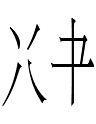~
~
11.12.3.23:59: OPEN SYLLABLE ORCHIDS
Last month, I wrote,
I don't understand why -let [of Chevrolet] was Sinified with a final -n [in Mandarin 雪佛蘭 Xuefolan 'Chevrolet', transcribed as 'snow Buddha orchid'].
I thank 龔勛 Gong Xun for solving this mystery. He reminded me that Wu languages have -e-type rhymes from *-an: e.g., in Suzhou pronunciation*, 雪佛蘭 is siɤʔ vɤʔ le with a final open syllable.
(12.5.00:50: Note the lack of a labial glide in Suzhou siɤʔ unlike Mandarin xue [ɕɥe]. If I were to create a Mandarin-based Sinification of 'Chevrolet', I would pick xie [ɕje] or she [ʂɤ] for the first syllable, not xue.)
He also reminded me that the use of voiced obstruents to represent foreign voiced obstruents is another Wuism: e.g., the correspondence of Suzhou -v- with the -v- of Chevrolet. Other examples he gave were:
喬治 'George' (which has been puzzling me until now!)
Suzhou dʑiæ zʮ
Md Qiaozhi [tɕhjawtʂr̩]
堂吉訶德 'Don Quixote'
Suzhou dɒŋ tɕiɤʔ (?həu) tɤʔ (the reading for 訶 is not in 漢語方言字匯 and is my guess)
Md Tang Jihede [thaŋ tɕixɤtɤ]
吉 still has k- in other languages: e.g., Hakka kit, Cantonese kat, Xiamen kiat
Gong Xun has come to my rescue twice before in two very different
areas. He helped me figure out how
Ukrainian o became i
and he explained the development of
Japanese uo 'fish'. Who knows how he'll help me next?
*12.4.22:02: Suzhou forms are from the 1962 edition of 漢語方言字匯 which is the only one I own. How different are the later editions?
I'm used to working with outdated books. For a couple of years, I
only owned Karlgren's 1940 Grammata Serica until I got a copy
of his 1957 Grammata Serica Recensa.
11.12.2.23:56: GOLDEN BONES AND TIGERS
The 阿 什河 Ashi River in Heilongjiang was once known as1. 安車骨水 *ʔan tɕha kot ɕwiʔ (晉 Jin to Tang Dynasties)
2. 按出虎水 *an tʃhu xu ʃui (金 Jin Dynasty)
3. 金水河 *kin ʃwi xo (Ming Dynasty)
4. 阿勒楚喀河 *a lə tʃhu kha xo (early Qing dynasty; Ashi dates from 1725)
in Chinese. The first, second, and fourth names are transcriptions of a Jurchen word for 'gold' plus a second morpheme (a suffix?). The third name is literally 'metal water river' in Chinese.
The oldest river name may reflect a word like *alca < ?*altya with *a as a second vowel instead of the *u in the later names. *altya is closer to Written Mongolian alta(n) than Turkic altun-type forms or Jurchen ?alcun.
The last transcription character of the first name (骨 *kot 'bone') may have represented a morpheme *kʊr which later became *xʊr (transcribed as 虎 *xu 'tiger') due to Vovin's (2010: 31) *-k-lenition rule. If the final morpheme ended in *-t or *-d, I would expect later transcriptions to end in Chinese *t(h)-initial characters since final *-t had been lost in the northeast after the Tang Dynasty: e.g., *按出虎忒 *an tʃhu xu thə for *alcuxʊt.
The fourth river name implies that the Jurchen word for 'gold' was *alcun rather than *ancun. If the word were *ancun, a post-Jurchen form would not begin with al-. There was no sound change *-n- > -l- in Manchu. I now regard the *-n- in the Chinese transcription 安春 *anchun as an approximation of Jurchen *-l-.
The fourth transcription may have represented Manchu Alcuka with an unlenited -k- and an open final syllable. This -ka may have nothing to do with the earlier *kʊr. Manchu medial -k- implies an earlier *-Nk- or could be an irregular archaism. Does anyone know the Manchu name(s) of the river?
Could the final name Ashi be an irregular transcription of aisin, the native Manchu word for 'gold'? (The regular transcription is 爱新 Aixin.)
Next: Open Syllable Orchids12.3.21:39: I'm glad I didn't upload this entry on time last night because I found even more Chinese transcriptions of the river name this afternoon. Unfortunately, none are dated, so I'm not sure how to reconstruct the readings that were current when they were devised. I'll list their modern standard Mandarin pronunciations followed by an approximate archaization.
Names with -l- for Jurchen *-l-Comments on variation
5. 阿禄阻 Aluzu / *a lu tsu
(6. Baidu baike has 阿禄祖 Aluzu / *a lu tsu)
Names with -n- for Jurchen *-l-
7. 按出滸 Anchuhu / *an tʃhu xu
8. 安珠胡 Anzhuhu / *an tʃu xu
9. 安出虎 Anchuhu / *an tʃhu xu
10. 按春(水) Anchun(shui) / *an tʃhun + Chn 'water, river'Names with zero for Jurchen *-l-
11. 阿觸胡 Achuhu / *a tʃhu xu12. 阿赤阻 Achizu / *a tʃi tsu
13. 阿之古 Azhigu / *a tʃi ku
14. 阿注滸 Azhuhu / *an tʃu xu
15. 阿芝(川) Azhi(chuan) / *a tʃi + Chn 'river'
16. 阿脂(川) Azhi(chuan) / *a tʃi + Chn 'river'
17. 阿術滸 Ashuhu / *a ʃu xu18. 阿術火 Ashuhuo / *a ʃu xwo
1. Transcriptions of *-c-: *tʃh ~ *tʃ ~ *ʃ
Perhaps the distinction between Jurchen *c and *j was one of voicing which did not match the Chinese distinction between unaspirated *tʃ and aspirated *tʃh.
2. Transcriptions of the vowel after *-c-: *u ~ *iCould the *ʃ-transcriptions be due to confusion with aisin 'gold'? None of the *ʃ-transcriptions have an *l or *n before *ʃ.
Could the word for 'gold' have been *alcïn or even *alcin in some Jurchen dialect(s)?
Cf. the vowels of Turkic forms like modern Turkish altın and Kazakh and Tatar алтын and perhaps Manchu aisin (which may not be native after all, but a loan from some ancient Turkic or para-Mongolic language into Proto-Tungusic)
I don't mean to imply that Jurchen got the word from Turkish, Kazakh, or Tatar, but that those languages have words for 'gold' whose second vowels may resemble the lost ancient source of Jurchen *alcïn ~*alcin.
3. Transcription of final *-n
Only one transcription (按春 Anchun) has a final -n. I presume 'gold' was *alcun in isolation and this isolation form got confused with the stem form *alcu- used in compounds like *alcu-kʊ (phonetically *[altʃuqʊ].4. The final syllable (morpheme? suffix?) *-KU
- is sometimes absent
- is transcribed as *ku ~ *xu ~ *xwo (and the oldest transcription is *kot)
The *k-transcriptions represent more archaic forms that had not undergone *k-lention.
The vocalic variation could indicate that the Jurchen vowel was *ʊ corresponding to later Manchu ū [ū]. There was no phoneme *ʊ distinct from *u or *o in the 金 Jin, Ming, and/or Qing Dynasty dialects underlying these transcriptions.
No transcription other than the very first one (安車骨 *ʔan tɕha kot) reflects a final consonant.
11.12.1.23:59: DYE AND DRY
In "From Alcun to Aisin Again", I proposed that Jurchen
alcun 'gold'
"was a borrowing from some extinct para-Mongolic language like Xianbei" but didn't clarify whether I thought alcun was related to Altaic alt-words for gold. Let me add a few more details to my scenario:
- The alt-word originated in Turkic and was something like *altuun (Clauson 1972: 131)
- *altuun was borrowed into a para-Mongolic language (Xianbei?).
- At some point it became something like *alcun.
- Are there any cases of Xianbei *c : Mongolic t, particularly before u?- Was the word originally *altün before being harmonized to *altun? Could *alcun be from preharmonized altün with t palatalizing before a palatal vowel?
- Jurchen speakers borrowed this word which was not related to the native Tungusic word aisin 'gold'.
- a variant like *altïn (cf. modern Turkish altın) was borrowed from some other early Turkic language into Proto-Mongolic or some direct ancestor of PM as *altan. (I assume the second vowel was delabialized to account for the nonlabial second vowel of PM *altan. I would expect Turkic *altuun to have been borrowed as PM *altun. T *ï could have been borrowed as PM *a since PM lacked *ï which had merged with *i.)
- the mismatch between Turkic *altuun and Mongolic altan reminds me of the mismatch between Khitan
<qid.un> 'Khitan'
and exonyms like Middle Chinese 契丹 *khɨttan and Korean 거란 kŏran < *kətan.
If Jurchen borrowed 'gold' from Xianbei rather than Khitan - which had at least one non-alt word for 'gold'
<n.i.gu>

- what other Xianbei loans could be in Jurchen and, by extension, Manchu? Last night it occurred to me that Manchu nikan 'Chinese' might be from the Xianbei word for 'Chinese' transcribed in Late Old Chinese as 染干 *ɲiemʔkan, lit. 'dye dry'. The sequence *ɲe was not possible in LOC, so perhaps LOC *ɲiemʔkan represented a Xianbei *ɲemkan (without vowel harmony?).
12.2.2:01: Alexander Vovin (1996 class handout; 2010: 31) proposed that
Manchu n- < Proto-Tungusic *ɲ- as well as *n-
Manchu i < Proto-Tungusic *e as well as *i
(Manchu e is from PT *ä, not PT *e.)
Manchu -k- < *-Nk-
so the sound correspondences between the two words are perfect if we assume the word entered some ancestor of Manchu prior to the application of those three sound laws.
| Xianbei | ɲ | e | mk | a | n |
| Manchu | n | i | k | a | n |
By coincidence, Xianbei *ɲemkan and Manchu nikan were both personal names:
賀蘭染干 Helan Rangan, brother of 賀蘭太后 Princess Dowager Helan, mother of 道武帝 Emperor Daowu, founder of Northern Wei
禿髮染干 Tufa Rangan, son of 禿髮傉檀 Tufa Rutan of Southern Liang
尼堪 Nikan, son of 褚英 Cuyen, son of 努爾哈赤 Nurhaci, founder of the Qing Dynasty
Rangan and other Xianbei names are modern Mandarin pronunciations of their LOC transcriptions.
I recall that Vovin proposed that Manchu nikan was from Middle Chinese 人間 *ɲinkɛn. Although this etymology is phonetically plausible, 人間 means 'human world' (lit. 'person-space'), not 'Chinese'. (人間 does mean 'human being' in Japanese, Korean, and Vietnamese, but I presume this is a modern meaning.)
I have no idea what Xianbei *ɲemkan originally meant. It does not resemble any Chinese word for 'Chinese'. I wonder if it's like Russian немец 'German' (no relation to *ɲemkan!) derived from нем- 'mute': i.e., a completely native word describing some attribute of the Chinese. This original Xianbei meaning would have been lost in Manchu many centuries later. Was Nikan, the son of Cuyen, called 'The Chinese', or was his name unrelated to nikan 'Chinese'?
Next: Golden Bones and Tigers
11.11.30.23:59: ENIGMA OF THE EIGHT BOWMEN
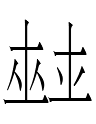
In "Baffled b-ai Beauty", I mentioned the Khitan large script (KLS) graph sequences
<k.ai> (line 2) and <k.ai> (line 10)
from 耶律褀墓誌. The first graphs for <k> (also <ka>, <ke> in Kane 2009: 179) look like combinations of 八 'eight' and 人 'person' atop 弓 'bow'. In "*Ai<-mbiguity", I proposed that these graphs were derived from Liao Chinese 兮 *xi with a slightly different bottom element.
The second KLS <k> graph looks exactly like the Jurchen graph
I'm surprised that Jin (1984: 231) did not list any derivation for it. It must either have been borrowed from the KLS or from some common ancestor of the KLS and Jurchen (large) script. I doubt that the Jurchen literate in Khitan reinvented the character out of Chinese parts without remembering that such a character already existed in the KLS.
One might guess that the Jurchen character
- was read something like <k> or <x>
- and/or meant 'eight', 'person', or 'bow'
But it turns out that it is an apparently meaningless phonogram for the Jurchen syllable <jan>. Why? I cannot think of any Chinese character pronounced like <jan> with a similar shape, and none of the graphs' components have <jan>-like readings in Liao or Jin Dynasty Chinese:
八 *ba 'eight'
人 *zhin 'person'
弓 *giung 'bow' (*gi is close to <k> and <ke>)
There is a Manchu word jan defined by Norman as 'a whistling arrow with a bone head with holes in it'. Is it a coincidence that
contains 弓 'bow'? Was it originally a logogram for a hypothetical Jurchen cognate jan 'a kind of arrow' before being recycled for writing the syllable jan in other contexts?
(12.1.2:48: There are only about 1400 known graphs in the Jurchen [large] script including variants. What is the proportion of logograms to phonograms? The number of logograms must be less than 1400. Would a logogram have been devised for such a specific kind of arrow instead of thousands of other words? Were jan-arrows particularly important to the Jurchen in spite of their absence from extant texts? A Jurchen military historian might know.)
Could the 人+弓 graph also have had a Khitan logographic reading <jan> in addition to phonogram readings <k(a/e)>? If so, could the Jurchen word jan be a loan from Khitan, or would Khitan <jan> have meant something completely different?
Could Jurchen jan be a translation of a Khitan word like ka or ke?
Next: Dye and Dry
11.11.29.23:36: BAFFLED B-AI BEAUTY
In "*Ai-mbiguity", I asked if the Khitan large script (KLS) graph

<ai>
was a variant or damaged version of
<ai> 'year'/'father'
If it were either of those things, the two <ai> might not coexist in the same text, though there's no guarantee someone would spell consistently. And more importantly, if the damaged hypothesis were correct, there should only be one instance of the first <ai> because it's unlikely that <ai> would be damaged the same way more than once.
Neither of those predictions were correct. Andrew West pointed out that the first <ai> appears a total of 15 times in just four KLS texts, and I'm embarrassed to admit that one of them was 多蘿里本郎君墓誌銘, the only KLS text I've ever had a good look at. Moreover, the second <ai> also appears in all four texts. So the two <ai> are distinct. But why were two characters devised when one would have sufficed to write [ai] in all contexts? The first <ai> appears in two spellings I predicted on Sunday
<k.ai> (耶律褀墓誌 line 2) and <k.ai> (耶律褀墓誌 line 10)
which may represent a Liao Chinese syllable *kai. What would have been wrong with using the other <ai> to write that syllable as
<k.ai> and <k.ai>?
The mysteries don't end there. It's well known that there is graphic and even semantic overlap between the Khitan large script and the Jurchen (large) script: e.g., 'year':
:
Khitan <ai> : Jurchen <aniya>
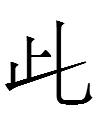
Can Jurchen help us understand the KLS better? Jin Qizong (1984: 223) derived Jurchen
(with a variant
)
<hojo> 'beautiful' (cf. Manchu hojo 'id.')
from KLS
<ai>
If there is a relationship between the two graphs, did the KLS graph also represent a Khitan word ai or even have a second reading like xojo or qojo 'beautiful'?
Khitan q in
<qa.ɣa> 'qaghan' (in the small script; is the KLS spelling known?)
corresponds to Jurchen h [x] in
<ha.an> ha(a)n [xa(a)n] 'qaghan'.
Cincius (1975 II: 468) lists no cognates for hojo outside Jurchen and Manchu, so it may be a Jurchen innovation (and a loan from Khitan?).
I still have not found the right side of
as an independent KLS character, but the right side of
<hojo>
is an independent Jurchen character
<dalba> 'side' (cf. Manchu dalba 'id.')
which Yamaji derived from Chinese 半 *ban 'side' (Jin Qizong 1984: 60). Is <dalba> related to <hojo>?
What is the function of the left sides of <hojo> which are not in any other Jurchen characters I've seen?
Next: Enigma of the Eight Bows
11.11.28.23:58: FROM ALCUN TO AISIN AGAIN?
In my last post on Jurchen ?alcun 'gold' and Manchu aisin 'gold', I left out the comparative evidence for these words.
Tungusic aisin-words for 'gold' (Cincius 1975 I: 22-23)Neghidal aysịn
Oroch aisi(n-)
Udehe aisi
Ulchi aịsị(n-) ~ aysị(n-)
Orok aysị(n-)
Nanai dialects: aysị̃, aịsị(n-) ~ aịsya(n-)Manchu aisin
Sibe aishin
Altaic alt-words for 'gold'
Tungusic (Cincius 1975 I: 33):
Written Mongolian alta(n)Evenki dialects: altan 'gold' or 'copper', aldun 'tin'
Solon altã, altá ~ altán
Neghidal altan 'copper'
Oroch akta (with -k- < -l-!) 'tin, zinc'
Udehe alta ~arta 'tin, zinc'
Ulchi alta(n-) 'tin'
Nanai dialects: altã, alta(n-) 'tin'
Manchu Altahatu 'name of a mountain'
Clauson (1972: 131): Early Turkish altuun
The Jurchen word for 'gold'
was transcribed in Chinese as 安出 *anchu and 安春 *anchun. It is impossible to tell whether Chinese *-n- represented Jurchen *-n- or was an approximation of an *-l or *-r that would have been impossible after a vowel in that variety of Chinese.
I have already explained in my earlier post that sound correspondences rule out Jurchen alcun (or ancun or arcun) being an ancestor of Manchu aisin. The comparative evidence indicates that aisin can be reconstructed at the Proto-Tungusic level. I would rather not claim that Jurchen preserved *alcun while all other languages including Jurchen's closest relative Manchu shifted *alcun to aisin in precisely the same irregular manner.
I think the Tungusic alt-words are borrowings from Mongolian with Tungusic-internal semantic shifts from 'gold' to other metals. Mongolian alta(n) in turn is a borrowing from Turkic.
Perhaps Jurchen alcun was a borrowing from some extinct para-Mongolic language like Xianbei. Khitan had a different word for 'gold':
<n.i.gu>
Or maybe Khitan was the source of Jurchen alcun. The Khitan logograms
<GOLD> (large script) ~ <GOLD> ~ <GOLD♂> (both small script)
~
~
could have been pronounced alcun (possibly with modification for the masculine form), but there is no way to determine their readings.
11.11.27.21:14: *AI-MBIGUITY
In "Ten-Point Evenings", I mentioned four Khitan large script characters with the right-hand element 十 'ten' +丶.
The first two may be variants of each other. I don't know their meanings or readings.
The second two are transcriptions of Liao Chinese 聖 *shing 'sage, sacred, holy'.
Later last week I found a fifth KLS character with the same right side:
I have not seen the left side in any other KLS character. It looks like a compromise between Chn 爿 'bed' and丬'split bamboo'. Kane (2009: 181) lists it as 5.160 "[ai] (開 final)" and as an equivalent of the small script
<ai>
There is another <ai> in the KLS which represents both ai 'year' and ai 'father':
When did the Khitan use one <ai> instead of the other? Was one reserved for the native words 'year' and 'father' while the other was reserved for transcribing Liao Chinese syllables like 開 *kai which might've been written as
~
<k.ai> ~ <k.ai>
The KLS graph for <k> (also listed by Kane 2009: 179 as [ka] and [ke]) resembles Liao Chinese 兮 *xi. The Khitan small script transcriptions
~
<k.ai> ~ <x.ai>
for 開 imply that the initial *k- ([kh] in strict notation) may have had a lenited variant *x-. Is there any northeastern dialect of Chinese that has x- < *kh-? Such lenition did independently occur in Cantonese and Vietnamese which are far from Khitan territory: e.g.,
Ct 開 hoi < *khaiViet 開 [xaaj] < *khai [khaaj] (still spelled khai today)
Perhaps <x> reflects Khitan perception/approximation of a Liao Chinese [kx] as x. If the Khitan were uncertain about the initial of 開 as *k- ~ *x-, perhaps the creator of the KLS used a hypercorrect (and therefore wrong) k-reading of 兮 as the basis for the <k>-graphs
~
Or maybe the above graphs should be interpreted as <x> ~ <xa> ~ <xe> - or <x> plus (certain?) unwritten vowels. The readings of many Khitan large and small script graphs are currently ambiguous. Perhaps a better understanding of the structure of both scripts will reduce this ambiguity in the future.
Ai-ddendumAndrew West suggested that Written Mongolian on 'year', Khitan ai 'year', and Jurchen aniya 'year' are cognate.
I recall seeing an ai-aniya connection suggested somewhere, but I can't remember the source. Given how Khitan words often do not have final vowels or syllables found in their cognates elsewhere, I think it's possible that a pre-Khitan *aña could have become ai. (Another possible case of *ñ > i in Khitan might be the Kitai-type variants of the name 'Khitan'.) The pre-Khitan form could have been borrowed from some descendant of Proto-Tungusic *añŋa 'year'.
I don't think WM on is related because it lost a x- present in other Mongolic languages. Like some unnamed scholars Kane mentioned (2006: 131), I regard WM on < *xon as being cognate to Khitan
which was borrowed into Jurchen as
~
<TIME> *po 'time' (in the large and small scripts*)
~
<po.on> ~ <po.on> *pon 'time'
and ended up as fon 'time' in Manchu.
Kane (1989: 16) wrote,
"There are also cases where the meaning of an ideographic character is nown, but not the pronunciation; in some cases it is possible to guess the reading of an ideogram [in the Khitan small script], for example,
means 'year'; and the word for year in the vocabulary appended to the History of the Liao Dynasty is transcribed by the Chinese character 桓 (Modern Standard Chinese huan); on the basis of this the tentative reading *hon has been given to this character."
If there was a Khitan word *hon 'year', then
*po 'time' is not cognate to *hon 'year', and Jurchen *pon cannot be from *hon 'year'
or *po 'time' is from a *p-preserving dialect whereas *hon is from a *p-leniting dialect, but there is no other evidence for *p- ~ *h-variation in Khitan
However, I can't find 桓 as a transcription "in the vocabulary appended to the History of the Liao Dynasty", and I don't recall Kane mentioning 桓 in his 2009 book.
Next: From Alcun to Aisin Again?
11.27.21:45: Ai-ddendum II: Could
<ai>
be a variant of
<ai> 'year'/'father'
with missing top and top right strokes? Or is the first <ai> a damaged version of the second <ai>? In other words, was there only one KLS <ai> graph with or without damage?
(11.29.22:09: No, no, and no.)
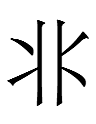
*po 'time' was written with a
logogram ![]() <TIME> in the small script, whereas its homophone
(?) 'monkey' was written as polygrams
<TIME> in the small script, whereas its homophone
(?) 'monkey' was written as polygrams
~
<p.o> ~ <p.o.o>
Did 'time' and 'monkey' respectively have short and long vowels?