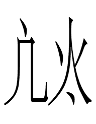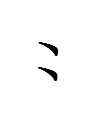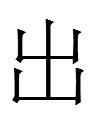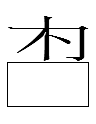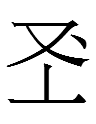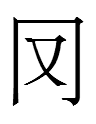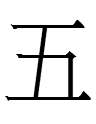
311-151-290 <b.ghu.án> 'sons'
15.3.21:23:54: AN UNKNOWN NUMBER OF SONS
I looked through Qidan xiaozi yanjiu (1985) hoping to find examples of
311-151-290 <b.ghu.án> 'sons'
in the construction
but I only found words other than numerals before 'sons':numeral♂ + plural masculine noun (see Kane 2009: 139-142 for examples)
1. Genitives before 'sons'
210-262-140 <aú.ui.en> 'woman of noble rank-GEN' (耶律撻不也 16.14)
295-097-311-222 192-339 <p.úr.b.iń shï.i> 'Purbin-Madame (< 氏)-GEN' (耶律撻不也 18.27)
The context implies that Purbin is a woman's name. It does not appear anywhere else in the Qidan xiaozi yanjiu corpus.
241-033-222-140 <pu.si.iń.en> 'lady (婦人)-GEN' (耶律撻不也 18.32)
374 071-154 <tai.ong.on> 'grand prince (太王)-GEN' (蕭仲恭 4.53-54)
334-345 104-289-273 <g.ung.j.iú.un> 'princess (公主)-GEN' (蕭仲恭 6.18-19)
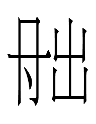
311-168-339 <b.qo.i> 'son-GEN' (蕭仲恭 30.4)
2. Plural nouns in apposition before 'sons'
122-254 <ai.d> 'father-PL' (蕭令公 23.6, 耶律撻不也 9.19)
021-247 <mó.t> 'mother-PL' (蕭令公 24.3, 蕭仲恭 29.8)
131-111-254 <u.?.d> '?-PL' (蕭仲恭 43.36)
How did 'fathers-sons' differ semantically from a hypothetical
*122-254 311-151-290 <ai.d.en b.ghu.án> 'fathers' sons'?
Was the genitive suffix unnecessary after certain nouns (e.g., 'fathers' and 'mothers')?
3. Verbs before 'sons'
295-016-189-123 <p.od.a.ar> 'return-PERF' (許王 48.26)
287-098 <?.al> '?-CONV' (耶律撻不也 24.4)
287 does not occur alone. It tends to precede a-graphs, so it may have been a Ca-graph. I do not know whether it really represented a verbal root. Nor do I know the exact function of the converb -al.
4. Other words before 'sons'
191*-262-348-162 <mú-ui-e-c> '?' (仁懿 8.20)
This could be a noun in apposition. I don't know of any other attestations.
153-254-222 <j.d.iń> '?-PL-GEN'? (蕭仲恭 34.24)
If 153 (which can occur alone) is a noun, could this be a genitive plural noun? But <j.d> '?-PL' is not attested by itself.
Are numerals - masculine or otherwise - attested before 'sons' in the small script texts discovered after 1985?
*3.22.4:02: Why did Kane (2009: 58) transliterate 191 as <mú>? The fact that 191 is often followed by <u>-graphs
262 <ui>, 366 <ul>, 372 <û>
may imply that it ended in <u>, but what evidence is there for an initial <m>?
15.3.20:23:50: AN ENQUIRY INTO EN-DEPENDENCE
In my last entry, I noted that <en>, normally a genitive suffix written in a block with a preceding noun, was isolated in 萬部華嚴經塔塔壁題字 2.8:
I found one other instances of isolated <en> in Qidan xiaozi yanjiu (1985):
(*
)
244-327-073 140 <s.ie.ên en> (instead of *244-327-073-140 <s.ie.ên.en>) 'thousand GEN (?)' before 311-290 178 378 <b.an ku "> '?* people' (the reduplication of ku 'person' is reminscent of Japanese hitobito 'people').
134 140 311- <TWO en b.qo> (仁懿 6.3-5) 'two GEN son' = 'two sons'?
An apparent third instance turned out to be the upper half of a now-illegible stack:
162 345 290 140-? <c ung án en.?> 'Chong An (a Chinese name?) ?' (慶陵壁畫題字 IV)
I have wanted to look into such unusual vertical stacks for almost a year now.
Perhaps there are more examples of independent <en> in the small script texts that have been discovered over the last three decades. Could some represent a word ne? (It seems that Khitan VC characters can also double as CV characters. I've guessed that they are CV before consonants and VC before vowels, but that does not always seem to be the case.)
Are the first two instances examples of numerals followed by genitives? Why is <TWO> nonmasculine in 仁懿? What is the semantic difference between
numeral♂ + plural masculine noun (see Kane 2009: 139-142 for examples) and
numeral + genitive + singular masculine noun
Is gender and number neutralized in the latter construction?
I thought <TWO en b.qo> might be 'two' followed by a compound noun '?-son', but I would expect <TWO> to be masculine and '?-son' to be plural:
135 140 311-151-290 <TWO♂ en b.ghu.án> '?-sons'.
3.21.2:11: Should <ghu> in <b.ghu.án> be interpreted as a VC character <ugh> before the vowel-initial character <án>? If so, then 'sons' was bughán which might have been from *buqo-án, implying that <b.qo> 'son' was buqo.
The phonetic difference, if any, between
~

011 ~ 127 <an> and 290 <án>
is unknown. Kane's acute accent for the transliteration of the latter is arbitrary.
*3.21.2:18: This is the only example of <b.an> in Qidan xiaozi yanjiu. I assume it is an adjective modifying kuku 'people'. I thought <b.an> might be an error for <b.ghu.an> 'sons', but I would not expect a bare (i.e., non-genitive) plural noun before 'people' unless the meaning was 'sons [and] people'.
What is the semantic difference between kuku 'people' and
~
~
047 <ghor> ~ 047-189 <ghor.a> ~ 047-131 <ghor.u> 'people'?
Did kuku refer to individuals while the ghor-words referred to a collective?
15.3.19:23:49: SEARCHING FOR SINO-KHITAN 'THOUSAND': BEFORE THE IMMORTALS
Last night, I asked,
Is there any evidence for Sino-Khitan numerals in the Khitan small script?
Although Kane (2009) only listed Khitan native numerals in his glossary of Khitan small script vocabulary, his list of Liao Chinese borrowings in the Khitan small script includes
244-189-184 <s.a.am> < Liao Chinese 三 *sam 'three' and
244-327-073 <s.ie.ên> < Liao Chinese 千 *tshien 'thousand'
as parts of longer loanwords but not as independent words. Perhaps they are Sino-Khitan numeral roots but not numerals themselves. Similarly, English has the Greek and Latin root tri- 'three', but tri is not a free morpheme like three (or Sino-Korean sam 'three' or Sino-Japanese san 'three').
I checked to see if <s.ie.ên> ever appeared outside Chinese loanwords in the texts in Qidan xiaozi yanjiu, and I found
- two instances of <s.ie.ên> for Chinese 仙 *sien 'Taoist immortal' (道宗 6.12, 31.33)
- two instances of <s.ie.ên> for Chinese 前 *tshien 'front, before' (蕭仲恭 20.24, 33.39)
- one instance of <s.ie.ên> (gloss unknown; 萬部華嚴經塔塔壁題字 2.8) before
140 <en>
which might be the native Khitan genitive suffix after a noun (仙 or 前?; the latter was borrowed into Korean as a free morpheme). I assume that last <s.ie.ên> is not 'three' since I have not seen a numeral-genitive construction in Khitan. (3.20.23:30: Now I have!)
(3.20.1:25: Maybe <en> is not a genitive suffix. Such a suffix would normally be written in the same block as the preceding noun. I will look at other cases of independent <en> next time.)
So far it seems that <s.ie.ên> is not 'three' outside the context of
244-327-073 264-019 <s.ie.ên ng.iu> < Liao Chinese 千牛 *1tshien 1ngiu 'thousand-ox'
from Kane's list corresponding to
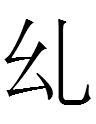
<sien ng iu> (耶律昌允 2)
in the large script.
However, there are small script texts discovered after the publication of Qidan xiaozi yanjiu in 1985 which I haven't checked. Nonetheless at this point I am skeptical about freestanding Sino-Khitan numerals in the small script. Moreover, I am not even certain that
<si sien ngu bai> < Liao Chinese 七千五百 *4tshi 1tshien 2ngu 4pai (耶律昌允 4)
represents Sino-Khitan numerals in the large script. Why did Liu and Wang (2004: 91) identify it as 'seven thousand five hundred'?
15.3.18:23:51: HOW WAS 'THOUSAND' WRITTEN IN THE KHITAN LARGE SCRIPT?
Kane (2009: 177) listed no Khitan large script character for 'thousand' corresponding to
207 <ming> (cf. Mongolian mingghan 'thousand', Jurchen minggan 'id.')
in the small script, even though Kane made use of Liu and Wang (2004: 91) which identified a similar large script character looking like Chinese 夹* as 'thousand' in line 4 of the 1062 epitaph for 耶律昌允 Yelü Changyun:
On the other hand, both Liu and Wang (2004: 91) and N4631 identifiedLiu and Wang (2004: 79-81): <si sen ŋu pe>
Kane (2009: 178-179): <sï (t)s(i)en ŋu bai>
'seven thousand five hundred' (cf. Liao Chinese 七千五百 *tsʰi tsʰien ŋu pai)
(~
~
)
as 'thousand' even though Kane (2009: 176) listed it as 'yellow' in calendrical contexts. Andrew West also listed
as another variant of 'yellow'. Were 'thousand' and 'yellow' homophones in Khitan? (Other evidence points to an *n-initial word for 'yellow, gold' in Khitan. See Kane 2009: 165-166. Maybe Khitan had two words for 'yellow', and the calendrical word sounded like Sino-Khitan 'thousand'.)
Did Khitan have two words for 'thousand', a borrowing from Chinese and a native word? The phrase above may be entirely in Sino-Khitan; would
?
<dalo (?) ming (?) tau jau>
with some unknown character for 'thousand' be its native equivalent? (Ironically the Khitan wrote their native numerals with large script characters sometimes matching Chinese numeral characters but wrote Sino-Khitan numerals with large script phonograms with almost no resemblance to Chinese numerals.**) When did the Khitan use Sino-Khitan and native numerals? Is there any evidence for Sino-Khitan numerals in the Khitan small script? I'll start to answer that last question next time.
*3.19.1:22: What looks like 夹 in Liu and Wang's (2004: 91) handwritten copy of the epitaph might correspond to
in their list of characters on p. 80. I cannot find 夹 in N4631.
**3.19.1:59: 吾, the Khitan large script character for Sino-Khitan 'five', resembles Chinese 五 'five' because it is a graphic cognate of Chinese 吾 whose phonetic is 五.
高 is the glyph for Sino-Khitan *bai 'hundred' in Liu and Wang's (2004: 91) handwritten copy of the epitaph; a variant
appears in their list of characters on p. 81.
I used to think it was significant that 高 <bai> looked like 'high' and was read <bai> because Tangut
1890 2be4 < *Nɯ-braŋ or *Cɯ-mbraŋ 'high' (cf. Japhug mbro < *mbraŋ 'id.')
had a similar reading and meaning, but now I think the resemblance is merely coincidental. The Tangut word is native. If there was a Khitan word for 'high' like *bai, I doubt that the Khitan would have borrowed it or any other basic vocabulary from the Tangut who were far to the west.
15.3.17:22:51: DID LITTLE BROTHERS COME TO BE FIGHTER CONTROLLERS?
Liu and Wang (2004: 91) identified
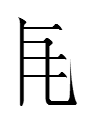
in the 1062 epitaph for 耶律昌允 Yelü Changyun as a Khitan large script equivalent of Liao Chinese 都統 *du tuŋ 'commander-in-chief' (translated as 'fighter controller' in the small script?) The large script graphs look exactly like Chinese 弟 'younger brother' and 来 'to come'.
Liu and Wang identified 弟 in line 5 of that epitaph as 'younger brother'. Presumably 弟 is a phonetic character in 弟来 'commander-in-chief' (if that gloss is accurate).
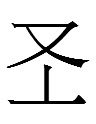
'Younger brother' is
(=
?)
101 (and 072 <EAST>, implying 'younger brother' and 'east' were homophones?)
in the Khitan small script. Kane (2009: 47) read this as <deu> but gave no explanation for that reading which resembles that of the first character of Jurchen
<deu.un> deun 'younger brother'
I will regard the Khitan reading of the large script character 弟 and its small script equivalent 101 as unknown.
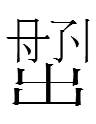
I also do not know the reading of 来 in the large script.It may be significant that in the small script, younger brothers precede older brothers, whereas the reverse order (i.e., Chinese order) is in the Chinese-like large script (see Kane's analysis of the 1114 epitaph for 耶律習涅 Yelü Xinie):
:
small 101 335 <YOUNGER BROTHER ia> : large <OLDER BROTHER YOUNGER BROTHER>
Could the small script reflect a native Khitan word sequence while the large script reflected a borrowing from Liao Chinese 兄弟 *xiuŋ di? (Cf. native Japanese 白黑 shirokuro 'white and black' vs. borrowed Sino-Japanese 黑白 kokubyaku or kokuhaku 'black and white'.)
The first half of Liao Chinese 都統 *du tuŋ appears in line 13 of Yelü Changyun's epitaph as
<du giam> < Liao Chinese 都監 *du giam 'director-in-chief'
whose first character matches its Chinese equivalent. The Khitan large script seal version of 都 is on Andrew West's site. Is there a large script term for 都統 like
with a near-lookalike of 統? Or
with the two characters that are possibly equivalent to the near-lookalike of 統?
15.3.16:23:56: FIGHTER CONTROLLER
Last night, I couldn't figure out why Liu and Wang (2004: 87) identified
and
(=
)
in the large script as <c> and <u> in my transliteration.
I had forgotten about how Liao Chinese 都統 *du tuŋ 'commander-in-chief' corresponded to the native* Khitan term
<cau.j ɣur.ú>
in the small script.
Apparently Liu and Wang equated the large and small script terms:
<c.auj ɣur.ú>? = <cau.j ɣur.ú>
Although all of those small script readings can be more or less confirmed** by their use in other contexts, I am less confident about the large script readings. Maybe
are <HEAVEN ɣur.ú> 'heaven controller' and <HEAVEN BELOW ɣur.ú> 'world controller' (the world being all under heaven), but is the common character
really <auj> in all 13 occurrences in 耶律褀墓誌?
Maybe <auj> was something like *auji if <cau.j> represented *cau-ji 'fight-er' with a deverbal suffix (Kane 2009: 94; his translation is 'those who engage in battle') that was cognate to Mongolian -ci and Turkish -cI/çI*** for names of vocations.
On the other hand, if the ends of the large and small script era equivalents of the Chinese era name 統和 *tuŋ xwo do not match,
≠
large <?.?> = <?.?> ≠ small <s.bu.o.ɣo>?
then there is no reason to expect the large and small script era equivalents of Chinese 都統 *du tuŋ 'commander-in-chief' to match, and.
might represent something other than <cau.j ɣur.ú>.
*3.17.1:07: 'Non-Chinese' would be a more precise term, as I cannot be sure that any non-Chinese Khitan word is native rather than a borrowing from Xiongnu or even Rouran.
Regardless of the precise origin of <cau.j ɣur.ú>, it contrasts with the loanword
<du t.uŋ>
from Chinese 都統 *du tuŋ. The first character is also a transcription of Liao Chinese 度 *du and <t.uŋ> is also a transcription of Liao Chinese 同 *tuŋ.
**3.17.1:04: Kane (2009) presented evidence for the readings of the four components of <cau.j ɣur.ú>:
022
<cau> corresponds to 炒~嘲 *cau in Chinese transcription.
337
<j> is a variant of 152
which corresponds to 只 *wu in Chinese transcription.
014
<ɣur> corresponds to 斛祿~胡虜~胡魯 *xulu in Chinese transcription. I don't know why Kane didn't read it as <x>, as there was no *ɣ in Liao Chinese.
245
<ú> corresponds to 武 *wu in Chinese transcription.
**3.17.1:17: Turkish c is voiced [dʒ]. Turkish I is a cover symbol for high vowels (i, ı, u, ü). Clauson (1962: 145) regarded voiceless ç as original.
15.3.15:23:48: BABELSTONE'S DISSECTION OF KHITAN 'SUCCESSION'
I thank Andrew West for his solutions to the problems that I raised in "The Dissection of Khitan 'Succession'.
According to Andrew, the noninitial characters/blocks of the Khitan large and small script equivalents of the Chinese era name 統和 'uniting harmony' did not represent the same words:
large <tu.uŋ> = <tu.uŋ> (< Liao Chinese 統 *tuŋ 'unite') ≠ native <s.bu.o.ɣo>
That mismatch is a clue to the elusive answer to the question of why the Khitan had two scripts.
The first large script spelling is a phonetic borrowing of 統 *tuŋ 'unite' written as a fanqie initial-rhyme sequence whereas the second is a graphic as well as a phonetic borrowing of 統 *tuŋ 'unite'.
Janhunen might regard the second as a graphic cognate of 統 rather than a derivative. Such a cognate might have been of Manchurian (Parhae?) origin, as I was unable to find a Chinese character resembling it or its right half in Longkan shoujian, Dunhuang su zidian, or at /dict.variants.moe.edu.tw (see its variants of 統 and 充).
Andrew also made the following identifications:
<ging en d(u?).u tu.uŋ> (the transliteration is mine)
京之都統 'commander-in-chief of the capital' (北大王墓誌 17)
Andrew regards the third character as a variant of
which Liu and Wang (2004: 87) somehow identified as [tʂʻ] = <c> on the basis of the small script. I suppose it must be equivalent to
162 <c>.
Kane (2009: 181) interpreted it as <c(i)>. I don't understand their reasoning. Did the character have two readings, <d(u?)> and <c(i)>?
<HEAVEN BELOW tu.uŋ> (the transliteration is mine)
'commander-in-chief of the empire' (耶律褀墓誌 6)
Once again, Liu and Wang's equation is somehow based on the small script - presumably on an equation with
131 <u>.
Since the small script characters
106 <uŋ> 345 <uŋ> 357 <úŋ>
are only for Chinese, could
represent a Khitanized loan <tu.u> without a final velar nasal from Liao Chinese 統 *tuŋ?
I wonder if <HEAVEN> had different readings depending on what followed: a Sino-Khitan reading like <tien> before <tu.uŋ> and <tuŋ> in the large script and an unknown native reading* before <s.bu.o.ɣo> in the small script:
<ten?.tu.u(ŋ?)> : <ten?.tuŋ> ≠ <? s.bu.o.ɣo>
*3.16.0:51: Possibly <o> as proposed by Ji Shi (Kane 2009: 63), but I suspect that
<s.bu.HEAVEN.ɣo> instead of <s.bu.o.ɣo>
in the 仁先 Renxian inscription might be an error influenced by a preceding <HEAVEN> if it represents the second half of the era name. (I have not seen the Renxian inscription, so I don't know what context <s.bu.HEAVEN.ɣo> appears in.)