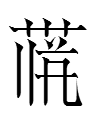
0100 1lew < *Cʌ-tek 'one'
*Cʌ- conditioned intervocalic lenition (*VtV > *VlV) before being lost; its low vowel prevented *e from partly raising to ie)
11.9.17.23:57: DEPARTING ALONE ON THE FIRST MONTH
The graph 正 for Old Chinese *teŋs 'straight, correct' from my last post had another reading *teŋ 'first' (month)* that might be cognate to Tangut
0100 1lew < *Cʌ-tek 'one'
*Cʌ- conditioned intervocalic lenition (*VtV > *VlV) before being lost; its low vowel prevented *e from partly raising to ie)
which is turn is cognate to 隻 OC *tek 'single'.
I have thought for a few years that 0100 might be cognate tobut couldn't explain why 5356 had no -w corresponding to the -w of 0100.
5356 1tiẹ < *Sɯ-te ́ 'only, unique'
*S- is the source of the tenseness in the vowel: *S-V > Ṿ*ɯ is a cover symbol for a high vowel that conditioned the partial raising of *e to ie
There are many Chinese alternations of the type
Middle Chinese *-k ~ *-h < Old Chinese *-k ~ *-k-s
e.g., 學 MC *ɣæwk 'to study' ~ *ɣæwh 'to teach' < OC *gruk ~ *gruk-s
in which a Middle Chinese 'departing tone' signified by *-h (phonetically a pitch associated with breathy voice?**) originated from an Old Chinese root *-k plus suffix *-s***.
Could something similar have happened in Tangut?If this sound change occurred, there should be pairs of the typeTangut tone 2 ('rising tone') < *-H < *-k-s
and 2-w would be from *-wH rather than *-H < *-k-s.1-w < *-k ~ 2-Ø < *-H < *-k-s
The trouble is that 5356 has tone 1, not tone 2, so it doesn't fit the expected pattern 2-Ø. And of course 5356 has no final -w which could be from *-k. So I have to reconstruct 5356 with an open syllable: *Sɯ-te.
The Tangut pair *Cʌ-tek ~ *Sɯ-te is reminscent of Matisoff's Proto-Lolo-Burmese *C-tik ~ *ti 'one' (as listed in Schuessler 2007: 614). Can a *tVk ~ *tV alternation be reconstructed at the Proto-Sino-Tibetan level?
I don't know of any Chinese *tV 'one' words, but I can think of other potential cognates for 正 OC *teŋ and 隻 OC *tek (glosses from Karlgren 1957):
特 *dək < *Nʌ-tək 'single, only one, only' and by extension, 'mate' (i.e., one of two) and in later Chinese, 'special' (i.e., singular)
犆 *dək < *Nʌ-tək 'single' (variant spelling of 特 in the sense 'single')
直*drək < *N(ɯ)-r-tək 'simply, only'
*N- conditioned voicing of root-initial *t-Presyllabic vowels conditioned emphasis (underlining) if they were low (*ʌ) or nonemphasis (no underlining) if they were high (*ɯ).
職 *tək 'simply, only'
正, 特, and 直 can also mean 'straight' and Karlgren (1957: 242) linked 'straight' to 'simply' via an intermediate stage 'straight out'. I wonder if the development was in the other direction
'one' > 'simple' > 'straight'
or if 'one' and 'straight' are ancient unrelated homophones.
*9.18.00:22: 正 Old Chinese *teŋ 'first (month)' developed into Middle Chinese *tɕieŋh and Tangut period NW Chinese *tʃɨẽ. Either of the latter is a likely source for
2105 1tʃɨõ 'first (month)'
in spite of the mismatching vowels (MC/TPNWC *e and Tangut o) which I can't explain. Did an original *e change to o via ablaut in Tangut? If 2105 is from 正, then 2105 1tʃɨõ and 0100 1lew 'one' could be distant relatives even though they don't share a single segment.
**9.18.12:45: Sagart (1999: 132) "personally heard" "a weak -ʰ coda in isolation" in the Xiaoyi descendants of Middle Chinese *-h words. Xiaoyi has "a glottal break in the middle of the syllable" in its descendants of MC *-ʔ words.
***9.18.18:05: Here's how I think *-k(-C) clusters might have developed between very early Chinese and MC:
*-k > *-k
*-k-P(V) > *-wk or *-p ~ *-k
Pulleyblank (1991: 51) drew my attention to the unusual phonetic series suggesting
立 MC *lip < OC *rəp 'to stand'
cognate to Tangut
1jaʳ < *rja 'to stand'
翌翊 MC *jɨk < OC *lək < ?*ləkʷ < ??*lək-p(V) or ??*ləp-k(V) 'next'
昱煜 MC *juk < OC *luk < ?*P(ɯ)-ləkʷ < ??*P(ɯ)-lək-p(V) or ??*P(ɯ)-ləp-k(V) 'bright'
煜 MC *jip < OC *ləp < ?*ləkʷ < ??*lək-p(V) or ??*ləp-k(V) 'bright'
Perhaps no suffix was involved. *-p could have dissimilated to *-k following one or more labial segments: e.g.,
翌翊 *Pɯ-ləp > *Pɯ-lək > *ləkAre there any other word families or phonetic series with MC *-wk or *-p ~ *-k alternations?昱煜 *P-ləp > *wləp > *lwəp > *lwək > *luk
煜 *ləp (bare root; no labial preceded *-p, so *-p did not dissimilate)
*-k-T(V) > *-k (cf. my pronunciation of fact as [fæk])
*-k-s(V) > *-h
*-k-N(V) > *-ŋ*-k-K(V) > *-ke.g., 隻 OC *tek 'single' and 正 OC *teŋ < *-k-N(V) 'first (month)'
No way to determine whether an MC *-k is from original *-k or suffixed *-k-K(V).
*-k-Q(V) > *-ʔ
This would account for *-k ~ *-ʔ alternations such as
格 OC *krak 'to arrive' : 假 OC *kraʔ < ?*krak-Q(V) 'to go to'
(example from Schuessler 2007: 68)
but it's also possible that the root was *kra:
*krak < *kra-k
*kraʔ < *kra (with automatic *-ʔ after a short vowel) or *kra-ʔ
9.18.18:21: ADDENDUM: Another numeral root with *-k ~ non-*-k variation is 'hundred':
百 Old Chinese *prak
Written Tibetan brgya < ?*prja
It's possible that Chinese once had *-j- in 'hundred', but there is no evidence for it within Chinese, and there is no evidence for a *-k-less root in Chinese. My guess is that the Proto-Sino-Tibetan word was *rja. This bare root acquired various affixes (*p-, *-k) in Tibetan and Chinese. Medial *-j- was lost in OC emphatic syllables.
Tangut
2jiʳ < *Ci-rja-H 'hundred'
may have had a prefix *Ci- (*pi-, shortened to *p- in Tibetan and Chinese?) conditioning full vowel raising and fronting (*a > i) and a suffix *-H conditioning the rising tone. Root-initial *-r- might have lenited to zero between a vowel and a glide.
11.9.16.23:33: A *DUGH-BIOUS RECONSTRUCTION
The section on etymology in the Wikipedia article on 德 de 'virtue' got me thinking ...
Peter A. Boodberg's analysis of 德 is still compatible with my Old Chinese (OC) reconstruction:
德 OC *Cʌ-tək > *tək [tˁʌˁq] > MC *tək 'virtue'
low vowel presyllable needed to account for 'emphasis' (underlining; phonetically pharygealization and vowel lowering)
cognate to 得 OC *Cʌ-tək > *tək [tˁʌˁq] > MC *tək 'to get'
9.17.1:09: Vietnamese được 'get' < *dɨək is presumably borrowed from a southern variant of 得 from OC *Nɯ-Cək with a nasal-initial, high-voweled presyllable to condition root-initial voicing and root vowel raising.
phonetic (and cognate?) 直 OC *N(ɯ)-r-tək > *N-trək > *Ndrək > *drək > *ɖɨək 'straight'
*N- needed to derive voiced MC initial from voiceless OC root initial *t-
high vowel presyllable or vowelless presyllable needed to prevent 'emphasis' and to condition root vowel raising
*r- needed to derive retroflex MC initial from dental OC root initial *t-
I wonder if these *T-k words may be cognate to *t-ŋ words (glosses from Schuessler 2007):
征 OC *teŋ 'to march on/against, campaign' < 'to target, to make straight for' (Schuessler 2007: 612)
的 OC *t-lekʷ 'target' cannot be cognate since its root has initial *l- and final *-kʷ
正 OC *teŋs 'straight, correct'
整 OC *teŋʔ 'orderly; to arrange, dispose'
貞 OC *r-teŋ 'to test, try out, correct, verify'
證 OC *təŋs 'to testify, prove'
and perhaps 眞 OC *tin 'true' if it is from an even earlier *tiŋ (cf. Kachin teŋ 'true'), but there is no Chinese-internal evidence for final *-ŋ
The final *-ŋ of those words could be from an earlier *k-N(V).
Victor H. Mair's reconstruction *dugh for 德 has several problems:
- there is no evidence for a voiced initial *d-
- 德 rhymes with *-ək words, not *-uk (= Mair's *-ugh?) words
- there is no Chinese-internal evidence for *-gh
He proposed that his OC *dugh was cognate to Proto-Indo-European *dugh, but the actual PIE root has initial *dh-.If the PIE root had initial *d-, its English derivative doughty would have been *toughty:
PIE *d > Proto-Germanic *t > English t
PIE *dh > Proto-Germanic *d > English d
Edwin G. Pulleyblank (1991: 50) reconstructed the OC rhyme of 德 'virtue' and 得 'to get' as *-əkʷ and proposed that they are cognate to Written Tibetan thub 'a mighty one, one having power and authority'* (i.e., one with virtue? one who gets what he wants?). I am skeptical because I know of no Chinese-internal evidence for *-kʷ in those words. I also don't know the semantic history of thub.
*9.17.1:24: Pulleyblank probably got the gloss from Jäschke's entry for thub-pa, whose root is thub. thub-pa is also 'to be able' which is reminiscent of the use of 得 and Vietnamese được 'get' for 'to be able'. Did 'to get' independently become 'to be able' in both Chinese and Tibetan, losing its original meaning in the former?
11.9.15.23:54: ALL MINUS FIVE EQUALS COME
In my last entry, I listed two tangraphic components used as abbreviations in character construction formulae from edition C of the Combined Homophones-Tangraphic Sea. Here's a third:
1602 2ŋõʳ < ?*rŋoNH 'all'
<
The deleted left-hand component
0036 2gəuu
was used to transcribe Chinese 五 'five' (though it resembles Tangut
4602 1jaʳ 'eight'!).
Nishida (1966: 243) glossed the right-hand component of 'all'
as 'come', presumably because it appears in
3456 1lia 'to come, fall' (but normally l- is followed by -ɨ-, not -i-!*)
(why is 'not' on its left?)
2373 2liẹ < ?*si-leH 'to come, arrive'
(why is 'person' on its right?)
4106 1liə 'to come, arrive' (only in dictionaries?**)
4307 1riaʳ 'to come, invite'(why is 'wood' on its top?)
(written like 4106 but with the bottom elements reversed)
which are mostly members of a l- 'come' word family***.
I am not comfortable with the reconstruction -õʳ for the rhyme because nasalized retroflex vowels are so rare. Maybe Gong's -oʳw or Arakawa's -ooʳ are preferable.
Example of abbreviated 'all': line 1, entry 3:
 3507 1pho 'to splash, to pour' |
1638 1gi 'clear, unmixed' |
3485 1lạ 'hand, arm' |
'right' |
'all' |
Fully written out:
In short:
Nishida (1966: 245) identified the right side of 'clear' (alphacode: yee) as 'eye', presumably because it appears in
+
3362 1kaaʳ 'eye' (with 'person' on the left)
4952 1tʃhɨii (first half of 1tʃhɨii 1kɔ̣ 'to observe'; with 'horned hat' [signifying verbs?] on top)
5324 1khioo 'to open eyes' (with 'evil' on the right - hence Grinstead's gloss 'evil eye' absent from Li Fanwen 2008: 839)
5593 1bioo 'to observe'
5614 1lwəụ 'to cry' (with 'water' on the right)
so 'to splash' looks like 'hand' (the means of splashing) plus ... 'eye'? Although it's convenient to call the component yee 'eye', I doubt it represents 'eye' in 'clear', 'splash' or
=
+
3494 1dziẹ 'muddy, turbid' = 'not' + 'clear'
*9.16.4:51: I would expect this kind of anomaly in Lhwe vocabulary, but 3456 1lia is a Mi word. Perhaps this very common word is an archaism preserving a *li that has generally merged with *lɨ elsewhere.
I have reconstructed 4106 1liə and 2373 2liẹ with -i- to match 3456, though perhaps they should be reconstructed with -ɨ-. Their rhymes have no /ɨ/ : /i/ distinction.**9.16.4:59: Is 4106 1liə the Lhwe cognate of 3456 1lia? If 4106 is a Mi word, why doesn't Li Fanwen (2008: 660) list any examples outside dictionaries? In other words, what made it unsuitable for translations of lay and Buddhist texts?
***9.16.5:16: The l-words to come have the same initial as Mandarin 來 lai 'to come' but cannot be cognates since the latter is from Old Chinese *mʌ-rə without an *l-. However, OC *mʌ-rə might be cognate to 4307 1riaʳ.
11.9.14.23:36: A MOUSY MYSTERY
Thanks to Andrew West, I got my first glimpse of the Combined Homophones-Tangraphic Sea. The first entry on the only (?) surviving page of edition C of that Tangut dictionary is
The strokes blend into a complex black mass resembling some exotic ancient arthropod or ostracoderm. The body of the entry presumably corresponds to the definition in the noncombined Tangraphic Sea. Some components in the two texts match. I can make out the top five characters with the help of the noncombined Tangraphic Sea:
 |
||
There are two strange things about this entry.
First, I've never seen dependent Tangut character components* written in isolation in an original Tangut text, as opposed to the writings of Tangutologists. These two components seem to be abbreviations:
<
2biẹ 'right side of a tangraph'
1pha 'left side of a tangraph'
<
Fully written out, the five tangraphs are
(first half of 1pæ 2no 'mouse') = left of 1ʃwʌ 'mouse' + right of 1xwɨi 'mouse'
Notice anything odd?
Second, that formula differs from the formula in the noncombined Tangraphic Sea:
(first half of 1pæ 2no 'mouse') = right of 1ʃwʌ 'mouse' + right of 1xwɨi 'mouse'
Is 'left' in the Combined Homophones-Tangraphic Sea an error for 'right'?
*9.15.3:21: Independent Tangut character components can also function as standalone tangraphs: e.g., the left side of 1pæ can stand by itself as
1kie 'insect'
whereas dependent Tangut character components like
normally cannot stand alone and have no readings.
ADDENDUM: Why so many mice?
Li Fanwen (2008: 1083) lists eight tangraphs glossed as 鼠 'mouse, rat'. Let's look at the three I have mentioned so far.
1pæ 2no 'mouse'
has only been seen in dictionaries and may be a Lhwe word.
The second syllable 2no < *noH is vaguely like *hnaʔ, one possible reconstruction of the Old Chinese reading of 鼠 'mouse', but the rhyme correspondence is irregular. This is an unusual case of a Lhwe word with a potential non-Tangut cognate that may lack a Mi cognate.

1ʃwʌ 'mouse'
may be a borrowing of Middle Chinese 鼠 *ɕɨəʔ or Tangut period NW Chinese 鼠 *ʃɨu, but the rhymes don't match. The left-hand component 'grass' may indicate that a 1ʃwʌ was a grass mouse.
1xwɨi 'mouse'
was defined as a 1ʃwʌ 'mouse' in Tangraphic Sea, but in texts it refers to the rat of the twelve Earthly Branches. Its derivation is circular:
=
+
1xwɨi was transcribed with 攜 *xwi in the Pearl but was listed in the section of Homophones for syllables with labiodental initials (i.e., v-). Perhaps the word had initial hw- or hv- in the Pearl dialect but had initial hv- or even f- in the Homophones dialect. (Its Arakawa-style reconstruction is fii in Kotaka's online Golden Guide.) The Grade III rhyme -ɨi of 1xwɨi implies a preceding labiodental because it normally follows the labiodental initial v-, not x(w)-.
11.9.13.23:59: REVISITING THE TANGUT RITUAL LANGUAGE 13: THE FAST AND THE FUSIONAL
Yesterday I found WY Peggy Wong's "Investigating the Prosody of Cantonese: Syllable Fusion and Speech Rate in Hong Kong Cantonese". Examples like
乜嘢 'what': mɐt jɛɛ > mii ɛɛ > mɛɛ
made me wonder if conscious fusion could have been used as a technique for creating Lhwe (ritual language or argot?) words. Just as fusion "can produce sequences that violateCantonese phonological structure constraints," fusion (of kennings?) could have produced Tangut sequences like 1bɨu that violated Tangut phonological structure constraints.
Perhaps Lhwe word creation techniques could have involved non-Tangut languages like Chinese or even Tibetan. Mary Haas (1957) described
the Rhyming Translation Game [...] in which each successive Thai word must rhyme with the English translation of the preceding word.
Could Lhwe be a form of bilingual rhyming slang?
I don't have access to that article beyond its first page, so I rely on Matisoff's (1996) account of another word game from it:
speakers intentionally mutilate the phonological structure of dissyllabic collocations for comic effect, often by a kind of spoonerism whereby the initial consonants remain intact while the vowels and tones of the syllables get switched [...] This word-play is actually of great interest, in terms of figuring out how native speakers parse the elements of their syllables.
Tangut syllables are full of elements that could be altered in word games:
| Initial p- ph- b- m- v- t- th- d- n- ts- tsh- dz- s- tʃ- tʃh- dʒ- ʃ- k- kh- g- ŋ- ʔ- x- ɣ- j- l- lh- r- z- ʒ- |
Rhyme | |||||
| Grade I: mid II: low III: high nonpalatal IV: high palatal |
Vowel: u i a ə e o |
Vowel length: short long |
Vowel quality: lax (V) tense (Ṿ) retroflex (Vʳ) |
Nasality (Ṽ) or final -w (mutually exclusive) |
Tone: 1 (level) 2 (rising) |
|
Not all combinations are possible: e.g., there are no long tense vowels.
I have already mentioned possible cases of tonal flipflop (Mi 2 > Lhwe 1). Was tonal flipflop merely the tip of a iceberg of word-disguising methods?
Next: Retreating from the Ritual Language
11.9.12.23:48: REVISITING THE TANGUT RITUAL LANGUAGE 12: FOUR, SEVEN : NINE, TEN ... OR FIVE?
Andrew West pointed out that 'fourth' (son) and 'seventh' (son) were both 1ŋwəʳ:
At first, I thought that 1ŋwəʳ was like the де- that would result if one truncated Russian девять 'nine' and десять 'ten'. However, 'fourth' and 'seventh' were might have been derived from disyllabic Lhwe numerals using two different methods:
Filial ordinals of Lhwe even numerals are the second syllables of those numerals: e.g.,
<
4934 1ŋwəʳ 'fourth' (son) < 1341 4362 1kwe 1ŋwəʳ 'four'
Filial ordinals of Lhwe odd numerals are the first syllables of those numerals: e.g.,
<
1423 1ŋwəʳ 'seventh' (son) < 0332 1347 1ŋwəʳ 1kạ 'seven'
See Andrew's "Month Numbers and Son Numbers" table for other numerals.
Note that second is an even ordinal and first is an odd ordinal. This pattern looks artificial to me, like something concocted for the argot that David Boxenhorn hypothesized. But why would argot numerals be used in Buddhist terminology like

4344 4730 2lheʳ 2ʔəuʳ 'Tripitaka' (lit. 'Three Storehouses')
1783 4783 4871 2tʃɨəʳ 2niʳ 1ŋəʳ 'Wutaishan' (lit. 'Five Platform Mountain')
I have been thinking that those words were coined by Lhwe speakers using shortened versions of their regular numerals. Or maybe those monosyllables were their regular numerals. Andrew thought that the disyllabic numerals
In part 11, I proposed thatwould seem to be expansions of the simple monosyllabic numbers. Quite why or how the single syllable numbers have been expanded to two syllables is unclear; except for the first character of the disyllabic word for "two" (L0795 rjɨr), all the other halves of the disyllabic numbers (L5565 gju, L1341 kwej, L1615 lu, L3849 źjiw, L1347 kạ) are bound characters and do not seem to occur by themselves or in combination with any other character anywhere else.
3849 1ʒiw [the second half of the disyllabic word for 'six'] looks like it may be from the Mi word [for 'six'] with a prefix that conditioned lenition:
and in part 1 of "Two Many Words", I wrote,
I am tempted to derive 2lọ [the second half of the disyllabic word for 'two'] from Tangut period northwestern Chinese 兩 *lɨõ 'both' which was transcribed in Tibetan as lyong in the pre-Tangut period.
but the latter etymology has phonological problems and in any case, the other halves of the disyllabic numerals do not resemble Mi or Chinese numerals (which are generally cognate to each other) with a few exceptions:
1ŋwəʳ 'fourth' (son), 2nd half of 'four', 'seventh' (son), first half of 'seven'
sound like the Mi numeral
1999 1ŋwə 'five'
̣(cognate to Written Tibetan lnga and Old Chinese a, both 'five')
with retroflexion that might have been added in a word game.
One might think then that
1341 4362 1kwe 1ŋwəʳ 'four'
0332 1347 1ŋwəʳ 1kạ 'seven'
are literally something like 'reduced five' (i.e., 'five minus one') and 'augmented five' (i.e., 'five plus two') but 1kwe and 1kạ are not homophonous with anything like 'reduced', 'five', 'augmented', or 'two'.
Homophones of the bound half of Lhwe 'four'
| Li Fanwen 2008 # | Reading | Downes gloss |
| 0560 | 1kwe | insect name |
| 1248 | grave, tomb | |
| 1342 | to pound to pieces | |
| 1735 | respectful | |
| 1749 | hoof |
Homophones of the bound half of Lhwe 'seven'
| Li Fanwen 2008 # | Reading | Downes gloss |
| 3614 | 1kạ | life |
| 5313 | to pull up, drag | |
| 5460 | to supervise | |
| 5676 | to hold, grip, grasp | |
| 5678 | tail, end, east |
'grave' > 'death' > 'four' (which sounds like 'death' in Chinese)
but maybe I need to cast a wider net. The Mi sources of 1kwe and 1kạ could have had initials or rhymes.
Maybe 1ŋwəʳ 'seven' has nothing to do with 1ŋwə 'five'. Its graphs is derived from the graph of its homophone 0257 'blue'. Did the Tangut associate numerals with colors?
Next: The Fast and the Fusional
11.9.11.23:59: REVISITING THE TANGUT RITUAL LANGUAGE 11: BROTHER DRUID
It occurred to me that the Golden Guide - which I have yet to finish translating - could be treated as an introduction to Mi rather than to Tangut (= Mi + Lhwe) in general.
The seventh tangraph in the Guide is the Mi word
2814 2lhị 'moon'
but its Lhwe equivalent
1846 0863 1ka 1ʔo 'moon'
doesn't appear in the Guide. The Guide is thus not like the Vietnamese primer 五千字 Ngũ thiên tự (Five Thousand Characters) whose second section begins with
月𩈘𦝄
Nguyệt mặt trăng
which tells us Sino-Vietnamese nguyệt 'moon' is equivalent to indigenous Vietnamese mặt trăng 'moon'.
Did the readers of the Guide already know the Lhwe graphs for 'moon' before learning the Mi graph? Were they like Koreans in pre-hangul Korea who studied the Thousand Character Classic written entirely in Classical Chinese? Or premodern Cantonese speakers who studied that very same text while knowing Cantonese characters absent from it? (OTOH, did any Cantonese speakers actually learn Cantonese 唔 'not' before its literary equivalent 不?) These comparisons are flawed because neither Korean nor Cantonese were ever treated as equal to a literary language in a premodern lexicon.
The Mi word for 'mother'
=
+
0092 1miaa = 2mie 'mother' (only in dictionaries? Lhwe?) + 2la 'maternal aunt' (Mi)
appears in line 113 of the Guide (which I haven't gotten to yet), though its possible Lhwe equivalent
4905 0003 2riaʳ 2si 'mother'
does not. 4905 0003 is interesting for two reasons.
First, 0003 (influenced by Chinese 母 'mother"?) is a Lhwe basic element that occurs in the Mi tangraphs like 'maternal aunt' and
0243 2si 'daughter-in-law' (homophonous with 0003; left side resembles Chn 女 'woman' which is also in
1232 2məi (first half of 2məi 2nie 'younger sister'; < Chn 妹?; only in dictionaries - could Lhwe contain Chinese loanwords, or are such words neither Lhwe nor Mi?)
1674 2nie (second half of 2məi 2nie 'younger sister')
0466 1vɨe 'to have' (why does this look like 'mother' + 2ʃɨẽ ' 'sage'?)
0467 1ziə̣ 'maiden name' (looks like 'mother' + 'person')
2067 2si 'the surname Si' (in line 56 of the Guide - a Mi surname? The Guide includes Chinese surnames. Does it also include Lhwe surnames?)
5162 1miə (second half of 0092 5162 1miaa 1miə 'mother')
Second, 4905 shares 4905 with
3671 4905 1nie 2riaʳ 'father'
(with 4905 as the second syllable, not the first!)
which may be the Lhwe equivalent of the Mi word 5049 1vɨa whose Tangraphic Sea analysis contains 3671:
=
+
+
5049 = 5031 1bə 'patriarch of the black-headed' + 2544 'sage'+ 3671 (first half of Lhwe 'father')
The inclusion of 5031 in a Mi graph implies that the Mi were the black-headed Tangut as opposed to the red-faced Tangut who would then be the Lhwe by process of elimination. (But what if the categories of Mi and Lhwe did not correlate with the categories 'black-headed' and 'red-faced'?)
The analysis of 3671 is unknown, but I wouldn't be surprised if it were derived from 5049. If that's the case, at least one analysis would have to be wrong. For the many functions of the left side of 3671
(3087 1dʒɨw 'waist' as an independent tangraph)
see Andrew West's "Untangling the Web of Characters".
Two of the above tangraphs
'to have' and 'father' (both Mi)
contain 'sage' like the second graph of the Lhwe (?) term for 'brother(s?)'
0012 5873 1bɨu 2kəụ
which looks like a combination of 2phəu 'tree' (why?) and 2ʃɨẽ 'sage' (why?):
=
+
'Tree-sage' makes me think of druids, literally 'oak-knowers'. What do trees and sages have to do with brothers? 'Tree' turns out to be an abbreviation of a Mi phonetic 2kəu 'to tie' (looks like 'tree' + line + 'person') plus 1ɣwɪ 'power' (why?; looks like 'hand' + 'sage'):
+
Is one powerfully bound to one's brothers?
The first graph of Lhwe 'brother(s?)' is derived from Mi 1miaa 'mother' plus Mi 1bɨu 'intelligent' (phonetic):
=
Why are male children associated with their female parents?
The Mi equivalent of Lhwe 'brothers'
2447 0605 2lɨo 2tiọ 'older and younger brother'
do not appear in the Guide. 2447 and 0605 contain similar elements in different orders.
The analysis of 2447 is unknown. 0605 was derived from 2447 plus 0607 1miəʳ 'people, tribe, scholar' (cognate with Mi and Written Tibetan mi 'person'?; there's 'sage' again, also used to write 'Mi'!):
=
+
2447 0605 is used to define 4934 1ŋwəʳ 'fourth' and 3649 1vəi 'sixth' (before 'son')
which are based on the Lhwe numerals
1341 4362 1kwe 1ŋwəʳ 'four'
3849 5081 1ʒiw 1vəi 'six'*
Are the words for the order of sons Lhwe-based borrowings in Mi or only in Lhwe? In any case, they are defined in terms of Mi.
Tangraphic Sea definitions generally have the formula
X
Y
X 3583 1tia Y 5285 1lɨə = 'as for X, it is Y'
Was there a Lhwe equivalent of 5285, or did Lhwe have a zero (present tense) copula like Russian?
Next: Four, Seven : Nine, Ten ... or Five?
*9.12.00:45: 3849 1ʒiw has an unusual combination of a Grade III initial 1ʒ- with a grade IV final -iw. Is this combination a trait of Lhwe phonology absent from Mi phonology? No, because the Mi word
3200 1tʃhiw 'six' (cognate to Written Tibetan drug 'six')
also has that unusual combination. Maybe that final wasn't grade IV after all.
3849 1ʒiw looks like it may be from the Mi word with a prefix that conditioned lenition:
*Cɯ-tʃhiw > *Cɯ-dʒiw > *Cɯ-ʒiw > *1ʒiw
But other Lhwe numeral syllables do not sound like Mi numerals with lenited initials, though there is a different kind of similarity between Lhwe and Mi numerals that I'll mention in part 12.
5081, the graph for the second syllable of Lhwe 'six', was analyzed as 1vəi 'to realize' (phonetic) plus ... Mi 1ŋwə 'five'!?
=
+
We'll see even more of Mi for 'five' next time.
Is it a coincidence that 5286 resembles 5285 which can also mean 'one'? Is Lhwe 'six' an artificial word derived from
- an altered form of Mi 'six' plus
- a word whose graph resembles 'one'; writing the left side of that graph next to the right side of 'five' reminds the reader that 1 + 5 = 6
3649 'sixth' is derived from the graphs of two homophones, 1vəi 'daybreak' and the second half of 1ʒiw 1vəi:
=
+