~
~ ~
~
14.11.8.23:16:
REDHOUSE'S TURKISH VOWELS
After struggling to identify Khitan vowels,
I would expect the
identification of Turkish vowels in James Redhouse's 1880 dictionary
to be
trivial. I thought Redhouse would have eight symbols corresponding to
the eight vowels of modern Turkish (a e ı i o ö u ü), but in
fact he
has eleven: five in roman type, three in small capitals, and three
in italics:
1. A as in wall
2. a as in far
3. a as in about
4. E as in pan
5. e as in pen
6. i as in pin
7. i as in girl
8. o as in go
9. u as in French tu
10. U as in full
11. u as in fun
Users could ignore the distinctions indicated with small capitals and italics. Redhouse wrote in 1856 that
were the European character ever to be adopted in Turkey [which happened less than eighty years later!], for the purpose of writing the Ottoman language, there is no reason why the a, the e, the i, and the u should not bear several values as they do with us; whereas in printing, and, if necessary, even writing, the difference could be pointed out by one or two strokes under them, thereby leaving the upper part free for the introduction of special signs to distinguish the long from the short vowels, and the accentuated from the unaccentuated syllables.
He used macrons and acute and grave accents to indicate vowel length
and accentuation (? - more on this below).
Clues to the other six (in bold) are in his list of the phonetic values of the hàrékÉ on pp. 11-12:- a, e, i, o, u = modern a, e, i, o, ü (not u!)
fètha = A, a, a, É, e
késsrÉ = i, i
dàmma ~ zàmma = o, u, U, uModern dotless ı, ö, and u must be equivalent to italic i, italic u, and small capital U:
Àlti = altı 'six'
dùrt = dört 'four'
òrdU = ordu 'camp, army' (the same word I wrote about two days ago)The other three have modern equivalents overlapping with those of a and e:
Àda = ada 'island'
tèkÉ = teke 'shrimp'
On page
20, Redhouse differentiated between "hard" (= nonpalatal) small
capital A and italic a and "soft"
(palatal) roman a.
Only small capital Ā and roman ā can be
long, and "there are scarcely any long vowels" in native Turkish words (pp. 13-14).
(The original Turkic long vowels were long gone, and modern long vowels
that resulted from the loss of /ɣ/ are absent from
Redhouse's description*. The 'silent' letter ğ corresponds
to Redhouse's gh,
a hard g, taking sometimes a gliding sound [...] sometimes softened down to the value of w when preceded or followed by o or U, and even by i; at other times it becomes almost imperceptible in the pronunciation. [p. 16])
After briefly browsing through Redhouse's dictionary, I tentatively conclude that
- the core (native) eight vowels were
nonpalatal/back: A (which could be long in Arabic and Persian loanwords), i, o, U [ɑ(ː) ɯ o u]
palatal/front: e, i, u, u [e i ø y]
- italic a was [ə] which was always short
The small capital A : italic a distinction corresponds to nothing in earlier Turkic or modern Turkish, and I wonder if Redhouse was hearing allophony.
Italic a seems to be in final syllables - but see àna below!
- roman a was a front or central [a] and could be long or short in Arabic and Persian loanwords
but it's also in native àna 'mother' (cf. modern ana ~ anne; the latter violates vowel harmony like Redhouse's form) and kara 'black' (after a back k)!
- small capital E in part corresponds to modern [ɛ], a word-final allophone of /e/
Although Redhouse wrote that small capital E was like the a [æ] of English pan, it does not always correspond to [æ], an allophone of /e/ before sonorant codas: e.g., Redhouse's ben (not bEn!) 'I' corresponds to modern ben [bæn].
On the other hand, kEtEn 'flax' corresponds to keten [ketæn], but it has a small capital E in nonword-final position!
I would have to look through Redhouse more carefully to refine my interpretation of his notation.
I was hoping to see another interpretation of the Redhouse
romanization in Yavuz
Kartallıoğlu's "The
Vowels of Turkish Language in Transcription Texts" (2010).
Unfortunately he did not look at Redhouse's dictionary, though he did
include Redhouse's earlier French-language grammar of Turkish in his
study.
*According to Kerslake
(1998: 184), /ɣ/ was already lost prior to the nineteenth century.
Redhouse may have been transcribing a spelling pronunciation.
14.11.7.23:35: FREQ<U>ENCY IN XINGZONG AND ZHONGGONG
Looking at spellings of 'camp' in the Khitan small script such as
<ordu.u> (Renyi 11.24, etc.) ~ <ordu.ú> ~ <ord.ó> (both unknown; see Kane 2009: 77)
one might conclude that their final characters all represent the
same vowel:
=
=
<u> = <ú> = <ó>
And if one looks at other alternations in Kane (2009),
<u> = <û> = <ó> = <ô> (p. 45)
=
=
=
<ó> = <o> (p. 65)
one could equate all back vowel characters:
<u> = <ú> = <û> = <ó> = <ô> = <o>
Using the same logic, one could spot the overlap (烏) between the various phonograms for Old Japanese u
于汙宇紆羽禹有雲卯兎菟得烏
and Old Japanese wo
乎呼袁遠怨惋越弘小少𠮧緒絃綬雄尾男麻嗚塢烏
from Igarashi (1969: 160, 163) and conclude they all represented the same syllable:
于汙宇紆羽禹有雲卯兎菟得 = 烏 = 乎呼袁遠怨惋越弘小少𠮧緒絃綬雄尾男麻嗚塢
But that was not in fact the case. Those phonograms were taken from
at least three strata of Old Japanese writing, each with its own
conventions. 烏 'crow' does not appear in the earliest of the three
strata. 烏 stood for u in the middle stratum and for wo
in the new stratum. The two sound values reflected two strata of
borrowing from Chinese:
- Before the seventh century, Early Middle Chinese 烏 *ʔo was borrowed as pre-Old Japanese *o which raised to u in Old Japanese. Hence 烏 was used as a phonogram for Old Japanese u in the middle stratum.
- Sometime between the seventh and early eighth century, Late Middle Chinese 烏 *ʔo was borrowed as Old Japanese wo because Old Japanese no longer had o (which had raised to u). Hence 烏 was used as a phonogram for Old Japanese wo in the new stratum.
The new style of writing in Nihon shoki (720) did not catch on, so the middle style continued to be used in later texts.
The lesson to be learned here is that there was no homogenous 'Old Japanese' orthography that lasted unchanged even over a brief two-century period.
Similarly, there is no reason to assume that Khitan orthography
lasted unchanged from the invention of the small script in c. 925 until
the script died out around 1200*. The earliest
dated Khitan small script text is the epitaph of 耶律宗教 Yelü Zongjiao
from 1053, over a century after the script's creation. Thus there is no
guarantee that even that text preserves the phonology that the script
was originally intended to represent. Perhaps the alternations of vowel
symbols reflect spelling errors due to mergers. Another source of error
may be influence from Jurchen in the Jin Dynasty texts. Jin Jurchen may
have had a vowel system that was simpler or at least different from
that of Khitan. (The Jin Jurchen reconstruction in Jin Qizong's
dictionary may have as few as five vowel phonemes depending on one's
analysis.) 12th century Khitan small script spelling may contain clues
to what Khitan with a Jurchen accent sounded like. (Unfortunately at
this point it's not clear what Jin Jurchen itself sounded like!)
Let's see if there are any differences in the frequencies of u/o-graphs in the earliest and latest Khitan small script texts I have on hand: the epitaphs for Emperor 興宗 Xingzong (1055) and 蕭仲恭 Xiao Zhonggong (1150):
| Character |
QXY# |
Transliteration |
Xingzong |
Zhonggong |
Xingzong : Zhonggong ratio |
| 090 |
ó |
17/15%/3rd |
43/15%/3rd |
1:1 |
|
| 131 |
u |
44/39%/1st |
139/47%/1st |
1:1.2 |
|
| 186 |
o |
29/25%/2nd |
38/13%/4th |
1:0.52 |
|
| 245 |
ú | 7/6%/5th |
9/3%/6th |
1:0.5 |
|
| 252 |
ô |
2/2%/6th |
11/4%/5th |
1:2 |
|
| 253 |
0/0%/7th |
2/1%/7th |
- |
||
| 372 |
û | 15/13%/4th |
51/17%/2nd |
1:1.3 |
|
| Total |
114/100% |
293/100% |
1:1 |
||
The relative rankings of vowels in the two texts are nearly identical except for
186 <o> and 245 <ú> which were only half as common in Zhonggong as in Xingzong
252 <ô> which was twice as common in Zhonggong as in Xingzong
The frequencies of 131 <u> and 372 <û> rose by 20% and 30% in Zhonggong. Were some Xingzong <ú>-words spelled with <u> and <û> in Zhonggong?
And were some Xingzong <o>-words spelled with <ô> in Zhonggong?
Did the Zhonggong language have only one u-vowel corresponding to three in Khitan c. 925?
090 <ó> rarely appears in transcriptions of Chinese words, and
its relative ranking did not change. Perhaps it was stable while
<o> and <ô> merged in the Zhonggong language.
The mergers above would have resulted in a Zhonggong vowel system
resembling that of Manchu:
| yin? |
i |
e [ə] |
|
u |
| yang? |
|
a |
o |
ó [ʊ] (like Manchu ū) |
The interpretation of 090 <ó> is from Qidan xiaozi yanjiu (1985: 152).
Confirmation of this hypothesis will require the close study of individual words in the two texts.*The Khitan small script was abolished by the Jin
emperor over two centuries later in c. 1191-1192. I do not know if the
Khitan small scripit continued to be used in the Kara-Khitan
Khanate until its demise or if Yelü Chucai
(1190-1244) knew the small script.
14.11.6.23:56: WHAT'S TO THE RIGHT OF 'RICE'? (AND THE LEFT?)
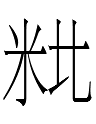
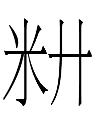
Two of the Khitan small script spellings of the Khitan equivalents of the era names 重熙 Chongxi (1032-1055) and 大安 Da'an (1085-1094) included the small script character 355 resembling Chinese 米 'rice':
<HEAVEN ordu.l.ɣa.ar> (Yelü Dilie 14)
<GREAT ordu.ó.o.ón> (Yelü Dilie 26)
They made me wonder about the other contexts in which 355 米 could be found:
| Preceding |  355 <ordu> |
Following | ||||||
| Character | QXY# | Transliteration | Source | Character | QXY# | Transliteration |
Source | |
| 038 | ? |
Xingzong 14.7 | 080 | ii | Xu 22.11 | |||
| 169 |
qó |
Xu 53.6 | 090 | ó | Yelü Dilie 26 |
|||
| 186 | o |
Daozong 5.20, Xu 25.21, Yelü Tabuye 13.7 | 131 | u | Xingzong 2.17, Renyi 11.24, Linggong 4.18, 17.3, Zhonggong 10.48, 13.46, 16.30, Yelü Tabuye 13.7 | |||
| 244 |
s |
Xu 43.23 | 154 | on | Xu 58.13 | |||
| 270 | êm | Xu 58.4 | 189 | a | Daozong 24.27 | |||
| |
245 | ú | Unknown (see Kane 2009: 77) | |||||
| 261 | l | Yelü Dilie 14 |
||||||
| 341 | er | Xu 58.4 | ||||||
The above table only lists characters immediately preceding or following 355 米 (which also occurs by itself in Xu 11.18); it is not a list of blocks or possible blocks: e.g., I know of no block 038/128-355-080 <?.ordu.ii>.
Given that
1. all known readings of preceding characters end in -o (ó) or consonants (s, -m)
2. there is no consistent vowel in the following characters (a, e, ii, o, ó, ú)3. the expected converbs after o- and u-final stems are
<oi> and <ui>
not <ii> (Kane 2009: 149-150; but
<p.o.ju> was followed by <ii>
in Langjun 3.15 and Zhonggong 20.28. Was
*<p.o.ju.ui> (not in any text in Qidan xiaozi yanjiu)
intended? Would the same mistake have been made in two different texts? Both date from the Jin Dynasty; do they reflect errors in Khitan as a second language?)
4. my hypothesis that Khitan generally avoided vowel sequences unless they contained identical vowels or ended in high vowels (Vi and Vu)I wonder ifbut that hypothesis cannot account for the verbal noun oduon 'nourished' transcribed in Chinese as 窩篤盌 *(ʔ)wo-tu(ʔ)-on (see Kane 2009: 159)
1. 米 355 was originally a logograph <ordu> 'camp'.
2. <o> was added to <ordu> as a clarifier of the initial vowel:
<o.ordu> = ordu (Xu 25.21; more examples in 3 below)
3. <u> and <ú> were added to <ordu> as a clarifier and/or lengthener of the final vowel:
<ordu.u> (Renyi 11.24, etc.) ~ <ordu.ú> (unknown; see Kane 2009: 77) = ordu(u)
~
<o.ordu.u> (Yelü Tabuye 13.7) ~ <o.ordu.ú> (unknown; see Kane 2009: 77) = ordu(u)
Cf. early Turkic ordu: ~ ordo: with a final long vowel (Clauson 1972: 203).
4. later <ordu> was reinterpreted as a phonogram <U(r)d> and used for
4.1. ordo 'camp' (reflecting an o-final variant of the word; cf. the Turkic variation above):
<ord.ó> (unknown; see Kane 2009: 64, 77) ~ <ord.on> (genitive?; Xu 58.13)
4.2. a consonant-final verb U(r)d- taking the converb -ii:
<U(r)d.ii>
4.3. an a-final verb (?) U(r)da- '?' taking the perfective suffix -(a)r:
<U(r)d.a.ar> (Daozong 24.27).
4.4. a noun or verb dêmU(r)d- '?' taking the accusative/instrumental or the perfective suffix -(e)r in
<d.êm.U(r)d.er> (Xu 58.4; related to <d.em> 'to enfeoff'?)
I would expect the perfective suffix <or> after an o-final verb stem.
4.5. a verb udu- in the era names also written with <ú.dû>:
See the top of this post for the spellings with 355 米 which I would now interpret as~
<HEAVEN ú.dû.l.ɣa.ar> (Kane 2009: 159; not in Qidan xiaozi yanjiu; primary source unknown) ~
<HEAVEN ú.dû.l.ɣa.a.ar> (Xingzong 1, 2, Xiao Linggong 17)
<GREAT ú.dû.ó.o.ón> (Yelü Tabuye 9, Xiao Zhonggong 6)
(heaven) udulɣa(a)r 'Chongxi'
(great) ud(u)o(o)n 'Da'an'
I also considered the possibility that 'camp' could have had a third form ord. Ord could have been borrowed from Turkic before apocope, whereas ordu(u) ~ ordo could have been later reborrowings from Turkic. Clauson (1972: 203) regarded the word as a loan in Turkic. Perhaps it is ultimately from Ruanruan or Xiongnu.
For an earlier take on 355 米 and 'camp', see what I wrote almost exactly three years ago.
11.7.15:28: Found and added line numbers for Yelü Dilie.
14.11.5.16:15: GREAT PEACE, GREAT DIVERSITY
One of the most complex characters in the Khitan large script
0430
is probably the same character that appears in the more complex spellings of the Khitan large script equivalent of the Liao Dynasty Chinese era name 大安 Da'an (Liao Chinese *taj an) 'Great Peace' (1085-1094):
~
~
~
~

(Kane 2009: 182; source of each spelling unknown)
(epitaph of 蕭袍魯 Xiao Paolu, line 15, 1090)
(epitaph of 耶律褀 Yelü Qi, line 22, 1108)
All of the above begin with <GREAT> resembling Chinese 大 'great'.
Kane listed six two-character spellings, but two (the third and fifth) look like
to me, so I count them as one (the fourth in my list above).
I suspect the first two spellings in Kane
are missing a third character present in the epitaphs I quoted:
The tiny characters in Kane's book are hard to make out, so
look almost identical. I used the zoom function of a digital camera to try to make out the subtle differences between them. Neither is in N4631. I wish I could compare them to the forms in inscriptions.
My image
is based directly on the only inscriptional form I have seen (on page 74 of N4631).
The font in N4631 has yet another variant with a joined 干, a dot instead of a vertical line, and no hook on the right:
.
I will consider these four forms to be equivalent:
They seem to be combinations of=
with
Those vertical ligatures are reminiscent of
~
=
+
<taulia> 'rabbit' = <tau> + <lia>
The bottom component of 0430 is abbreviated as 匚~氵 and placed on the left (not right, where 氵 would not be permitted in Chinese) in
~
~
~
Another variant of that combination may be 1792
from N4631.
This horizontal ligature also appears in the Khitan large script equivalent of the Liao Dynasty Chinese era name 重熙 Chongxi (Liao Chinese *tʂhuŋ xi) 'Repeated Splendor' (1032-1055; as translated by Kane 2009: 6):
All of the above begin with <HEAVEN> resembling Chinese 天 'heaven' atop 土 'earth'.
Note how different spellings can coexist within the same epitaph:
I would expect to find more if I had a complete database of known Khitan large script texts.
As if all of the above weren't complex enough, the identical large script second halves of the Khitan equivalents of Chongxi and Da'an correspond to different second halves in the small script:
'Chongxi':
~
<HEAVEN ú.dû.l.ɣa.ar> (Kane 2009: 159; not in Qidan xiaozi yanjiu; primary source unknown) ~
<HEAVEN ú.dû.l.ɣa.a.ar> (Xingzong 1, 2, Xiao Linggong 17) ~
<HEAVEN ordu.l.ɣa.ar> (Kane 2009: 77, 159; Yelü Dilie 26)
'Da'an':
~
<GREAT ú.dû.ó.o.ón> (Yelü Tabuye 9, Xiao Zhonggong 6) ~
<GREAT ordu.ó.o.ón> (Kane 2009: 77; Yelü Dilie 14)
So did
have two readings depending on context, U(r)dUoon and U(r)dUlɣaar? (Capital letters indicate uncertain vowels.)
Could the first part
be a verb stem U(r)du- 'nourish' (suggested gloss from Kane 2009: 159)? But it is hard to believe the nominalizer -oon and the causative/passive-perfective sequence -lɣa-ar which are neither nearly homophonous nor synonymous would be written identically as
And would either of those two characters or some variant represent the verb written as
<ú.dû.l.ɣa.a.ar> 'nourished'? (Daozong 13)
without a preceding <HEAVEN> in the small script?
John Tang's proposal of slight differences between the large and small script languages is attractive here. Perhaps names for the two eras had identical endings in the large script but different endings in the small scripts. Another possibility is that
represented a morpheme entirely different from -oon and -lɣa-ar, as it does not have the textual frequency I would expect for a verb ending. Does it ever appear in contexts other than era names? Moreover, if 'Chongxi' ended in the perfective ending -ar in the Khitan large script, I would expect
<ar>
which is a frequent character (and which, unlike most large script characters, resembles its small script counterpart:
).
11.5.21:05: Added <HEAVEN ú.dû.l.ɣa.ar>, <ú.dû.l.ɣa.a.ar> as an independent verb, the comparison between large and small script characters for <an>, and sources for small script spellings of 'Chongxi' and 'Da'an'.
11.7.15:27: Found and added line numbers for Yelü Dilie.
14.11.4.22:08: BIG-MOUTHED MEDICINE
The case for y in the N4631 reconstructions of Khitan (as opposed to Khitan itself) is even weaker than I had thought. Andrew West suggested that yo for the Khitan large script character
0067 'medicine' < Liao Chinese 藥
may have been intended to be IPA [jo] rather than IPA [yo]. Although there are modern Mandarin dialects with yo for 'medicine', their y may have secondary rounding. I do not know of any Khitan small script spelling of the word, but the Liao Chinese form must have been intermediate between Sino-Korean 약 yak [jak] (reflecting eighth century northeastern Chinese) and Yuan Dynasty forms like
Phags-pa Chinese ꡭꡠꡓ <yew> *jɛw (as reconstructed by Coblin 2007: 155)Zhongyuan yinyun *jaw ~ *jɔ (as reconstructed by Pulleyblank 1991: 363)
and it would be simplest to reconstruct *j instead of a transient *y (or *ɥ).
I have no idea why the shape 夻 (resembling 大 'big' atop 口 'mouth') is associated with 'medicine'. It looks nothing like any variant of 藥 or any other character that probably would have been pronounced *jo in Liao Chinese. It does look like the Chinese character 夻 hua 'big-mouthed fish', but it doesn't sound like it, and I don't know if it is attested anywhere before Zihui (1615).
Chinese 藥 'medicine' does have an exact lookalike in the Khitan small script (0344 in N4631). It is the most complex character in N4631. Here are statistics on characters in N4631 with more than ten strokes:
| Number of strokes | Number of characters | N4631 numbers | Chinese lookalikes? |
| 18 | 1 | 0344 | 0344 = 藥 |
| 17 | 0 | - | - |
| 16 | 1 | 1606 (variant of 0275 below?) | none |
| 15 | 2 | 0275 (variant of 1606 above?), 0736 | none |
| 14 | 3 | 0430, 0724, 1921 | 1921 similar to 殿 |
| 13 | 6 | 0247, 0337, 1670, 1841, 1931, 2106 | 1670 similar to 焰 1841 similar to 尊 1931 = 殿; cf. 1921 above |
| 12 | 7 | 0350, 0627, 1236, 1454, 1497, 1716, 1776 | 0350 similar to 爾 0627 = 黄 1716 = 道 |
| 11 | 20 | 2,198 characters is too many for me to look at right now! | |
| 10 | 32 | ||
| 9 | 78 | ||
| 8 | 188 | ||
| 7 | 349 | ||
| 6 | 441 | ||
| 5 | 492 | ||
| 4 | 373 | ||
| 3 | 182 | ||
| 2 | 39 | ||
| 1 | 4 | ||
The most frequent stroke count is 5, matching what Andrew found with a smaller sample.
I have very limited experience with the Khitan large script. Until tonight, I only knew of four characters with twelve or more strokes: 1716 道, 1921 resembling 殿, 0344 藥, and
0430
without any Chinese twin. Based on that small sample, I assumed that most complex characters were Chinese near-lookalikes, but in fact the opposite seems to be true. I don't know of any lookalikes for 12/20 (60%) of the characters with twelve or more strokes. Perhaps I could find more lookalikes - particularly by digging for variants in Longkan shoujian (997).
1716 道 was read dau (phonetically [taw]?), a match for Liao Chinese 道 *taw. However, I do not know how the other complex Chinese lookalikes such as 0344 藥 were read. There is no guarantee that they had Chinese-based readings, as many less complex Chinese lookalikes have unpredictable readings of mostly unknown origin: e.g.,
| Character form | Khitan large script reading | Liao Chinese reading |
| 上 | xa (transcription of initial of Liao Chinese 行 *xaŋ) | *ʂaŋ 'above' |
| 五 | tau 'five', transcription of Liao Chinese 討 *thaw | *ŋu 'five' |
| 午 | iri 'name' (corresponding to Khitan small script <i.ri> | *ŋu 'seventh Earthly Branch' |
| 至 | an (transcription of rhyme of Liao Chinese 韓 *xan) | *tʂi 'to arrive' |
| 高 | bai (transcription of initial of Liao Chinese 百 *paj) | *kaw 'high' |
五 represents both the Khitan and Liao Chinese words for 'five', so perhaps the other readings in the Khitan column above are Khitan translation equivalents of the Liao Chinese readings: e.g., the Khitan word for 'high' was something like bai (which coincidentally sounds like Tangut
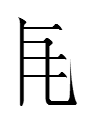
2be 'high'!).
However, this hypothesis has yet to be tested: e.g., does
<b.ai>
correspond to 'high' in small script texts? That particular combination of characters is not in Qidan xiaozi yanjiu (1985). Is it in any texts that were found over the following three decades?
14.11.3.22:01: THE VOWELS OF KHITAN IN N4631
See my last post for the consonants.I don't think the 175 reconstructed readings of Khitan large script characters in this Unicode proposal were intended to represent a single coherent system. Nonetheless I could not help but catalog their ten vowels with their frequencies. Dubious vowels are in red.
| i: 70 | y: 2 | u: 58 | |
| e: 18 | ə: 14 | o: 21 | |
| ɛ: 1 | |||
| æ: 1 | a: 36 | ɑ: 13 | |
Khitan had some sort of vowel harmony, so I would expect pairs or sets of vowels: e.g.,
| 'higher' series | i | ɛ | y | ə | (ɔ) | u |
| 'lower' series | e | æ | (ø) | a | ɑ | o |
I have filled in a couple of holes.
Back to the inventory from N4631:
1. i and u are more secure than y which is in only two readings:
tɕyr 'two' and yo < Liao Chinese 藥 *yo(ʔ) 'medicine'
If not for the small script characters
<y> and <ü>
corresponding to Liao Chinese *ɥ and *y, I would hesitant to reconstruct y in Khitan. I think Khitan had y, though I don't know if it appeared in native words such as 'two'.
The Proto-Mongolic cognate of 'two', *jiri-n (Janhunen 2003: 16), has a neutral vowel i that could be from front *i or nonfront *ï. So it does not necessarily support the front-vowel reconstruction tɕyr.
2. Although there are many examples of ə, only two have transcriptional support:
ən, transcribed in Liao Chinese as 恩 *ən and 隱 *in (or *ɨn, if it was still like the 8th century form underlying Sino-Korean ŭn)
nəzəi 'dog', transcribed in Chinese as 捏褐 *njexo

In the latter case, ə appears to be a guess intended to bridge the gap between *e in the Chinese transcription and o in Classical Mongolian noqai 'dog'.
I would still expect ə in Khitan since it is in Manchu and Korean. But expectations should be backed by evidence.
3. The only example of ɛ is in the mysterious title
transcribed in Chinese as 詳穩 *sjaŋwən. I think it may simply be a variant of Khitan
sianggün 'general'
from Chinese 將軍. I don't see any reason to reconstruct a special vowel for this word.
4. The only example of æ is in
pæt
transcribed in Chinese as 八 *pa(ʔ). The reading pæt is probably based on Middle Chinese 八 *pæt which predated the creation of the large script by three centuries. By the Liao Dynasty, northeastern Chinese final stops had either been reduced to glottal stops or lost entirely, and *æ had shifted backward toward the space vacated by *a after it raised to *o:
*æ > *a > *o (or in phonetic notation, *[æ] > *[ä], *[ɑ] > *[ɔ]; the new /a/ was not as back as the old /a/)
If Khitan had an æ distinct from a, there would have been no way to unambiguously indicate that in Chinese transcription. Moreover, there do not seem to be multiple types of a-graphs in the small script.
5. That is one reason I am skeptical about an a vs. ɑ distinction in Khitan.
Another is that there is no Chinese transcription evidence for such a distinction:.
The Liao Chinese homophones 上 and 尚 *ʂaŋ ~ *ʂɑŋ (the exact pronunciation of the *a-type vowel is unknown) were borrowed as
ʃaŋ and ʃɑŋ
which have different vowels in N4631.
xwɑ
is a transcription of Liao Chinese 化 *xwa with a nonback vowel (not *xwɑ with a back vowel!).
I would simply reconstruct *a instead of *ɑ. *a may have been phonetically [ɑ] in some or even all environments, but I cannot reconstruct that level of detail.
6. Subtracting ɛ, æ, ɑ, and the loanword vowel y from the vowel inventory of N4631 leaves a six-vowel system which happens to be like the ones I reconstruct for pre-Tangut and Old Chinese:
| 'higher' series | i | ə | u |
| 'lower' series | e | a | o |
That is too small to be the Khitan vowel system because the small script has a wealth of symbols for back and/or rounded vowels (Kane 2009: 29):
<o ó ô u ú û>
The diacritics in the transliteration are purely for differentiation purposes and have no phonetic value. Kane expected [y] and [ø], but I think [ʊ] and [ɔ] are also possibilities: cf. Manchu which has u [u] and ū [ʊ].
14.11.2.23:02: THE CONSONANTS OF KHITAN IN N4631
175 (7.9%) of the 2,218 Khitan large script characters in this Unicode proposal have reconstructed readings with twenty-six consonants. Dubious consonants are in red.
| h | ||||||
| q | ||||||
| k | kʰ | ŋ | x | ɣ | ||
| tɕ | j | |||||
| tʃ | tʃʰ | ʃ | ||||
| ts | s | z | ||||
| t | tʰ | d | n | r, l | ||
| p | pʰ | b | m | w | ||
1. There is only one character with h transcribed as Liao Chinese 海里 *xɑjli and 解里 *xjajli:
hɑili (a name)
Nearly all other Liao Chinese *x correspond to x. I suspect that h could be rewritten as x.
2. The voiced counterpart of q may have been ɣ which could have been uvular [ʁ].
ɣ is, however, doubtful in
ɣa and ɣuaŋ
if those characters were read like Liao Chinese 何 *xɔ and 皇 *xɔŋ rather than Middle Chinese 何 *ɣɑ and 皇 *ɣwɑŋ.
3. The unaspirated-aspirated distinction in N4631 corresponds to the voiced-voiceless distinction in my Khitan transliterations and transcriptions: e.g., N4631 k, kʰ : my g, k. I do not think there was a three-way distinction between unaspirated voiceless, aspirated voiceless, and voiced. More in 8 and 10 below.
4. tɕ is in only one reading:
tɕyr 'two'
I suspect it could be rewritten as tʃ. If it was meant to be an allophone of /tʃ/ before front vowels, it should also appear before i.
5. ts was probably only in Chinese loanwords. I do not know why the first character of
ts.(u) 都統 'commander-in-chief'
was reconstructed as ts. (The second character has no reading in N4631; Liu and Wang 2004 reconstruct that character sequence as tʂʻ.u on the basis of small script evidence that I have not yet seen.)
6. z is only in
nəzəi 'dog'
which was transcribed in Chinese as 捏褐 *njexo which has no sibilant. z may be a typo for x.
Li and Wang (2004: 26) regard that character as a variant of
ʃɑ.
7. I treat th which only appears once in

then 'heaven'
as equivalent to tʰ. I do not know how the reading of that character was determined. Without any transcription or alternation evidence, there is no reason to believe that it sounded like Liao Chinese 天 *tʰjen 'heaven.' Liu and Wang (2004: )
8. d could be rewritten as t, as it corresponds to Liao Chinese *t (there was no Liao Chinese *d) and Mongolian and Jurchen/Manchu d [t]:
9. I treat ph which only appears once in
dan, transcribed as Liao Chinese 丹 *tan (Liao Chinese had no *d, so there would be no better transcription of a foreign d)

dol : Mongolian doloqan 'seven'
dor : Jurchen/Manchu doron 'seal', Manchu doro 'ritual'
dun < borrowing of Liao Chinese 屯 *tun

pho 'time'
as equivalent to pʰ.
10. I don't think there was a b distinct from p. b is in only two readings:
bur 'Buddha/all' and bun.
The first reading is shaky (part 1 / part 2 / part 3).
The second character is a transcription of Liao Chinese 汾 *fun (not *bun; Liao Chinese had no *b-).
11. I would rewrite the table without [h tɕ z d b] as
| q [qʰ] | ɣ [ʁ] | |||
| k [kʰ] | g [k] | ng [ŋ] | h [x] | |
| c [tʃʰ] | j [tʃ] | š [ʃ] | y [j] | |
| dz [ts] | s | |||
| t [tʰ] | d [t] | n | r, l | |
| p [pʰ] | b [p] | m | w | |
with a non-IPA notation for compatibility with Mongolian and Manchu romanization. This is an attempt to improve upon the table without changing it too much; it does not represent my reconstruction of Khitan consonants.
Next: Vowels.