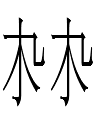
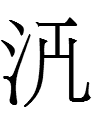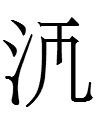<s.l.b> = [(e)s(e)l(e/o)b(o)]?
11.11.19.21:31: HEAVEN AND EARTH WATER NINETEEN
Having just mentioned a word written with nothing but ambiguous Khitan small script characters
<s.l.b> = [(e)s(e)l(e/o)b(o)]?
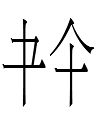
four days ago, I felt like seeing it in context. So I found it in the 興宗皇帝哀冊 memorial for Emperor Xingzong which begins with the reign title known in Chinese as 重熙 Chongxi 'repeated splendor' (in Kane 2009's translation; 1032-1055). One might expect the Khitan version of the reign title to be a translation or a transcription of Liao Chinese 重熙 *chunghi, but of course it was neither. In the large script it is
'heaven' (reading unknown?): cf. Chn 天 'heaven' and 土 'earth'
'ordu-?': cf. Chn 氵 'water', 一 'one', 九 'nine' (not 'nineteen' as in the title, but close)
The first graph must be related to Jurchen
~
abka 'heaven'
and even more strongly resembles
Vietnamese 𡗶 trời ~ giời 'heaven' < Chn 天 'heaven' over 上 'top'
Zhuang 𡗶 gwnz [kɯn] 'top' (identical in shape to the Vietnamese character)
and is a near-lookalike of
Zhuang dienh [tiin] 'imperial palace'* < Chn 夭 'to die young' (! - not 天 'heaven'?) over 土 'earth'
the word [tiin] is probably borrowed from a form like Cantonese 殿 [tiin] 'palace'
I don't think the similarity between the Khitan and Jurchen graphs and the later southern graphs indicates that the latter are derived from the former. Different peoples familiar with the Chinese script could have independently created 天 'heaven'-based graphs for non-Chinese words associated with 'heaven', 'top', etc. What truly indicates a relationship between the Khitan and Jurchen large scripts are similar graphs that have no known Chinese sources: e.g.,
and
Khitan ai 'year' and Jurchen aniya, both 'year'.
If one asked two sinographically literate people to create a new character for 'year' unlike Chinese 年, they would not both come up with more or less the same shape. (The absence of this shape and the presence of 年 in the Parhae script may suggest that the graph is a Khitan innovation rather than a carryover from Parhae.)
The second graph has nothing that suggests 'ordu'. The function of its three elements resembling Chn
氵 'water'
一 'one'
九 'nine'
are unknown. These elements may or may not be sinified replacements for non-Chinese elements found in these variants:
The third variant has a left-hand component of unknown function also in
Could this C-like component have influenced the shape of the Tangut
component  ? See Kychanov's list of "eleven elements that are common
to both Liao [Khitan] and Tangut" scripts reproduced in Grinstead
(1972: 14). (My copy of Kychanov's 1964 article "К изучению структуры
тангутской письменности" in Краткие сообщения Института народов Азии 68
is missing several pages, including p. 135 with the original version of
that list.)
? See Kychanov's list of "eleven elements that are common
to both Liao [Khitan] and Tangut" scripts reproduced in Grinstead
(1972: 14). (My copy of Kychanov's 1964 article "К изучению структуры
тангутской письменности" in Краткие сообщения Института народов Азии 68
is missing several pages, including p. 135 with the original version of
that list.)
Next: Eight Great Rice Hordes
*Zh dienh also has a variant that looks like 户 'door' + 电 'lightning'. Is this a modification of the left side of 殿 'palace' with Cantonese 电 [tiin] as phonetic instead of 共 on the bottom?
11.11.18.3:19: OLD WOMEN ON THE GOLDEN MOUNTAIN
There are three forms for 'gold' in the Khitan small script:
<GOLD> ~ <GOLD♂> ~ <n.i.gu>
~
~

The first two resemble Chinese 山 'mountain' and presumably represent words sharing a root which may or may not be shared with <n.i.gu>. This may be a rare case of a word family with both logogram and polygram spellings. If the three words do not share a root, the first and/or second may be
<g.m> = [gim] 'metal, gold' < Chn 金 *kim
plus native gender suffixes. In any case, <n.i.gu> is not related to Jurchen
~
<alcu.un> 'gold'
from my last post.
Kane (2009: 54) wrote,
Aisin Gioro suggests that the underlying word [of <n.i.gu>] is a form of 女古 *nügu, the Kitan word for 'gold' corresponding to Chinese 金 jin [the modern Mandarin reading] in the Liaoshi [History of the Liao Dynasty] glossary. This would mean <nu.i.gu> for
.
And perhaps <u.i> was [ü]. But is there any other case in
which ![]() was [nu]? My reversible-reading graph hypothesis predicts
that
was [nu]? My reversible-reading graph hypothesis predicts
that ![]() was [en] ~ [n] ~ [ne] but not [nu]. But I could be wrong.
was [en] ~ [n] ~ [ne] but not [nu]. But I could be wrong.
Let's suppose ![]() was <n>. How could
was <n>. How could ![]() <n.i.gu> be reconciled with its Chinese phonetic transcription 女古
*nüku? (女 is 'woman' and 古 'old'. Chinese unaspirated *k
may have sounded like [g] to Khitan ears.) There is no guarantee that
the Chinese transcribed the dialect of Khitan underlying written
Khitan. Perhaps proto-Khitan *nügu became [nigu] in that
dialect but remained [nügu] in the dialect recorded in the History
of the Liao Dynasty.
<n.i.gu> be reconciled with its Chinese phonetic transcription 女古
*nüku? (女 is 'woman' and 古 'old'. Chinese unaspirated *k
may have sounded like [g] to Khitan ears.) There is no guarantee that
the Chinese transcribed the dialect of Khitan underlying written
Khitan. Perhaps proto-Khitan *nügu became [nigu] in that
dialect but remained [nügu] in the dialect recorded in the History
of the Liao Dynasty.
Another possible example of *ü > [i] shift might be
~
<us.g> = [usig]? 'writing': cf. Written Mongolian üsüg 'id.'
Perhaps the later WM form preserves an ü lost in written Khitan. The common ancestor of WK [usig] and WM üsüg might have been *usüg without vowel harmony.
There are several different earlier Chinese names for the 西喇木伦 Xar Moron 'yellow river' whose Khitan name might have contained 'gold' (i.e, 'yellow'):
Pre-Tang names
饒樂 Early Middle Chinese *ɲewlak
弱樂 EMC *ɲɨaklak
如洛瑰 EMC *ɲɨəlakkuy
Kane (2009: 165-166) wrote,Post-Tang names
裊羅個 Liao Chinese *niawloko
女古 LC *nüku
These are different transcriptions of the same name. The first syllable should be something like *nyu. The second syllable should be *lak or *lo, and the third syllable should be something like *gu or *gui. It is difficult to account for the *r/l implied by the earlier transcriptions [and even post-Tang 裊羅個], and for the -r- in forms like Jürčid [Mongolian for 'Jurchen'], unless we presume a form like *nirugu and a reading like *urgu for
I wonder if these transcriptions reflect different Khitan dialects at different periods. The earliest form might have been something like *niulagu-i which then developed into *nyawlag(u), *nölagu-i, *niulgo, *nü(l)gu, and <n.i.gu>. How these forms relate to Jurchen (< Mongolian Jürcen) and related forms is unclear to me.
I know of no other VCCV Khitan small script readings, so I prefer to
interpret ![]() as <gu> instead of <urgu>. I know of no CCV
KSS readings, so I also rule out <rgu>. This graph appears in at
least five other words:
as <gu> instead of <urgu>. I know of no CCV
KSS readings, so I also rule out <rgu>. This graph appears in at
least five other words:
<t.gu> (word introducing a quotation)

<x.?.gu>

<gu.u> (this word seems to rule out <rgu> if Khitan had no initial <r>)
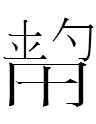
<ɣa.gu.il>
<t.?.gu>
Next: Heaven and Earth Water Nineteen
11.11.16.23:39: FROM ALCUN TO AISIN?
Mentioning the Khitan word
<g.m> = [gim] 'metal, gold' < Chn 金 *kim
last night reminded me of this post which I advertised as "next" on October 30 but didn't get around to writing until now.
According to Kane (2009: 165), the Jurchen word for 'gold' (and for their state) was alcun:
<alcu.un>
But Kane (1989: 350) reconstructed it as ancu (transcribed in Chinese as 安出 *anchu) for the late Jurchen dialect recorded in The Sino-Jurchen Vocabulary of the Bureau of Interpreters. As far as I know, Ligeti (1953) was the first to reconstruct this word with -lc- as alcu. I have not seen that article, so I don't know why Ligeti reconstructed -l- instead of -n-. (Acta Orientalia Academiae Scientiarum Hungaricae is not easy to find around here in Nowhere, NJ.)
The corresponding Manchu word is aisin. At a glance, its segments line up nicely with those of alcun
| Jurchen | a | l | c | u | n |
| Manchu | a | i | s | i | n |
and one would be tempted to propose the following sound changes:
J l > M i
J c > M s
J u > M i
These changes are phonetically plausible in isolation, but do not occur in any other words that I know of.
In Starostin's database, Proto-Tungusic *-lc- corresponds to Manchu -lc-, not -is-.
I don't see anything like *-lc- > M -is- in Vovin's unpublished 1996 table of Tungusic correspondences.In Kane (1989: 115), late Jurchen -lc- ~ -nc- (transcribed in Chinese as *-nch-) corresponds to M -lc-, not -is-.
Kane (1989: 118) lists 10 cases in which late J u did not correspond to M u. But none involve the correspondence J u : M i:u : a (4 cases)
u : e (2 cases)
u : o (4 cases)
I conclude that J alcun and M aisin are not cognate, though it is possible that aisin is a loan from some aberrant Jurchen dialect which had undergone the sound changes that I proposed above.
Next Time for Sure: Old Women on the Golden Mountain
11.11.15.21:21: DID KHITAN HAVE INITIAL R-?
Khitan is typologically an 'Altaic' language with subject-object-verb, modifier-modified word order, suffix-based morphology, and vowel harmony. Altaic languages lack r- except in loanwords. I would have predicted that Khitan would have no r-words at all since its chief source of loanwords was northeastern Chinese which did not have an initial *r- during the Liao Dynasty. However, in the Khitan small script texts that I have on hand, two of the three known <r>-initial characters appear in initial position:
| Khitan small script character | Transcriptions of words containing this character in first position |
|
|
<ra> x 2 = [ar]? <ra.b> = [arob]? <ra.b.úŋ> = [arobúŋ]? <ra.?.ɣa.a.ar> = [ar?ɣaar]? <ra.er> = [arer]? <ra.én> = [arén]? <ra.ul> = [arul]? <ra.ul.ge.mó> = [arulgemó]? |
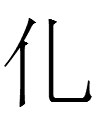 <ri> <ri> |
<ri> = [ir]? <ri.úr> = [irúr]? <ri.l.úr.ún> = [irelúrún]? <ri.g.d> x 2 = [irigid]?; pl. of <ri.g.en> = [irigen]? 'tribal chief' <ri.e> = [ire]? <ri.én> = [iren]? |
 <rí> <rí> |
None? |
As the above table implies, I suspect that <rV>-graphs could also double as <Vr>-graphs in initial position. Unfortunately, I know of only one Chinese transcription that confirms this:
夷離堇 *ilikin for<ri.g.en> 'tribal chief'
These <rV>/<Vr>-graphs in turn belong to an even larger set of graphs with 'reversible' readings: e.g.,
I predict that reversible-reading graphs
<s(e)> in
<s.en> = [esen]? 'long life', transcribed in Chinese as 義信 *isin
1. have inherent vowels (Kane 2009: 30, 32):
a. [o] with labial consonants
b. [e] with dental/alveolar consonants (exception: <ri>)
c. [i] with palatal consonants
d. [e] or [i] with velar consonants
This predicts reading pairs like
[ob] ~ [bo]
[ed] ~ [de]
[ij] ~ [ji]
[ek] ~ [ke]
[ig] ~ [gi]
but not, say,
[eb] ~ [be]
[od] ~ [do]
[aj] ~ [ja]
[ug] ~ [gu]
I wonder if
is really [er] ~ [re]. If so, then <ne.ra> 'tomb' should be reinterpreted as [nere], and the anomalous stem-locative ending sequence [nera-de] becomes harmonious [nere-de].
2. are read as [(V)C]
a. before <V>:
<s.en> = [esen]? 'long life'
<r>-graphs in initial position must be read as [Vr] to avoid initial [r]:
<ri.g.en> = [irigen]? 'tribal chief'
b. after <C> (to avoid a consonant cluster [CC]):
<us.g> = [usig]? 'writing': cf. Written Mongolian üsüg 'id.'
Kane 2009: 127 interpreted this as [usgi] with a final vowel
3. are read as <CV> before <C> (to avoid a consonant cluster [CC])::
<g.m> = [gim] 'metal, gold' < Chn 金 *kim (unaspirated Chn *k was borrowed as voiced [g])
<m.ri> = [mori] 'horse': cf. Written Mongolian mori(n) 'id.'
The readings of 'metal' and 'horse' lack question marks because they are more certain than those of the other words above.
The readings of words like
<c.c> and <s.l.b> = [(i)c(i)c(i)]? and [(e)s(e)l(e/o)b(o)]?
which are written entirely using reversible-reading graphs are especially uncertain without external evidence: e.g., possible Mongolian cognates, Chinese transcriptions, and/or borrowings into Jurchen.
If I am correct and
was [ra] ~ [ar] or [re] ~ [er], then when was it preferable to
<ar> and <er>
for writing [ar] and [er]? Both <ar> and <er> can appear in word-initial position or even together in

<er.ar.en>
from the 興宗皇帝哀冊 memorial for Emperor Xingzong. Could that word also
have
been written with ![]() ?
?
11.11.14.00:59: (O)ROGAN-DE ESEN-ER!
Today is Rogan Hazard's birthday. I wish
<or.o.g.án-de> = Orogán-de 'to Rogan'; <-de> = indirect object suffix like Jpn に (not で!)
<s.en.er>: <s.en> = esen 'long life'; <-er> = direct object suffix like Jpn を
in the extinct Khitan language.
The Khitan small script consists of phonetic characters grouped into stacks representing words. If Japanese were written similarly, Rogan would be written in a single block asロー <ro.o (ー represents a lengthening of the preceding vowel)
ガン ga.n>
It's unlikely that any words could begin with r- in Khitan, so Rogan was written as <or.o.g.an> with an extra <o>:
 |
||
Mongolian, a distant living relative of Khitan, also didn't allow initial r-, so 'Russia' was borrowed as Oros with an extra o. (This Oros was then borrowed into earlier Mandarin as 俄羅斯 Olosï, whose first syllable became modern standard Mandarin 俄 E 'Russia'.)
The first character 소 looks like Korean 소 so, but the resemblance is wholly coincidental. King Sejong invented the Korean hangul alphabet five centuries after Yelü Diela invented the Khitan small script in 925. The stacking principle of hangul - e.g, 소 <so> consists of ㅅ <s> atop ㅗ <o> - might have been influenced by the Khitan small script.
The characters, 及 <o> and 出 <án> look exactly like Chinese characters but have readings unique to Khitan. Perhaps the Khitan translation for 及 'to reach' (or some other Chinese word written with 及) was o. Similarly, the Khitan translation of 出 'to go out' (or some other Chinese word written with 出) might have been án.
The third character <g> (also <gi> in other contexts) might be derived from Chinese 几 whose 10th century reading sounded like gi to Khitan ears.
12.16.22:11: I confused
<án> and <an>
and should have written Rogan's name with the more basic <an> instead of <án>:
<or.o.g.an>
The phonetic difference between <an> and <án>, if any, is unknown.
11.11.13.23:45: PATERNAL AID, ANNUAL ICE, AND A HUNDRED MOTHERS
In "Sometimes Sensitive", I mentioned Khitan <ai> 'father, male'. <ai> can also mean 'year'. The two <ai> are identical in the singular but have different plurals:
<ai.d> 'fathers' vs. <ai.s> 'years'
<-d>-plurals
<-d> is often after biologically masculine nouns, but there are exceptions (Kane 2009: 139):I assume <-d> was [ed] after a consonant. It couldn't have been [de] because <de> has its own small script character:<aú.ui.d> 'royal ladies' (cf. the Sanskrit masculine plural noun daaraas 'wife [sg.!], wives')
<x.iŋ.d> 'capitals' - [xiŋed]?
presumably from Chn 京 *kiŋ 'capital', though the initial is unexpected
Two other <-d>-plural suffixes follow biologically masculine nouns or nouns that might be grammatically masculine: e.g. (Kane 2009: 140-141),
<REGION.a.ad> 'regions'
<po.od> 'hours'
<-ud> in <ei.ra.u.ud> 'Yelü' may be a masculine plural ending.
<-s>-plurals
There is no distinction in the small script between <s> and <se> and no known character for <es>, so <ai.s> might have been [ajse] or even [ajes].
Kane (2009: 141-142) lists other examples of <-s> plurals:
Although I thought <-s> might be a feminine plural ending because of the phrase<ui.s> 'matters'
<qid.s> 'Khitans'
<g.úr.s> 'countries' (< Old Chinese 郡 *gurs 'district'?)
<MONTH.s> 'months'
<n.on.s> 'generations'
<qi.t ai.s.er> 'those years' (<-er> is an accusative ending)
with <qi> 'that' plus the feminine plural ending <t>, >qid.s> 'Khitans' is likely to be masculine. But 'year' may be feminine and 'matter', 'country', 'month', and/or 'generation' could also be feminine. Perhaps <-s> is both a masculine and feminine plural ending.
A tentative scheme of Khitan plural suffixes
| Masculine (generally) | Masculine or feminine | Feminine only |
| <-d> [-d] ~ [-ed]? | <-s> [-s] ~ [-es] ~ [-se]? | <-t> [-t] ~ [-et] ~ [-te]? |
| <-ad> | ||
| <-od> | ||
| <-ud> |
The irregular plurals (Kane 2009: 142)
<bo.ɣu.an> 'children' < <bo.qo> 'child'
<ń.iau.ń.er> 'siblings' < <ń.iau> 'sibling'
do not fit into this scheme. Are they ever preceded by <qi.t> 'those' (f.)?
mo-ther?The small script graph
<mó> 'mother, female'
reminds me of 百 'hundred', the right side of 陌洦蛨袹貊銆, all read mo in modern Mandarin. Could <mó> be from 百? The trouble is that the expected Sino-Khitan reading of such sinographs would be maɣ, not mo. What if the small script graph were originally read maɣ which became maw and then mo, transcribed in the History of the Liao Dynasty (1343) as 麼 *mo? In any case, the transcriptions in the 14th century History probably do not all represent Khitan as it was spoken in the early 10th century when the small script was devised. My guess is that the transcriptions were copied from texts from different eras such as the lost Liao Dynasty Veritable Records and the Jin Dynasty History of the Liao Dynasty.
<mó> resembles three other small script graphs:
The first is <ei>, perhaps pronounced [j(e)] initially and [ej] finally.
The phonetic value of the second is unknown.
Kane (2009: 40) transcribed the third as <ɣor>. I am not sure about the consonants. Its Chinese transcriptions are 曷魯 ~ 何魯 *xolu, which could also have represented a Khitan *ɣol, *xol, or *xor.
There are no other <Cor> or <Col> graphs. Such syllables would have been written with graph sequences like <C.or> or <Co.l>. (There is no known graph <ol>.) Why did *GoR have its own special graph?