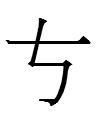<t.ge.l.ge.l.g> (興宗 32-19)
14.5.10.22:20: DID KHITAN HAVE DOUBLE CAUSATIVES? (PART 1)
Yesterday I made this image
<t.ge.l.ge.l.g> (興宗 32-19)
as an example of an <l.g> causative, but realized I already had one - a hapax legomenon* possibly containing yet another hapax legomenon* - <b.ge>, the word preceding <ś.ei> in 許王 18:
<b.ge.l.g.a.121>
So I shelved that first image but didn't want to waste it. Hence this post.
When I made that image, I was oblivious to the fact that it appeared to contain a double causative:
<t.ge> '?' + <l.ge> (causative with buffer vowel) + <lg> (causative) = 'causes X to cause Y to <t.ge>'
I suppose it's possible that there could be a monomorphemic verb stem <t.ge.l.ge> which happened to contain <l.g> like a causative verb. I might go with that if <t.ge.l.ge> were attested all over the place, but <t.ge.l.ge.l.g> is a hapax legomenon*, which is what I'd expect for a double causative in a limited corpus. I think it is part of a paradigm containing the following forms:
<t.ge> (base form; 蕭令公 19-23)
<t.ge.er> (masculine past; 蕭令公 1-1)
<t.ge.én> (feminine past; 故耶律氏銘石** 14-6, 蕭仲恭 5-57, 椁*** 2-1)
I cannot identify all the suffixes in the other <t.ge>-words:
<t.ge.en.er> (? + masculine past?; 許王 16-27, 故耶律氏銘石** 12-2)
<t.ge.356.i> (? + converb 'after'?; 興宗 13-2)
<t.ge.l.û.j> (? + converb 'after'; 興宗 12-20)
Another potential example of a double causative is
<s.ún.g.l.ge.l.g> (宣懿 8-12)
Its root <s.ún.g> is also in
<s.ún.g.én> (feminine past; 道宗 15-3, 30-8, 36-22)
<s.ún.g.én> (feminine past; different spelling; 宣懿 14-15)
<s.ún.g.er> (masculine past; 蕭仲恭 32-10)
<s.ún.g.ún> (verbal noun?; 道宗 12-11)
<s.ún.g.u.j> (? + converb 'after'?; 宣懿 29-21)
<s.ún.g.s.ii> (converb 'after'; 蕭仲恭 46-36)
<s.ún.g.l.ge.ei> (causative + converb 'after'****; 故耶律氏銘石** 20-27)
<s.ún.g.l.ge.ún> (causative + verbal noun?; 興宗 20-16, 蕭令公 11-18)
Next: <t.ge.l.ge.l.g> in context
**This name is from Qidan xiaozi yanjiu. Andrew West identified it as the epitaph of 耶律撻不也.
***This abbreviated name is from Qidan xiaozi
yanjiu. Andrew West identified it as "Inscriptions on a painted wooden coffin" in the Wikipedia list of Khitan inscriptions. Page 680 of Qidan xiaozi yanjiu lists 木 (short for 木椁壁面题字) as the code for those inscriptions.
****The converb <ei> is probably a grammaticalization of the verb <ei> 'to have, exist'.
14.5.9.23:49: DID KHITAN HAVE TWO LATERALS?
Last night I mentioned a hapax legomenon (?)* <ś.ei> which I thought might be a form of the Khitan word for 'good'. Here it is in context from 許王 18:
...
...
<... b.ge ś.ei 115 ...>
Unfortunately <b.ge> may also be a hapax legomenon*. The only similar word I know of is
<b.ge.l.g.a.121>
which may contain the causative suffix <l.g> after the root <b.ge>.
That suffix has a variant <al.ɣu> in words such as<l.ɣa.al.ɣu.an> (from Chinggeltei 1992 cited in Kane 2009: 46; not in any text I have on hand**)
Those suffixes have cognates in Mongolian:
Khitan <al.ɣu> : -lɣa-
Khitan <l.g> : -lge-
Although some imply that such Mongolian suffixes are of late origin (Ozawa 1967 and Hsiao 2009), lg-type causatives are attested much earlier in Khitan.
Some time ago, I wondered if there was a Khitan small script character for [la]. It occurred to me that perhaps small script character 098was velar <ɫ>, a character that could represent either *ɫa or *aɫ just as small script character 261

<l>
could represent either *lə or *əl.
The two laterals of Khitan would be like the two laterals of Old Turkic written in the 'runic' script as 𐰞 and 𐰠. (I have also reconstructed a velar *ɫ for Tangut.) Each type of l would accompany certain other consonants and vowels:
*ɫ with uvulars and lower vowels: e.g., *a
*l with velars and higher vowels: e.g., *ə
This distribution would be like that of 'emphatic' *lˁ and 'nonemphatic' *l in my Middle Old Chinese reconstruction.
*l would also appear in Chinese loanwords with any vowel since Liao Chinese only had *l.
There is one obvious problem with this hypothesis: the uvular-low vowel sequence <ɣa> in
<l.ɣa.ɫ.ɣu.an> (with small script character 098 retransliterated as <ɫ>)is preceded by <l> rather than <ɫ>. So Khitan probably had a single lateral phoneme (though it still might have had allophones like [ɫ]). Maybe small script character 098 was [la] ~ [al] with the same [l] as 261.
*I don't know for sure since I don't have access to all known Khitan small script texts.
**The closest word I can find is
<l.ɣa.ai>
from 蕭仲恭 31-28.
14.5.8.23:59: GOOD BLOG OR BLOG GOOD?
Before I can go on to address the problem of whether a good blog would be *śia or *śien in Khitan, I should address a question that Andrew West asked: would 'good' (*śia or *śien or something else) precede or follow 'blog'?
The unspoken assumption of Khitan linguistics is that Khitan is an Altaic-type language. Such languages from Turkish in the west to Japanese in the east have modifier-modified order. That order certainly does exist in Khitan, yet the same words can also be placed in the opposite order. What is the significance of the two orders?
The only known Khitan phrase with 'good' in Chinese transcription is
賽離捨 *saili še ~ 賽咿唲奢 *saiiži še (I am deliberately not using IPA to avoid committing to phonetic details)
for something like *saiir śe, lit. 'moon good'. Andrew pointed out this structure is parallel to 洪邁 Hong Mai's literal translation of Khitan 'bright moon' as 月明 'moon bright'. (Alas, we don't know what the Khitan word for 'bright' was. Perhaps it lies undiscovered in the corpus.)
*śe does not quite match any of the known Khitan small script forms for 'good':
~
~
<ś.ia> *śia ~ <ś.iá.aɣ> *śia(a)ɣ ~ <ś.ên> *ś(i)en
Perhaps the transcriber did not hear the final *-n of *ś(i)en. Maybe that word had an open-syllable variant *ś(i)ẽ. Or *śie could have been a nonstandard pronunciation of *śia. It is also possible that the three forms above are not an exhaustive list of forms of 'good', and one has only been identified in Chinese transcription. Might
<ś.ei> *śəi < *śiəi < *śiei < *śiai < *sia-i < *sia < root *sai?
from 許王 18-13 be the Khitan small script spelling of the form of 'good' transcribed as 捨 ~ 奢 *še?
5.9.0:50: <ś.ei> is flanked by an unknown word <b.ge> and by <115>, which Kane (2009: 48) tentatively glossed as 'two, couple' or 'some, several':
...
<... b.ge ś.ei 115 ...>
I don't know which word it's modifying.
A more straightforward Khitan small script equivalent of 捨 ~ 奢 *še would be
<ś.ie> *śie
with <ie> *ie, the character used to transcribe the rhyme of Liao Chinese 捨 ~ 奢 *še (see Kane 2009: 245 for examples). But I have not found any examples of such a spelling.
5.9.1:25: How would 'good' have been written in the Khitan large script? The closest match I can think of is
<śia>?
which according to Liu and Wang (2004: 88, #189) corresponds to the first half of a transcription for Liao Chinese *šiau, written in the small script as
<ś.iau.u>
with an unexpected double <u.u>. Most Liao Chinese *-au syllables were transcribed with an <iau> not followed by <u> (Kane 2009: 248).
14.5.7.23:54: A GOOD BLOG: ŚIA OR ŚIEN IN KHITAN?
Tonight I started reading Christopher Culver's blog. It's hard to stop. Click on "(+)Languages" on the right to see the breadth of his linguistic interests.
I wanted to title this entry 'good blog' in Khitan. It's easy to Khitanify 'blog' as

<b.l.o.g>
but there are at least two forms of 'good' in Khitan:
<ś.ia> *śia < *sia < *sai
<ś.ên> *śien < *śian < *sian < *sain
Which form is appropriate before 'blog'? Do they have different grammatical genders? I'll compare these forms in my next entry.
14.5.6.23:16: DID VOWEL LENGTH BLOCK THE METATHESIS OF KHITAN DIPHTHONGS? (PART 2: SHOOTING A HUNDRED RABBITS IN BATTLE)
In part 1, I proposed that in Khitan
- short *ai metathesized to *ia:
e.g., *taaulai > *taaulia 'rabbit' (see below f
or why I reconstruct *aau)
- long *aai and *aii remained intact:
e.g., *naai 'head', *saiir 'month'
the long vowel of the latter (suggested by Andrew West) is reflected in the transcription 賽咿唲 *sai-yi-ži
I should have added that I think short *ai metathesized and became *e before *-n:
e.g., *sain > *śian > *śen 'good'
Here I propose parallel changes for diphthongs with *u:
- short *au metathesized to *ua:
e.g., *qarbu- > *qabu > *qawu > *qau > *qua 'to shoot an arrow'
cf. Mongolian qarbu- 'to shoot an arrow'
I am assuming that the *x- of the Chinese transcription 化 ~ 樺 *xwa is an attempt to transcribe Khitan *q-. If it isn't, then the Khitan and Mongolian words may be unrelated unless there are other cases of Khitan *x- corresponding to Mongolian *q-.
I do not know how *(C)ua-syllables would have been written in the Khitan scripts.
- long *aau and *auu remained intact:
e.g., *taaulia 'rabbit', *jaau 'hundred', *cauur 'battle'
I reconstruct *aau instead of *auu in the first two words since they were transcribed as 淘裏 ~ 陶里 *thau-li (not *淘伍裏 ~ 陶伍里 *thau-u-li) and 爪 *cau (not *爪伍 *cau-u).
The long vowel of the last word (suggested by Andrew West) is reflected in the transcription 炒伍侕 *chau-u-ži.
- short *au might have metathesized and become *o after *-n:
e.g., *xarban > *xaban > *xawan > *xaun > *xon 'ten'
cognate to the *-xon/*-xun suffix in Jurchen 'twelve' through 'nineteen' which may be loans from a Khitan-like language; the Khitan word for 'ten' is unknown
Although Mongolian is attested after Khitan, in some ways it is more conservative than Khitan. On the other hand, if the above hypotheses are correct, Khitan may preserve vowel length lost in Mongolian itself:
Proto-Khitano-Mongolic *taaulai 'rabbit'
> Khitan *taaulia (preserved long *aa but metathesized final *ai)
> Mongolian taulai (lost long *aa but preserved final *ai)
If the name Proto-Khitano-Mongolic is too awkward for the ancestor of Khitan and Mongolic, maybe it could be called Proto-Xianbeic or even Proto-Donghuic (though I know of no hard linguistic evidence to prove that all the Donghu spoke a Khitan/Mongolic-type language; perhaps only the Xianbei subgroup did).
14.5.5.22:12: DID VOWEL LENGTH BLOCK THE METATHESIS OF KHITAN DIPHTHONGS? (PART 1)
Just as I was about to segue from Hungarian back to Khitan (or should I say kitaj nyelv?), I learned of Andrew West's "Accounts of Khitan Life and Language" from bitxəšï-史. I was going to write about reconstructing a long vowel ii in Khitan - and Andrew independently mentioned transcription evidence for it:
the Khitan word [for 'month' transcribed in Chinese as 賽咿唲 *sai-yi-ži] is something like *sair or *saiːr (if the 咿 yī is an attenpt to represent a long vowel).
Last September, I proposed that Khitan *ai metathesized to *ia, but could not explain why *ai 'father' and *nai 'head' did not become *ia and *nia (or *ńia; cf. *sai > *śia). I should have added *sair 'month' to that list of nonmetathesizing ai-words. Andrew's proposal of a long vowel now makes me wonder if
- short *ai became *ia
- but long *aii and *aai remained intact
If 'month'was *saiir, could 'head' (transcribed in Chinese as 耐 *nai) have been *naai? (If 'head' was *naii, I would expect the Chinese transcription 耐咿 *nai-yi.)
Next: Shooting in Battle
14.5.4.22:59: A-V-O-IDANCE: CONSTRAINTS ON HUNGARIAN WORD-FINAL VOWELS
When one hears that a language has short and long versions of each of its vowels, one might expect short and long vowels to have an equal chance of appearing in any given position. For instance, Japanese has short and long versions of /a i e u o/, and so one might think that any of its ten (= 5 x 2) vowels would have a ten percent chance of being in final position, but that is not the case:
| Short vowels | Long vowels | ||
| /a/ | any word | /aa/ | mostly non-Chinese loanwords |
| /i/ | /ii/ | mostly non-Chinese loanwords and -shii adjectives | |
| /u/ | /uu/ | mostly Chinese loanwords | |
| /e/ | /ee/ | ||
| /o/ | /oo/ | mostly Chinese loanwords and volitional -ō forms of verbs | |
If Japanese never had any loanwords and never had lenition in its inflections (-shii is from -shiki and -ō is from -amu), it would have very few final long vowels.
According to Kenesei et al. (1998), Hungarian final vowel distribution is even more skewed:
| Short vowels | Long vowels | ||
| a | not in major lexical categories except for fa 'wood' and ma 'today' (archaisms unaffected by a change that wiped out original *-a?) | á | generally not in underived root morphemes* |
| e | no restrictions | é | no restrictions |
| i | í | uniformly shortened to [i] | |
| o | loanwords? and no(no) 'well (well)' | ó | no restrictions |
| ö | loanwords?: e.g., Malmö | ő | |
| u | no restrictions | ú | tends to be shortened to [u] |
| ü | ű | tends to be shortened to [y] | |
I am surprised by the restrictions on a [ɔ] and á [aː] since /a/ is perhaps the generic vowel in human languages. Maybe the restrictions on a [ɔ] are somehow related to the constraints on o and ö.
Was a [ɔ] originally [a] or [ɑ] when Hungarian was first written?
Kenesei et al. (1998) do not mention loanwords spelled with word-final o and ö. Are they pronounced with final long vowels? If so, they are like the mirror image of words spelled with word-final long vowels that are pronounced short. I assume this shortening is a recent phenomenon and that Hungarian spelling is etymological: i.e., it preserves the original lengths of final high vowels.
I could summarize the distribution of Hungarian word-final long vowels as follows:
- high vowels are shortened
- mid vowels are unrestricted (yet short mid rounded vowels are highly restricted!)
- the low vowel á is restricted
And the distribution of Hungarian word-final short vowels could be summarized as unrestricted except for o-type vowels (a, o, ö - hence "a-v-o-idance" in the title).
I know the historical reasons for the skewed distribution of Japanese vowels, but I have no idea why Hungarian final vowels are the way they are (beyond the obvious recent shortening of final high vowels). Does the Hungarian situation make more sense in a bigger Uralic perspective? Does it have parallels in other languages?
*Kenesei et al. (1998: 425) list four types of á-words:
1. interjections
2. function words
3. names of letters
4. affixes: i.e., suffixes?
I would add loanwords as a fifth category: e.g., burzsoá 'bourgeois'. Is hajrá 'spurt' a loanword?