



songgiyan uliya aniya

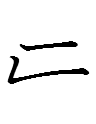




juwa juwe biya orin duin inenggi
'yellow pig year, ten two month, twenty four day'
songgiyan uliya aniya
juwa juwe biya orin duin inenggi
'yellow pig year, ten two month, twenty four day'
1. Years ago I noticed that 朽 <ROT> had
an irregular Sino-Vietnamese reading: hủ instead of hửu. But
I never gave any further thought to that until this week.
朽 belongs to the Early Middle Chinese *-u > Late Middle Chinese *-ɨw rhyme category. Most Sino-Vietnamese readings are borrowed from a southern Late Middle Chinese dialect, so that rhyme category normally corresponds to Sino-Vietnamese -ưu. 舊 <OLD> was borrowed at least twice, first as what became cũ¹, and then as what became cựu. cũ is from southern Early Middle Chinese *gṳ, whereas cựu is from southern Late Middle Chinese *kɨ́w.
hủ has the same rhyme (tone aside) as cũ, so I
regard both as Early Middle Chinese borrowings. To be more precise, hủ
seems to be from a stratum of borrowing whose tones
match the pattern found in Late Middle Chinese borrowings, whereas cũ
is from an even earlier stratum with a different pattern of 'tonal'
(strictly speaking, registral) borrowing. See the table below:
Vietnamese renderings of the ́*-u > *-ɨw rhyme (not all possibilities necessarily attested)
| Chinese initial |
Chinese 'tone' class |
stratum 1 |
stratum 2 |
stratum 3 |
| *voiceless |
rising |
-ú |
-ủ (e.g., 朽 hủ) | -ửu |
| *voiced |
-ụ | ̣-ũ | -ữu | |
| *voiceless | departing | -ủ | -ú | -ứu |
| *voiced | -ũ (e.g., cũ) |
-ụ |
-ựu |
An even more surprising reading of 朽 is Cantonese nau2
in addition to the regular jau2. 朽
has a variety of different initial types across the Sinitic language
family. I have omitted tones. (In hindsight I shouldn't have because
tones would help refine my reconstruction of the history of the
initials.)
| initial type |
form |
group |
variety |
| aspirated velar stop | kʰa < *-æw? |
Southern Min | 潮州 Chaozhou in Bangkok |
| kʰieu |
Eastern Min |
福安 Fu'an | |
| velar fricative | xiu |
Eastern Min | 福州 Fuzhou |
| glottal fricative |
hĩũ |
Southern Min |
潮州 Chaozhou |
| shibilant |
ɕiu |
Hakka | 城廂 Chengxiang |
| ʃiɑu | Central Min |
三明 Sanming |
|
| sibilant |
sio |
Central Min |
沙縣 Shaxian |
| zibilant |
ziu |
Hakka |
玉林興業 Yulin Xingye |
| affricate |
tsʰiou |
Pinghua |
橫縣 Hengxian |
| lateral |
ɬou |
Pinghua |
富寧 Funing |
| lɐu |
Yue |
仁化 Renhua |
|
| glide |
jou |
Pinghua |
龍州 Longzhou |
| glottal stop |
ʔiu |
Guangxi Min |
平南 Pingnan |
| zero |
iəu |
Pinghua |
永福 Yongfu |
| nasal |
ŋɔu |
Pinghua |
田東 Tiandong |
| ɲɐu |
Yue |
寧明 Ningming |
|
| nau |
Min dialect island |
中山 Zhongshan |
|
| Hakka dialect island |
|||
| mau |
Yue |
懷集 Huaiji |
|
| prenasalized stop |
ⁿdæ |
Yue |
新會 Xinhui |
Here's an attempt to make sense of that diversity of initials. Some of it is probably wrong because I don't have the time to work out the history of all the varieties involved.
*mVqʰ- > *m̥- > m- in Huaiji
*mVqʰ- > *ŋkʰ- > ŋ- in Tiandong
*mVqʰ- > *ŋkʰj- > ɲ- in Ningming
*mVqʰ- > *ŋkʰj- > *ɲ- > n- in Cantonese; borrowed into Min and Hakka Zhongshan
but *ɲ- > j-, not n- in Cantonese!
*ɲ- or *xj- (cf. *x- below) > j- in Longzhou
cf. *j- > d- [z] in northern Vietnamese
*ɲ- or *xj- (cf. *x- below) > *j- > zero + vowel i in Yongfu
*ɲ- > *n- > ⁿd- in Xinhui
*ɲ- > *n- > l- in Renhua
Funing ɬ- has a different origin
*mVqʰ- > *kʰj- > tsʰ- in Hengxian
*mVqʰ- > *qʰ- > *x- > h- in Chaozhou
is the nasalization of the vowel a trace of *m-?
*mVqʰ- > *qʰ- > *x- or *h- > ɕ- before *i in Chengxiang
*mVqʰ- > *qʰ- > *x- or *h- > *ɕ- or *ʃ- before *i > s- in Shaxian
To wrap this up, in theory 㽲 <>, 㱙 <>, and 殠 <> should have the same reading as 朽 in Vietnamese (or any other language that inherited or borrowed those Chinese morphemes). In theory their Sino-Vietnamese readings should be
stratum 1: hú < Chinese *xṵ with creaky
voice
stratum 2: hủ < Chinese *xú with a tone
stratum 3: hửu < Chinese ́*xɨ́w
But in fact the actual readings according to Mineya (1972: 67) are hữu for 㽲 and hứu for 㱙殠!
hữu has stratum 3 vocalism and a stratum 3 tone pointing to a *voiced initial.
hứu has stratum 3 vocalism. The tone could be stratum 3 if it's from a Chinese departing tone.
¹Although Vietnamese cũ 'old' is a borrowing of Chinese 舊 <OLD>, it is not written as 舊 <OLD> according to nomfoundation.org which lists nineteen different spellings. My HTML editor (KompoZer) doesn't fully support Unicode, so I can only display nine spellings:
寠屡屢𡳰𡳵𡳶𦼨𪡻𫇰
Approximations of the remaining ten:
⿰𫇰娄
⿰娄𫇰
⿰𫇰𪧘
⿰𪧘𫇰
⿰屡古
⿰旧具
⿰𫇰者
⿰屡旧
⿰𫇰具 minus one stroke
⿰寠𫇰
Those spellings have several common components:
𪧘寠: phonetic củ
屡屢: phonetic lũ (with l- instead of c- [k]!)
娄: phonetic lâu (with l- instead of c- [k]!)
古: semantic <OLD>
旧: semantic <OLD>
艹: semantic <GRASS> (why?)
貝: simplification of phonetic 具 cụ
2. For some reason I thought turmeric was ˟tulmeric until I learned the correct spelling today. Reminds me of the r > l dissimilation in Latin peregrinus > Old French pelegrin (> English pilgrim).
In Japanese, 'tulmeric' is ukon with five interesting spellings:
鬱金 ~ 欝金 <LUXURIANT GOLD> looks as if it should be read ukkon
this seems to be a case of a 'close-enough' phonogram chosen for partly semantic reasons
郁金 <FRAGRANT GOLD> looks as if it should be read ikkon
郁 can also be a variant of 鬱 ~ 欝 <LUXURIANT> and has
taken its place
玉金 <JADE GOLD> looks as if it should be read gyokkon
宇金 <EAVES GOLD> is the only one of the five that is read the way it looks; 宇 is a phonogram for u
3. Speaking of 郁 ... last Sunday I learned that anime company founder 布川ゆうじ Nunokawa Yūji was born 布川郁司 Nunokawa Yūji. I initially misread 郁 as Ikuji because 郁 is normally iku. However, in that instance it seems to have been read yū by analogy with its phonetic 有 yū. The two were of course closer in Old Chinese pronunciation:
郁 Early Old Chinese *qʷək > Late Old Chinese *ʔwɨək > Early Middle Chinese *ʔwɨk (> Sino-Japanese iku) > Late Middle Chinese *ʔuk
有 Early Old Chinese *ɢʷəʔ > Early Middle Chinese *wṵ > Late Middle Chinese *(w)ɨ́w (> Sino-Japanese iu > yū).
20.1.17.23:59: YELLOW PIG 12/23
songgiyan uliya aniya
juwa juwe biya orin ilan inenggi
'yellow pig year, ten two month, twenty three day'
1. How did I not figure out that Alaric was 'all-ruler'?
2. Is Alaric cognate to Aldrich? ancestry.com quotes the Dictionary of American Family Names (2013):
English: from a Middle English personal name, Ailric, Alrich, Aldrich, etc. (Many different forms are recorded.) It represents the coalescence of at least two Old English personal names, Ælfric 'elf ruler’' and Æ{dh}elric 'noble ruler'.
Did -lfr- in Ælfric really become -lr-? I assume the -d- was inserted in Middle English. Is there a single word for such transitional stops: e.g., the [t] in modern English prince [pʰɹɪnts]? (It's been maybe thirty or more years since I learned about that pronunciation in an early linguistics class.)
If forced to disambiguate between prince and prints,
I might say [pʰɹɪ̃s] and [pʰɹɪntʰs]. The noninitial [tʰ] is, of course,
deliberate and artificial.
3. Scott DeLancey's "Creolization in the Divergence of Tibeto-Burman" (forthcoming) distinguishes between two kinds of Tibeto-Burman languages: archaic and creoloid. I think Pyu fits the creoloid profile, as its grammar is "very reminscent of the minimal grammar which we find in creole languages" (p. 1). What does that suggest about the prehistory of Pyu? That this scenario applies to it (pp. 4-5; emphasis mine):
"[...] I am not proposing a pidgin stage in the development of any of the languages discussed here, these are not true creoles, in the sense of McWhorter 2001. [... C]ertain creole-like patterns can develop through intense language contact involving suboptimal transmission. What I am suggesting is that Proto-Bodo-Garo, Proto-Lolo-Burmese, Proto-Bodish, and probably others such as Proto-Tani, took on their grammatical shape in circumstances in which they were widely spoken by non-native speakers, as trade languages, languages of administration, soldier’s argot, or by mixed populations.
DeLancey is speaking of Lolo-Burmese on p. 15, but his words may
also
apply to Pyu:
an extended historical phase involving urban centers and kingdoms
The relative uniformity of Pyu in inscriptions from different
locations has suggested to me that Pyu may have been a standardized
literary language that was not necessarily spoken by everyone in the
various Pyu cities. It may be too simplistic to regard the populations
of those cities as homogeneously 'Pyu' in a linguistic, much less
ethnic, sense. The inscriptions could have been in a lingua franca
spoken natively only by an elite, possibly of northern origin. (The
sesquisyllabic, superficially Mon-like structure of Pyu might suggest
an Austroasiatic [but not specifically Mon]-speaking component in
the substratum population.)
It doesn't help that nobody really knows the autonym of the Pyu;
neither the Burmese exonym Pyu nor the Mon exonym Tircul have been
found in Pyu inscriptions, though both are attested in Chinese
historical records.
4. Bob Hudson proposes five Pyu dynasties based on archaeological evidence:
I. Big Club Man Dynasty, 1st-3rd c. AD
named after imagery of "a heroic figure with a club", possibly a representation of the dynasty's founder
II. Vikrama Dynasty, 4th-5th c. AD
named after the such-and-such-vikrama kings whose names were inscribed on urns
III. World Pillar Dynasty, 6th c. AD
IV. Prabhuvarma, Prabhudevi, Khin Ba and the square-based stupas
dynasty, 7th c. AD
named after a king and queen (?) whose names are on a silver reliquary:
tgam·ṃḥ dav·ṃḥ tdav·ḥ to śri prabhuva[r·]rma
'Righteous Earth-Lord (?) King Śrī Prabhuvarma'
tgam·ṃḥ dav·ḥ tdav·ḥ nu va(l·)ṃḥ śri p[r]abh[ud]evi
'Righteous Earth-Lord (?) Queen (?) Śrī Prabhudevī'
V. Bawbawgyi builders and inscribed bricks dynasty, 8th c. AD
named after 8th century "fingermarked, incised or
stamped bricks with Pyu letters or numbers on them" whihch "are not seen in the earlier square-base stupas. Was this a way to recognise and encourage the donors of building materials? Does it perhaps indicate increasing literacy - or at least some number and letter recognition?"
Bob and I visited the Bawbawgyi four years ago.
I wish I could give Bob more linguistic evidence to back up his hypothesis.
Toward the end he quotes our colleague Arlo Griffiths (who also went
to the Bawbawgyi with us):
Every time I think I see a pattern, I find a new specimen which seems to contradict it.
That's been my experience in different fields. I think if I could go
back in time and learn the answers to all the mysteries of Pyu, Tangut,
Jurchen, and Khitan, I'd observe patterns that fit all the evidence -
both the evidence I found for my proposed patterns and their
counterevidence.
5. I tend to use AD rather than CE on this site because 'common'
could be interpreted as 'universal', which CE is not. But of course the
D of AD is also objectionable. I wish there were another alternative,
an English equivalent of 西曆 seireki 'western calendar'. Which
has a poor initial combination in English. Western Era spells
WE which implies 'ours'. Another turnoff.
6. It's taken me years to notice that Khitan ei 'to have, exist' might be the source of the converb -i which "indicates the order in which the action happened: 'then, after that' (Kane 2009: 149):
V₁-i ... V₂
'after V₁, then V₂'
Is the converb from the full verb: 'that action having existed, then ...'? I just realized the construction above could be translated as
'having V₁, ... V₂'
and ei can be translated as 'to have'.
Examples of the converb from Kane (2009: 149-150; CV = converb):
baid-gha-i 'having been buried'
dem-lge-i 'having been granted'
mulu-i 'having been appointed'
o-i 'having become'
7. The bai- of baidgha- 'bury' is written as
<061>
in the Khitan small script. Today it occurred to me that bai
sounds like be (< *Npai), a Japanese reading of the 061-like
kanji 可 <ABLE> used to write the -be- of the debitive suffix -ube-
from Old Japanese umbəy 'indeed'. So dare I say that 061 was
influenced by a peninsular logogram for a Para-Japonic cognate of
Japanese -ube-? No, because -ube-
"represents a purely Japanese innovation based on grammaticalization"
(Vovin 2008: 880) which occurred in the Old Japanese period long after
Japonic split from its peninsular relatives.
8. Why was Lao ສິ້ນ <si2n> [sin˧˩] 'skirt' borrowed into English as sinh? Is nh originally a French romanization device to indicate [n] (as opposed to simple n which might be misinterpreted as a mark of nasalization on the preceding vowel)? I keep thinking -nh in Lao romanization is a palatal nasal [ɲ] as in Vietnamese, even though Lao has no words ending in [ɲ].
It seems that the Khmer equivalent of that romanization device is nn since nh was already used to represent [ɲ] as in Vietnamese: e.g., Sinn Sisamouth for ស៊ីន ស៊ីសាមុត <s'īna s'īsāmuta> [sɨn siːsaːmut].
th appears to be a romanization device for nonsilent final [t]. I used to think that th was a romanization of final <tha> [t] in Khmer, but that wouldn't explain its use in the romanization of Lao in which <tha> is not used in spelling: e.g., Bounnhang Vorachith for ບຸນຍັງ ວໍລະຈິດ <punyaṅa vŏlaḥcita> [bun˩ɲaŋ˥ wɔː˥la˧tɕit˥].
This chart of Lao romanization reminds me that -ne is another way to write final [n], presumably again to avoid a simple n which might be misinterpreted as a mark of nasalization on the preceding vowel.
9. Wikipedia
uses a symbol for the Lao falling tone that I've never seen before:
U+1DC6 COMBINING MACRON-GRAVE: -᷆ (the hyphen is a placeholder).
10. I've been using the
Leipzig Glossing Rules for years now in my publications (though I
can't claim I've been consistently applying them on my blog). I just
discovered this
Wikipedia list of glossing abbreviations.
20.1.16.23:59: YELLOW PIG 12/22
songgiyan uliya aniya
juwa juwe biya orin juwe inenggi
'yellow pig year, ten two month, twenty two day'
1. I rediscovered Peter Golden's An Introduction to the History
of the Turkic Peoples (1992) to look up Burut in the index. I
didn't find it, but I did find lots of references to the Tangut,
Jurchen, and Khitan. I should read the whole book instead of just
consulting it.
2. I've done more thinking about these
'irregular' Sino-Japanese
readings:
數 suu
偶遇寓隅嵎耦藕 guu
The morphemes represented by those characters all belong to the Old Chinese *-o rhyme class. In Late Old Chinese, the *-o class split in two depending on the vowel (if any) preceding it:
*(CA)Co > *Co > *Cou
*CICo > *CICuo > *Cuo
*o bent in two ways: to *-ou if not preceded by any
vowel or if preceded by a low vowel *A or to *-uo if
preceded by a high vowel *I.
Both subtypes are represented in the readings for the characters
above:
Suppose Late Old Chinese *-ou and *-uo were borrowed
into pre-Old Japanese as *-ou and *-uo. One of the
defining traits of Old Japanese is *o raising to *u. So
*suo, *ŋguo, and *ŋgou became suu, guu, and guu.
And the 'regular' reading 愚 gu is a postraising borrowing from
Late Middle Chinese in which *-uo became *-u.
That's how I see things now, which is a lot simpler than what I
originally had in mind last week.
1.21.19:20: APPENDIX: Shpika stats.
| kanji |
Early Old Chinese |
Late Old Chinese |
Aozora |
news |
Twitter |
Wikipedia |
| 数 |
*sIroʔ/h | *ʂuoʔ/h |
225 |
142 |
318 |
119 |
| 隅 |
*CIŋo | *ŋuo |
938 |
1854 |
1914 |
1767 |
| 愚 | *CIŋo | *ŋuo |
1106 |
2168 |
1331 |
2077 |
| 偶 | *ŋoʔ/s | *ŋouʔ/h |
1172 |
1741 |
1490 |
1234 |
| 遇 |
*CIŋos | *ŋuoh |
1215 |
1470 |
1245 |
1625 |
| 數 |
*sIroʔ/h | *ʂuoʔ/ | 1422 |
0 |
0 |
3763 |
| 寓 |
*CIŋos | *ŋuoh |
2790 |
3215 |
3363 |
2924 |
| 藕 |
*CAŋoʔ | *ŋouʔ | 4861 |
0 |
0 |
6716 |
| 嵎 |
*CIŋo | *ŋuo |
5510 |
0 |
0 |
7414 |
| 耦 |
*ŋoʔ | *ŋouʔ | - |
- |
- |
8580 |
Shpika stats only apply to modern Japanese, so they are not reliable guides to kanji frequency in the past. Nonetheless, they can serve a starting point for hypotheses.
Perhaps originally there could have been just one very early, pre-*o-raising borrowing *ŋgou > guu for a very common 禺-kanji (e.g., 遇 <MEET>?), and that reading spread by analogy to less frequent 禺-kanji, displacing *ŋgu > gu readings borrowed later. But the gu reading for the common kanji 愚 <FOOLISH> remained unchanged.
Shpika has separate entries for 數 <NUMBER> and 数, the modern
standard form of 數. 數 is so common that analogy cannot be a factor in
its reading. I think the morpheme was borrowed very early as *suo
prior to *o-raising.
3. Best Hawaiian language news I've heard in a long time: Hawaii News Now reported that young native speakers of Hawaiian on Niihau have published professional-looking books in their own language. A pity I can't find a link online.
Niihau
Hawaiian is to standard Hawaiian what Sibe is to Manchu: a variety
preserved on the periphery while its prestigious sister is endangered.
4. Tonight I was surprised to hear Lev Parnas speak perfect American English. I had assumed he had immigrated as an adult, but he actually arrived in the US at the age of three in the 1970s, well before the independence of Ukraine.
I was also surprised to see that he didn't have his own Wikipedia
page - and that he
served as a translator [I think 'interpreter' is intended] for a legal case involving Dmytro Firtash, one of Ukraine's wealthiest oligarchs with self-admitted mob connections [...] However, recordings of Parnas speaking Ukrainian and Russian evidence that he has not retained total fluency in these two languages since coming to the United States.
I would have expected "one of Ukraine's wealthiest oligarchs" to hire a professional interpreter.
5. One last surprise: learning that the Ukrainian equivalent of Russian Дмитрий Dmitrij is Дмитро Dmytro with final stress. I would have predicted ˟Dmytryj with initial stress via mechanical conversion from Russian (dangerous, I know). Does the Ukrainian final -o reflect the o of Δημήτριος <Dēmḗtrios>?
I would have predicted that the initial cluster Дм- Dm- came from an even earlier Дьм- Dĭm-, but Wikipedia says Дъм- Dŭm- also existed. I wouldn't have expected Greek η <ē> ([i] by the time the name was borrowed into Russian) to be Russified as ъ ŭ.
20.1.15.23:59: YELLOW PIG 12/21
songgiyan uliya aniya
juwa juwe biya orin emu inenggi
'yellow pig year, ten two month, twenty one day'
1. Last night I learned of this year's new 'Super Sentai' show, 魔進戦隊キラメイジャー Mashin sentai Kirameijā (Devil Advance Task Force Kiramager).
The super-vehicles in the show are called 魔進 mashin 'devil advance', a pun on 'machine'. 魔 ma implies 'magical'. Maybe 'magiforth' would be a better English rendering.
Kirameijā is a blend of 煌めく kirameku
'sparkle', mage, and ranger. And the last
part sounds like major, perhaps unintentionally.
2. Tonight I learned of the late Betty
Pat Gatliff's SKULLpture Lab. How did that pun never occur to me
before? It's
occurred to others.
Imagine English written in a Chinese-style script with a pictogram
of a skull recycled to write the scul- of sculpture.
Perhaps the stylized spelling ☠lpture already exists. Typing "☠lpture"
into DuckDuckGo generates results that don't seem to have that
spelling: e.g., this
page which has the typo "Scu;lpture" instead.
I wonder if there are Sinospheric puns involving 髑髏 'skull'.
Imagine, for instance, an independence movement called 獨髏 (with 髑
respelled as its homophone 獨 'alone', the first half of 獨立
'independence') or 髑立 (which sounds like 獨立 'independence') with a
skull as its symbol.
3. Why isn't 髑髏 a choice if I type "dulou" into Windows 10's Pinyin
IME? I had to type "dokuro" in Japanese to type that. I could have
fished for髑 and 髏 separately by typing "du" and "lou" into the Pinyin
IME, but that would have taken longer.
4. Why did the Manchu call the Kyrgyz ᠪᡠᡵᡠᡨ Burut?
Prior
(2013: 29) says of Burut, "The required full study on this
ethnonym [...] has yet to be produced."
5. I just heard "animoji" for the first time on The Late Show
with Stephen Colbert. Who would have imagined centuries ago that
Latin animatio would merge with Japanese 文字 moji
'character', a descendant of Old Japanese 文字 *mənzi (*məndzɨ?),
probably a borrowing from a similar (identical?) Sino-Paekche word
borrowed in turn from southern Early Middle Chinese 文字 *mən dzɨ̰.
(1.16.16:26: Scripta Sinica shows that the word 文字 is attested as early as 史記 Shiji [Records of the Historian, c. 94 BC]. Is it in any earlier texts?)
animoji has an entry in Wiktionary ... but it's for Spanish animoji defined as English animoji ... which doesn't have an entry yet!
6. How did I not discover the "citations" tab of Wiktionary until
now?
20.1.14.23:51: YELLOW PIG 12/20
songgiyan uliya aniya
juwa juwe biya orin inenggi
'yellow pig year, ten two month, twenty day'
1. I wrote about orin 'twenty' here.
2. Tonight's episode of The Late Show with Stephen Colbert was titled "Dem Moines Dembate!" (See the title here at 0:55.) I think I hear Jen Spyra saying Moines as [mɔjnts] rather than as [mɔjn] or even [mɔjnz], as if she were making an effort to pronounce the final written <s>.
Wiktionary says Des Moines (Washington) is pronounced [dəˈmɔɪnz], whereas Des Moines (Iowa) is pronounced [dəˈmɔɪn]. I never heard of the first one before.
Dem Moines works well as a pun in English because /mm/ can be reduced to a single [m] in rapid speech. So Dem Moines and Des Moines can be homophonous.
The similarity between Dembate and debate
reminds me of the allophony of prenasalized obstruents that I proposed
in Old Japanese over twenty years ago: /Nk Ns Nt Np/ could be [ŋg nz nd
mb] or [g z d b]. (Or even [vowel nasalization + g z d b].)
3. Minutes after I saw that, I encountered the word microburst for the first time. How micro is micro?
20.1.13.23:59: YELLOW PIG 12/19
songgiyan uliya aniya
juwa juwe biya oniohon inenggi
'yellow pig year, ten two month, nineteen day'
No need for a boilerplate discussion of 'nineteen' here since I already did that last month. Instead, I want to talk about Wu Yingzhe's (2014: 425) observation that 'eight' is also phonetically spelled as
<222.327.270> <ny.yê.êm> (<ê> = a front vowel unlike <e> for /ə/).
Written Mongolian naiman points to an original *a
that fronted after *ny /ɲ/. Compare the fronting of *a
in Khitan with the rounding of *a to *o after *ny
in the language from which Jurchen borrowed niohon
'eighteen'.
Shimunek (2017: 358) reconstructs 'eight' in Proto-Serbi-Mongolic *ñayɪma (*nyayïma in my notation). Janhunen (2003: 17) regards *-PAn (with an assimilated variant *-man after the nasal *ny-) as a suffix. I might expect that lower numeral suffix to be reduced to a single consonant in other Khitan numerals, but so far 'eight' seems to be unique; 'ten' doesn't have it.
1.21.20:14: APPENDIX: Written Mongolian suffixed lower numerals and their Khitan cognates
| gloss |
Proto-Serbi-Mongolic | Written Mongolian |
Khitan (expected) |
Khitan (actual) |
| three |
*gur |
ghurban |
?ghurb |
ghur |
| four |
*dör |
dörben |
?durb |
dur |
| six |
*nil |
jirghughan |
?nil |
? |
| seven |
*dalu |
dologhan |
?dalugh |
dalu |
| eight |
*nya(y)ï |
naiman |
?nyêm |
nyêm |
| ten |
*par |
arban |
?parb |
par |
The Proto-Serbi-Mongolic forms are based on Janhunen (2003) and Shimunek (2017).
The absence of reflexes of *-PAn in Khitan 'three', 'four', and 'ten' could be explained away as the result of a simplification *-rb > *-r. But that doesn't account for the absence of -gh in dalu 'seven'.
I think *-PAn is a Mongolic innovation absent in Khitan. But doesn't Khitan nyêm contain a reflex of *-PAn? Maybe not. It just occurred to me that the m of naiman and nyêm could in fact be part of the root, and Mongolic -an in naiman could be by analogy with dologhan. That analogy never occurred in Khitan which never added *-PAn to 'seven' or any other numeral.
The evidence for a reading of Khitan
<SIX>
seems to be ... nil. nil based on Jurchen nilhun 'sixteen' is not a bad guess, but there is no guarantee that Khitan proper had the same root for 'six' as the Khitan dialect or Khitan-like language that is the source of nilhun.
In any case, I agree with Janhunen (2003: 17) that Mongolic 'six' is
an innovation: jir 'two' times ghu 'three' plus *-PAn.
Janhunen (2003: 17) writes that "The absence of *.pA/n in 1 *nike/n
> *nige/n, 5 *tabu/n, and 9 *yersü/n
suggests that these numerals were somehow special and perhaps
secondary." He does not comment on the absence of *.pA/n in
'two'.
20.1.12.23:57: YELLOW PIG 12/18
songgiyan uliya aniya
juwa juwe biya niuhun inenggi
'yellow pig year, ten two month, eighteen day'
1. 'Eighteen' in Jurchen dates is either niuhun 'eighteen' (in Jurchen Empire usage) or juwa jakun 'ten eight' (in Ming dynasty usage). niuhun 'eighteen' is obviously not cognate to juwa 'ten' or jakun 'eight' and is probably a loan from a para-Mongolic language (a nonstandard Khitan dialect?).
Khitan as preserved in written records has <TEN EIGHT> in both scripts rather than a special word for 'eighteen'. The Khitan words for 'ten' and 'eight' are unknown.
As far as I know (I do not have anything like a complete
concordance), <TEN> never combines with any other character in
the small script, so it (a) may be a true logogram for 'ten' (though
the possibility of it representing a nonnumeral homophone in one or
more contexts cannot be dismissed yet) or (b) have a phonetic value
that does not happen to occur in any other word. If 'ten' was something
like the -hun/hon suffix found in the Jurchen teen-words
borrowed from para-Mongolic, I would expect it to appear at least once
in another block since I cannot imagine HUn being an exotic
syllable in Khitan.
I have only seen <EIGHT> in combination with <de>, the dative-locative suffix, toward the end of line 7 in the epitaph for 蕭仲公 Xiao Zhonggong (1150). Can all Khitan numerals take nominal suffixes? (<THREE> has the suffix <de> earlier in the line.) What I wrote about <TEN> applies here as well: <EIGHT> (a) may be a true logogram for 'eight' (though the possibility of it representing a nonnumeral homophone in one or more contexts cannot be dismissed yet) or (b) have a phonetic value that does not happen to occur in any other word.
Jin (1984: 200) derives the Jurchen graph <EIGHTEEN> from
Chinese 十 <TEN> and 八 <EIGHT>, but I don't see any
resemblace between the three beyond a cross-shaped intersection (and
<EIGHTEEN> really doesn't have a vertical stroke). Thinking of
<EIGHTEEN> as <TEN> with two extras at the top left and
bottom right is useful for memorizing the character, though.
Janhunen (2003: 399) reconstructs the potential ultimate source of
Jurchen niuhun as pre-Proto-Mongolic *nya(y)i.ku/n
'eight-teen' via *nyo.hun or *nyohon¹.
The rounding of *a (preserved in Proto-Mongolic *na(y)i.man
[Janhunen 2003: 17]) < *ny seems to be an assimilation of *a
to a following labial vowel. Conversely, the Proto-Mongolic first
decade numeral suffix *-man < *-pA/n has a nasal due
to assimilation to the initial *n- of the root *na(y)i
(Janhunen 2003: 17). Maybe the Khitan word for 'eight' was somethig
like nyai - a direct preservation of Proto-Serbi-Mongolic
'eight'? (There is no evidence for the consonant-vowel sequence yi
in Khitan.)
But Wu Yingzhe introduces a twist in the decipherment of 'eight' that
I'll save for tomorrow, assuming I have time. Although I had other
topics planned for today, midnight approaches, so I'll stop here.
¹The absence of a period before *-hon seems to be a typo.






