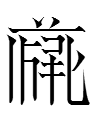
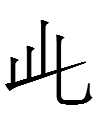
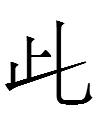
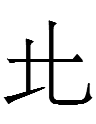
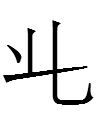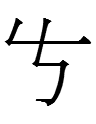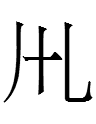3459 1kio 'to drive'

2264 1kyo 'mother's brother'
11.12.24.23:59: TANGUT THROUGH TIBETAN (PART 3)
Now I can finally start my comments on Andrew West's observations on Tangut in Tibetan transcription:The Tibetan glosses are particularly difficult (for me at least) to read as they are generally written in an untidy, cursive, headless script in which many letterforms are very similar to other letterforms (e.g. the letters ng ང, d ད and ra ར all look almost identical in some hands), and without context it can be difficult to be sure exactly what letters are intended.
When I first started learning Tibetan 18 years ago, I had difficulty distinguishing ང <ng> and ད <d> in a clear computer font. Looking back, I'm surprised I didn't confuse ར <r> with them. The Tibetan glosses of Tangut are indeed hard to read. Until a few years ago, I had never seen the actual glosses themselves and relied on Nevsky's 1926 handwritten copies of them. I acquainted myself with their script using Nevsky's romanization.
For this reason, in many cases the identification of the Tibetan gloss can only be determined with certainty by reference to the reconstructed reading of the corresponding Tangut character.
This sounds more circular and dangerous than it actually is. Andrew mentions a case in which a gloss looks like it could be <ngu>, <du>, or <ru>. Let's pretend we don't know anything about Tibetan. Using Chinese glosses alone (risky, I know) to avoid circularity, we can determine that the entries in the Homophones dictionary were organized into nine chapters by initial class:
I. labials
II. labiodentals (this category is controversial)
III. dentals
IV. 'retroflexes' (this category is even more mysterious than II, partly due to a paucity of transcriptive evidence)
V. velars
VI. alveolars
VII. alveopalatals
VIII. glottals
IX. liquids
I would determine the interpretation of a <ng>/<d>/<r> gloss on the basis of a tangraph's location in Homophones: e.g., a <ngu>-graph would be in chapter V, etc.
Secondly, Tibetan is a writing system that is particularly well-equipped to represent a wide range of phonetic values
The Tibetan alphabet is an Indic alphabet, so it is suited to write the rich consonantal inventory of Sanskrit: e.g., three kinds of /s/-sounds. However, Sanskrit did not have a rich vowel system compared to, say, about 30 for Khmer*. Tangut may have had an even richer vowel system than Khmer because the Tangraphic Sea rhyme dictionary has 105 rhymes disregarding tones, and all 105 may have lacked final consonants. This poses a huge problem for Tangutologists: how can a language have 105 different ways of ending open syllables?
Gong's solution was to posit seven basic vowels with or without
- glides** (medial -i-, -y-, -w-, -iw-, -jw-, final -y, -w)
(I am writing Gong's j as y to simplify comparison with Tibetan y = IPA [j].)
- length
- nasalization
- tenseness
- retroflexion
There are
(±-i/y/w/iw/yw-) x (a/e/i/o/u/ə/ɨ) x (±length) x (±nasal) x (±tense) x (±retro) x (±-y/w)
6 x 7 x 2 x 2 x 2 x 2 x 3 = 2016
possible combinations of these elements, but only 105 are actually needed. In any case, no language has 105 simple vowels not otherwise distinguished by length, nasalization, etc.
The Tibetan alphabet already has symbols for medial <y> and <w>. Although Tibetan words do not end in -y or -w, Chinese syllables ending in those glides were transcribed in Tibetan as <Hi> and <Hu>. (འ <H> is a Tibetan letter whose phonetic value is controversial. Nathan Hill has convinced me that <H> was a voiced fricative in an earlier period, but I do not know what its phonetic value was in the dialect[s] of the authors of the Tibetan glosses of Tangut.)
Indic long vowels can be indicated with an <H>-like symbol.
So in theory, Tibetan should support the transcription of
<±y/w><±H for vowel length><a/e/i/o/u><±Hi/Hu>
3 x 2 x 5 x 3 = 90
rhymes which is close to 105. The number increases to 120 if the un-Tibetan sequence <yw> or <wy> is allowed.
However, in reality
- Gong's medials often correspond to no medial in the Tibetan glosses
- I have never seen a Tibetan gloss ending in <Hi> or <Hu>, suggesting that the dialect(s) of Tangut that were transcribed lacked final glides
But wait. Notice that I referred to "dialect(s) of Tangut". There is no guarantee that transcribed Tangut dialect(s) were the same as the presumably standard dialect recorded in Tangut dictionaries. So maybe the glosses never reflected a dialect with 105 different rhymes.
Similarly, the Chinese glosses in the late 12th century Pearl in the Palm (dating long after the compilation of Tangut monolingual dictionaries in the 11th century) may reflect a (nonstandard?) dialect with less than 105 rhymes.
If these glosses and the Tangut dictionary tradition reflect different dialects, trying to reconstruct the 105 rhymes of the latter on the basis of the former is like trying to reconstruct the rhymes of Cantonese on the basis of romanizations of Mandarin. Looking at Peking and Beijing for 北京, how could anyone guess that the first character 北 was read as pak in Cantonese? (Cantonese retained final stops lost in Mandarin.)
Perhaps the reconstruction of Tangut requires two stages:
Phase 1: Reconstruction of the glossed dialect(s) with smaller rhyme inventori(es)
Phase 2: Expansion of the rhyme inventory of the standard dictionary dialect using
- internal evidence
- external evidence:
- Chinese loanwords
- formats of Chinese dictionaries and rhyme tables which influenced their Tangut counterparts
The preceding procedure assumes that the standard dialect has more rhymes than the nonstandard glossed dialects. However, it is also possible that the nonstandard dialects preserve distinctions lost in the standard dialect. Until a few years ago, I assumed that the consonant clusters in the Tibetan glosses represented actual consonant clusters in Tangut that were not reflected in the Tangut dictionary tradition which preserved a 'sinified' dialect of Tangut. I am now more sympathetic to a tonal interpretation of those clusters, but that approach also has problems. Other candidates for nonstandard conservative features might be
- prenasalization (glossed with preinitial <H->)
- voiced aspirates (glossed as <dh>, <bh>, etc.)
- final consonants (glossed with final <-H>)
A third phase of Tangut reconstruction could result in a pre-Tangut reflecting features from both the nonstandard and standard dialects:
| Standard Tangut: fewer consonants? more rhymes |
Pre-Tangut: lots of consonants and rhymes |
| Glossed Tangut: more consonants? fewer rhymes |
Next: The Conclusion (I hope!)
*12.25.00:51: There is no agreement on the number of vowels in standard Khmer. Khmer vowels are written in the Khmer alphabet - another Indic script - with a combination of consonants and vowels, reflecting how Khmer's complex vowel inventory arose from lost consonantal distinctions: e.g.,
កា <kaa> [kaa] < *kaa
គា <gaa> [kiə] < *gaa
កី <kii> [kəy] < *kii
គី <gii> [kii] < *gii
Khmer vowels after *voiceless consonants lowered if possible: e.g., *ii > [əy], still written as <voiceless consonant> + <ii>. (*aa was already low, so it had nowhere to go.)
Khmer vowels after *voiced consonants raised if possible: e.g., *aa > [iə], still written as <voiced consonant> + <aa>. (*ii was already high, so it had nowhere to go.)
**12.25.2:01: Gong reconstructed a distinction between -i(w)- and -y(w)- in Tangut. He may have been influenced by the same distinction in Li Fang-Kuei's Middle Chinese reconstruction which in turn inherited it from Karlgren's Middle Chinese reconstruction. Does any language have such a distinction? Vietnamese comes close: e.g.,
kia [kiə] 'that'
giơ [zəə] < ?*kyəə or *C-cəə 'to extend, raise'
(A loan from Middle Chinese 舉 *kɨəʔ 'to raise'? But MC *-ʔ should correspond to a sắc tone, not a ngang tone. Also, the MC word does not mean 'extend', though it's possible that 'extend' was a later semantic, um, extension within Vietnamese.)
gió [zɔɔ] < *kyɔʔ 'wind'
However, medial -i- and *-y- are in complimentary distribution:
-i- before short ə
*-y- before all other vowels including long əə
There were/are no pairs in Vietnamese like Gong's reconstructions of
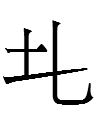
3459 1kio 'to drive'
2264 1kyo 'mother's brother'
which have medial -i- and -j- before the same vowel. My Tangut reconstruction only has -i- (which could be rewritten as -y-). I normally reconstruct a zero medial corresponding to Gong's -i- and an -i- or -y- corresponding to Gong's -y-, though I have considered reconstructing no -i- or -y- at all:
| Tangraph | Gong | This site | Tibetan glosses for rhymes |
|
|
1kio | 1kɔ (or 1kœ?) | <uH>, <a> (<a> is the default vowel for a Tibetan consonant letter without a vowel symbol, so a vowel symbol may have been lost or accidentally omitted) |
|
|
1kyo | 1kio (or 1kyo; perhaps even 1kø?) | <o>, <oH>, <ooH>, <uH> (no medial <y>!) |
I have not seen any Tibetan glosses for these two tangraphs, but I extracted glosses from tangraphs sharing their rhymes.
11.12.23.23:59: TANGUT THROUGH TIBETAN (PART 2: VLADIVOSTOK DETOUR)
In part 1, I tried to exemplify the problems of transcribing non-Chinese words in Chinese characters mostly using abstract formulae. Here's a concrete example. Suppose that in the future, we only have Chinese transcriptions of Russian. How well could we reconstruct Russian phonetics even if we had a perfect knowledge of the Mandarin underlying those transcriptions? For example, Владивосток [vɫədʲɪvɐˈstok] with four syllables would be transcribed as a seven-syllable sequence
符拉迪沃斯托克
fu la di wo si tuo ke [fulatiwɔsz̩thwɔkɤ]
which is far from the original:
| Sinograph | Mandarin in IPA | Russian in IPA | Match? |
| 符 | f | v | No; voicing mismatch (inevitable because Mandarin has no [v]) |
| u | (none) | Corresponds to nothing in Russian (inevitable because Mandarin does not allow the clusters [fl] or [vl]) | |
| 拉 | l | ɫ /l/ | More or less: Mandarin /l/ corresponds to Russian /l/, though the former is not velarized (inevitable because Mandarin has no [ɫ]) |
| a | ə | No; Mandarin is influenced by Russian spelling а <a> rather than Russian phonetics | |
| 迪 | t | dʲ | No; voicing and palatalization mismatch (inevitable because Mandarin has no [dʲ]) |
| i | ɪ | No (inevitable because Mandarin has no [ɪ]) | |
| 沃 | w | v | No (inevitable because Mandarin has no [v]) |
| ɔ | ɐ | No; influenced by Russian spelling о <o> rather than Russian phonetics | |
| 斯 | s | s | Yes |
| z̩ | (none) | Corresponds to nothing in Russian (inevitable because Mandarin does not allow the cluster [st]) | |
| 托 | th | t | No; aspiration mismatch; influenced by Russian spelling т <t> and assumption that foreign t should be transcribed as Md [th] |
| wɔ | o | No (inevitable because Mandarin has no [tɔ] or [to]) | |
| 克 | kh | k | No; aspiration mismatch; influenced by Russian spelling к <k> and assumption that foreign k should be transcribed as Md [kh] |
| ɤ | (none) | Corresponds to nothing in Russian (inevitable because Mandarin does not allow syllable-final [k]) |
Only one segment matched: [s]! (12.24.14:02: Or two if one ignores phonetic details and is satisfied with Md /l/ : Rus /l/.) The Russian stress accent could not be reconstructed from the Mandarin transcription which contains tones (omitted here) of no relevance to the original.
Now I'll finish commenting on Andrew West's first paragraph:
For these reasons, phonetic glosses in Chinese characters are inferior to phonetic glosses given in phonetic scripts such as Tibetan or Phags-pa.
Neither Tibetan nor Phags-pa are IPA. As we will see in part 3, Tibetan probably did not have enough letters for an accurate segmental transcription of Tangut. Nonetheless, both of those scripts are alphabets which are moreflexible than a huge syllabary like sinography: e.g., I could transcribe 'Vladivostok' in Tibetan as
ཝླ་དི་ཝ་སྟོཀ་
<wla.di.wa.stok.>
(with an un-Tibetan sequence <wl> and final <k>)
and in Phags-pa (displayed here on its side rather than vertically) as
ꡓꡙ ꡊꡞ ꡓ ꡛꡈꡡꡀ
<wla di wa stok> (<w> may have been [v]; see Andrew West's section on letter 20)
which are not perfect, yet still a vast improvement over 符拉迪沃斯托克 Fuladiwosituoke.
Luckily for us, a number of Tangut Buddhist manuscripts with phonetic transcriptions of Tangut characters in the Tibetan script are known, and have been the subject of considerable interest to Tangutologists ever since the existence of such manuscripts was first reported by Nevsky in 1926.
I got ahold of Nevsky's book on Tibetan transcriptions of Tangut 70 years later and have been struggling to understand them for the last 15 years.
Next: Tibetan at Last!
11.12.22.23:59: TANGUT THROUGH TIBETAN (PART 1: TANGUT THROUGH CHINESE)
Here is my first round of comments on Andrew West's post on the Tibetan transcriptions of Tangut.
Perhaps the core problem of Tangutology, which has directly and indirectly involved most of the effort of most Tangutolgists most of the time, has been the reconstruction of the pronunciation of the extinct Tangut language.
I've been wrestling with that problem off and on since 1996. The core of the reconstruction I currently use on this site dates from 2008, though the details have fluctuated ever since.
However, it is necessary to first reconstruct the pronunciation of 11th century Chinese before the Chinese glosses can be used to try to reconstruct the pronunciation of the corresponding Tangut characters
Although the phonology of Middle Chinese and Old Mandarin is well documented, the phonology of the northwestern Chinese dialect underlying the Chinese transcriptions of Tangut is poorly understood. It does not help that those same transcriptions are the only direct evidence of that dialect. The problem is seemingly circular but not entirely hopeless. Coblin's (1991, 1994) studies of the Tibetan transcriptions of northwestern Chinese predating the rise of the Tangut Empire give us an idea of the ancestor of that dialect. Unfortunately, modern northwestern Chinese dialects may not be descended from that dialect (which may have been their substratum rather than their ancestor). So we cannot necessarily assume that the unknown dialect was partway between two knowns (Tang Dynasty NW Chinese and current NW Chinese).
as Chinese characters are notoriously incapable of accurately representing the phonetic systems of other languages
Although it is often difficult to represent one language in a script designed for another, Chinese characters are particularly problematic because they are syllabic symbols with rare exceptions*. Here are examples of distortions found in Chinese character transcriptions:
- Consonant clusters absent from Chinese are either broken up or simplified:
non-Chn C1C2 > Chn C1VC2 or C1
or even C3 (a completely different consonant if neither C1 nor C2 exist in Chinese)
- Even simple CV syllables may be absent from Chinese, forcing writers to compromise:
non-Chn C1V1 >
Chn C1V2 (accurate consonant, inaccurate vowel)
or C2V1 (inaccurate consonant, accurate vowel)
or C2V2 (completely inaccurate; only vaguely like original)
Chn V2 could even be a diphthong corresponding to a foreign monophthong.
- Near-impossibility of indicating foreign tones
Tone systems of different languages almost never match. (One can't indicate the six-plus tones of Cantonese with a transcription based on Mandarin with four different tones.)
And even if the tones in one Chinese variety perfectly matched those of a non-Chinese language, there is no guarantee that a non-Chinese CV + tone combination also exists in Chinese.
- Derography, the use of derogatory characters with little regard for phonetic accuracy:
The name of a 3rd century queen in Japan was transcribed as 卑彌呼 *pie mie xo 'humble full call'. Although the second and third characters are not derogratory and hence may be reliable, it is uncertain whether 卑 *pie 'humble' represented a non-Chinese *pie, *pe, *pi, etc.
On the other hand, letters of an alphabet can be assembled into novel combinations to represent a foreign language: e.g., the initial cluster zn- does not occur in English, yet I can romanize Russian знать as znat'.
Next: My Final Comments on Andrew's First Paragraph (and more, I hope!)*E.g., -儿 -r and graphs with polysyllabic readings like 圕 tushuguan, an abbreviation of 圖書館 tushuguan 'library'.
11.12.21.23:59: THE GOLDEN GUIDE: LINE 93: TANGRAPHS 461-465
My last entry on the Golden Guide inspired me to pick up where I left over a year ago.
93. This line is in the middle of the list of Chinese surnames. All five tangraphs normally represent other words but double as phonetic transcription characters.
| Tangraph number | 461 | 462 | 463 | 464 | 465 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 2012 | 3630 | 5910 | 2527 | 5630 |
| My reconstructed pronunciation | 1təũ | 1vieʳ | 1kæ | 2nee | 1dʒɛw |
| Tangraph gloss | winter | divination | price | imperial court | to be worried about |
| Word | the surname 董 Dong (*təũ) | the surname 衛 Wei (*wɨẽ)? | the surname 賈 Jia (*kæ) | the surnames 佴 or 能 Nai (*ne)? | the surname 卓 Zhuo (*tʃæw) |
| Translation | 董 Tun, 衛 Wei, 賈 Jia, 佴/能 Nai, 卓 Zhuo | ||||
461: 2012 is one of only three rhyme 104 (-əũ) syllables in Tangut. All three are borrowings from Chinese:
1402 1xəũ 'red' < Chn 紅 *xəũ
2012 1təũ 'winter' < Chn 冬 *təũ
4305 1tsəũ (a Chinese surname) < Chn 宗 *tsəũ
(12.22.22:44: Native -ũ denasalized at some point shortly before Tangut was first written. The loanword
5625 1thwəəu < Chn 同 *thəũ 'same'
has an initial th- reflecting the *d- > *th- shift that occurred not long before the birth of tangraphy. The word may have been borrowed as *1P-thəəũ with a native *P-prefix added. That prefix is the source of the medial -w- absent from the Chinese original:
1. Borrowing and partial nativization: 同 *thəũ > *1P-thəəũ
The long vowel is unexpected. I once thought vowel length might be a trace of a lost final consonant: e.g., Chn *thəuŋ > T thəəu, but Chn syllables ending in oral vowels also correspond to Tangut syllables with long vowels: e.g.,
2138 2bəəu < Chn 墓 *mbəu 'grave'
Is it a coincidence that all three examples of such Chinese open syllables all had prenasalized initials?
2. Prefix loss: *1P-thəəũ > *1thwəəũ
3. Denasalization: *1thwəəũ > 1thwəəu)
Why would winter be written as a collection of water rather than ice or snow?
+
2012 1təũ 'winter' =
left ('water') of 3058 2ʒɨəəʳ 'water' +
all of 0269 1khiəə 'to collect'
462: Nie and Shi (1995) identified 3630 as the surname 隋 Sui (*swi in the Chinese dialect known to the Tangut), but 1vieʳ doesn't sound anything like it.
3630 was analyzed as the 'meaning of the four brights':
+
+
3630 1vieʳ 'divination' =
left and central line of 2205 1lɨəəʳ 'four' +
top left of 5120 1swew 'bright' +
left of 0797 1phi 'meaning; idea'
Is this a mnemonic? Were there 'four brights' in Tangut divination?
463: 5910 is a loanword from Chinese 價 *kæ 'price' which was homophonous with the Chinese surname 賈 *kæ. I'm surprised there's no 'money' in its analysis:
+
5910 1kæ 'price' =
left of 5875 2ʒɨị 'to sell and buy' (< Early Middle Chinese 市 *ʑɨəʔ 'market') +
center and right of 3934 2kwɛ 'true; precious':
464: The only phonetic matches for 2ne are the rare Chinese surnames 佴 *ne and 能 *ne. The reading *ne is based on the modern Mandarin reading nai in the list of surnames in Giles (1892: 1358).
I wonder if 2527 2nee was borrowed from Chinese 內 *ne 'inner' as in 內宮 'inner court'.
Its analysis is unknown, but
'sage'
is on its right side. Perhaps 'sage' is taken from one of the tangraphs for the imperial surname Ngwimi:
or
2nee 'imperial court' = ? + left of 2339 2ŋwəi or bottom center of 1903 1mi
465: The Tangut initial dʒ- normally corresponds to Chinese *ndʒ- - e.g., in
4706 1733 2dʒɨəəu 2tʃɨi < Chn 女直 *ndʒɨu tʃɨi 'Jurchen'
- but I can't think of any Chinese surname like *ndʒɛw. Nie and Shi (1995) identified 5630 as the surname 卓 Zhuo *tʃæw in spite of the voiceless initial.
ソ is short for 'many' in 5630:
+
5630 1dʒɛw 'to be worried about' =
top left of 5414 2reʳ 'many' +
all of 1262 1ʒɨị 'vexed, worried'
(12.22.22:49: The entire left side of 5414 has a similar function in
=
5076 1dʒʃɨəəʳ 'feast' =
top left of 5414 2reʳ 'many' +
4508 1tị 'to eat')
11.12.20.23:59: PRACTICING THE GOLDEN GUIDE
Thanks to Andrew West for leading me to this fragment of Tangut handwriting practice with five tangraphs (Tangut characters) on it, I hoped that the student was copying a five-tangraph line from the Golden Guide, and I was right! I wrote about that very line back in August 2010. (Note that I presented the tangraphs of line 75 from left to right, whereas they were written from right to left on this fragment:
1xiõ, 0ʔa, 1de, 1lwo, 2so (from right to left)
'Solwo, De, Ahon' ((from left to right; a list of Tangut surnames; A and Hon might be two separate surnames)
I should complete my translation of the Guide. I haven't translated a single line of it this year. I hope to do something about that soon.
12.21.0:25: The next fragment seems to continue from the last. It contains the last tangraph of line 75 of the Golden Guide and the two surnames at the beginning of line 76: 'Babi, Dew ...'
1dew, 2bəi, 2ba, 1xiõ (from right to left)
'...hon, Babi, Dew ...' (from left to right)
12.21.2:07: But alas, I have no idea where the third fragment is from:
2lhị 2dʒɨa 2siẹ 1ʃɨẽ 2ziuʳ (from right to left)
'broom, accomplish, wisdom, sharp, moon'
'broom accomplish' could be a Tangut object-verb sequence ('become a broom'?) and 'wisdom sharp' could be a Tangut noun-adjective sequence ('sharp wisdom') but neither make sense together or with 'moon'. Maybe this is an excerpt from some primer other than the Golden Guide. 'Broom accomplish' might be the end of one line and 'wisdom sharp' might be the start of another.
15.2.21.18:24: I somehow misread
1dzwy1 'chapter' as 2zur4 'broom'
even though the left radical clearly has two horizontal strokes which do not cross the vertical strokes.
Also, 2lhiq is 'moon'. More including the solution to this mystery here.
11.12.19.16:21: UP ON THESE MOUNTAINS
In "Feminine Lines", I mentioned that Jin (1984: 263) derived Jurchen
~
~
<ali> 'mountain'
from a Khitan large script (KLS) character
which in turn resembles a KLS character that has a Chinese 山 *shan 'mountain'-like shape on the left:
Could this be the KLS graph for the Khitan word for 'mountain'? Then I could posit the following chain of derivation:
>
>
>
Chn *shan 'mountain' > KLS 'mountain' (reading unknown) > Jurchen <ali> 'mountain'
No, that would be too easy. The KLS 山-like graph and its variants, including one that is identical in shape to Chn 此 *tsï 'this'
are phonograms for Liao Chinese 上 'up' and 尚 'still'* *shang (not 山 *shan!). Did these graphs originate from 上 plus added strokes?
Up north
Kane (2009: 182) listed a lookalike of Chn 北 'north'
as another phonogram for 尚 *shang. Presumably its variants could also be read *shang:
These graphs also mean 'north' as in Chinese. Did the Khitan borrow Chinese 上 *shang 'up' as 'north'? Should the Khitan small script graph for 'north'
also be read <shang>**? Could 一 be an abbreviation of 上?
<as> and <or>
There is another set of KLS allographs including 山-like shapes:
But none of these mean 'mountain' or even Chn 正 'correct'. 正 is a phonogram for <as>. It and one of its allographs combines with <ar> to form
~
both <as.ar> (are other allographs attested as the first character?)
the KLS equivalents of
<as.ar> 'quietness, peace(ful), clear'
at the end of line 1 of the poem in the eulogy for 宣懿皇后 Empress Xuanyi.
Perhaps that set of allographs should be split into two, as three represent <or> of <po.or> 'become':
~
~
also spelled
~
equivalent to Khitan small script
<p.o.or>
Summing up how I split the 山-type KLS graphs:
| Reading | Allographs |
| <as> | 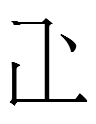 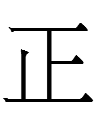
|
| <or> | 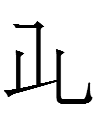 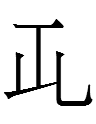 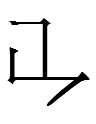
|
Maybe these are all allographs after all which can be read as either <as> or <or> depending on context.
After all that, I still have no idea what the Khitan word(s) or large script graph(s) for 'mountain' were. I conclude with two final mysteries.
<po> 'mountain'?
KLS 山 is not only a phonogram for *shan (Kane 2009: 181) but also appears in a ligature for 'monkey' implying another reading <po>:
=

Subtracting the <o> graph results in<poo>? = <po.o>
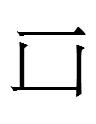
<po> = <po>
Should these two comprise an allograph set? Was <po> the Khitan word for 'mountain'?
<u> in 'mountain'?
KLS 山 appears in line 26 of the epitaph of the 北大王 Great Prince of the North:
The first two graphs at first seem to be <ten.shan> (cf. Chn 天山 *tienshan 'heaven mountain'). They should be followed by the genitive suffix 至 <an>, but are actually followed by the genitive suffix <un> which implies that the preceding noun had an <u>. Did KLS 山 have a third reading with <u>? Did 天 have a second native reading? Did 天山 represent a native Khitan word rather than Chn 天山, or was it a combination of a Chinese loanword *ten 'heaven' plus a native word with <u>?
The fourth and fifth graphs are <NORTH> and <EAST> in Khitan order rather than Chinese order (東北 'east-north').
The sixth and seventh graphs (readings/meanings unknown) may represent a noun modified by 'northeast'.
So the whole phrase may mean 'The northeastern ... of Tenshan'.
*尚 is also 'upwards' and probably shares an Old Chinese root *daŋ with 上. Schuessler (2009: 81-82) reconstructed a medial *-j- in both words on the basis of proposed Tibetan cognates, but there is no unambiguous Chinese evidence for *-j-. The nonemphatic *d- of both words palatalized to *dʑ-. This would have happened with or without a medial *-j-.
**Kane (2009: 35) listed other "[s]uggested readings based on Mo[ngolian ... which] lack evidence":
<umar-a>: cf. Written Mongolian umar-a 'north'
<xoina>, <xoi>: cf. Written Mongolian qoyna 'in the rear / north'
<aru>: cf. Written Mongolian aru 'back, north'
11.12.18.23:58: THE JADE HARE AND THE GOLDEN BIRD
In "Lost Looking for Lexical Temples", I sought an example of Khitan small script poetry in vain. I had forgotten that
- Andrew West had already linked to such a poem (which I will eventually examine)
- I had seen one on page 20 of Kane 2009
I'll tackle the latter first since it is only half as long. It is from lines 28 and 29 of the eulogy for 宣懿皇后 Empress Xuanyi and is not separated from the main text*. It consists of four lines of four words each (read from top to bottom, right to left; the line divisions are mine).
| Char\Line | 4 | 3 | 2 | 1 |
| 1 |  |
 |
 |
 |
| 2 |  |
 |
|
|
| 3 |  |
 |
 |
 |
| 4 | 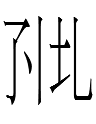 |
 |
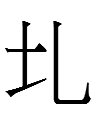 |
 |
The pronunciations and meanings of many of the words are unknown:
Transliteration (rhymes in italics)
| Char\Line | 4 | 3 | 2 | 1 |
| 1 | ? | ɣo.c | g.e.? | ?.b |
| 2 | ?.i | m.in.is | (same as 2.1) | (same as 1.1) |
| 3 | ? | g.u | ? | neu.e |
| 4 | ɣu.ɣo | tau.lí.a | ɣo | as.ar |
Glosses (from Kane 2009: 223 unless noted)
| Char\Line | 4 | 3 | 2 | 1 |
| 1 | ? | ? | ? | ? |
| 2 | of seal/ritual | ? | (same as 2.1) | (same as 1.1) |
| 3 | gold | jade | heaven | earth |
| 4 | bird | hare | ? | quietness, peace(ful), clear (Kane 2009: 111) |
Structure
This short poem has a lot of parallelism:
1. The first two lines begin with reduplicated words (1.1-1.2 : 2.1-2.2).
2. 1.3 'earth' is parallel to 2.3 'heaven'.
3. 1.4 is presumably parallel to 2.4. Perhaps 1.4 is an adjective: 'earth [is] quiet/peaceful ... heaven [is] (adjective).'
4. 3.3-3.4 'jade hare' (representing the moon) is parallel to 4.3-4.4 'gold bird' (representing the sun).
2.4 <ɣo> '?' rhymes with 4.4 <ɣuɣo> 'bird'. One can even see that they were both written with 圠 <ɣo>.
Each line may contain a total of eight syllables:
| Char\Line | 4 | 3 | 2 | 1 |
| 1 | 2 or 1? | 2 or 1? | 2 or 3? | 2? |
| 2 | 2 or 3? | 2 or 3? | 2 or 3? | 2? |
| 3 | 2? | 1 | 3 or 1? | 2 |
| 4 | 2 | 3 | 1 | 2 |
A trisyllabic reading for <HEAVEN> is unlike either the disyllabic tengri-type readings that have been suggested (see Kane 2009: 63 and 101 for lists; cf. early Turkish tengrii [Clauson 1972: 523] and Written Mongolian tngri) or Kane's (2009: 20, 63) monosyllabic <ỏ>. If <HEAVEN> was <ỏ>, then 2.1 and 2.2 may have been trisyllabic.
If 4.2 <SEAL.GEN> was <doro.i>, perhaps <ro.i> counted as one syllable.
Possible readings for 4.3 <GOLD> are disyllabic: Kane's <nigu>, Kara's <jürgü>, a Turkic or Mongolic-like altVn, and my <alcun> (a hypothetical source of Jurchen alcun).
Textual uncertaintyI have not seen the original text, so I must rely entirely on Kane's various versions of it.
Hares or chickens?
On page 222 of Kane 2009, 3.4 appears as
=[
]
<sh.de.a> = [<t.qo.a> 'chicken']
<sh.de.a> looks like an error for
<tau.lí.a> 'hare'
Kane's footnote on p. 223 identified this word as "<te.qo.a>** 'cock'", but the main text on p. 20 identified it as "<tau.lí.a> [...] hare". Since the hare is associated with the moon in East Asia, I assume <tau.lí.a> 'hare' was the intended word, though the actual text may have <sh.de.a>.
A singular seal?
I have followed Kane's (2009: 20) transliteration <doro.i> for 4.2 and converted it back into the Khitan small script asHowever, his small script text on that page has <doro> and the genitive ending <i> written as separate words:
This is unusual because <i> is normally written as part of the preceding noun. See Kane (2009: 136) for examples.<doro i>
There is another unusual spelling on page 223:
<doro.i.t>
<t> is a plural ending absent from the version on page 20. <t> normally precedes the genitive <i>, so I would expect
<doro.t.i>
in accordance with Kane (2009: 142): "The plural suffix comes before the case suffix."
The transliteration and gloss on p. 223 has a different unusual sequence
<doro.i te>
<doro.i> seal ~ ritual GEN?; <te> PLUR (?)
with the suffix <te> (my <t>) written separately:
I have not yet seen <t> as a separate word.
The sound of seals
I prefer to transliterate Kane's <doro> as <SEAL> because I do not know of any transcription evidence for his reading.
Although the Khitan large script character for 'seal'
is similar to the Jurchen characters
for <doro> 'seal' and it's possible that the Jurchen borrowed the word as well as the graph for 'seal' from their Khitan rulers, graphic resemblance does not entail phonetic resemblance.
12.19.00:57: For example, the Khitan large script characters
'child' (presumably <boqo>)
are similar to the Jurchen character
'son' <jui>
but their readings are completely unrelated.
*According to Kane (2009: 214), a circle in his text for Xuanyi "separates lines of rhymed verse", but there are no circles around or within this poem, and I have not been able to identify any poems using his circles.
**Kane (2009) includes inherent vowels in his transliteration whereas I do not: e.g.,
| Khitan small script | Kane 2009 | This blog |
|
|
bo | b |
|
|
ci | c |
|
|
te | t |
An absence of inherent vowels in transliteration does not mean they were absent in pronunciation: e.g.,
<?.b> could have been [?bo]
<ɣo.c> could have been [ɣoci]
An understanding of Khitan meter would enable us to guess the number of syllables in 1.1-1.2 and 3.1.
11.12.18.21:34: ŮH-ŌH
The Manchu letter ᡡ has been romanized as ū, ō, and even v. Yesterday It occurred to me that it could be romanized with the Czech letter ů for an original long oo that became long uu. The o atop u indicates that Manchu ů belongs to the same vowel class as o but has a pronunciation similar (though not identical) to u. o and ů follow uvulars whereas u follows velars. The Manchu alphabet distinguishes between uvulars and velars but the romanization I've been using does not. Syllables in parentheses are only in Chinese borrowings and are romanized with an apostrophe: h'a = <xa>, etc.
| Romanization | k- | g- | h- | k- | g- | h- |
| Transliteration | q- | ɣ- | χ- | k- | g- | x- |
| -e | (not possible) | ke | ge | xe | ||
| -a | qa | ɣa | χa | (ka) | (ga) | (xa) |
| -i | (not possible) | ki | gi | xi | ||
| -o | qo | ɣo | χo | (ko) | (go) | (xo) |
| -u | (not possible) | ku | gu | xu | ||
| -ů | qů | ɣů | χů | (not possible anymore; see below) | ||
(<ɣ> represents a voiced uvular fricative.)
Vowel harmony in sets of suffixes indicates that a was paired with e and u was paired with ů:
<ara-χa> 'wrote' : <ji-xe> 'came'
<yada-χůn> 'poor' : <etu-xun> 'strong'
If a is lower than e, then ů must have been lower than u. I interpret e and ů as [ə] and [ʊ]:
| High | i | ə | (none) | u |
| Low | (none) | a | o = [ɔ]? | ʊ |
Perhaps the empty slots in the above table were once filled:
| High | *i | *ə | *o | *u |
| Low | *ɪ | *a | *ɔ | *ʊ |
Could that have been the (early?) Jurchen vowel system?
Comparative evidence points to two sources for Manchu i: e.g.,'thou': Manchu si : Ewen hi
'three': Manchu ilan : Ewen elan
In an unpublished 1996 class handout, Vovin reconstructed Proto-Tungusic *si and *elan. Could the latter have been *ɪlan? Rewriting my *ɪ as a front vowel *e results in
| High | *i | *ə | *o | *u |
| Low | *e | *a | *ɔ | *ʊ |
which is close to my Proto-Korean vowel system (but note the very different third column and the lack of *ʊ):
| High | *i | *ə | *ɯ | *u |
| Low | *e | *a | *ʌ | *o |
This *e is not to be confused with the e of Manchu romanization which
- was [ə] in this scenario
- came from Vovin's Proto-Tungusic *ä
If ä is the opposite series counterpart of a, I could use the diaeresis to consistently indicate opposite series counterparts. This notation suggests a Turkic-type front-back vowel system:
| Front | *i | *ä = *e | *ö | *ü |
| Back | *ï | *a | *o | *u |
Suppose (pre-)Jurchen had such a system. It collapsed into a seven-vowel system in Old Manchu (OM):
| Front | *i | e | ö | ü |
| Back | a | o | u |
The seven OM vowels corresponded to five graphemes:
| Front | <i> | <e> (<a> in medial position) |
<ů> = <u> +
<i> (<u> after <ů>) |
| Back | <a> | <u> |
Dots were not used to differentiate between vowels in the OM alphabet.
The following vowel changes occurred between OM and standard Manchu (SM):
ö > o (but ö > ü > u or ö > o > u after velars)
ü > u > ʊ <ů> (a chain shift)
The OM letter <ů> for [ö] ~ [ü] was used for SM [ʊ].
After these changes, the letter sequences <ků gů xů> ceased to be used since SM <ů> = [ʊ] followed uvulars rather than velars.
Examples of Manchu vowel changes:
| Gloss | OM spelling | OM phonetics | SM spelling | SM phonetics |
| Jurchen | <jůsan> | [jüʃen] | <jushen> | [juʃən] |
| country | <gůrun> | [gürün] | <gurun> | [gurun] |
| wild animal | <gůrgu> | [görgö]? > [gürgü] | <gurgu> | [gurgu] |
| reason | <tůrgun>, <turgůn> | [türgün] | <turgun> | [turgun] |
| thirty | <ɣusin> | [ɣusin] | <ɣůsin> | [ɣʊsin] |
| eight | <jaqun> | [jaqun] | <jaqůn> | [jaqʊn] |
| calculate | <bůdu-> | [bödö] | <bodo-> | [bodo] |
The front vowels in [jüʃen] and [gürün] match those of Mongolian Jürcid and gürün.
I suspect that OM <gůrgu> 'wild animal' once had mid vowels since it corresponds to Mongolian göröge (Lessing 1960: 387: görüge(n) 'hunting, game'). Doerfer (1993: 83) wrote that SM gurgu is "in all probability from" Khitan but did not explicitly state his reasoning.
There are at least four kinds of problems with this scenario. None may be fatal.
1. No support from Chinese transcriptions of Late JurchenKane (1989: 105) reconstructed a five-vowel system (a e i o u) for Late Jurchen on the basis of Chinese transcriptions. That transcribed variety of Late Jurchen is not ancestral to SM, so perhaps it lost front rounded vowels retained in the Manchu line.
2. Foreign ö : OM <u>
Early Turkic törüü ~ töröö (Clauson 1972: 531) and Written Mongolian törü correspond to OM <turu>, not <tůru> 'rule, ritual'. The SM form is doro. (OM <t> could represent both t and d.) Perhaps o backed to dissimilate from preceding acute consonants:
| Consonant type | Pre-OM | OM | SM |
| Labial | *Pü, *Pö | <Pů> | <Pu>, <Po> |
| Acute | *Tü, *Tö | <Tů>, <Tu> | <Tu>, <To> |
| Velar | *Kü, *Kö | <Ků> | <Ku> |
Conversely, Chinese 功 *gung appears in OM as <kůng> implying [güŋ] even though the Chinese word did not have a front vowel. (OM <k> could represent [k g x].) Perhaps [güŋ] was an attempt to approximate a Chinese *gung that violated OM phonotactics. OM [g] could only precede front vowels. [gu] became permissible in SM, so the SM form is <gung>.
4. OM <ů> after uvulars
If OM <ů> was a front vowel, it should not occur after uvulars, yet the late OM spelling <daχůn daχůn> (in a 1636 text with a <t>/<d> distinction) is identical to SM <daχůn daχůn> 'repeatedly'. This text may have been written by someone who mixed the emerging new spelling conventions with the old ones. I would be more troubled if an early OM text had uvular-<ů> sequences.
Next: The Jade Hare and the Golden Bird (at last!)
11.12.18.2:15: NO KIDD-IN' AGAIN
Recap
In "No Kidd-in'", I proposed that
'Khitan'
was <qid.ïn> [qɯdɯn] with nonfront high vowels. I also reconstructed Jurchen
as <ïn> because of the equation
Khitan small script
= Khitan large script
= Jurchen
However, in my last entry, I concluded that <ïn> should simply be <in> which might have been [ɯn] as well as [in]. If Jurchen ever had [ɯ], it must have merged with [i], resulting in a neutral i as in Manchu.
The Jurchen name for the Khitan
I would expect Khitan [qɯdɯn] to correspond to a Jurchen Kidin (or Kïdïn) with high vowels. But the Jurchen name for the Khitan was
<hi.tan> Hitan [xitan]
with an a in the second syllable like other foreign names for the Khitan. I would expect the Jurchen approximation of 'Khitan' to be the most accurate of all since they experienced Khitan rule firsthand. So I'm back to square one: why wasn't 'Khitan' written with <an> in the Khitan small or large scripts?
the hypothetical spelling *<qid.an> in the Khitan small and large scripts
But that's just the beginning of the problems with Hitan.
1. Why does Hitan have initial H-?
If Manchu and Jurchen back k was [q], why wasn't the name Kïtan [qɯtan]?
Perhaps Khitan q shifted to x [x] ~ [χ] at some late date. The Khitan q : Jurchen h [x] ~ [χ] correspondence also occurs in
:
(
)
Khitan <qudug> : Jurchen <hutu(.r)> hutu(r) [χʊtʊ(r)] 'good fortune'* (cf. Manchu hūturi [χʊturi])
The Khitan word was transcribed in Chinese as 胡覩古 *xudugu, possibly reflecting a variety of Khitan that had undergone the q to x shift.
12.18.16:45: Another instance of Khitan q : Jurchen h [χ] is
:
Khitan <qa.ɣa> : Jurchen <ha.gan> [χaɣan] 'qaghan'
2. Why does Hitan have medial -t-?
'Good fortune' also contains the correspondence Khitan d : Jurchen t. The Old Turkic source of 'good fortune' was qut. Did intervocalic -t- voice in Khitan? Could such voicing have accounted for at least some of the confusion between <t> and <d> in the Khitan small script?
3. Was Hitan really Çitan?Jin's (1984) readings of Jurchen characters are more phonetically precise than mine: e.g, he read
as <çi.tan>. My <hi> could have been [çi] and/or [xi], but I prefer a more phonemic notation <hi> since Jin's <ç> is in complementary distribution with his <x>:
| Environment | Jin 1984 | This blog |
| Before <i> and <ü> | <ç> | <h> |
| Elsewhere | <x> |
Jin derived
~
<çi> (also <xi> in the body of his entry for the first allograph)
from the similar-looking sinograph 犀 'rhinoceros' pronounced *si in Jin Chinese. Was a palatalized [xʲ] or a palatal [ç] close enough to [s] to motivate the Jurchen to derive a <hi> graph from犀 *si? Was there a local Chinese dialect word *xi 'rhinoceros', not to be confused wtih modern standard Chinese xi [ɕi] 'id.'?
Jin also reconstructed the reading of this set of Jurchen allographs as
~
~
as <çi> ~ <si> ~ <ʃï>. But this second set of graphs was used to transcribe Jin Chinese *si, so I'd rather read them as <si>: e.g.,
<si.tiyen> < Chn 西天 *sitien 'western heaven'
<si.fan> < Chn 西番 *sifan 'western barbarian' (i.e., Tibetan - did the Jurchen call the Tangut the Sihiya < Chn 西夏 *sixya?)
<si uye.he> < Chn 犀 *si 'rhinoceros' + uyehe 'horn' (cf. Manchu uihe, weihe 'horn')
Jin's two <çi> are side by side in
<sa.hi.si.ing> 'intelligence' (cf. Manchu sa- 'to know')
Unfortunately, I know of no Manchu sahising that would confirm my readings of the middle two graphs.
**See Kane (2006: 127-128) for more on 'good fortune' in Altaic languages.
Jin (1984: 292) noted that a Jurchen character resembling <hutu> without a dot appeared in 女眞字文書:
He listed its meaning and reading as unknown. I suspect that this was an early spelling of <hutur>, later written with two graphs as
<hutu.r>
The -r may have been a Jurchen attempt to imitate a Khitan final -ɣ which was not possible in Jurchen. (I suspect Khitan qudug was [quduɣ].)
Jurchen hutu-compounds lack -r: e..g,
<hutu.nggai> hutunggai 'possessing good fortune'
Jin derived <hutu> from a Khitan large script (KLS) graph
Could this be the KLS graph for qudug? It is almost identical to the KLS graph
corresponding to syllables transcribed in Chinese as 兀里 *uli. Were these two KLS graphs distinct or were they allographs both read <uli> or <uri>? Did <uli>/<uri> have a second reading <qudug>?
My IPA for Jurchen hutu(r) [χʊtʊ(r)] and hūturi [χʊturi] reflects my assumption that Jurchen and Manchu vowel harmony was height-based:
Jurchen 'low' u and Manchu ū [ʊ] were to Jurchen 'high' u and Manchu u [u]
what Jurchen and Manchu a [a] was to e [ə]
cf. the Korean harmonic pair 아 a : 어 ŏ [ə]
However, I do not reject other interpretations of the Jurchen and early Manchu vowel systems. I think the Manchu letter ᡡ <ū> has changed its value over time. I've been putting off blogging about <ū> for years. I'll finally get to the topic tomorrow.
Next: Ūh-Oh
Eventually: The Jade Hare and the Golden Bird