2007 2sie (cirfexgoncok; analysis unknown; cir = 'water')
0499 1pɪ̣ 'frog; turtle' (duubaejio)
10.11.20.22:20: GAPS AS GUIDES (PART 3)
In my last entry, I asked,
[W]hat do the fricative and sonorant classes have in common? Can you answer that question after examining these loanwords?
The earlier loanwords I listed have the pattern
| Sanskrit/Pali initial type | Modern Thai initial | Modern Thai tone |
| voiceless aspirated | voiceless aspirated | rising |
| voiced | mid |
whereas the later loanwords have the pattern
| English initial type | Modern Thai initial | Modern Thai tone |
| voiced | voiceless unaspirated | (omitted) |
(These tables are simplified and do not include all possible initial-tone associations.)
The key word is modern. Would the ancient Thai have borrowed voiced consonants as voiceless aspirates? No, because the two are at opposite ends of the voice onset time spectrum:
| positive VOT | voiceless aspirated |
| zero VOT | tenuis (voiceless unaspirated) |
| negative VOT | voiced |
Hence in terms of VOT, k is closer to g than kh. Thus English golf was borrowed as Thai kɔɔp rather than as *khɔɔp.
The ancient Thai borrowed Sanskrit guru as *gruu which later became khruu with a mid tone. Perhaps there was an intermediate stage *kɦ between *g and kh. (Cf. the *kɦ I proposed for Tangut last week.)
If they had borrowed a hypothetical khuru, it would correspond to modern Thai khruu with a rising tone.
Thus the ph-class turns out to really be a merger of two earlier classes:
- primary aspirates that were always aspirated (and are now associated with the rising tone in a subset of Sanskrit/Pali loanwords)
- secondary aspirates that were originally voiced (and are now associated with the mid tone in a subset of Sanskrit/Pali loanwords)
Let's call the second ph-class the b-class and look at tonal distribution again:
| Initial \ Tone | Mid | Low | Falling | High | Rising |
| p-class | ✓ | ✓ | ✓ | (rare) | (rare) |
| ph-class (primary) | (none) | ✓ | ✓ | (none) | ✓ |
| b-class (> secondary ph-class) | ✓ | (none) | ✓ | ✓ | (none) |
| f-, m-, w-, l-classes | ✓ | ✓ | ✓ | ✓ | ✓ |
Ignoring (rare) and counting the number of tones per initial, the table looks like this:
| Initial \ Tone | Number of tones |
| p-class | 3 |
| ph-class (primary) | |
| b-class (> secondary ph-class) | |
| f-, m-, w-, l-classes | 5 |
One can usually determine whether a ph-class word has primary or secondary aspiration by the spelling:
| Modern Thai ph-class initial | ph | th | chh | kh |
| Primary ph-class letter | ผ | ถ | ฉ | ข |
| Ancient Thai ph-class initial | *ph | *th | *chh | *kh |
| Secondary ph-class letter | พ | ท | ช | ค |
| Ancient Thai b-class initial | *b | *d | *j | *g |
(The chart has been simplified. There are even more letters, but I only intend to show the basic pattern.)
f-class initials also have two sets of letters (again, this table is simplified):
| Modern Thai f-class initial | f | s | h |
| Letter set 1 | ฝ | ส | ห |
| Letter set 2 | ฟ | ซ | ฮ |
What does this imply about the phonetic values of those letters in ancient Thai? Answer next time.
Hint 1: Compare the shapes of the modern ph- and f-class letters. Some are graphic cognates.
Hint 2: Some minimal pairs:
ฝาย faay R 'dam'
ฟาย faay M 'to scoop with one's hand'
สาน saan R 'to weave'
ซาน saan M 'to crawl; to struggle'
หา haa R 'to seek'
ฮา haa M 'the sound of laughter'
10.11.19.21:48: GAPS AS GUIDES (PART 2)
In my last entry, I asked,
[...] what distinguishes p-, etc. from the larger class of [Thai] initials with a full range of tones?
p, t-, ch-, k-, ʔ- are all voiceless unaspirated obstruents. I'll call this group of initials the p-class.
The other initials which differ from the p-class in one or more ways:
1. voiceless aspirated obstruents: ph, th-, chh-, kh- (ph-class)
2. voiceless fricatives: f-, s-, h- (f-class)
3. voiced sonorants:
a. nasal: m-, n-, ŋ- (m-class)
b. oral glides: w-, y- (w-class)
c. oral liquids: l-, r- (l-class)
Why are such disparate classes associated with five tones whereas the p-class is most commonly associated with three?
| Initial \ Tone | Mid | Low | Falling | High | Rising |
| p-class | ✓ | ✓ | ✓ | (rare) | (rare) |
| ph-, f-, m-, w-, l-classes | ✓ | ✓ | ✓ | ✓ | ✓ |
One might think that all classes were originally associated with five tones
| Initial \ Tone | Mid | Low | Falling | High | Rising |
| p-class | ✓ | ✓ | ✓ | ✓ | ✓ |
| ph-, f-, m-, w-, l-classes | ✓ | ✓ | ✓ | ✓ | ✓ |
until two categories merged with the other three after p-class initials: e.g., *rising merged with low and *high merged with falling:
| Initial \ Tone | Mid | Low | Falling | High | Rising |
| p-class | ✓ | ✓ (< *rising) | ✓ (< *high) | (gap!) | (gap!) |
| ph-, f-, m-, w-, l-classes | ✓ | ✓ | ✓ | ✓ | ✓ |
Current high and rising tone p-class syllables would be onomatopoeia and/or borrowings postdating the shift:
| Initial \ Tone | Mid | Low | Falling | High | Rising |
| p-class | ✓ | ✓ | ✓ | (late onomatopoeia/borrowings) | |
| ph-, f-, m-, w-, l-classes | ✓ | ✓ | ✓ | ✓ | ✓ |
However, that is not what actually happened. To unravel what really occurred, let's look at the situation from the opposite angle. What do the non-p-class initials have in common? Nothing at present:
| Class | ph | f | m | w | l |
| Voicing | - | - | + | + | + |
| Continuant | - | + | - | + | + |
| Sonorant | - | - | + | + | + |
The ph-class is identical to the p-class except for aspiration. However, if one viewed aspirated obstruents as Ch-fricatives (i.e., stop-fricative sequences), then the ph- and f-classes comprise a fricative class.
The other three classes (m-, w-, l-) can be grouped into a sonorant class.
Restating what I just asked, what do the fricative and sonorant classes have in common? Can you answer that question after examining these loanwords? M, L, F, H, and R represent tones of preceding syllables.
Premodern loanwords from Sanskrit and PaliS phala > T phon R 'fruit'
S braahmaṇa > T phraam M 'Brahmin'
P ṭhāna (cognate to station) > T thaan R 'station'
S daana (cognate to donation) > T thaan M 'gift'
S jana (cognate to gene) > T chhon M 'people'
S guru > T khruu M 'teacher'
(S/P chh-, kh- should correspond to T chh-, kh- with rising tones in syllables ending in sonorants, but I can't think of any examples. Aspirates are uncommon in S/P.)
Modern loanwords (ignore the tones)
chet L or H 'jet' (ch- is unaspirated)
Tones in modern loans are difficult to predict: e.g., according to regular Thai rules, chet and kɔɔp should both be L, but kɔɔp is H, and thai-language.com lists chet as both L and H!kɔɔp H 'golf'
22:45: Hint: Modern Thai has no j or g. But what about earlier Thai?
Last week, I proposed some possible future phonological systems for Korean dialects:
Future Seoul Korean| Tone | C- | Ch- |
| 1 | 1CV < CV (original lax initial) | (none!) |
| 2 | 2CV < CCV (original tense initial) | 2ChV |
Future Yanbian Korean
| Vowel | C- | Ch- |
| Lax | CV < CV (original lax initial) | ChV |
| Tense | CṾ < CCV (original tense initial) | (none!) |
The gaps would be filled with onomatopoeia and foreign loans, but the distribution of the four syllable types would never be even: i.e., 25/25/25/25. The low frequency of one type in each dialect (Seoul 2CV, Yanbian CṾ) would indicate that they are special (i.e., of secondary origin).
Such unbalanced systems are common in languages I'm familiar with.
Mandarin has four tones. The level tone is rare in syllables beginning with m- and n-. The first level tone m-words I could think of are 媽媽 mama (guess), 抹 ma 'wipe', and 貓 mao 'cat'. Examples of n-words are 捏 nie 'pinch' and 蔫 nian 'wither'. Mandarin level tone usually indicates an earlier voiceless initial. Earlier *m- and *n- were voiced, so nasal-initial syllables did not normally develop level tones. These words are exceptional because they include
- expressives ('mama', 'cat' < 'meow')
- former 'entering tone' (< final *stop) words like ma < *mat and nie < *net (whose subsequent tonal development is complex and unpredictable)
- at least one word with an original *ʔ-: nian, which may be a borrowing from a Mandarin dialect that underwent the shift
*ʔ- > Ø- > *ŋ- (> *ɲ-?)(Neither ŋ- nor ɲ- are permissible initials in standard Mandarin)
Thai has five tones. Here is their normal distribution in 'live' syllables ending in sonorants (vowels or nasals). Can you explain why certain tone-initial combinations are rare? In other words, what distinguishes p-, etc. from the larger class of initials with a full range of tones?
| Initial \ Tone | Mid | Low | Falling | High | Rising |
| p-, t-, ch-, k-, ʔ- | ✓ | ✓ | ✓ | (rare) | (rare) |
| ph-, th-, chh-, kh- f-, s-, h- m-, n-, ŋ- w-, l-, r-, y- |
✓ | ✓ | ✓ | ✓ | ✓ |
Hint 1: The history of Thai has some parallels with Mandarin.
Hint 2: ch- is unaspirated, whereas chh- is aspirated.
11.18.0:12: I excluded the initials b- and d- to simplify the puzzle. I'll explain why when I reveal the answer next time.
11.18.0:54: Hint 3: The shapes of the tones are irrelevant. The table could be simplified as
| Initial \ Tone | Tones 1-3 | Tones 4-5 |
| p-, t-, ch-, k-, ʔ- | ✓ | (rare) |
| ph-, th-, chh-, kh- f-, s-, h- m-, n-, ŋ- w-, l-, r-, y- |
✓ | ✓ |
Note how the structure of this simplified table is similar to that of the future Seoul Korean table at the top of this entry: a 2 x 2 grid with one (near-)gap.
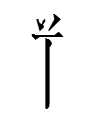
If 0492-(0614) 1kə-(2raʳ) from last night didn't mean 'turtle', what was the Tangut word for 'turtle'? In the bilingual Pearl glossary, 龜蛙 'turtle (and) frog' (following Nishida's 1964 interpretation) was translated as
and transcribed in Chinese as 寫 o百 *sie pɛ 'transcribe hundred'. (寫 is 'write' in modern Chinese. Tangut period northwestern Chinese had no syllable *pɪ̣, so *pɛ was the closest subsitute.)2007 2sie (cirfexgoncok; analysis unknown; cir = 'water')
0499 1pɪ̣ 'frog; turtle' (duubaejio)
I assume that 2007 is 'turtle'. It also apparently means 犀 'rhino' in some text I can't identify. (Li Fanwen calls the text 津. Is that an abbreviation of the name of the Tangutologist 李英津?)
2007 shares a right-hand side (fexgoncok) with two other tangraphs:
=
+
0297 2sie 'turtle; armor (< shell)' (tunfexgoncok; tun = 'skin') =
obviously the same word as 2007; originally devised for 'armor' but later confused with 2007?
23:46: 0297, like 2007, also means 'rhino'. I just realized that 2sie 'rhino', regardless of spelling, is a borrowing from Chn 犀 *sie.
1153 1dʒɨə 'skin' (tun) +
0021 1bɨu 'elephant, ox' (fexciagoncok; cia = 'not')
=
+
2131 1thoo 'to ripple, undulate' (dexfexgoncok; dex = 'person') =
2750 1ɣʊ 'head' (dexgoscin) +
cf. Homophones text D annotation: '2131: move the head'
0021 1bɨu 'elephant, ox' (fexciagoncok)
Do the heads of elephant and/or oxes ripple?
fexgoncok is phonetic in 2007 and 0297 but not 2131. Is fexgoncok (which cannot stand by itself) really an abbreviation of 0021? Why was cia 'not' removed? Did 0021 really mean something like 'large mammal'? If it did, why is it in two tangraphs for 'turtle'? Turtles aren't mammals.
0588 1tsiụ 'spider' (fiajio) from last night's post has this annotation in the D version of Homophones:
0492 1kə (daijio; oddly dai is a phonetic for raʳ, so I'd expect it to sound like 0614 below)
0614 2raʳ (hukjio)
The second and third tangraphs share jio 'bug' with 'spider' and have similar left-hand radicals (dai and jio). One might expect the two tangraphs to be a synonym of 1tsiụ 'spider', but Li Fanwen (2008: 84, 100, 105) translated 0492-0614 1kə-2raʳ as 龜蛙 'turtle frog'. He then translated 0492 and 0614 in isolation as 龜 'turtle' and 蛙 'frog'. But what do spiders have to do with turtles and frogs? There is no obvious semantic or phonetic relationship between the words represented by these three tangraphs. Are they together simply because they look like each other?
I am not sure that Li's translations for 0492 and 0614 are correct.
First, 0492 1kə only precedes 0614 2raʳ, so 0492 is not an independent word.
Although it is tempting to compare 0492 1kə (his 'turtle') with Old Chinese *kʷrə
- the phonetic correspondences are loose
- Li (2008) does not list any attestations of 1kə in running text which unambiguously mean 'turtle'
On the other hand, Tangraphic Sea defines 1kə as 1pɪ̣ 'frog; turtle' and derives 1kə and 1pɪ̣ from each other:
=
+
0492 1kə (daijio) =
0754 1kə 'coarse, rough' (daigolcin; phonetic) +
0499 1pɪ̣ 'frog; turtle' (duubaejio)
+
+
0499 1pɪ̣ 'frog; turtle' (duubaejio) =
2485 2pɛ̣̃ 'tadpole' (jioduudex) +
2383 1bõʳ 'bag, pocket' (baegiijio; function unknown) +
0492 1kə (daijio)
Moreover, the annotation for 0499 in the D version of Homophones is also 0492-0614:
But there is no guarantee that the meanings of 0492-0614 and 0499 completely overlapped, particularly since the two words are not cognate. 0499 1pɪ̣ may have been a generic word for four-legged small aquatic animals, whereas 0492-0614 1kə-2raʳ may have specifically meant 'frog'. 0492-0614 1kə-2raʳ has an initial similar to the *k- of Old Chinese 蝌蚪 *khwajtoʔ 'tadpole', but the two are otherwise too different to be cognates.
Second, 0614 2raʳ only follows 0492 1kə, so 0614 is not an independent word. Hence I regard 0492-0614 1kə-2raʳ as a disyllabic word for a kind of frog.
11.16.1:08: I forgot to include the analysis of 0614:
=
+
0614 2raʳ (hukjio) =
1791 2raʳ 'coarse, rough, rude' (hukdum; phonetic; also synonymous with the phonetic 0754 1kə in the analysis of 0492 - are their similar meanings coincidental?) +
0499 1pɪ̣ 'frog; turtle' (duubaejio)
There is no guarantee for total semantic overlap between 0614 (which may only be half a morpheme) and 0499: i.e., even if 0614 were an independent word, it might not have meant both 'frog' and 'turtle'.
Third, I would rather not specify 'turtle frog' because turtle frogs are only in Australia. In modern Chinese, 龜蛙科 'turtle frog family' refers to Myobatrachidae in Australia and New Guinea. Was 龜蛙 'turtle frog' a premodern Chinese word for a kind of Asian frog? If 0492 and 0614 were independen words for 'turtle' and 'frog' despite my doubts, was the Tangut expression 0492-0614 'turtle frog' a calque or an original compound without a Chinese basis? In any case, a Tangut 0492-0614 1kə-2raʳ '(turtle?) frog' was not an Australian turtle frog.
10.11.14.21:14: THE GOLDEN GUIDE: LINE 92: TANGRAPHS 456-460
92. I can't explain the slight phonetic mismatches of 2387 and 5970. Exact matches (tshiã and pɛ) were theoretically possible. Perhaps my modification of Gong's Tangut period northwestern Chinese reconstructions are wrong. (His reconstructions also don't match: his Tangut 2tshjɨj and 1pie correspond to his Chinese *tshjã̃ and *piej, though the latter are theoretically possible in his Tangut reconstruction.)
| Tangraph number | 456 | 457 | 458 | 459 | 460 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 5471 | 1484 | 2387 | 5970 | 3135 |
| My reconstructed pronunciation | 1yõ | 1kiu | 2tshiẽ | 1pɪ | 2vɨã |
| Tangraph gloss | (transcription of Chinese) | (transcription of Chinese) | purple, violet | wide, broad | (transcription of Chinese) |
| Word | the surname 羊/楊 Yang (*yõ) | the surname 鞠 Ju (*kiu) | the surname 錢 Qian (*tshiã) | the surname 伯 Bo (*pɛ) | the surname 萬 Wan (*wɨã) |
| Translation | 羊 Yon, 鞠 Ku, 錢 Tshen, 伯 Pi, 萬 Van | ||||
456: 5471 looks like a phonetic-semantic compound:
+
5471 1yõ (transcription of Chinese) (doopux) =
5087 1yõ (transcription of Chinese) (doogiicok) +
2888 2mə 'surname' (dexpux)
Why were both 5471 and 5087 necessary for 1yõ? One might think 5471 was reserved for surnames since it contained the surname radical pux, but 5087 could also represent surnames.
doo may be based on Chinese 羊 *jõ 'sheep'. This may explain the bizarre analysis
+
+
5087 1yõ (transcription of Chinese) (doogiicok) =
3452 2jie 'sheep' (baequupaa) +
2262 1dʒwɨõ 'bird' (giigirwur) +
2107 1tsəiʳ 'earth' (giigircok)
in which doo is supposedly extracted from parts of 3452 'sheep'. The functions of 'bird' and 'earth' are unknown.
21:30: Compare doo to gon which has an extra stroke:
gon, a phonetic for ja, is probably another derivative of 羊 *jõ 'sheep'.
457: 1484 has a circular analysis. 1811 must be derived from 1484, but not the reverse.
+

1484 1kiu (transcription of Chinese) (boadux) =
1045 2dạ 'language' (pulcun; cun 'langage' is the right-hand variant of boa) +
1811 1kiu 'eardrop' (boafaajum; faa is a stretched version of dux)
1811 1kiu 'eardrop' (boafaajum) =
1484 1kiu (transcription of Chinese) (boadux; phonetic) +
4681 1niu 'ear' (biobaebescin; semantic; biobes = jum)
458: What is 'spider' doing in 2387? I might expect 'purple' to be from 'blue' plus 'red', not 'spider'. And could readers really guess that a vertical line stood for 'blue'?
+
2387 2tshiẽ 'purple, violet' (baefiajio) =
0257 1ŋwəʳ 'blue, green' (bokbaefus) +
0588 1tsiụ 'spider' (fiajio) (resemblance to 2nd half of Chn 蜘蛛 *tʃɨi-tʃɨu 'spider' coincidental)
459: 5970 is derived from its synonyms. Do they have different nuances?
+
5970 1pɪ 'wide' (panyun) =
5864 1zie 'wide' (pandex) +
4874 2lõ 'wide' (yun)
460: 3135 transcribes the Chinese word for 'ten thousand' and contains the tangraph for the native word for 'ten thousand' as a cryptophonetic. 'Before' may be an arbitrarily chosen 'source' for dex 'person'.
+
3135 2vɨã (transcription of Chinese) (dexbixbaebumcin) =
2104 1ʃɨi 'before' (dexgirjem) +
0966 2khiə 'ten thousand' (bixbaebumcin)