

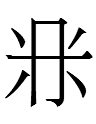



? qulugh ai nai sair ? nyair
'white rat year, head month, one day'
20.1.25.23:55: KHITAN NEW YEAR: THE 1100TH ANNIVERSARY OF THE KHITAN LARGE SCRIPT
? qulugh ai nai sair ? nyair
'white rat year, head month, one day'
This year the
Khitan large script turns 1100, so I'll be using the Khitan large
script for dates for the rest of the year.
The last three characters of the date are shared with Chinese (月一日), but the other four bear no resemblance to Chinese 白鼠年首 <WHITE RAT YEAR HEAD>. (Other Chinese equivalents exist, but they don't look like the Khitan large script characters either: e.g., 子 <CALENDRICAL.RAT>, 頭 <HEAD>, etc.) Why? As Janhunen (1994: 111) asked,
If it was the aim to create a [Khitan] script distinct from the Chinese, why were not all [Khitan large script] characters consistently replaced or modified?
I agree with Janhunen that the Khitan large script was not 'invented' in 920; it is an outgrowth of some earlier script, perhaps the fragmentarily attested Parhae script or the wholly lost Serbi script. And that script was a sister of the Chinese script with innovations absent from Chinese: <WHITE>, etc. I think the date 920 may refer to the revision of an earlier script for Khitan use.
The date itself may not be accurate, as the earliest dated Khitan
script text is the
epitaph for 耶律延寧 Yelü Yanning from 986. Are there Khitan large
texts from 920-985 that have not yet been discovered, or was the script
'created' after 920?
Notes on the characters/words:
<WHITE>: Reading unknown.
<HEAD>: A pictograph of a headdress?
To tie up loose ends from last year, I've posted all the blog entries from between 1.2 and today:
20.1.24.23:59: YELLOW PIG 12/30

songgiyan uliya aniya
juwa juwe biya orin gusin inenggi
'yellow pig year, ten two month, thirty day'
1. Today I clicked on Andrew
Hsiu's map of the Qiangic linguistic area. Tangut is to the north
of it; the former Tangut capital is now known by its modern Mandarin
name Yinchuan.
I care about the Qiangic linguistic area because the languages in it are Tangut-like. Whether they actually subgroup with Tangut is another matter. Jacques (2014: 2) thinks most of them do, so he places them in a 'Macro-rGyalrongic group'. The exceptions are:
Ersuic (Jacques [2004] regards this as a sister of Macro-rGyalrongic)
Naic (Jacques [2004] regards this as a sister of Macro-rGyalrongic)
Baima (no close relation to Bai or Macro-rGyalrongic)
Bai (no close relation to Baima or Macro-rGyalrongic)
2. Hsiu posits 'missing'
Sino-Tibetan branches to serve as sources of Sino-Tibetan-like
vocabulary in
"Contrary to Starosta's (2005) proposal that Sino-Tibetan, Austroasiatic, and Austronesian are all related (the 'Altaic of southern China,' so to speak), I consider similarities between these language families to be due to intensive contact in southern China during the Middle Neolithic. [...] Could Proto-Austroasiatic have started out as a Middle or Late Neolithic creole in Lingnan that mixed elements of Sino-Tibetan and Austronesian with a non-related native substratum? The creoloid typology of Austroasiatic, especially in its grammar, seems to suggest so, in addition to the lexical evidence."
"Proto-Hmong-Mien *dzjuŋH 'seven' is shared by [the
Sino-Tibetan branches] Bodish, Idu-Taraon, Miju, and Meyor."
[Links mine.]
Is that the only word from a lost branch in Hmong-Mien? I think it's just a random vague lookalike of Tibetan bdun, Miju nɯn, and Hsiu's Proto-Idu-Taraon *ɣoŋ < *roŋ, which may not be related to each other. STEDT lists weŋ (cognate to the Idu-Taraon word?) for Meyor.
Roger Blench and my former student Mark Post (2011) regard
Miju as an isolate, Idu-Taraon (their 'Mishmic') as a non-Sino-Tibetan
language family, and Meyor as an East Bodish
language.
Hsiu considers Jiamao to be an independent branch of Kra-Dai,
but usually Jiamao is regarded as an aberrant member of the Hlai
branch, and Norquest (2016) regards Jiamao as an isolate heavily
influenced by Hlai. I find Norquest's arguments persuasive at first
glance.
To solidify the case for these branches, one would have to
demonstrate the resemblances are not by chance
demonstrate that the words could not be from known branches because of
geography
features (innovations/retentions) absent from other potential donors
3. When hearing the word petrol /ˈpɛtɹəl/ out loud on Magnum, P.I. tonight I finally realized it's short for petroleum /pəˈtɹoʊliəm/. Duh. That isn't the first time it took me a long time to link two words whose relationship is obvious in spelling but not in pronunciation. I wish I could remember the last time that happened. I think it was sometime within the past few months.
Someone learning English as a foreign language and first encountering those words in print would immediately link them and face the different problem of pronouncing them differently: petrol is not /pəˈtɹoʊl/, and petroleum is not /ˈpɛtɹəliəm/.
4. Tonight - three days after I started reading William C. Hannas' The Writing on the Wall: How Asian Orthography Curbs Creativity (2003) - it finally occurred to me that literate Khitan would be interesting test subjects for his ideas about the effects of writing systems on thinking.
The Khitan had two scripts, and nobody really knows why. Andrew West's great essay on the mystery ends,
Both scripts are complex enough to require a considerable investment of time and effort to learn to read and write, so how is it possible that both scripts managed to coexist and flourish for so long ? Did the Khitan education system require students to learn both scripts, or were Khitan scholars only able to read and write one or other of the two scripts ? It makes no sense to me ...
... or me.
Let's imagine that Hannas could be sent back a thousand years to the Khitan Empire. Using his knowledge of Chinese, Japanese, and Korean, Hannas would be able to easily learn Khitan, an 'Altaic'-type language with many Chinese loanwords like Japanese and Korean. Hannas proposes that syllabic scripts without word division inhibit creativity. So in his framework, what effects would the Khitan scripts have?
A brief comparison:
| Khitan script |
syllabic? |
alphabetic? |
word division? |
| large |
not quite |
no |
no |
| small |
no |
not quite |
mostly |
The large script, despite its superficial similarity to the Chinese script, does not have a one-to-one correspondence between syllables and characters. Some syllables are written as two-character sequences: e.g., Han (the Chinese name 韓) as 何至 <ha.an>. Conversely, some disyllabic words are written as single characters: e.g., namur 'autumn' as 禾 (cf. Chinese 秋 <AUTUMN>).
The small script has a mixture of characters for single segments and
syllables. The small script is more analytic than the large script
which in turn is more analytic than the Chinese script:
small script > large script > Chinese script
And unlike either the large script or Chinese script, words are
generally written as blocks - the first instance of word division in
East Asia. The only exceptions to that rule are Chinese loanwords which
are written as one syllable per block (not counting Khitan affixes
added to those blocks): e.g., the disyllabic word hongdi
'emperor' from Liao Chinese 皇帝 *hongdi [xɔŋti] is
written as two blocks

<075 037> <hong di>
rather than as a single block
<075.037> <hong.di>.
So if Hannas is right, small script users might be more inclined
toward creativity than large script users who would still be more
inclined toward creativity than those only literate in the Chinese
script.
20.1.23.23:51: YELLOW PIG 12/29
songgiyan uliya aniya
juwa juwe biya orin uyewun inenggi
'yellow pig year, ten two month, twenty nine day'
1. Last night I learned from the Korean
Wikipedia that the
eight trigrams have 二進法 ijinbŏp 'binary' equivalents.
2. I have no idea if this is a true explanation for the presence of 隹 <BIRD> in 進 <WALK.BIRD> for 'forward', but it's a useful memory aid:
A bird can only walk forward but not backwards, hence implying "forward".
3. How did Proto-Germanic *hw- become tsj- in West
Frisian tsjil 'wheel'?
4. Wikipedia's discussion of the possible Indo-European origin of the Chinese chariot is a bit anachronistic:
However archeological evidence shows that small scale use of the chariot [in China] began around 1200 BCE in the late Shang dynasty. This corroborates the material spread of the invention from the Eurasian Grass-Steppe to the West, by Proto-Indo-Europeans (likely the Tocharians) who similarly have borne horse, agricultural, and honey making technologies through the Tarim Basin into China.
Proto-Indo-European speakers and Tocharians are not the same people.
Proto-Indo-European had ceased to exist centuries before eastern
Indo-European speakers might have introduced the chariot to China.
5. Today I found a Wiktionary entry for
རོ་མཱན་གྱི་ལྷ་གཙོ་བོ་
<ro.mān.gyi.lha.gtso.bo.> = 'Roman-GEN god principal' = 'principal god of the Romans' = 'Jupiter'
Is that a real Dzongkha expression? It looks like a nonce attempt to explain who Jupiter was rather than a name for Jupiter. I appreciate how Wiktionary contains entries for items absent from traditional dictionaries, but I draw the line at transparent phrases. And a Google search for that particular phrase only leads to that Wiktionary entry. (I'm not counting partial matches.)
It is strange that a Dzongkha description of Jupiter has an entry
but that Tibetan ཕུ་བོ <phu.bo> 'older brother' does not.
Oddly
STEDT doesn't have that Tibetan word either.
6. Today while copying the 契丹小字研究 Qidan xiaozi yanjiu (Research on the Khitan Small Script) hand copy of the epitaph for Empress 仁懿 Renyi (?-1076) of the Khitan Empire, I encountered the first Khitan small script block I've ever seen with three components in a row:
<244.172.339> <s.ugh.i> (12.1)
The index of blocks has a more conventional two-on-one form:
<244.172/339> <s.ugh/i>
(I use </> to indicate row breaks within a block.)
Which form is the one on the inscription?
I don't know what the word means. It was a hapax legomenon as of
1985. Have more attestations been found since?
7. Today I've been puzzled by the Sino-Tibetan word for 'horn':
Old Chinese 角 *C[k]rok 'horn', 'corner'
*[k] is in brackets because Baxter and Sagart (2014)
could not determine on the basis of Chinese-internal evidence whether
the stop was velar or uvular. rGyalrong forms like Tshobdun tə˥qrɯ˧
'horn' point to *-q-.
Written Tibetan ru 'horn', gru 'corner'
Old Burmese khruiv· > Written Burmese khyui [dʑo] 'horn'
Li Fanwen (2008: 329) says 𗅡 1981 is an 訛體 erroneous form of 𗅡 3517, but I can't see any difference between the two in his font. Both have the same Unicode codepoint (U+17161).
see below for my reasoning for *K-
I wish I knew the Pyu word for 'horn'.
Nathan reconstructs *əw for this correspondence:
OC *o : WT u : OB uiv·
I think OB uiv· was [əw], a direct preservation of Sino-Tibetan *əw that became modern ui [o] via *ow.
I reconstruct a root *rəw. That much seems certain.
The rest, however ...
The *C- in Old Chinese 'horn' is carried over from Baxter and Sagart (2014). Why did they reconstruct it?
I know of no phonetic series evidence or Chinese-internal
comparative evidence for *C-: e.g., 建陽 Jianyang
Min has k- instead of an h- resulting from
intervocalic lenition (cf. 狗 Jianyang hou˨˩ < *CAkoʔ
'dog').
What is the function of the *-k in Old Chinese?
What is the function of the g- in Written Tibetan?
Why is the initial of modern spoken Burmese 'horn' voiced [dʑ]
instead of the regular reflex of khr-: voiceless aspirated
[tɕʰ]?
Why does Tangut have an aspirated initial? I think the aspiration may be a trace of an earlier aspirating prefix: *KAk > *xk- > kh-.
I think pre-Tangut *KA- is the same prefix that I can't explain in Old Chinese (*C-), Written Tibetan (g-), and pre-Burmese (*k-).
On the other hand, rGyalrong forms often have minor syllables with t-: e.g., Tshobdun tə˥qrɯ˧.
8. Nathan
Hill (2019: 227) thinks dr- in Tibetan drug 'six'
is from *kr- (cf. Old Burmese khrok· < *krəwk
'six'). *kr- > dr- would be a double assimilation in
terms of place and voicing.
But Pyu has tr- (tru 'six') and Tangut chh- in 𗤁 3200 1chhiw3 'six' may be from *Ktr-
(cf. rGyalrong kətr-forms like lCogtse kətɽok; Jacques
[2004: 296] reconstructed Proto-rGyalrong *kə-tɽɔk.
Moreover, *kr- became khr- (Hill 2019: 221) in Tibetan khrab
'armor', so why would it become dr- in 'six'?
Might the Tibetan, Burmese, and Pyu initials all be simplifications
of an earlier complex cluster *ktr-?
9. Nathan Hill (2019: 229) proposes that Written Burmese kuiy· [ko] 'body' may be a borrowing from Pali kāya- 'body' rather than a Sino-Tibetan word cognate to Tibetan sku and Old Chinese 軀 *CIkʰo (*HIko with a minor syllable initial conditioning aspiration?). But Luce (1981) lists kuiv· [kəw] as the Old Burmese spelling. Perhaps the Pali-like silent -y· in the modern spelling was an addition motivated by folk etymology. However, regarding kuiv· as native raises another unresolved issue: k- should be from *g- which doesn't match the voiceless stops in Tibetan and Chinese.
10. Burmese
has [tɕ tɕʰ dʑ] but [ʃ] (not [ɕ]). What is the reason for this
asymmetry?
11. The rGyalrongic Languages Database has two varieties called "Pho
sul" in nearby locations: 蒲西 Puxi (a Mandarinization of Pho sul?) and a
village called 斯遥吾 Siyaowu in 蒲西 Puxi. Wikipedia says there are
"Phosul" varieties of both Khroskyabs
and Horpa.
Is there one Phosul language that has been classified two different
ways or are there two Phosul languages? Jackson Sun (2000: 214)
explains:
Puxi is one of the three townships in southern Rangtang County in which Shangzhai [Horpa] speakers dwell [...] Of the five villages within Puxi Township, Shangzhai is used in Dayili Village and those hamlets of Puxi and Xiaoyili Villages north of the Rangtang River, abutting Lavrung [Khroskyabs]-speaking hamlets across the river in the same villages. The latter language is distributed in Siyaowu Village also [...]
If I understand that passage correctly, a variety of Shangzhai Horpa
is spoken in Puxi Village, and a variety of Khroskyabs is spoken in
Siyaowu Village.
Horpa and Khroskaybs have different words for 'sleep'. Let's compare
the "Pho sul" words for 'person' from the rGyalrongic Languages
Database with some data from Jackson
Sun (2018: 4) (sortable
version at Wikipedia):
Phosul (Puxi Village) vdzi
Phosul (Siyaowu Village) vʝu
Hbrongrdzong Khroskyabs vɟoʔ
Stau (a.k.a. Rtau; a Horpa language) vdzi
Puxi Village Phosul may be Horpa, as it has vdz- like Horpa languages, whereas Siyaowu Phosul may be Khroskyabs, as it has a palatal after v like Hbrongrdzong Khroskyabs.
The Khroskyabs and Horpa words for 'person' may be cognate to Tangut 𘓐 2541 2dzwo4 < *PIndzojH 'person'.
Jacques (2014: 206) only proposes pre-Tangut *-jok (= my *-I-ok)
as a source of -jo (= my -o3 and -o4), but I
wonder if pre-Tangut *-I-oj (equivalent to a nonexistent *-joj
in Jacques' system) might be another source. Puxi Village Phosul and
Stau -i seem like unlikely reflexes of an earlier *-ok.
12. Is Lai Yunfan's site
the only website written in Wobzi?
20.1.22.23:59: YELLOW PIG 12/28
songgiyan uliya aniya
juwa juwe biya orin jakun inenggi
'yellow pig year, ten two month, twenty eight day'
1. Last night I got the copy of William C. Hannas' The
Writing on the Wall: How Asian Orthography Curbs Creativity
(2003) that I ordered on Yellow Pig 12/6.
On Yellow Pig 12/1,
I wrote my initial impressions based on a preview on my Kindle. I'm
rereading the preview now. I'm not used to reading on paper anymore.
2. Last night I found Andrew Hsiu's Sino-Tibetan Branches Project for its Proto-rGyalrong reconstruction. Why does rGyalrong matter?
Proto-rGyalrong is an elegant marvel. It may be one of the most conservative reconstructable Sino-Tibetan meso-languages. It is clear that a reconstruction of Proto-Sino-Tibetan would definitely need to take Proto-rGyalrong into account, since Proto-Sino-Tibetan morphology, phonology, and lexicon would have looked very similar to those of Proto-rGyalrong. In order to understand how reflexes of highly eroded eastern Sino-Tibetan languages had gotten to where they are from Proto-Sino-Tibetan, it is crucial to consider Proto-rGyalrong.
Is rGyalrong the Sanskrit or Greek of Sino-Tibetan?
Hsiu's Proto-rGyalrong *k.tek 'one' is very much like my
pre-Tangut *kVtek or *kAtik (formerly *kʌ-tek or *kʌ-tik
in 2012 and *CV-tek in 2011).
The low series vowel of Tangut 1lew1 'one' is either original (< *e) or secondary (< *A-i): i.e., conditioned by a preceding *A.
The l- of 1lew1 'one' is from a *-t-
that lenited intervocalically. The lost preceding vowel could have been
an unknown low series vowel *A that conditioned the lowering of
a following *i or it could have been a high or low series vowel
*V that was lost after lenition but before presyllabic
vowels conditioned the warping of main vowels.
3. Hsiu also has a page on Pyu. His 2018 Excel file incorporates data from my 2016 SEALS presentation on Pyu numerals. A paper on Pyu language history is on my to-do list.
4. I just found Hsiu's
page illustrating his wave model of Sino-Tibetan. He places Pyu in his
fourth wave, but I am hesitant to commit to such a detail.
5. I want to figure out where Pyu is in the comparative framework that Nathan Hill established in his landmark book The Historical Phonology of Tibetan, Burmese, and Chinese (2019).
Nathan wrote on p. 156,
Many features of [Old Chinese] loans into Vietic are not predictable on the basis of the Old Chinese source word in Baxter and Sagart's reconstruction; for example, Rục has at least -ə-, -à-, -a-, and -u- available as the vowel of the minor syllable (kəcáy 'paper', kàraŋ 'bright sunshine', kadɔːk 'nape of the neck', kumúa 'dance'), but these different vowels are not predictable on the basis of the Old Chinese forms (紙 tsyeX < *k.teʔ 'paper', 朗 langX < *k.rˤaŋʔ 'bright', 脰 duwH < *kə.dˤok-s 'neck', 舞 mjuX < *k.m(r)aʔ 'dance').
I first saw those comparisons six years ago, but it didn't occur to
me until last night to compare Ruc minor syllable vowels with the minor
syllable vowels that I would reconstruct for Old Chinese if I didn't
know about Ruc:
| sinograph |
gloss |
Early Old Chinese |
Middle Old Chinese |
Late Old Chinese |
Middle Chinese |
Ruc |
height match? |
| 紙 | paper |
*CIteʔ | *CItieʔ | *tɕieʔ | *tɕḭe | kəcáy | ? |
| 朗 | bright |
*raŋʔ | *raŋʔ | *laŋʔ | *la̰ŋ | kàraŋ | ? |
| 脰 | neck |
*CAdoks | *CAdoks | *doh |
*do̤w |
kadɔːk | yes |
| 舞 | dance |
*CImaʔ | *CImɨaʔ | *mɨaʔ | *mṵo | kumúa | yes |
Notes on each word:
'paper': I know of no Chinese-internal evidence for the identity of *C-.
Baxter and Sagart reconstruct *k- on the basis of Ruc.
A high vowel *I is needed to account for the Middle Chinese
vocalism and the palatalization of *t. I don't know whether *I
was *[i], *[ɨ], or *[u]. Ruc ə would seem to rule out *[u]. I
don't know if Ruc has i in minor syllables; if it doesn't, Ruc ə
might correspond to a Chinese *[i] or *[ɨ].
'bright': Baxter and Sagart reconstruct *k- on the basis of
Ruc. I am unaware of any Chinese-internal evidence for a minor
syllable. Early and Middle Old Chinese *CACa-sequences and *Ca-sequences
can have the same reflexes in Late Old Chinese, so it's possible that
Late Old Chinese *laŋʔ is from an earlier, Ruc-like *kAraŋʔ.
I cannot explain why Ruc kàraŋ doesn't have an acute tone
corresponding to Chinese *-ʔ. Cf. the tone/*-ʔ
correspondences in 'paper' and 'dance'.
'neck': Lenition in 建陽 Jianyang lo was condiotnied by the vowel of a lost presyllable:
*CVd- > *CVl- > l-
I know of no Chinese-internal evidence for the identity of *C-. Baxter
and Sagart reconstruct *k- on the basis of Ruc. *V had
to be low *A since high *I would have conditioned the
palatalization of *d.
'dance': I know of no Chinese-internal evidence for the identity of *C-. Baxter and Sagart reconstruct *k- on the basis of Ruc.
A high vowel *I is needed to account for the Middle Chinese vocalism. *CAmaʔ or *maʔ would have become Middle Chinese *mo̰, not *mṵo with a high vowel. Ruc enables me to identify *I as *u. I think Early and Middle Chinese had at least two kinds of high vowels in minor syllables: *i and *u. It is usually not possible to determine whether a minor syllable's high vowel was front or back, but this is a rare exception.
Another kind of rare exception involves *i before *a:
*CiCa > *Cia
*CuCa (and *CɨCa?) > *Cɨa
Contrast these two words for 'chariot' which are both written 車:
Early Old Chinese *tiqʰ(l)a > Late Old Chinese *tɕʰia > Mandarin chē
Baxter and Sagart (2014: 157) reconstruct *t.K- for cases of velars and uvulars palatalizing before nonfront vowels. But maybe such cases involved *CiK-.
Early Old Chinese *Cuq(l)a > Late Old Chinese *kɨa > Mandarin jū
Could *C- have been *t-?
See Baxter and Sagart (2014: 158) for the reasoning behind reconstructing a uvular.
The *-qʰ- ~ *-q- alternation is unexplained. If *Ci- were *ki-, perhaps *kik- > *xtɕ- > *tɕʰ-. *k-conditioned aspiration is reconstructed for Korean, and I have reconstructed it for Tangut as well.
There is no Chinese-internal evidence for a medial liquid, but if there was one, I think it would have to be *-l- which disappeared without a trace. On the other hand, Baxter and Sagart (2014) see *-r- as a possibility, but I think an *-r- would have conditioned retroflexion: *tiqʰr- would have become *tʂʰ- rather than *tɕʰ- in Late Old Chinese.
I recall that Pulleyblank thought this word might be a loan from Indo-European (cf. Proto-Indo-European *kʷékʷlos 'wheel', Tocharian B kokale 'cart, wagon', Sanskrit cakra- 'wheel'). But Baxter and Sagart's *t- doesn't match *kʷ-, though it might be the closest approximation of a foreign palatal *c- absent from Old Chinese.
Another possibility was that the Chinese forms were something like *kiqʰla and *ku- in *kuqla-. But why would the Chinese borrow a foreign labiovelar as a uvular if they already had labiovelar *kʷ in their own language?
Here are revised reconstructions incorporating features from Ruc:
| sinograph |
gloss |
Early Old Chinese |
Middle Old Chinese |
Late Old Chinese |
Ruc |
height match? |
| 紙 | paper |
*kIteʔ | *kItieʔ | *tɕieʔ | kəcáy | ? |
| 朗 | bright |
*kAraŋʔ | *kAraŋʔ | *laŋʔ | kàraŋ | yes |
| 脰 | neck |
*kAdoks | *kAdoks | *doh |
kadɔːk | yes |
| 舞 | dance |
*kumaʔ | *kumɨaʔ | *muaʔ | kumúa | yes |
The Ruc forms seem to have been borrowed between the Middle and Late Old Chinese stages. They have a mix of old and new features:
old (i.e., like Middle Old Chinese):
minor syllable retention
*r-retention
*-k-retention
new (i.e., like Late Old Chinese):
*-e > -aj (southern breaking; a dialectal feature not in my generic Late Middle Chinese reconstruction)
*-ɨa > *-ua after labials (a change I thought came later in Early Middle Chinese)
6. While using BabelMap to type Pho sul βjot 'eight' last
night, I discovered the character Ꞵ (U+A7B4 LATIN CAPITAL
LETTER BETA). What languages are written with it? eki.ee lists
none.
7. Today I discovered that both my
2012 sketch of pre-Tangut and Sofronov's
2012 reconstruction of Tangut rhymes are online at
orientalstudies.ru.
songgiyan uliya aniya
juwa juwe biya orin nadan inenggi
'yellow pig year, ten two month, twenty seven day'
1. Thoughts today while typing and handwriting the Sino-Jurchen
vocabulary of the Ming dynasty bureau of translators:
1a. Jin (1984: 159) identified the phonogram
<gai> [kaj]
as being derived from Chinese 可 when it was read *ka (*kʰa
to be more precise). But if the Jurchen script was invented c. 1119,
long after 可 came to be read *kʰo in northern Chinese, how
would its creator(s)
know of the old reading *kʰa? This archaism hints at older
roots for the Jurchen script. In Late Old Chinese, 可 was read *kʰaiʔ.
Perhaps the origin of <gai> goes back to a pre-Jurchen script in
which 可 or a derivative was used to write [kaj]. The trouble is that
the earliest (?) of the northern scripts, the lost Serbi script, is
from the 5th century AD after *-ai shifted to *-a in
Chinese.
1b. Why does the Jurchen phonogram
<giyau>
have what looks like
<BRUSH> pi (< graph and word from Chinese 筆)
on the right side? And what is the function of the element
resembling Chinese 亻 <PERSON> on the left?
1c. Jurchen aliku 'platter' was miswritten as
<ali.in>
as if it were alin 'mountain'. Presumably the unknown correct spelling has two characters <ali.ku>. But which of these <ku> is the proper <ku>?
In theory the unknown character could even be a fifth <ku> that has not yet been discovered. There is no guarantee that all Jurchen large script characters have been found. (Almost none of the Jurchen small script characters have been found except for these six in two blocks:
![]()
![]()
. Assuming the Jurchen small script had roughly the same number of
characters as the Khitan small script, I presume there were a few
hundred Jurchen small script characters.)
1d. The Jurchen phonogram
<me>
resembles Chinese THOUSAND>, so for a second I thought it might
have originated as a graph for a me-something word for
'thousand' resembling Jurchen minggan 'thousand' in some
language in Parhae. But then I thought it might be a simplification of
the right side of Liao or Jin Chinese 脉 *mai.
2. Today I was reading about Mary
Callahan Erdoes. How is Erdoes pronounced in American
Emglish? It looks like an Americanization of Hungarian Erdős
[ɛrdøːʃ] (as in the Erdős number).
I associate oe with German ö and not Hungarian ő,
but I just learned that óe
with an acute accent is a historical spelling of ő in
names. Was the name spelled with an acute accent as Erdóes
in Hungary? I only found a
single Google result for Erdóes.
3. The late Paul Erdős
would offer payments for solutions to unresolved problems. These ranged from $25 for problems that he felt were just out of the reach of the current mathematical thinking (both his and others), to several thousand dollars for problems that were both difficult to attack and mathematically significant. There are thought to be at least a thousand remaining unsolved problems, though there is no official or comprehensive list. The offers remain active despite Erdős's death[.]
What would a list of unsolved linguistic problems be like, and how much would each problem be worth? Naturally I first think of Pyu and TJK (Tangut/Jurchen/Khitan), but other possibilities include the Voynich manuscript, Linear A, rongorongo, etc.
4. Erdős had his own personal vocabulary.
5. Timothy Gowers in a review of a book by Terence Tao:
It has been said that David Hilbert was the last person to know all of mathematics
Is it possible to 'know all of linguistics'? I vote no.
6. Speaking of knowing, Hilbert's
epitaph is a response to ignoramus et
ignorabimus 'we do not know and we shall not know':
Wir müssen wissen. 'We must know.'
Wir werden wissen. 'We will know.'
I wish I could say we will know how the TJK scripts work. I want to believe there is some reasoning that has eluded us. But what I want and believe is not necessarily what is real.
Hilbert was speaking of mathematics. Here's a quotation in a similar vein about decipherment:
Any possible system made by a man can be solved or cracked by a man.
- Yuri Knorozov, 1998
I didn't learn of him until the following year after his death. It's
been over twenty years since I read Breaking the Maya Code, a
gift from my Russian language professor Prof. James Brown. I should
read the new edition I got a few years ago.
7. I remember the dark hour when Russian might have been eliminated from the University of Hawaii (despite Russia's Pacific presence!):
But James Brown, a professor of Russian, said just because a subject is not popular now does not mean it is not needed.
"There's something to be said about providing students with what they want, but it can become ludicrous to the point where you provide only that"; Brown said. "You end up having just one flavor of things."
Obviously I wanted (and took) Russian.
Today Russian is
still around at UH. But where is Prof. Brown?
8. In the
final episode of Reba,v
the title character coined luffle (sp.?) from loving couple.
What's interesting is the [f] in the middle: it's a fricative like [v]
but voiceless like [p].
20.1.20.23:24: YELLOW PIG 12/26
songgiyan uliya aniya
juwa juwe biya orin ninggu inenggi
'yellow pig year, ten two month, twenty six day'
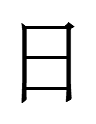
1. I've been playing 宇宙からのメッセージ・銀河大戦 Uchū kara no messēji: ginga taisen (Message from Space: Galactic Wars, 1978-79) in the background while working. A name in the ending credits caught my eye: 高梨 曻 Takanashi ?. I had never seen the third character 曻 before and couldn't find it anywhere until today when I figured out that its radical according to Unicode was 曰 <SAY> rather than 日 <SUN> and was finally able to find it in Andrew West's BabelMap.
I guessed that 曻 was an alternate spelling of the common name 昇 Noboru 'rise', and Wiktionary confirms my guess. 曻 is a Japanese-only character with the same readings as 昇: Sino-Japanese shō and native Japanese noboru.
昇 is a semantic-phonetic compound <SUN.stəŋ>: the phonetic 升 (Old Chinese *stəŋ) is a drawing of a container (in Old Chinese, 'container' and 'to rise' were homophones both written as 升), and 日 <SUN> (something that rises) was added as a disambiguator.
The top element of 曻 should also be 日 <SUN>, but the character is in the 曰 <SAY> block of characters in Unicode, and I think that's a mistake.
The bottom element of 曻 is 舛 <OPPOSE> which sounded nothing like 升 in Old Chinese:
舛 *CI[tʰ]o[n]ʔ vs. 升 *stəŋ
the initial of 舛 could have been a *CIC- sequence that later simplified to*tʰ-
But 舛 and 升 are graphically similar, so in Japanese, 舛 (also with an optional 木 <WOOD> radical: 桝) came to be an alternative spelling for the native word masu (a unit of measurement) written 升. So 舛 came to replace 升 in 曻. And 舛 <OPPOSE> with its original meaning is so rare in Japanese that few would perceive any negative connotations in 曻.
Shpika stats
(plus 漢検 Kanken
levels added 1.21.19:01):
| kanji |
Aozora |
news |
Twitter |
Wikipedia |
Kanken |
| 日 | 5 |
1 |
2 |
2 |
10 |
| 木 | 118 |
244 |
201 |
142 |
10 |
| 曰 | 1397 |
3535 |
2229 |
1753 |
1 (!) |
| 昇 | 1578 |
618 |
1138 |
879 |
3 |
| 升 | 2095 |
2122 |
2482 |
2370 |
pre-2 |
| 桝 | 3393 |
2845 |
2713 |
2893 |
pre-1 |
| 舛 | 5491 |
1665 |
2667 |
2989 |
pre-1 |
| 曻 | - |
- |
- |
4698 |
- |
曰 <SAY> in modern Japanese is almost wholly in the archaic expression 曰く <SAY.ku> iwaku 'sayeth'.
(1.21.19:03: 曰 is at the highest Kanken level, which makes no sense given its relative frequency and the fact that every high school student in Japan encounters it during the required study of Literary Chinese.)
(1.21.20:11: I would expect 曰 to be a level pre-1 character. Only characters required in school can be at levels 2 or lower. Pre-1 characters are relatively common but not required, whereas level 1 characters are rare. 曰 is encountered in school but is not on the must-learn jōyō kanji list.)
I'm surprised 桝 is more common than 舛 which I've encountered in the
name 舛田 Masuda (a name I learned from 舛田利雄 Masuda
Toshio on the staff of Space Battleship Yamato). I've never
seen 桝 before. Wiktionary
says some strange things: that 桝 is a postwar simplified form of 枡 (but
桝 has more strokes!) and means 'measuring box' in Chinese (even though
I thought 舛 = 升 is a Japanese-only equation).
I just learned that 升 has a new modern reading: チート chīto 'cheat', based on the coincidental similarity of the katakana to 升. There is no graphic relationship between the katakana and 升:
チ <chi> is derived from 千 <THOUSAND>
ー (vowel length marker) is derived from the right side of 引
<PULL> (turned ninety degrees)
ト <to> is derived from 止 <STOP>
2. New words I encountered today:
2a. Redology
(紅學 - not Erythrology?)
(often humorous) added to an ordinary English word to create a name for a (possibly non-existent) field of study.
2b. logy,
the sister of ism
(with an
unrelated homograph)
2c. pseudepigrapha
(not pseudo- ... or ... -ia!)
2d. anapodoton
2e. anacoluthon
I've known of all of those things but didn't have names for them until now.
3. I did not, however, know of the Codex Amiatinus until today.
The Codex Amiatinus is the earliest surviving complete manuscript of the Latin Vulgate version of the Christian Bible.
Although it is named after the Italian mountain where it was found, it
was produced around 700 A.D in the north-east of England, at the Benedictine monastery of Monkwearmouth–Jarrow in the Anglo-Saxon Kingdom of Northumbria and taken to Italy as a gift for Pope Gregory II in 716.
More new words (in bold):
A little space is often left between words, but the writing is in general continuous. The text is divided into sections, which in the Gospels correspond closely to the Ammonian Sections. There are no marks of punctuation, but the skilled reader was guided into the sense by stichometric, or verse-like, arrangement into cola and commata, which correspond roughly to the principal and dependent clauses of a sentence.
Today, colons and commas have different referents (and regularized English plurals).
4. I never heard of the acronym TRO until
today.
20.1.19.23:29: YELLOW PIG 12/25
songgiyan uliya aniya
juwa juwe biya orin shunja inenggi
'yellow pig year, ten two month, twenty five day'
1. For years, I thought
<ca> (a transcription of Liao Chinese 察 *cha in line 1 of the 耶律昌允 Yelü Changyun epitaph [1062])
was unique to the Khitan large script, but today I learned that it
looks like a
Tang dynasty (i.e., pre-Khitan Empire) variant of the Chinese character
司.
There is even a variant of the derivative character 詞 <SPEECH.司>
with a <ca> lookalike on the right side. But ... 司 was pronounced
*sï in Liao Chinese. Not very much like ca. So why is a
lookalike of a variant of 司 a phonogram for ca?
The odds of any Khitan large script character being pronounced
approximately like its Chinese lookalike are low, though not zero, as
there are some Khitan large script characters that have Liao
Chinese-like readings (minus tones, of course): 太 tai (but also
dai!), 天 tên, 水 shui, 吾 ngu, 之 cï,
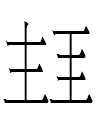
皇帝 hongdi, 京 ging, 守 sheu, 王 ong, etc.
But one must be on guard, because many other Khitan large script
characters are false friends: e.g.,
上 is read ha (cf. Liao Chinese *shang)
仲 is read shang (cf. Liao Chinese *zhung)
五 is read tau (cf. Liao Chinese *ngu)
高 is read tau (cf. Liao Chinese *gau)
氷 is read mu (cf. Liao Chinese *bing 'ice'
2. Another variant of 詞 <SPECH.司> is 𧥝 <SPEECH.𠃌> with the phonetic reduced to 𠃌. The current simplified character for standard Mandarin 詞 cí 'word' is 词, but that could be reduced even further to three strokes: ⿹𠃌讠.
3. Wiktionary regards 𠃌 as a component in the Korean phonogram 㔖 <ka.k> kak, but the bottom component is in fact the hangul letter ㄱ <k> which is never written with a hook. The top part is the Chinese character 加 <ADD> which is pronounced ka in Korean.
4. Peter Golden's An Introduction to the History of the Turkic Peoples (1992) brings up the ever-vexing problem of consistency in writing different languages in the Roman alphabet: e.g., <ł> represents both Polish [w] and Armenian ղ [ʁ]. Historicallyղ was a velar lateral [ɫ] (which is what I think Tangut /l/ was).
Classical Armenian had a distinction between velar ղ /ɫ/ and 'regular' լ /l/ absent from Proto-Indo-European? How did that develop? Wikipedia's article on 'Proto-Armenian' (more like 'pre-Armenian'; cf. my 'pre-Tangut') doesn't have the answer yet. But it listed a few words with both liquids:
Velar /ɫ/-words:
ałaxin 'slave girl' from Hurrian al(l)a(e)ḫḫenne
pełem 'dig, excavate' from Urartian pile 'canal', Hurrian pilli
Wiktionary
derives this from Proto-Indo-European *bel 'to dig',
citing Sanskrit bila- 'hole, pit', but a regular
Sanskrit reflex of *bel should have a < *e
ułt 'camel' from Hurrian uḷtu 'camel'
Wiktionary
has a dot under the t, but Wikipedia's
table of Hurrian consonants shows only one kind of /l/ and /t/
Wiktionary suggests that Proto-Indo-Iranic *uštras
'camel' could be connected to this word, but the l : š
correspondence and -r- need to be explained
salor ~ šlor 'plum' from Hurrian *sāll-orə or Urartian *šaluri (cf. Akkadian šallūru 'plum')
xarxarel 'to destroy' from Urartian harhar-š- 'to destroy'
I don't see any pattern that would enable me to predict when foreign
l was borrowed as /ɫ/ or /l/ in Armenian.
5. I've never seen a French name written in Armenian before: Րեմի Վիրդա.








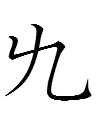

















{kind=link}