Home
15.3.28:23:59:
WORKING ON KHITAN AND JURCHEN DUKES AND PRINCES
To Chinese eyes, the Khitan large script at first appears to be a random
mix of Chinese characters and alien shapes.
Given that the Khitan large script is said to have been 'invented'
c. 920 using the Chinese script as a model, one might expect it to be
something like the modern Japanese script in which Chinese
loans are generally written with Chinese characters and kana almost
always represent non-Chinese words*:
Khitan large script characters resembling Chinese characters :
Chinese loanwords
Khitan large script characters not resembling Chinese characters :
native Khitan words
However, the reality is more complex:
Khitan large script characters resembling Chinese characters :
Chinese loanwords
e.g., 皇帝 (looks like Liao Chinese *hongdi 'emperor')
for Khitan hongdi 'id.'
and native Khitan words
e.g., 五 (looks like Liao Chinese *ngu 'five') for
Khitan tau 'id.'
Khitan large script characters not resembling Chinese characters :
native Khitan (or at least non-Chinese**)
words
e.g.,  doro (?) 'seal'
doro (?) 'seal'
and Chinese loanwords
e.g.,  gün 'army' for Liao Chinese 軍 *gün
'id.'
gün 'army' for Liao Chinese 軍 *gün
'id.'
One could also hypothesize that Chinese character lookalikes were
used to write Khitan syllables that had (near-)homophones in Chinese,
whereas nonlookalikes were used to write non-Chinese Khitan syllables
and words with un-Chinese segments and phonotactics: e.g., Khitan iri
'name' with an un-Liao Chinese -r-.
But in fact, syllables shared by Khitan and Chinese were sometimes
written with nonlookalikes:
e.g.,  for ai (why not write it with a
lookalike of Liao Chinese *ai-graphs like 愛?)
for ai (why not write it with a
lookalike of Liao Chinese *ai-graphs like 愛?)
And syllables and words with un-Chinese elements were sometimes
written with lookalikes:
e.g., 午 (looks like Liao Chinese *ngu 'horse
(calendrical)') for Khitan iri 'name'
Did the creator(s) of the Khitan large script take the Chinese
script as used in the early 10th century, keep random characters,
change the sound values of some of them, and then make up new
characters?
One might come up with such an explanation for Cyrillic: its
inventors took the Latin alphabet, kept some letters (e.g., А), changed
the sound values of some of them (e.g., В for [v] instead of [b]), and
then made up new characters (e.g., Б for [b] and Г for [g]). However,
that is not what what happened. Both the Cyrillic and Latin alphabets
are derived from the Greek alphabet. They are sisters, not daughter and
mother.
If Janhunen (1994, 1996) is correct, the Khitan large script is to
the Chinese script what Cyrillic is to Latin. Like Cyrillic, the Khitan
large script was not invented on the spot; it was an adaptation of an
existing script: the Parhae script, a Manchurian offshoot of the early
Chinese script. The following seven Khitan large script characters
might then be inherited from the Parhae script rather than taken from
the 10th century Chinese script:
| Sinograph
|
Liao/Jin Chinese |
Khitan large script
|
Khitan
|
Jurchen large script
|
Jurchen
|
| 何 |
*ho (< Middle Chinese *ɣɑ) |
 |
ha
|
   |
ha
|
| 舍 |
*she (< Middle Chinese *ɕjæˀ) |
  |
?
|
 |
sha
|
| 先 |
*sien (< Old Chinese *sˁir
< *sˁər) |
 |
?
|
 |
shira or shïra
|
| 工 |
*gung
|
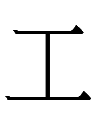
|
?
|
(no similar Jurchen character)
|
(*gung***)
|
| 公 |
 |
gung
|
 |
gung
|
| 王 |
*ong (< Old Chinese *ɢʷaŋ)
|
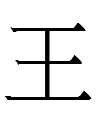 |
ong
|
  |
ong
|
Janhunen then proposed that the Jurchen large script was another
derivative of the Parhae script rather than a direct successor of the
Khitan large script.
Let's suppose the conventional wisdom is correct and that the
Jurchen large script was invented c. 1120 with the then-current Chinese
script as a model. Why was Jin Chinese 公 *gung 'duke' written
with Jurchen 王, a lookalike of the characters for Jin Chinese *ong
'prince' and Khitan ong 'prince'?
Jin Guangping and Jin Qizong (1980: 56) proposed that Jurchen 王 gung
was derived from Jin Chinese 工 *gung 'work' with an added
stroke. Why not just copy 公 or 工?
Here is a wild speculation. In Old
Chinese, 王 was pronounced *ɢʷaŋ. In mainstream Chinese *ɢʷ-
weakened to *w-, and later, *waŋ became -ong in
the northeast. What if a now long-extinct Manchurian Chinese dialect
retained a stop initial for 王? Then perhaps 王 had two readings in
Parhae, *gung based on the colloquial stratum of Manchurian
Chinese, and *ong based on a literary stratum borrowed from
mainstream Chinese. The first reading is the source of the Jurchen
reading and the second is the source of the Khitan reading.
3.29.0:34: I am skeptical of the stop-retention scenario because
there is no other evidence for *ɢʷ- surviving as a stop at such
a late date in the northeast or anywhere else. Nor is there any
evidence for *-ʷaŋ becoming *-ung in the
northeast.
3.29.0:46: The Jurchen characters
for ong resemble those for ja (see my previous entry)


with two extra strokes on top.
However, Jin Qizong (1984: 236) regarded the ong-graphs as
derivatives of the Khitan small script character
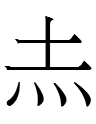
071 <ong>.
How would Janhunen explain that resemblance? Do the Jurchen large
script and Khitan small script characters both go back to a Parhae
prototype? Could the Jurchen character retain a 'roof' lost in the
Khitan small script character?
*3.29.0:57: Although there is a strong
tendency to write Chinese loans with Chinese characters in Japanese,
some Chinese loans are in kana: e.g., サンゴ sango 'coral'
(instead of 珊瑚).
Furthermore, Chinese characters do not always represent Chinese
loans. In many cases they represent native Japanese words: e.g., 薔薇 for
bara 'rose' as well as the much rarer borrowings shōbi
and sōbi.
**3.29.1:01: Not all non-Chinese words in
Khitan are native: e.g.,
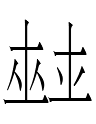
053-051 <qa.gha> 'qaghan'.
may ultimately be of Xiongnu origin. (Has this word been identified
in the large script?)
***3.29.1:14: Jin Qizong read two different
Jurchen characters

as gung (in my notation), so in theory either could have
transcribed Jin Chinese 工 *gung 'work'.
However, the second is only attested as a transcription of 宮
'palace' which was transcribed as

334-019-345 <g.iu.ung>
in
Khitan.
So I suspect that the two Jurchen characters originally represented
two different syllables, gung and giung, that merged
into gung in the Yuan Dynasty Old Mandarin dialect of the Zhongyuan
yinyun but not Phags-pa Chinese where they are still distinct as
ꡂꡟꡃ <g.u.ng> and ꡂꡦꡟꡃ <g.ee.u.ng>.
15.3.27:23:57:
THE UN-*SˁƏR-TAIN ORIGIN OF THE JURCHEN SCRIPT
When I first became interested in Jurchen, I assumed that its
(large) script was "obviously derived from the Chinese script and the
Khitan large script, with many innovations of its own" (Kane 1989: 21).
Then I discovered Janhunen's (1994: 114) hypothesis which I still
regard as plausible after almost twenty years:
It was the other Sinitic script [of Parhae] that, due to its
firm local [i.e., Manchurian] roots, was later transmitted
first to the Khitan, and then to the Jurchen. All of this means that
the conventional view, according to which the Jurchen script was
successive to the Khitan «large» script, cannot be correct. As graphic
systems, and heirs of the Bohai [= Parhae] script, the Khitan
and Jurchen «large» scripts should be viewed as parallel, rather than
successive developments.
There is much more to Janhunen's argument than that, but for now I
want to focus on one of its implications. If the Khitan and Jurchen
large scripts are offshoots of the Parhae script developed at some
point prior to the end of the Parhae state in 926, then the readings of
their Chinese-based elements are likely to reflect pre-10th century
Chinese phonology to some extent. Such a scenario has a precedent in
Old Japanese man'yōgana whose readings contain archaisms from
the Chinese learned by the Paekche centuries earlier: e.g.
支 for Old Japanese ki < *ki and *ke is
closer to Late Old Chinese *kie than Middle Chinese *tɕie
止 for Old Japanese tə is closer to Old Chinese *təʔ
than Middle Chinese *tɕɨəˀ
(But Gerald Mathias views 止 as a kungana whose reading
is based on Old Japanese töma- 'stop' [my təma-]; if
so, then the resemblance to Old Chinese is coincidental.)
富 for Old Japanese pə is closer to Late Old Chinese *puəh
than Middle Chinese *puʰ
Conversely, if the Khitan and Jurchen large scripts had no deeper
roots, the readings of their Chinese-based elements should be derivable
purely from Liao and Jin Chinese, as there would be no way for their
creators to know about earlier readings.
Jin Guangping and Jin Qizong (1980: 56-57), Kane (1989: 23), and Kiyose
(2004: 93) list Jurchen characters* with
readings as well as shapes of Chinese origin**:
| Jurchen |
Jurchen reading |
Sinograph |
Liao/Jin Chinese*** |
Middle Chinese |
Old Chinese |
  |
aci |
赤 |
*ci |
*tɕʰiek |
*tɯ-qʰjak |
 |
ging |
京 |
*ging |
*kɨeŋ |
*Cɯ-qraŋ or *qɯ-raŋ |
|
gung |
工 |
*gung |
*koŋ |
*koŋ |
  |
hi |
犀 |
*si |
*sej |
*sʌ-ləj |
  |
i |
于 |
*ü |
*u < *wuo |
*Cɯ-ɢʷa |
   |
i |
雨 |
*ü |
*u < *wuoˀ |
*Cɯ-waʔ |
|
ja |
志 |
*jr |
*tɕi < *tɕɨʰ |
*təs |
  |
ki |
其 |
*ki |
*gɨ |
*gə |
  |
ngu |
吳 |
*ngu |
*ŋo |
*ŋʷa |
 |
sa |
茶 |
*cha |
*ɖæ |
*rla |
 |
u |
五 |
*ngu |
*ŋoˀ |
*ŋaʔ |
 |
dai |
大 |
*da(i) |
*dɑjʰ |
*lats |
 |
fu < pu |
府 |
*fu |
*fu < *puoˀ |
*poʔ |
 |
jul |
朱 |
*ju |
*tɕu < *tɕuo
|
*Cɯ-to |
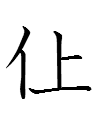  |
shang |
上 |
*shang |
*ɕɨaŋ < *dʑɨaŋˀ
|
*Cɯ-daŋʔ or *Nɯ-taŋʔ |
 |
tai |
太 |
*tai |
*tʰɑjʰ |
*l̥ats |
|
ha |
何 |
*ho |
*ɣɑ |
*ɢaj |
|
sha |
舍 |
*she |
*ɕjæˀ |
*l̥jaʔ |
| |
shira (Kiyose) or shïra (Jin and
Jin) |
先 |
*sien |
*sen |
*sˁir < *sˁər
< *Cʌ-sər |
Out of that incomplete sample of nineteen characters,
- eleven have readings based on Liao/Jin Chinese (green)
- five have readings that could be based on either Liao/Jin
Chinese or Middle Chinese (bluish green)
- two have readings that resemble Middle Chinese (blue)
- at least one has a reading that resembles Old Chinese (yellow)
I'll discuss a less likely instance in my next
entry.
The last three characters (which all have have Khitan large script
predecessors that look exactly like Chinese 何舍先) are hardly solid proof
for Janhunen's
hypothesis.
The Khitan and Jurchen may have used Liao/Jin Chinese 何 *ho
for ha in their languages because there may not have been a
character for *ha in Liao/Jin Chinese. (The only character read
ha in the Phags-pa Chinese of the Yuan Dynasty is rare: 閜.)
Nonetheless the other two are difficult to explain if they were
devised c. 1120 or perhaps even c. 920. Why write Jurchen sha
with a derivative of Jin
Chinese 舍 *she when Jin Chinese 沙 *sha was a closer
phonetic
match? And is the close match of Jurchen shira ~ shïra
and Old Chinese *sˁir
< *sˁər just a coincidence?
*3.28.2:50: Since this post does not deal with
the Jurchen small script, I will refer to Jurchen large script
characters simply as Jurchen characters.
**3.28.2:58: There are Jurchen characters with
shapes of Chinese origin and native readings that are translations of
Chinese: e.g.,
 ~
~
looks like Jin Chinese 一 *i 'one' but represented the native
Jurchen word emu 'one'.
***3.28.3:15: I wrote Liao/Jin Chinese forms in an
orthography resembling my transcriptions of Khitan and Jurchen to
facilitate comparison. Khitan and Jurchen voiced obstruents may have
been unaspirated and voiceless: e.g., Jurchen jul may have been
[tɕul], a close match for Middle Chinese 朱 *tɕu(o).
15.3.26:23:49:
QUINTUP-<UL> TROUBLE (PART 3)
In part 1, I proposed that
Khitan
small script character

366
might have
represented <ül> because

131-366 <u.?> 'winter'
corresponds to Written Mongolian ebül 'id.'
In a generic 'Altaic' language, harmonic rules prevent the mixture
of segments from two classes which I will call A and B*:
e.g.,
| A |
B |
| a, u, ł, ɣ ... |
e, ü, l, g ... |
'Neutral' segments can occur with segments of either class A or B.
Hence <ül> should be a class B character that should only
co-occur with class B and/or neutral characters within a Khitan small
script word block.
I used to think that
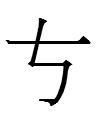

098 and 261
represented class A <ał> and class B <(e)l>, but in fact
they not only coexist with each other but even with 366 in

340-098-366-261-349-021
<x.ał.ül.el.ge.mó>** (興宗 26.6)
(021 <mó> looks like an error for the dotless verb ending
020 <ei>)
which is unexpected from an 'Altaic' perspective. I would have
expected
* *
*
class A *130-098-206-098-051-122
<x.ał.uł.ał.ɣa.ai>***
or class B *340-261-366-261-349-020 <x.el.ül.el.ge.ei>.
366 can also coexist with both class A 051 <ɣa> and class B
349 <ge> in the same text (道宗):
 (*
(* )
)
161-366-261-051-189-123 <aú.ül.el.ɣa.a.ar> (道宗 12.30)
(instead of 161-206-261-051-189-123 *<aú.uł.ał.ɣa.a.ar>)
and 131-097-372-366-334-140 <u.úr.û.ül.g.en> (道宗 18.6)
That would also be unusual for an 'Altaic' language.
I am conflicted.
On the one hand, Khitan has sets of suffixes implying the presence
of an 'Altaic'-style harmonic system: e.g., the causative-passive
suffixes (class A?) and (class B?) in the above pair of words.
On the other hand, there seem to be harmonic violations. Are those
violations artifacts of incorrect class assignments (e.g., is 366 a
neutral character?), or are they real and perhaps even predictable?
The earliest known small script text is dated 1053, over a century
after the invention of the small script c. 925. Do all small scripts
discovered so far reflect Khitan after its harmonic system began to
break down? Would the very first texts in the small script have more
harmonic spellings?
*3:27.2:13: I got the A/B terminology from EG
Pulleyblank who used it to describe Old Chinese syllable types. Norman
(1994) was the first to draw parallels between Old Chinese and Altaic
syllable types. I have gone even further and proposed harmony rules for
Old Chinese.
I use the terms A and B to avoid specifying the nature of the
classes: e.g., front vs. back, ±RTR, etc. As Khitan is in the
Manchurian linguistic area, I suspect it had RTR harmony like its
neighbor Jurchen.
**3.27.2:17: This is Andrew West's
reading. Qidan xiaozi yanjiu has

340-067-366-261-349-020 <x.eü.ül.el.ge.ei>
which is not only harmonic but also has the dotless verb ending 020
<ei> instead of dotted 021 <mó> which is not a verb ending.
I have not seen the handwritten copy of 興宗, and the original stele is
inaccessible, so I do not know who is correct.
***3.27.2:24: I assume 206 is a type A character
since it is flanked by a-characters in

029-206-189 <tau.uł.a> 'hare'.
15.3.25:23:59:
QUINTUP-<UL> TROUBLE (PART 2)
In part 1, I built upon Aisin Gioro's work
by equating the following five Khitan small script characters and
regarding the first three as variants of each other:
 =
= =
= =
=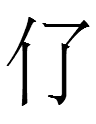 =
=
013 <ul> = 050 <ul> = 206 <ul> =
228
<ul> = 366 <ul>
The second and third appear in the same word:

050-131-206 <ul.u.ul> (道宗 16.21, 20.13 [1101 AD], 蕭仲恭 33.33
[1150 AD])
Did scribes of two different inscriptions nearly fifty years ago
apart really use two variants so close together in three instances, or
did 050 and 206 have two different readings?
3.26.1:10: Was 050-131-206 for ulul (?) above related to (or
at least partly homophonous with)


050-131-366-311-162 <ul.u.ul.b.c> (宣懿 18.2 [also 1101 AD])
050-131-366-311-222 <ul.u.ul.b.ń> (道宗10.25, 15.19, 28.24, 宣懿
17.11)
which have 366 instead of 206 for their second <ul>? Or did
206 and 366 have different readings?
15.3.24:23:24:
QUINTUP-<UL> TROUBLE (PART 1)
In my last entry, I proposed that the rare
Khitan small script character 013 might be a variant of 050 which Aisin
Gioro (2008) read as <ul>. Both in turn resemble 206 which Aisin
Gioro (2003) also read as <ul>. Could 206 be yet another variant
of 050?
==?
050 <ul> = 013 <ul> = 206 <ul>
If Aisin Gioro is correct, then
029-206-189 'hare'
was <tau-ul-a> = taula, and Khitan may have lost a
final -i retained in Written Mongolian taulai.
How can taula be reconciled with the History of the Liao
Dynasty transcription 陶里 *tauli
for 'hare'? There is no guarantee that Chinese transcriptions and the
Khitan small script represent the same variety of Khitan. Perhaps *ai
simplified differently in different dialects of Khitan:
| Proto-Khitan-Mongolic *taulai
|
| Proto-Khitan
*taulai |
Proto-Mongolic *taulai
|
| Standard taula |
Nonstandard tauli |
Written Mongolian taulai
|
Aisin Gioro (1999, 2004) identified two more small script characters
for <ul>. Why did the Khitan have five characters for the same VC
sequence?
====?
050 <ul> = 013 <ul> = 206 <ul> = 228
<ul> = 366 <ul>?
The first three may be allographs, but the last two do not resemble
them. Did 050/013/206, 228, and 366 originally represent three
different sequences? If Khitan were like Mongolic, an obvious two-way
distinction would be between <ul> and <ül>. 366 might have
been <ül> since
131-366 <u.ul> 'winter'
corresponds to Written Mongolian ebül 'id.' But what
would have been a third value contrasting with <ul> and
<ül>?
Kane (2009: 29) wrote that Khitan "was exceptionally rich in rounded
vowels." Was there a three-way contrast between front [y], back [u],
and near-high [ʊ] (like Manchu ū)? Did these three characters



131 <u>, 245 <ú>, 372 <û>
represent those vowels without a following lateral? (I almost wrote
[l], but /l/ may have had different allophones depending on the
adjacent vowel.)
At first, one might identify 131 as ü since it preceded 366
which might have been ül. However,

226 <ü>
transcribed Liao Chinese ü, whereas the three other
<u>-type characters were used to transcribe Liao Chinese *u.
Were they always interchangeable, or was that interchangeability due to
later mergers?
Has anyone looked at Khitan spelling over time? Spelling variation
may give us clues to changes in Khitan over a two or even a
three-century period. If Nova N 176 is from, say, 1200 - the eve of the
fall of the Qara Khitan - its large script spelling could differ from
the norm established c. 920. Moreover, some variation may be due to
Jurchen speakers' perceptions of Khitan phonology: e.g., Jurchen
speakers may have heard only one or two kinds of /u/ in Khitan which
might have had three. (3.25.0:16: First-language influence in Khitan
texts written by Jurchen speakers has yet to be explored.)
15.3.23:23:36:
DID THIRTEEN EQUAL FIFTY IN THE KHITAN SMALL SCRIPT?
Last night, I accidentally miswrote

070-050 <w.?>
in the Qidan xiaozi yanjiu transcription of 興宗 15.19 as

070-013 <w.?>
with a slightly different and much rarer character that only appears
twice in the texts in Qidan xiaozi yanjiu:


028-067-013 <sh.eu.?> (道宗 27.9) and 013-224-327
<?.mu.ie> (耶律撻不也 12.1)
Is 013 in any of the texts that have been found in the three decades
since the publication of Qidan xiaozi yanjiu? Could 013 be a
variant of 050? Is that why Aisin Gioro did not include 013 in
契丹小字の音価推定および相関問題?

028-067 <sh.eu> (a transcription of Liao Chinese 守 *sheu;
could it also be a native word?)
occurs by itself. Does that imply 028-067-013 <ś.eu.?> is a
suffixed form, or are they unrelated partial homophones? There are
eight forms beginning with 028-067; some have known suffixes (e.g.,

028-067-273 <sh.eu.un> ending in what may be genitive
<-un> in 蕭令公 25.16 and 許王 50.5)
and others do not (e.g.,

028-067-041 <sh.eu.?> 'dew' in 宣懿 25.14 and 許王 cover 1.5).
Aisin Gioro read 041 as <us>* and 050 as
<ul> ~ <l-> for reasons unknown to me. The Khitan small
script has many sequences of the same vowel in two adjacent characters,
so sequences such as
028-067-041 <sh.eu.us> and 028-067-013 <sh.eu.ul>
(if 013 = 050)
look plausible. Moreover, 028-067-041 <sh.eu.us> may be
a variant spelling of
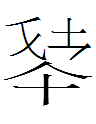
028-067-244 <sh.eu.s> (巴拉哈達洞壁墨書 I.2.4; <s> may
be a plural ending)
Unfortunately, I know of no

*028-067-261 <sh.eu.l>
corresponding to 028-067-013 <sh.eu.ul>.
*3.24.1:56: If Aisin Gioro's reading of 041 is
correct, then
028-067-041 <sh.eu.?> 'dew'
woulld be less of a match for Written Mongolian sigüder(i)
'dew'. If Mongolian -der(i) is not a suffix, then perhaps the
Khitan form is a reduction of an earlier sigüder(i)-like form
to sheu with a plural suffix -s: i.e., drop of dew. The
two words may also be unrelated.
15.3.22:23:59:
DID KHITAN HAVE W IN NATIVE WORDS?
Two nights ago, I wrote,
It seems that Khitan
VC characters can also double as CV characters. I've guessed that they
are CV before consonants and VC before vowels, but that does not always
seem to be the case.
Offhand certain types of VC characters are less likely to have
reversible readings than others: e.g., VN characters seem to have
nonreversible readings with the sole definite exception of
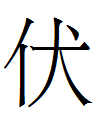
222 <ń> for iń ~ ńi (see Kane 2009: 61 for the
Chinese transcription evidence)
There are dedicated characters for some NV sequences other than ńi
and ngV*: e.g.,


139 <na> and 191 <mú>
Conversely, vowel-liquid characters may have had reversible readings:

084 <ar> ~ <ra>, 098 <al> ~ <la>, 261
<el> ~ <le>?
See "<Ra>-Construction 5"
and "Did Khitan Have Two Laterals?".
The VG sequence character

020 <ey> (Kane's <ei>)
represented <y> in
word-initial position: e.g.,

020-084-131-344 <y.ar.u.ud> '耶律 Yelü'
Could <w> also represent a VG sequence: i.e., Vw? That
is unlikely
because such sequences already have characters:


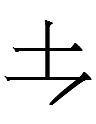





019 <iu>, 023 <iu> (?), 067 <eu>, 138
<iû>, 161 <au>, 164 <au> (?), 210 <aú>, 289
<iú>
(I could also transliterate them as <iw>, etc. to match
<ey> instead of <ei>.)
Might some of those characters be read as wV in word-initial
position? Could 019, for instance, have been read wi 'to not
exist, die'? I doubt it because Chinese w- was always written
with initial
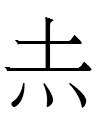
070 <w>
instead of any of the above <Vu> (= <Vw>) characters.
That character never appears in medial position. If Khitan had medial -w-,
it must have been written in some other way: e.g., could 019 <iu>
stand for -wi- after vowels? Were


262 and its variant 263
ever read as wi instead of [uj]? Was

210-262-140 <aú.ui.en> 'woman of noble rank-GEN' (耶律撻不也
16.14)
from my last entry pronounced
something like awiən?
The only non-Chinese Khitan word with an initial <w> is
070-050 <w.?> (興宗 15.19)
according to Qidan xiaozi yanjiu. Its reading is open to
question, as Andrew West read it as

073-? <ên.?>
Alas, I can't consult the original because only a handwritten copy
remains, and I have not been able to examine a good reproduction of it.
3.23.1:35: That mystery word occurs after a space that may indicate
respect. Does it have an aristocratic referent?
Could it be an error for

072-050 <?.?>
from 道宗 25.17 and 耶律撻不也 16.4? Neither of those instances was
preceded by a space.
*3.23.1:27: ng was only in Chinese
loanwords. Initial and occasionally final ng were written with

264 <ng>.
The absence of ng in native Khitan words is not surprising
since Janhunen (2003: 6) did not reconstruct it for Proto-Mongolic
which may be the descendant of a 'sister' of Khitan. However, there is
no guarantee that Khitan and Proto-Mongolic lacked the same consonants:
e.g., Khitan had p, but Proto-Mongolic did not. Similarly, the
absence of Proto-Mongolic *w does not guarantee the absence of w
in native Khitan words.
Tangut fonts by Mojikyo.org
Tangut radical and Khitan fonts by Andrew
West
Jurchen font by Jason Glavy
All other content copyright © 2002-2014 Amritavision
{kind=link}