

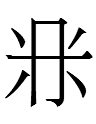


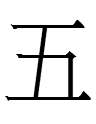
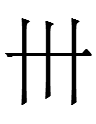
? qulugh ai nai sair par tau nyair
'white rat year, head month, ten five day'
20.2.8.23:59: WHITE RAT 1.15
? qulugh ai nai sair par tau nyair
'white rat year, head month, ten five day'
Finally a Khitan numeral that everyone is certain about: tau
'five'. Scholars have guessed the Khitan numerals for 'one' through
'four' and 'seven' on the basis of ordinals and Mongolian, but ordinals
are not
necessarily like cardinals: e.g., English second is not cognate
to two.
| Khitan |
ordinal |
ordinal suffix type |
cardinal |
Written Mongolian |
| one |
mo ~ masqu |
A |
mas? |
nigen (not cognate) |
| two |
curer ~ jurer¹ |
B |
cur? ~ jur? |
qoyar (not cognate); cf. Janhunen's
Proto-Mongolic *jiri/n |
| three |
ghurer |
B |
ghur? |
ghurban |
| four |
turer ~ durer¹ |
B |
tur? ~ dur? |
dörben |
| five |
tadogh ~ todogh² | C |
tau |
tabun |
| six |
X-er |
B |
X (= nil?) |
jirghughan (not cognate) |
| seven |
daloer |
B |
dalo? |
dologhan |
| eight |
nyêmder ~ nyêmirer |
D, E |
nyêm |
naiman |
| nine |
ishider ~ ishidegh |
F, G |
ish |
yesün (may not be cognate) |
| ten |
parder |
D |
par |
arban |
(I have only listed masculine numerals.)
And even when the two are cognate, one cannot always subtract an
ordinal suffix to generate a cardinal: e.g., third³ minus -d is not three,
and Khitan tadogh ~ todogh 'fifth' minus -dogh
is not tau 'five'.
There is no single strategy for forming masculine ordinals in Khitan:
A. -qu may be an adjectival suffix also in liauqu 'red' and siauqu 'blue/green'.
B. -er is a masculine suffix also found in verbs.
C. -dogh may be unique to 'fifth', though it has a variant in 'ninth' (see G below).
D. -der looks like -d (like the noun plural suffix?) plus -er (see B above).
E. -irer may be from -ider (see F below) with -d-lenition.
F. -ider looks like -id-, an allomorph of -d- from -der (see D above) plus -er.
The noun plural suffix has no allomorph -id, so maybe -id- is not related.
G. -idegh combines -id- with a variant of -dogh
(see C above).
2.9.23:51: Shimunek (2017: 230) analyzes 'ninth' as ishi-degh.
¹2.9.23:49: This numeral is an 'alternator' spelled with two different consonant letters. See eight approaches to alternation in these posts:
²Is todogh is from tadogho with a assimilating to the following labial vowels?
³It seems þridda underwent metathesis in Old English. Dutch derde 'third' apparently also independently underwent metathesis back on the continent, as Middle Dutch has dridde preserving the Tr-cluster still in German dritte 'third'.
20.2.7.23:59: WHITE RAT 1.14
? qulugh ai nai sair par ? nyair
'white rat year, head month, ten four day'
1. Big news, small script (from Andrew West):
This is a test page for a prototype font for the Khitan Small Script, with glyphs derived from a font designed by Jing Yongshi. The Khitan Small Script will be included in Unicode 13.0 (code charts) to be released in March 2020. The font uses OpenType features for automatic cluster formation.
I downloaded the font. It works!
2. This Khitan small script pendant looks fake to me because of the errors in it:
2.1. The
<ng>
in regular script block 2 has a strangely written bottom half.
2.2. The
<sh>
in regular script block 4 looks like Japanese モ and the Khitan small script character <ONE>.
2.3. The
<s>
in regular script block 5 resembles Japanese タ.
I am not an expert on Khitan small script calligraphic variation,
but I have been unable to find the above characters in Starikov's
(1982) catalog of variants which is not comprehensive.
2.4. The seal script text is a grammatical mess:
<au.ui.er di.en hong d.em.l.ge.ei>
'lady-INS ror-GEN empe grant.PASS.CVB'
'having been granted by lady ror's empe'
2.4.1. The Khitan passive constructions I have seen have the structure
(X) Y V-PASS
'(X) was V-ed Y'
without accusative -er.
In this case, <d.em> 'grant' is the verb. Perhaps
<au.ui> 'lady' is the one doing the granting. If so, <er>
is instrumental rather than accusative. But I don't know if 'by Z' is Z-er
in Khitan passive constructions. Even if it is, other problems remain.
2.4.2. Presumably <hong di.en au.ui> 'emperor's lady' was intended, but the order of elements is wrong: the halves of <hong di.en> are inverted, and both halves follow rather than precede the possessed: <au.ui> 'lady'.
2.4.3. The inscription ends in a converb <ei> rather than a finite verb suffix. I would expect another clause after a converb: 'Having been granted by the emperor's lady, ...'
Whoever made this looked up words and did place the verb in the
correct (final) position but doesn't fully understand Khitan grammar
and is not familiar with the Khitan small script.
2.4.4. I don't understand Khitan society well enough to know whether
an emperor's lady would be granting ranks (in this case, gim ngu ui
shang sang gün 'imperial insignia guard superior general' in the
regular script on the other side) or pendants. Or if that rank had a
pendant.
3. One scenario for the spread of Semitic. I have no idea if it or any of these alternatives are correct:
There is no consensus regarding the location of the Proto-Semitic urheimat; scholars hypothesize that it may have originated in the Arabian Peninsula, the Levant, the Sahara, or the Horn of Africa.
I just like seeing scenarios expressed in map form. I wish I had seen the historical maps on Wikipedia when I was in school.
4. Today I found Richard Sproat's site. I know of Sproat as one of the trio famous for their opposition to regarding the Indus script as a script in a landmark 2004 article ("Hundreds of thousands of downloads since its publication"). I don't know why it took me so long to find his site. I've visited Steve Farmer's site from time to time and I think I've visited Michael Witzel's site at least once before. I just learned Witzel had studied Japanology at university!
5. This paper by my former student Mark Post and this presentation by Roger Blench make me think Pyu might not belong to Sino-Tibetan - a possibility that's been in the back of my head since I started working on Pyu five years ago.
Blench is blunt and right - this applies to Pyu too:
The classificatory tradition of Tibeto-Burman [i.e., Sino-Tibetan minus Chinese] studies, which can be traced back at least to Konow, is to assume affiliation based on geography and a few lexical similarities. In some cases, the argument is no more than 'my friend said so' or 'I had a brilliant student who'
Pyu was spoken in an area where Sino-Tibetan languages are now spoken, and it certainly has Sino-Tibetan vocabulary. But is that enough to make it a Sino-Tibetan language?
6. Today I finally got around to looking into the Wuhan dialect after constantly seeing the name in the news. I could go on and on about it, but for now I'll just saw that it is a variety of Mandarin with a pre-Mandarin substratum lacking palatalization: e.g.,
家 'house, family':
superstratum [tɕia˥] (roughly identical to standard Mandarin)
substratum [ka˥] (cf. Sino-Korean ka borrowed from northern Chinese c. 1300 years ago; no trace of the *-j- that was already in Liao Chinese *kja from c. 1100 years ago)
7. Today I learned of this Chinese language vocabulary database with a radical index unlike any I've seen before (click on the 部首検索 tab, pick a radical, and then click the blue box with 部首検索 for search results).
2.8.23:48: The index contains many nontraditional radicals: e.g., the phonetic 冈 gāng which is not a radical in any list I've ever seen. The results for 冈 even include characters with similarly shaped components:
| sinograph |
reading(s) |
traditional radical |
phonetic |
| 岗 | gāng, gǎng, gàng |
山 |
冈 |
| 钢 | gāng, gàng | 钅 |
冈 |
| 纲 | gāng |
纟 |
冈 |
| 躐 | liè | 足 |
巤 |
| 嫓 | pì | 女 |
𭯍 (written slightly differently) |
Oddly 冈 gāng itself has no entry.
20.2.6.23:55: WHITE RAT 1.13
? qulugh ai nai sair par ? nyair
'white rat year, head month, ten three day'
1. I uploaded all the entries from White Rat 1.2 to this one using WinSCP thanks to David Boxenhorn:
I've been reluctant to upload partly because FileZilla has lately
begun to crash almost every time I load multiple images. But I just
uploaded 36 images without any issues in WinSCP. Looks like I'm going
to switch.
2. David Boxenhorn also drew my attention to this tweet by Benjamin Suchard:
Proto-Semitic *ṣ́ (> Arabic ض) had some funky Old Aramaic reflex that was spelled with <q> but was distinct from /q/ < PS [Proto-Semitic] *q. Later, this sound merges with ʕ; the spelling lags behind but eventually gets updated to reflect this merger.
When I first learned years ago (from David, I think) that Aramaic ʕ was from PS *ṣ́ as well as PS *ʕ. I was baffled. But not knowing much about Semitic, I put the mystery aside. Now things are clearer. I see parallels with Chinese that I should have seen back then.
Baxter and Sagart (2014) reconstruct an Old Chinese voiceless pharygealized lateral approximant *l̥ˁ which is similar to the PS emphatic lateral fricative *ṣ́. Who knows, maybe the Old Chinese consonant was a fricative like PS *ṣ́ in some environments and/or dialects. It is impossible to be certain about phonetic details of long-gone language stages.
Compare the development of *l̥ˁ in two types of Old Chinese dialects with the development of *ṣ́ in Semitic:
Eastern (i.e., coastal) Old Chinese: *l̥ˁ > *tʰ
Western (i.e., interior) Old Chinese: *l̥ˁ > *x ([χ]?)cf. PS *ṣ́ > Arabic ḍ [dˤ] ~ [d̪ˤ] ~ [d̪ˠ] (modern pronunciations from Wikipedia)
cf. PS *ṣ́ > Old Aramaic [χ]? (spelled <q>) > later Aramaic [ʕ]
Eastern Old Chinese and Arabic hardened their unusual *laterals (*l̥ˁ and *ṣ) into stops, whereas Western Old Chinese B and Aramaic backed them.
Western Old Chinese has no living descendants, though an important word from it marginally survives as a loanword in the east:
祆 'Ahura Mazda': Mandarin xiān [ɕjɛn˥] < Western Old Chinese *xen ([χen]?; cognate to Eastern Old Chinese 天 *tʰen 'sky'; both are from *l̥ˁin 'sky', and 祆 is written as 天 plus the religious radical 示).
What I still don't understand is how [χ] became [ʕ] in Aramaic.
Maybe *ṣ́ voiced to [ɮˁ] (possibly also
the pronunciaiton of <ḍ> in earlier Arabic) and backed to [ʁ]
on the way to [ʕ]. [ʁ] was written as <q> since there was no
letter for a voiced uvular <ɢ> or <ʁ>.
3. What is the origin of "the beatings will continue until morale improves"? The sentiment is old - pour encourager les autres is from Voltaire's Candide - but the exact wording seems to be recent. Google Books Ngram Viewer has no results for "beatings will continue until morale" until 1990.
4. Somehow I had gotten the mistaken idea that KOTONOHA, the
journal of the 古代文字資料館 Ancient
Writing Library, hadn't had an issue in a year or so. But now I
see that there were twelve issues in 2019.
The second article in the final issue of 2019 (#205) is 吉池孝一 Yoshiike Kōichi's 『東アジアの諸文字と契丹文字』 (The Scripts of East Asia and the Khitan Scripts) which places the Khitan scripts in areal perspective. Yoshiike regards the Khitan scripts, the Jurchen (large) script, and the Tangut script as 擬似漢字系文字 giji kanjikei moji 'pseudosinographic scripts' as opposed to sinographic scripts directly derived from Chinese or nonsinographic scripts that are wholly unrelated (e.g., Sogdian, Phags-pa, and hangul). That might give the impression that Yoshiike agrees with Janhunen that the Khitan large script is a sister to the Chinese script, but Yoshiike agrees with the mainstream view that the Khitan large script was created in 920. Janhunen and I, on the other hand, think that the Khitan large script grew out of an earlier script.
Oddly Yoshiike views the Khitan language as a 方言 hōgen
'dialect' of Mongolian, though as he certainly must know, it is not
mutually intelligible with Mongolian. (If it were, deciphering it would
be much easier.)
5. A user-added word in Naver's dictionary: 핥 <h.a.l.th>
'a shortened word of heart', added in 2014 - is that word really in use?
20.2.5.19:18: WHITE RAT 1.12
? qulugh ai nai sair par ? nyair
'white rat year, head month, ten two day'
1. This morning I finally learned the Arabic spelling of Hoda Kotb: هدى قطب
<hdá qṭb>. I was surprised by the <q>, as <q> is [ʔ]
in Egyptain Arabic. Is the name from this noun?
(Yes, according to articlebio.com:
"Her name Hoda means 'guidance' in Arabic and last name 'Kotb' means
pole.")
Many years earlier I was surprised by Kotb, as I had first
encountered her name in speech as [ˈkɒtbiː] and had assumed it was
written with a final vowel. Or had I first encountered her name when
she briefly spelled it Kotbe with an e?
She even changed her professional name at one point to "Kotbe" to help people understand its correct pronunciation: "COT-BEE."
"People kept saying 'buy a vowel,' so I stuck another one on," Hoda said. It didn't help, so she decided to just let her freak name flag fly.
2. The alif maqṣūrah (ى <á>) at the end of Hoda looks like the
dotless final <y> of Egyptian Arabic. How did Egypt (and
neighboring areas) come to have a dotless form?
3. And while I'm at it, why does Persian <y> have no dots in both isolated and final forms?
My guess is that Egypt and Persia retained the older dotless
<y> even after the dots became obligatory elsewhere. But this
makes it sound as if Egyptian dotless <y> might be an innovation:
The Arabic grammarians of North Africa changed the new letters, which explains the differences between the alphabets of the East and the Maghreb.
Is that passage referring to letters like Maghrebi ڢ <f> and ڧ
<q>?
4. Why does Kashmiri have a ringed version of <y>: ؠ?
5. I just learned that Arabic vowel marks
were introduced, beginning some time in the latter half of the 7th century, preceding the first invention of Syriac and Hebrew vocalization.
I had assumed Hebrew vocalization had come first. Oops.
Initially, this was done by a system of red dots, said to have been commissioned in the Umayyad era by Abu al-Aswad al-Du'ali a dot above = a, a dot below = i, a dot on the line = u, and doubled dots indicated nunation. However, this was cumbersome and easily confusable with the letter-distinguishing dots, so about 100 years later, the modern system was adopted.
I don't know of any script in general use which uses color.
6. Is there a Mongolian term equivalent to rasm for dotless Mongolian script like
ᠤᠬᠠᠬᠠᠨ
uqaghan <'UQAQAn> 'sense, meaning, knowledge'
from yesterday? I would write that with dots as
ᠤᠬᠠᠭᠠᠨ
<'UqAghAn>.
The presence of dots distinguishes <gh> from <q>.
<A> is not as ambiguous as one might think since vowel harmony
requires it to represent a in a word with q and/or gh.
7. Not rasm: a
Qur'an manuscript from the 1st century AH with dots.
8. An obituary in today's Honolulu Star-Advertiser says "No koden".
It would be hard to guess the meaning of Japanese 香典 kōden
'condolence money for a funeral' on the basis of its parts: 香 kō
'incense' and 典 ten
(not den by itself!) with various
meanings (and none are money-related).
典 ten is a postwar respelling of the uncommon kanji 奠 ten
(also den by itself!), once again
without any money-related meanings.
The -d- of -den reflects a nasalized vowel in *kaũ, the old reading of kō:
kaũten > kaũnden > kauden > kɔ̄den > kōden
9. I've struggled with the translation of Japanese 妖怪 yōkai. 'Supernatural creature' is too long. I guess I won't bother anymore given that the word seems to be slowly entering the English mainstream. BYU has a site devoted to 化物之繪 Bakemono no e (Illustrations of Supernatural Creatures, c. 1660). Bakemono hasn't penetrated English as much as yōkai has, but who can predict the future? I wouldn't have predicted in the 80s that I would see yōkai in English.
One recently appeared on American TV (link added):
After its appearance in an Asahi newspaper article, a photograph of BYU’s nurikabe made its way across the world wide web, inspiring new interpretations of nurikabe in art, comic books, animation, and a variety of other formats, including an appearance as an enemy combatant in the long-running Power Rangers television series.
10. What is
the pen in penultimate (which I just heard on Gilmore
Girls)? (It's cognate to patient, passive, and ... field!)
Wiktionary says,
the traditional English expressions for this idea were last but one and (less often) second last.
I've never heard of either.
I'm surprised there's no note about the common and erroneous use of penultimate
as ultimate (which came up in the Gilmore Girls
episode).
11. What is the arap in Daniel arap Moi? (I just read his obituary.) 'Son of' (presumably in Tugen), judging from this.
12. I use N3696 as a phonetic index for Jin's (1984) Jurchen
character dictionary. I was having trouble finding the phonogram
for the transcription of Chinese 君 and 軍 until I went to ccamc.org
and found that Jin's reading was [dʑyn] which is anachronistic and
based on modern Mandarin jūn [tɕyn] rather than Ming Mandarin
[kyn] without palatalization. I read it as gün [kyn].
The Khitan large script cognate of that character is
<gün>.
13. Today I realized that the versatile Jurchen phonogram
<her> ~ <u> ~ <hu> ~ <e> ~ <we> ~ <du> (Kiyose [1977: 65, 127])
might be from Chinese 右 <RIGHT>. The reading we [wə] resembles Late Old Chinese 右 *wɨəʔ. Perhaps Jurchen borrowed a version of 右 used by some other people centuries earlier to transcribe [wə] in another language.
Later, 右 was pronounced *wṵ in Early Middle Chinese and *wú in Late Middle Chinese. So in Parhae 右 could have been a phonogram for [u] (cf. the Sino-Korean reading 우 u south of Parhae).
Kiyose's <du> should be <u> if
hadu 'clothing'
is <CLOTHING u> (i.e., <hadu u>) rather than <ha
du>. (The h- is unexpected, as it corresponds to zero in
Manchu adu 'clothing'.)
I think Kiyose's <e> in
<RETAINER.we> buwe 'retainer'
is really <we>. <RETAINER> was originally read buwe by itself and then got a redundant <we> to indicate the last syllable.
<hu> might reflect a Late Middle Chinese reading of 右 as
something like *xú: cf. Sino-Vietnamese hữu
from a southern Late Middle Chinese dialect. The trouble is that I
don't know of any northern dialect with a fricative in that word.
The one reading I can't explain is <her> (or <hel> or <here> or <hele>? - the Chinese transcription 黑勒 *hele is ambiguous). The Ming dynasty Bureau of Translators vocabulary has the entry

<? ?> 黑勒厄 *helee 'market' (36)
which is hard to interpret because there is no (obvious?) Manchu
cognate except perhaps for heren 'corral, stable'.
20.2.4.23:32: WHITE RAT 1.11
? qulugh ai nai sair par ? nyair
'white rat year, head month, ten one day'
1. The Khitan words for teens are all straightforward combinations
of 'ten'
+ numeral unlike the para-Mongolic source of the '-teen' loanwords in
Jurchen. The jury is still out on whether that source was a dialect of
Khitan (i.e., mutually intelligible with written Khitan) or a sister of
Khitan (i.e., another Serbi language). Different numerals alone are not
enough to claim that source wasn't Khitan. Varieties of French with septante
instead of soixante-dix
for 'seventy' are still considered French.
2. The Honolulu Star-Advertiser reprinted a New York Times story mentioning a "Harmo Tang". I DuckDuckGoed (DuckDuckWent?) and found that spelling in the original, so it's not a secondary typo. "Harmo" is an unusual Mandarin name since the only permissible Xr syllable in names is er. (A famous example is 吾爾開希 Wú'érkāixī which is actually a Mandarinization of an Uyghur name ئۆركەش Örkesh, not a Mandarin name.) There are r-final words like 哪兒 nǎr 'where' and 那兒 nàr 'there', but they wouldn't be used as names or parts of names.
Could "Harmo" be a primary typo for "Hanmo" in the
source article? But r and n are not close on keyboards.
Is "Harmo" an idiosyncratic spelling of standard Hamo? (Cf.
the use of r in English Myanmar
to indicate a final [aː]; there is no final [r] in the Burmese original
[or Burmese at all].) But there is no common Mandarin name component ha.
Is "Harmo" a combination of a Mandarin surname and a non-Chinese
name Mandarinized as Ha'ermo?
3. How was I unaware of Kryptos until two days ago? I never
saw the
text or creator
Jim Sanborn's official site until today. The
Puzzling site lists each of the four passages of ciphertext and
the plaintext and decryption methodology for three of them. The fourth
remains unsolved. Sanborn
charges a $50 fee for responses to emails regarding the fourth passage.
What amazes me is how people were able to identify the borders
between the passages. There are none in the ciphertext, though
fortunately the first passage ends on line 2 and the second on line 12.
The third ends with a question mark toward the end of the fourth line
from the end.
While looking into Kryptos I learned how a
Vigenère cipher works.
4. I've never seen the Russian name Илья Il'ya ('Elijah') spelled Illlya with three L's before.
Uppercase I and lowercase L look identical in a sans
serif font. The difficulty of distinguishing them reminds me of the
difficulty of distinguishing letters made up of sidün 'teeth'
in the Mongolian and Manchu scripts.
An example I happened to encounter just now is
ᠣᠳᠬᠠᠨ
odqan <'UTQan> 'youngest'
in which <U> is a loop or belly (gedesün) like the
first half of <T> and the second half of <T> is a 'tooth'
like <A>.
Kara (2005: 93) gives the example
ᠤᠬᠠᠬᠠᠨ
uqaghan <'UQAQAn> 'sense, meaning, knowledge'
with four letters made up of teeth: <Q> (two teeth; twice) and <A> (one tooth; twice). Final <A> and <n> can also look alike, but the readings <-AA> and <-nn> are impossible.
5. Kara (2005: 94) notes that in preclassical Mongolian orthography,
<Uy> (normally for ü/ö) may represent u: e.g., ghurban
'three' was spelled as <QUyrbAn> (if I understand Kara
correctly). That reminds me of how the same two letters <Uy> came
to
represent Manchu ū [ʊ] (not [uː]!).
There are also cases of the reverse: i.e., Mongolian ü spelled as <U> in <mUnKKA> rather than <mUynKKA> for möngke 'eternal'.
6. While copying the Sino-Jurchen
vocabulary of the Ming dynasty bureau of translators, it occurred to me
that the Jurchen phonogram
<ni>
one of the first Jurchen characters I ever encountered, might be from a Parhae graphic cognate of Chinese 新 <NEW> used to write a para-Japonic cognate of Old Japanese nipi (later nii) 'new'.
But the trouble is that the Proto-Japonic word might have had *m-,
judging from Okinawan mii- 'new'. *mi > ni
is more likely than the reverse. Could *mi > ni have
occurred twice, once in Japanese and again back on the peninsula in
para-Japonic? Pushing believability even further, could *mipi
have become *nii in para-Japonic centuries before Old Japanese nipi
became nii?
7. Can
cats recognize their own names?
20.2.3.22:59: WHITE RAT 1.10
? qulugh ai nai sair par nyair
'white rat year, head month, ten day'
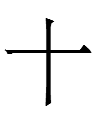
1. The Khitan large script graph 十 <TEN> looks exactly like
Chinese 十 <TEN> but represents a native word par unlike
Liao Chinese *shï.
I used to think the -hon/-hun of the Jurchen '-teen' words was from a Khitan or Khitan-like cognate of Proto-Mongolic *xarban with *-arba- becoming *-o- via *-aβa-, but that just won't work: Khitan preserved Proto-Serbi-Mongolic *p- instead of weakening it to *x-, and *-arba- : *-o- has no parallels in other Mongolic-Khitan comparisons.
Janhunen (2003: 399) reconstructed para-Mongolic *-kUn '-teen'. Manchu ᠵᠣᡵᡤᠣᠨ jorgon 'twelfth (month)' preserves the *stop that became a fricative in Jurchen
jirhon 'twelve' < *jir 'two' + *kon '-teen'.
(Earlier i assimilated to o in jorgon. The voicing of *-k- is irregular.)
2. Norman (2013: 216) says Manchu ᠵᠣᡵᡤᠣᠨ ᡳᠨᡝᠩᡤᡳ jorgon inenggi,
literally 'twelve day', is 'the eighth day of the twelfth month'. I
suppose the phrase is a contraction of *jorgon biya jakūn inenggi
'twelve month eight day'. There is no confusion with 'the 12th' which
is ᠵᡠᠸᠠᠨ ᠵᡠᠸᡝ ᡳᠨᡝᠩᡤᡳ juwan juwe inenggi 'ten two day' (with the
native words for 'ten' and 'two').
3. Today I learned of Assamese মান দেশ Mān
desh 'Burma'. I assume Mān is from the first syllable
of whatever pronunciation of မြန်မာ <mran mā> 'Burma' was current.
4. What is the etymology of the second half of Chinese 緬甸 'Burma' (read as Miǎndiàn in standard Mandarin)? I assume the first half is from <mran>. 甸normally represents a word for 'suburb', but I think it is a transcription of a foreign syllable like *den which is not in Burmese <mran mā>.
I don't know of any etymology for the word <mran mā> itself. Burmese roots are typically monosyllabic, but disyllabic <mran mā> is monomorphemic.
5. How did I not see the Plain of Jars until tonight? I never even heard of it until the end of last year.
Its Lao name is ທົ່ງໄຫຫິນ [tʰoŋ˧ haj˨˦ hin˨˦], lit. 'plain jar
stone' = 'plain [of] stone jars'.
6. I wouldn't have imagined that Google Play has a page for 闘士ゴーディアン Gordian the Fighter (1979-81) in Amharic. Here's the English version.
7. I had heard of malacology but
didn't know what it meant until tonight. I wondered if malaco-
and mollusc
were cognates. Wiktionary derives both from Indo-European *mel-
'soft'.
20.2.2.21:24: WHITE RAT 1.9
? qulugh ai nai sair ish nyair
'white rat year, head month, nine day'
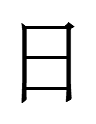
1. The Khitan large script graph
<NINE>
is more complex than Chinese 九 <NINE> and has no obvious Chinese graphic cognate. Could the Khitan graph have originated as a logograph for a non-Khitan word *ish in an earlier (Parhae?) script that was recycled for a (nearly) homophonous, unrelated Khitan word for 'nine'?
There is disagreement on what the Khitan word for 'nine' was and whether it is related to the Mongolic word:
Kane (2009): is (which he favors over ish, though he mentions the latter as a possibility)
Shimunek (2017): ishi
For about a decade I've thought the word was is, but today I
finally realized that Chinese transcriptions of words written with the
character for 'nine' in the small script all contain *sh, not *s.
So I now think the word was ish.
Kane and Shimunek regard the word as cognate to Written Mongol yesün,
but Janhunen (2003: 399, 400) regards the reconstruction of Khitan is
for 'nine' as "anachronistic". He reconstructs Proto-Mongolic
*yer.sü/n 'nine'¹ with an *r in the root absent from
Khitan. (But perhaps a Proto-Serbi-Mongolic *rs fused into sh
in Khitan. However, I know of no other examples of Mongolic ye
corresponding to Khitan i, so the match may still be loose and
coincidental.)
Jurchen <NINE> uyewun is not graphically cognate to Khitan <EIGHT>, though it is certainly graphically cognate to Chinese <NINE> (Jin Chinese *giu):
<九
¹I think Janhunen's *r is motivated by words for 'ninety' like Written Mongol yeren which can be analyzed as yer-en by analogy with jir-an 'sixty'², dal-an 'seventy', and nay-an 'eighty'.
²This numeral must date after the innovation of jir-ghu-ghan 'two'-'three'-(numeral suffix) (i.e., 2 x 3) for 'six'. If Jurchen and Manchu preserve the Khitan word for 'six' (or a close relative) in their words for 'sixteen' and 'sixteenth day of the first month' (nil-hun and niol-hun), an earlier word for 'sixty' might have been *nil-an. Could the Khitan word for 'sixty' written
~

<SIXTY> (large script) ~ <SIXTY> 266 (small script)
(masculine variants in the small script omitted)
be nilan? But there is no evidence for the readings
of the tens in Khitan, let alone any evidence for a Mongolic-like X-an
pattern for the tens in Khitan.
2. Children of empire are where you least expect them. Elizabeth Shepherd almost played Emma Peel on The Avengers:
She spent her first years in Burma (her first public appearances were performing Burmese dances at missionary meetings!), and came back to England to experience the wartime Blitz in London.
3. The etymology of Hawaiian hae 'flag'?
perhaps so called because a piece or torn [hae] tapa was used as a banner
4. The etymologies of the Hawaiian names of Kamehameha's British advisors:
[Isaac] Davis was given the Hawaiian name ʻAikake, after the way that the Hawaiians tried to pronounce Isaac, from /ˈaɪzək/ to /ˈaɪzɑkɛ/, Isaac"eh", to /ˈaɪkəkɛ/ (ʻAikake).
The Hawaiians gave [John Young] the name ʻOlohana based on Young's typical command "All hands (on deck)".
5. How did La Guardia
learn German? Did his mother speak it?
His father, Achille La Guardia, was a Catholic from Cerignola, Italy, and his mother, Irene Luzzatto Coen, was a Jewish woman from Trieste, then part of the Austro-Hungarian Empire [...] He spoke several languages; when working at Ellis Island, he was certified as an interpreter for Italian, German, Yiddish, and Croatian.
6. The
hospital that just got completed in ten days is named 火神山
Huǒshénshān 'Fire God Mountain'. Its
soon-to-be completed sister is 雷神山 Léishénshān 'Thunder God
Mountain'.
7. Ō NO
An urge: please, if using “ou” to spell ō, add hyphens between o and u when they are separate! Otherwise, from recent: Inōe, Marunōchi, and, constantly in Sumō context, Shimanōmi.
I confess I use ou a lot for ō and ou,
leaving it up to the reader to figure out which is [oː] and which is
[oɯ], but I never write o-u [oɯ] across morpheme boundaries as ō.
All three cases above involve two morphemes: no and a noun
beginning with u.
8. I never thought about how Viking names were hibernized until I saw Sitric from Old Norse Sigtryggr.












{kind=link}