 <052.e'> instead of
<052.e'> instead of  <052.e>.
<052.e>.
19.10.26.23:02:
KHITAN SMALL SCRIPT DIAMONDS AND PYRAMIDS
1. Most Khitan small script character blocks have these structures. In short, characters are arranged from left to right and top to bottom in rows that are two characters wide.
What I call 'vertical stacks' have one character directly atop another instead of side by side: e.g.,
Today I came up with the term 'diamond' for blocks with more characters in the center than at the top or bottom:
<294.051.098.151> <294.gha.al.ghu> (Xing 28.3), <364.051.098.151> <364.gha.al.ghu> (Dao 26.24)
364 is a variant of 294. By itself, 294 represents a word 'south'. Perhaps 294 ~ 364 is an alternate spelling of <t.093> ~ <t.ie.093> ~ <d.093> 'south'.
And today I came up with the term 'pyramid' for blocks with only one
character on the top atop one or more rows of two:
<280.028.097> <280.sh.ur> (Xing 28.1), <294.051.098.051.122> <294.gha.al.gha.ai> (Xing 19.22)
I hate 'this exists, that's it, bye'-type posts, but I don't have
time to look into these blocks any further tonight. (I found all four
yesterday and didn't have time to write about them then.)
2. Last night I noticed the similar-looking Khitan small script blocks
<282.128.339> <282.128.i> and <282.196.339> <282.bu.i>
next to each other in the block index of 契丹小字研究 Studies on the Khitan Small Script (1985: 401) and wondered if
<128> <?> and <196> <bu> (Shimunek 2017: <ebu>)
might be variants of each other. I'll have to see if they occur in
other identical environments.
3. I'm curious about how Southern Min was romanized in this 17th century
Southern Min-Spanish dictionary.
4. 懦 GSR 134e is an oddity in a phonetic series whose usual common
denominator is Old Chinese *no: e.g.,
需 134a *sIno 'to wait; weak', *sInorʔ
'supple', *norʔ 'weak'
繻 134b *sIno
儒 134c, 濡 134f, 𣽉 134g, 襦 134i *CIno
臑 134h *CIno 'pliant, soft', *naw(s) or *CAnu(s)
'shoulder; upper part of an animal's front leg'
孺 134d *CInos
醹 134j *CIno(ʔ)
懦 GSR 134e 'weak' not only has the expected reading *Cino 'weak, timid' but also has three other readings (also all meaning 'weak, timid'):
*Cinorʔ
*norʔ
*nojʔ < *nolʔ?
The *liquid-final readings of 懦 134e and its phonetic 需 134a reflect
confusion with 耎 238a *CInorʔ 'soft, weak' as noted by Karlgren
(1940: 163). I suspect 耎 238a *CInorʔ 'weak' was homophonous
with 需 134a *sInorʔ 'supple', an alternate spelling of the
same word, but there is no evidence within series 耎 238 directly
pointing to *s-: e.g., modern readings with [s] such as
Cantonese seoi1 for 需. It is possible that *CInorʔ
and *sInorʔ had a common root *norʔ with different
prefixes.
Both 需 134a and 耎 238a in turn have 而 982a *nə 'and' as their phonetic. 而 982a is originally a drawing of whiskers and represented a word 'whiskers' - probably the same word as 須 ~ 鬚 *sIno 'beard'. I suspect *nə 'and' might be an unstressed reduction of an earlier *no.
How one phonetic became three:
| Primary phonetic |
Derived phonetic |
Further derivatives |
| 而 *sIno? 'beard' |
需 *sIno 'to wait; weak' |
繻 *sIno 'frayed silk', etc. |
| 耎 *CInorʔ 'weak' |
需 *CInorʔ 'supple', *CInorʔ 'weak', 懦 *CInorʔ ~ *nojʔ 'weak' | |
| 而 *no? > *nə 'and' | 栭 *nə 'fungus', etc. |
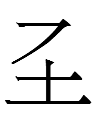
5. I have never seen an English name begin with <Jch> before.
I presume the female name <Jchandra>
is from Sanskrit candras 'moon' (masculine!). <Jch> would
be understandable as a rendering of Sanskrit voiceless unaspirated c,
though I don't think that was the motivation for that unusual letter
combination.
19.10.25.22:05: VERTICAL STACKS IN KHITAN: 052 (PART 4)
1. The last instance of vertically stacked
<052.e>
in the Khitan small script that I know of is in line 27 of the eulogy for Emperor 道宗 Daozong (1101):
<mu.188 dau.o.gho tau.is.en 371.a 079? 318.er j?.u.ur 232 sh.eu.013 ur.u.er ghu.as.al ung.su 336 c.er>
Incomprehensible to me except for <c.er> 'wrote' at the end of
a sentence which is a convenient point for breaking the line into two.
The second half has a few words I recognize:
<COMPOSE.l.ghu ui.l us.g 066.l.ge.en mu.u.j.i 026.s.g ts.ar hua.315 ghu.ogh 268.ir.o.o.on mo.ge.de y.ie.er 042.a p.ge.ii 282.128.i eu.ul.ge.y as.ar p.ge.ii m.g.un 052.e dau.o.on as.320>
'compose-CAUS/PASS-? affair? character V-CAUS/PASS-PTCP.M sagely ? ? ? ? ? N-LOC/DAT ? ? V-CVB ? ? pure V-CVB V-PTCP.M? 052.e ? ?'
Unfortunately, I understand none of the words around <052.e>.
<m.g.un> looks like a masculine perfective participle modifying a
noun <052.e>.
2. It's taken me years to notice this rare case of semi-overlap between the Khitan large and small scripts:
1864 <ar> (large) and 123 <ar> (small)
I'm so accustomed to the same shape standing for different things in the two scripts (e.g., 一 is 'one' in the large script but 'above, north' in the small script) that I've never looked for any homophonous lookalikes.
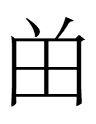
3. Here's a fun Cantonese character I learned today: a semantic
compound with a Khitan small script-like¹
two-on-one structure: 膥 ceon1.
| 未 <NOT.YET> |
成 <BECOME> |
| 肉 <MEAT> |
|
I can't think of any other semantic compound with that layout of
elements, and 肉 is a rare bottom element.
Can you guess what 膥 means? Answer here (visible if you select the
blank space before the period): reptile or bird egg.
I've found three Mandarin readings for 膥: chun1, cun1, and cen1. Jun Da's modern Mandarin rank for膥 is #8529; 膥 only appears twice in the corpus, presumably as a loan from Cantonese. Are the Mandarin readings borrowings from Cantonese?
I seem to be the only person who ever looked at the
CantoDict entry for 膥 (other than the editor of the page).
This word has been viewed 1 times since 30th Oct 2012
¹But of course Khitan small script blocks are phonetic symbol combinations, not semantic compounds.
The only common character with 肉 <MEAT> on the bottom is 腐 'decay, rotten' (Jun Da #1576). There turn out to be at least fifty more characters with 肉 <MEAT> on the bottom, but I don't know what they represent:
肏𦘫𦘬𦘻䏑𦙂𦙡𦙩胔胬𦙲𦚇𦚘𦚨𦚮𦚷𦛄𦛆𦛇𦛝𦜑𦜜𦜾𦝍𦝎𦞍𦞏膐 𦟡𦟴𦠂𫆰𦠕𦠩𦠪𦠬𦠶𦡈𦡜𦡭𦡼𦢆𦢰𦢽臠臡𦣚
Some interesting characters for future investigation:
A rare (and unique?) case of both the abbreviated (月) and full forms of 肉 <MEAT> in the same character:
𦝾
己 at the top right is <SELF>.
A rare (and unique?) case of 肉 <MEAT> as a bottom right corner element the same size as a bottom left corner element:
𦞋
A rare (and unique?) case of 肉 <MEAT> as a top element:
𫆭
An 夕 <EVENING>-like variant of 肉 <MEAT> I've never seen before:
𦠹𦠺𦣐𤓏
Finally
𮌾
is ⿰腐丑 <DECAY.OX>. Is it a semantic compound or a
semantic-phonetic compound? If it is the latter, which half is semantic
and which half is phonetic?
19.10.24.23:14: VERTICAL STACKS IN KHITAN: 052 (PART 3)
1. There are at least two more instances of vertically stacked <052.e> in the Khitan small script:
Let's look at the first from line 20 of the eulogy for Emperor 道宗 Daozong (1101).
<b.as s.188.o.oi.en h.su.gu 193.ad REGION.y.i y.au.ul.ghu em.d.er neu.e dau.ui t.c t.092.gu HEAVEN 050.u.lia neu.e sh.ur.l.b.ñ k.ii k.ii mu.u.j us.g m.g.s ETERNAL s.092 n.am.ur sh.ul.g.s ETERNAL as.ar heu.ur s.eu.ur.un ta.u.d.b.356 c.ie.271.ñ 052.e gho.l.g pu.ulji.l.g sh.al.s dau.ur s.iau>
'again N-GEN? ? N-PL? region-GEN? ? V-PFV.FIN.M? earth V-CVB? ? ? heaven ? earth ? ? ? sage written.character ? eternal ? autumn ? eternal pure spring N-GEN? ? V-PFV.PTCP? N? ? ? ? ? ?'
<c.ie.271.ñ> might be an <-ñ> participle modifying <052.e> which could be a noun here as it seems to be in the epitaph for 蕭仲恭 Xiao Zhonggong (1150). The only other form of <c.ie.271-> that I know of, <c.ie.271.i>, may end in a converb <-i>. 271 may end in a vowel since a final consonant-[ɲ] cluster is unlikely.
2. I've been wondering since maybe 1992 why 旺角 wong6 gok3 is called Mong Kok in English. Tonight I finally learned why:
The current English name is a transliteration of its older Chinese name 望角 (Jyutping: mong6 gok3; IPA: [mɔːŋ˨ kɔːk˧]), or 芒角 (Jyutping: mong4 gok3; IPA: [mɔːŋ˨˩ kɔːk˧])
Or reviewed why - that explanation sounds vaguely familiar.
Mong Kok belongs to the category of conservative English exonyms for
places. Others are Peking (preserving *k), Belgrade (preserving
*l), and Prague (preserving *g). But in those cases, the
modern autonyms are descendants of the forms underlying the English
exonyms, whereas Mong Kok is only half-cognate to modern wong6 gok3.
New question: Why was the name of Mong Kok changed?
3. Today I learned that an American superstar is called the 貓王 Cat King in Chinese. Who is he?
4. I had never heard had waked before, and was surprised to
see that it
was more common than had woken until recently.
19.10.23.23:51: VERTICAL STACKS IN KHITAN: 052 (PART 2)
1. The Khitan small script epitaph for 蕭仲恭 Xiao Zhonggong (1150;
hereafter 'Zhong') has two spellings which might represent the same
word:
<052.348> (7.13) and <052.109'> (48.1)
<'> indicates vertical stacking.¹
Khitan small script character 109 <e> is a five-stroke variant of six-stroke 348 <e>, so the only potentially significant difference between the two spellings is the orientation of the two characters within each block. "Potentially" only if the two blocks represent different (though homophonous) words.
How can I tell if they represent different words? If the two blocks appear in identical contexts, they are unlikely to be different words (unless a play on words was involved).
Let's look at the contexts of those blocks:
Zhong 7: <qid.i c.iau qu.i us.g h.an na al.a.ar c.iau qu.ui qid.i shï COMPOSE.un 052.e eu.ul po.ogh s.eu.ur.un ta.u.en ...>
'Khitan-GEN China-GEN character ? ? ?-PFV.FIN.M China-GEN Khitan-GEN master N compose-PFV.PTCP N cloud ? ? ?'
'... al-ed Khitan [and] Chinese characters ... 052.e [that was] composed by a Chinese [and] Khitan master ... cloud ...'
052.e is a noun modified by <COMPOSE.un> 'composed', so it
presumably refers to a composition of some sort.
Zhong 48 (line 47 might end at the end of a sentence):
<052.e ku YOUNG.qu.ETERNAL ◊ h.zu.ge.en pu.ulji.i p.ir.en t.e.er ◊ gur.en>
'N person ? (a noble title?) ? ? ?.FIN.M?. country.GEN ...'
052.e seems to be a noun modifying ku 'person'. If this is the same 052.e that was composed in line 7, then a 052.e ku might have been a scribe or even a poet or storyteller (if the composition was oral).
It seems that the writer of Zhong, is.g.un h.ang.n.u (named in line 618), might not have made a semantic distinction between
<052.348> (7.13) and <052.109'> (48.1).
They do at least both seem to be nouns, though I can't be sure they
both meant the same thing. Next I'll see if the vertically stacked
version might also be a noun in other contexts.
¹I just realized the short vertical stroke could symbolize vertical stacking. If I used short horizontal strokes to indicate left-to-right sequences and placed direction indicator strokes between character numbers, the first block would be <052-348> in contrast with <052'109> for the second.
2. Shimunek (2017: 243) proposes that Khitan did not allow the clusters rc and rj "perhaps ... word-finally or across morpheme boundaries". I did a quick search for such clusters and could only find <n.ar.c.en> (Xu 60.2) which might be narc-en, the feminine perfective of a verb narc- '?'.
3. I've mostly used the Leipzig glossing rules for Pyu and other South and Southeast Asian languages, so I never thought about how to gloss forms like German gesehen 'seen'. The Leipzig rules gloss it as
PTCP-see-PTCP or
PTCP-see-CIRC
Oddly, CIRC (for circumfix?) is not in the rules' list of abbreviations. Until now I would have glossed it simply as 'see.PTCP' without breaking it up.
I suppose I could then gloss Sanskrit a-paśa-t 'saw' as
IPFV-see-IPFV.3SG or
IPFV-see-CIRC.3SG
though I would prefer 'see.IPFV.3SG'.
19.10.22.23:32: VERTICAL STACKS IN KHITAN: 052 (PART 1)
1. Last night, while looking for what 契丹小子研究 Research on the
Khitan Small Script (1985) had to say about
342 <?> (see my previous post),
I saw the block <052.348'> which is one of a minority of
vertically
stacked blocks. (I indicate vertical stacking with <'>.)
|
block |
|
|
|
|
|
# |
052.109 |
052.109' |
052.348 |
052.348' |
|
Dao |
unattested |
- |
- |
20.31, 27.34 |
|
Xu |
- |
4.2, 5.13, 26.15, 27.24, 61.13 |
- |
|
|
Gu |
- |
4.21 |
- |
|
|
Zhong |
48.1 |
7.13 |
- |
Kane (2009: 41) states that 052 "is only found in the word
<RECORD.gi>
'record', with various suffixes." But 052 can also occur by itself (only once in Gu 10.7) or followed by characters other than 334 <g> (Kane's <gi>):
109 <e>, 112 <ge>, 348 <e>, 349 <ge>, 354 <j>
It is true, though that 052 is most often followed by 334 <g>. And it's possible that <052.ge> contains the same root as <052.g> 'record'. I could even go so far as to say that
'record' was Xg <052> ~ <052.g>
but there are no other known cases of Khitan small script
logograms with both full logogram and logogram-phonogram spellings
<052.ge> was a derived form Xg-e
but there is no known suffix -e, so maybe Xge is an indivisible root unrelated to 'record'
<052.j.de> (the only known instance of <052.j>) could be a dative/locative of a derived noun Xg-j
<052.j.de> could also represent an Xj word unrelated to the Xg-words meaning 'record'
In any case, 052 never occurs in noninitial position in a block. Nor does it ever seem to transcribe any Liao Chinese syllables. 052 could have represented a string that was only in 'record' (and an unrelated <052.e>?).
Going back to the stacking of <052.e>:
<052.348> is the majority spelling
<052.348> coexists with <052.109'> in Zhong
<052.348'> is unique to Dao
Is there any significance in vertical stacks as opposed to the more
common horizontal stacks? I'll start comparing the contexts of the two
types of stacks next time.
2. Yesterday when discussing a possible of case of root-final <p> ~ <b> alternation I forgot to mention a case of possible noun plural suffix alternation:
<-t> ~ <-d> (cf. Written Mongolian -d)
And tonight I thought of the converb
<-c> ~ <-j> (cf. Written Mongolian -ju/-jü)
What determines the forms of the suffixes? Could they be predictable from a historical perspective? E.g.
<ai.d> < *ai-d 'fathers'
<mo.t> < *moH-d? 'mothers'
In the above scenario, the aspiration of <t> [tʰ] is a trace
of a root-final *-H that was lost in isolation (the singular of
'mother' is <mo> < *moH?).
Compare the <d> ~ <t> alternation with the -da ~
-tha alternation of the Korean finite suffix:
나다 nada < *na-ta 'to come out'
놓다 notha < *noh-ta 'to put'
the *h has no trace after a vowel: 놓아 noa < *noh-a 'put and ...'
ㅎ <h> is consistently spelled in Korean even though it is not pronounced in all members of the paradigm
And compare the <j> ~ <c> alternation with the -ja ~ -cha alternation of the Korean hortative suffix:
나자 naja < *na-ca 'let's come out'
놓자 nocha < *noh-ca 'let's put'
3. Last night I rediscovered the problem of 幽靈漢字 ghost
characters in JIS (and Unicode) encoding:
Of these [twelve], it is conjectured that several glyphs came about due to copying errors.
That made me wonder about the problem of ghost characters in TJK
(Tangut/Jurchen/Khitan).
Three Tangut characters that puzzle me are 5997-5999 in Li Fanwen
(1997) which are only known from Sofronov (1968):
LFW1997-5997 𘅈 1lhy1
looks like a variant of 𘀮 3932 1lhy1
LFW1997-5998 𗤗 2zwiq2 has
no (near-)homophone lookalikes (or any homophones)
LFW1997-5999 𗧄 (class IX initial; rhyme unknown) has no (near-)homophone lookalikes
Okay, make that two that puzzle me.
See Wu and Janhunen (2010: 48) for a brief discussion of Khitan small script ghost characters ("mistakes and overlappings").
I don't know of any discussions of ghost characters in the Khitan
large script or the Jurchen (large) script.
19.10.21.23:59: KHITAN 'STABLES' AND 'ALTERNATORS': BEYOND ONSETS?
1. Last night while copying line 28 of the Khitan small script epitaph of 耶律迪烈 Yelü Dilie (1092), character 343 caught my eye in block 12 <p.al.s.gha.al.343> (as printed in Kane 2009: 205).
343 (left) looks a lot like 342 (right):
Visual similarity is no guarantee of phonetic identity or even phonetic similarity in the Khitan small script. Nonetheless the fact that 342 and 343 occur in similar contexts could imply that they are homophonous variants of each other:
<342.295.140> <342.p.en> 'wine-GEN'?
<342.311> <342.b> 'wine'
<343.295.140> 'wine-GEN'?
<343.311> <343.b> 'wine'?
<343.311.140> <343.b.en> 'wine-GEN'?
The only one of those five that has been identified with some degree of certainty is <342.b> 'wine', identified as the object in the Khitan object-verb expression corresponding to Chinese 酣飲 han 'rapturously drunk' in the bilingual Langjun inscription.
342 has even been regarded as a logogram <WINE>, though I
doubt I am not sure that is the case since 'wine' is <342.b> and
not <342> by itself. As far as I know, neither 342 nor 343 ever
occur alone which would seem to rule out logogram status unless
<342.b> is a redundant spelling with <b> added to clarify a
final -b in the reading of <342>.
Most interesting of the five is <342.p.en> which might be a variant spelling of <343.b.en> , possibly 'wine-GEN'. Might 'wine' have [p] in final position but [pʰ] before a vowel like Korean /pʰ/ words such as /apʰ/ 'front'?
앞 <Ø.a.ph> /apʰ/ [ap] 'front'
앞에 <Ø.a.ph Ø.ŭ.i> /apʰe/ [apʰe] 'in front'
In earlier Korean, /apʰ/ in isolation was spelled phonetically as <Ø.a.p>¹. Khitan <342.b> and <343.b> may be similar phonetic spellings reflecting a final [p].
Khitan <342.p.en>, on the other hand, reflects a medial [pʰ].
So far I have been talking about alternations in Khitan initial consonants. Could there be alternations in Khitan medial and final consonants as well? If <342.p> and <342.b> both represent 'wine', how many other nononset alternators are there?
Jishi (2012) has read both 342 and 343 as [səm]. I don't know what the underlying reasoning is; I know of no Mongolian word like sem- for 'wine'. Moreover, if Jishi is right, <342.b> looks like it should be read [səmp], though it seems Khitan did not have final consonant clusters.
¹10.22.0:45: In post-1933 Korean orthography, 앞 <Ø.a.ph> is the spelling used in all contexts, but in premodern Korean, there were at least three spellings used before vowels:
아ㅍ- <Ø.a ph->
압ㅍ- <Ø.a.p ph->
압ㅎ- <Ø.a.p h->
All three have <(p)h> in a second block. See Yu (1964: 531)
for examples.
2. Last night I forgot to mention another unusual Japanese spelling
in the
entry for 王冠・叡智の光 Gōremu Keterumarukuto:
原初 <ORIGIN BEGINNING>
for adamu (rather than the normal gensho 'very beginning'). Obviously the logic is that Adam is the first man.
In theory one could create a semantic compound for adam like
⿰亻初 <PERSON.BEGINNING>.
傆 <PERSON.ORIGIN> already exists and represents two morphemes, Middle Chinese *ŋuan 'anger' and *ŋuanʰ 'hypocrite' (related to 鄉愿 <VILLAGE HONEST.CAREFUL> *xɨaŋ ŋuanʰ 'hypocrite', whose logic eludes me?).
I would rather not create a semantic compound with gender-specific 男 <MAN> because 男 <MAN> forms few compunds, and ⿰男初 <MAN.BEGINNING> and ⿰男傆 <MAN.ORIGIN> are complex.
²10.22.0:38: Or three? The 大徐本 Great Xu
edition (986) of 說文解字 Shuowen jiezi
gives the fanqie 魚福切 *ŋɨə + *puk = *ŋuk
and the gloss 黠 'shrewd'. But 原 is an *-n phonetic which would
normally never represent *-k syllables.
3. Last night I was surprised to learn that 智 <WISE> in
王冠・叡智の光 Gōremu Keterumarukuto isn't a jōyō kanji even though
it's so common and well within my figure of 2000 for must-know kanji.
Here are its Shpika
stats,
Kanken level,
and Jun
Da's general Chinese rank:
| Aozora |
news |
Twitter |
Wikipedia |
Kanken |
Jun Da |
| 946 |
1064 |
1129 |
882 |
pre-1 |
956 |
智 is mostly in names. One doesn't have to learn it in school because
one will encounter it effortlessly in everyday life. Hence I don't
think it belongs at the Kanken pre-1 level; lots of lower level
characters are less frequent and more difficult. But I understand why
it has such a high rank; non-jōyō JIS
level 1 kanji are automatically assigned to pre-1.
4. Looking at the top of Jun
Da's combined Mandarin and classical frequency list, I get the
sense that the ratio of Mandarin to classical isn't 50/50.
High-frequency Mandarin morphemes outrank their classical equivalents:
genitive: Md 的 (#1) vs. Cl 之 (#13)
change of state marker: Md 了 (#5) vs. Cl 矣 (#830)
了 has a broader range of meanings in Mandarin than 矣 in classical, so there should be a gap between them, but I would put 矣 in the top 100 characters for classicla students to learn.
'this': Md 这 (#11) vs. Cl 此 (#89)
5. I would never have guessed that 𢦕 <HALBERD.ALL> is an old
variant of the change of state marker 矣. The visual gap between 𢦕 and
矣 is roughly comparable to the visual gap between many Khitan or
Jurchen large script characters and their Chinese character translation
equivalents. The hypothetical Parhae script ancestral to Khitan and
Jurchen large script characters could have been as different from
mainstream sinography as 𢦕 is from 矣.
6. Today I was surprised to learn that ridings in Canada have nothing to do with riding anything.
If English were written in a Japanese-like script, it might be spelled as something like 三部 <THREE PART> even though ri- < thri- no longer sounds like three.
7. Tonight I learned that 說文解字 Shuowen jiezi
is a
TV series!
19.10.20.23:54: THE FIFTH, SIXTH, AND SEVENTH APPROACHES TO KHITAN 'STABLES' AND 'ALTERNATORS'
1. Approaches 1-3 are here and 4 is here. In short, they are
the allographic approach (2-series)
the allophonic approach (2-series)
the phonemic approach (3-series)
Approach 5 is the geographic approach. Are alternators characteristic of texts in certain locations? Might they reflect Khitan dialects in which the two series of obstruents merged (in certain environments)? I have not yet tried to answer that question.
The geographic hypothesis does not necessarily predict that all texts in a certain region will have only one type of spelling. I would expect nonstandard Khitan texts to have a mixture of 'correct' and 'incorrect' spellings. The 'incorrect' spellings would reflect the local pronunciation.
Suppose in standard Khitan, a word X is pronounced with initial [tʰ] and written with <t>.
Then suppose that in a nonstandard Khitan dialect, X is pronounced
with initial [t] in some or all environments. Speakers of that dialect
may spell X either with <t> (reflecting the standard or a
[t]-allophone) or with <d> (reflecting the local pronunciation
[tʰ]).
2. Approach 6 is the chronological approach. Suppose an alternator has two spellings A and B. Do all B spellings postdate the year X? If so, B may reflect a sound change predating the year X.
The chronological hypothesis does not necessarily predict that all
texts after the year X will have only spelling type B. I would expect
post-X Khitan texts to have a mixture of conservative type A spellings
and innovative type B spellings.
3. Approach 7 is the KSL (Khitan as a second language) approach. Khitan was an official literary language of the Jurchen empire until 1192. There is no doubt that Jurchen was a 2-series language. What if Jurchen speakers had trouble with Khitan which may have been phonetically and/or phonemically different from their own language?
Ethnicity does not equal language. What if under Jurchen rule, some Khitan scribes came to adopt Jurchen as their first language and wrote Khitan with errors characteristic of Jurchen speakers?
The KSL hypothesis does not necessarily predict that all Jurchen Empire Khitan texts will only have 'wrong' spellings. I would expect Jurchen Empire Khitan texts to have a mixture of correct and 'incorrect' spellings.
I have no evidence in favor of any of the seven approaches. Nor have I tested any of the approaches by searching for counterevidence. I am still in an exploratory phase. Much basic work needs to be done to resolve the question of alternators:
compliation of a list of alternators
compliation of a list of all occurrences of alternators
cataloguing all occurrences of alternators by phonological context, time, place, and author
Many problems besides the alternator issue may be clarified by
ceasing to view the Khitan corpus as a unified whole. Khitan was in use
over centuries over a large area by by both native and KSL speakers,
and clearly its spelling was never standardized.
4. In a draft of my last entry that I didn't upload, I mentioned the Khitan small script characters for 'ten thousand' as examples of characters with reconstructed readings that to the best of my knowledge don't seem to be supported by either Khitan spelling alternations or Chinese transcriptions of Khitan.
| # |
character |
Chingeltei 2009 |
Wu & Janhunen 2010 |
Jishi 2012 |
Takeuchi 2012 |
Shimunek 2017 |
| 187 |
 |
t'um |
MYRIAD |
ɔlu |
tum |
tum |
| 312 |
 |
tum |
? |
The reading t(')um is reminiscent of Mongolian tümen,
Jurchen tume(n), and Manchu tumen, all 'ten thousand'.
Although I am unaware of any alternate spelling like <tu.m> for
'ten
thousand', I forgot that 312 seems to correspond to the Chinese
transcription 圖木 *tʰu mu. So I was wrong to regard 312 as
having an ungrounded reading.
I don't know Jishi's reasoning for reading 187 as ɔlu. I don't know of any Mongolian olu-word meaning 'ten thousand' or 'myriad'.
I don't even know if I should be treating both characters as
logographs for <TEN.THOUSAND>. Why would a numeral have two
different logographs? Moreover, both also function as phonograms
in noninitial position where they cannot be interpreted as stems
followed by suffixes: e.g.,
Gu 22.9 <323.341.187> <qi.er.187> (the only instance of 187 in noninitial position I know of)
Zhong 25.6 <020.098.051.312> <y.al.gha.312> (the
longest block I know of with 312)
I know of no similar blocks with other characters in place of 187
and 312.
312 is quite common in noninitial position which makes me think it
is a phonogram. Perhaps 187 is a logogram <TEN.THOUSAND> and 312
is a homophonous phonogram <tum(u)>.
5. The Sinogenesis hypothesis: Last week I wrote,
Liao Chinese had two series [of obstruents] in speech. If a speaker of a two-series language worked on the Khitan small script, he might project those two series onto Khitan.
"A speaker" doesn't necessarily have to be a native speaker of Liao
Chinese (or any form of Chinese). Clearly Chinese was known to the
ethnic Khitan elite. Khitan educated in Chinese would draw upon their
knowledge of Chinese to devise the Khitan small script. The writing of
most sylllables as onset-rhyme character sequences is reminiscent of fanqie onset-rhyme
spelling.
The trouble with this hypothesis is that a Chinese-literate Khitan
might be familiar with the Chinese rhyme table
tradition which has three series, not two. The tables would have
provided a prestigious precedent for three series in the Khitan small
script. But the actual script only seems to have two.
At the moment I am turning away from approach 3 to the
stable/alternator problem and favoring 4-7 which do not require three
series, at least in the Liao dynasty. (I still think pre-Khitan could
have had *three series and perhaps some Khitan dialects still had all
three. But I don't think the dialect that was the initial basis of the
small script had three series.)
Since magical lacks a "k," it only makes sense (thought Noah Webster, and as far back as his 1806 dictionary) that magic too would go without a "k"—hence no magick in American English. The same reasoning gave us also our public and traffic spellings, as well as others. The words gimmick and haddock and maverick have no k-less relation (there is no gimmical, haddocal or maverical) to argue away their "k's."
So I wonder - how did magic, public, and traffic
lose their K's in the UK?
Center turns out to not be a Websterism:
[Samuel] Johnson's choice [of centre] was, according to the Oxford English Dictionary, likely based on a very particular edition of an earlier dictionary by one Nathan Bailey: while all 30 editions of Bailey's dictionary featured the "er" spelling of center (which was likewise used in editions of Shakespeare, Milton, and others), the folio edition of Bailey's dictionary was the one Johnson used, and it employed centre.
7. WWII Japanese-language officer Gordon McLendon's Correct Spelling in Three Hours (1962) is a rarity: a modern English-language book not listed at Amazon! What rules did he think could be learned in three hours?
8. This is the most bizarre Japanese spelling I've ever seen:
王冠・叡智の光
<KING CROWN LIGHT ASTUTE WISE no LIGHT>
pronounced
ゴーレム・ケテルマルクト
gōremu keterumarukuto
rather than the expected ōkan eichi no hikari 'royal crown:
light of wisdom'. Golem corresponds to nothing in the spelling,
and eichi no hikari corresponds to nothing in the Hebrew.







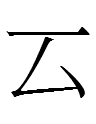








{kind=link}