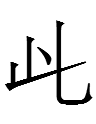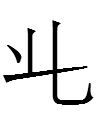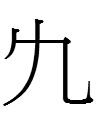![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
11.12.17.19:50: JURCHEN TW<IN>S
In "No Kidd-in'", I proposed that Jurchen
represented <ïn> with a back vowel <ïn>.
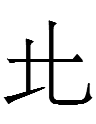
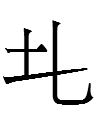
Jin (1984: 67) listed two kinds of Jurchen <in> graphs, the set above (for <ïn>?) and another pair
Could this other type of <in> graph be the front vowel counterpart of <ïn>? I don't think so for two reasons.
~
First, its final consonant was -m, not -n, since it transcribed the Jin Chinese rhyme *-im which did not become *-in in northern Chinese* until the Ming Dynasty:
<han.li.im> Hanlim = Chn 翰林 *xanlim 'Hanlin Academy' (lit. 'forest of pens')
<u.en.li.im.la.ang> wenlimlang = Chn 文林郎 *wenlimlang 'man of the literary forest' (an official rank)
<gon.im.ta.ang> Gonimtang = Chn 觀音堂 *gonimtang 'Guanyin Hall'
(Northern Chinese *o did not break into ua until the Ming Dynasty.)
Second, this <im> could occur with back as well as front vowels**: e.g., in the native words
<im.gai.da> (name of a river; does a cognate Manchu name exist?)
<im.ma.la> 'mulberry' (cf. Manchu nimala(n) 'id.'; an instance in which Jurchen was less conservative than Manchu which kept initial n-)
and the a and o of the loanwords Hanlim and Gonim (see above). I conclude that
- the Jurchen script had only one <in> and one <im> (disregarding allography)
- <in> and <im> do not indicate vowel harmony
- they could have always represented [in] and [im] (and i was a neutral vowel in Jin Jurchen as in Manchu)
- or they could have represented [in] ~ [ɯn] and [im] ~ [ɯm] depending on context:
| Jurchen graph | Jin (1984) | This blog | Examples |
 |
<in> | <in> | <ali.in> [alin] or possibly [alɯn] 'mountain' <eshi.in> [eʃin] (not [eʃɯn]) 'not' |
|
<im> | <im.gai.da> [imgaida] or possibly [ɯmgaida] (river name) <han.li.im> [χanlim] or possibly [χanlɯm] (if harmonized) <u.en.li.im> [wenlim] (not [wenlɯm]) 文林 |
*Final *-m remains in southern Chinese languages today: e.g., Cantonese 林 lam 'forest', 音 yam 'sound' (cf. Jin Chinese *lim, *im but modern standard Mandarin lin, yin).
林 and 音 once had nonfront vowels in Old Chinese: *rəm and *ʔəm. OC *ə then raised to *ɨ. Sino-Korean rim and ɯm indicate that *ɨ had fronted to *i before acute initials in Tang Dynasty northern Chinese:
林 TDNC *lim > SK rim音 TDNC *ʔɨm > SK ɯm
The *-im and *-ɨm rhyme categories had merged into *-im by the Liao Dynasty:
| Tang | Liao, Jin, and Yuan | Ming and Qing | Modern standard Mandarin |
| *-im | *-im | *-in | -in |
| *-ɨm | |||
| *-in | *-in |
Hence Jin Dynasty <li.im> and <im> could not represent [lɨm] and [ɨm] unless Chn *lim and *im were harmonized:
Chn 翰林 *xanlim > harmonized Jurchen [χanlɯm]?
Chn 觀音 *gonim > harmonized Jurchen [gonɯm]?
The nonfront a [ɐ] of Cantonese lam and yam is a Tang innovation, not a direct retention from Old Chinese. The older layer of Sino-Vietnamese has -im corresponding to -âm [əm] in the later Cantonese-like layer from the late Tang Dynasty: e.g.,
心 Old Chinese *səm 'heart'
> Late Old Chinese *sim (borrowed into Vietnamese as *sim > tim)
> Late Southern Tang Chinese *sɪm or *səm (borrowed into Vietnamese as *səm > təm)
> Cantonese sam [sɐm]
**The 'front' vowel <e> of <u.en> may have been [ə] instead of [e]. Perhaps I could use a more neutral term like 'opposite series vowel'. For compatibility with Möllendorff's Manchu romanization which I use with modifications -
[ʃ]: Möllendorff š : sh on this blog
[sχ] ~ [sx] (depending on following vowel): Möllendorff sh : s'h on this blog
- I will write the 'opposite series' counterpart of Jurchen a as e even if it was [ə].
11.12.16.23:54: NO KIDD-IN'?
Jin (1984: 89) derived two of the variants of Jurchen <in> from Khitan large script (KLS) characters:
<
<
Could those KLS characters be variants of the second characters in the KLS spellings for 'Khitan' (Kane 2009: 162, 179)?
(The third first character is in Andrew West's KLS font but I have not seen it in Kane 2009.)
These KLS spellings presumably correspond to the Khitan small script spelling
<qid.144>
<qid> looks like a fusion of the Khitan small script characters <GREAT> and <HEAVEN> (Kane 2009: 163):
大 on the bottom of <qid> is Chinese 'great'.=
+
Perhaps the KLS graphs
were also read <qid>. (Kane did not specify readings for the two KLS 'Khitan' graphs.)
The reading of Khitan small script character 144
has been reconstructed as <da>, <en>, <in>, <u>, and <ún> (Kane 2009: 51).
Kane found that
<b.144>
was interchangeable with
<bun> (transcribed in Chinese as 本 *bun: <c.i.is.d.bun> = 赤實得本 *chishideibun 'filial piety'*)
and concluded that 144 = <ún>. Kane used the acute diacritic to distinguish <ún> in transcription from the genitive suffix
=

<un> (and its KLS equivalent)
It's not clear whether all <ú> were phonetically identical or phonemically distinct from <u>.
Hence Kane interpreted
as <qid.ún>. However, no other evidence points to an u-like vowel in 'Khitan': e.g., the Korean name for the Khitan is 거란 Kŏran < *kətan. There is no reason why a Khitan u couldn't have been borrowed into other languages as u: e.g., a hypothetical Korean *kətun. So I am skeptical of <u>-readings like <u> and <ún>.
If I were unaware of the interchangeability of <bun> and <b.144>, I would have interpreted 144 as <an> since all non-Khitan words for 'Khitan' that I know of have a in the second syllable.
I could propose that 144 had two readings, <un> after <b> and <an> after <qid>.
But what would distinguish that <an> from
<an> and <án>?
Projecting the Jurchen reading <in> back onto its possible KLS sources and in turn onto 144 is also problematic because no foreign words for 'Khitan' resemble Qidin. <b.in> is an unlikely equivalent of <bun>.
The reading <en> has similar problems. Qiden would have been borrowed into Korean as *kətən (instead of *kətan) and Chinese as *kidien (instead of *kidan). Moreover, <b.en> is even less like <bun> than <b.in> is due to the different vowel heights: <e> is mid and <u> and <i> are high.
Liu Fengzhu (1983) interpreted 144 as <da> in
<kiday> 'Khitan' (cf. Cathay, Kane's <qid.ún.i>)

<duanda> 'middle' (cf. Mongolian dumda, Kane's <da.úr.ún>)
but <b.da> is even less like <bun> than <b.in>, <b.en>, or <b.an>.
I think 144 might have been <ïn>. A high nonfront unrounded vowel <ï>
Was Jurchen <in> also <ïn>? Nearly all Jurchen words written with <in> have the back vowels <a o u>. Perhaps they were followed by <ïn> with a back vowel: e.g.,- is nonfront and unrounded like the a of the foreign names for the Khitan
There was no Chinese syllable *dïn, so 丹 *dan was the closest possible approximation
The *a of the Korean form *kətan could be due to Chinese influence, replacing an earlier *kətən or *kətɯn?
Forms like Orkhon Turkic Qitay and English Cathay could reflect a Khitan
<qid.i> [qɯdɯɰ] or [qɯdəɰ] (an -n-less stem form rather than a genitive of <qid>?)
/i/ backed to [ɯ] after /q/ and the second /i/ backed to match the first [ɯ]
backed (final?) /i/ could have been a diphthong: cf. Russian ы [ɯɨ] (Lyovin 1997: 65)
or the diphthong is an irregular or dialectal reduction of the -ïn-i of
<qid.ïn.i> 'Khitan' + genitive suffix -i
- could have been backed and rounded after /b/: /bïn/ = [bun]?
cf. Korean /ɯ/ which becomes [u] after labials, though hangul spelling does not reflect this:
기쁜 <ki.ppɯn> [kippun] 'happy'
- is close to the <i> of Jurchen <in>:
small
= large
=
<ïn>
> J
<in>
However, there is also a single word<alï.ïn> alïn 'mountain'
<morï.ïn> morïn 'horse'
<ushï.ïn> ushïn 'field'
<eshï.ïn> eshïn 'not'
with <e> which should not coexist with <ï> assuming that Jurchen had typical Altaic vowel harmony. Was eshïn an exceptional word, or was it eshin with a front i? Or did <ïn> have two readings, [ïn] in back-vowel words and [in] in that one front-vowel word?
Next: Jurchen Tw<in>s
*Transcription from History of the Liao Dynasty as written in Kane (1989: 15). Kane (2009: 98) has 赤是得本 *chishideibun with 是 *shi instead of 實 *shi.
11.12.15.23:15: NINE IN LINE (OR SO MANY SIXES)
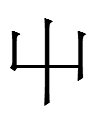
The Jurchen (large) script graph
resembles Jin Dynasty Chinese 列 *lie 'line', so one might expect it to have been read as paida-, an archaization of the root of Manchu words like faida- 'to line up', faidan 'row', faidangga ulabun 'arranged biographies' (a translation of Chn 列傳), etc. But it was actually an apparently meaningless phonogram pronounced <in>.
<in> also looks like Chn 夕 *si 'evening' (a drawing of a moon) and 刂 *dau 'knife', neither of which sound like it.
None of its many variants resemble Chinese characters pronounced *in:
As far as I know, eight variants is a record within Jurchen.
The record holder in the Khitan large script (KLS) might be 'six' which also has eight variants:
These nine were found in only four memorial inscriptions. Perhaps other variants may be found in other texts.
How many of the c. 1,300 Jurchen characters and c. 1,000 KLS characters are variants?
Are these variants actually variants: i.e., are they truly interchangeable? Seven of the nine appear in the epitaph of 耶律褀 Yelü Qi:
Forms of 'six' used twice
<SIX YEAR> (x 2)
<SIX ?> (x 2)
Forms of 'six' used once

<SIX u.ru> = 六院 'six divisions' (lit. 'six upper')
-un is a genitive suffix for stems with -u or -w; this implies that either SIX or some word ending in what sounds like SIX had -u or -w, unlike Kane's (2009: 117) suggested readings nil or jir*. The previous two graphs are illegible, so this <SIX> may or may not be the end of a word.
<SIX u(.ru)> = 六院 'six divisions' (lit. 'six upper')
like <SIX u.ru> above, this <SIX u> comes before <SOUTH>, so I suspect 'six uru' was intended. <ru> has either been accidentally left out or <u> can also be read as <u.ru>.
Would an individual scribe write a word seven different ways within the same text? Could these graphs represent two or more words? Two or more (related?) morphemes for 'six'?
(12.16.17:20: There are nonmasculine and masculine Khitan small script graphs for 'six':
<SIX> and <SIX♂>
Perhaps gender was also indicated in the Khitan large script. However, both 'year' and 'division' are preceded by nonmasculine numerals in the Khitan small script, so gender cannot account for the variation in the epitaph for Yelü Qi.)
Why is there so much variation in the Jurchen script and the KLS? I think the variation is the product of a long tradition: namely, the "local (Southern Manchurian) tradition of writing" that Janhunen (2003: 396) proposed. Truly new creations like the Khitan small script, the Tangut script, and hangul have much less variation.
Next: No Kidd-in?
*12.16.17:05: Kane's nil is based on Jurchen nilhun 'sixteen' and Manchu niolhon 'sixteenth day of the first month', thought to be loanwords from Khitan. J -hun and M -hon may be from the Khitan word for 'ten'. The native Manchu expression for 'sixteen' is juwan ninggun 'ten six'.
Kane's jir is based on Mongolian jirɣuɣan 'six' < *ji-r-gu-pan, literally 'two' (*ji) times 'three' (*gu) (Janhunen 2003: 17).
The genitive suffix -un might point to a Khitan jirɣu 'six'.
11.12.14.23:59: FEMININE LINES
The Jurchen (large) script is usually considered to be a derivative of the Khitan large script which in turn is usually considered to be a derivative of the Chinese script:
One might expectJurchen (large) < Khitan large < Chinese
But in reality, the Khitan large script is not like nom or sawndip. Only a seemingly random sample of sinography - e.g.,- the Khitan large script to be an 'extended sinography' like Vietnamese nom or Zhuang sawndip with a Chinese core plus new characters for native (i.e., non-Chinese) words
- the Jurchen (large) script to be an 'extended khitanography' with a Khitan large script core plus new characters for native (i.e., non-Chinese and non-Khitan) words
'day' and 'month'
- is carried over while the rest of the script consists of un-Chinese elements and element combinations such as
'year' (cf. Chn 年)
And even shapes identical to Chinese characters have unfamiliar readings and/or meanings from a Chinese perspective: e.g.,
| Shape | Khitan reading (Kane 2009) | Khitan meaning | Liao Chinese reading | Chinese meaning |
| 上 | <ɣa> ~ <qa> | (phonogram for initial of Chn 行 *xang - so why doesn't Kane list its reading as <xa>?) | *shang or *chang | top |
| 至 | <an> | (phonogram for Chn 安, rhyme of Chn 韓 *xan, Khitan genitive suffix -an) | *ji | to arrive |
| 仲 | <shang> | (phonogram for Chn 上 'top') | *jung | middle brother (cf. 中 'middle') |
| 高 | <bai> | (phonogram for Chn 百 'hundred') | *gau | high |
| 囯 | <gúr> | state | *gui | state* |
| 午 | <iri> | name | *ngu | horse (Earthly Branch) |
| 正 | <asa> | pure? | *jing | correct |
| 未 | <o> ~ <u> | (phonogram for first syllable of olibun 'preface') | *ui | not yet |
| 仁 | <ku> | man | *zhin | humane (homophonous with 人 *zhin 'person' > hence its use in Khitan for 'man'?) |
| 夫 | <sh> | (phonograms for Chn 帥 *shoi 'commander') | *fu | man |
| 坐 | <oi> | *dzo | sit | |
| 由 | <xua> | (phonogram for Chn 化 'change') | *yeu | from |
The Jurchen (large) script is to the Khitan large script what the KLS is to sinography. KLS graphs seem to be recycled or modified at random in Jurchen:
| Jurchen | Khitan large script | Sinography |
|
|
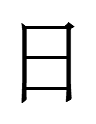 <?nair> 'day' |
日 *zhi 'day' |
 <aniya> 'year' |
<ai> 'year'/'father' |
年 *nien 'year' |
    <shunja>** 'five' (the first form is the oldest and the second the most common) |
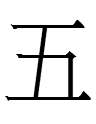 <tau> 'five' (Kane 1989: 21 lists a graph resembling a reversed 正 - is that still considered to be 'five'?) |
五 *ngu 'five' |
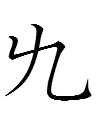  <uyewun> 'nine' (I am uncertain about the second form from Jin 1984: 179) |
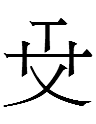 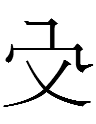 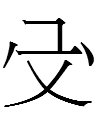  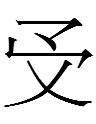 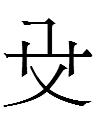  <is> 'nine' (the last one is clearly not related to the others, and Kane 1989: 21 lists a third type of 'nine' that looks like 一 atop 几 - is that graph still considered to be 'nine'?) |
九 *giu 'nine' |
If the Jurchen script was derived from the KLS, why were 'day' and 'year' more or less retained whereas KLS 'five' was replaced with completely un-Khitan, un-Chinese characters and 'nine' was replaced with a more Chinese-like character***?
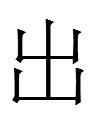
The shape and reading of the Chinese character 山 *shan was recycled in the KLS, but I don't know if it meant 'mountain' or not. In any case, Chinese and KLS 山 did not resemble Jurchen
<ali.in> alin 'mountain'
The first graph
~
~
<ali>
reminds me of Chn 牝 *pin 'female (of animals)' and Khitan small script
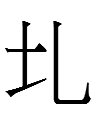
<ɣo>
but Jin (1984: 263) derived it from
an undefined KLS graph
or the nearly homophonous Jurchen graph
<uli> 'north'
which he derived from Chn 北 *bui 'north' (my reconstructed reading)
Is this an instance of one Jurchen graph as a phonetic in another Jurchen graph? How many other cases are there like this?
<uli> also resembles the KLS graphs for 'north':
which in turn resemble Chn 北.
I wonder if
was originally read as <alin> and
<in>
was added later as a phonetic clarifier. This second graph resembles Chn 列 *lie 'line'.
Next: Lots in Line
*12.15.17:49: Khitan gúr 'state' and Liao Chinese 國 *gui 'state' are not related in spite of their similarity. I plan to write about the histories of these two words in a separate post. I suspect that Liao Chinese *gui would have been written with phonogram(s) in the KLS.
**12.15.16:07: Jurchen shunja 'five' is cognate to Manchu sunja. I would like to look for other instances of Jurchen sh corresponding to Manchu s.
***12.15.16:17:18: Jin (1984: 179) notes that there is a KLS graph similar to Jurchen 'nine':
However, I don't know whether this graph represented a word meaning 'nine' or sounded like Jurchen uyewun 'nine'.
11.12.13.23:57: MOUNTAINS AREN'T FOREVER
Some Khitan large script (KLS) characters are (nearly) identical to their Chinese equivalents: e.g.,
<?sair> 'day' and <?nair> 'month'
look exactly like Chn 日 'day' and 月 'month'.
KLS 山 <shan> looks exactly like Chn 山 'mountain', which was pronounced *shan in the Chinese dialect known to the Khitan. But did KLS 山 also mean 'mountain', or was it a phonogram for the syllable <shan> regardless of meaning? I don't know.
The shape 山 represents the word 'gold' in the Khitan small script (KSS). The KSS graph for 'mountain' is quite different and resembles, of all things, the graph for 'eternal' which in turn vaguely resembles Chn 永 'eternal':
<MOUNTAIN> and <ETERNAL>*
The pronunciations of <MOUNTAIN> and <ETERNAL> are unknown. Were 'mountain' and 'eternal' (nearly) homophonous in Khitan?
Since Jurchen (large) script characters sometimes resemble KLS and even KSS characters, one might expect the Jurchen to recycle a Khitan character for 'mountain'. But the graphs (plural!) for Jurchen alin 'mountain' are quite different. What were they?
Next: Feminine Lines
Then: The Jade Hare and the Golden Bird*12.14.0:34: The Khitan small script graph
<ETERNAL>
also resembles a graph
"in the handcopy of the Renyi inscription where
<sh.?>
corresponds to 軍 *gün ['army'], normally writen
<g.ün>
Presumably a mistranscription."(Kane 2009: 49)
I'm puzzled because the pairs

<sh> and <g>
and
<?> and <ün>
don't look that much alike to me. Could there have been a native Khitan synonym <sh.?> for
<cau.úr> 'army'? Or could <sh.?> be an alternate spelling of <cau.úr> (perhaps <sh.aur>?) reflecting the para-Mongolic c > sh shift that Janhunen (1996: 397) posited? Is the handcopy reliable? Has anyone checked it with "the original stele [which] is still in the Yongxing tomb" (Kane 2009: 10)?
11.12.12.23:59: MORE JURCHEN MOUNTAINS
Chinese characters with common components usually represent morphemes with similar readings and/or meanings: e.g.,
山 shan 'mountain':
Phonetic in
舢 shan (first syllable of 'sampan*')
邖 shan (a place name and surname)
汕 shan 'basket for catching fish'
訕 shan 'to laugh at'
疝 shan 'hernia'
赸 shan 'to try to conceal embarrassment'
Semantic in
屹 yi 'high (of a mountain)'
屺 qi 'bare mountain or hill'
岌 ji 'high (of a peak)'
岑 cen 'high, pointed hill'
岡 gang 'ridge of a hill or mountain'
(These five examples are from the 1998 edition of the Far East Concise Chinese-English Dictionary.)
There are of course exceptions which represent
morphemes that have presumably lost their connection with mountains: e.g.,
岔 cha 'fork': e.g., 岔路 'branch road'
homophones of morphemes written with 山: e.g.,
岑 cen (first syllable of 岑寂 'quiet'; homophonous with 'high, pointed hill')
Jin Qizong's 1984 dictionary lists 12 characters under the 山 radical. This radical is a modern creation. We do not have a list of radicals written by Jurchen (or by Khitan or Tangut). I have looked at one of these twelve in "Heavy Mountains". Now let's look at his entries to see if they have any semantic and/or phonetic common denominator. My notes are in parentheses.
| Jurchen graph | Origin | Reading (in my revision of Jin's reconstruction) | Meaning | Select examples (in transcription only) | My additional notes |
 |
resembles two Khitan large script (KLS)
characters: 1. 山 atop 人 atop 寸 minus top half of vertical stroke 2. 山 atop the graph for the locative suffix: 寺 minus second horizontal stroke from top |
<mu> (and <shi>? - but Jin gives no examples) | perfective suffix (but Jin gives no examples of <mu> as a morpheme independent from <lu>; was <mu.lu> a single morpheme?) | <mu.lu> 'to complete'; homophonous
with Manchu mulu 'ridge of a mountain';
possibly cognate?: 'peak > 'to peak' > 'to complete'? no examples of <shi>) |
originally <mulu> with <lu> added later as a phonetic clarifier? |
 |
variant of Jurchen whose origin is unknown |
<hong> (too close to Chinese transcription; maybe <hon>?) | (none; phonogram) | <inda.hong> 'dog' (too close to Chinese transcription; maybe <inda.hon>?) | contains 山-like shape, but not 山 itself for the vowel cf. Old Manchu indahon > later Manchu indahūn 'dog' |
 |
resembles a KLS character 山 atop 亽 | <golmi> | <golmi.gi go.buren> 'to forgive' | cf. Manchu golmin 'long' Chn 長 'long' with the strokes rearranged? E on top turned 90 degrees (山) and bottom changed to X plus dot? |
|
 |
? | <ewu> | busy | <ewu.lu> 'then'; 'busy' | contains 山-like shape, but not 山 itself is 力 'strength' exerted by 人 people when busy? |
 |
resembles a KLS character 山 atop dotless 土 | <dusu> | sour | <dusu.hung> 'vinegar' (too close to Chinese transcription; maybe <dusu.hun>?) | cf. Manchu jushun 'vinegar', jushu-(hun)
'sour' root originally *düsü with *d and *s palatalizing before front vowels that later backed to u? |
 |
resembles a KLS character 山 atop 禾+丶 | <fi> | (none; phonogram) | <fi.bun> 'lamp', <a.fi> 'lion', <o.fi> 'because' | cf. Manchu ofi 'because' < o- 'be' + subordinative (perfective) converb -fi |
 |
resembles a KLS character 山 atop 大 | <nen> | the name <nen.ke.hun> | why did Jin reconstruct <nen> if the corresponding Chinese character was 南 *nam (later *nan?)? to harmonize it with <ke>? | |
 |
resembles KLS <lu> 'dragon' |
<mudu> | dragon | <mudu.r> 'dragon' | originally <mudur> with <r> added later as a phonetic clarifier? |
 |
? | <shen> | (none; phonogram) | <ju.shen> 'Jurchen' | the Jurchen had a 'gold' state, so did they
write their name with a graph incorporating Khitan small script 山 'gold'? |
 |
? | the name <giya.gu.?.bi> | dotted 山 may not be the same as 山 dotted 山 is <GOLD♂> in the Khitan small script why not undotted 山? there is no similar Jurchen graph without the dot is dotted 山 a phonetic? |
||
 |
Variant of <mudu>
above; resembles Khitan small and large script <lu> 'dragon' (rare case of small script graph derived from large script?) |
||||
 |
Resembles a Khitan large script character 一 atop 厶 x 2 atop ㅈ | ? | |||
Only the first graph has a possible connection to mountains. None sound like <shen> might have something to do with gold, but the rest seem like arbitrary line patterns with no common denominator. Yet I'd like to think they have some kind of internal logic. Did the Jurchen simply take a handful of Chinese characters more or less as is such as
<inenggi> 'day' (dot added in Ming Jurchen; cf. Khitan large script and Chn 日 'day')
<biya> 'moon, month' (dot added in Ming Jurchen; cf. Khitan large script and Chn 月 'moon')
and then assemble Chinese and Khitan character components at random to create 1,300 shapes that were arbitrarily assigned to words and syllables? Or is there some reasoning that eludes me?
Next: The Not-So-Eternal Mountain
Then: The Jade Hare and the Golden Bird
*12.13.1:08: 舢 has bugged me since I first discovered it because
舢舨 'sampan' is from Cantonese 三板 saampaan 'three planks'
but 山 is Cantonese saan, not saam
so why isn't the first syllable written as 舟 'boat'+ 三 saam 'three'?
because 三 isn't a common phonetic?
the first example I could think of was 仨 sa 'three' (colloquial; with 亻 'person' on the left; you'd think a less formal word would be written with fewer strokes, but no ...)
I forgot about 叁, the fraud-proofing form of san 'three' with an arbitrary addition, and 弎 'three' which can't be useful for fraud-proofing since one could easily create it by adding strokes to 弌 'one' and 弍 'two'.
hence 舢 looks like it should be read in Cantonese as saan, not saam - and it is read as saan (but I bet 舢舨 is saampaan like 三板 in natural speech - is it?)
I assume the Mandarin reading shan for 舢 is by analogy with 山 Md shan. (Cantonese merged *sh- with *s-, whereas standard Mandarin maintains the distinction. However, Md shan is not evidence for reconstructing an earlier *shampan 'sampan'!)
The second syllable of 'sampan' has been respelled as 舨 with 舟 'boat' instead of 木 'wood' as in 板 'plank'.