~
~ /
/
13.8.10.22:39: Å-SYMMETRY IN AVESTAN VOWELS (INTRODUCTION)
To eyes (and ears) accustomed to the Sanskrit vowel system (below; I excluded syllabic liquids),
| a | i | u | e [eː] < *ai | o [oː] < *au |
| ā | ī | ū | ai < *āi | au < *āu |
Avestan has a lot of 'extra' vowels (in bold):
| a | ą̇ | å | i | u | ə | e | o | (ai) | aē | (au) | ao |
| ā | ą | å̄ | ī | ū | ə̄ | ē | ō | āi | ōi | āu | ə̄u |
(8.11.3:33: I have only listed vowels and diphthongs from Beekes [1988: 12-13] except for short ai and au which are but two of many Avestan V(V)i and V(V)u sequences absent from Sanskrit: e.g., aēi, aou, etc. Jackson [1892: 3, 16] also mentioned ə̄e and āa.)
One might think that Avestan preserved many vocalic distinctions lost in Sanskrit. However, Beekes (1988: 38, 40, 52, 101) reconstructed only six vowel phonemes and four diphthongs for Gatha (i.e., early) Avestan and regarded the rest as allophones:
| /a/ | /i/ | /u/ | /ai/ | /au/ |
| /ā/ | /ī/ | /ū/ | /āi/ | /āu/ |
Next: How did Beekes manage to minimize the Avestan vocalic inventory into a Sanskrit-like system?
13.8.9.23:59: WHICH IS MORE CONSERVATIVE, AVESTAN MRŪ OR SANSKRIT BRŪ?
At the end of "W-ʔas There an ʔA-ugment?" I mentioned mraot̰ /mraut/ 'he said' as an example of an Avestan imperfect without the augment a- /ʔa/. Its root is √mrū < *mruʔ and one would expect its Sanskrit cognate to be √*mrū, but the actual Sanskrit form is √brū.
Which form is more conservative? Accustomed to seeing Avestan through Indocentric eyes, I initially guessed Sanskrit, but I should have realized that Sanskrit was the innovator because nasal-liquid clusters like mr- seem to be rarer than stop-liquid clusters like br-, and it is more likely that the former would shift to the latter.
Moreover, most non-Indo-Iranian cognates have a nasal: e.g., Czech mluviti 'to speak' (-ti is an infinitive suffix). An exception is Tocharian B pälw-. Was there an intermediate *bl-stage between päl- and Proto-Indo-European *ml-?
(8.10.0:30: Tocharian devoiced all stops. I assume ä [ɨ] was inserted to break up the cluster *bl-. If it had been inserted between *m and *l, there would have been no reason to dissimilate *m from the following sonorant *l.)
8.10.1:20: The Sanskrit cognate of Avestan mraot̰ is abravīt which not only has the augment a- but a long -ī- between the root -brav- and the suffix -t. Why isn't the Sanskrit form *abrot < *abraut? Sanskrit √brū is a class II verb, and some class II verbs have a short -i- (not -ī-!) between their final consonants and consonant-initial suffixes: e.g., svap-i-ti 'sleeps' (but not svap-anti 'they sleep' with a vowel-initial suffix). I think long -ī- is from the final *-ʔ of the root plus the union vowel -i-: *ʔa-mrauʔ-i-t > abravīt. The union vowel is absent from Avestan mraot̰ (and from Avestan in general). One might think that suffix is a Sanskrit innovation, but it is also in Latin and Slavic: e.g., Latin sōp-i-ō 'I sleep', Old Church Slavonic sup-i-tŭ 'sleeps' and mluv-i-tŭ 'mutters' (Burrow 2001: 321-322). Perhaps it was already on the wane in Proto-Indo-Iranian. It is not always present where one would expect it in Sanskrit: e.g., the infinitive of √svap is svap-tum, not *svap-i-tum.
13.8.8.23:16: W-ʔAS THERE AN ʔA-UGMENT?
For twenty years, my main reference on Avestan was Jackson's Avesta Grammar (1892). In 2009 I discovered Skjærvø's online works, but I didn't get ahold of Beekes' A Grammar of Gatha-Avestan (1988) until I bought it on sale last February.
Seeing Avestan through Beekes' eyes was a bit of a revelation, as he reconstructed a glottal stop phoneme absent from the Avestan script and from Jackson and Skjærvo's transcriptions: e.g., /ʔaʔaram/ for ārəm 'I reached' (p. 84), a combination of the augment /ʔa/, the root /ʔar/, and the first person singular ending /am/. An initial glottal stop is often ignored in orthographies (e.g., English), but I am surprised that intervocalic glottal stop wasn't indicated by a vowel letter sequence: e.g., *aarəm (cf. ʻokina-less spellings of Hawaiian with VV for [VʔV]: Hawaii for [havaiʔi]). Still, I can believe that /ʔaʔa/ was pronounced as [ʔaː] and written as ā since /Vʔ/ became [Vː] before consonants and in word-final position (p. 83).
However, I was skeptical that as 'he was' can be synchronically interpreted as /ʔaʔas/, a combination of the augment /ʔa/, the root /ah/ < *as (cognate to Sanskrit √as and English is), and the third person singular ending *-t which was lost after blocking the lenition of *-s to -h: final *-s after *a became -h (p. 80), but final *-st became -s (p. 102). (The *-t was later restored "[i]n many cases".) If as contained the augment, why isn't it *ās with an initial long vowel like ārəm or Vedic Sanskrit ās < *ʔa-ʔas-t 'he was'?
Could /ʔaʔa/ contract to a short vowel /ʔa/ even though the shorter sequence /ʔaʔ/ would be pronounced [ʔaː] before a consonant or in word-final position?
Is as an error for *ās? Beekes wrote,
In the course of a thousand years of oral tradition errors must have crept in, and the length of vowels was probably much more liable to errors than other points of the sound system. This would be all the more understandable if length was not phonemic (with all or some vowels) in the language of the people who handed the text. (p. 49)
(8.9.00:48: Beekes investigated instances of "[l]ong ā for expected short a" on pp. 46-48, but did not include as in his list.)
Moreover, Jackson (1892: 137) wrote that
For metrical purposes it seems sometimes that augment must be restored in reading where the texts omit it.
Does the meter imply a long *ā?
Could as simply lack the augment like other imperfect forms such as mraot̰ /mraut/ 'he said' < √mrū < *mruʔ?
13.8.7.21:59: WHERE KŬ-LD THAT QI COME FROM?
Khitan
qi 'that' (in the large and small scripts)
may have been something like [qʰɪ], [qʰɨ] or [qʰɯ]. The last two are vaguely like Korean kŭ [kɯ] 'that'. Alexander Vovin (2007) has found Koreanic loans in Jurchen and Manchu, and if the Khitan script is derived from a Parhae script originally devised for a Koreanic language, it would not be surprising if Khitan also had Koreanic loans.
Although there is no evidence for uvulars in Koreanic, perhaps Khitan harmony rules forbade a velar-[ɨ/ɯ] sequence and [qʰɨ] or [qʰɯ] was the closest possible Khitan syllable with the same vowel.
There is one major problem with this hypothesis. If Khitan had borrowed a word as basic as 'that', there should be other prominent Korean loans in Khitan, but no other Koreanic loans have been identified. It is likely that qi and kŭ are merely monosyllabic soundalikes.
13.8.6.23:56: COLD SPRING
冷泉 'cold spring', the posthumous name of a Japanese emperor (r. 967-969), looks as if it should be read Reisen, but is actually pronounced Reizei.
The -z- could reflect an earlier *-nz- conditioned by the now-lost nasalization of the preceding -i-: *reĩs- > *reĩnz- > Reiz-. Other emperors' names also have a *z whose voicing is from a preceding nasal segment:
反正 Hanzei < *pan seĩ (mythical)
平城 Heizei < *peĩ seĩ (r. 806-809)
陽成 Youzei < *yaũ seĩ (r. 876-884)
Another possibility is that -z- is from *zen, which is a hypothetical Sino-Japanese borrowing of Early Middle Chinese 泉 *dzwien (as opposed to Late Middle Chinese 泉 *tsɦwien, the source of the Sino-Japanese reading sen). The biggest problem is the final -i fcorresponding to Chinese *-n. Are there any other cases of this correspondence?
8.7.1:30: Was -n changed to -i in the emperor's name to avoid homophony with the common noun 冷泉 reisen 'cold spring'?
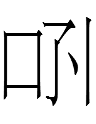
13.8.5.22:22: HU IS BEHIND THAT QI?
Khitan
<qi> 'that' (here in the small script; see "What Is the Qi to That Body?")
has a synonym (?)
<qi.ɣu> (qi.hu in Kane's transcription)
in the small script. What is the difference between these two words? Both can occur before the singular noun
<ai> 'year'
so <qi.ɣu> cannot be a plural.
And what is the large script spelling of <qi.ɣu>? I presume <qi> would still be
but I have not yet seen <ɣu> as a reconstructed reading of a large script character.
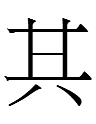
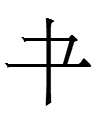
13.8.4.23:59: WHAT IS THE QI TO THAT BODY?
"Qi" was the Khitan word for 'that' as reconstructed in Kane (2009: 121). It may have been pronounced [qʰɪ] - closer to key than to qí [tɕʰi˦˥], the Mandarin reading of 其 'that'. The Khitan large script often has characters that not only resemble Chinese characters but even represent morphemes with similar semantics, so one might expect qi to be written as
which looks like 其 'that' minus a stroke. However, that character was actually <x(i)> (cf. its Liao Chinese reading *khi) and the actual Khitan large script character for qi looked like Chinese 身 'body' minus a stroke:
The first of those two characters is identical to a Dunhuang variant of 身.
Why would qi be written with a 'corporal' derivative? Qi did not sound like Liao Chinese *ʂin 'body' or any other word for 'body' in the region:
Mongolian beye(n)
Jurchen and Manchu beye (with cognates throughout Tungusic; a borrowing from Mongolic)
Korean mom
Japanese mi < *mo-i (a borrowing from Koreanic)
Kane (2009) did not list a Khitan word for 'body'. Could these 'body'-like graphs represent a qi-like Khitan word for 'body' as well as qi 'that'?
Last night it occurred to me that maybe the 身 'body'-like graph for 'that' is a distortion of Chinese 其 'that'. However, I cannot find any 身-like Chinese variants of 'that' (and as I noted above, the one exact match I did find for Khitan qi was a variant of 身 'body').
Another possibility is that the 身 'body'-like graph is an abbreviation of a more complex graph containing 身 'body' like 銵 *khɛŋ whose reading vaguely resembles Khitan qi. But did the creator of the Khitan large script (or its possible Parhae predecessor) know about that obscure graph? If not, what other 身-graphs could be sources of qi?
8.5.4:25: There are not many 身 'body'-graphs in common use. One high-frequency 身 'body'-graph is 射 *ʂe 'to shoot'. Was there a Khitan verb qi- 'to shoot'?
The reduction of a complex graph (銵, 射) to a simpler Khitan large script phonetic symbol could be described as 'katakana-ization' since the same process produced katakana: e.g., 幾 > キ ki.
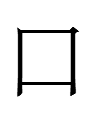
Could the Khitan small script character 口 for qi have been 'katakana-ized' from a Chinese character containing 口: e.g., 器 *khi 'vessel'? Or was it extracted from the boxy part of the large script character? The latter seems unlikely as I don't know of any other small script characters derived from large script characters. The two scripts do share shapes but identical-looking characters have different values: e.g., 一 is 'one' in the large script but 'north' in the small script.
*Perhaps *ʂin was phonetically [ʂɪn] with a near-high vowel [ɪ] since its rhyme was borrowed into Khitan as <en> as well as <in>.