
2147 2rjuʳ 'broom'
14.11.22.23:52: BLACK AND WHITE EVIDENCE FOR VIETNAMESE PHONOLOGICAL HISTORY
Last night, I hypothesized that several unexpected letters in the Tai Viet script for Black Tai, White Tai, and Thai Song were devised to write consonants in loanwords with anomalous 'high' tones from Vietnamese:
ꪓ U+AA93 TAI VIET LETTER HIGH DO
(ꪒ U+AA92 TAI VIET LETTER LOW DO is for [d] + 'low' tones < implosive *ɗ)
ꪗ U+AA97 TAI VIET LETTER HIGH THO
(ꪖ U+AA96 TAI VIET LETTER LOW THO is for [tʰ] + 'low' tones < voiceless aspirated *th)
ꪛ U+AA9B TAI VIET LETTER HIGH BO
(ꪚ U+AA9A TAI VIET LETTER LOW BO is for [b] + 'low' tones < implosive *ɓ)
ꪟ U+AA9F TAI VIET LETTER HIGH PHO
(ꪞ U+AA96 TAI VIET LETTER LOW PHO is for [pʰ] + 'low' tones < voiceless aspirated *ph)
Tonight I found even more letters of that type:
ꪃ U+AA83 TAI VIET LETTER HIGH KHO
(does not resemble ꪂ U+AA82 TAI VIET LETTER LOW KHO for [kʰ] + 'low' tones < voiceless aspirated *kh; looks like a derivative of ꪅ U+AA85 TAI VIET LETTER HIGH KHHO presumably for White Tai* [x] < voiced *ɣ; the left side resembles HIGH PO which has no phonetic resemblance - could it be a graphic cognate of Khmer ឃ <gh>?)
ꪍ U+AA8D TAI VIET LETTER HIGH CHO
(derived from ꪌ U+AA8C TAI VIET LETTER LOW CHO for [cʰ] + 'low' tones < voiceless aspirated *ch)
ꪭ U+AAAD TAI VIET LETTER HIGH HO
(derived from ꪬ U+AAAC TAI VIET LETTER LOW HO for [h] + 'low' tones < voiceless *h)
ꪯ U+AAAF TAI VIET LETTER HIGH O
(derived from ꪮ U+AAAE TAI VIET LETTER LOW O for [ʔ] + 'low' tones < voiceless *ʔ)
I assume these letters could also be used to write native onomatopoeia and non-Vietnamese loanwords with anomalous 'high' tones.
By 'anomalous' I mean that a word has a tone not conditioned by the usual historical source(s) of its initial consonant: e.g., Black or White Tai could borrow Vietnamese thành 'to become' as, say, than 31, with a mid-low falling tone that normally developed after *voiced initials, not voiceless *th- which is the usual source of Black and White Tai th-. See these tables.
All of the above letters are for stops with the exception of HIGH HO for the fricative h followed by normally *voiced tones. It occurred to me that any Vietnamese loans with HIGH KHO, CHO, and PHO must have been borrowed before *kh *ch *ph became fricatives [x s f] in Vietnamese. In short, their stop quality dates them. (I am assuming that the Vietnamese dialects known to Black and White Tai speakers lost most aspirates like the major dialects did.) Such old loans can tell us that their tones in Vietnamese may have sounded like *voiced tones to Black and White Tai speakers at the time of borrowing. That resemblance may not have survived to the present day; Tai and/or Vietnamese might have changed its tones. Hence Vietnamese borrowings may be clues to tonal change (or its absence) in Black and White Tai and Vietnamese. There could be multiple strata of Tai borrowings from Vietnamese with different patterns of tonal correspondences: e.g.,
- suppose the Vietnamese ngang tone was once 44 (mid-high level)
- Black and White Tai speakers could borrow ngang as their tone 44
- then ngang lowered to 33 (mid level)
- Black and White Tai speakers borrowed ngang as their tone 22 (neither language has 33, so 22 is the closest match)
- so the same Vietnamese tone category (ngang) corresponds to two different tones in Black and White Tai: 44 in older loans and 22 in newer loans
Again, without any Vietnamese loan data on hand, I can't explore this idea any further.
*11.23.2:46: Is Black Tai [k] < *ɣ written etymologically with HIGH KHHO or with LOW KO as if it were from *g? I don't know what the Thai Song reflex of *ɣ is or how it is written.
14.11.21.23:54: D-OU-B-LED LETTERS IN TAI VIET
After asking about the Lao script last night, I thought it might be a good time to ask a question about the Tai Viet block of Unicode:
Are the 'extra' Tai Viet d and b letters for Vietnamese loanwords?
I downloaded an SIL Tai Viet font last December, but forgot about it until Wednesday when I needed to install a pre-Unicode SIL IPA93 Sophia font to view John Coleman's page on Shilha. I looked in my folder of SIL fonts and rediscover their Tai Heritage font. Last night while looking through its character inventory in Andrew West's BabelMap, I was surprised to see two letters for d and b:
ꪒ U+AA92 TAI VIET LETTER LOW DO
ꪓ U+AA93 TAI VIET LETTER HIGH DO
ꪚ U+AA9A TAI VIET LETTER LOW BO
ꪛ U+AA9B TAI VIET LETTER HIGH BO
Although Thai has six letters for th and three letters for ph, it has only one letter each for d and b (< Proto-Tai *ɗ and *ɓ) in native words:
| Initial type | *implosive | *voiceless aspirated | *voiced | *voiced aspirated in Indic loans (pronounced as *voiced) |
| retroflexes in Indic loans (pronounced as dentals in Thai) | ฎ <ɗ̣>*ɗ > d | ฐ <ṭh> *th > th | ฑ <ḍ> *d > th | ฒ <ḍh> *d > th |
| dental | ด <ɗ> *ɗ > d | ถ <th> *th > th | ท <d> *d > th | ธ <dh> *d > th |
| labial | บ <ɓ> *ɓ > b | ฝ <ph> *ph > ph | พ <b> *b > ph | ภ <bh> *b > ph |
(Although neither Sanskrit nor Pali had a retroflex implosive ɗ̣, some Indic ṭ correspond to d written as ฎ in Indo-Thai loans.)
Similarly, Lao has two letters for th and two letters for ph (without counterparts of the 'extra' letters in Thai for Sanskrit and Pali loanwords), but only one letter each for d and b:
| Initial type | *implosive | *voiceless aspirated | *voiced |
| dental | ດ <ɗ> *ɗ > d | ຖ <th> *th > th | ທ <d> *d > th |
| labial | ບ <ɓ> *ɓ > b | ຜ <ph> *ph > ph | ພ <b> *b > ph |
In Thai and Lao native words, d and b are associated only with tones that developed in *voiceless-initial syllables. (Proto-Tai implosives, though voiced, conditioned the same tones as *voiceless consonants in those languages.) The same is true for Black Tai and White Tai, two of the three languages written with Tai Viet (see Gedney's descriptions in Hudak 2008: 9, 12):
| Proto-Tai tone | A | B and D | C |
| 'low' tone class: *voiceless and *implosive' initial | 22 | 45 | 21 |
| 'high' tone class: *voiced initial | 55 | 44 | 31 |
| Proto-Tai tone | A | D | B | C |
| 'low' tone class: *voiceless and *implosive initial | 22 | 45 | 24 | |
| 'high' tone class: *voiced initial | 44 | 454 | 31 | |
The 'high' and 'low' tone classes in the Unicode names roughly correspond to the heights of the *voiced- and *voiceless-initial tones: all *voiced-initial tones start at 3 or higher on a 5-point scale, whereas only *voiceless-initial tones may start as low as 2.
I have no data on Thai Song, the third language written with Tai Viet, but I expect its *implosives to follow the same pattern as Black Tai and White Tai.
Hence I hypothesize that the 'extra' Tai Viet d and b letters are for borrowings of Vietnamese words with implosive initials đ- [ɗ] and b- [ɓ] and tones resembling native tones that developed in *voiced-initial syllables. Unfortunately I cannot test this hypothesis, because I have no Vietnamese borrowings in any script on hand.
11.22.4:04: The Tai Viet 'low' d and b letters are obviously related to the d and b letters of Thai and Lao.
Tai Viet ꪓ 'high' d looks like a ligature of ꪙ 'high' n and ꪒ 'low' d. I assume ꪙ high n was chosen to signify the tone class and is not a trace of earlier prenasalization: i.e., ꪓ 'high' d was never pronounced *[nd].
Tai Viet ꪛ 'high' b, on the other hand, looks like a ligature of ꪚ 'low' b and ꪝ 'high' p (< *b). Although one might think it once represented a cluster [bɓ], such a sequence is highly improbable.
Tai Viet ꪝ 'high' p in turn looks like a derivative of ꪜ 'low' p (< *p), a long-tailed derivative of ꪚ 'low' b, rather than a relative of Thai พ <b> ph < *b and Lao ພ <b> ph < *b which lack a right-hand tail.
Graphic cognates
| Tai Viet | Thai | Lao |
| ꪒ 'low' d < *ɗ | ด <ɗ> d < *ɗ | ດ <ɗ> d < *ɗ |
| ꪓ 'high' d < Vietnamese? | no equivalent; น <n> + ด <ɗ> | no equivalent; ນ <n> + ດ <ɗ> |
| ꪔ 'low' t < *t | ต <t> t < *t | ຕ <t> t < *t |
| ꪕ 'high' t < *d and ꪗ 'high' th < Vietnamese? | ท <d> th < *d | ທ <d> th < *d |
| ꪖ 'low' th < *th | ถ <th> th < *th | ຖ <th> th < *th |
| ꪚ 'low' b < *ɓ | บ <ɓ> b < *ɓ | ບ <ɓ> b < *ɓ |
| ꪛ 'high' b < Vietnamese? | no equivalent; บ <ɓ> + พ <b> | no equivalent; ບ <ɓ> + ພ <b> |
| ꪜ 'low' p < *p and ꪝ 'high' p < *b | ป <p> p < *p | ປ <p> p < *p |
| ꪞ 'low' ph < *ph | (not cognate to ผ <ph> ph < *ph) | (not cognate to ຜ <ph> ph < *ph) |
| ꪟ 'high' ph < Vietnamese? | no equivalent | no equivalent |
| ꪠ 'low' f < *f | (not cognate to ฝ <f> f < *f) | (not cognate to ຝ <f> f < *f) |
| ꪡ 'high' f < *v | (not cognate to ฟ <f> f < *v) | (not cognate to ຟ <f> f < *v) |
The last four Tai Viet letters in the table have no Thai or Lao graphic cognates.
Tai Viet ꪟ 'high' ph and ꪡ 'high' f look like derivatives of ꪝ 'high' p < *b in the Noto Sans Tai Viet font, but do not resemble 'high' p in N3220 or this Unicode chart.
I assume the 'extra' Tai Viet letters for 'high' th and ph are for Vietnamese loans with 'high' tones that would not normally follow native 'low' th.
14.11.20.23:40: 'LOST' LAO LETTERS?
I shouldn't interrupt my Churyumov-Gerasimenko series (which itself interrupted a series on Tangut rhyme 4) but I want to ask this before I forget:
Were Sanskrit and Pali loanwords ever written etymologically in premodern secular Lao writing?
Today, Sanskrit and Pali loanwords are written phonetically in Lao, whereas they are written etymologically in Thai: e.g.,
Lao ພາສາ <bāsā> phaasaa
Thai ภาษา <bhāṣā> phaasaa
from Skt bhāṣā or Pali bhāsā 'language'. In earlier Lao and Thai, the word was *baasaa; neither language ever had a *bh or *ṣ. Later, *b shifted to ph in both languages.
I count Lao <bāsā> as a 'phonetic' spelling even though the word is no longer [baːsaː] in modern Lao because <b> is always [pʰ] in modern pronunciation; it is an absolutely regular spelling without any regard for Sanskrit or Pali. (To simplify matters, I will not discuss the interaction between consonants and tones in Lao and Thai.)
Conversely, I count Thai <bhāṣā> as etymological because it retains special letters <bh> and <ṣ> for Indic sounds that never existed in Thai.
As far as I know, the usual pattern is for religiously motivated scripts to keep 'extra', etymological letters even in secular writing, unless there are later attempts to eliminate those letters in modern times: e.g.,
- Russian only lost the Greek-based letters Ѳ (< theta) and Ѵ (< upsilon) less than a century ago, and lost others (Ѯ < xi, Ѱ < psi, Ѡ < omega) a little over three centuries ago.
- Ottoman Turkish retained 'extra' letters for Arabic loans up to its demise. I know of no attempt to create equivalents in the Turkish Latin alphabet, though that would have been theoretically possible.
- Persian retains 'extra' letters for Arabic loans to this day despite proposals for reforms that would eliminate them (see Sprachman 2002: 54-77 for examples).
- Burmese and Khmer, like Thai, retain 'extra' letters for Indic loans: e.g., Burmese ဘ <bh> and Khmer ភ <bh>.
- There was a short-lived attempt to eliminate the 'extra' letters in Thai.
Lao seems to be an exception to this pattern if my understanding of Enfield (1999: 260) is correct. I used to think that Lao script had lost the 'extra' letters (e.g., this post), but according to Enfield, it apparently never had them:
When people argue on this basis for a "return to tradition" through incorporation of the remaining characters [needed for etymological spelling of Indic loans], they are in fact not arguing for restoration, but for the modern, and in many cases novel, fixture of orthographical devices in the language. The deeper historical questions regarding developments of "native" Lao/Thai orthography are complex ones, which I cannot pursue here. But it is important to understand in the present context that the standardized etymological basis of Thai orthography in its present form, being literally designed to handle faithful transcription of Pali and especially Sanskrit, does not represent something that Lao once had or, in particular, could ever "go back to."
Yet Maha Sila Viravong's Lao alphabet had most of those 'extra' letters. I once assumed they were retentions, but they weren't even resurrections: e.g., the description of his Lao <ṭ> says it is (emphasis mine)
[o]ne of the 14 additional Lao letters that were created to transcribe Pali consonants. The letters were originally created in the 1930's by Dr Maha Sila Viravong who was working for the Buddhist Academic Council which was presided over by Prince Phetsarath.
I don't think they were created ex nihilo, though. I assume the letters were derived from some variant of the tham 'dharmic' script that retained the 'extra' letters. (The forms of the 'extra' letters in the two scripts as presented on Wikipedia do not always match: e.g., Lao <jh> and tham <jh>. Are the Lao forms novel inventions or are they based on variant letter forms not in Wikipedia or my fonts?)
Putting aside whatever happened in the 1930s, would Lao - and Thai - of centuries past have spelled Indic loanwords as if they were native words: e.g., *baasaa as <bāsā>? Is Lao <bāsā> a spelling that has been unchanged since the word was first written in a secular context? On the other hand, is Thai <bhāṣā> a modern pseudoarchaism?
Although I know something about Tai historical phonology, I know nothing about Tai philology. Why is Tai spelling history not mentioned in English-language studies of Tai language history? It is not as if the Tai languages were never written until modern times. Is it because Tai linguistics is largely the domain of field workers? I fear a large body of data (especially in Zhuang which is written in a Chinese-based script) has been overlooked.
11.21.2:41: Some romanizations of Lao names indicate knowledge of Indic etymology. Many examples are on this page: e.g., Bhuma for ພູມາ <būmā> [pʰuːmaː] from Sanskrit/Pali bhūma- 'earth' (with final lengthening). I used to think these were transliterations of Lao spellings prior to a reform that eliminated the 'extra' letters, but if Lao never had these 'extra' letters prior to Maha Sila Viravong's alphabet, what is the origin of these spellings? Are they just carryovers from the Indic style of transliterating Thai?
14.11.19.23:50: CHURYUMOV IN TANGRAPHY (PART 3)
Tangutizing the second syllable of Ukrainian Чурюмов [tʃuˈrʲumow] 'Churyumov' should be trivial. There is no doubt that Tangut had r- (transcribed in Tibetan as r-), and Gong Hwang-cherng (1997) and Arakawa (1997) both reconstruct two -ju rhymes*. Yet neither reconstruct a syllable rju. In Gong's reconstruction, r- can only precede retroflex vowels in rhymes 77-103 with the exception of rhyme 43 -jɨj. Similarly, in Arakawa's reconstruction, r- can only precede retroflex vowels in rhymes 77-103 with the exceptions of
rhyme 43 rjẽ2
rhyme 75 rjoŋ (rjọ̃ in his 1999 reconstruction**; Gong reconstructed ljọ with l-)
rhyme 77 rjek2 (rjẹ ĩn his 1999 reconstruction; Gong reconstructed reʳj with a retroflex vowel)
rhyme 78 re'2 (re'̣ in his 1999 reconstruction; Gong reconstructed rieʳj with a retroflex vowel)
rhyme 79 rje'2 (rjẹ' in his 1999 reconstruction; Gong reconstructed rjiʳj with a retroflex vowel)
I reconstruct rhyme 43 as -ẽ, and I think rẽ was a simplification of an earlier *rẽʳ with an unusual nasalized retroflex vowel like those of Kalasha (Heegård and Mørch 2004: 67). rjoŋ/rjọ̃ with rhyme 75 may have a similar explanation if its initial was r- (as opposed to Gong's l-): it may be from an earlier *rjọ̃ʳ with a nasalized retroflex tense vowel. (Does any language have that triple combination? I doubt it, but then again, I would be skeptical of nasalized retroflex vowels if I didn't know about Kalasha.)
Therefore the ryu of Churyumov would have to be Tangutized with a retroflex vowel as something like rjuʳ. Gong reconstructed twenty rjuʳ-syllables, whereas Arakawa only reconstructed eighteen. Arakawa may have accidentally left out the two members of Homophones A group 9.77. The obvious choice is
which rhymes with its synonym, the first half of
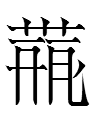
2147 2rjuʳ 'broom'
2271 0109 2zjuʳ 2gjịj (Gong), 2zzjuʳ 2gẹ̃ (Arakawa) 'comet' (lit. 'broom star')
So can we finally move on to Tangutizing -mov yet?
Next: Y not?
*[ju] is -yu in Arakawa's notation. I have rewritten Arakawa's and Gong's reconstructions in an IPA-like system to facilitate comparison.
**Arakawa (1999: 41) reconstructed both rhymes 73 and 75 as -ọ, but I think 75 -ọ was a typo for 75 -jọ̃ since he regarded 75 as a Grade II rhyme, his Grade II has medial -j-, and he placed 75 across from 57 -jõ.
14.11.18.23:45: CHURYUMOV IN TANGRAPHY (PART 2)
In part 1 I decided to Tangutize the first syllable of Ukrainian Чурюмов [tʃuˈrʲumow] 'Churyumov' as 1013
which was pronounced something like chu.
Were Tangut shibilants palatal, alveopalatal, or retroflex?
I have been using the neutral notation ch to avoid answering that question up until now in this series.
There is no doubt that Tangut class VII initials were shibilants. They were most commonly transcribed in Tibetan as c-, ch-, j-, and sh- (ignoring preinitials; Tai 2008: 194). Moreover, one of the class IX initials was commonly transcribed in Tibetan as zh- (again ignoring preinitials; Tai 2008: 201). Although the Tibetan initials were probably palatal* [tɕ tɕʰ dʑ ɕ ʑ], that does not mean that the Tangut initials were necessarily palatal, as the Tibetan script had no characters for alveopalatal [tʃ tʃʰ dʒ ʃ ʒ] or retroflex [tʂ tʂʰ dʐ ʂ ʐ].
Middle Chinese had a distinction between palatals and retroflexes. Twelfth-century reflexes of both types of initials were used to transcribe Tangut shibilants in the Timely Pearl. That either implies that the distinction was lost (as in Phags-pa Chinese to the east from the following century) or that neither was a perfect match for the Tangut shibilants (which could have been alveopalatal).
Sanskrit also had a distinction between palatal ś [ɕ] and retroflex ṣ [ʂ]. Both were transcribed with Tangut sh-, though there are a few alveolar s-tangraphs for Sanskrit palatal ś-syllables and the s-tangraph 0493
could represent Sanskrit palatal ś, retroflex ṣ, and alveolar s (Arakawa 1997: 110-114). This admittedly small tendency to write Sanskrit palatal ś as Tangut alveolar s may suggest that Tangut sh was closer to Sanskrit retroflex ṣ. The correspondence of Sanskrit palatal ś to Tangut alveolar s is also reminiscent of the Russian transcription of Mandarin palatal x [ɕ] as palatalized alveolar [sʲ]: e.g., 西夏 Xixia 'Tangut' as Си Ся [sʲi sʲa].
However, the use of Tangut alveolar affricates (ts- tsh- dz-) to transcribe Sanskrit palatal stops (c ch j**) is not evidence against Tangut shibilant affricates being palatal because the variety of Sanskrit known to the Tangut had alveolar affricates instead of palatal stops.
Shibilants are one of the three types of 'vigilant' Grade III initials in Tangut. If Grade III was palatal as reconstructed by Gong, then I would expect the 'vigilant' initials to be palatals:
I prefer to more or less follow 李新魁 Li Xinkui (1980)*** and reconstruct these initials as follows:class II ɥ- (which I would not expect in a labiodental class)
class VII tɕ-, tɕh-, dʑ-, ɕ-
class IX λ-, ʑ-
class II v-
class VII tʂ-, tʂh-, dʐ-, ʂ-
class IX l- [ɫ], ʐ-
These initials are all 'antipalatal': cf. how Russian retroflexes and nonpalatalized [v] and [ɫ] cannot precede [i]. Just as Russian /i/ retracts to [ɨ] after retroflexes, pre-Tangut *i became ɨi after retroflexes.
There is acoustical affinity between l and v: e.g., in Ukrainian, syllable-final *-l became /v/: e.g., *volk > /vovk/ 'wolf'.
Moreover, there is also acoustical affinity between retroflexes and labiodentals: e.g., in modern northwestern Chinese dialects (whose substrata if not ancestors were the dialects known to the Tangut 800-900 years ago), retroflexes became labiodentals before *w and *u (Coblin 1994: 97, 102)
*tʂ- > pf-
*tʂh- > pfh-*ʂ- > f-
*ʐ- > v-
So I am not surprised that the 'vigilant' initials form a class in Tangut.
Lastly, if the Tangut grades were like Chinese grades, Grades II and III were less palatal than Grade IV. And those are precisely the two grades associated with shibilants****. Hence I think palatal initials are less likely in those two grades.
In any case, Tangut must have had retroflexes at some stage, as the shibilant in
3200 1tʂhɨiw < *K-truk 'six'
is from an *r-cluster: cf. Classical Tibetan drug, Written Burmese khrok, and many other Sino-Tibetan words for 'six'. This retroflex *tʂh- from *K-tr- could have shifted to alveopalatal *tʃh-, palatal *tɕh-, or even alveolar *tsh- in Tangut dialects. There are rare cases of Tibetan alveolar affricates (ts- dz-) transcribing Tangut shibilants (Tai 2008: 194). If those instances of ts- and dz- are not errors*****, they may reflect the beginnings of a shift from retroflexes to alveolars.
Next: On to the second syllable in part 3.
*They were palatal in Old and Classical Tibetan (Jacques 2012: 90). There is no guarantee they were also palatal in the dialect(s) underlying the Tibetan transcriptions of Tangut. Nonetheless there is also no evidence suggesting that they were not palatal in that dialect or dialects.
**I have not seen any Tangut transcriptions of the rare Sanskrit consonant jh.
***11.19.0:24: Li Xinkui (1980) was the first to reconstruct retroflexes in classes VII and IX. My reconstructions are identical to his (as listed in Li Fanwen 1986: 126-127) except for (1) dʐ- corresponding to his aspirated dʐh- and (2) [ɫ].
****Arakawa (1997: 135) proposed that rhyme 50 which only has shibilant and l-initials (i.e., two of the three types of 'vigilant' initials) was grade I. Sofronov, Gong, and I regard 50 as Grade III.
*****The Tibetan characters for ts and dz are derived from the characters for c and j:
ཙ ts < ཅ c
ཛ dz < ཇ j
I would expect the extra stroke of ts and dz to be accidentally omitted rather than accidentally added. Thus I suspect the scribes intended to write ts and dz, though it is not clear whether they actually heard [ts] and [dz] or if they misheard shibilants as [ts] and [dz].
14.11.17.23:51: CHURYUMOV IN TANGRAPHY (PART 1)
Last night I wrote,
I still think each half is appropriate since Philae did cause us to see 67P/Churyumov-Gerasimenko. I'm not going to try to Tangutize all of that.
But tonight I decided to try anyway since Tangutizating Churyumov and Gerasimenko brings up some interesting issues in Tangut phonological reconstruction.
*Churyumiv?
Before I deal with Tangut, I have a Ukranian question. I assume that Чурюмов [tʃuˈrʲumow] 'Churyumov' was once Чурюмовъ with a final weak yer. Normally o fronted to i before a weak yer in Ukrainian: e.g., Харьковъ > Харків 'Kharkiv'. Yet the surname is not *Чурюмів. Nor is the genitive plural of мова 'language' *мів from мовъ; it's мов. All other forms of мова never had weak yers in the syllable before o. Was o restored by analogy in those words?
Tangutizing Chu-Many scholars (Nishida, Sofronov, Huang, Li Fanwen, Gong Hwang-cherng, Arakawa, and most recently even myself) reconstruct Tangut rhyme 1 as -u. (Huang and Li also respectedly reconstructed -iu and -ü.) Hashimoto reconstructed a long vowel -U [uː]. This rhyme was almost always transcribed in Tibetan as -u (Tai 2008: 204), and it was used to transcribe Sanskrit -u and -ū (Arakawa 1997: 110, 112).
The consensus is that rhyme 1 was Grade I. Grade I rhymes never follow class VII initials: i.e., shibilants such as ch-. Therefore there was no Grade I syllable chu in Tangut. Why were ch- and -u incompatible in Tangut? That question incorporates the assumption that rhyme 1 was -u. Perhaps the Grade III (Arakawa's Grade II) rhyme 2 syllable 1013
that transcribed the Tangut period northwestern Chinese cognates of modern Mandarin
朱蛛猪諸 zhū [tʂu ˥]
竹竺 zhú [tʂu ˧˥]
主 zhǔ [tʂu ˨˩˦]
祝 zhù [tʂu ˥˩]
粥 zhōu [tʂow ˥]
帚 zhǒu [tʂow ˨˩˦]]
was chu (and therefore the best match for the Chu- of Churyumov), and the Grade I rhyme was something other than -u. Here are three possible scenarios:
| Grade/rhyme | A | B | C |
| I/1 | nonshibilant + -u | nonshibilant + X + -u | nonshibilant + X + -u |
| III/2 | shibilant + X + -u | shibilant + -u | shibilant + Y + -u |
In scenario A, rhyme 1 was -u, but rhyme 2 had an extra quality X that differentiated it from simple -u: e.g., Gong Hwang-cherng's -j-, Arakawa's -y- (= [j]), and my -ɨ-.
In scenario B, it is rhyme 1 that had an extra quality X that differentiated it from simple -u. If Gong Xun (2014) is correct, that quality may have been pharyngealization or retracted tongue root. But this begs the question of why the Tangut would use rhyme 1 to transcribe Sanskrit -u and -ū without pharyngealization or retracted tongue root. My short answer is that rhyme 1 was the best available match after many initials. I will elaborate on that answer in the future.
In scenario C, neither rhyme had a simple -u. For years until recently I reconstructed rhyme 1 as -əu and rhyme 2 as -ɨu.
Next: Tangutizing the rest of Churyumov.
14.11.16.23:16: PHILAE IN TANGRAPHY
Having just written about the Tangut word for 'comet', I wanted to come up with a Tangutized name of the Φιλαί Philae lander. A Tangutization could be based on at least three different pronunciations:
English [fajli]
Modern Greek [file]
Classical Greek [pʰilai]
Each poses at least one problem for Tangutization.
Did Tangut have f-?
As far as I know, only Nishida, Huang Zhenhua, and Arakawa reconstructed f-. I do not think it is completely impossible, but I am not yet fully convinced. It is a low-frequency initial in all three reconstructions:
- it appears before only 18 of Nishida's (1964: 85-86) 102 rhymes
- it appears before only 6 of Arakawa's (1997: 125-149) 105 rhymes
- it appears before only 12 of Huang's (1983: 128-134) 97 'level' tone rhymes
Only Arakawa and Huang (?) reconstruct f- before -i(:) in 3859 'rat' which has no homophones:
Arakawa 1fi:, Huang 1fi (?)
but Nishida 1wi, Sofronov 1968 1xi̭we, Gong 1xjwi
That tangraph was in the labiodental chapter of Homophones, but its initial fanqie speller - also in that chapter - had an initial fanqie speller in the glottal chapter which includes back (velar?) fricatives:
=
+
3850 1xwɨi (rhyme 10) = 0418 1xwɨə + 2228 pi (rhyme 11, not 10!)
+
0418 1xwɨə = 2504 1xu + 1760 1ʂwɨə
Unfortunately there is no Tibetan transcription data for 2504 or any other tangraph in its initial fanqie chain (VIII 10, Tai 2008: 196).
2504 is a transcription character for Sanskrit hu. That would be unlikely if its Tangut reading were fu - unless Tangut had no hu or xu. It transcribed both *x- and *f-initial Chinese syllables.
On the other hand, why would a xw-syllable be placed in the labiodental chapter of Homophones? Was [f] an allophone of /xw/? Were [f] and [x] in free variation before -u?
Moreover, 0418 means 'Buddha' and may be a loanword from Tangut period northewestern Chinese 佛 *fɨə. Was that word borrowed with f- and/or xw-?
In any case, I wouldn't want to Tangutize Philae with 'rat'.
Did Tangut have -ai?Even if Tangut had f-, I am unaware of anyone reconstructing a Tangut syllable like fai. And it is doubtful that the extant recorded varieties of Tangut had -ai (though such a rhyme could have existed in unwritten dialects). Such a rhyme should have corresponded to -aHi in Tibetan transcription, but no such transcription exists.
ai is rare in Sanskrit, so it is not surprising that Arakawa (1997: 113) listed only four Tangut transcriptions of Sanskrit Cai-syllables:
4884 2ni (Grade IV rhyme 11) for Skt nai and ni; transcribed in Tibetan as niH
2563 2mɛ (Grade I rhyme 34) for Skt mai; rhyme mostly transcribed in Tibetan as -i and -e
4262 2be (Grade IV rhyme 37) for Skt vai; rhyme mostly transcribed in Tibetan as -e
5300 3639 1tə 2reʳ (Grade IV rhyme 79) for Skt trai; rhyme mostly transcribed in Tibetan as -e
If Tangut had a rhyme -ai, all Sanskrit syllables would have been transcribed with that rhyme and its retroflex variant -aiʳ after r-.
The use of both Tangut -i and -e-type rhymes indicates that Tangut had no exact match for -ai. -i imitated the second half of -i while mid front -e was a compromise between low a and high front i.
One might counter that the Tangut heard a foreign (e.g., Tibetan or Chinese) pronunciation of Sanskrit with a monophthong like e instead of ai, but if that were the case, the Tangut could have consistently transcribed that e as e.
Following the precedent of transcribing Sanskrit ai with -e-type rhymes, I would Tangutize Philae as
0749 0046 1phi 2le
which one might be tempted to 'translate' as 'cause to see', though that would be ungrammatical in Tangut since the causative 1phi follows verbs. I chose 1phi because it transcribed Tangut period northwestern Chinese *phi-syllables (霹鼻脾備琵) in the Timely Pearl. 2le 'to see' transcribed Sanskrit le. Even though 0749 0046 can't be a Tangut phrase, I still think each half is appropriate since Philae did cause us to see 67P/Churyumov-Gerasimenko. I'm not going to try to Tangutize all of that. I'll settle for
3200 1084 2205 0749 1tʂhɨiw 2ɣạ 1ʂɨạ 1phi 'six ten seven causative'
with a Tangutization of English [pʰi] 'P'.














{kind=link}
{kind=link}
{kind=link}
{kind=link}