/a ɑ ə/ vowels | /a ɑ ə/ | short vowels |
| Earlier Khmer | *k | *ʔ | |
| Modern Khmer | /k/ | /ʔ/ | |
There could have been a similar (but only occasional and perhaps dialectal) shift of *-k to *-ʔ in Old Chinese.
12.8.20.23:59: WHY NO FINAL *-RO?
Axel Schuessler's Minimal Old Chinese and Later Han Chinese: A Companion to Grammata Serica has a table of Old Chinese (OC) finals on p. 145 revealing a curious gap: there was no emphatic (= pharyngealized) *-ro (= *-rô in Schuessler's reconstruction). Below is a summary of that table (converted into my reconstruction):
| Early Old Chinese | Middle Old Chinese | Late Old Chinese | Middle Chinese | Middle Chinese grade |
| *(Cʌ)-o, *(Cʌ)-oŋ, *(Cʌ)-ok | *-o, *-oŋ, *-ok | *-o, *-oŋ, *-ok | *-əu, *-oŋ, *-ok | I |
| (no *(Cʌ)-ro?), *(Cʌ)-roŋ, *(Cʌ)-rok | (no *-ro?) *-roŋ, *-rok | (no *-ɔ?), *-ɔŋ, *-ɔk | (no *-ɔ?), *-ɔŋ, *-ɔk | II |
| *Cɯ-(r)o, *Cɯ-(r)oŋ, *Cɯ-(r)ok | *-(r)o, *-(r)oŋ, *-(r)ok | *-uo, *-uoŋ, *-uok | *-uə, *-uoŋ, *-uok | III |
My version of the OC emphatic theory predicts that Early OC (EOC) syllables with nonhigh vowels should develop emphasis in what I'll call Middle OC (MOC) unless this is blocked by a preceding high vowel presyllable that conditions nonemphatic harmony: e.g.,
EOC *Cro (no presyllable) > MOC *Co (emphatic)
EOC *Cʌ-Cro (low vowel presyllable) > MOC *Cro (emphatic)
EOC *Cɯ-Cro (high vowel presyllable) > MOC *Cro (nonemphatic)
(The presyllables are implied by phonetic elements in the script predating their loss and/or characteristics of initial consonants postdating their loss.)
If MOC had *Cro but no *Cro, that implies EOC *Cɯ-Cro (among other possibilities*) but no simple EOC *Cro. The absence of EOC *Cro might not be so strange if EOC were also missing other *Cr-nonhigh vowel syllables like *Cra and *Cre, but both were common.
I think EOC *Cro also used to be common, though its reflexes later merged with those of *Cɯ-Cro:
| Stage 1: EOC; pre-emphasis | Stage 2: MOC; emphatic harmony | Stage 3: vowel bending (nonemphatic *o partly raises to match the height of *Cɯ if presyllable not already lost) | Stage 4: Late OC; loss of presyllables, emphasis, *-r- | Stage 6: Very Late OC: merger | Stage 6: Middle Chinese |
| *(Cʌ)-Cro | *(Cʌ)-Cro | *(Cʌ)-Cro | *Cɔ | *Cuɔ | *Cuə |
| *Cɯ-Cro | *Cɯ-Cro | *Cɯ-Cruo | *Cuo |
Although historians use Middle Chinese readings to determine the emphatic status (or its equivalent in their reconstructions: e.g., vowel length) of their OC sources, that may not be possible for MC *-uə if it is from an OC *-o-type syllable**.
Two things that bother me:
First, is there any rhyming evidence for stage 4 when *-ɔ and *-uo briefly did not rhyme? Is there any evidence outside the rhyme dictionary/table tradition (e.g., Min colloquial forms) for such a distinction that may have been lost in literary dialects?
Second, why did this merger occur in LOC 'open'*** syllables but not in closed syllables?
Starostin reconstructed no merger. His OC reconstruction has both *-rō (equivalent to my MOC *-ro) and *-ro (equivalent to my MOC *-ro). In modern Sinitic-type languages with vowel length, long -ō is more common than short -o: e.g., in the SEAlang Thai dictionary, -oo outnumbers -o by 157 to 18. Khmer, though not tonal, has a sesquisyllabic structure like OC, and in the SEALang Khmer dictionary, -oo outnumbers -o by 512 to 0. However, in Starostin's OC database, there are only two words with *-rō:
貿 'to barter': MC *məuh (not *mɔh!) < Starostin *mrō(ʔ)s = my MOC *mro(ʔ)s
裒 'to collect': MC *bəu (not *bɔ!) < Starostin *bhrō = my MOC *bro
Are these the only two surviving instances of *-ro that did not merge with *-(r)o?
8.21.3:35: If I knew nothing but the MC readings of 貿 and 裒, I would derive them from EOC *mos and *bo. However,
*The possible EOC sources of MOC *Cro are貿 has the phonetic 卯 EOC *mruʔ, implying that its vowel was *-u.
Perhaps 貿 was EOC *mʌ-ru(ʔ)s or *Cʌ-mru(ʔ)s which became LOC *mɔuh. I could take two irregular steps to get from there to *moh, the direct ancestor of MC *məuh:
*mɔuh > *mouh > *moh
On the other hand, if 貿 was EOC *mro(ʔ)s, why didn't it become MC *muəh, as my table above would predict?
裒 seems to have the phonetic 臼 EOC *guʔ - could that be from an earlier *gwəʔ < *kbəʔ?
Starostin pointed out two alternate spellings of the same word:
掊 MC *phəuʔ < EOC *p(h)oʔ 'to beat; to cleave' (Karlgren 1957: 263) doesn't have anything semantically in common with 裒, though its phonetic 立 = 不 EMC *pə is close to my proposed 臼 EOC *kbəʔ.
捊 MC *bæu ~ *bəu < EOC *Tʌ-bu ~ *bo 'to come together'I think 裒 was simply *bo like 捊.
*Cɯ-Croh
(with a presyllable that was later lost)
*Cɯ-ro (with a presyllable that later fused with *r-)
*Tɯ-Co (with a presyllable that later lost its vowel and underwent metathesis; see "The Great Grade II (and III) Merger?")
**MC *-uə can also be from MOC *-a preceded by labial or labialized consonants: e.g.,
MOC *Pa > *Pɨa > *Pua > *Puo > *Puɔ > MC *Puə
***'Open' syllables included those ending in *-ʔ and *-h. If *-ro, *-roʔ, and *-roh all behaved identically except for their final consonants, perhaps *-ʔ and *-h were no longer final consonants, and Late OC had developed phonemic phonation or even tones.
12.8.19.23:59: THE GREAT GRADE II (AND III) MERGER?
The rhymes of Middle Chinese (MC) have been classified according to four 'grades' in rhyme tables. These grades roughly correspond to four possible combinations of Old Chinese (OC) segment types. (I am oversimplifying.*)
| Old Chinese | Middle Chinese Grade | |
| Medial *-r- | Emphasis | |
| - | + | I |
| - | IV | |
| + | + | II |
| - | III | |
Tangut also had a grade system with similar though not identical origins (again oversimplifying**):
| Pre-Tangut | Tangut Grade | |
| Medial *-r- | Emphasis | |
| - | + | I |
| + | II | |
| -/+ | - | III or IV generally depending on initial consonant |
MC has many Grade II and III syllables that should go back to OC *-r-syllables if the above account of grade origins is correct. I agree with Schuessler (2009: 21): there is "a suspiciously large number of OC words with *r. He gave two types of examples which I have converted into my reconstruction:
15 syllables of the type MC *mɨi (Grade III) < OC *mr(ə)i
0 syllables of the type MC *mi (Grade IV) < OC *mi
3 syllables of the type MC *mɨe (Grade III) < OC *mre
27 syllables of the type MC *mie (Grade IV) < OC *me
Did OC really have 15 *mr(ə)i but zero *mi - while having *me outnumber *mre by nine to one?
(8.20.1:32: For comparison, here are the numbers of entries beginning with similar <m(r)V> syllables in SEAlang's Burmese dictionary [head entries only; disregarding tones]:
မြီ <mrii>: 3*** ['debt', 'tail', 'kind of Chinese noodles']
မီ <mii>: 5
မြေ <mre>: 1
မေ <me>: 25
As I would expect, <mV> outnumbers <mrV>.)
Schuessler concluded that "[s]omething is out of balance with these types of syllables. For the sake of simplicity, OCM [Schuessler's Minimal Old Chinese] will try [to] remove *r in some [OC finals corresponding to MC Grade III] finals."
I have wondered if some excessive *-r- should be reinterpreted rather than removed. What if OC *Cr- was a merger of several earlier types of clusters: e.g. (disregarding emphasis for simplicity),
| Stage 1 | Stage 2 | Stage 3 |
| *tC- | *rC- | *Cr- |
| *rC- | ||
| *lC- | ||
| *Ct- | *Cr- | |
| *Cr- | ||
| *Cl- |
I am not sure about some of the stage 1 clusters: e.g., perhaps preinitial *t- remained and medial *-l- disappeared as in Sagart (1999: 90-97, 124).
I use the symbol *T- to represent an unknown nonnasal, nonsibilant coronal in OC clusters: e.g., last night I reconstructed 麃 'a kind of deer' as OC *Tbau which could be *tbau, *rbau, or *lbau but not *nbau or *sbau.
*8.20.1:24: A more precise list of sources of the Four Grades:
I. OC [+emphatic] *a, *u, *ə, *o (cf. IIIa)
**8.20.1:24: I think Tangut Grade II may be partly from syllables with uvular initials which were automatically [+emphatic].II. OC [+emphatic] *ra, *ri, *ru, *rə, *re, *ro (cf. IIIb)
IIIa. OC [-emphatic] *a, *u, *ə, *o (cf. I)
IIIb. OC [-emphatic] *ra, *ri, *ru, *rə, *re *ro (cf. II)
IVa. OC [-emphatic] *i, *e (cf. IVb)
IVb. OC [+emphatic] *i, *e (which both became *ie in late MC, merging with MC *ie < OC [-emphatic] *e; cf. IVa)
***8.20.1:35: SEAlang listed "25 items" without differentiating between head entries and nonhead entries, but all 25 items belong to only three head entries.