
12.1.7.17:09: JURCHEN POLYPHONY 2: SCIENTIA ALBA
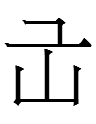
Jurchen has a single character with variantsfor both shang- of
shanggiyan 'white' (cf. Manchu shanggiyan 'id.')
and sa- 'to know' (cf. Manchu sa- 'id.'*).
Jin (1984: 98) listed
~
as variants that were only read sa. Did the first character originally represent only shang? Kiyose (1977: 68) wrote, "It is impossible to say whether similar characters with different pronunciations were erroneously written the same way."
Jin (1984: 98) derived this graph from the Khitan large script graph
<sha>
~
in the Khitan title
<sha.ri>
transcribed in Chinese as 沙里 *shali and translated as 郎君.
There is also a Khitan large script character
<?> '?'
resembling one of the Jurchen variants.
'White' was
<?>
in the Khitan large script. Janhunen (2003: 397) regarded Manchu shanggiyan 'white' as a loan from a Para-Mongolic cognate of Proto-Mongolian *cagaxan with a Para-Mongolic innovation *c- > sh-. One might think that the Manchu and Jurchen words for 'white' were borrowed from Khitan, but Khitan had a c- in addition to an sh- even in native words (implying that the c- > sh- shift had not taken place) and the Khitan word for 'white' is unknown, so it is doubtful that Khitan had a sh-word for 'white'. In any case, the KLS graph for 'white' only very vaguely resembles the Jurchen characters and is probably not related to them.
If the Jurchen characters were derived from the KLS:
|
Khitan large script |
Early Jurchen |
Later Jurchen (and/or mistakes in the Sino-Jurchen Vocabulary) |
|
|
<shang>? (but not <sha>!) |
<shang> ~ <sa> and <sa> (but not <sha>!) |
|
<?> (<sa> like its Jurchen derivative?) |
<sa> |
|
If the Jurchen and KLS characters were independently derived from common (Parhae?) prototypes:
|
Parhae |
Derivatives |
|
? |
Khitan large script:
<sha> |
|
Jurchen:
<shang> ~ <sa> and <sa> (but not <sha>!) |
|
|
? |
Khitan large script:
<?> (<sa> like its Jurchen counterpart?) |
|
Jurchen:
<sa> |
Next: The We Back to the City
(Post revised 15.4.4.23:23.)*A shaman is a sa-man 'knower' in Manchu. The same suiffix was in Jurchen
<sori.duman>
soridu-man 'fighting'
from soridu- 'to fight' in part 1.
12.1.6.23:56: JURCHEN POLYPHONY 1: BITTER URBAN BARBARIANS
Kiyose (1977: 80) listed two Jurchen characters in a row with identical shapes:
399: <ku>; transcribed in Chinese as 苦 *ku 'bitter'; phonogram for the second syllable of takura- 'send':
<ta.ku.ra> (cf. Manchu takūra- 'id.')
400: <duman>; transcribed in Chinese as 都蠻 *duman 'capital-southern barbarian'; phonogram for the second half of soridu-man 'fighting, melee':
<sori.duman> (cf. Manchu soridu- 'to fight' [Kiyose 1977: 122; I can't find this word in any Manchu lexicon at hand])
One might wonder if Jurchen characters often had multiple readings like the Chinese characters used in Japanese. However, I could only find three Jurchen characters in Kiyose (1977) with multiple readings. I'll look at the other two in parts 2 and 3 of this series.
Kiyose (1977: 80) wrote,
This character [400] seems to be exactly the same as character 399 as far as appearance goes. These characters were, however, perhaps different from each other, and one or the other is presumably a scribal error.
Either possibility raises questions I cannot answer:
If 399 and 400 are a single polyphonous character (i.e., a character with multiple readings), which reading came first? Or was the character designed with two readings in mind?
If 399 and 400 were originally distinct characters, what did the lost other character look like?
1.7.00:59: Jin (1984: 160) listed two variants of 399/400:
The second was read <ku>. I do not know which reading(s) belonged to the first. Could one or both of these variants actually be distinct characters? For example, perhaps
≠
~
or
were <ku> and <duman> or vice versa.
In either case,
what is the relationship between the shape(s) of 399/400 and its readings?
why was a phonogram <duman> created even though there was no suffix -duman? Kiyose (1977: 122) analyzed soriduman as soridu-man with a nominal suffix -man, and Kiyose (1977: 80) speculated that -du- "could be the cooperative verbal suffix; cf. Ma. -ndu- id." I know of no Manchu word duman, so there may not have been a Jurchen word duman.
1.7.1:28: why not write the infrequent syllable sequence duman with phonograms as, say,
<du.man>
(The character <man> is in Jin's (1984: 231) entry for the place name 滿涇站 <man.ging.jan> but does not have an entry of its own in that dictionary.)
or
<du.ma.an>?
Next: Scientia alba
12.1.5.18:20: FLORA DIVINA
Kiyose's (1977) A Study of the Jurchen Language and Script: Reconstruction and Decipherment has a list of 728 Jurchen (large script) characters arranged by number of strokes:
| Number of strokes | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Number of characters | 1 | 4 | 14 | 73 | 165 | 197 | 155 | 88 | 22 | 9 |
| Percentage of total | 0.1% | 0.5% | 2% | 10% | 23% | 27% | 21% | 12% | 3% | 1% |
The characters in Jin Qizong's (1984) Jurchen dictionary have a similar distribution.
I'd like to make a similar table for the number of syllables in a Jurchen character. There is no correlation between graphic complexity and the complexity of a Jurchen reading: e.g.,
~
<r> (phonogram; zero syllables : eight strokes)
~
<uyewunju> 'ninety' (logogram; four syllables: three strokes)
Kiyose lists only one Jurchen character whose reading begins with a consonant cluster:
~
<lha> [lχɑ] (the variant is from Jin 1984)
(Written Tibetan lha [l̥a] is 'god'.
This character only appears in the spelling
<i.lha>
for ilha 'flower'. No Jurchen word could begin with <lh>, and no other Jurchen character had a reading beginning with a nonhomorganic cluster. Why wasn't 'flower' spelled
<il.ha>
just as ilhahong 'shallow' was spelled
<il.ha.hong>?
The above two readings are based on those in Jin (1984). However, Kiyose (1977: 135, #694) read 'shallow' as <ir.ha.hun> with <r> instead of <l> on the basis of the Chinese transcription 一兒哈洪 *i ri xa xuŋ. Kiyose did not reconstruct <il> as the reading of any Jurchen character. Hence if Kiyose is correct, a spelling <il.ha> would not be possible. There was no Jurchen character read <l>, so <i.l.ha> would also not be possible.
Why was irhahun (possibly irhahũ?) written as <ir.ha ...> whereas flower was written as <i.lha>? Why not write Ch-clusters consistently either as <C.h> or as <.Ch>?
I was surprised a <lhV> graph exists at all because I assumed that
- there were no <lh> (or <Ch>-initial words in Jurchen just as there were no such words in Manchu. The absence of initial consonant clusters is a trait of 'Altaic' languages , though there are exceptions: e.g., Middle Korean had ᄣ pst- and Monguor developed st- under Tibetan influence (Ramsey 1987: 202).
- Jurchen character readings would be pronounceable in isolation.
Then again, Jurchen did not have syllabic r, so
<r>
would also not be pronounceable in isolation.
Literate Jurchen knew of the Khitan scripts which also contained chararacters with subsyllabic readings, though such characters might have been read with inherent vowels in isolation.
I wonder if
was originally a disyllabic logogram <ilha> 'flower' (could it be even a drawing of a flower?) and
<i.lha>
was added later, so the later two-character spelling for ilha
should be transliterated as <i.ilha> and Jurchen referred to the second character in isolation as <ilha>, not <lha> with an initial <lh> they couldn't pronounce.
There are many Jurchen words written as <logogram.phonogram(.phonogram)>: e.g.,
<guru.un> 'country' (the first character is related to Chn and Khitan large script 囯 'country').
I presume these words appeared as <logogram> sans <phonogram> in 女眞字書 The Book of Jurchen Characters in which "[a]lmost all the individual characters [...] represent complete words" (Kane 1989: 8-9): e.g.,
>
?
Kane (1989: 29) lists an extreme case of a logogram (a drawing of a saddle?) being replaced by a logogram-phonogram-phonogram sequence:
>
<engemer> (BJC spelling) > <engemer.ge.mer> (later spelling) engemer 'saddle'
Is <i.ilha> the only case of a logogram later preceded by a phonogram, or are there others?
Next: The Bitter City of the Southern Barbarians
Maybe Someday: Initial Consonant Clusters in Jin's Jurchen Reconstruction
12.1.4.16:09: *K-OUNTING IN TANGUT
Last Friday, I proposed that Tangut 'six' and 'seven' shared a *k-prefix. The following day, I wondered if I could reconstruct a *k-prefix in other Tangut numerals. Let's see how far I can go with that. But first, let me predict the effects of *k-prefixes on different pre-Tangut initial classes:
1. *k- + nonfricative obstruent = aspirated nonfricative obstruent
2. *k- + fricative = fricative + tense vowel
3. *k- + nasal = nasal
4. *k- + glide = ʔ- + glide
5. *k-r- > *k- + grade II rhyme
6. *k-l- > lh-
7. *kV- may condition
lenition of the following consonant
bending of the root vowel
upward if *V is *ɯ
downward if *V is *ʌ
How many of those predicted reflexes can be found among Tangut numerals?
| Gloss | Tangraph | Reading | Pre-Tangut | Tibetan transcription | Also cf. | Notes |
| one |  |
1lew | *Cʌ-tek | gliH, gli, kli | OC 隻 *Cɯ-tek, WT gcig | Pre-Tangut and OC prefixes could have had initial *k- |
| two |  |
1niəə | *(k-)niəə | gniH, gni, nyi | WT gnyis | *k-prefix possible, but no internal evidence for it: *kn- > *hn- > n- |
| three |  |
1sọ | *k/s-so | gsoH, gso, bso, so | WT gsum | Prefix could be *k- or *s- |
| four |  |
1lɨəəʳ | *r-ləə | ldiH, ldi, zlaH | Mawo Qiang gʐə | Initial l- instead of lh- < *k-l- rules out *k-prefix; I could claim the prefix dropped before it left a trace, but I'd rather not do so |
| five |  |
1ŋwə | *(k-)pʌ-ŋə | bngiH, rngwa | WT lnga | *k-prefix possible, but no internal evidence for it: *(k-)pʌ-ŋ- > *kpŋ- > *kŋw- > *hŋw- > ŋw- |
| six |  |
1tʃhɨiw | *k-trik | chiH, chi | WT drug | Aspirate initial points to *k-prefix |
| seven |  |
1ʃɨạ | *k/s-ʃa | sha, gshaH | Mawo Qiang stə, Taoping Qiang ɕiŋ | Prefix could be *k- or *s- |
| eight |  |
1ʔjaʳ | *k-rja | rye, na (sic!) | WT brgyad < *bryad | Unsure if Tangut had ʔj- instead of j- |
| nine |  |
1giəə | *gəə | HgiH, dgiH | Mawo Qiang rguə | Initial g- instead of kh- < *k-g- (cf. 'ten thousand' below) rules out *k-prefix; I could claim the prefix dropped before it left a trace, but I'd rather not do so |
| ten |  |
2ɣạ | *(k-)sʌ-KaH | Hga, k.ha, dgaH | Daofu zʁa | No need for a *k-prefix, but if one existed, it could have fused with *s-: *k-s- > *kʃ- > *ʃ- > *s-. |
| hundred |  |
1ʔjiʳ | *k-rji | (none) | Mawo Qiang khiʴ, WT brgya < *brya | Unsure if Tangut had ʔj- instead of j- |
| thousand |  |
1təụ | *(k-)sʌ-tu | tu (?) | Taoping Qiang χto < *st-?, WT stong | No need for a *k-prefix, but if one existed, it could have fused with *s-: *k-s- > *kʃ- > *ʃ- > *s-. |
| ten thousand |  |
2khiə | *k-gəH | (none) | Taoping Qiang χgya < *s-g-?, Daofu khʂə < *s-g-?, WT khri | Not possible to reconstruct *k-prefix using internal evidence due to lack of kh- ~ g- alternation; root *g- reconstructed on the basis of Taoping Qiang |
In a 'strong-k' scenario in which I reconstruct as many *k-prefixes as possible, the only numbers without them are 'four' and 'nine' (unless I resort to the 'prefix dropped without a trace' trick - ugh).
In a 'weak-k' scenario in which I reconstruct as few *k-prefixes as possible, the only number with a prefix is 'six', and even its *k- is debatable because there is no Tangut-internal alternation tʃ- ~ tʃh- suggesting a prefix.I suspect several, though not all, of the numerals above had *k-. I am tempted to interpret the k- and g- in the Tibetan transcriptions as a prefix rather than as a tone letter, so 'one', 'two', and 'three' and perhaps 'ten' may have had k- in the transcribed dialect.
I don't understand why prefixation isn't consistent even in the 'strong-k' scenario or in Written Tibetan:
| WT prefix | g- | b- | l- | d- | s- | none? |
| WT numeral | gcig 'one', gnyis 'two', gsum 'three', perhaps dgu 'nine' via Sa-skya Pandita's law (named by Hill 2011): *g- > d- before grave consonants. | bzhi 'four', bdun 'seven', brgyad 'eight', bcu 'ten', brgya 'hundred' | lnga 'five' | drug 'six'; the d- of dgu 'nine' could be from *g- (see the g-column) | stong 'thousand' | khri 'ten thousand' |
Janhunen (1994) pointed out that there is no consistent numerical radical in the Tangut characters for numerals. The component
(alphacode: dex)
appears in 'one', 'four', 'six', and 'nine' and at least 1183 other characters. One out of five characters contains dex, the most frequent of 825 different character components. Determining the function(s) of dex could be a key to the Tangut script.
Next: Flora divina
12.1.3.2:31: THE *REK-ONING
On Fri day I stumbled on Schuessler's (2009: 132) entry for the homophones 歷 'to count, to experience, calendar' and 曆 'calendar', both Old Chinese *rek. Schuessler compared those words to
Written Burmese ရေ re 'to count'
Kanauri ri (no definition given)
Written Tibetan rtsi-ba < *rhji < *rhi 'to count', rtsis-pa 'astronomer'
This comparison also appeared on p. 73 of his 2007 dictionary.
I was surprised by his derivation of rtsi from *rhi. I couldn't find any sound change like -ts- < *-h- before *i in Nathan Hill's recent (2011) compilation of Tibetan sound laws. Such a change looked odd to me until I inserted some extra steps (in bold):
0. *rhi
1. *rhyi (palatalization of *rh before *i)
2. *rhji (fortition of *y)
3. *rhci (devoicing of *j before *h)
4. *rci (loss of *-h-)5. rtsi (shift of *c from palatal to alveolar - why?)
Written Tibetan has no rc-, though other similar clusters are possible (derivations from Jacques 2004):
| lc- < *hly-, *lt-y- | (no rc-) | rts- |
| lj < *n-ly- | rj- < *r-ly- | rdz- |
Is the absence of rc a chance gap (was there no pre-Tibetan *r-hly-?) or is rts- partly derived from *rc-?
Benedict derived Tibetan rtsi- from Proto-Tibeto-Burman *r-tsiy, later revised to *r-tśrəy (Matisoff 2003: 79; STEDT etymon 2738), and linked it to his Old Chinese 數 *śri̭u = my *sroʔ 'to count'. However, the vowels of the PTB and Chinese forms do not match. OC 數 *sroʔ might share a *s-r-ʔ root with OC 算 *sonʔ < ?*sorʔ 'to calculate' (cf. Jpn soroban 'abacus').
Neither Schuessler's *rhi nor Benedict's PTB forms have codas corresponding to the *-k of OC 歷/曆 *rek. Would Schuessler regard that *-k as a "k-extension"?
I think there might be a relationship between OC *rek and WB re, but am hesitant to relate them to WT rtsi-.
There are no TSr-clusters in WT, so rts- might be partly from *tsr-. However, I do not know of any Tibetan prefix ts- and hence cannot derive rtsi- from *ts-ri- with a root *ri cognate to the OC and WB r-words.
Schuessler's *rhi avoids the problem of explaining what *ts was, but are there any other examples of WT rts- from *rh-, and why did Tibetan have *rh- instead of simple *r-?
My *r- [rˁ] was an allophone of */r/ before and after nonhigh vowels that became phonemic after presyllabic loss and reduction:
*/re ra ro/ [rˁeˁ rˁaˁ rˁoˁ] > */rˁe rˁa rˁo/ *re *ra *ro
*/ri rə ru/ [ri rə ru] > */ri rə ru/ *ri *rə *ru
*/Cʌ-rV/ [CˁʌˁrˁVˁ] > */(C)rˁV/ *(C)rV
*/Cɯ-rV/ [CɯrV] > */(C)rV/ (C)rV
The phonemicization of pharyngealization (a.k.a. 'emphasis' on this site) in Old Chinese is similar to the phonemicization of palatalized consonants in Slavic: e.g.,
Russian тьма /tʲma/ (one syllable) < *tĭma (two syllables) 'fog'
In both cases, vowels that conditioned allophony were lost and the allophones became phonemes.
12.1.2.2:02: DISSECTING DRAGONS
(I originally intended to only dissect the Tangut character for 'dragon', but why stop there?)
There are two words for 'dragon' in Chinese languages, the noncalendrical 龍 (with at least 51 variants!) and the calendrical 辰 (with at least 19 variants!).The right side of 龍 looks like a drawing of a dragon, but the left side initially seems to defy explanation: 立 is 'to stand' and 月 is either 'moon' or 'flesh'. One might wonder if the Chinese think of dragons as standing on the moon. In Shuowen (100 AD), Xu Shen analyzed 龍 *luoŋ as an abbreviation of a phonetic 童 *doŋ plus 月 'flesh' and the shape (of a dragon, presumably) in flight. However, *d-phonetics are otherwise unknown in *l-graphs and as far as I know, 龍 originated as a drawing of a dragon that was later split into three components. Two resemble unrelated components 立 'to stand' and 月 'moon/flesh' while the third is only found in 龍 and its variants and compounds.
According to Richard S. Cook (1995), 辰is in fact a representation of a scorpion in striking position as seen in profile. It is shown that this representation bears directly upon the once vigorous traditions relating to the ancient equinoctial position of the star Antares in the Breast of the Celestial Scorpion. And though certain stellar concepts betray the likelihood of an early (pre-OBI [oracle bone inscription]) Sino-Mesopotamian relation (stimulus diffusion), these concepts nevertheless took peculiar Chinese form, such that it is possible to demonstrate the cognacy of Chinese 辰 chén and ‘scorpion’ words in Sino-Tibetan.
I have not yet read this monograph, so I don't know how 辰 'scorpion' came to mean 'dragon'. I would reconstruct 辰 as Old Chinese *dər which only shares a *d with Matisoff's Proto-Tibeto-Burman *s-diik 'scorpion' and doesn't have any strong matches in the STEDT database or in Tangut.
One might expect the Tangut, Jurchen, and Khitan graphs for 'dragon' to resemble some of the 70+ Chinese graphs for 'dragon', but none have any obvious Chinese origin:
| Khitan large script | Jurchen (large) script | Khitan small script | Tangut |
 |
 ~ ~ |
 |
 |
| <lu> | <mudu.r> = mudur | <lu> | 1vəi |
The Khitan large script character and Jurchen <mudu> are obviously related, though it is not certain whether the Jurchen character was derived from its KLS equivalent or if both were derived from a common Parhae prototype.
The second Jurchen character <r> may have been added later if the first character originally stood for <mudur>. <r> has nine strokes and is surprisingly complex for a graph representing a single consonant. Then again, its Chinese equivalent 兒 -r has eight strokes. To Chinese eyes, <r> looks like two 人 people standing atop a 羊 sheep minus one horizontal stroke. The rationale for the structure of <r> is unknown. It also has a variant with Xs instead of 'people':
No other Jurchen characters have 人x 2 or X x 2 as top elements.
The Khitan small script character <lu> may or may not be derived from its large script equivalent.
Khitan <lu> was borrowed from Chinese 龍 *liuŋ, though their graphs are completely different.Jurchen mudur is from Proto-Tungusic *muduri. It is vaguely similar to Middle Korean mirɯ < ?*mitɯ 'dragon', but the vowels do not match. Japanese mi 'snake (calendrical)' might be related to the Korean word. But if it's from *mi rather than *məi, *moi, or *mui, it could just be an abbreviation of Old Japanese pəymi, itself probably a loan from a relative of Middle Korean pʌyam 'snake'.
Tangut 1vəi may be from *Cʌ-Pi. The presyllabic vowel conditioned the lenition of the following labial consonant and the partial lowering of *i.
The Tangut character for 'dragon' has four parts:
+
+
+
The Tangraphic Sea analysis of 'dragon' is
+
0083 1vəi 'dragon' =
top of 0111 (first half of
1lɨə 1lwɨụ 'to crawl' - a reduplicated root?) +
bottom of 4234 (first half of
1vəi 1məuʳ 'dragon tree' (lit. 'dragon dark' = 'dark dragon')
I doubt that the character for the first half of 'dragon tree' was devised before the much more frequent character 'dragon'. 'Dragon tree' looks like 'dragon' and 1məuʳ 'dark' plus the 'wood' radical. The Tangraphic Sea analyses confirm that:
=
+
4234 1vəi = top of 4250 1si 'wood' + bottom of 0083 1vəi 'dragon'
=
4117 1məuʳ = top of 4250 1si 'wood' + all of 1məuʳ 'dark'
The second half of 'to crawl' is derived from 'dragon' and the first half of 'to crawl':
=
+
0047 1lwɨụ (2nd half of 'to crawl') =
top of 0083 1vəi 'dragon' +
bottom right of 0111 1lɨə (1st half of 'to crawl') +
bottom left of 41691tshõ 'desolate' (why?) +
bottom left of 0080 2phɔ 'snake'
The first half of 'to crawl' is not derived from the second:
+
0111 1lɨə (1st half of 'to crawl') =
0054 1tswa 'hair worn in a bun' (why?)
0338 1lɨə 'to lock up' (phonetic)
The top component of 0054 may mean 'top'. 'Dragon' is a top animal and hair worn in a bun is near or at the top of the body, but things crawl on the bottom, not the top.
The analysis of 0054 implies that the top element does mean 'top':
+
0054 1tswa 'hair worn in a bun' =
0055 2tʃɨw 'top of the head' +
2061 2pɛ̃ 'hair'
Unfortunately, no analysis of 0055 is known, so the chain of characters with 'top' ends there.
If the top element of 'dragon'
is 'top', what is the bottom? There is only one other tangraph with the same bottom elements
as 'dragon' and the first half of 'dragon tree':
1188 2ŋa 'egg' (analysis unknown)
The function of the top element ユ is unknown. Were dragons 'top eggs'? 1188 in turn had a derivative
=
+
1210 2dʒæ̃ 'egg' =
frame of 1188 2ŋa 'egg' +
? of 0088 1tew 'egg' (defined as 1210 in Tangraphic Sea)
No part of 0088 matches the bottom center of 1188. Is this Precious Rhymes of the Tangraphic Sea analysis really a list of synonyms? Why did Tangut have three words for 'egg'? How did these words differ?
What if 'dragon' had nothing to do with eggs? Three of the four parts of 'dragon' vaguely resemble the components of 龍:
: right of 龍
But what about the fourth part 干? Is it the horizontal lines 二 from 月 plus an additional vertical line?
If 'dragon' is not a heavily disguised 龍, what is it?
Next: The *Rek-oning
12.1.1.12:21: DISSECTING THE DATE 2012
Here's the solution to the problem I posted last night:
The five Tangut characters under 'dragon'
say '2012 year'. Can you identify the characters for
1. 'two'
2. 'thousand'
3. 'ten'
4. 'year'
And can you figure out whether the line at the bottom is read from left to right or right to left?
The first clue is '2012 year'. The un-English order of these words is absolute. '2012' comes first, followed by 'year'. If the line was meant to be read from left to right, 'year' should be the character on the right:
Conversely, if the line was meant to be read from right to left, 'year' should be the character on the left:
Since
appears twice and '2012 year' only contains one 'year', that character cannot mean 'year'. So by process of elimination, the line must read '2012 year' from right to left:
|
|
|
|
|
|
| 4. year | ? | ? | ? | ? |
| 2012 | ||||
My next clues were in the questions. I asked if you could identify characters for 'two', 'thousand', 'ten', and 'year'. We already know what 'year' is, so 'two', 'thousand', and 'ten' must be among the remaining four characters.
The gloss 'ten' hints that 'twelve' must contain 'ten' in it: 'ten two' or 'two ten' (cf. Sanskrit dvaa-daśa 'two-ten' = 'twelve')..
The character
appears twice, so it must be the 'two' in 'two thousand' and 'twelve' (= 10 + 2 or 2 + 10):
|
|
|
|
|
|
| 4. year | 1. two | ? | ? | 1. two |
| 2012 | ||||
Often the key to solving my puzzles lies in finding a character that appears more than once correlated with something that appears more than once in the gloss. Once this character is identified, the rest of the pieces fall into place.
In theory, the line could be either
'two ten thousand two year' ((2+10) + (1000 x 2))
or
'two thousand ten two year' ((2 x 1000) + (10 + 2))
read from right to left, but I was hoping the reader would assume that the order I listed the glosses in
1. 'two'
2. 'thousand'
3. 'ten'
4. 'year'
was the order the characters were read in:
|
|
|
|
|
|
| 4. year | 1. two (again) | 3. ten | 2. thousand | 1. two |
| 2012 | ||||
I was also hoping that the reader would have the English phrase two thousand (and) twelve in mind. The Tangut equivalent 'two thousand ten two' is close.
If Tangut had the more exotic word order
'two ten thousand two year' ((2+10) + (1000 x 2))
I would have listed the glosses in that order as a hint: 'two', 'ten', 'thousand'. Or I might not have asked the question. I'd be reluctant to ask someone to figure out that French
quatre-vingt-quatre
lit. 'four-twenty-four' ((4 x 20) + 4)
is 'eighty-four' is tough unless I gave the hints 'four' and 'twenty'. And even then, one would not know if the structure of that numeral were
((4 x 20) + 4) = 84
or
(4 + ((4 x 20)) = 84
without another example like
quatre-vingts
(4 x 20s) = 80
Moreover, one might even think that 'four-twenty-four' could be 'ninety-six' (4 x 24). Sanskrit has numerals like tri-nava 'three-nine' (3 x 9) for 'twenty-seven', though I haven't seen any Sanskrit numeral as complex as catuś-catur-viṃśati 'four-four-twenty' (4 x (4 + 20)).
(Skt catur is cognate to Eng four and Fr quatre. Its final -r becomes -ś before c-: catuś-catur. Skt viṃśati 'twenty' is cognate to Fr vingt.)
Next: Dissecting the Dragon (I originally meant to include that in this post, but I decided to separate the two topics.)
12.1.1.3:31: HAPPY SIW YEAR 2012
This siw (Tangut: 'new') year is associated with the vəi (Tangut: 'dragon'):

The five Tangut characters under 'dragon' say '2012 year'. Can you identify the characters for
1. 'two'
2. 'thousand'
3. 'ten'
4. 'year'
And can you figure out whether the line at the bottom is read from left to right or right to left?
No knowledge of Tangut is required. Logic is sufficient.
Next: Dissecting the Dragon




























{kind=link}