




19.11.30.21:10: GHO GUO: THE COUNTRY OF 309
After spending almost all week on spellings of Khitan qudugh (if that is what
<FORTUNE FORTUNE₂ FORTUNE₃ FORTUNE₄ FORTUNE₅>
represent - see part 4 of "The Qudugh Question" for a different interpretation), I'd like to prove that I can think about other Khitan small script characters.
When looking for instances of isolated
140 en
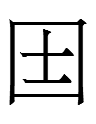
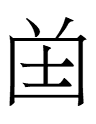
in 契丹小字研究 Qidan xiaozi yanjiu (Research on the Khitan Small Script, 1985) while writing part 5 of "The Qudugh Question", I stumbled upon a hand copy of the text on a coffin containing ... 国 in line 4. Without seeing the actual coffin (photos would do), I think 国 - an exact lookalike of the Chinese character <COUNTRY> pronounced guó in modern standard Mandarin - might be a mistake for
309
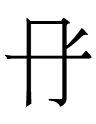
Kane (2009: 72) transliterated 309 as <hó>. <h> is his symbol for [ɣ]. My uvular gh [ʁ] corresponds to his velar <h>. The acute accent indicates that a vowel may have "the same, or perhaps a similar pronunciation" as its unaccented counterpart. I am more agnostic about vowels, so I don't add any accents to avoid implying that all characters that Kane transliterates with accented <ó> share a vowel that distinguishes them from the characters that he transliterates with plain <o>. In this particular case, he needs an accent to distinguish between
076 <ho> and 309 <hó> (both <gho> in my system)
in his transliteration.
I don't know yet that 309 rhymes with
021 090 125 169
which Kane transliterates as <mó ó ió qó> to distinguish them from
021 090 168 <m(o) o qo>
in his transliteration. I can't find any <io> in his system, so I do not know why he transliterates 125 as <ió> on p. 302. He also transliterates 125 as <iáu> on p. 49 to distinguish it from
362 <iau>
which may be "an allograph" (and hence would have the same vowels). The problem of allography in the Khitan small script remains to be fully solved.
Let's focus on the problem of how to read 309. The key is how 309
seems to correspond to the transcription 訛 in the name 訛里本 (= Khitan Gholbun?)
in 遼史 Liao shi (History of Liao, 1344; see Kane 2009: 72 for
details). In 1344, 訛 was read as something like *o in Old
Mandarin. But was 14th century Old Mandarin the language underlying the
choice of 訛? In Liao Chinese 訛 was read as something like *ng(w)o.
ng- is unlikely for a native Khitan word, and ngw- even
less unlikely. (Initial ŋ- is uncommon in the 'Altaic' world,
and ŋw- may be unknown except in loanwords.) So that seems to
rule out interpreting 訛 in terms of Liao Chinese (though one must
wonder how accurately Gholbun's name was preserved by the 14th century,
two centuries after the fall of the [first] Khitan Empire in 1125 - the
only datable Gholbun I can find is also known as 侯古 Hougu, sixth son of
Emperor 聖宗 Shengzong [b. 972; r. 982-1031]).
Perhaps Khitan 309 gho [ʁɔ] was approximated in Old Mandarin as something like *o without any initial consonant since Old Mandarin had nothing like [ʁ]. 309 could not simply be o since a character for o has already been identified:
090
That character represents Liao Chinese *o in loanwords. 309, on the other hand, is apparently never in Khitan small script spellings of Chinese loanwords. That implies 309 represented a sound or a syllable absent from Liao Chinese. gho fits the bill: it has an un-Liao Chinese initial gh- disqualifying it from Khitan spellings of Chinese loans, and its vowel o matches the vowel of its apparent transcription 訛 *o.
11.30.21:57: APPENDIX: Other readings of 309
Liu (2009, 2014) reads 309 as u which doesn't match 訛 *o. It is, however, homophonous with Liu's readings of
076 e ~ u ~ ulu, 172 u, 245 u, 372 u, 131 u
which I read as gho, ugh, u, o, u, u, more or less following Kane (2009). (I can't explain the differences between the various u-graphs either. 131 is the usual graph for transcribing Liao Chinese *u, but 172 and 372 also transcribe that vowel. See Kane [2009: 246-247].)
Jishi (2012) reads 309 as k'ua ([kʰwa]?) which is even further from 訛 *o. 訛 did end in Middle Chinese *-wa (cf. the Middle Chinese-derived Sino-Korean reading 와 wa of 訛), but *-wa had become *-(w)o by the Liao dynasty, and 訛 never began with a voiceless stop, aspirated or otherwise.
19.11.29.19:21: THE QUDUGH QUESTION (PART 5)
Here are the contexts of the two Khitan small script blocks
<FORTUNE₂> and <FORTUNE₄>
from Part 4:
1a. 蕭仲恭 Xiao Zhonggong 35.28:
<qatun.i 343.p.en FORTUNE₂.a.an m.gha.379 c.er>
queen-GEN wine?-GEN fortune-GEN N write-PFV
'... wrote the queen's wine's? fortune's ?'
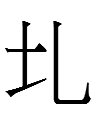
<343.p> may be a noun possessed by the queen and possessing 'fortune' in turn. It may be a variant spelling of <342.b> 'wine' (?; Kane 2009: 76) and <342.p> (if <342.p.en> is a genitive). (<p>/<b> alternation is common in Khitan.) 342 and 343 are similar:
But 'wine's fortune' seems like an unlikely combination of words.
<m.gha.379> is in the slot for a noun possessed by the
preceding genitive of 'fortune' and an object of the verb cer
'wrote', so I expect it to be a noun.
1b. 蕭仲恭 Xiao Zhonggong 47.26:
<343.p.en FORTUNE₂.a.an t.ugh.ii c.iu.ur.094.c>
'?-GEN fortune-GEN N V-after'
'After ?'s fortune's N V-ed,' or
'After [?] V-ed ?'s fortune's N,'
There's <343.p.en> again and in the same position before 'fortune'.
<t.ugh.ii> could be a verb ending in a converb <ii>, but 'fortune-GEN' needs something to possess, so I regard it as a noun which is either the subject or object of the following verb.
<c.iu.ur.094.c> ends in a converb <c> that I translate
as 'after' (following Kane 2009: 153-154).
2. 仁懿 Renyi 5.29:
<326.041 c.l.ugh s.tumu FORTUNE₄.ń hong.ghu p.ud.z.iu TWO en b.qo ○ HEAVEN as.ar hong di>
'? ? fortune-GEN.PL Hongghu Pudziu two ? son heaven clear emperor'
'... Pudziu Hongghu of ... blessings' two ? son / the Heaven Clear Emperor'
<326.041> is a hapax legomenon.
<c.l.ugh> is also a hapax legomenon; it might be the singular
of
<c.l.ghu.ad> (for cVlughad?; Xingzong 28.7) which might
have a plural ending in -ad (but I'd expect a plural ending in -ud
with vowel harmony!).
It's tempting to assume <tumu> is 'ten thousand' which it can
be elsewhere but not here with a preceding <s>. There do not seem
to be any prefixes in Khitan, and I don't know of any numeral beginning
with s-, so <s.tumu> can't be interpreted as 'X ten
thousands' with <s> representing a reduced form of a numeral X.
<s.tumu> doesn't have a verb ending, so it is unlikely to be the
end of a clause. It may be a noun or adjective modifying 'fortune'. It
could also be a variant spelling of <s.313> which occurs four
times in Zhonggong. Characters 312 <tumu> and 313 <?> are
identical in shape except for the location of their right-hand dots:
<p.ud.z.iu> is a unique spelling of a title for Khitan noblewomen that appears elsewhere as <p.ü.z.iu>, <b.ü.z.iu>, and <p.ü.089.iu> (more here). The name of this pudziu is Hongghu, a hapax legomenon.
<TWO en> is strange. First, I would expect <TWO.en> as a
single block. Second, reading <TWO en> as 'two-GEN' = 'of two'
doesn't make sense in this context: why would 'son of two' be after the
name and title of a woman? Third, 'second' might make more sense, but
'second' for masculine nouns like the following <b.qo>
'son' is <c.ur.er> ~ <dz.ur.er>, not <TWO>. Fourth,
<TWO> without a dot is grammatically feminine, not masculine.
Fifth, <en> is almost always never by itself; the only other
instance of isolated <en> that I know of is in a wall inscription
of the 萬部華嚴經塔 Wanbu Avataṁsaka Sutra pagoda.
'Heaven Clear' following a space of respect transliterated as ○ (and
converted to '/' in the translation) is the Khitan era name
corresponding to Liao Chinese 清寧 *cingning (now Qingning;
1055-1064) 'Clear and Tranquil' in Chinese. The emperor of that era was
道宗 Daozong,
first (not second!) son of Empress Renyi (birth name 撻里 Dali, not
Hongghu!), the subject of this epitaph. In other words, Daozong
isn't the <b.qo> 'son' before the respectful space.
Someone else is the son of two - Pudziu Hongghu and some man. Might
the mystery words before 'Pudziu Hongghu' be the man's name? I could
parse the mystery phrase as
X Hongghu pudziu two-GEN son
'son of the couple - X and Pudziu Hongghu'
X might be somewhere in <326.041 c.l.ugh s.tumu>. The hapax
legomena <326.041 c.l.ugh> might be a name.
19.11.28.23:59: THE QUDUGH QUESTION (PART 4)
In Part 3 I mentioned that these proposed
characters for qudugh 'good fortune' previously regarded as
two-character blocks
<FORTUNE₂> and <FORTUNE₄>
were attested as parts of larger blocks in 契丹小字研究 Qidan xiaozi yanjiu (Research on the Khitan Small Script, 1985):
<FORTUNE₂.a.an> and <FORTUNE₄.ń>
-ń might be a genitive plural ending which can follow final consonants (Kane 2009: 135), but <a.an> -an looks like a genitive ending for an -a-final noun (Kane 2009: 132) ... which qudugh is not. Could <FORTUNE₂> represent a Khitan cognate of Written Mongolian aja 'fortune'? Could all of the five <FORTUNE> graphs
<FORTUNE FORTUNE₂ FORTUNE₃ FORTUNE₄ FORTUNE₅>
represent that a-final word? qudugh is attested phonetically in Chinese transcription as 胡覩古 *xutuku and 胡都 *xutu¹. Could its Khitan small script spelling be something other than a form of <FORTUNE> - a block of multiple phonetic characters?
(On to Part 5)
¹11.29.11:33: The reasoning for the interpretation of *xutu(ku) as qudugh:
The transcriptions resemble Written Mongolian qutugh [qʊtʰʊʁ] 'bliss', Manchu hūturi [χʊtʰʊri] 'good fortune' (with a noun suffix -ri; Gorelova 2002: 114), and Jurchen
hutur 'good fortune' (transcribed as 忽禿兒 *xutʰuər; Bureau of Translators vocabulary #343)
huturi 'good fortune' (transcribed as 忽禿力 *xutʰuli; Bureau of Interpreters vocabulary #740)
Jurchen/Manchu h [χ] < *q corresponds to Written Mongolian q which corresponds to Khitan q
2nd millennium AD northern Chinese had no uvulars, so uvulars had to be transcribed as velars:
Chinese*x could correspond to Khitan q-
Chinese *k could correspond to Khitan gh- [ʁ]
In my non-IPA transcription system for Written Mongolian, Jurchen/Manchu, and Khitan, /nonaspirates/ are written as voiced, and /aspirates/ are written as voiceless. The Chinese transcriptions of Khitan 'good fortune' have unaspirated *-t- which points to Khitan unaspirated -d- /t/ (with an intervocalic [d]?) rather than t /tʰ/ like Mongolian or Jurchen/Manchu.
'Altaic' harmonic rules forbid uvular q coexisting with velar g, so Chinese *k cannot represent Khitan velar g /k/; it must stand for a uvular. Chinese unaspirated *k cannot represent Khitan uvular q /qʰ/ which is aspirated. It must represent the other Khitan uvular obstruent gh /ʁ/, the voiced counterpart of q.
2nd millennium AD northern Chinese had no final *-gh, so the Chinese transcriptions of the Khitan word exemplify two coping strategies:
approximate -gh with a voiceless stop and add an echo filler vowel: -gh as 古 *-ku
simply ignore -gh (and a final sonorant is easier to
ignore than a final stop)
19.11.27.23:59: THE QUDUGH QUESTION (PART 3)
I put off my original plans for Part 3 just minutes ago when I spotted an unusual Khitan small script block configuration in 契丹小字研究 Qidan xiaozi yanjiu (Research on the Khitan Small Script, 1985: 457):
| ① |
② |
| ③ |
The normal three-character block configuration has two characters on top and one on the bottom:
| ① | ② |
| ③ | |
e.g.,
<013.224.327> <?.mu.ie> (Gu 12.1)
A less common configuration has a wide horizontal character atop two characters:
| ① | |
| ② | ③ |
e.g.,
<001.251.257> <?.n.em> (Ren 13.5)
This new (to me) configuration has a tall vertical character to the left of a stack of two characters:
<335.327.054> <ia.ie.?> (Xing 27.12)
That combination looks like the single character
<380> qudugh 'good fortune'
and is even glossed on p. 500 of Qidan xiaozi yanjiu as 福 'good fortune'.
So I now think there are at least five different versions of the single character qudugh 'good fortune':
<FORTUNE FORTUNE₂ FORTUNE₃ FORTUNE₄ FORTUNE₅>
(11.28.23:41: Transliterations added.)
1. 380, previously regarded as <335.277>
2. serial number needed, previously regarded as <335.275>¹
3. serial number needed, previously regarded as <335.276>
4. serial number needed, previously regarded as <335.278>²
5. serial number needed, previously regarded as <335.327.054> (note the proportions of the components)
(On to Part 4)
¹11.28.15:30: I've extracted this character from a
larger block in Qidan xiaozi yanjiu. See part 4.
²11.28.15:30: I've extracted this character from a larger block. in Qidan xiaozi yanjiu. See part 4.
19.11.26.23:56: THE QUDUGH QUESTION (PART 2)
Yesterday in Part 1, I mentioned that one
reason I didn't think
<380> qudugh 'good fortune'
in the Khitan small script was a sequence of two characters
<335.277> <ia.?>
was that qudug does not begin with ia- (i.e., the reading of 335). But what is the reading of 277?
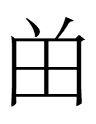
Maybe 277 has no reading. In 契丹小字研究 Qidan xiaozi yanjiu (Research on the Khitan Small Script, 1985), a quartet of characters
<277 275 276 278>
transliterated by Wu and Janhunen 2010 as <LUCK LUCK₂ LUCK₃
LUCK₄> always occur in second position after 335. I suspect that the
three two-character blocks
<335.275> <335.276> <335.278>
are really three characters
(note the proportions of the components)
that are variants of
<380> qudugh 'good fortune' (Wu and Janhunen's <LUCK₅>).
So I think three new serial numbers are needed for those variants.
And the serial numbers 275-278 should be retired except for historical
purposes ("we used to think 275-278 were characters, but we don't
anymore"). I don't object to 275-278 being in Unicode, as there has to
be a way to discuss elements that were regarded as characters for
decades.
I initially thought that 275-278 and

<448> (function unknown)
formed a graphic family sharing 厶 on top, but now I don't think 275-278 are independent characters. 448 seems to be isolated within the Khitan small script character inventory unless it turns out to be a variant of a character without 厶 on top.
(On to Part 3)
19.11.25.18:55:
THE QUDUGH QUESTION (PART 1)
Today I was copying line 11 of the Khitan small script epitaph for
Liao dynasty Empress 宣懿 Xuanyi (1040-1075) which contains the word qudugh-er
'good.fortune-ACC'. In 契丹小字研究 Qidan xiaozi yanjiu (Research on the
Khitan Small Script, 1985), the word appears as a block of three
characters
<335.277.341>
However, looking at the
actual inscription at Wikipedia, I see that the character looks
like this:
Can you spot the difference?
It's the proportions of the two elements
in the top half of the block. In Qidan xiaozi yanjiu, they are roughly the same width, whereas in the actual inscription, the left element is about 60% the width of the right element. A narrow left-hand element is characteristic of many two-element Chinese characters: e.g., 福 'good fortune' in which the left side ネ is narrower than the right side 畐. To put it another way, both ネ and 畐 are narrowed in side-by-side combination, but ネ is more compressed than its neighbor. And the proportions of
qudugh
are closer to those of the single character 福 than to a
two-character sequence ネ畐.
So I see for myself now that Kane (2009: 81, 99) is right:
<335.271>
is a single logogram 380 (or 379, as he numbered it on p. 305):
<FORTUNE>
I've always thought that was a single character because of a reason
I'm surprised Kane doesn't bring up. 335 in other contexts is read ia,
and obviously qudugh doesn't begin with ia-.
Kane (2009: 99) suggests that 380 may be "derived from the cursive form of the Chinese character 福 fu 'good fortune, happiness'." The site cidianwang.com (词典网 Dictionary Net) has 23 samples of 福 in cursive. If Kane is also correct about his derivation of 380 (and I think he is), 380 is a rare Khitan small script character that not only mimics the shape of a Chinese character but also represents a Khitan word (qudugh) with a meaning similar to that of the word represented by that Chinese character (Liao Chinese fuʔ; modern standard Mandarin has lost the glottal stop). Usually Khitan small script characters with Chinese lookalikes have functions completely different from those of their apparent graphic models: e.g.,
| shape | Khitan small script |
Liao Chinese |
||
| reading |
meaning |
reading |
meaning |
|
| 一 |
? |
above/north |
*iʔ |
one |
| 丁 |
? |
twenty |
*tiŋ |
fourth Heavenly Stem |
| 丙 |
iu |
(none; phonogram) |
*piŋ |
third Heavenly Stem |
| 力 |
na |
*liʔ |
strength |
|
| 火 |
ud |
*xwo |
fire |
|
Neither
335 nor 277
looks exactly like any Chinese characters. And even if they did, their functions could not be guessed on the basis of their hypothetical Chinese lookalikes.
I have no idea why 335 has the reading ia, and I have no idea what the reading of 277 is. I have no time either, so I'll have to look into 277 ... another time.
(On to Part 2)
19.11.24.23:27: WHAT IS THE RELATIONSHIP BETWEEN THE KHITAN SMALL SCRIPT AND THE JURCHEN LARGE SCRIPT? (PART 3: THE LOYALTY PRINCIPLE IN JURCHEN)
The blocks of Jurchen characters resembling Khitan small script blocks in 弇州山人四部稿 Yanzhou shanren sibu gao (Draft [Catalog of] the Four Categories of Yanzhou Shanren['s Library]; 16th c.) and 方氏墨譜 Fang shi mopu (Mr. Fang's Ink [Cake] Book, 1588) exemplify an extreme version of the loyalty principle from part 2: each block is a translation or borrowing of a Chinese monosyllabic word in Chinese word order:
| line |
language |
block 1 |
block 2 |
block 3 |
block 4 |
| 1 |
block |
 |
 |
 |
 |
| Jurchen |
genggiyen |
wan |
tiko-ci-ghun |
de |
|
| English gloss |
bright > wise |
prince |
heedful-if-? | virtue |
|
| Ming Chinese | 明 *1'miŋ |
王 *1'waŋ |
慎 *3ʂən |
德 *4tə |
|
| English gloss | bright > wise | prince |
heedful |
virtue |
|
| 2 |
block |
 |
 |
 |
 |
| Jurchen | duin |
tulile |
hiyen |
andahai |
|
| English gloss | four |
outside |
all |
guest |
|
| Ming Chinese |
四 *3sz̩ |
夷 *1'ji |
咸 *1'xjen |
賓 *1pin |
|
| English gloss | four |
foreigner |
all |
guest |
(I have slightly altered Kiyose's reading of the Jurchen.)
The first line would have object-verb order in regular Jurchen:
'wise prince virtue heedful-if'
This special kind of Jurchen appears to be related to the highly
sinified Jurchen of Ming dynasty petitions. I hypothesize that unlike
the Japanese who read Chinese in a highly stylized Japanese that still
maintained Japanese syntax and morphology, the Jurchen read Chinese in
a highly stylized Jurchen with Chinese syntax and little morphology.
Notes on the words (the blocks will have to wait until part 4):
Line 1
1. genggiyen 'bright, wise': cf. Manchu genggiyen
'id'.
2. wang 'king, prince': a borrowing from Chinese; cf. Manchu wang. Kiyose wrote wan, probably since Jurchen only had -n (possibly [ɴ] as in Japanese) in native words, but the Bureau of Translators vocabulary transcribes this word as 王 *1'waŋ whose *-ŋ could either point to -n [ɴ] or even -ng as in Manchu. I would be more certain about wan if this word were transcribed in Chinese with a *wan character.
3. tiko-ci-ghun 'if heedful': cf. Manchu -ci 'if'. tiko-
is not cognate to Manchu yohi- 'to pay heed to', and -ghun
is a verbal suffix of unknown function without any Manchu cognate.
4. de 'virtue': a Chinese borrowing. Could this have
coexisted with or even replaced a Jurchen cognate of Manchu erdemu
'virtue'?
Line 2
1. duin 'four': cf. Manchu duin. (I dropped
Kiyose's -w- since there is no distinction between ui
and uwi in Jurchen.)
2. tulile 'outside': cf. Manchu tule 'id.' (with
haplology: i.e., loss of -li- before a similar -le?).
3. hiyen 'all': a Chinese borrowing. This word is literary
in Chinese and is probably not the normal Jurchen word for 'all'.
4. andahai 'guest': cf. Manchu antaha 'id.'
Did Ming Jurchen shift *nt to *nd? If it did, are words
like fanti 'south' and fonto 'chestnut'
(the only known cases of -nt- in the Bureau of Translators
vocabulary) loanwords?








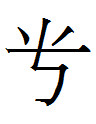






















{kind=link}