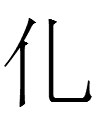11.11.4.23:59: A TANGUT QUA-NDARY
On Halloween, I wrote 'Halloween' in Tangut as
1xa 1lo 1ʔwĩThe last tangraph 1ʔwĩ has a right-hand element 'fat' that is pix in David Boxenhorn's alphacode. In other tangraphs, pix is broken up into a vertical line (alphacode bae) that is the same height as the right-hand elements (alphacode hem):
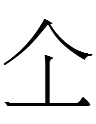
And in three other tangraphs, the vertical line of pix/baehem 'fat' is placed beneath a 'roof' (just a nickname, not a serious gloss) next to a 'person':-
0969 2dʒɨiʳ 'butter'
0984 1tshwəu 'fat, corpulent' (why is 'horse' on the left?)
1195 2khɪ 'yak'
=
+

3966 1vɨị 'taste' = 3968 (below) + 1197 'fat, grease' (with pix)
borrowed from Chn 味 *wi 'taste'
3968 2khɪ 'taste' = (analysis unknown; 3966 above + 0969 'butter'?)
native word for 'taste' not attested outside dictionaries? ritual language word in spite of its brevity?
=
+
This 'roof-person-vertical line' combination has the alphacode qua.4243 1vɨị 'pear' = (analysis unknown; 4250 'tree' + 3966 1vɨị as phonetic?)
Nishida (1966) has no gloss for 'roof' + 'person' without a vertical line:
What does it stand for in the three qua-tangraphs? Why did the vertical line of pix/baehem have to be written under the 'roof'? Why not consistently draw the vertical line at the same height relative to its right-hand neighbor?
Could pix/baehem 'fat' be a Tangutization of Chn 脂 'fat'?
| 月 | 旨 |
 bae |
 hem |
Next: Men with Hats
11.11.3.22:51: SNOW BUDDHA GOOSEFOOT CENTENNIAL
The car company
is a hundred years old today.
<ś.e.b.or.l.e>
Chevrolet has at least three different Sinicizations. All Chinese readings are in Mandarin unless specified otherwise.
| Che | vro | let |
| 雪 xue 'snow' | 佛 fo 'Buddha' | 蘭 lan 'orchid' |
| 萊 lai 'goosefoot' | ||
| 福 fu 'good fortune' | 蘭 lan 'orchid' |
I don't understand why -let was Sinified with a final -n.
Lin Yutang's dictionary equates 萊 lai 'goosefoot' with 藜 li. This equation surprised me because the two graphs had different vowels in Old Chinese
萊 *rə(s) 'a kind of weed; to weed' (is the *-s form the verb?)
藜 *ri 'Tribulus terrestris'
and I couldn't think of any other -ə ~ -i alternations. The OC meanings are also quite different. How old is their later shared meaning 'goosefoot'? Is it a coincidence that both words have the same consonant?
*I don't know of any Khitan small script character for <ro>, so I approximated it with
<or>
I wonder if <or> could also stand for ro, just as
<ri>
could stand for both ri and ir (Kane 2009: 62).
<ra>
might stand for ar as well as ra, though the difference, if any, between ar written with <ra> and ar written with
<ar>
is not clear. I'll explain why later.
11.11.3.21:45: HOUSEHOLD HOLY TOMB
Yes, it's another Khitan
birthday
post.
<?.?.?.de* tumu eu.úr**>
But for a change, I'm not going to name the honoree in English. You can decipher his*** Khitan name
<?.?.?>
by studying the spellings of these three real Khitan words:
Here's one more hint: Blue Öyster Cult. Need I say more?goer 'house, household, tribal unit, tent'
muuji 'holy'

nera 'tomb'
*I now doubt that -de is the correct ending. I'll explain why later.
**I've been translating Chinese 萬歲 'ten thousand years' as
<tumu ai.se>
but now I wonder if it's
with <eu.úr> 'years of age' instead of <ai.se> 'years'.<tumu eu.úr>
Is either collocation attested? I can't find either in the Khitan small script texts I have on hand thanks to Andrew West.
***The Khitan equivalent of 'birthday' that I chose above gives away his gender:
<BORN.er DAY> (-er is a masculine past tense ending)
The birthday of a female is a
<BORN.en DAY> (-en is a feminine past tense ending)
See Kane (2009: 144).
11.11.2.22:55: DITKO-DO TUMU AISE!
Today is also the 84th
birthday
of
cocreator of Spider-Man:
It can be said without hesitation that the world of comics would be a very different place today without the contributions of Steve Ditko.
To him, I say,
Ditko-do tumu aise!
'To Ditko, ten thousand years (of life)!' = 'Long live Ditko!'
You may have noticed that other names in this series of posts were followed by
Maria-de 'to Maria'
The Khitan suffix for 'to' varies depending on the vowel that precedes it. If that vowel is o or u, the suffix vowel has to match it; otherwise, the suffix is -de:
| Preceding vowel | Suffix |
| a (e.g., Sera, Lash,
Maria) e i |
-de |
| o (e.g., Ditko) | -do |
| u | -du |
Note that the characters for the suffixes look nothing like each other, even though their readings share the consonant d. So it is not surprising that the character for di in Ditko looks nothing like them. These characters are clustered into stacks. Each stack represents one word.
Breakdown of Khitan for 'Steve'
 |
||
Breakdown of Khitan for 'Ditko'
 |
||
Khitan di may be reserved for writing the second syllable of hongdi 'emperor', but I thought it was fitting to write the name of a great comic book creator with the di for hongdi 'emperor'.
11.11.2.2:32: MARIA-DE TUMU AISE!
Today is the
birthday
of
Maria
so I wish to tell her in Khitan,
Maria-de tumu aise!
The Khitan polygram for Maria'To Maria, ten thousand years (of life)!' = 'Long live Maria!'
consists of four parts. Which parts stand for a? If you can answer that question, you can figure out which parts stand for m and ri.
11.11.1.23:59: WATERY HAND, BODILY YAK
Last night I wrote 'Halloween' in Tangut as
I have already analyzed the second graph in the course of my analysis of line 89 of the Golden Guide.
1xa 1lo 1ʔwĩ
Tangut dictionaries defined the first and third graphs as surnames.
1xa looks like 'water' plus 'hand':
+

but was analyzed as
+
left of 2xa 'a surname' (phonetic)
+ left of 2ʔiiʳ 'to spread' (< 'hand' + 'long'; semantic?)
Why write a family name with 'to spread'? Chn 張 is also a family name (Zhang in modern Mandarin). Could the Tangut 1xa family have been related to a Chinese 張 family?
The other xa-surname, 2xa had a tangraph analyzed as
2ziəəʳ 'water'
+ center of 2roʳ 'circle'
Did the 2xa family live by something circular near a river?
The tangraph for the surname 1ʔwĩ was analyzed as
+
left of 1kõ 'body' (< Chn 躬)
+ center and right of 2khɪ 'yak'
The left side of 1ʔwĩ is 'person', a suitable radical for a surname. But is the right side really an abbreviation of 'yak'? Notice that 1ʔwĩ and 'yak' do not actually share the same right-hand components: the vertical line in 1ʔwĩ is shorter than its component in 'yak'.
There are five other tangraphs with the same right side (pix in David Boxenhorn's alphacode) as 1ʔwĩ. Could any of these be a more plausible source for the right-hand component of 1ʔwĩ? Were the 1ʔwĩ a fat family?
| LFW number | Tangraph | Reading | Gloss | Notes |
| 957 |  |
1vʌ | fertile | cognate with 'fat' below |
| 1197 | |
fat, grease | cognate with 'fertile' above 'skin' on left |
|
| 3164 |  |
1zwiə | seed | 'grass' on left |
| 3967 |  |
2lɨẽ | grease | left of 'stomach' |
| 4736 |  |
1na | fat, corpulent | 'horse' on bottom left |
4736 'fat' in fact turns out to be the source of the right side of 'yak' (alphacode: baehem) according to the Precious Rhymes of the Tangraphic Sea.* And 4736 in turn is derived from a graph for a synonym,
1tshwəu 'fat, corpulent'
with baehem on the right. All this indicates that pix and baehem are really equivalent. But why write a character with one instead of the other? And why were both elements only on the right with the sole exception of
2dʒɨiʳ 'butter'
in which there was nothing to the left of pix?
Next: Qua-ndary
Later: What Sundown Evening Knife?
*11.2.1:12: Did the Tangut use yak fat as food and/or fuel? Was the 1ʔwĩ family in charge of yak fat?
11.10.31.23:50: TJK HALLOWEEN
Here are my attempts to write 'Halloween' in the four extinct nonalphabetic scripts that I work on. In all four spellings below, characters or character components correspond to syllables.
Tangut<ha.lo.win>
Jurchen (large) script
<ha.lo.in>
I wish I could also write 'Halloween' in the Jurchen small script, but it's the most mysterious of the 'TJK' scripts and there is no consensus on what it is.
Khitan large script
<xa.lu.in> (<x> is the closest Khitan equivalent of h; it was pronounced like German ch)
I don't know what the Khitan large script characters for <lo> and <win> were, so I've substituted <lu> and <in>.
Khitan small script

<xa.lu.in>
Syllables of a word are written together in a cluster:
To illustrate the difference between the large and small script, I've chosen components for <lu> and <in> even though I know the components for <lo.w.in> in the small script.
No one knows why the Khitan had two different scripts for the same language.
11.10.30.23:36: BORN TO HEAR GOLD
Yesterday was Batton Lash's
<BORN.er DAY> birthday
and I've wondered if the first Khitan small script graph
<BORN>
was derived from Chinese 生 'born' by leaving its top left stroke in place and turning the rest on its side.
It resembles the first half of one spelling of Jurchen
~
alcun <alcu.un> 'gold'
and that shape is even closer to one variant of Jurchen doldi- or dondi- 'to hear'
which Jin Qizong (1984: 217) regarded as cognate to the Khitan large script graphs~
~

without known phonetic and semantic values.
Could 'hear' be from a cursive form of Chn 聞 'to hear'?
the surrounder 丿 + 冂 could be from Chn 门, a reduction of 門, the phonetic of 聞
the bottom center element could be a reduction of 耳 'ear', the semantic element of 聞
'Gold'
the near-lookalike of
'hear',
could be cognate to Chn 金 'gold' which has 33 variants including one with 丿 + 囗 (close to 丿 + 冂).
The other Jurchen graph for 'gold'
could be a slight rearrangement of its strokes minus the right vertical stroke.
Li Qiang (1982: 114) listed the standard character 金 for 'gold' in his Parhae data, but I see nothing like any of the above forms for 'born' or 'hear'.
Next: From Alcun to Aisin?
*The Manchu stem for 'to hear' is donji- which may come from a Jurchen dondi- whose proto-Tunguisic source was *doldi- (Cincius 1975: 1.214). There is no doubt that di shifted to ji in Manchu. The question is whether early Jurchen had already undergone a *-lC- > *-nC- shift.
If the reconstruction alcun (as opposed to later ancun) for 'gold' in Kane (2009: 165) is correct, then it is likely that the word for 'hear' in that dialect was doldi-. Chinese transcriptions with -nC- are ambiguous because there was no way to unambiguously transcribe foreign -lC- in Chinese: the only choices were -lVC- with an extra vowel and -nC- with a different sonorant.