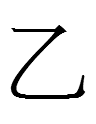









<ś.ên>




14.1.25.23:57: 'FLIP-FLUP' (SIC) IN SHIRA YUGHUR
I was surprised by Shira Yughur cüsin 'blood' in Nugteren (2003: 270) because its vowels were 'flip-flupped' (sic) relative to Classical and Middle Mongolian cisun 'id.' I came up with the following scenario beginning with Janhunen's (2003: 9) reconstruction for pre-Proto-Mongolic 'blood':
Pre-Proto-Mongolic *cïsun
Proto-Mongolic *cisun (back *ï merged with front *i)
Stage 1: *cisün (second vowel fronted to match the first vowel)
Stage 2: *cüsün (first vowel rounded to match the second vowel)
Stage 3: cüsin (second vowel dissimilated by losing rounding)
Shira Yughur 'nine' also underwent stage 3:
Proto-Mongolic *yersün (Janhunen 2003: 16)
Common Mongolic *yesün (Janhunen 2003: 16)
*yisün (raising of *e after stage 2?; if it had occurred before stage 2, *i from *e would have rounded to *ü, unless that didn't happen before *y-)
Stage 3: hyisün (the unexpected h- reminds me of Greek words like hýdōr < Proto-Indo-European *udōr 'water' [Watkins 2011: 98]*)
Stage 4: shyisün (palatalization of h- before i)
I assume Shira Yughur 'person' avoided stage 3 because dissimilation didn't apply to single long vowels:
Pre-Proto-Mongolic *küpün (Janhunen 2003: 6)
why did *p nasalize to m in Classical Mongolian and Oirat kümün?
Common Mongolic *küxün > *küün (Janhunen 2003: 6)
*1.26.1:02: Sihler (1995: 173) wrote:
The regular source of G[reek] initial /h/ is PIE *s (170). But it occurs also by analogy (item 3, below); or in words originally beginning with *y or *w [...] Some instances are of wholly enigmatic origin, for example G ἴππος <híppos> 'horse': its cognates - L[atin] equus, Ved[ic] áśva-, O[ld] E[nglish] eoh, Gaul. Epona, and so on - point unambiguously to a word-initial *e- (or *H1e- [ʔe-], which for present purposes is the same thing); and even in G itself compounds such as the name Ἄλκ-ιππος <Álk-ippos>, with unaspirated κ [as opposed to *Álk-hippos], are inconsistent with the rough breathing of the simplex [i.e., the initial h- of 'horse' by itself].
The PIE root of 'water' is √*wd. Greek y is from *u, the vowel version of *w.
I thought Greek h- in 'water' might be 's-movable' (i.e., a final *-s reinterpreted as the initial of a following word), but according to Sihler (1995: 169), 's-movable' only occurred before consonants and there is no other Indo-European language with *s- added to that root for 'water'. Moreover, on p. 173 Sihler wrote,
Initial ῡ̆- <ȳ̆-> [< *ū̆-] of whatever history, always has spiritus asper [i.e., h-]. How this state of affairs came about is unknown.
I cannot believe that all *u-initial words happened to be reinterpreted as having *s- in pre-Greek. So my 's-movable' hypothesis is dubious. Is there any language that has a Greek-like constraint against initial y-? Does that vowel have some characteristic that makes it unattractive in initial position?
Why does Unicode have codes for Greek initial ὐ ὒ ὔ ὖ <y ỳ ý ỹ> without h- and codepoints reserved for their capital versions? (I have nothing against that, as I like being able to type 'impossible' character combinations.)
14.1.24.23:41: VOWEL LENGTH IN KHITAN AND SHIRA YUGHUR
While looking up Janhunen's (2003) quotation on vowel length in Proto-Mongolic, I found some words with Khitan cognates in Nugteren's chapter on Shira Yughur:
| Page | Gloss | Shira Yughur | Classical Mongolian | Khitan small script | Transliteration | Vowel length match |
| 267 | fifty | tawin | tabin | |
<tai>?* | not if <tai> was [taːj]; no known alternation with <ta.ai> that might confirm vowel length |
| five | taawin | tabun | |
<tau> | only if <tau> was [taːw]; no known alternation with <ta.au> that might confirm vowel length; Chinese transcription 討 *thaw is ambiguous since Chinese may not have had vowel length | |
| summer | jun | jun | |
<ju.un> | not if <ju.un> was [ɟuːn] | |
| hundred | juun | jaɣun | |
<jau> | Shira Yughur vowel length secondary (uu < *aɣu); no known alternation with <ja.au> that might confirm vowel length; use of <jau> to transcribe Liao Chinese 招*tʂaw is ambiguous since Chinese may not have had vowel length | |
| red | hlaan | ulaɣan | |
<l.iau.qu> ~ <l.iau.qú> | Shira Yughur vowel length secondary (aa < *aɣa); possible that pre-Proto-Mongolic had a long vowel corresponding to Khitan iau, but I doubt that, as the long vowel of *pulāgan would correspond to zero in Korean pulk- 'red' | |
| 270 | blood | cüsin | cisun |
|
<c(i).i.is> | not if <c(i).i.is> was [ciːs] |
| 271 | horse | moori | morin |
|
<m(o).ri> | no; if Khitan had a long vowel I would expect <m(o).o.ri> with a phonogram for <o>; I assume the inherent vowel of <m(o).ri> was short; cf. the Hebrew and Arabic practice of not writing short vowels while explicitly writing long vowels |
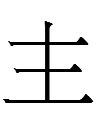
| good | sain | sain | |
<ś.ia> ~ <ś.iá.aɣ> ~ <ś.ên> |
not if the second Khitan word had long [aː] | |
| nine | hyisin ~ shisin | yisün | |
<is> | yes | |
| ten thousand | temen | tumen |
|
<tum(u)> | not if <tum(u)> was [tuːm(u)]; Chinese transcription 圖木里 *thumuli for <tum(u).úr> is ambiguous since Chinese may not have had vowel length | |
| 272 | person | küün | kümün |
|
<ku>, <ku.u> | Shira Yughur vowel length secondary (üü < *üpü following Janhunen [2003: 6]); not clear if Khitan <ku> and/or <ku.u> was [kuː]; also not clear if that [kuː] was also the result of contraction (though Khitan seems to have retained *p lost in Mongolic, at last in initial position) |
| 283 | dog | noqoi | noqai | |
<ń(i).qo> | yes; was the common ancestor *nioqa? |
There is not one clear correlation between nonsecondary vowel length in Shira Yughur and a possible long vowel in Khitan, and there is at least one instance of a potential primary long vowel in Shira Yughur and a short vowel in Khitan ('horse'). (If the long vowel of Shira Yughur moori is secondary, its lengthening had nothing to do with the contraction found in 'hundred', 'red', and 'person'.)
The name Shira Yughur contains the word shira 'yellow' with a short vowel. It would be interesting to see if Khitan had a cognate with a short vowel. Unfortunately, the only Khitan word for 'yellow' that I know of is
<n.i.gu>
I do not know whether
<GOLD> <GOLD♂>
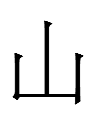
was also pronounced nigu or a synonym (e.g., a cognate of shira). <n.i.gu> and <GOLD> were Khitan names for the 金 Jin 'Gold' (despite the resemblance of the latter to Liao Chinese 山 *ʂan 'mountain' - was there a Khitan word like śan for 'gold'?).
*1.25.0:40: The reading <tai> was suggested by Andrew West.
14.1.23.17:20: KHITAN BLOOD ANALYSIS
The first morpheme of
<c.i.is.d.bun> 'filial piety'
is
<c.i.is> 'blood' (cf. Mongolian cisun 'id.')
What are the origins of its three phonograms?
<c> has reminded me of the left side of 雑 or its even simpler form 杂. Both are currently used as variants of 雜 which was read as *tsa in Liao Chinese. But I don't know if 雑 was used in 10th century northeastern China. (It was used in the northwest. See Dunhuang su zidian, p. 531). 杂 was a variant of 朵 *two in the Liao Dynasty according to Longkan shoujian. Moreover, even if one or both simplifications of 雜 were known to the Khitan, *ts sounded like Khitan s to Khitan ears, not Khitan c. So the resemblance between this phonogram and 雑/杂.
The Old Turkic characters 𐰲 č and 𐰱 či/ič vaguely resemble Khitan <c> with their vertical lines flanked by symmetrical diagonal lines, but the similarity is far from striking. Kane's (2009: 14) description of Murayama's unsuccessful attempt to derive the Khitan small script from the Old Turkic script makes me skeptical of any connection between the two.
<i> doesn't look like anything phonetically similar in sinography or Old Turkic.
is identical to the Chinese character 乙 yǐ, the second of the ten heavenly stems, which is notably used in the astronomical and Daoist word tàiyǐ 太乙 "Great One". Is it possible that 乙 was chosen to represent 'fifty' precisely because of the association of 乙 with 太乙, and because the Khitan pronunciation *tai for 'fifty' was homophonous with Chinese 太? This sounds like a very circuitous and contrived derivation, but perhaps it was precisely because of this sort of indirect derivation of characters that it is so hard to explain KLS [Khitan lage script] and KSS [Khitan small script] logograms.
Kane (2009: 32) proposed that palatal consonant phonograms had an inherent vowel <i>. If so, then I could also transliterate
as <ci.i.is>. Does the use of three <i>-characters in a row indicate an long or even an overlong vowel? Only a few languages have three degrees of vowel length. If 'blood' were cis, why not write it as <c.is>? Could Khitan preserve vowel length lost in Proto-Mongolic*?
Could <is> have been read as [si] after a vowel, just aswas read as [ri] after a vowel in<ir>/<ri>
<m.ir> = [mori] 'horse' (cf. Mongolian morin 'id.')?
If so, then 'blood' may have been [ci(ː)si] (and the correspondence of Khitan -i to Mongolian -u would need to be explained).
If not, was <is> an exception to the rules for VC/CV graphs because it was originally devised as a logogram for is 'nine' and the association with 'nine' was too firm to read it as [si]?
In spite of claims made to the contrary, it has been impossible to establish any quantitative correlation for the Proto-Mongolic vowels. While virtually all the Modern Mongolic idioms have distinctive long (double) vowels, these are of a secondary contractive origin. Occasional instances of irregular lengthening are observed in most of the modern languages, and in a small number of cases there would seem to be a correspondence between two peripheral languages, notably Dagur and (Huzhu) Mongghul, as in Dagur mood 'tree, wood' = Mongghul moodi id. < *modu/n. In spite of the seemingly perfect match, such cases are too few and involve too many counterexamples to justify any diachronic conclusion other than that of accidental irregular convergence.
It would be neat if the unknown Khitan word for 'tree' and/or 'wood' turned out to be <mo.(o.)od> with a (over)long vowel. Could Manchu moo 'tree, wood' with a long vowel have been borrowed from a Khitan mood? Should Jurchen
<mo> 'tree, wood'
be reconstructed as moo with a long vowel? (Ming Chinese lacked phonemic vowel length, so the transcription of this Jurchen word as 莫 *mo could have represented [mo] or [moː].)
14.1.22.23:59: TRANTER ON THE KOREAN-KHITAN CONNECTION
Last night I found a paper I've been curious about for some time: Nicolas Tranter's (2002) "The 'Ideal Square' of Logographic Scripts and the Structural Similarities of Khitan Script and Han'gul":A comparison of the Khitan Small Script and Korean han'gŭl shows a striking structural similarity of two essentially phonetic scripts that combine 'letters' into large blocks. These blocks in han'gŭl correspond to the syllable, whereas in Khitan they correspond to the word-level.
To illustrate the similarities and differences between the two scripts, here's the Korean word han'gŭl in both of them:
Hangul: one block per syllable; one segment per grapheme
| 한 | ㅎ <h> | ㅏ <a> | 글 | ㄱ <k>* |
| ㅡ <ŭ> | ||||
| ㄴ <n> | ㄹ <l> | |||
Khitan small script: one block per word; one-plus segment per grapheme
 |
<x> (Khitan had no [h]?) |
<a> |
<an> |
<g> |
|
<ul> (not sure if Khitan had /ɯ/) |
||
Khitan compound words (including polysyllabic Chinese loanwords) may be written as series of Khitan small script blocks, so in theory one could write the compound word han'gŭl as two blocks <x.a.an g.ul>, but I've treated han'gŭl as indivisible since its parts (han 'great'/Han 'Korea'** and kŭl 'writing') are meaningless in Khitan.
Examples of Khitan small script block sequences
~
<u.ur ai> ~ <u.ur.ai> 'ancestor' (lit. 'preceding father')
<xoŋ di> 'emperor' < Liao Chinese 皇帝 *xoŋ ti (no <xoŋ.di> block spelling exists AFAIK)
On my site I normally squish Khitan small script 5+-element oblong blocks so they are the same height as 1-4 element blocks: e.g.,
Khitan small script blocks with 5-1 elements
| 5 elements | 4 elements | 3 elements | 2 elements | 1 element | ||||
 |
 |
 |
 |
 |
||||
| 1 | 2 | 1 | 2 | 1 | 2 | 1 | 2 | 1 |
| 3 | 4 | |||||||
| 5 | 3 | 4 | 3 | |||||
| <x.a.an.g.ul> | <mu.u.j.d> | <n.i.gu> | <qid.ún> | <doro> | ||||
| 'hangul' | 'sacred' (pl.) | 'Jurchen' | 'Khitan' | 'seal' | ||||
However, I maintained the oblong shape when I first wrote <x.a.an.g.ul> because it is common in the Khitan small script and absent in hangul (and even the four-tier stacks of phonograms in Gale's [1903] Korean Grammatical Forms).
(As the only probable examples of the Jurchen small script contain only three phonograms, we do not know whether that script had oblong blocks like the Khitan small script, though such a block is in the Jurchen large script in a medallion reproduced in 方氏墨譜 Fangshi mopu.)
Tranter provides a detailed comparison of hangul and the Khitan small script on pp. 518-520. One difference I would add is that Khitan CV symbols may double as VC symbols depending on context: e.g.,
represented both ri and ir depending on context in
<m.ri> 'horse' (cf. Mongolian morin 'id.') and <ir.g.en> (a Khitan title transcribed into Chinese as 夷離堇 *ilikin; borrowed from Turkic irkin 'tribal chief')
Here are my notes on the rest of his paper:
p. 506
"Khitan Large Script appears to have been predominantly logographic in nature"
I used to think that too, but now the Khitan large script appears to be more syllabic. The only pure logograms in the large script might be those which represent morphemes lacking homophones. Otherwise I assume any logogram can also be used as a phonogram: e.g., 冬 <uul> 'winter' (cf. Chinese 冬 'winter') can also be used to write the first syllable of uulge- 'to marry'.
p. 508 (accidentally left this page out; added 1.23.1:46)
First, Tranter analyzed
<c.i.is.d.bun> 'filial piety'
as having a case ending, but it has none as far as I know. <c.i.is> is 'blood' (cf. Mongolian cisun 'id.'); the rest may be another noun or a derivational suffix.
Second, Tranter referred to Khitan small script "manuscripts". To the best of my knowledge, no Khitan small script manuscripts have been discovered. The first Khitan large script manuscript fragment was identified in 2002, and the only other Khitan large script manuscript (Nova N 176) was identified by Viacheslav Zaytsev in 2010.
p. 509
First,
There is a possibility that King Sejong and his scholars may have been aware of the earlier existence of Khitan Small Script, considering that the Khitan script existed for two centuries while the two states shared a border, but with almost 250 years between the prohibition and demise of Khitan Small Script and the creation of han'gŭl this is a difficult case to argue.
If the Khitan small script was used up to the end of the Kara Khitan Khanate and a bit after that, then the gap between the demise of that script and the birth of hangul might have been about 200 years.
The block style of writing the Jurchen large script might have been current at the time hangul was devised. 15th century Koreans knew of the script of their Jurchen neighbors (see p. 518) and "Jurchen was studied as a regular foreign language in the [司譯院] Sa-yŏk-wŏn [Institute of Translation Management]' (Kane 1989: 88).
In any case, the Jurchen small script seems to have died out rapidly and is highly unlikely to have influenced hangul.
Second, offhand I don't recall anyone equating whole sinographs with graphemes. Would anyone say that the 64-stroke sinograph 𪚥 is a single grapheme rather than a combination of four 龍 graphemes?
Third, is jihaofu 记号符 'symbol mark'? The word is rare with fewer than 71 results in Google. (The 71 include sequences of the word 记号 jihao 'symbol', a punctuation mark, and 符 fu 'mark'.)
Fourth, I would not regard jihaofu as "functionless". I would call them 'distinguishers' since they "just serve to make the logograph unique": e.g., the jihaofu (if I understand correctly) 辶 of 迦 (phonogram for Sanskrit ka) differentiates it from 加 'to add'.
p. 513
Is it possible that the Japanese phonogram stack 麿 maro (< 麻 ma + 呂 ro) was influenced by lost Korean peninsular models ancestral to the Korean phonogram stacks in my last post?
p. 515
Should the Baxter (1992)-style Middle Chinese notation for the sinograph 𠂇 (now normally written 左) be tsaX instead of tsa? (-X indicates the rising tone.)
p. 519
In conclusion, therefore, it is intriguing that the Khitan script shared a fundamental principle with han'gŭl, but, though it is impossible to prove that knowledge of the nature of Khitan script did not have some small role in the creation of han'gŭl, we should not expect to find any evidence to support this. We do, however, have powerful evidence for a common ancestor of both scripts in terms of influence, namely the Chinese character script.
I agree that the similarities between hangul and the Khitan small script are not coincidental, though I think both may be products of two branches (Shilla/southern and Parhae/northern) of a peninsular tradition of stacked phonograms. See the family tree in my previous post.
*Korean voiceless /k/ becomes voiced [g] after voiced /n/.
**Han 'great' and Han 'Korean' are unrelated homophones. The latter is the Sino-Korean reading of 韓 which is ultimately a Sinicization of a peninsular name like *gara:
Early Koreanic (?) *gara > Old Chinese *gar > Late Middle Chinese *xan > Sino-Korean Han
According to Martin et al. (1967: 1792), han 'great', Han 'Korea', and han'gŭl all have short a (even though 韓國Hān'guk 'Korea' has long a!), whereas Naver's Korean dictionary lists all but han 'great' as having long a. Martin's vowel lengths are largely in accordance with the lengths I would predict based on Middle Korean tones. I would, however, have predicted *Han'guk with a short *a. I do not know why the same morpheme (韓 Han) has two different lengths.
In any case, I spelled han'gŭl in Khitan with <a.an> because Liao Chinese *-an was spelled <a.an> (Kane 2009: 250), and it is not clear whether the *a of that Liao Chinese rhyme was long or not.
14.1.21.23:59: KOREAN STACKS AND KHITAN BLOCKS
After looking through Gale's 1897 Korean-English dictionary last night, I found his Korean Grammatical Forms (2nd ed., 1903) which had unusual characters in the left margin without comment. They initially reminded me of Jurchen characters. But Jurchen characters have ten strokes or less, and some of these mystery characters were more complex (see below). Then I realized I was looking at stacks of sinograph-based phonetic symbols for Korean: e.g., this four-tier, sixteen-stroke stack on page 15 for the respectful interrogative <ha.ri.s.ka> harikka (in late 19th century pronunciation) 'does ... ?':
| Element | Reading | Derivation |
| 丷 | ha < hă* | < hă-, Middle Korean translation
of 爲 Sino-Korean wi 'to do' |
| 日 | ri | 里 Sino-Korean ri; not to be confused with 日 Sino-Korean il |
| 叱 | s | unknown; does not match ch- of 叱 Sino-Korean chil 'to scold'** |
| 可 | ka | 可 Sino-Korean ka |
All four elements are in this list of kugyŏl characters including both full sinographs and their made-in-Korea abbreviations. (叱 is listed under its modern word-final pronunciation [t].)
This stack is reminscent of made-in-Korea sinographs (國字 kukcha) which may consist of a sinograph atop a hangul letter or a sinograph atop another sinograph: e.g.,
乫 kal = 加 Sino-Korean ka + 乙 Sino-Korean ŭl
乭 tol = tol, Korean translation of 石 Sino-Korean sŏk 'stone' + 乙 Sino-Korean ŭl
哛 and 兺 ppun < spun = 叱 s (see above) + 分 Sino-Korean pun
According to Wikipedia, 哛 is normally a transcription character whereas 兺 (which looks as if it should be for *puns) is for -ppun 'only'
Wikipedia has many more examples of both types of kukcha. The sinograph-hangul hybrids obviously must postdate King Sejong's invention of hangul in 1443/4 (unless one were to claim that hangul was a systematization of preexisting phonetic elements in kukcha). But what about sinograph-atop-sinograph and sinograph-kugyŏl abbreviation stacks? When were they created relative to
- the creation of the vertical ligatures of the Khitan large script (c. 920-)
- the creation of the Khitan small script (with phonograms grouped in blocks from left to right as well as top to bottom) c. 924
- the creation of the block style of the Jurchen large script (c. 1120) seen in a medallion reproduced in 方氏墨譜 Fangshi mopu (1588) and an undated travel pass found in Shajgino, Russia in 1976
- the creation of the Jurchen small script (structurally similar to the Khitan small script) in 1138
- the creation of the Hphags-pa script (with letters stacked in vertical syllabic blocks) c. 1269
- the creation of hangul in 1443/4
In other words, who (re)invented stacking, and how did the practice spread? The Jurchen must have gotten the idea from the Khitan, but did the Khitan get it from Parhae (which may have had its own stacked characters; see possible examples in table 4 of Li Qiang 1982: 117), and are kugyŏl stacks, phonogram stack kukcha, and hangul ultimately offshoots of that same peninsular tradition?
1.22.0:33: ADDENDUM: A family tree of stacked scripts
| Hphags-pa (combines Tibetan-based letters in syllabic groups with Mongolian-style vertical layout; not related to the other stacked scripts) |
Peninsular phonogram stack kukcha | |
| Parhae branch | Shilla branch | |
| Khitan large script vertical ligatures | kugyŏl stacks | |
| Khitan small script | ||
| block-style Jurchen large script | hangul | |
| Jurchen small script | ||
Scripts on the same horizontal level are not contemporaneous: e.g., Hphags-pa and hangul both postdate the Jurchen small scripts.
The chronology within each vertical column may not be correct: e.g., the combined styles of the Khitan and Jurchen large scripts could respectively postdate the Khitan and Jurchen small scripts. (There is, however, no doubt that the isolated styles of the Khitan and Jurchen large scripts respectively predate the Khitan and Jurchen small scripts.)
*By 1893, Korean a and ă [ʌ] had merged as a, and Gale spelled hă- 'to do' as ha-.
**I used to think 叱 for s reflected an Old Chinese reading *sʰit (as reconstructed by Starostin 1989: 574) for its phonetic 七, but 叱 had a standard Middle Chinese initial *tɕʰ- which cannot be from Starostin's Old Chinese *sʰ-. Schuessler (2009: 32) and I reconstruct its Old Chinese initial as *tʰ-, not *sʰ-. Perhaps that *tʰ- is from an even earlier *st-, but such a cluster would have been long gone by the time sinographs were first used to write Korean. Zhengzhang's Old Chinese reconstruction for 叱 at ytenx.org is *n̥ʰjid, whose initial is even less like s. Pan's Old Chinese reconstruction at eastling.org also has a nasal initial: *n ... id. (The character 坖 appears in place of whate between n and i due to an encoding issue.)
I do not know why 叱 has a Sino-Korean reading with ch- [tɕ] rather than chh- [tɕʰ] which regularly corresponds to Middle Chinese initial *tɕʰ-. The alternate reading chŭl also has an inexplicable vowel.
I later thought that s for 叱 was taken from the Middle Korean translation skutsits- for 叱 'to scold', but that form is first attested in 續三綱行實圖 Sok samgang haengshilto (1514), and the earliest attested forms for the verb are kutsit- (月印千江之曲 Wŏrin chhŏngang chi kok, 1447) and kutsits- (釋譜詳節 Sŏkpo sangjŏl, 1447) without an initial s-.
So now I wonder if there was an unattested Korean word for 'scold' with initial s-.
14.1.20.23:54: THROUGH OLD THIS
The title sounds like through all this to me. It's a literal translation of the Chinese character spelling 通古斯 that I found in Martin et al. (1967: 866) for Korean 통구스 Thonggusŭ 'Tungus' while flipping through it for my entry on the Korean words for 'boxed lunch'. Although not as bizarre as the readings in my previous entry, 통구스 Thonggusŭ is still not the sum of its parts:
通 thong 'through' (so far, so good)
古 ko (not gu < ku*!) 'old'
斯 sa (not sŭ!) 'this'
The spelling 通古斯 appears to be taken directly from Mandarin, but the reading is part-Sino-Korean, part-Koreanized Mandarin. The pure Sino-Korean reading (not in Martin et al. 1967 or the Korean Wikipedia but in Google) is Thonggosa, and a pure Koreanized Mandarin reading would be *Thunggusŭ. When was the hybrid reading Thonggusŭ coined? (1.21.1:03: Thonggusŭ is still barely in use today as a reading. Googling for "통구스" and "通古斯" led to eight results [including two instances of 통꾸스 Thongkkusŭ]; "통구스" by itself sans characters [i.e., not as a reading] led to 5,640 results.)
Written Korean has changed a lot since 1967. Chinese characters are barely present. Foreign names are hardly ever written in Chinese characters unless they are Chinese or Japanese**, and even then, the characters are secondary: e.g., Xi Jinping's Korean Wikipedia entry is titled 시진핑 Shi Chinphing in Koreanized Mandarin rather than Sino-Korean 습근평 Sŭp Kŭn-phyŏng. The Chinese characters 習近平 for his name do appear in his entry, but they are no more important there than in the English entry; they are just there for reference. They are not the normal way to write his name in Korean. 習近平 seems to always appear in parentheses after 시진핑 Shi Chinphing in the online Korean edition of 東亞日報 Dong-A Ilbo; it is not a standalone default spelling. I wonder how many readers can write his name in characters from memory. Perhaps more than I think, since his name's characters happen to all be relatively common (but still not as common as the handful of characters still regularly used in papers like 北 Puk 'North [Korea]' which probably survive because they stand out in otherwise all-hangul headlines and can be used as abbreviations for longer words).
Korean readings of Chinese characters are extremely regular compared to Japanese readings. Combinations of characters almost never have special readings which is why 통구스 Thonggusŭ for 通古斯 is so odd. I wish I could find other examples in Martin et al. 1967. I doubt any such examples are still in use today.
Tonight I happened to find a potential example: the English and Korean Wikipedias give 奇一 as the Korean name of James Scarth Gale, but do not specify whether they were read in Sino-Korean as 기일 Ki-il (긔 일 Kŭi-il in the spelling that dominated in his lifetime) or in Koreanized English as 게일 Keil. (An unaspirated k is the closest Korean equivalent of English [g].) Was 긔 kŭi ever pronounced [ke] just as the genitive postposition 의 ŭi is pronounced [e] today? Unfortunately Gale's 1897 Korean-English dictionary does not include ㅢ ŭi in its pronunciation key.
*Korean /k/ regularly voices to g after a nasal.
**Here's a rare exception. I found 33 Google results for 土耳其 Thoigi (the Sino-Korean reading of Mandarin Tuerqi 'Turkey') leading to a single article in the online Korean edition of 東亞日報 Dong-A Ilbo. That article has 土耳其 in parentheses after the normal Korean term 터키 Thŏkhi. The Chinese character term is misspelled as 士耳其 Saigi in the title!
14.1.19.23:59: SEVEN WATERFALLS, SEVEN PUZZLING READINGS
Although I am far from understanding how the extinct Tangut script works, on occasion I see modern Japanese spellings that baffle me. Their readings are not the sums of the readings of their parts. I encountered six of these during the last four months:
1. 大仏 Osaragi (normally Daibutsu; this one has bothered me for 23 years)
2. 河 津七滝 Kawazu Nanadaru ('Seven Waterfalls of Kawazu'; looks like *Kawazu Nanataki; the waterfalls all have names ending in -滝 -daru)
3. 熊谷 Kumagai or Kumagae (as well as Kumagaya)
4. 府中 Kō (normally read as fuchū 'provincial capital')
5. 精進 Shōji (looks like *Seishin or *Shōshin)
6. 東海林 Shōji (as well as Tōkairin)
7. 寿斗 sushi (looks like *suto; not a normal spelling; the Japanese Wikipedia cites an article 「すしの事典」 Sushi no jiten "An Encyclopedia of Sushi" by 吉野昇雄 Yoshino Masuo in the March 1971 issue of『近代食堂』 Kindai shokudō (Modern Dining Room).
If you thought those were easy, can you read these Kansai place names?
The Japanese Wikipedia has three explanations for 大仏 Osaragi. I find none convincing. They involve changes that are unusual for Japanese (though all phonetically plausible out of context): *n > r, *ō > o, o, e > a.
滝 -daru is from *-N-taru with genitive *-N- < *nə and *taru 'waterfall', which is probably short for Old Japanese tarumi 'hanging water'.
The regular reading of 熊谷 Kumagaya is from kuma 'bear' + ga (genitive) + ya 'valley'. Ya is not reduced to i or e anywhere else. Is gai from ga (genitive) plus another i like 'well', or is it a single morpheme? Is e 'river'? Is Kumagai from Kumagae 'bear -'s river'?
府中 Kō is probably derived from 国府 kō, an irregular compression of kokufu 'provincial capital'.
精進 Shōji reminds me of 冷泉 Reizei: the first syllable may have once ended in a nasal vowel conditioning the voicing of the following consonant and the second syllable is missing a final nasal (*Syaũsin > Shōji).
ecsetiam explained that the 東海林 Tōkairin who were 庄司 shōji 'manor managers' in feudal Japan became simply known as Shōji, though the spelling of their name did not change.
寿斗 sushi shares its first half 寿 with the common spelling 寿司, but the second half 斗 is never read as shi anywhere else. Jesse Good speculated that "it has to do with Masu and its use for drinking sake."
14.1.20.0:40: 寿 su 'long life' is purely phonetic in 寿斗/寿司 sushi. So is 司 shi 'manager' (as in 庄司 shōji above). sushi is an obsolete adjective 'sour' whose root is 酢 su 'vinegar'. Yoshino (1971) reported 酢 as another spelling of sushi. Was 鮓 'salted fish' used to write sushi because it contained 魚 'fish' and the right side of 酢 'vinegar'? -shi is the Old Japanese final predicative (and sometimes attributive) suffix for adjectives. The only other nouns I can think of that are derived from -shi-adjectives are male personal names: Takashi 'high', Kiyoshi 'pure', etc.
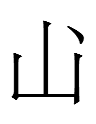





{kind=link}
{kind=link}