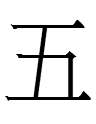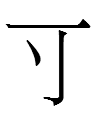12.8.11.23:59: TWO READINGS FOR TWO PEOPLE?: POLYPHONY IN THE KHITAN LARGE SCRIPT
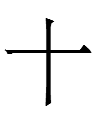
Although many Khitan large script (KLS) characters look like the characters for their Chinese translation equivalents, the KLS character for <ku> 'person' is not
as in Chinese* but is
with variants (purely graphic or representing differences in gender, number, and/or case?):
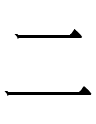
~
~
~
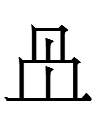
The first of the KLS characters for <ku> looks exactly like Liao Chinese 仁 *žin 'humane' (written as 亻 'person' + 二 'two'), a homophone of Liao Chinese 人 *žin 'person'. One might think that the Khitan cleverly chose to write their native word for 'person' with the shape representing a Chinese homophone of the Chinese word for 'person'. However, if that was the case, why didn't they employ that strategy more frequently if not consistently? Why did the Khitan seemingly borrow other Chinese characters (more or less) as is to write (native?) words instead of borrowing their Chinese homophones: e.g.,
~
like Liao Chinese 南 *nam 'south'** instead of 男 'man', a Liao Chinese homophone of 南 'south'?
<ku> in the Khitan small script*** is
which is the second half of the native word
<mó.ku> 'wife' (lit. 'female/mother person')
One might expect KLS 仁 <ku> to always correspond to 几 <ku> in the Khitan small script, but that does not seem to be the case in 'lady':
|
Khitan large script |
Khitan small script |
|
<un ku> or <mó ku> 'wife'? |
<mó ku> 'wife' |
|
<mó ku> 'wife'? |
|
|
<pu sin> < Liao Chinese 夫人 *fu žin****, lit. 'husband person' instead of <pu ku>? |
|
Did 仁 have two readings: native <ku> and Sino-Khitan <siń> (< Liao Chinese *žin)?
Did
which has no Chinese lookalike have two native readings: <un> (as a genitive suffix) and <mó> (before <ku>)? Or was it an error for (or a variant of?) the very similar-looking KLS character
which might have been read <mó> (and be a logogram for <mó> which does not resemble Liao Chinese 母 *m(e)u 'mother'******)?
How many other KLS characters are polyphonous, and how much of this polyphony can be reconstructed?
*8.12.2:38: There is a KLS character 人 that looks exactly like Chinese 人 'person' but its reading and meaning (if any) are unknown.
**8.12.2:39: The second graph for 'south' is my interpretation of the graph as printed in Kane (2009: 176, 184).
***8.12.3:10: The shape of KLS 几 <ku> could be derived from Liao Chinese 人 *žin 'person' and/or Liao Chinese 几 *ki 'small table, stool'.
****8.12.3:46: Liao Chinese *ž was normally borrowed into Khitan as <ź> (in Kane 2009's transcription; [zin] on p. 182 for KLS 仁 is probably an error for [źin]). <ź> is probably only in Sino-Khitan borrowings. But why does <pu sin> 'wife' have <s> instead of <ź>? I think it could be an early loan predating the adoption of the non-Khitan consonants <f> and <ź>. I would have expected <ś> instead of <s>, but perhaps Khitan did not have a /si/ : /śi/ distinction at the time of borrowing. Maybe it was originally [puśin] /pusin/ with automatic palatalization of /s/ before /i/, but became [pusin] by the time it was first written in the Khitan script, and Khitan got a new [śi] from Chinese. However, that does not predict the native Khitan name
<ś.m.i>
transcribed in Chinese as 審密 *šinmi.
It is interesting that Liao Chinese 西 *si (not *śi!) 'west' was spelled as
<ś.i>
in the Khitan small script (Kane 2009: 253). Perhaps that <ś> for Liao Chinese *s reflects a Khitan dialect which (still?) lacked a /si/ : /śi/ distinction.
*****8.12.3:59: Why was 'lady' written as
<pu.is.iń>
instead of
<pu.s.in>
in the Khitan small script? Perhaps
was reserved for Chinese borrowings and the genitive suffix <in> (Kane 2009: 37). 'Lady' might not have been perceived as a Chinese borrowing anymore and hence was spelled with <iń> instead of <in>.
Another possibility is that 'lady' was trisyllabic [pusini] and
<is>
was chosen to represent [si]. I suspect that some Khitan <VC> graphemes could also represent [CV] sequences and vice versa. Perhaps such graphemes were read as [CV] after vowels: e.g.,
<pu> + <is> = [pusi]
[pusi] + <iń> = [pusini]
4:05: If that was the case, then the two readings of KLS 仁 were [ku] and [sini].
******8.12.4:00: The phonetic resemblance between Khitan <mó> 'female/mother' and Liao Chinese 母 *m(e)u 'mother' is coincidental.
12.8.10.23:59: WHENCE ARRIVES THE SEDENTARY MAN?
I am fascinated with Khitan large script (KLS) characters like
<ś> <oi> <an> (readings from Kane 2009: 178, 181)
which are not equivalent to
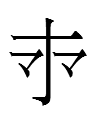
Liao Chinese 夫 *fu 'man'
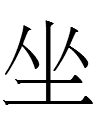
Liao Chinese 坐 *tso 'to sit'
Liao Chinese 至 *ci 'to arrive'
In my featural notation, those three KLS characters are
[+graphic]: they have Chinese lookalikes
[-phonetic]: they don't sound like their Chinese lookalikes
[-semantic]: they don't have meanings like their Chinese lookalikes; in fact, if they are pure (?) phonograms*, they don't have meanings at all!
Why were these three characters read as <ś> <oi> <an> in Khitan? Did the creator of the KLS simply decide to pick random Chinese character shapes and assign random sound values to them?
I think the readings of these characters might have been carried over from earlier readings in the lost Parhae (= Balhae / Bohai) script. Parhae's elite came from Koguryo where Koreanic and para-Japonic** languages were spoken. Hence I think some KLS readings might originate from Koreanic and/or para-Japonic readings of Parhae characters.
Over a month ago, it occurred to me that
- <ś> for 夫 ('man' in Chinese) might reflect a Koreanic word cognate to Middle Korean snàhʌ́y*** 'man'; to this day the Korean name of the character 夫 is sanae pu 'the pu [meaning] man'.
- <oi> for 坐 ('to sit' in Chinese) might reflect a para-Japonic word cognate to Old Japanese wi- < *wo-i- or *wə-i- 'to sit'.
Today I wondered if <an> for 至 ('to arrive' in Chinese) could reflect a Koreanic word cognate to Korean anc- 'to sit'. I realize this is a semantic stretch, and I wish I could quote a parallel shift in meaning ('sit' > 'arrive' or vice versa) from another language. For now, here's how I link the two: Those who settle somewhere arrive there, and settle is cognate to sit.
It is possible that the resemblance between those Koreanic/Japonic words and the KLS readings is coincidental. But if I'm wrong, where did those readings come from?
8.11.4:52: I am skeptical of Khitan-based explanations since the Khitan word for man was
<ku> (Kane 2009: 180; cf. Liao Chinese 仁 *źin 'humane', homophonous with 人 *źin 'person')
without an initial ś-, and I am unaware of any logographic uses of 夫坐至 in KLS texts.
Given that Tungusic language(s?) like Malgal/Mohe were spoken in Parhae, are there plausible Tungusic-based explanations for these KLS readings? I don't know of any similar-sounding Manchu words with appropriate meanings.
*8.11.2:49: It is possible that KLS 夫 is a hemilogogram used only to write the first half of the word 夫坐 <ś.oi> 'commander' borrowed from Liao Chinese 帥 *šoi 'id.' This hypothesis can be disproven if KLS 夫 occurs in other contexts. So far, I have only seen it before 坐 <oi> which can occur in other contexts and therefore cannot be a hemilogogram which is exclusive to the spelling of a single word.
The small number of KLS characters relative to the thousands of sinography (1,800 is the highest figure I have seen) might rule out a large number of hemilogograms. It is certain that 1,800 must contain a combination of logograms and phonograms.
Khitan had a more complex syllable structure than, say, Japanese, so the number of phonograms may be in the hundreds; a Khitan equivalent of the Japanese 五十音圖 'fifty-sound diagram' would not be sufficient to write all Khitan syllables.
I suspect the figure 1,800 contains many variants: e.g.,
for 'six'. Some variants may reflect different gender (or even case?) forms of a word (cf. gender marking in the Khitan small script); others may be purely graphic. Once variants are excluded, the total number of KLS characters may be less than a thousand - perhaps only two or three times as many as the number of Khitan small script characters minus their variants.
The difference in the number of characters might be largely due to the difference in the number of logograms in the two scripts. KLS clearly has many more logograms than the Khitan small script, and it's possible that there are no true logograms in the Khitan small script: i.e., any apparent Khitan small script logogram could have been used solely for its phonetic value.
**8.11.3:30: I use Janhunen's term Para-Japonic to refer to sister language(s) of Japanese that were spoken on the Korean peninsula:
| Pre-Proto-Japonic | ||
| Peninsular: Para-Japonic | Pelagic: Proto-Japonic | |
| (no descendants) | Ryukyuan languages | Japanese mainland dialects |
The term is parallel to his term Para-Mongolic for Khitan:
| Pre-Proto-Mongolic | ||
| Para-Mongolic languages: Khitan, Kumo Xi, Tuoba/Tabghach, Tuyuhun (all descendants of Xianbei), Wuhuan ... | Proto-Mongolic | |
| (no descendants) | Modern Mongolic languages | |
Para-Mongolic is not necessarily a coherent group. It's possible that one or more Para-Mongolic languages subgroup with Proto-Mongolic: e.g., they could be what Iranian is to Indo-Aryan if one called all non-Indo-Aryan Indo-European languages 'para-Indo-Aryan' (which is not a legitimate subgroup).
The terms Japonic and Mongolic are, in this view, inappropriate for peninsular Japanese-like language(s) and Khitan which are not descendants of the ancestors of the modern Japonic and Mongolic languages.
I could call Pre-Proto-Mongolic 'Proto-Mongolic' (or even 'Donghu'?) and call Proto-Mongolic 'Shiwei' since the Mongols of Genghis Khan are descended from the 室韋 Shiwei (Late Middle Chinese *śir-wi, a transcription of *śirwi < *serpe, transcribed into Old Chinese as 鮮卑 *serpe = Xianbei?). In that nomenclature, Para-Mongolic would be 'non-Shiwei'.
***8.11.4:46: The earliest attested form of 'man' in Middle Korean is snàhʌ́y which is ironically less archaic than the later attested form sʌ̀nàhʌ́y. The first vowel ʌ̀ could be a reduction of an earlier *à or *ò.
If the word originally began with *so- in Old Korean, 夫 could have represented a Koreanic word like *śo in Parhae and might be a phonogram for <śo> in Khitan. Hence KLS 夫坐 might be transliterated as <śo.oi> and the only (?) KLS phonogram for <ś> might be
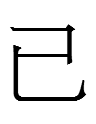
a lookalike of Liao Chinese 已 *i 'already'. The reading <ś> for 已 could reflect
- an eastern Chinese
*śɨʔ < *źɨəʔ < *m-ləʔ
with an *m-prefix absent in mainstream Middle Chinese
*yɨʔ < *yɨəʔ < *ləʔ
- a Para-Japonic cognate of Old Japanese sunde (< *sum-i-te) ni 'already'
Incidentally, the Chinese character 夫 has the reading so(re) (homophonous with sore 'that') in the kanbun reading tradition, but this cannot have anything to do with how 夫 was pronounced in Parhae, since kanbun developed long after Para-Japonic and Japonic parted ways.
12.8.9.23:59: 何 W-HA-T'S THE BIG DEAL?
The Khitan large script (KLS) was a variant of sinography (the Chinese script) created around 920 AD according to the consensus view. The Khitan small script (KSS) was invented four or five years later. KSS spellings of Chinese indicate that the northeastern dialect of Chinese known to the Khitan - Kane's 'Liao Chinese' - no longer had voiced obstruent initials like *ɣ-: e.g., 和 'peace' was spelled as
<xo> (Kane 2009: 243)
rather than as
<ɣu.a>
indicating that it was pronounced as *xo in Liao Chinese rather than as Middle Chinese *ɣwa (cf. Middle Chinese-based Sino-Korean ɦwa instead of ho). Note also that
the vowel changed from *a to *o between Middle Chinese and Liao Chinese
the medial *-w- was lost before *o between Middle Chinese and Liao Chinese
The Khitan large script has many lookalikes of sinographs (Chinese characters). These identical twins are usually regarded as borrowings from Chinese. If the two changes
*a > *o
*w > Ø before *o
had already occurred in Liao Chinese by the 920s, in theory
何 Middle Chinese *ɣa > Liao Chinese *xo 'what'
could have been borrowed as
a KLS character for the syllable <xo>. But in fact Kane (2009: 180) glossed KLS 何 as a phonogram for "ha" (= <ɣa> in my notation). How would the Khitan have known that 何 was once pronounced as *ɣa in Middle Chinese if its reading had become *xo in Liao Chinese?
Here are several possible explanations:1. Janhunen (1994) was right: the KLS was not invented in 920. Instead, it was based on an already existing (but poorly documented, to say the least) Manchurian variant of sinography (his 'Bohai [= Parhae] script') predating Liao Chinese. 何 could have had a Middle Chinese (or even Late Old Chinese)-based reading *ɣa in that script, and that character and its reading were carried over into the KLS even after Middle Chinese *ɣa had shifted to Liao Chinese *xo.
At first I thought the reading <ɣa> for 何 was a big deal because it proved Janhunen's hypothesis, but I can't find any other unambiguously archaic KLS readings. Then I considered the next two possibilities.
2. KLS 何 was still pronounced *ɣa in Liao Chinese in 920 but its reading became *xo by the time the first known KSS texts was written in 1053. Perhaps undiscovered pre-1053 KSS texts have spellings preserving more Middle Chinese-like forms: e.g.,
~
<ɣu.a> or <xu.o>
for 和 'peace'.
3. The <ɣa> reading of KLS 何 has nothing to do with Chinese; its resemblance to Middle Chinese *ɣa is merely coincidental. That begs the question: if the reading isn't from Chinese, where did it come from? Was the word for 'what' *ɣa in Khitan or in a language written with the Manchurian forerunner of the KLS?
(8.10.1:04: There is a similar situation in Japanese: the native Japanese reading of 死 'die' is shi, which is coincidentally closer to Middle Chinese *siʔ than to modern Mandarin [sɨ] which sounds like su to Japanese ears.)
8.10.1:39: 4. What if the reading of KLS 何 was actually <xa> instead of <ɣa>?
Kane (2009: 174, 180) gave only one example of a word containing KLS 何:
<ɣa.an>
for the Chinese name 韓 which would have been *xan in Liao Chinese but *ɣan in Middle Chinese. Was the name *ɣan borrowed into Khitan before 920 and retained even after the initial *ɣ- devoiced to *x- in Liao Chinese, or should the KLS spelling be reinterpreted as <xa.an>?
Kane (2009) did not list any KSS spellings of 韓 in his seventh chapter. It would be interesting to see if the name was spelled as
~
<ɣa.an> or <xa.an>
in the KSS and if its spelling changed over time in both the KLS and KSS: e.g., was it ever spelled as

<xa.an>
in the KLS after (or even while?) it was spelled as <ɣa.an>?
12.8.8.23:59: WHICH KHITAN WORDS DESERVED LOGOGRAMS?
The Khitan large script (KLS) superficially resembles sinography (the Chinese script). Many KLS characters are identical to sinographs (Chinese characters), and many even have the same meanings and/or readings:
| KLS sinographic lookalikes: +graphic | +phonetic | -phonetic |
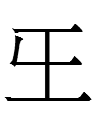
| +semantic | 王 <oŋ> 'king' : Liao Chinese *oŋ 'king' | 五 <tau> 'five'; also a phonogram : Liao Chinese *ŋu 'five' |
| -semantic | 何 phonogram <ɣa> : Middle (not Liao!*) Chinese *ɣa 'what' | 夫 phonogram <ś> : Liao Chinese *fu 'man' |
Some KLS characters appear to be derived from sinographs: e.g.,
'heaven' (pronunciation unknown)
looks like a compound of the sinographs for 天 'heaven' and 土 'earth' (and happens to look almost like Vietnamese 𡗶 trời 'heaven' and Zhuang 𡗶 gwnz 'top' which have 上 'top' on the bottom instead).
Yet other KLS characters are [-graphic]: i.e., completely different from the sinographs for their translation/phonetic equivalents: e.g.,
<ai> 'year'/'father'
does not look like any sinograph (a) pronounced *ai in Liao Chinese (e.g., 哀埃矮藹毐愛隘, etc.**) or (b) representing Chinese words for 'year' (年歲) or 'father' (父).
In any case, there is a strong sinographic influence in the KLS, though the KLS is not just simply recycled sinographs with added strokes or components here or there; it is distinct from 'extended sinographies' like Vietnamese nom or Zhuang sawndip which include the whole of orthodox sinography plus combinations of existing sinographic elements*** and do not have characters of the [+graphic -phonetic -semantic] type like KLS 夫 <ś> which look like sinographs but have no obvious relation to their lookalike's functions.
As a general rule, each sinograph stands for one monosyllabic morpheme and can be called a logogram (even though strictly speaking a morpheme is not necessarily equivalent to a word).
When I first heard about the KLS in the 90s, I was under the impression that it was logographic. But this clearly cannot be the case. There are only up to about 1,800 KLS characters including variants. Obviously if one took the term logogram literally, this would have to mean there were fewer than 1,800 words in Khitan. And even if one interpreted logogram in the looser sense as 'morphogram' (a more precise term that has not caught on), this would have to mean there were fewer than 1,800 morphemes in Khitan.
One might try to explain this extremely low number by pointing out that the KLS was mostly used for epitaphs which had a limited vocabulary. However, Viacheslav Zaytsev recently identified Nova N176, an example of a nonepitaph KLS text which surely has a larger vocabulary. It may be only the tip of an iceberg of lost texts in many genres.
If the KLS was not exclusively or even mostly logographic, what were the nonlogographs? Phonograms, of course. There are words that are apparently exclusively written with phonograms: e.g.,
<u.ru> 'upper'
corresponding to the single sinograph 上 *šaŋ. Why didn't the Khitan devise a logogram for uru 'upper': e.g., 上 'top' with an added dot or something****? Was it because uru had two syllables and therefore had to be written with two KLS characters? No, it seems that there is no correlation between the number of syllables and the number of KLS characters for a word: e.g., in theory there could have been twelve KLS logograms for the twelve animals of the zodiac, but in fact five animal names were written with phonograms:
| Number of syllables according to Kane (2009: 176-177) | Logogram | Phonograms |
| 1 | <lu> 'dragon' |
|
| 1~2 (uncertain if <o.o> is [oo] or [oʔo]) | <ui(l)> 'pig' | <p.oo> 'monkey' (also with an alternate phonogram ligature spelling) |
| 2 | <?...ɣu> 'rat', <uni> 'ox', <mori> 'horse', <iam.a> 'sheep', <ńiqo> 'dog' |
|
| 2~3 (uncertain if <o.o> is [oo] or [oʔo]) | <qaɣaas> 'tiger' | <tau.lía> 'hare', <muɣ.oo> 'snake' (both with alternate phonogram ligature spellings) |
| 3 | <te.qo.a> 'chicken' |
|
Did the creators of the Khitan large script select which animals were deserving of logograms at random? Why are animal names so inconsistent in the KLS compared to elements/colors, seasons, directions, and numerals which all have logograms (Kane 2009: 176-177)?
Tonight it occurred to me that perhaps KLS logograms each represented a monosyllable: e.g.,
'chicken'
could have been <tqa> (or <təqa> with a presyllable?) instead of <teqoa> (Kane 2009's usual trisyllabic transliteration) or <teɣa> (the disyllabic transliteration in Kane 2009: 181 - was this based on Liu and Wang 2004?). I could similarly rewrite other animal names written with logograms as monosyllables:
<Cɣu> 'rat' (first consonant unknown)
<wni> ([vni]?) or <uń> 'ox'
<qɣaas> 'tiger' (probably not <qɣas> or <qaɣs>; the small script spelling is <qa.ɣa.as>, not <qa.ɣa.s>; does any language in the world have the initial cluster qɣ-?)
<mri> or <mor> or <moŕ> (with a palatalized <ŕ>?) 'horse'
<yma> 'sheep' (the small script spelling <iam.a> points to a final <a>, so <yam> is not possible)
<ńqo> or <ńiq> 'dog'
<wi(l)> 'pig'
But this assumes that Khitan had complex consonant clusters like those of Middle Korean or Khmer. Was that actually the case? Is that the reason why Khitan small script spellings sometimes seem to be 'missing' vowels: e.g.,
<t.q.a>
for 'chicken'? Have researchers been expecting vowels that were absent in Khitan?
Next: 何 W-ha-t's the Big Deal?
*8.9.1:43: I will explain the significance of a Middle Chinese basis for 何 <ɣa> in my next entry.
**8.9.3:12: It occurred to me tonight that the 毋 *wu on the bottom of the rare character 毐 *ai vaguely looks like KLS <ai>, but if you look at sinographs long enough and add or subtract enough strokes, they can look like whatever KLS (or even Tangut!) character you want, so this proves nothing.
***8.9.3:12: There are nonsinographic elements in nom and in sawndip: e.g.,
the diacritic < in Vietnamese 買< mới 'new'
the Zhuang character 3· aemq 'back' (with curved strokes and a circular dot absent from sinography)
However, they are minor compared to the conspicious nonsinographic elements of the KLS. It is difficult to make statements that apply to all the thousands of characters in these scripts.
****8.9.3:15: According to Kane (2009: 178), what looks like the sinograph 上 *šaŋ 'top' was already in use as a KLS phonogram for <xa> and <ɣa>, so the shape 上 could not be reused without modification to write uru without making it even more ambiguous.
12.8.7.23:59: ARE THERE ANY PURE LOGOGRAMS IN THE KHITAN LARGE SCRIPT?
Last night I wrote two asterisks after "logograms (characters for specific words)" in the previous post but forgot to write the accompanying footnote. I've removed those asterisks and am writing that footnote as this standalone entry.
Khitan large script characters belong to two basic categories:logograms for words: e.g.,
'heaven' (pronunciation unknown)
phonograms for sound sequences: e.g.,
the consonant <ś> (not <f> as one might expect from Liao Chinese 夫 *fu!)
the vowel <u>
the syllable <po> (used to write the unrelated words <po.o> 'monkey' and <po.or> 'become')
But in fact the line between the two is not clear-cut.
At least some logograms can also function as phonograms: e.g.,
<jau> 'hundred' + <tau> 'five' = <jautau> 'bandit suppression commissioner' (< borrowed from Liao Chinese 招討 *jautau, lit. 'invite-punish' which has nothing to do with 'hundred' or 'five')
Can any logogram also be used as a phonogram in theory? (There could be logograms for words containing sound sequences that appear nowhere else; such logograms could not be used as phonograms. For instance, if 'heaven' was tengri - not that I know of any evidence for that - and if Khitan had no non-'heaven' words with the two-syllable sequence tengri in them - then 'heaven' would be a pure logogram.)
Conversely, how many characters thought to be phonograms originated as logograms? It is doubtful that single-consonant phonograms like <ś> could also be logograms unless they represented single-consonant stems. But it is possible that <u> originated as a logogram for a word u.
Finally, there are wholly uncertain cases like
<ai>
for both ai 'year' and ai 'father'. The Jurchen used a similar character
as a logogram for aniya 'year'. This might mean that the character's primary meaning (in the Manchurian prototype for the two scripts?) was 'year' and that ai for 'father' was a secondary usage in Khitan. Or did the Jurchen arbitrarily choose only one of two (or more?) uses of a single Khitan large script phonogram?
Next: Which Khitan Words Deserved Logograms?
8.8.8:20: In the handful of Khitan texts that I have seen (mostly thanks to Andrew West), 夫 <ś> always precedes 坐 <oi> to spell 夫坐 <ś.oi> 'commander' (< Liao Chinese 帥 *šoi 'id.'). 坐 <oi> occurs in other contexts and might be a pure phonogram. 夫, on the other hand, might be a hemilogogram, a character that exists solely to write half a word. Chinese and Tangut have hemilogograms such as
蝴, the first half of 蝴蝶 'butterfly' (the second half 蝶 can occur elsewhere like Khitan 坐 <oi>)
the second half of 'ritual' Tangut 2lheʳ-2giu 'three' which cannot stand by itself in normal text (dictioanry entries for it don't count)
Hemilogograms represent monosyllabic cranberry morphemes in Chinese and Tangut. If English were written in a similar script, twilight would be written with a hemilogogram for the cranberry morpheme twi- and a logogram for light.
Hemilogograms could represent even smaller units in Khitan: e.g., 'commander' is a monosyllabic morpheme in Khitan, but its spelling 夫坐 <ś.oi> might consist of a hemilogogram <ś> plus a phonogram (not a logogram!) <oi>.
12.8.6.23:59: WAS THE JURCHEN LANGUAGE EVER WRITTEN IN THE KHITAN SCRIPTS?
Last night I was rereading Andrew West's "The Mystery of Two Khitan Scripts" for the umpteenth time and was looking at his entries for Khitan large and small script inscriptions from the Jurchen Jin Dynasty:
| Year | Script | Inscription |
| 1134 | Small | 大金皇弟都統經略郎君行記 Record of the Younger Brother of the Emperor of the Great Jin Dynasty, Campaign Commander, Military Commisioner, and Court Attendant (Mandarin Langjun) |
| 1150 | Memorial for 蕭仲恭 Xiao Zhonggong | |
| 1171 | Memorial for the 金代博州防禦使 Jin Dynasty Defense Commissioner of Bozhou | |
| 1176 | Large | Memorial for 李愛郎君 Lord Li Ai |
The only one of the four I have seen is the Langjun inscription of 1134 as presented in Kane 2009. I would like to see the other three because I wonder if they contain Jurchen words, phrases, or even sentences in the Khitan script: e.g., was Jurchen
~
uju 'head'
ever written in the Khitan large script
- with a semantogram
<HEAD> (originally for Khitan nai 'head')
- with phonograms
<u.ju>
- with a semantogram-phonogram mixture*
<HEAD.ju>
or in the Khitan small script as
<u.ju>?
It would be impossible to tell if a Khitan logogram were being used to write an unrelated Jurchen word in isolation (e.g., Khitan <HEAD> for Jurchen uju 'head'), but if it were surrounded by unambiguous Jurchen language text, then it is likely that it was meant to be read in Jurchen**.
Even if none of those four inscriptions contain any Jurchen words, they might contain Jurchenisms (i.e., Jurchen-like uses of Khitan words and morphemes) that have so far eluded detection.
My thoughts above were inspired by Janhunen (1994: 7):
Due to its logographic nature, this script [= the Manchurian variant of the Chinese script] was equally suitable for writing both Khitan and Jurchen, and any text written in it could, in principle, be read in either language, possibly even in Chinese.
Strictly speaking, the Manchurian variant of the Chinese script - at least as reflected in the Khitan large script and the Jurchen (large) script - is only partly logographic; it had both logograms (characters for specific words) and phonograms (characters for specific sounds). It could represent any language because its phonograms could be used to write any word (though not necessarily with absolute phonetic accuracy).
But there is no way "any text written in it could, in principle, be read in either language". Even if Khitan and Jurchen had completely identical word order, speakers of one language could not understand what was written in phonograms for the other language: e.g., neither
~
<u.ju> nor <HEAD.ju>
for Jurchen uju 'head' would make any sense to a monolingual Khitan speaker. And a monolingual Jurchen speaker might not understand the Khitan phonogram sequence
<u.ru> 'upper'
because Jurchen may not have borrowed the Khitan word uru 'upper'.
Finally, even if the Khitan and Jurchen scripts had no phonograms, reading a Khitan or Jurchen text in Chinese would be impossible without kanbun-style grammatical acrobatics in reverse to convert Altaic grammar into Chinese grammar.
*8.7.1:07: Cf. Old Korean semantogram-phonogram hybrid spellings like 夜音 <NIGHT.ɯm> for a native Korean word for 'night' ending in -(ɯ)m - presumably an ancestor of Middle Korean pàm 'night'.
An English equivalent would be 夜特 <NIGHT.te> for night. (te is a Mandarin reading for 特.)
**8.7.3:45: Cf. how the Chinese character 一 in isolation could represent
Mandarin yi 'one'
Cantonese yat 'one'
Sino-Japanese ichi 'one'
Sino-Korean il 'one'
Sino-Vietnamese nhất 'one'
Zhuang it (the first syllable of itciengz 'since')
the unknown Khitan word for 'one'
Jurchen emu 'one'
but 一つ with the Japanese hiragana つ tsu has to be Japanese hitotsu 'one'.
12.8.5.23:55: JURCHEN NIRU : KHITAN ?
Having just mentioned Jurchen
beri 'bow'
in my last post, I thought I might say a little about Jurchen
niru 'arrow'
which Jin (1984: 169) noted looks like this Khitan large script (KLS) character
in line 6 of the 北大王墓誌*. What could this KLS character represent? Here are five possibilities:
|
|
+phonetic | -phonetic |
| +semantic | a Khitan word for 'arrow' that sounded like Jurchen niru | a Khitan word for 'arrow' that did not sound like Jurchen niru |
| -semantic | a Khitan word or syllable (sequence) nir(u) that did not mean 'arrow' | something that had no phonetic or semantic resemblance to Jurchen niru 'arrow' |
It would be interesting to look at all KLS characters that match Jurchen characters and see how many fall into each of the four categories above.
The shape of the KLS and Jurchen characters looks like an arrow head to me, though the bottom is bent unlike an arrow shaft. This is a rare instance in which I can see a resemblance between a KLS/Jurchen character and the shape of its referent (excluding characters that resemble those of Chinese: e.g., 'one' which can be a simple horizontal line in all three scripts**: 一).
If the KLS character was a phonetic symbol for nir(u), could it have been the first character in the KLS spelling for the Khitan word for Jurchen which could have been something like nirugu (Kane 2009: 166)?
*8.6.00:44: By coincidence, the line containing the KLS character resembling Jurchen niru is also the line with the KLS spelling for 'twelve' that I mentioned in "Young Sheep Khan?":
<eur> 'years of age' 'ten' 'two' <cin> <liu>
<ten> '?' '?'
The first three characters mean 'age twelve'.
The fourth and fifth characters might be a transcription of a Chinese name like 陳? *Cin Liu. The fifth character is clearly related to Chinese 流 *liu.
The sixth character 'ten' presumably counts whatever the niru-like character represents (arrows?).
It is not clear whether the final character at the end of the line is part of the same word as the niru-lookalike.
**8.6.00:45: Jurchen emu 'one' can also be written with an initial vertical line
that bends into a horizontal stroke familiar to those literate in Chinese and/or KLS.