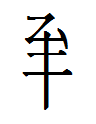14.11.15.23:05: ARE COMETS BEAUTIFUL BROOMS?
Since a comet has been in the news lately, this would be a good time to take up Andrew West's suggestion to write about the Tangut word for 'comet' which appears in Timely Pearl 074:
2271 0109 2ɮyʳ 2gẹ 'comet'
It corresponds morpheme by morpheme to its Chinese translation 掃星 'broom star'. 2271 is probably a derivative and special spelling of 3695 2ɮyʳ 'broom' used in astronomical contexts:
+
(<
?)
2271 = 'grass' (left of 3695) + an element Grinstead (1972: 28) glossed as 'finery' and 'ornament', perhaps from a character such as 0364 tsẽ 'beautiful' - were comets 'beautiful brooms' in the sky as opposed to those on the ground which could be held with hands (the right-hand element of 3695)?
Is 2ɮyʳ 2ge a calque of 掃星?
Although I do not know of any pre-Tang attestations of 掃星, 彗星 'comet', also literally 'broom star', goes at least as far back as the Han Dynasty, and Karlgren (1957: 143) glossed 彗 by itself as 'comet' in the pre-Han Zuo zhuan.
Unfortunately there is no way to determine how old the Tangut term is; the most I can say is that it certainly was not invented on the spot by Timely Pearl author Gule Maocai in 1190, as it also appears in other texts: 53A53 in the first edition of Homophones which was written 65 years earlier, Newly Assembled Precious Dual Maxims (1187), and volume 6 of the Tangut translation of the Golden Light Sutra. And each half is in the Precious Rhymes of the Tangraphic Sea dating from sometime after 1069.
I do not know of any Tibetan term for 'comet' like 'broom star'. Are there languages outside the Sinosphere with 'broom star' for 'comet'? How likely it is that the Tangut coined the term independently?2271 could also mean 'comet' in the compound
2814 2271 2ɬị 2ɮyʳ 'comet'
'moon comet'
from Timely Pearl 083. It too is a morpheme-for-morpheme match of Chinese 月孛 'moon comet'. Could Late Middle Chinese 孛 *pɦot be the source of Tibetan phod 'comet'?
In Homophones 53A52 and Timely Pearl 265, the regular tangraph for 'broom' is paired with a rhyming synonym also written with the 'grass' radical:
3695 2147 2ɮyʳ 2ryʳ 'broom (and?) broom'
Are those two words cognates? I would not expect lateral ɮ- and retroflex r- to be in the same word family. Is 2ɮyʳ from *2l-ryʳ? Are there other pairs of ɮ- and r-words with identical rhymes and similar semantics?
Nishida (1964: 213) has the English translation 'broom' for 3695 2147, implying that it was a redundant compound. Other possible redundant compounds are:
2147 4260 2ryʳ 2ɬø̃ 'broom (and?) broom' (Homophones A 51A37 and 48B32)
4260 2147 2ɬø̃ 2ryʳ 'broom (and?) broom' (Tangraphic Sea 1.55.211)
0094 4910 2147 1ʂwo 2vɛ 2ryʳ 'sweeping broom' (Tangraphic Sea 1.55.211)
0094 4910 2147 1ʂwo 2vɛ 2ɬø̃ 'sweeping broom' (Tangraphic Sea 1.81.252)
0094 4910 1ʂwo 2vɛ is a verb 'to sweep'. Although Li (2008: 16, 777) glossed it as a noun followed by a verb, the two halves seem inseparable, so I regard it as a disyllabic root rather than as a compound.
14.11.14.23:54: THE M-D-L-ED MYSTERY OF TANGUT RHYME 4 (PART 1)
The second syllable of3721 5407 2bʌ 2dɤu 'stupa, pagoda'
has Tangut rhyme 4
0730 1mɤu 'protruding mouth; pestle' (name of the level tone variant of rhyme 4)
0310 2mɤu 'transcription of Sanskrit mu, mū; cord (< Chn 纆?); to wipe (< Chn 抹?); to connect' (name of the rising tone variant of rhyme 4)
which has mystified me for almost seven years.
Modern scholars have categorized Tangut rhymes in terms of 'grades'. I am not entirely comfortable with that because I don't know of any Tangut word for 'grade'. I have not seen any of the Tangut translation equivalents of Chinese 等 'grade' used in a phonological context:
0382 1dzɨi 'equal, even'
0424 2te 'equality (< Chn 等); to measure'
0724 2nə 'plural suffix'
1290 2tsew 'class'
1576 2kɑ̣ 'equality'
17371kɑ 'equal, even'
(Of course, there is the possibility that the Tangut used an entirely different word for 'grade' that has not yet been identified. Tangut phonologists were surely familiar with the concept from Chinese phonology; the issue is whether they applied it to their own language.)
Moreover, what I have seen of the Tangut rhyme tables (not enough!) was not arranged by grade unlike the Chinese 韻鏡 Yunjing 'Rhyme Mirror' rhyme tables. Nonetheless, I am convinced by Gong's (1994) arguments in favor of Tangut grades, though I favor four grades instead of three. And I would add another argument: each grade is strongly correlated with a different set of initials:
| Grade | Labials | Labiodentals | Dentals | Velars | Alveolars | Retroflexes | Glottals | l- | Non-l liquids |
| I | ✓ | ✓ | ✓ | ✓ | ✓ | X | ✓ | ✓ | ✓ |
| II | ✓ | ✓ | ✓ | ✓ | X | ✓ | ✓ | ✓ | ✓ |
| III | X | ✓ | X | X | X | ✓ | X | ✓ | X |
| IV | ✓ | X | ✓ | ✓ | ✓ | X | ✓ | X | ✓ |
(I have omitted the controversial and rare class IV initials.
✓ means 'present'.
X means 'ideally absent'. Red means 'actually absent'; yellow means 'ideally absent but exceptions exist': e.g.,
labial b- and glottal ʔ- and x- before grade III rhyme 2 -ɨu
alveolar tsh- before grade II rhyme 8 -ɤi
velar k-, alveolar dz-, and glottal ʔ- before grade III rhyme 10 -ɨi
l- before grade IV rhymes 3 -y and 37 -e
Exceptions list added 11.15.1:20.)
Today I coined the term 'vigilant' to refer to Grade III. Vigil is a mnemonic for three initial types associated with Grade III: v- for labiodentals (class II), g- [dʒ] for shibilants (class VII + class IX ʐ-), and l.
Grade IV is nonvigilant: i.e., it generally follows initials other than those three types.
Grade II is 'hypervigilant'; it can have any initial - vigilant or nonvigilant - other than alveolars and r-. Gong derived Grade II from medial *-r- in a 1993 paper I have not yet seen:
*CrV > CV + Grade II
I think Gong was right because his hypothesis predicts no r- before Grade II unless pre-Tangut had a cluster *rr-. And *alveolar-r clusters may have become retroflexes as in Chinese: e.g, *sr- > ʂ-.
Grade I is shibilant-free. Maybe I could call it 'hypervalent', meaning that it may occur after v-, l-, and nonvigilant initials, but not shibilants.
Rhymes 1-4 were all transcribed as -u in Tibetan. All scholars who reconstruct grade systems in Tangut agree that rhyme 1 was grade I, but disagree on the others:
| Rhyme | Grades | Labials | Labiodentals | Dentals | Velars | Alveolars | Retroflexes | Glottals | l- | Non-l liquids | ||||
| Hashimoto 1965 | Gong 1997 | Arakawa 1999 | Sofronov 2012 | This site | ||||||||||
| 1 | I | I | I | I | I | ✓but not m-! | ✓ | ✓but not d-! | ✓ | ✓ | X | ✓ | ✓ | ✓ |
| 3 | II | III | IIa | II/III | III | b- only | ✓ | X | X | X | ✓ | ʔ-, x- only | ✓ | X |
| 3 | III | IIb | IV | IV | ✓ | X | ✓ | ✓ | ✓ | X | ✓ | ✓ | ✓ | |
| 4 | IV | I | III | I | II | m- only | X | d- only | ✓ | X | X | ✓ | X | ɬ- only |
The initials of rhyme 4 are unlike any of the initial sets expected for the four grades. They are all back initials with the exceptions of m- and d- (as reconstructed by Gong) and ɬ- (= Gong's lh-). Why do m- and d- appear before rhyme 4 but not rhyme 1 in Gong's reconstruction?
Next: Were m- and d- really m- and d-?
14.11.13.21:13: STUMPED BY 'STUPA' (PART 4: ETYMOLOGY OF THE SECOND SYLLABLE)
Having covered homophones of the first syllable of
3721 5407 2bʌ 2dɤu 'stupa, pagoda'
in parts 2 and 3, and hypothesizing that
4908 1b(w)ʌ 'ceremony and propriety'
might be related to it, I am now going to look for a plausible cognate of the second syllable among its (near-)homophones:
| Homophones A group |
Homophones A page/location | Homophones B/D group | Homophones B/D page/location | Tangraph | Gloss | Reading | Tangraphic Sea rhyme | Overall rhyme |
| III.5 | 12A48 | (1) | 13A41 | to exist, have, place | 1dɤu | 1.4 | 4 | |
| 12A51 | 13A42 | peaceful | ||||||
| 12A52 | 13A44 | building | ||||||
| 12A53 | 13A45 | first half of 0979 0978 1dɤu 2da 'slow, obtuse, dazed' | ||||||
| III.6 | 12A54 | 13A43 | anger, rage (< Chn 怒) | |||||
| 12A55 | 13A46 | to ban, prohibit, resist; to sink, drown, trap (when reduplicated) | ||||||
| 12A56 | (2) | 13A47 | to measure (< Chn 度) | 2dɤu | 2.4 | |||
| 12A57 | 13A48 | second syllable of the surname 4561 2284 2ba 2dɤu (almost homophonous with 3721 5407 2bʌ 2dɤu 'stupa'!) | ||||||
| 12A58 | 13A51 | second syllable of 4373 4281 2dɤu 2lɨi 'pear tree' (< Chn 杜梨) | ||||||
| 12A62 | 13A53 | second word of 2671 0712 2bʌ 2dɤu 'drawers and stomacher' (< Chn 肚), a homophone of 3721 5407 2bʌ 2dɤu 'stupa' | ||||||
| 12A63 | 13A54 | second syllable of 0691 0710 2bɤa 2dɤu 'large-collared gown' | (not in Tangraphic Sea) |
Homophones group numbering follows the conventions established in part 3.
Note how the different placement of ![]() and
and ![]() in
the middle implies that they could have had different tones in
different editions of Homophones. Perhaps the circle marking
the end of group III.5 was improperly placed in Homophones A,
and that error was corrected in later editions of Homophones.
in
the middle implies that they could have had different tones in
different editions of Homophones. Perhaps the circle marking
the end of group III.5 was improperly placed in Homophones A,
and that error was corrected in later editions of Homophones.
The missing 12A61 (Homophones A)/13A52 (Homophones B
and D) is of course ![]() 5407 2dɤu, the second half of 'stupa'.
And its obvious source is 2829
5407 2dɤu, the second half of 'stupa'.
And its obvious source is 2829 ![]() 1dɤu 'building':
1dɤu 'building':
+
=
?
4908 + 2829 = 3721 5407
1bʌ 'ceremony' + 1dɤu 'building' = 2bʌ 2dɤu 'stupa'?
Semantically that is fine, but the tones do not match. Why were 'level' tones changed to 'rising' tones? And when did that happen? Before or after a final glottal *-H conditioned rising tones - if Tangut tones are of segmental origin? (What if Tangut tones originated from pitch accent as in southern Qiang?)
Moreover, is it simply a coincidence that four out of seven disyllabic words with dɤu fit the pattern bA dɤu?
0691 0710 2bɤa 2dɤu 'large-collared gown'
2671 0712 2bʌ 2dɤu 'drawers and stomacher'
3721 5407 2bʌ 2dɤu 'stupa, pagoda'
4561 2284 2ba 2dɤu (a surname)
The homophones from yesterday's list of 1bʌ-syllables come to mind:
5035 4068 1bʌ 1mɛ 'to present a gift; to fete'
5042 4072 1bʌ 1mɛ 'soft'
Is such (near-)homophony the result of unconscious evolution, or is it the product of conscious design? The study of Tangut polysyllabic morphemes has barely begun.
14.11.12.22:54: STUMPED BY 'STUPA' (PART 3: NEAR-HOMOPHONES OF THE FIRST SYLLABLE)
In part 2, I looked at exact homophones of the first syllable of
3721 5407 2bʌ 2dɤu 'stupa, pagoda'
in search of possible cognates and found none. I forgot to look at near-homophones with the first tone:
| Fanqie | Tangraph | Li Fanwen number | Gloss | |
| Initial | Final | |||
1475 1bi |
3732 1kʌ |
3149 | first syllable of 3149 2811 2816 1bʌ 1lɨə 1lø 'round bone' (only in dictionaries) | |
| 5035 | first syllable of 5035 4068 1bʌ 1mɛ 'to present a gift; to fete' (homophonous with 'soft' below) | |||
| 5042 | first syllable of 5042 4072 1bʌ 1mɛ 'soft' (homophonous with 'present a gift' above) | |||
2366 1bu |
0515 1lʌ |
0022 | resources | |
| 3594 | first syllable of 3594 0620 1bʌ 2dɑ 'abrupt', 3594 0700 1bʌ 2dʐɨaʳ 'to throw' (only in dictionaries), and 3594 5586 1bʌ 2dʐwø 'to throw' | |||
| 3692 | first syllable of 3692 0342 1bʌ 1dzə 'to throw' (only in dictionaries); why weren't all three 'throw' verbs written with the same tangraph? Why change the bottom right corner? | |||
| 4908 | ceremony and propriety (only in dictionaries) | |||
| 5031 | second syllable of 2621 5031 2lɨə 1bʌ, name of an ancestor of the black-headed Tangut | |||
Although these eight tangraphs have two different fanqie (which I will call A and B), they were placed in the same group as all but one of the 2bʌ tangraphs in Homophones A:
| Homophones A group |
Homophones A page/location | Tangraphs | Reading | Tangraphic Sea rhyme | Overall rhyme |
| I.16 | 03A55-03A61 | 1bʌ B | 1.27 | 28 | |
| 03A62-03A63 | 2bʌ | 2.25 | |||
| 03A64 | 1bʌ A | 1.27 | |||
| 03A65-03A67 | 2bʌ | 2.25 | |||
| 03A68 | 1bʌ A | 1.27 | |||
| 03A71-03A72 | 2bʌ | 2.25 | |||
| 03A73 | 1bʌ' | 1.31 | 32 | ||
| 03A74 | 1bʌ A | 1.27 | 28 | ||
| 03A75-03B12 | 2bʌ | 2.25 | |||
| I.17 | 03B13 | ||||
| 03B14 | 1bʌʳ | 1.84 | 90 |
The numbering of Homophones A groups follows Li Fanwen 1986 and Arakawa 1997.
The two types of bʌ 1.27 were separated from each other and
from bʌ 2.25 in Homophones B and D. Rhyme 28 tangraphs
were no longer mixed with tangraphs of other rhymes. ![]() (rhyme 32)
is 10A21 and
(rhyme 32)
is 10A21 and ![]() (rhyme 90) is 10A57 in Homophones B and D.
(rhyme 90) is 10A57 in Homophones B and D.
| Homophones B/D group |
Homophones B/D page/location | Tangraphs | Reading | Tangraphic Sea rhyme | Overall rhyme |
| (1) | 04A54-04A58 | 1bʌ B | 1.27 | 28 | |
| (2) | 04A61-046A62 | 1bʌ A | |||
| (3) | 04A63-(04B01) | 2bʌ | 2.25 |
I have arbitarily numbered the Homophones B and D groups.
The main character of 04B01 in Homophones B has not
survived, but what remains of the clarifier beneath it matches 1765 ![]() in Homophones
A and D. 1765 is not separated from other 2bʌ in B or D. (This
section is missing from Homophones C.)
in Homophones
A and D. 1765 is not separated from other 2bʌ in B or D. (This
section is missing from Homophones C.)
The (mis)matches between the different editions of Homophones and the Tangraphic Sea indicate that
- 1bʌ (both types) and 2bʌ were very close (or even homophonous in the Homophones A dialect: i.e., they all had the same tone - or no tone?)
- the distinction between the two types of 1bʌ may not have been an isolated quirk of the Tangraphic Sea, as the B type tangraphs are clustered at the beginning of Homophones A group I.17, and have their own group (1) in Homophones B and D
- the fanqie suggest the difference may have involved a medial -w-, though such a medial is not otherwise thought to be distinctive after labials:
A: 1bi + 1kʌ = 1bʌ
B: 1bu + 1lʌ = 1bwʌ? (whose -w- may be from a prefix *P- - but would *P-prefixed forms really have outnumbered prefixless forms five to three?)
- rhymes 32 and 90 were similar to rhyme 28
-
1bʌ' (rhyme 32) might have been 1bʌ A in the Homophones A dialect whose ancestor may have lacked the conditioning factor that became the 'apostrophe' feature in the Tangraphic Sea dialect
-
2bʌ (rhyme 28) 'dark green' might have been 1bʌʳ like
in the Homophones A dialect whose ancestor may have had a prefix *R- in 'dark green' that conditioned retroflexion absent from the Tangraphic Sea dialect
At the pre-Tangut level, the sources of 1bʌ and 2bʌ could have been identical except for the absence or presence of a final glottal *-H that conditioned the rising tone. (I am putting aside the question of whether type B 1bʌ had *P- at the pre-Tangut level.)
Out of the eight 1bʌ above, the only one with any potential
semantic relevance to 3721 5407 2bʌ 2dɤu 'stupa, pagoda' is ![]() 4908
'ceremony and propriety'. If 4908 were suffixed with *-H or
shifted to the rising tone after tonogenesis (but why?), it could have
been added to something like 'mound' or 'building' to form 'stupa,
pagoda'. But is there a 2dɤu with such a meaning?
4908
'ceremony and propriety'. If 4908 were suffixed with *-H or
shifted to the rising tone after tonogenesis (but why?), it could have
been added to something like 'mound' or 'building' to form 'stupa,
pagoda'. But is there a 2dɤu with such a meaning?
Next: Homophones of 2dɤu 'stupa, pagoda'.
14.11.11.23:36: STUMPED BY 'STUPA' (PART 2: ETYMOLOGY OF THE FIRST SYLLABLE)
The second half of the Tangut word3721 5407 2bʌ 2dɤu 'stupa, pagoda'.
could be used on its own to mean 'stupa'. Was the first half 3721 2bʌ a prefix or modifier? Eight of the homophones of 3721 2bʌ are not free morphemes and cannot be modifiers. Nor does it seem likely that the noun 'stupa' shared a prefix with, say, the verb 'to swell'. The remaining five homophones do not look like probable modifiers: .e.g, 'insect'.
| Tangraph | Li Fanwen number | Gloss |
| 0589 | first syllable of 0589 3530 (2008) 2bʌ 2dəʳ (1xõ) 'scabies' (only in dictionaries) | |
| 1386 | first syllable of 1386 2434 2bʌ 1be and 1386 1146 2bʌ 1kɑ̣, botḥ 'old and shabby' | |
| 1765 | dark green (only in dictionaries) | |
| 1888 | insect | |
| 2276 | first syllable of 2276 1972 2bʌ 2reʳ 'to swell' (the second half can occur by itself) | |
| 2280 | first syllable of 2280 0504 2bʌ 2lɨẽ 'spinach' | |
| 2671 | first word of 2671 0712 2bʌ 2dɤu 'drawers and stomacher', a homophone of 3721 5407 2bʌ 2dɤu 'stupa'; Li Fanwen (2008: 439) regarded 2671 as a loan from Chinese 襪 'drawers', but the latter was *va which is a poor phonetic match. | |
| 2828 | first syllable of 2828 0865 2bʌ 1tʂɨe 'to bear a burden' (only in dictionaries?; the quotation from Nevsky 1960 II may be a quotation from the lost rising tone volume of the Tangraphic Sea) | |
| 3301 | first syllable of 2828 0090 2bʌ 1voʳ 'mandarin duck' (1voʳ is 'chicken') | |
| 3304 | first syllable of the place name 2828 5856 2bʌ 2ɣɑ | |
| 3381 | pellet; first word of phrases 3381 2290 2bʌ 2lõ and 3381 5900 2bʌ 2di, both 'pellet' (2lõ is 'round' and 2di is 'broken') | |
| 4677 | bull | |
| 4766 | first syllable of 4766 1032 4789 2bʌ 1vʌ̣ 1ny 'a kind of vegetable' (only in dictionaries) |
I presume that the homophony of 3721 5407 2bʌ 2dɤu 'stupa' and the phrase 2671 0712 2bʌ 2dɤu 'drawers and stomacher' is purely coincidental.
If none of the above are related to 3721 5407 2bʌ 2dɤu 'stupa', there are several other possibilities.
First, 2dɤu may be an abbreviation for a disyllabic root 2bʌ 2dɤu, just as Chinese 塔 ta 'stupa' is an abbreviation of 塔婆 tapo < *thəp-ba. Unlike the Chinese word, 2bʌ 2dɤu is not a borrowing from Indic, and I wonder what its original meaning was.
Second, 2bʌ- could be a fusion of *N- with *p(h)ʌ or even *Nʌ- which lowered the vowel of a following *p(h)ə or *bə, so its true cognates may have been pronounced p(h)ʌ, p(h)ə, bə or and/even vʌ (< *Cʌ-Pə) or və (< *Cə-Pə). Casting a wider net may eventually yield results.
The third is a copout: 2bʌ- is the last survival of a morpheme that was lost elsewhere: cf. were- of werewolf (from an extinct wer 'man'; were- has only recently has become productive in neologisms) and -groom of bridegroom (from an extinct guma 'man').
(11.12.8:25: Fourth, a cognate of 2bʌ- could have the first ['level'] tone. I'll look at 1bʌ tangraphs in part 3.)
14.11.10.22:33: STUMPED BY 'STUPA' (PART 1: TANGRAPHIC STRUCTURE)
Andrew West put up a page on Tangut text decorations including drawings of stupas. That got me thinking about the Tangut word
3721 5407 2bʌ 2dɤu 'stupa, pagoda'.
Each of the two tangraphs is the clarifier for the other in the various editions of Homophones:
2bʌ 2dɤu (a left-hand clarifier is read after the main tangraph; see scans)
2bʌ 2dɤu (a right-hand clarifier is read before the main tangraph; see scans)
The characters have nearly symmetrical structures. The analysis of the first tangraph is unknown, but I suspect it is similar to the analysis of the second:
=
+
?
3721 2bʌ (first half of 2bʌ 2dɤu 'stupa') =
'earth' < left of 3792 1lwy 'low' (only in dictionaries?) +
all of 5053 1tsəʳ' 'fifth' (used before 1448 2ʔew 'son'; see Andrew's article on Tangut filial ordinals)?
+
5407 2dɤu 'stupa' =
top of 5053 1tsəʳ' 'fifth' +
right of 1572 1phɤõ 'white' +
'earth' < left of 3792 1lwy 'low'
The 'earth' radical is not surprising, as the Chinese character 塔 for 'stupa' also contains an 土 'earth' radical. But why extract it from 'low' (a curious choice for a tall structure), and what are the functions of 'fifth' and 'white'?
I would have expected
1ŋwʌ 'five'
for the five elements symbolized by a stupa instead of 'fifth' (son).
'White' may refer to the color of a stupa. Why is 'white' in the analysis of 5407 but not 3721? The left-hand component of 5407 analyzed as a blend of 'fifth' and 'white' is unique to that tangraph:
=
+
It is that unusual radical that makes 3721 5407 unlike disyllabic words with symmetrical tangraphs: e.g.,
1721 5660 1ma ?kwi 'stirrup'
Next: Etymology.
14.11.9.23:05: DID THE KHITAN LARGE SCRIPT HAVE FEWER VOWEL DISTINCTIONS THAN THE KHITAN SMALL SCRIPT?
Kane's transcription of the Khitan large script in chapter five of his 2009 book has few of the diacritics that are common on vowels in his transliteration of the Khitan small script. The exceptions are ü and ï in Khitan large script spellings of Chinese loanwords and ê which may also be exclusive to Chinese loanwords:
[sêng un] 'commander' (transcribed in Chinese as 詳穩; < Chinese 將軍 'general'?)
[an] ~ [ên] for the transcription of Chinese 元 and 原
Liu and Wang (2004: 87) read the latter as [ɑn].
Does that mean the language underlying the Khitan large script had fewer vowels than the language underlying the Khitan small script? Not necessarily.
I think it is more likely that one phonology was written in two different ways. From a phonemic perspective, the Khitan large script may have underdifferentiated the Khitan vowel system whereas the Khitan small script overdifferentiated it by including characters for allophones. And overdifferentiation could have led to spelling problems as the vowel system changed over time and as Jurchen came to write in Khitan.
I could be wrong. Future analysis may reveal that the Khitan large script had at least six characters corresponding to the six back (?) vowel characters of the Khitan small script, and all six might have been phonemic in the tenth century when both scripts were established. But current scholarship indicates a degree of vocalic flexibility in the large script absent in the small script: e.g.,
[un] ~ [ən] (Liu and Wang 2004: 81; Kane 2009: 179 only has one reading [un])
may correspond to up to three characters in the small script:
<un>, <ún>, and/or <en> (= [ən])
Kane only confirmed the [un] : <un> correspondence.
In any case, it doesn't correspond to
<én> (two variants)
whose large script counterpart is
according to Kane 2009: 174. Maybe é was front whereas u, ú, and e [ə] were nonfront.
A future transliteration of the Khitan large script might have capital letters for vowel classes: e.g., <Un> for
with an <u> indicating a nonfront, nonlow vowel. Precise vocalism could only be determined via comparison with small script spellings (if any).