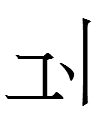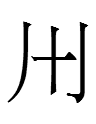 ~
~
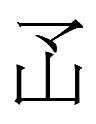
12.8.18.23:59: THAT YU-NI-KŬ COMPONENT
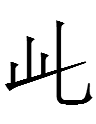
Last night, I wrote that the Khitan large script grapheme resembling the katakana ユ yu and the hangul letter combination 그 kŭ* was "shared with Tangut but rare in Chinese."
See group 5.9 of Andrew West's "Radical Index to Li Fanwen's Tangut Dictionary" for Tangut characters with ユ.
Today I had a hard time finding examples of 그 in Suxanov's (1980) Упрощенные начертания и разнописи китайских иероглифов. The only example I found was a variant of a character component resembling 耳 with ㄱ on top (p. 17).
The only example I've found so far in 異體字字典 is a variant of 兆 with 그 on the right of 乚, not the top. I can't say I've tried to look very hard, though.
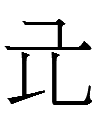
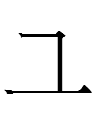
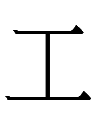
그 is a full-fledged character in the Khitan large script with a variant that looks exactly like Liao Chinese 工 *kuŋ 'work':
그 even occurs together with a graph I mentioned last night that has a 'horned hat' shared with Tangut:

(蕭袍魯墓誌銘 6.1-2)
The simplicity and high frequency of 그 lead me to guess that it is a phonogram. Andrew West's Khitan large script database glosses it as Liao Chinese 辛 *sin 'eighth Heavenly Stem; bitter'. Since the Khitan used colors in lieu of the Heavenly Stems and I doubt 'bitter' would appear often in funerary inscriptions, I think 그 stood for sin. So perhaps the four-character sequence above is
<sin ?u? un gui>
'Sin ?u? GEN country' = 'state of Sin ?u?'
if the third graph is <un> and in harmony with the preceding syllable.
According to Kane (2009: 181),
with 그 on top is a variant of the first half of
<śa ri> ~ <laŋ gün> 'court attendant'
which I have discussed before in "An Un-lai-kely Reading" and "High Am-bai-guity".
also has a third reading <ńiqo> 'dog'. I think this character might be related to Chinese 犬 'dog' but with ㄱ~ㄗ on top and 儿 instead of 人.
Perhaps the form with 卫 is original and that 卫 was changed to 그 under the influence of the second character <ri> - a case of graphic assimilation:
>
However, I don't know if the second spelling of 'court attendant' is attested.
To confuse matters further, Andrew West's database lists
as another variant of <śa> ~ <laŋ> ~ <ńiqo>. I wrote about this variant and its Jurchen lookalike in "Jurchen Polyphony 2: Scientia alba". Since
is Jurchen <shang> ~ <sa>, my guess is that
might be the original phonogram <śa> inherited from Parhae (and also retained in Jurchen) whereas
~

are Khitan-internal variations absent from Jurchen; the latter could have been the original Khitan large script logogram for <ńiqo> 'dog' which is graphically unrelated to Jurchen
~

<indahun> 'dog'
which seems to contain Liao Chinese 午 *ŋu 'horse (Earthly Branch)' of all things.
The exact match between a Khitan large script character and Jurchen <sa>
:
suggests either a common inheritance from Parhae or a Jurchen borrowing from Khitan.
| Stage 1 (when the Khitan large script was 'invented' [i.e., derived from Parhae] c. 920; no texts from this period survive) | Stage 2 (new variant; development of Sino-Khitan reading <laŋ>) | Stage 3 (confusion with 'dog') |
<śa> (both inherited from Parhae) |
<śa> (~ <laŋ> before <gün>) |
<śa> ~ (<laŋ> before <gün>) ~ <ńiqo> 'dog' |
|
<ńiqo> 'dog' (shape of character from Chn 犬?) |
||
The second half of 'court attendant', <ri> ~ <gün>, also has a variant with マ instead of 그:
I don't know of any other Khitan large script characters with マ (which happens to resemble hangul kă and is absent from Tangut).
According to Andrew West's Khitan large script database,
is a logogram for 初 'beginning' and
~
is a phonogram for Liao Chinese 鄜 *fu**.
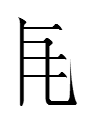
I don't know what the other Khitan large script characters with 그 represented:
~
~
The second of those characters
the only Khitan large script character with 그 on its left, looks unbalanced to my eye because it has a blank space at the top left which I wouldn't expect in a Chinese character. I see such a lack of balance occasionally in the Khitan and Jurchen large scripts. I wonder if such an off-balance aesthetic was inherited from the Parhae script that Janhunen proposed as their common ancestor.
15.4.0:40: The character above looks more balanced in its listing in N4631 (#1880).
(Post revised 15.4.5.0:40.)
*Frellesvig and Whitman compared Korean 그 kŭ 'that' to Old Japanese ko (kə in my reconstruction) 'this'. For a critique of this proposal, see Vovin (2010: 67-71).
**8.19.5:00: Liao Chinese 鄜 *fu < Middle Chinese *p(h)uə (dictionaries disagree on the initial) was the name of a place in Shaanxi.
鄜 looks like it should have been pronounced *luʔ since it appears to combine the phonetic 鹿 *luʔ < Middle Chinese *lok < Old Chinese *rok 'deer' with the semantic component 阝 for place names. (And in fact, it does have an alternate MC reading *lok in Guangyun.)
I initially thought that 鄜 was from an Old Chinese *pɯ-ro with a ro matching 鹿 OC *rok, but according to Shuowen, its phonetic is actually a 灬 'fire'-less abbreviation of 麃 *Tɯ-pau 'to run' (cognate to Md 跑 pao < ?*phauʔ 'run'?) ~ *Tbau 'a kind of deer'. I would now reconstruct 鄜 in Old Chinese as *Tɯ-p(h)o. However, I don't know of any other examples of Old Chinese*-au ~ *-o alternations in phonetic series, even though the two rhymes are phonetically similar. (Pulleyblank's 1991 Old Chinese reconstruction can account for the absence of overlap: my *-au and *-o correspond to his *-aɥ and *-aw with different final consonants.)
I should explain my use of the symbol *T- in a separate post.
The high vowel *ɯ blocks the 'emphasis' (pharygealization indicated as underlining) that normally developed in syllables with nonhigh vowels like *a and *o:
麃 *Tɯ-pau > *p(r)au > MC *pɨau > Liao *piau
麃 *Tbau > *brau > MC *bæu > Liao *phau
鄜 OC *Tɯ-p(h)o > *p(h)o > *p(h)uo > MC *p(h)uə > Liao *fu
cf. hypothetical OC *T-p(h)o > *p(h)o > *p(h)ou > MC *p(h)əu > Liao *p(h)eu
It is strange that there are almost no examples of emphatic *Po, as that would imply that all but one early OC *Po was preceded by a *Cɯ-presyllable. Even the sole exception has a nonemphatic alternate reading:
柎 'board on which a body lies inside in a coffin':
OC *boʔ > *boʔ > *bouʔ > MC *bəuʔ
OC *Cɯ-boʔ > *boʔ > *buoʔ > MC *buəʔ
(MC readings are from Karlgren 1957 and converted into my reconstruction.)
Perhaps late OC *Po (from emphatic *Po) and *Puo (from nonemphatic *Po) generally merged as *Puo.
12.8.17.23:59: THREE JADE KINGS
In "Some Private Interior", I wrote about the entries for 𠫣 (a Liao Dynasty Chinese character lookalike of Jurchen
di- 'come')
at zdic.net and in the 欽定四庫全書 edition at archive.org. Thanks to a donor I will call 冖乂冖八, I was able to check the entries for 𠫣 in other editions of 龍龕手鑑 (Liao Dynasty, 997 AD):
宋本新修 63A.3.5: 音三 '[has the] sound [of Liao Chinese] *sam 'three''
中華書局影印高麗刻本 184.2.4: 音王 '[has the] sound [of Liao Chinese] *oŋ 'king''
Neither matches zdic.net's quotation of the 龍龕手鑑: 音玉 '[has the] sound [of Liao Chinese] *ŋuʔ 'jade''.
Which of these readings are correct? There is no semantic gloss for 𠫣, but my guess is that it might be a variant of 參 *sam 'three' with 内 in place of the strokes beneath the topmost 厶. The phonetic gloss 三 could have been miscopied as 王 which in turn was then miscopied as 玉. Unfortunately, I cannot find 𠫣 as a variant of 參 in the 異體 字字典 Dictionary of Chinese Character Variants of Taiwan or in 黄征's (2005) 敦煌俗字典 Dictionary of Vulgar Characters from Dunhuang.
8.18.4:06: Addendum: Khitan private interiors
Although I have not yet seen 𠫣 as a Khitan large script (KLS) character, its components do appear in other characters.
KLS characters with 厶 (resembling Liao Chinese 厶 *sï 'private') on top
The first of these KLS characters
corresponds to the Khitan small script character
so I suspect the second KLS character with a dot corresponds to that small script character's dotted variant
I think the first member of each pair was originally a phonogram <uil> (for the homophones 'pig' and 'affair') and the second member was a derived phonogram <ui>, though the two might have been confused later. (Was Khitan -l lost after -i?) See Kane (2009: 66-67).
I don't know how these characters were pronounced or what they meant. The first two may be variants of each other, though I can't confirm that without finding them in the same context. The bottom of the first character resembles Liao Chinese 丹 *tan 'cinnabar', used to write the name 契丹 *khiʔ tan 'Khitan'. The third character resembles Liao Chinese 真 *cin 'true'.
KLS characters with 内
This is glossed as its Liao Chinese lookalike 内 *nui 'interior' in Andrew West's database. I have seen it only before
which happens to look like Liao Chinese 仚 *sien 'lightweight' (as defined in 龍龕手鑑).
The other three 内-characters elude identification:
The first and third have top elements that are shared with Tangut but rare in Chinese. The third may be a variant of
just as Jurchen
and

are variant spellings of di- 'come'. Unfortunately I have not yet found
in the same context. I have only seen the latter in the sequence
with a lookalike of Liao Chinese 信 *sin 'trust'.
12.8.16.23:59: THE GRAPEFRUIT SAGE FESTIVAL
I don't know anything about Hungarian sound changes with one exception*, so perhaps that's why I was surprised by this etymology of bölcs 'wise man' in Róna-Tas (1999: 364):
Turkic bügüchi > bűcs > bőcs > Hungarian bölcs
There are no stars for the intermediate stages. Are they attested?
I can understand how -ügü- became long -ű- through intervocalic -g-lenition.
-cs is simply a Hungarian spelling of -ch.
The final -i was lost.
But if ű lowered to ő, where did later Hungarian ű come from?
And most puzzling of all, why did long ő become short ö plus l? Is a similar change known elsewhere?** I might expect VC to become VV with compensatory lengthening (e.g., öl > ő), but not the reverse. (In my own English dialect, /ol/ has become [oɰ] which one could phonemicize as long /oo/.)
Another etymology two pages later is
id nap 'holy day' > ünnep 'festival, holiday'
The assimilation of -d to the following n- is not surprising.
Is id an archaic word for 'holy'?
i is currently neutral, which implies there might have been a front i : back ï distinction in the past. Did back a front to e to assimilate to a preceding front i?
And did i round to ü to assimilate to a distant p? Such long-range assimilation reminds me of this Sanskrit rule (Whitney 1889: 64-65):
The dental nasal न् n, when immediately followed by a vowel or by न् n or म् m or य् y or व् v, is turned into the lingual ण् ṇ if preceded in the same word by the lingual sibilant or semivowels or vowels - that is to say, by ष् ṣ, र् r, or ऋ ṛ or ॠ ṝ -: and this, not only if the altering letter stands immediately before the nasal, but at whatever distance from the latter it may be found: unless, indeed, there intervene (a consonant moving the front of the tongue: namely) a palatal (except य् y), a lingual, or a dental.
For example, the instrumental singular of राम- Rāma- 'Rama' is रामेण Rāmeṇa instead of रामेन Rāmena because the retroflex quality of the initial R- spreads through the sonorants between it and the n of the instrumental ending.
*I still remember h < *k (see Róna-Tas 1999: 38-39) which was in a historical linguistics textbook I read many years ago, but I've forgotten the other changes.
**Róna-Tas (1999: 39) regarded gyümölcs 'fruit' as having "evolved from the derivation of the very same Turkic stem" as another loanword from Turkic, szőlő 'grape'. Is the -ölcs of gyümölcs from an earlier -őcs, just as bölcs is from bőcs?
8.17.0:19: And what was that Turkic stem?
8.17.8:07: Ah, now things are making a bit more sense ... on p. 107, Róna-Tas wrote (the paragraphing, emphasis, and link are mine):
In Hungarian, the phonetic cluster short vowel + /l/ often changes to a long vowel, in such a way that the /l/ is dropped; or vice versa, the long vowel becoming shorter and a so-called inorganic /l/ being inserted [...] the Turkic bügüchi became bőcs in Hungarian, and later bölcs 'sage' [...]
If now and then an original /sh/ phoneme in Turkic became /ch/, then /lch/, and later /l/, as happened in [the Turkic language] Chuvash, then it cannot be said that the Hungarian adopted the /ch/, as in the word búcsú 'farewell', or the /lch/, as in the word bölcső 'cradle'; but (perhaps) did after all take the /ch/, as in the form *becsű [for 'cradle'?], and added an /l/ in Hungarian. Such, for example, is the Hungarian word gyümölcs 'fruit', whcih may have been borrowed from the Chuvash form jemich or jemilch.
Whatever the explanation, if the equivalent of the common Turkish /sh/ phoneme is the Hungarian /ch/ or /lch/, this is a Chuvash criterion [i.e., evidence for borrowing from Chuvash into Hungarian?].
It would also be conceivable that in this case we are dealing with an early change in Hungarian, i.e. that Hungarian adopted the Turkic word with an /sh/, which then became /ch/ in Hungarian [instead of already having become /ch/ in Chuvash before being borrowed]. In this event, the Hungarian /ch/ and /lch/ would not be Chuvash criteria [i.e., would be the products of Hungarian-internal changes and not evidence for borrowing from Chuvash?].
In numerous instances, the original Turkic /ch/ phoneme appears in the Hungarian as an /sh/: e.g.: the Hungarian kos [kosh] 'ram' < *kocs, Hungarian kés-ik [kesh-] 'to be late'< *kécs-, Hungarian kis [kish] 'small' < *kichi > kicsi [kichi]. We may also hypothesise that we are dealing with an early Hungarian /sh/ ~ /ch/ dialectal change. Which is to say that the Hungarian language may have adopted these words [from Turkic] at any stage of the Turkic /sh/ > /ch/ > /lch/ > /l/ chain of development.
Unmistakable Chuvash phonetic criteria [i.e., characteristics?] can be found in the Hungarian word szőlő 'vine/grape'. This word exists in Chuvash [what is its phonetic shape?], but means only 'berry' or 'wild vine'.
Here's what I'm guessing is going on within Róna-Tas' framework:
- Early Chuvash jemich without an -l- was borrowed into Hungarian as something like *gyümőcs which later developed an -l- and became gyümölcs 'fruit'. (I don't understand why Hungarian has rounded vowels corresponding to unrounded vowels in Chuvash.)
- Or early Chuvash jemilch (from even earlier jemich) with an -l- was borrowed into Hungarian, later becoming gyümölcs 'fruit'.
- Chuvash j and lch respectively became ç [ɕ] and l.
- Hence Chuvash jemilch became çemil (?) and was borrowed again into Hungarian, becoming szőlő 'grape'.
I wonder if there is a modern Chuvash reflex of jemi(l)ch.
12.8.15.23:59: HIGH AM-BAI-GUITY
In "An Un-lai-kely Reading", I was puzzled by the combination of a Khitan noun ending in 髙 ~ 高 <bai> with the genitive suffix <un> which normally follows nouns with <u>:
~
<? ? bai un> '?-GEN' (多 6.15-18; 15.24-27)
Last night, I realized that the solution was so obvious - what if 髙 ~ 高 had a Sino-Khitan reading <gau> based on Liao Chinese *kau* 'high'? 髙 ~ 高 could have been used as phonograms for either native or borrowed gau. I suspect these three-character sequences represent a native noun ending in -gau that was in harmony with the suffix -un.
Given that Khitan large script characters may or may not resemble Chinese characters and might have had two readings, one native and one Sino-Khitan, that could be used to write both native and borrowed words, there are eight possibilities:
| |
Signifying | Native reading | Sino-Khitan reading |
| Character resembling Chinese | Native word | 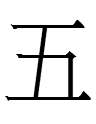 <tau> 'five' |
   <? ? gau> '... gau'? |
| Nonnative word |  <jau tau> 'bandit suppression commissioner' < Liao Chn 招討 *cauthau |
  <xoŋ di> 'emperor' < Liao Chn 皇帝 *xoŋti |
|
| Character not resembling Chinese | Native word | <śa ri> 'court attendant' |
(Do any examples exist? Have I forgotten something obvious?) |
| Nonnative word |   <ś oi> 'commander' < Liao Chn 帥 *šoi |
<laŋ gün> 'court attendant' < Liao Chn 郎君 *laŋkün** |
8.16.5:54: Was <bai> really a native reading for 髙 ~ 高? Those characters mean 'high' in Chinese - and their Tangut translation was 2bie (whose rhyme might be -ai in Huang Zhenhua 1983's reconstruction). Could Khitan <bai> be a loanword from Tangut? Is there a Mongolic word similar to <bai> and with height-relevant semantics?
If I am reading Andrew West's Khitan large script notes correctly, the graph
was glossed as Liao Chinese 上 *šaŋ '' and 尚 *šaŋ. I doubt it is an ambiguous logogram for two different words that happen to be homophones in Liao Chinese. I suspect it is either a phonogram<śaŋ> for the syllable śaŋ or a logogram for Sino-Khitan śaŋ 'high' (note how the graph contains 山 'mountain' on the left - symbolizing height?) that could be used to write other śaŋ-syllables.
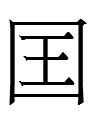
<śaŋ>? and 髙 <bai>/<gau>? together remind me of the modern Chinese names for the Tangut state listed in Kepping (1994: 358; translations into English are from Van Driem's translation of her Russian text; the choice of 'state' or 'country' for 国 seems arbitrary):
大白高国 Da Bai Gao Guo 'Great White Lofty State' (Shi 1988: 310)
大白上国 Da Bai Shang Guo 'Great White Upper Country' (Li 1983: 73)
白上大国 Bai Shang Da Guo 'White Upper Great State' (Cai 1986: 121)
which are all translations of
1phɔ̃ 2bie 2lhiẹ 2liẹ
lit. 'white high state great'
白高大夏国 Bai Gao Da Xia Guo 'White Lofty Great Xia State' (Shi 1988: 310)
白上大夏国 Bai Shang Da Xia Guo 'White Upper Great Xia Country' (Li 1983: 73)
which are both translations of
1phɔ̃ 2bie 2lhiẹ 2dʒwɨe 2liẹ
lit. 'white high great summer state'
Could
have something to do with the Tangut? I doubt it because I would expect the first character to be
'great', 'summer', or 'state'
not the unidentified character resembling 草. So for now I read the mystery three-character sequence as <? śaŋ gau>. Using Kane's 2009 question mark diacritic, I could call the first character <cảo> after the Mandarin reading cao of its near-lookalike 草.
*8.16.2:16: Liao Chinese unaspirated obstruents were borrowed as Khitan voiced obstruents; cf. how modern Mandarin unaspirated obstruents are pronounced as English voiced obstruents largely due to the use of voiced obstruent letters in Pinyin romanization: e.g., Md 北京 Beijing [pejtɕiŋ] as Eng [bejdʒɪŋ].
In previous posts I've experimented with writing Liao Chinese in a Kane 2009-like Pinyin-based romanization: e.g., *jautau instead of *cauthau for [tʃawthaw]. This makes Khitan-Liao Chinese comparisons more transparent and spares me the need to explain 'mismatches' in every post. However, such benefits are at the expense of phonetic accuracy and complicate comparisons with Middle Chinese which cannot be written in a Pinyin-style romanization since it has three series of obstruents, not just two: e.g.,
| Middle Chinese | Liao Chinese | Modern Mandarin | Pinyin-style romanization |
| *t | *t | [t] | d |
| *th | *th | [th] | t |
| *d | (no voiced obstruents) | (none) | |
**8.16.6:02: I kept reconstructing 君 in previous entries as Sino-Khitan kun < Liao Chinese *kun with Sino-Korean kun in mind, but that can't be right because Liao Chinese underwent this chain shift
*wa > *o > *u > *ü
which may have occurred about two centuries after Sino-Korean was borrowed. 軍, a homophone of 君, was spelled as
<g.ün>
in the Khitan small script, so 君 was presumably also Sino-Khitan gün.
12.8.14.23:57: SOME PRIVATE INTERIOR
In "An Un-lai-kely Reading", I blended the Chinese characters 𠫘 and 𠫣 together to create this GIF of the Khitan large script character
which looks like one of two spellings for Jurchen di- 'come':
The other spelling
looks like one of those Chinese characters (𠫣) which in turn looks like Liao Chinese 厶 *sï 'private' ~ *meu 'some' atop 内 *nui 'interior'. zdic.net lists the modern Mandarin reading of 𠫣 as yù and quotes the 龍龕手鑑 (Liao Dynasty, 997 AD): 音玉 '[has the] sound [of Liao Chinese] *ŋuʔ'. No meaning is given.
I can't find 𠫣 in the 異體字字典 of Taiwan. That dictionary normally reproduces the 龍龕手鑑 entry when available for a given character, so I expected to find 𠫣, but I guess not all characters from the 龍龕手鑑 are included.
I did find a free copy of 龍龕手鑑 at archive.org. 𠫣 is on page 214 of the PDF of volume 1 (101.2.8.4 of the original). Its entry has only two characters: 音三 '[has the] sound [of Liao Chinese] *sam' - not the 玉 Liao Chinese *ŋuʔ I expected. Where did zdic.net get "音玉" from? (8.15.00:35: A copying error or a variant edition? Only two strokes distinguish 三 and 玉.) Alas, 龍龕手鑑 has no gloss for 𠫣.
Is the resemblance between the characters for Jurchen di- and Liao Chinese *sam and/or *ŋuʔ coincidental? Was the shape 𠫣 created for the Parhae script (or a predecessor?) before the Liao and later recycled by the Chinese during the Liao and the Jurchen after the Liao? Or was it independently created twice: once by the Chinese and again by the Jurchen? Was it in the Khitan large script?
How many other Jurchen characters look exactly like Chinese characters?
12.8.13.23:59: AN UN-LAI-KELY READING
Khitan genitive (possessive) suffixes are thought to vary according to the vowel of the preceding noun: e.g., <un> follows nouns with the vowel <u>: e.g., in the Khitan large script epitaph for 'Duoluoliben'* (多羅里本; 1037-1080; hereafter 多) from 1081 AD:
<dan gur un> 'Dan state-GEN' = 'of the Dongdan Kingdom' (多 3.17-18)
<jur un> 'two-GEN' = 'of the two (people') (多 8.4-5)
For examples of <un> after <u>-nouns in the Khitan small script, see Kane (2009: 134-135).
Assuming that <un> could only follow such nouns, one can guess that the readings of Khitan large script characters preceding <un> must have contained <u>: e.g., the character before <un> in
<? un> '?-GEN' (多 15.42)
might have been read as <tuŋ> (cf. Liao Chinese 同 *tuŋ 'same').
The character right before <un> in
<? ? ? un> '(name)-GEN' (多 1.1-4)
looks like Liao Chinese 來 *lai 'come' but could not have been read as <lai> because neither <a> nor <i> match <un>. If the Khitan large script were derived from the Parhae script which might have had Koreanic-based readings, perhaps 来 was <un> (cf. Proto-Korean *on-** 'come'; see Vovin 2011: 27). (But that begs the question of why the Khitan large script would have two phonograms for <un>:
Was 来 for non-genitive <un>?***)
The <un>-after-<u>-noun hypothesis predicts that <un> should not follow non-<u> nouns. Yet such cases do apparently exist:
<śa ri un> 'court attendant-GEN' (多 1.11-13)
<irgen un> 'tribal chief-GEN' (多 2.23-24, 2.41-42)
<hoŋ di un> 'emperor-GEN' (多 3.11-13)
<? ? bai un> '?-GEN' (多 6.15-18; 15.24-27)
Conversely, here is an instance of an <u>-noun followed by <in> instead of <un>:
<siaŋ guŋ in> 'lord-GEN' (多 5.17-19)
What is going on? Here are several possibilities which are not necessarily mutually exclusive:
1. The spellings for the nouns above also had readings that harmonized with <un> which served as a disambiguator: e.g.,
'court attendant'
could be either
native <śa ri>
or
Sino-Khitan <laŋ gun> (< Liao Chinese 郎君 *laŋkun)
in isolation, but could only be <laŋ gun> before <un>:
<laŋ gun un> (not <śa ri un>)
What would the readings of the other characters before <un> have been?
2. <un> is not (always?) <un>; it could have had another reading that harmonized with the vowels of the nouns.
3. The <un>-after-<u>-noun rule is wrong.
4. Khitan did not have vowel harmony; suffix variation was really driven by inflectional classes rather than phonology.
5. Khitan vowel harmony was collapsing or even lost in the dialect of the scribe, so <un> and <in> (both merging into [ɨn]?) were used after what would have once been the wrong nouns; cf. how the Middle Korean genitive postpositions
ɯy (generally after nouns with higher vowels)
ʌy (generally after nouns with lower vowels)
have merged into a single modern standard Korean 의 <ŭi> [e] after all nouns. Unfortunately, the epitaph is not dated. It would be interesting to see if vowel harmony was present in earlier Khitan texts but partly or even wholly lost in later Khitan texts. There is no reason to assume that Khitan stayed phonologically still for three centuries.
*8.14.4:26: The name 'Duoluoliben' is a modern Mandarin anachronism based on the Chinese transcription of his name which was
<doro.le.bun>
in the Khitan large script.
**8.14.5:24: 'Proto-Korean' refers to the ancestor of the modern Korean dialects. 'Proto-Koreanic' is the ancestor of Proto-Korean and its extinct sister languages spoken in eastern Manchuria and on the Korean peninsula.
Proponents of 'vowel rotation' theories might welcome the reading <un> for the Khitan large script character 来 because its <u> matches the *u they reconstruct as the source of later Korean o. However, Sino-Korean o for Middle Chinese *o indicates that Korean o was *o even during the Tang Dynasty, so perhaps the reading <un> reflects an *o > *u shift in a Koreanic language spoken in Parhae.
Or maybe the reading <un> is completely wrong.
is definied as Liao Chinese 第 *ti (ordinal indicator) and 都 *tu 'capital city' in Andrew West's Khitan large script database. (Liao Chinese voiceless *t was borrowed as voiced d in Khitan; cf. the romanization of modern Mandarin [t] as d: 第 [ti] di and 都 [tu] du.) Maybe 来 was pronounced <du> for Sino-Khitan du 'capital city' and a homophonous native ordinal indicator du, though none of the ordinals from 'first' to 'eighth' have small script forms indicating du in Kane 2009. (I cannot find any higher ordinals in Kane 2009. Perhaps du only attached to, say, numerals over 'nine' or even 'eight'.)
Another possibility is Tungusic-based. Liao Chinese 第 *ti sounds like Jurchen di- (> Manchu ji-) 'come'. Was <di> a reading originating from Tungusic usage of the Parhae script? It would not only conflict with the suffix <un> but also be an monosyllable unlikely to represent a complex concept like 'capital city' in a polysyllabic language like Khitan. Lastly, the Jurchen characters for di- 'come' do not resemble 来:
According to Jin (1984: 248), a Khitan large script character in the Memorial for the Grand Preceptor (故太師銘石記; 1056)
looks like the first of these Jurchen characters.
***8.14.5:26: I used to assume that
<un>
was a pure phonogram. However, it is unclear whether
'wife' (Yongning epitaph; see Kane 2009: 173)
is a misspelling or alternate spelling of
<mó ku> 'wife' (多 13.34-35)
or a synonym <un ku> 'wife' (unattested in the small script and therefore suspicious) in which <un> is a phonogram rather than a logogram (morphogram?) for the genitive suffix. See "Two Readings for Two People?" for more on these words.
12.8.12.23:59: OT-LANDISH PƜR-POSALS
Writing about the Khitan large script character
<un>
last night inspired me to look at the 火-characters of the Khitan scripts and the Jurchen (large) script. I still can't figure out what each set of 火-characters has in common, if anything. None of the identified characters have anything to do with fire, so I couldn't understand why they have what looks like Chinese 火 'fire' in them.
But then tonight I wondered if one character does in fact have fiery roots. The Khitan small script character
<ud>
looks exactly like Chinese 火 'fire' and even sounds similar to early Uyghur o(o)t 'fire' (see Clauson 1972: 34 for attestations). Is this an example of the Uyghur influence on the Khitan small script implied by the History of the Liao Dynasty?
Uighur messengers came to [the Khitan] court, but there was no one who could understand their language [... Tiela] was able to learn their spoken language and script. Then he created a script of smaller Kitan [= Khitan] characters which, though few in number [compared to the Khitan large script], covered everything.
(Translation by Wittfogel and Fêng 1949: 243; quoted from Kane 2009: 35 since I haven't had a library copy of W&F in years and can't afford my own copy)
The Khitan small script doesn't look like the old Uyghur script, but could Uyghur words have influenced the choice of shapes? Contrary to the above passage, members of the Khitan elite may have been conversant in Turkic. Róna-Tas () wrote,
Firstly, it must be stressed that Khitai [= Khitan] society featured a significant Turkic element, most probably of Uighur origin. The clan from which the Khitai emperors took their wives was Turkic [Uyghur, to be exact], and the Turks also played an important role in the political life of the Liao Empire.
Here's my other ot-landish proposal. In a 1996 class handout, Alexander Vovin reconstructed the Proto-Turkic word for 'fire' as *hoot on the basis of Khalaj hot (Starostin's online database has huụt) which preserves an h- lost elsewhere in Turkic. Proto-Turkic had no *p-, so *h- could be from an earlier *p-: *poot. What if that form were cognate to Middle Korean *pɯ́r 'fire' which could be from *pɯ́tV́? I don't really believe that. The vowels don't match and there is no Korean-internal evidence for a final *-tV́. (A final vowel is needed to condition the lenition of the *-t- needed to match Turkic.) MK *pɯ́r may be related to Proto-Japonic *pə- 'fire' which has no trace of a *-t(V). This just shows how easy it can be to create an Altaic etymology that doesn't hold up under scrutiny.
8.13.3:46: Starostin proposed a different Altaic etymology for his Proto-Turkic *oot 'fire' (without *h- even though he includes the Khalaj h-form in his database). I have doubts because
- none of the other four forms means 'fire': Mongolic 'spark', Tungusic 'wood fire' (very specific), Korean 'warm', Japanese 'warm' and 'hot'.
- If Proto-Turkic *h- is from *p-, it should correspond to Proto-Tungusic and Proto-Japonic *p-, not Proto-Tungusic *x- (< Starostin's Proto-Altaic *k`-) or Proto-Japonic *Ø-. (I suspect Proto-Japonic might have had an *h-* and/or *x- which left traces in pitch accent and had nothing to do with later Japanese h- from *p-.)
- the Proto-Korean* form begins with *t-; where is the syllable corresponding to Proto-Turkic *hoo-, Proto-Mongolic *(h)o-, Proto-Tungusic *(x)u-, and Proto-Japonic *a-?
- four forms only have *t in common and it is not clear that Proto-Mongolic *c in 'spark' came from *ti
- almost nothing matches after *t/c; can all of this material be found in other words of the various proto-languages, or must one reconstruct ad hoc 'suffixes'?
Starostin's Proto-Altaic *Ø *oo t(`) a Proto-Turkic *h oo t Ø Proto-Mongolic *(h) o c ki-n Proto-Tungusic *(x) u t innge Proto-Korean *Ø t a- Proto-Japonic *Ø a t a-/u-
I don't think these forms are related. I don't even think Altaic is a genetic family; I regard it as a convergence zone.
*8.14.4:15: I would use the term Proto-Koreanic to refer to a proto-language reconstructed on the basis of more than one Koreanic language.