![]()
![]()
![]()
![]()
![]()
<RED ? tai siang gün>
14.11.1.23:01: GOLD I OR RED ANCESTOR?
I thank Andrew West for pointing out that the Khitan large script title from my last post
<RED ? tai siang gün>
actually corresponds to Liao Chinese 金吾大將軍 *kim ŋu taj tsiaŋ kyn, not 金五大將軍 *kim ŋu taj tsiaŋ kyn. Kane (2009) has the correct spelling 金吾 on pages 18, 42, and 99 along with its Khitan small script transcription:
<g.m ng.u>
I was wondering how Kane was able to translate 金五 as 'imperial insignia'. 金吾 - 'gold I' at first glance - also doesn't look like 'imperial insignia'. Hucker (1988: 168) wrote that the literal meaning of 金吾 was
[...] not wholly clear; probably used interchangeably from Chou into Han times with a homophonous term for prison, but traditionally interpreted as a special weapon, or a gold-tipped baton, or the image of a bird called chin-wu that was believed to frighten away evil. From Han on, commonly used in reference to imperial insignia, as in chih chin-wu (Chamberlain for the Imperial Insignia).
What was the "homophonous term for prison"? The closest term I can think of is Old Chinese 圄 Cɯ-ŋaʔ whose stressed syllable was close to 吾 *ŋa.
Andrew also reminded me that 吾 was also a Khitan small script character and noted that
<RED ngu>
corresponds to 金吾 in line 7 of the epitaph for 蕭袍魯 Xiao Paolu. This raises the question of whether <?> is a homophone of <ngu> rather than a variant of <sung> transcribing Liao Chinese 宗 *tsung 'ancestor':
=
≠
?
Also, if <RED> could do double duty for native liauqu ~ liauqú 'red' and Sino-Khitan gim 'gold', could <?> do double duty for the unknown Khitan first person pronoun 'I' as well as Sino-Khitan ngu?
14.10.31.22:31: GOLD FIVE OR RED ANCESTOR?
Having just discussed multiple readings of Tangut characters, I think it's a good time to discuss the possibility of multiple readings of Khitan large script characters.
On Monday, two titles jumped out at me when I was rereading Kane's overview of the history of Khitan large script decipherment in The Kitan Language and Script (2009):
<RED ? tai siang gün> =
Liao Chinese 金五大將軍 *kim ŋu taj tsiaŋ kyn
'senior general of the imperial insignia guard' (translation from Kane 2009: 170)
(lit. 'gold five great take* army')
<RED si chung lu tai fu giem giau tai ui> =
Liao Chinese 金紫崇祿大夫檢校太尉 *kim tsɨ tʂhuŋ luʔ taj fu kiem kiaw thaj uj
'lord of the golden seal and the purple ribbon, grand master of the court of imperial entertainments, inspector, and defender-in-chief' (translation with help from Hucker 1988)
(lit. 'gold purple lofty blessing great man inspect examine great official')
There are several odd things about these titles:
1. They seem to be transcriptions of Liao Chinese with the possible exceptions of <RED> and/or <?>. More on this point below.
2. <RED> corresponds to Liao Chinese 金 *kim 'gold'. I expected
~
<GOLD>
or some phonogram for <gim> corresponding to
<g.m>,
the small script transcription of 金.
3. Liao Chinese 五 *ŋu 'five' corresponds to
<?>
which this Khitan large script Unicode proposal regards as equivalent to
<sung> ~ <dzung> (hereafter 1190, its number in the proposal)
a transcription of Liao Chinese 宗 *tsung 'ancestor' which in turn is equivalent to the small script transcriptions
~
<sung> ~ <dzung>
Was <?> a phonogram for *ŋu that should be transliterated as <ngu>?
And was it a variant of 1190 which had at least two kinds of readings, <ngu> and <sung> ~ <dzung>? Or were <ngu> and 1190 <sung> ~ <dzung> distinct characters?
One might expect the large script character
<tau> 'five'
to correspond to its Liao Chinese lookalike and translation equivalent 五 *ŋu 'five'. But the Khitan seemed to prefer borrowing Chinese titles in toto rather than partly translating them, which is why the initial <RED> is unusual.
The Unicode proposal lists the reconstruction *kim (<gim> in my system) for
(hereafter 1651, its number in the proposal)
and glossed it as Chinese 金 'gold'. Reading the titles as
<gim ngu tai siang gün>
<gim si chung lu tai fu giem giau tai ui>
seems straightforward, but then raises the issue of why 1651 meant 'gold' in titles but 'red' in the calendrical system (see table 2.1 in Andrew West's post). Did 1651 and the Khitan color term written as
~

<l.iau.qu> ~ <l.iau.qú> (does this variation reflect grammatical gender?)
in the small script have a broad semantic range corresponding to 'red' through 'deep yellow'? Was the calendrical term for 'yellow' written as
~
<GOLD> ~ <GOLD♂>
in the small script more precisely 'pale yellow'?
Then again, the small script equivalent of 金 *kim 'gold', the Chinese name of the Jurchen state, was none other than 山 <GOLD>! What was the Khitan large script spelling of the name of the Jurchen state,
or
?
Did 1651 and its variants have two kinds of readings, one Khitan and another Sino-Khitan?
| Khitan | Large script | Small script |
| liauqu (native) |
(added last variant 11.1.22:29) |
|
| liauqú (native) | ||
| gim |
|
It is also possible that each of the large script characters above had a different reading.
John Tang suggested that the language written with the large script was not quite the same as the language written with the small script. Perhaps large script writers translated Chinese 金 'gold' in noncalendrical contexts as 'red' whereas small script writers translated it as 'gold'. However, as Andrew West pointed out,
"the Khitan scripts do not show any significant chronological variation"
"there is no obvious geographical distinction between the two scripts"
"both scripts were commonly used for exactly the same function (writing memorials for the dead)"
"both scripts are used to write memorials for both men and women"
"there are memorials to princes and princesses in both scripts, although the only memorials to emperors and empresses found so far are in the small script"
"both scripts were used to write memorials for members of the Yelü 耶律 clan"
Nearly all those factors make a linguistic (as opposed to a merely orthographic) distinction between the large and small scripts unlikely, unless scribes were led in different directions by schools that did not communicate with each other, each school accumulating idiosyncracies of their teachers without noticing what the other school was doing. That hypothesis would predict that the earliest texts in both scripts should be more similar than the last texts.
If John Tang is right, maybe the language underlying the small script was considered to be of slightly higher status which would explain why it was used in imperial memorials. On the other hand, there must be memorials we have not yet seen, and the correlation between the small script and emperors and empresses may break down following further discoveries.
My frustration brings to mind the quotation by Nishida Tatsuo at the beginning of Kane's book:
To tell you the truth, the Kitan script is becoming more and more incomprehensible. Things which we were not able to understand before we are even less able to understand now.
*I have long been puzzled by the tone of 將 in 將軍 'general'. 將 has two tones:
'level' for 'to take'
'departing' for 'to lead an army', 'general' (as a monosyllabic word and in compounds other than 將軍 'general')
One would expect 將 to have a 'departing' tone in 將軍 'general' which looks like '將 lead an 軍 army'. But in fact the 將 of 將軍 'general' has a 'level' tone. So is 將軍 'general' literally 'take[r of] an army'? Is the 'level' tone due to irregular tone sandhi (軍 'army' has a 'level' tone)? The influence of the verb-object phrase 將軍 'take army' for 'checkmate' in chess (and in a broader sense, putting someone on the spot)? Is there some obvious explanation that has eluded me for years? Is there any Chinese language in which 將 has a 'departing' tone in 將軍 'general'?
14.10.30.23:59: THE SOUND OF THE DOUBLE-SKINNED MOUTH
Last night I mentioned
=
+
4620 1ka 'how' =
left of 2247 1tu (first half of 1tu 1muʳ 'stupid'; arbitary source for the 'mouth' radical?) +
all of 1326 1kə (perfective prefix; phonetic)
as one of three Tangut transcriptions of Sanskrit ka. It also transcribed Sanskrit krā, ga, and kiṃ (Nevsky 1960 I: 574).
The title refers to its structure: 'mouth' on the left and what appears to be 1dʐə 'skin' doubled on the right. I have no idea why one would write a perfective prefix with 'skin'.
Nor do I have much of an idea of why 4620 transcribed Chinese syllables other than *ka (Li Fanwen 2008: 733):
| Tangut text | Sinograph | Middle Chinese | Tibetan transcriptions of Tang NW Chinese | Tangut period NW Chinese | Liao Chinese | Phags-pa Chinese |
| Forest of Categories | 吉 | *kit | kyir | *ki | *kiʔ | ꡂꡦꡞ gÿi [kji] |
| Forest of Categories, Sunzi | 建 | *kɨanʰ | (Used by Amoghavajra to transcribe Skt -kaṇ-, kañ-) | *kɨã | *kien | ꡂꡠꡋ gen [kɛn] |
| Forest of Categories | 蹇 | *kɨanˀ, *kɨenˀ | (Amoghavajra used a homophone 謇 to transcribe Skt -khaṇ-, -kan-) | |||
| Forest of Categories (see Nevsky 1960 II: 83) | 堅 | *ken | kyan, kyen | *kiã | ꡂꡦꡋ gÿan [kjɛn] |
Although my Tangut period NW Chinese reconstruction is based on Gong's which in turn is based on Tangut evidence, none of the readings of those characters match 1ka.
I have included Liao and Phags-pa Chinese (with Coblin 2007's transliteration and phonetic reconstructions) for reference. Neither the reconstruction of Liao Chinese nor the attested forms of Phags-pa Chinese is dependent on the reconstruction of Tangut. Both varieties were spoken to the east of northwestern Chinese, and of course Phags-pa Chinese postdates the fall of the Tangut Empire.
No single reconstruction of 4620 can account for all of its uses*:
| Source | Reconstruction | Sanskrit ka | Sanskrit krā | Sanskrit ga | Sanskrit kiṃ | Chinese *ki | Chinese *kia-type syllables |
| Nishida 1966 | 1kǐɑ | partial match | full match except for nasality | ||||
| Sofronov 1968 Li Fanwen 1986 This site now |
1ka | full match | partial match | weak match | partial match | ||
| Arakawa 1997 (Nishida-style) | 1kaɦ | partial match | weak match | partial match | |||
| Gong Hwang-cherng 1997 | 1kja | partial match | full match except for nasality | ||||
| This site 2008-2014 | 1kia | partial match | full match except for nasality | ||||
| Kotaka 2012 (Arakawa-style) | 1ka: | full match except for vowel length | partial match | weak match | partial match | ||
How do I explain those mismatches?
1. Tangut knowledge of Sanskrit was probably limited, so some inaccuracy was inevitable.
1a. Tangut probably did not have contrastive vowel length (contra Arakawa and Gong) which explains why transcription characters such as 4620 did double duty for short and long-vowel syllables.
1b. Tangut had no Cr-consonant clusters. Sanskrit kr could be misheard as k.
1c. If Tangut g was prenasalized [ŋg], then Tangut k could have been an acceptable approximation of Sanskrit g.
2. Educated Tangut were well versed in Chinese. Hence it is inconceivable that they repeatedly made glaring errors in transcription.
2a. Tangraphs may have had multiple readings, and the lexicographical tradition only listed basic readings unless the readings were very different from each other: e.g.,
4456 2tha / 4457 2lẹ 'big' (the tangraph is listed twice in Li Fanwen 2008)
Readers could supply nonbasic readings from context. Nonbasic readings of 4620 may have been closer to Chinese *ki and *kia.
2b. The readings of tangraphs underlying transcriptions may have been from nonstandard dialects: e.g., a dialect in which *kia had not simplified to ka or a dialect in which *kia had simplified to ki. The situation may have been comparable to the use of non-Mandarin-based transcriptions in written Mandarin today.
2c. The readings of the sinographs being transcribed may have been colloquial forms that were irregular from the viewpoint of the Chinese lexicographical tradition: e.g., 吉 may have had a reading like *ka (cf. Sino-Vietnamese cát [kaːt] instead of the expected regular *cất [kət] or *kia in addition to *ki. I cannot explain the *a of my speculative *ka. (Is SV cát the product of taboo deformation?) *ia may have been conditioned by a low-vowel prefix:
Standard reading: *klit > *kit > *kir >*ki
Alternate reading: *Cʌ-klit > *Cʌ-kleit > *ket > *kiet > *kier > *kia?
(That in fact is the evolution of 結 which was transcribed in Tangut by 2219 1ke which was also the transcription character for Sanskrit ke.)
Amoghavajra's transcriptions with 建 and 謇 (a homophone of 蹇) may suggest that they had alternate *kan-like readings in eighth century northwestern Chinese, though it is more likely that he used *kɨan-type characters because *kan was *[qɑn] with an un-Sanskrit uvular initial whereas *kɨan was *[kɨan] with a velar initial.
10.31.0:45: The problem with 2c is that it is unlikely that colloquial readings would be used to pronounce the Classical Chinese texts translated by the Tangut. And surely Tangut who could not only speak colloquial Chinese but also read Classical Chinese would know better than to mix informal and formal pronunciations of words. Then again, the line between colloquial and literary is not absolute: e.g.,
However, some dialects of Hokkien, such as Penang Hokkien as well as Philippine Hokkien (Lan-lang-oe) overwhelmingly favor colloquial readings. For example, in both Penang Hokkien and Philippine Hokkien, the characters for 'university,' 大學, are pronounced toā-ȯh (colloquial readings for both characters), instead of the literary reading tāi-hȧk, which is common in Taiwanese and Mainland Chinese [Hokkien] dialects.
10.31.0:49: Grinstead's dictionary (1972: 144) defined 4620 as 'Skt. ke' but I think ke may be a typo for ka. His table of dhāraṇī transcription tangraphs on p. 184 does not list 4620 as ke, his list of Tangut phonetics on p. 190 equates 4620 with ka, and no other scholar has ever equated 4620 with Sanskrit ke.
14.10.29.22:59: TANGUT GRADE III -A('): RHYMES 19 AND 21 (PART 2)
I started what was meant to be a series almost three weeks ago. Then I got caught up correcting my own mistakes - the ones I noticed, that is: a wrong rhyme and a wrong fanqie speller. (There must be even more errors in my Tangut reconstruction that I haven't even noticed yet!). I thank David Boxenhorn for reminding me of my plans to write about Tangut 'apostrophe' rhymes like 21 -ɨa'.
I got the apostrophe notation from Arakawa Shintarō. He uses apostrophes to indicate glottal stops in initial position, so maybe they indicate final glottal stops in his reconstruction. I, on the other hand, use apostrophes simply to mean 'different in some unknown way'.
In the Tangraphic Sea, nonapostrophe rhymes are followed by similar apostrophe rhymes in the first group of rhymes (1-60). Apostrophes and tenseness are always mutually exclusive, and apostrophes and nasality are almost mutually exclusive. Their coexistence in 59-60 should be investigated. There are also some anomalous combinations of nasality with tenseness (65 and 76) and retroflexion (97-98). I am fairly confident about the classification of rhymes up to 60; later rhymes, particularly 97 and up, are iffy, and others interpret them very differently (e.g., Arakawa only has two retroflex apostrophe rhymes: 88-89). The ordering pattern breaks down after 62: e.g., 63 is an e-type rhyme rather than an i-type rhyme. 104 and 105 look like last-minute additions.
| Rhyme type | Plain rhymes | Tense rhymes | Retroflex rhymes | ||||
| Nonapostrophe | Apostrophe | Nasal | Nonapostrophe | Apostrophe | Nasal | ||
| u | 1-4 | 5-7 | 104 | 61-62 | 80-81 | (none) | (none) |
| i | 8-11 | 12-14 | 15-16 | 68-70 | 82-84 | 99, 101 | |
| a | 17-20, 105 | 21-24 | 25-27 | 66-67 | 85-87 | 88-89 | |
| ə | 28-31 | 32-33 | (none) | 71-72 | 90-92 | 100 | |
| e | 34-37 | 38-40 | 41-43 | 63-64 | 77-79 | (none) | |
| 65, 76 (!) | |||||||
| ew | 44-47 | 48-49 | (none) | 93-94 | |||
| o | 50-53 | 54-55 | 56-58 | 73-75 | 95-96 | 102-103 | 97-98 (!) |
| 59-60 (!) | |||||||
I do not rule out the possibility of a reinterpretation of the later rhymes in the future. For now, let's focus on 19 and 21.
In my reconstruction, both 19 and 21 are Grade III rhymes, so in theory they should have Grade III initials (in green). The reality is messer. Unexpected initial types are in pink, and initial types with minimal pairs are in red.
| Grade | Initial | Labial | v- | Dental | Velar | Alveolar | Retroflex | Glottal | l- | Other laterals |
| III | 19 -ɨa | X | ✓ | X | k-! | ts-! | ✓ | h-, ɦ-! | ✓ | X |
| IV | 20 -a | ✓ | X | ✓ | ✓ | ✓ | X | ✓ | l-! | ✓ |
| III | 21 -ɨa' | X | ✓ | d-, n-! | k-, kh-! | X | ✓ | ʔ-, ɦ-! | ✓ | X |
| IV | 24 -a' | ✓ | X | ✓ | ✓ | ✓ | X | X | X | ✓ |
I used to follow Gong and write glottal fricatives as if they were velar, but I thought it was odd to have x- and ɣ- under "Glottal", so I now follow Arakawa and write the voiceless fricative as h-. By analogy I write its voiced counterpart (absent in Arakawa's reconstruction) as ɦ-.
There are no labial or lateral fricative (ɬ- ɮ-) initials which were generally somehow incompatible with Grade III. The absence of lateral fricatives is due to a larger constraint against alveolar fricatives in Grade III (but see below!).
Arakawa reconstructed Grade III as vowel length and reconstructed 21 as the only Grade IV rhyme in his system with both vowel length and medial -y-. But I don't understand why those features would be incompatible with labials. If pya and pa: were possible (Arakawa 1997: 128), why not *pya:?
| Rhyme | Arakawa | This site | Labial |
| 17 | -a | -ɑ | ✓ |
| 18 | -ya | -ɤa | ✓ |
| 19 | -a: | -ɨa | X |
| 20 | -a | ✓ | |
| 21 | -ya: | -ɨa' | X |
| 22 | -a' | -ɑ' | ✓ |
| 23 | -ya' | -ɤa' | ✓ |
| 24 | -a:' | -a' | ✓ |
In my reconstruction, labials are rarely followed by Grade III -ɨ-.
Let's look at all the anomalies and see if they can be explained (or at least have notable features):
| Rhyme | Li Fanwen 2008 number | Tangraph | Reading | Gloss | Notes |
| 19 | 5758 | 1kwɨa | bent, winding, crooked (only in dictionaries) | No Grade IV rhyme 20 *kwa; regular reflex of pre-Tangut *Cɯ-kwa or *Pɯ-ka? | |
| 3408 | 1tsɨa | to broil, roast (only in dictionaries); cognate to Grade IV rhyme 20 1tsa 'hot' | Why isn't this Grade IV rhyme 20 1tsa? Minimal pair with Grade IV rhyme 20 1tsa |
||
| 1644 | 1hɨa | first half of 1hɨa 1ʂɤe 'to condemn' (only in dictionaries) | No Grade IV rhyme 20 *ha; regular reflex of pre-Tangut *Cɯ-ha? | ||
| 2521 | fast, rapid | ||||
| 3005 | 2ɦɨa | second half of 1dzəʳ 2ɦɨa 'fast, rapid'; cognate to 2521 with voiced initial conditioned by lost prefix and second tone conditioned by suffix *-H | No Grade IV rhyme 20 *ɦa; regular reflex of pre-Tangut *Cɯ-Ka (with lenition of intervocalic *-K-)? | ||
| 3008 | cover, lid, to cover; borrowing from Late Middle Chinese 盒 *xɑ(p) 'box' or some related word with voiced initial and vowel bending conditioned by high-vowel prefix? | ||||
| 3401 | umbrella of a carriage (specialized usage of 3008 above) | ||||
| 20 | 0259 | 1lwa | to make a detailed inquiry | No Grade III rhyme 19 *lwɨa; regular reflex of pre-Tangut *Cɯ-lwa or *Pɯ-la? | |
| 1289 | second half of 1bạ 1lwa 'lower limbs, legs' | ||||
| 21 | 2936 | 1dɨa' | second half of 1ti 1dɨa' 'to drip' (only in dictionaries); < Tangut period northwestern Chinese 滴答 *ti tɑ (but final vowels don't match - did front vowel of 1ti condition breaking of an earlier *ɑ in the following syllable?) | Minimal pair with Grade IV rhyme 24 1da' for transcribing Sanskrit ḍa | |
| 0176 | 1nɨa' | black | No Grade IV rhyme 24 *na'; regular reflex of pre-Tangut *Cɯ-naX? | ||
| 1997 | deep | ||||
| 1943 | 2nɨa' | to not be | |||
| 2015 | dung, excrement | ||||
| 2519 | wisdom | ||||
| 3296 | second half of 2mə 2nɨa' 'Tangut'; Tibetan minyag 'Tangut' may reflect an earlier or nonstandard form; may be derived from 0176 'black' plus a suffix *-H conditioning the second tone | ||||
| 3948 | 1kɨa' | transcription of Sanskrit ka and kā | No Grade IV rhyme 24 *ka'; regular reflex of pre-Tangut *Cɯ-kaX (except for transcription character, of course)? | ||
| 3985 | foundation, basis, burden; transcription of Sanskrit ka and kā | ||||
| 4127 | pedestal, plinth (same word as 3985 above) | ||||
| 4823 | 1khɨa' | transcription of Sanskrit kha | No Grade IV rhyme 24 *kha' | ||
| 1718 | 1ʔɨa' | yes | No Grade IV rhyme 24 *ʔ(j)a'; regular reflex of pre-Tangut *Cɯ-ʔaX? | ||
| 2822 | 2ʔɨa' | horn (only in dictionaries) | |||
| 4611 | second half of 2vɪ 2ʔɨa' 'singing' (with 2vɪ 'to sing'; both halves only in dictionaries) | ||||
| 5322 | gold (less common synonym of 1kɤẹ) |
Six anomalies in Gong's reconstruction (3456, 3502, 5584, 5763 in rhyme 20 and 0357, 0837 in rhyme 24) are not listed because they are no longer anomalies if they are reconstructed with ld- (following Tai 2008) instead of l-. ld- may have been a lateral affricate with the same pattern of distribution as the lateral fricatives ɬ- and ɮ-: i.e., in Grades I, II, and IV but not III.
Out of the remaining twenty-four anomalies, only two have corresponding Grade IV syllables (3408 and 2936). Those minimal pairs force me to reconstruct 19 and 20 differently (unlike Arakawa and Gong who seem to reconstruct them as homophones*).
All others are in complementary distribution, albeit not in the ideal pattern of complementary distribution. Did the Tangut dictionary tradition reflect a mixture of dialects with different sound changes: e.g.,
- in dialect A, *Cɯ-tsa became Grade III rhyme 19 1tsɨa
- in dialect B, *Cɯ-tsa became Grade IV rhyme 20 1tsa
and the dialect A form was chosen to be the standard form for 'to broil' while the dialect B form was chosen to be the standard form for 'hot'. I would rather not reconstruct different prefixes to account for the different vocalism of 'to broil' and 'hot' which probably share the same root *tsa.
Only two of the anomalies (3948 and 4823) are characters created for transcribing Sanskrit, and one of them (3948) is homophonous with a native word (3985). Why were Sanskrit ka, kā, and kha transcribed with the Tangut rhyme -ɨa' containing -ɨ- and the mysterious apostrophe feature absent from Sanskrit? (No Tangut transcription of Sanskrit khā is known.) Was that practice influenced by the Chinese transcriptions 迦 *kɨa and 佉 *khɨa for those syllables? (In earlier Chinese, *k(h)a was [q(ʰ)ɑ] with an un-Sanskrit uvular, so velar-initial sylalbles with medial *-ɨ- were regarded as closer matches.) The Tangut transcription of Sanskrit ka as
4620 1ka
without -ɨ- may reflect Sanskrit filtered through Tibetan or even Sanskrit itself. Are transcriptions with 4620 closer to (Tibetanized) Sanskrit? Conversely, are transcriptions with
3948 1kɨa', 3985 1kɨa', and 4823 1khɨa'
based on Sinified Sanskrit? Or were those two types of transcriptive characters randomly mixed up?
*Although both 19 and 20 are -a: in Arakawa's notation, Arakawa's (1997: 128) table appears to list two subtypes of each of those rhymes (not including subtypes with -w-).
14.10.28.23:42: 'CROSSED NINE' IN THE KHITAN SMALL SCRIPT
Today I was looking at the Khitan small script fish tally in Bushell (1897: 18) which ends with character 089 resembling Chinese 九 with a bar across it:
Kane (2009: 45) wrote,
Aisin Gioro 2004: 51 notes that the title for a [Khitan] lady of high rank, 別胥 biexu [in modern standard Mandarin pronunciation] was normally written
~
<b.ɥ.dz.ü> ~ <p.ɥ.dz.ü>
but in Gu [i.e., 故耶律氏銘石 Gu Yelü shi mingshi, the epitaph of Mme. Yelü, 1115] it is written
The evidence for the pronunciation of 089 points in contradictory directions:
<p.ɥ.089.ü>
suggesting that [089] is similar to [258] <dz>. [089] is only found in [native] Kitan words. In the rhymed sections of the Xingzong inscription, [089] rhymes with [131] <u>.
1. 別胥 was something like *pje(ʔ)sy in Liao Chinese.
2. 089 was interchangeable with 258 <dz> (used for Chinese unaspirated *ts)
3. 089 may have fused with 289 <ü> to represent a syllable [Cy].
4. 089 rhymed with <u>.
I think 089 might have been <su> or <sy>:
1'. The Chinese transcription 胥 *sy suggests [s].
2'. Although 258 <dz> was created to transcribe Chinese *ts, an affricate absent from Khitan, the Khitan often spelled that foreign consonant with 244 <s>. Perhaps even those who spelled Chinese loanwords with 258 <dz> may have pronounced them with [s]. So interchangeability with 258 <dz> may indicate either [dz] or [s].
3'. Maybe there was a rule of assimilation: <su.ü> > [sy(ː)] or <ɥ.us> > [y(ː)s] (if <su> had an alternate reading [us] after consonant characters; 082 <ɥ> is usually a semivowel, though perhaps it was [ø] in the title transcribed as 別胥)
4'. It is simplest to assume that 089 ended in [u] if it rhymed with <u> [u], though the possibility of the rhyming of similar vowels ([y] and [u]) cannot be ruled out.
The Chinese loanword data in Kane (2009) lacks the syllables *su and *sy. Would such syllables have been transcribed as 089?
If 089 had an alternate reading [us], how would it have differed from
~
068 and 103 <us>?
Are there any instances of 089 alternating with those characters?
I also considered the possibility that the alternation between <089.ü> and <dz.ü> might have indicated a reading like [dʑu] or [dʑy] for 089, but if 089 were <ju>, it would be homophonous withs
~
~
147 ~ 148 ~ 149 <ju>
and therefore redundant. And there are no known cases of Liao Chinese *tɕy transcribed as 089. (The Khitan consonants written as voiced obstruents corresponded to Chinese voiceless unaspirated obstruents.)
(10.29.0:29: The modern standard Mandarin pronunciation of 九 'nine' as [tɕjow] is not evidence for pronouncing 089 as [dʑu] or [dʑy]. In Liao Chinese, 九 was *kiw, and the Khitan borrowed it as
<g.iu>
with a velar stop, not a palatal affricate.)
089 appears at the end of
~
<284.089> which "must refer to the emperor, the throne, or affairs of state" (Kane 2009: 69): i.e., 'imperial'
Are there any continental 'Altaic' terms for rulers ending in something like -su or -us? The first word that comes to mind is Mongolian ulus 'people, nation' which has already been proposed as a potential cognate of
<xu.177> (see the discussion of this mysterious word in Kane 2009: 162-165)
Could <284.089> have meant 'national'?
The vertically stacked variant of <284.089> is from the fish tally. (The handwritten copy of the fish tally on p. 623 of Qidan xiaozi yanjiu has the regular horizontal combination.) The significance of vertical stacks, if any, is unknown. Back in May I started to collect vertical stacks for a future post, but I never finished.
14.10.28.15:14: LOST WORD FAMILIES
Today I read Stephen Wootton Bushell's account of the end of the Tangut Empire. I looked through Li Fanwen's (2008) Tangut dictionary to translate 亡國 'lost country' and found six equivalents of 亡 'to be lost, die':
1. 0316 1xwɤa 'to lack, die, kill'
2. 0788 2me (second half of 1sə 2me 'death'; the first half is 'to die')
3. 1508 1bɛ 'to lose, fail'
4. 1839 1ɬø 'to lose, fail'
5. 2194 1me 'to not exist, not have'
6. 4007 1phɑ 'to damage, lose'
The m-words belong to an m-family of Tangut negatives related to *m-negatives in Old Chinese (e.g, 亡 *Cɯ-maŋ 'to be lost') and elsewhere in Sino-Tibetan. Only two (1918 and 2376) contain 'not' (Nishida radical 041):
0788 2me < *CE-ma-H or *Cɯ-ma-j-H
This bound morpheme is homophonous with 1064 'not yet', but may have a different pre-Tangut origin because 1064 precedes rather than follows the verb 'to die', and 'not yet die' for 'death' makes no sense.
0944 1mʌ̣ < *Sʌ-mə 'not'
1064 2me < *CE-ma-H or *Cɯ-ma-j-H 'not yet'
1918 1mi < *CI-ma 'not' (the most general negator)
2194 1me < *CE-ma or *Cɯ-ma-j 'to not exist, not have'
2376 2mẹ < *SE-ma-H or *Sɯ-ma-j-H 'nothing, not'
5643 1mə < *mə 'not' (for auxiliary verbs)
I have been tempted to include 1943 2nɨa' 'not' (before 'be') in that list, but I cannot prove that n- is from *mj-. Nor can I explain why an *m-family word would have a medial *-j-. My pre-Tangut reconstruction has no *-j-infix.
If 0316 1xwɤa 'to lack, die, kill' is from *P-xra, it might be related to the first syllable of
3913 4862 1xɤə 2lɨa' < *xrə (Cɯ-)laXH 'to leave' (only in dictionaries).
4862 (also written 4951 ![]() ) is
'frontier, border' by itself, but it would be odd to have a noun in
second position if 3913 4862 was a verb-noun sequence. Is 3913 a prefix
that derived a verb out of a noun? Or is 4862 a phonetic symbol for a
syllable unrelated to 'border' in 3913 4862? Could 3913 4862 be a
sequence of verbs: e.g., 'vacate leave'? Then the second half of 3913
4862 might be related to a lateral-initial family of 'loss' words
) is
'frontier, border' by itself, but it would be odd to have a noun in
second position if 3913 4862 was a verb-noun sequence. Is 3913 a prefix
that derived a verb out of a noun? Or is 4862 a phonetic symbol for a
syllable unrelated to 'border' in 3913 4862? Could 3913 4862 be a
sequence of verbs: e.g., 'vacate leave'? Then the second half of 3913
4862 might be related to a lateral-initial family of 'loss' words
1068 1lɨə < *lə 'to fall, sink'
1839 1ɬø < *Kɯ-lo < *-əw < *-ə-k? 'to lose, fail'
3545 1ɬəʳ' < *R-K-lə 'to lose, fall'
related to Old Chinese 失 *l̥it 'to lose'.
Li Fanwen (2008: 252) regarded 1508 1bɛ (Grade I rhyme 34) as a loan from Chinese 敗 'to lose', but the two may be unrelated lookalikes, as I would expect Middle Chinese 敗 *bɤajʰ (Grade II) to correspond to Tangut *bɤe (Grade II rhyme 35). Gong (2002: 421) regarded 1508 as an irregular loan. See Gong (2002: 421) for examples of the regular correspondence between Middle Chinese *-ɤaj (his *-aj) and Tangut Grade II rhyme 35 in loanwords.
Li Fanwen (2008: 643) translated 4007 1phɑ 'to damage, lose' as Chinese 破 'to break, smash'. I agree with Gong (2002: 417) who regarded 4007 as a loan from Middle Chinese 破 *phɑ.
14.10.27.23:21: THE GOLDEN GUIDE: LINE 102: TANGRAPHS 506-510
102. Translating lists of Chinese surnames in tangraphy is relatively easy, but not as interesting as translating coherent text. No wonder I haven't been motivated to translate the Golden Guide since I got stuck in the surname section in 2010. If only I had more patience. The last surname is just four lines away!
| Tangraph number | 506 | 507 | 508 | 509 | 510 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 4579 | 2736 | 4807 | 2177 | 2476 |
| My reconstructed pronunciation | 2l ɨu |
2bɤa' | 1khi | 1pʌ | 1xwɤa |
| Tangraph gloss | the surname element Lu | the surname element Ba | to lose (< Chn 棄 *khi) | big | flower (< Chn 華 *xwɤa) |
| Word | the surname 呂 Lü (*lɨu) | the surname 馬 Ma (*mbɤa) | the surname 杞 Qi (*khɨi) or 祁 Qi (*khɨi) | the surname 不 Bu (*pʌ) | the surname 華 Hua (*xwɤa) |
| Translation | Lü, Ma, Qi, Bu, Hua | ||||
506: The analysis of 4579 is unknown, but its structure is obviously inspired by its Chinese soundalike 呂 (also 吕) which looks like a stack of two 口 mouths. (It is actually a drawing of the spine.) The left side of 4579 consists of two Tangut
mouth radicals. The right side
has no known independent function and could be from 547 (!) other tangraphs. Some radicals can stand alone while others require it as an apparent filler: e.g.,
0764 1reʳ 'horse' (with a radical derived from Chinese 馬 'horse' on the left)
which brings us to the next tangraph.
507: The analysis of 2736 is also unknown, but it is obviously related to 0764 'horse' (above).
+

2736 2bɤa' sounds like Chinese 馬 *mbɤa 'horse', the translation equivalent of 0764 1reʳ. The mysterious phonetic feature that I write as an apostrophe must not have made 2bɤa' sound too different from Chinese *mbɤa. (Tangut b- might have been prenasalized [mb].)
It would be nice if the top left radical of 2736 were a diacritic indicating that a tangraph was to be read like its Chinese translation. However, I doubt that is the case. I don't have time to investigate all 42 tangraphs with that radical on the left at the moment, so for now I'll pick one at random which may not be representative:
2314 2ʔɨu 'death' (only in dictionaries?; analysis unknown)
does not sound like any Chinese word for 'death', and subtracting its left-hand radical results in
=
+

5156 1vɑ (name and transcription character; see 369) =
left of 5489 2ryʳ (surname element rur)
right of 1925 2bɨu (surname element -bu)
which has nothing to do with death and doesn't even sound like 2ʔɨu. I presume that a va-family had something to do with families whose names contained the syllables rur and bu.
Miscellaneous Tangraphs (27.7.11-12, #837) lists these last two Chinese surnames in the opposite order:
2736 2bɤa' 'Ma' and 4579 2lɨu 'Lü'
508: The other three tangraphs have surviving analyses; ironically one of them is 'to lose':
+
4807 1khi 'to lose' =
top of 4910 2ve (second half of 1ʂwo 2ve 'to clear away, clean up'; semantic) +
all of 3545 1ɬəʳ' 'to lose, fall' (cognate to Old Chinese 失 *l̥it 'to lose'?; semantic)
3545 has a circular analysis:
=
+
3545 1ɬəʳ' 'to lose, fall' =
bottom left of 1068 1lɨə 'to fall, sink' (cognate to 3545?; semantic) +
bottom right of 4807 1khi 'to lose' (semantic)
3545 looks like a semantic compound of 'die' (Nishida's radical 045) and 'hand':
+
509: 2177 is a semantophonetic compound:
+
2177 1pʌ 'big' =
left of 2892 2khwɛ 'big' (< Chn 魁 *khwɛ) (semantic)
all of 2306 1pʌ (second half of 2tsoʳ 1pʌ 'small colt') (phonetic)
2306 has a dubious circular analysis:
=

2306 1pʌ =
center of 2177 1pʌ (phonetic) +
right of 2132 2ʔjew 'achievement' (why?)
The analysis of 2132 also leads back to 2177:
+
2132 2ʔjew =
2477 2thọ (second half of 1dza 2thọ 'to grow up'; semantic)+
2177 1pʌ 'big' (semantic)
I think 2306 came first, followed by 2177 and then 2132.
510: I'm not surprised the tangraph for the loanword for 'flower' is derived from the tangraph for the native word, but what is 'head' doing?
+
2476 1xwɤa 'flower' (< Chn 華 *xwɤa) =
left and center of 2750 1ɣɤu 'head' (why?) +
right of 2467 1vạ 'flower' (semantic)
2467 1vạ superficially resembles Old Chinese 華 *wra, the source of *xwɤa, but it goes back to *Sɯ-wa which has no *-r-. If the medial *-r- of OC *wra is a metathesized prefix -
*T-wa > *r-wa > *wra
- then perhaps the Chinese and Tangut words for 'flower' are related. But if Baxter and Sagart (2014) are right, 華 was OC *qʷʰˁra, sharing nothing in common with Tangut *Sɯ-wa other than a vowel.
14.10.26.18:52: THE GOLDEN GUIDE: LINE 101: TANGRAPHS 501-505
101. I couldn't resist the opportunity to try out my newest Tangut vowel reconstruction in a continuation of where I left off last year (even if doing so entailed inconsistency with my reconstructions of lines 1-100).
| Tangraph number | 501 | 502 | 503 | 504 | 505 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 4695 | 5087 | 2259 | 3951 | 2042 |
| My reconstructed pronunciation | 1giw' | 1ʔjø̃ | 2mɤe | 1thu | 2kɤa |
| Tangraph gloss | the name Giw | the Chinese surnames Yang and Wang | the surname element Me | to talk, speak | duck |
| Word | the surname 牛 Niu (*ŋgɨiw) | the surname 酒 Yang (*jø̃) | the surname 孟 Meng (*mɤẽ) | the surname 杜 Du (*thu) | the surname 家 Jia (*kɤa) |
| Translation | Niu, Yang, Meng, Du, Jia | ||||
501: 4695 1giw' contains 1909 1guʳ 'ox, cattle' as a 'xenophonetic' (i.e., a phonetic element chosen for the pronunciation of its translation in another language: in this case, Tangut period northwestern Chinese *ŋgɨiw 'ox'). However, 1909 is not in its Tangraphic Sea analysis:
+
4695 1giw' 'the name Giw' =
top of 4940 2ʔjə 'the surname Y' (a family associated with the Giw?) +
bottom of 4107 1giw' (first syllable of 1giw' 1kie 'a kind of plant')
Nor is 1909 in the analysis of 4107 which takes us back to 4695:
=
+
4107 1giw' (first syllable of 1giw' 1kie 'a kind of plant') =
top of 4303 1kie (second syllable of 1giw' 1kie 'a kind of plant') +
4695 1giw' 'the name Giw'
The Tangraphic Sea analysis of 1909 is dubious; surely its 'sources' are actually its derivatives:
=
+

1909 1guʳ 'ox, cattle' =
part of the bottom of 4704 2rɛʳ 'ox, elephant' (i.e.., large mammal?) +
part of the bottom of 0021 2bɨu 'ox, elephant' (synonym of 4704)
1909 is not a simple pictograph. It seems to contain 'not' (left), a Tangut derivative of 羊 'goat' (center), and a mysterious right-hand element whose function eludes me. 'Not' must be an abbreviation of some other tangraph.
Chinese 牛 *ŋgɨiw < *ŋʷəʔ and Tangut 1guʳ < *Nʌ-gur or *Tʌ-ŋgu are vaguely similar but difficult to relate. A zero grade Tangut derivative of the root *ŋʷʔ would be *2ŋu, not 1guʳ.
502: The analysis of this surname tangraph makes me wonder if there was a Yang family associated with sheep and birds.
+
+

5087 1ʔjø̃ 'Yang' =
center of 3452 2ʔje 'sheep' +
left of 2262 1dʐwɨõ 'bird' +
right of 2107 1tsɪʳ 'earth'
I am not sure it is necessary to reconstruct a glottal stop before *j-. It is odd that Tangut had ʔj- but no simple j-, and I cannot account for the ʔ- in 1ʔjaʳ < *rjat 'eight' unless it is a remnant of a prefix.
5087 also transcribed the surname 王 *wɨõ 'Wang'. Another Tangut transcription was in 412:
0403 1võ (Chinese transcription character)
503: 2259 is a straightforward semantophonetic compound:
+
2259 2mɤe (the surname element Me) =
left of 2888 'surname' (semantic) +
center and right of 1966 1mɤe 'to call, greet' (phonetic)
2259 2mɤe did not have a nasal vowel like Chinese 孟 *mɤẽ 'Meng', but perhaps the Tangut thought it was appropriate to write a Chinese surname with a tangraph for a similar-sounding syllable in indigenous surnames such as.
0493 2259 2sə 2mɤe 'Syme' and 2259 0714 2mɤe 1tʂɤew 'Mechew'.
504: 3951 is a phonosemantic compound used as a transcription of an unrelated Chinese name:
+
3951 1thu 'to talk =
left of 3949 1thu (second syllable of 2kyʳ 1thu 'skill') (phonetic) +
right of 1045 2dạ 'speech' (semantic)
505: I could guess the analysis of this tangraph even before seeing it in Li Fanwen (2008: 339):
+
2042 2kɤa 'duck' =
left of 3058 2ɮəʳ' 'water' +
right of 2262 1dʐwɨõ 'bird'
Such transparent tangraphs are rare, which is why I continue to wonder how tangraphs were learned.
14.10.26.13:16: ALBANIAN 'SALT' FROM 'GROATS'?
Two months ago I was looking up the reflexes of Proto-Indo-European *seʕl- 'salt' and was surprised to see Albanian ngjelmët 'salty'. I've long been puzzled by how *s- became gj- (part 1 / part 2). Today I found Matasović's (2012: 14) reconstruction of the stages between *s- and gj- which are like mine from two years ago:
*s- > *ś- > *ź- > gj-
But where did the n- in ngj- [ɲɟ] come from? Orel (1998: 298) reconstructed Proto-Albanian *en-salma. What is the prefix *en- doing? Is it *en 'in' which is a verbal prefix (Orel 2000: 168)? Or is it another prefix? Wiktionary has a prefix *(a)n- without any attribution.
The unrelated Albanian noun kripa < *krūpā 'salt' (Orel 1998: 197) is a loan from ... Slavic 'groats' (e.g., Russian krupa)! What is the semantic bridge between 'salt' and 'groats'?
14.10.26.9:59: UMBROUS UMBRELLA
Umbrellas have been in the news lately. The Sino-Vietnamese (SV) reading of Cantonese 遮 ze 'umbrella' (< 'to obstruct') is già with an irregular huyền 'dark' tone. In Middle Chinese (MC), 遮 was *tɕja. Normally
MC *tɕ- corresponds to SV ch- [c]
MC *-ja corresponds to SV -a
which reminds me of my recent derivation of Tangut rhyme 20 -a from *-ia
the MC 'yin level' tone corresponds to the SV ngang 'level' tone
so I would expect the SV reading of 遮 to be *cha with a ngang tone indicated by the absence of a tonal diacritic. However, the actual reading già on the surface not only has initial gi- [z] ~ [j] but also has a huyền tone implying a *voiced initial.
The initial gi- turns out to be regular.* Annamese Middle Chinese (AMC)* *tɕ- was borrowed as Old Vietnamese (OV) *c- before all rhymes other than *-ja. (See further exceptions here.**) Both *k- and *c- voiced before *-j- in Old Vietnamese, merging into Middle Vietnamese (MV) [ɟ] and leniting to [z] or [j] in New Vietnamese (NV):
OV *kj- > *gj- > MV [ɟ] > NV [z] ~ [j]
OV *cj- > *ɟj- > MV [ɟ] > NV [z] ~ [j]
The spelling gi- reflects a *ɟ-like pronunciation in 17th century Middle Vietnamese.
The voicing implied by Vietnamese tones reflects primary rather than secondary voicing: e.g.,
加 MC *kæ > AMC *kja > OV *kja > *gja > SV gia 'to add'
加 has a ngang tone reflecting its original *voiceless initial and not its secondary *voiced initial gj-.伽 MC *gɨa > AMC *kjà > OV *kjà > *gjà > SV già 'transcription of Indic ga'
Similarly, the huyền tone of 伽 reflects its original *g- rather than the new *g- that developed in OV.
I wondered if MC *tɕj- had become AMC *dʑj- with 'yang' tones, but MC *tɕj- non-'level' tone syllables have SV tones implying *voiceless initials:
者 MC *tɕjaˀ with 'rising' tone > AMC *tɕjả > OV *cjả > *ɟjả > SV giả (not SV *giã) 'nominalizer'
蔗 MC *tɕjaʰ with 'departing' tone > AMC *tɕjá > OV *cjá > *ɟjá > SV giá (not SV *giạ) 'sugar cane'
If *tɕj- became AMC *dʑj- only in 'level' syllables, what would be the phonetic motivation for such a limited change? Why would 'oblique' (i.e., non-'level') tones be anti-voicing?
Original MC *dʑj- and MC *ʑj- apparently merged into AMC *tɕʰ- with 'yang' tones***: e.g.,
社 MC *dʑjaˀ > AMC *tɕʰjã > > OV *cʰjã > MV [ɕã] > SV xã 'altar for the god of the soil'
蛇 MC *ʑjaˀ > AMC *tɕʰjà > > OV *cʰjà > MV [ɕà] > SV xà 'snake'
cf. 車 MC *tɕʰja > AMC *tɕʰja > OV *cʰja > MV [ɕa] > SV xa 'cart' with an original *voiceless initial and ngang tone (i.e., a 'yin' tone)
The aspiration of OV *cʰ- might have blocked voicing before *-j-. Conversely, *-j- could have become voiceless after *cʰ-: *cʰj- > *cʰj̊-.
MC *dʑj- and MC *ʑj- merged into AMC *ɕ- with 'yang' tones when not followed by *-j-: e.g.,
臣 MC *dʑjin > AMC *ɕə̀n > > OV *sʰə̀n > MV [tʰə̀n] > SV thần 'minister'
神 MC *ʑjin > AMC *ɕə̀n > > OV *sʰə̀n > MV [tʰə̀n] > SV thần 'god'
cf. 申 MC *ɕin > AMC *ɕən > OV *sʰən > MV [tʰən] > SV thân 'ninth Earthly Branch' with an original *voiceless initial and ngang tone (i.e., a 'yin' tone)
Summing up the history of shibilants in SV (with some more details):
| MC | AMC | OV | MV | NV | Example |
| *kɤ- > *kɣ- > *kɰ- | *kj- | *kj- > *gj- | [ɟ] | gi- | 加 |
| *tɕj- | *tɕj- | *cj- > *ɟj- | 遮 | ||
| *tɕʰj- | *tɕʰj- | *cʰj- | [ɕ] | x- | 車 |
| *dʑj- | 社 | ||||
| *ʑj- | 蛇 | ||||
| *ɕj- | 奢 | ||||
| *tɕ- | *tɕ- | *c- | [c] | ch- | 眞 |
| *tɕʰ- | *tɕʰ- | *cʰ- | [ɕ] | x- | 瞋 |
| *dʑ- | *ɕ- | *sʰ- | [tʰ] | th- | 臣 |
| *ʑ- | 神 | ||||
| *ɕ- | 申 |
I can't explain why there was a four-way merger of MC *tɕʰj-, *dʑj-, *ʑj-, and *ɕj- but only a three-way merger of MC *dʑ-, *ʑ-, and *ɕ-. Was there a three-way merger of *Cj-clusters in AMC and OV parallel to the other three-way merger?
| MC | AMC | OV | MV | NV | Example |
| *tɕʰj- | *tɕʰj- | *cʰj- | [ɕ] | x- | 車 |
| *dʑj- | *ɕj- | *sʰj- | 社 | ||
| *ʑj- | 蛇 | ||||
| *ɕj- | 奢 |
I am reluctant to reconstruct aspirated fricatives in OV, but they allow me to formulate a single rule covering two changes:
OV *s(ʰ)- > MV [t(ʰ)]Reconstructing palatal fricatives in OV forces me to formulate two rules:
OV *s- > MV [t]
OV *ɕ- > MV [tʰ]
I do not know of any modern Vietic language with [ɕ]. Then again, I do not know of any modern Vietic language with [sʰ] which is of course a rare sound in the world's languages.
I could reconstruct palatal stops instead of affricates in AMC or palatal affricates instead of stops in OV, but I presume that AMC had affricates like other Chinese dialects and OV had palatal stops like modern Vietnamese. There is no guarantee that was the case: e.g., AMC could have had palatal stops due to Vietnamese influence. (One could use a term like 'Annamese' to avoid the anachronism of 'Vietnamese' as a name for the early Vietic language of Annam.)
*AMC is the dialect of Middle Chinese that developed in Annam and later became extinct after the independence of Vietnam. See Phan (2013).
I write AMC tones using Vietnamese tone marks for convenience. I would not be surprised if the phonologies of the two languages had converged.
**炙 MC *tɕjaʰ 'to roast meat' corresponds to SV chả (< *cả) and chá (< *cá) with ch- [c] instead of gi-. The tone of SV chả indicates that it is an older loan borrowed before the convention of borrowing *tɕj- as *cj-. The tone of SV chá with a tonal reflex characteristic of newer loans may indicate that tonal borrowing patterns changed shortly before the convention of borrowing *tɕj- as *cj- with a *-j- that later conditioned the voicing of the preceding *c-.
***I am using 'yin' and 'yang' as shorthand for 'normally**** conditioned by voiceless initial' and 'normally conditioned by voiced initial'. Here are the six written***** Vietnamese tones and their 'yin/yang' status:
| 'yin' | ngang | sắc | hỏi |
| 'yang' | huyền | nặng | ngã |
The name of each tone contains its characteristic diacritic (or no diacritic in the case of unmarked ngang).
****There are 'yang' tones in Chinese in syllables with *voiceless initials: e.g., standard Mandarin 國 guó < *kwək 'country' which has a 'yang level' tone even though it originally had a 'yin entering' tone.
*****Southern Vietnamese speakers merge the ngã tone with the hỏi tone, but that is not reflected in spelling which mostly reflects Middle Vietnamese.






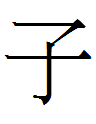


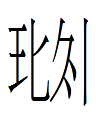
















{kind=link}