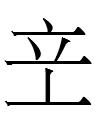
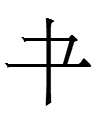
 >
>
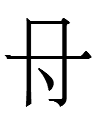
<ai> 'father' > <ai.d> 'fathers'
 >
>
13.11.29.9:05: FORE(S)FATHERS: PRENOMINAL INFLECTION IN KHITAN
The most common Khitan plural ending in small script texts is <(V)d>: e.g.,
`<ai> 'father' > <ai.d> 'fathers'
<mu.u.ji> 'sacred' (sg.) > <mu.u.ji.d> 'sacred' (pl.)
13.11.29.9:05: DO GO-BETWEENS INVITE DAUGHTER-IN-LAWS?
Out of curiosity I looked up Korean 며느리 myŏnŭri 'daughter-in-law' in Sergei Starostin's database and found it traced back to a Proto-Altaic *májŋV 'go-between' on the basis of that Korean word and
Proto-Tungusic *maŋa 'go-between, matchmaker'
Proto-Japonic: *mániák- 'to invite' (all PJ forms in this post are Starostin's, not mine)
That Altaic form is in turn derived from a Eurasiatic
*mVjNV from a Borean
*MVNV. That in turn could be derived from a Proto-World *CVCV
...
Seriously, here's what I think might be the logic behind the Proto-Altaic reconstruction:
The meaning 'go-between' was retained in Tungusic, but shifted to 'daughter-in-law' (the product of matchmaking) in Korean and lost all matrimonial associations as 'to invite' in Japanese. The semantic fit between Tungusic and Korean is loose to be generous and almost nonexistent in Japanese.
*-j- disappeared in Tungusic, whereas it moved before
the preceding vowel in Korean and after the following consonant
in Japonic. This is phonetically plausible.
Tungusic and Japonic share the second vowel *a in common, but it doesn't match Korean -ŭ-, so the second vowel is left unspecified at the Proto-Altaic level.
Japonic *-k- is unexplained - could it be a verbal suffix added to a nominal root?
Now here's what I think:
First, the semantics are weak, and get weaker at higher nodes (the
Eurasiatic meaning is 'female relative', so the meaning went almost
full circle in Korean, going from 'female relative' to 'go-between' and
to 'daughter-to-law').
- I would expect more examples of Proto-Altaic (PA) *ajC becoming Korean yŏC, but I can only find two others:
'breast': PA *č`ằjǯV : Korean chŏt < Middle Korean /cyəc/
'to stand': PA *sajri : Korean sŏ- < Middle Korean /syə/
Elsewhere, PA *aj becomes Korean i, a, ʌ(y), or u.
- I would expect more examples of PA *ajC becoming Japonic *aCi, but I can only find instance of PA *ajC becoming Japonic *aC (thrice), *i, *aiNC (not *aiC!), *iCi, word-final *ai and *u, *uC.
These chaotic 'reflexes' in Korean and Japonic are what I would expect from an attempt to link a lot of lookalikes into cognate sets, and some seem less probable than others (e.g., *aj > u in both Korean and Japonic).
PA intervocalic *-ŋ- has 'split reflexes' in Korean, becoming zero, Middle Korean -ɲ- (which others interpret as -z-), and -ŋ- as well as -n-.
Similarly, PA intervocalic *-ŋ- has 'split reflexes' in Japonic: zero, *-m-, and *-nk- as well as -n-.
Split reflexes are not impossible, but they need to be conditioned. A very complicated system could account for such diverse outcomes, but there is a risk of ad hoc solutions, particularly if many individual words have unique explanations.
Near-homophones in a proto-language should develop similarly in a daughter language. One might expect PA *mà̀jŋì 'temple, forehead, ear' (the semantic range of the gloss is itself a warning sign) to develop like *májŋV 'go-between', but it does not: the former became *mìmì in Japanese, not *mànì by analogy with *mániák- from PA *májŋV. The shift of PA *-ŋ- flanked by palatal segments (*j, *i) to Japonic *-m- is highly unlikely.
Third, Vovin might argue that 'to invite' can't be reconstructed at
the Proto-Japonic level if it is not attested in Ryukyuan (and I have
not found it there). (One could, of course, argue that Ryukyuan lost
it.)
In conclusion, I think the Tungusic, Korean, and Japonic forms have
nothing in common but initial *ma- (since I reconstruct Old
Korean *mainɯRi 'daughter-in-law' with an *R which
could have been *-r- or *-t-).
13.11.27.23:59: KA(H)I-NUS ET *TAI-MPLUM
One advantage of online publishing is immediate peer feedback. For example, in " 'Buddha Khan' in Korea and Japan" I wrote,
This begs the question of where Middle Korean ㅐ ay came from. Did only some *ai monophthongize to *e, and if so, why? Is [16th century] Middle Korean 개 kay 'dog' from *kaCi with a *-C- that blocked monophthongization before it was lost?
Sven Osterkamp reminded me that the answer in that particular instance is yes. In my haste to write something that night, I forgot about 15th century Middle Korean 가히 kahi 'dog' whose medial fricative was also recorded centuries earlier in the 12th century Jilin leishi transcription 家稀 *kya xi. (Such embarrassing oversights result from my self-imposed rule requiring me to post something before going to bed; most of these posts are written while racing against time.)
Sven also pointed out that not all instances of Middle Korean ㅐ ay could be from *aCi: e.g., 내 nay 'I-NOM' from na 'I' plus nominative -i. Could analogy have prevented monophthongization from taking place when -a (pro)nouns were followed by nominative -i?
Getting back to the subject of Buddhism, it occurred to me that Jurchen
(
)
<tai.ra(.an)> taira(n) 'temple'
might preserve an Old Korean *ai that diphthongized to *e and broke to yə, resulting in Middle Korean tyər 'temple'.
Middle Korean Sino-Korean readings ending in -ay from circa the eighth century AD must postdate diphthongization. Thus I think that *taira was borrowed into Jurchen before the eighth century: e.g., perhaps in the early years of the Parhae state.
11.28.0:56: Old Korean *taira may have been contemporaneous with Sino-Korean readings such as
低 chŏ < tyə < *te < *tai
西 sŏ < syə < *se < *sai (cf. Go-on sai, presumably from Sino-Paekche *sai)
which were borrowed before monophthongization.
Go-on sai in turn may have been borrowed from Paekche after *ai > e monophthogization in Japanese, whereas Japanese tera 'temple' was presumably borrowed from Paekche *taira before monophthogization.
Strata of early Koreanic *e/*ai in Japanese
| Paekche | Pre-Old Japanese | *e-raising | *ai-monophthongization | Old Japanese |
| *sema 'island' | *sema | sima | ||
| *taira 'temple' | *taira | tera | ||
| *sai 'west' (< southern Chinese 西) | (not yet borrowed) | sai | ||
*ai-monophthongization must postdate *e-raising because tera did not become *tira.
Sino-Japanese 世 se 'world' may have been borrowed as *sai before *ai-monophthongization.
Returning to native Korean words, I wonder if 'daughter-in-law' can be reconstructed with *ai. Here is how I would account for the variants listed on this page: e.g.,
standard 며느리 [myənɯri] < *me ... < *mai ...미느리 [minɯri] < *mi ... < *me ... < *mai ...
메니리 [meniri] < *məi ... < *mai ...
매느리 [mɛnɯri] < *mai ...
The medial -r- may be from a *-t- that lenited in intervocalic position (or Ramsey's *-d-).
I wonder what the reflexes of early Korean *sema 'island' with (presumably) primary *e (as opposed to secondary *e from *ai) are in those dialects. The standard word is
섬 [səm] < syəm < *sema
but I would predict
심 [ɕʰim] /sim/ in a dialect with 미느리 [minɯri] (i.e., a dialect which had raised *e to [i])
though not 셈 [sem] or 샘 [sɛm] which would be reflexes of *saima rather than *sema.
11.28.13:43: No, wait, 셈 [sem] would be possible in dialects preserving *e.
11.28.13:39: I would expect 질 [tɕil], 젤 [tɕel], and 잴 [tɕɛl] as variant reflexes of *taira 'temple' parallel to 미느리 [minɯri], 메니리 [meniri], and 매느리 [mɛnɯri]. But I fear that reality is messier than the predictions of this simple model.
13.11.26.23:36: NEAR-HOMO-*FO-NES OF 'BUDDHA' IN THE KHITAN LARGE SCRIPT
In my previous post, I wrote,I wonder if Liu and Wang's <bor> was actually read <fu> or <pu>, a transcription of Liao Chinese 佛 *fu 'Buddha', just as <ta> may be a transcription of 塔 *tʰa 'pagoda'.
Since there was no f in native Khitan words (see Kane 2009: 256), Liao Chinese *f- could be transcribed as
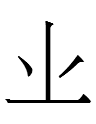
<p>
in the Khitan small script, implying that Liao Chinese *f-loanwords could also be pronounced with [p] in Khitan.
This begs the question of why Liao Chinese 佛 *fu 'Buddha' would have been transcribed in the Khitan large script as Liu and Wang graph (hereafter LW) 187 (and 188 if it is a variant of 187?)
(
?)
instead of as LW 22, 56, or 161
which Liu and Wang read as <pu>.
I will examine those three graphs below.
1. LW 22
This graph transcribed Chinese characters which were all pronounced as *fu (albeit with different tones) in Liao Chinese: 副, 夫, 傅, 府, 撫. This suggests a reading <fu> which would have been perfect for transcribing 佛 *fu 'Buddha'. Was 'Buddha' considered worthy of a special character? And/or could some instances of 'Buddha' have been written as LW 22? See below for a third possibility.
LW 22 would have been read as <pu> in native Khitan words and in a Khitanized pronunciation of Liao Chinese loanwords.
The Khitan small script equivalent of LW 22
<pu>
has a dotted variant
for <fu>, whereas LW 22 was ambiguous and could have been read as either <pu> or <fu>. (Perhaps the dotless original version of <pu> was similarly ambiguous.)
2. LW 56
This corresponds to Liao Chinese 邑 *i (line 4 of 耶律昌允 Yelü Changyun's epitaph) and 保 *pau (line 12), so Liu and Wang read it as <i> and <pu> (= <bu> in the Kane-style notation I use for Khitan on this site).
Khitan large script characters generally do not have multiple dissimilar readings, so I wonder if LW 56 represented a native Khitan <bu> 'village' that was the translation equivalent of Liao Chinese 邑 *i 'village'. 邑 did have a final *-p in Late Middle Chinese (cf. its Sino-Korean reading ŭp which was borrowed from a northeastern Late Middle Chinese dialect), but it's unlikely that <bu> represented a final *-p that was lost by the 11th century. Kane (2009: 179) did not reconstruct an <i>-like reading for LW 56; he listed <bau> as its sole reading.
Liu and Wang's second reading <bu> is in
<tai bu>
a transcription of the Liao Chinese title 太保 *tʰai pau 'great protector'. Such titles are rendered as straight transcriptions, so I would not expect a half-translated <tai i> combining the loanword <tai> with a native word <i> as an equivalent of 太保.
<bu> matches the unusual Khitan small script spelling
<b.u>
for 保 *pau in line 29 of the epitaph for 許王 Prince Xu. The spelling I would have expected is
<b.au>.
Kane (2009: 179) listed <b.au> as a small script equivalent of LW 56 but did not include <b.au> in his section on the Khitan small script transcription of Liao Chinese. Where is <b.au> attested? (契丹小字研究 does not list <b.au> in its list of possible <b>-combinations on p. 432, but it is possible <b.au> for保 has been found during the 24 years between the publication of that book in 1985 and Kane's book.)
The Khitan equated Liao Chinese unaspirated *p- with their <b> whose exact phonetic value is unclear; it could have been [p], [b], or even [ɓ]. The Khitan small script graph <b> may have had been read with an inherent vowel as <bo> implied by the Khitan small script spelling
<tai b(o)>
for the Liao Chinese title 太保 *tʰai pau (Kane 2009: 32, 80). Hence
<b.u>
could be reinterpreted as <bo.u> for a Liao Chinese reading like *pɔu. I could then revise my reading of LW 56 as <bou>.
3. LW 161Once again, Liu and Wang's <pu> is equivalent to <bu> in Kane-style notation. LW 161 appears in the word
<bu ai> 'grandfather'
whose Khitan small script spelling is
<bu ai>
<ai> is 'father'. This <bu> was distinct from the aforementioned
<bo.u>
that Kane (2009: 256) read as <b.u>.
ConclusionHere is a table comparing my readings with those of Liu and Wang (2004) and Kane (2009). Some differences are merely notational (e.g., Liu and Wang's <th> = Kane's and my <t>).
| LW | Liu and Wang | Kane | This site |
| 22 | pu | fu ~ pu | |
| 56 | pu ~ i | bau | bou (~ i?) |
| 161 | pu | bu | |
| 187 | bor | (none) | fu ~ pu (or fo ~ po?; see below) |
| 188 | tha | ta | fu ~ pu (or fo ~ po?; see below) or ta |
LW 56 <bou> and LW 122 <bu> were not suitable for writing <fu> ~ <pu> 'Buddha', but LW 22 was. I have already mentioned the possibility that some instances of 'Buddha' could have been written as LW 22. Although 'Buddha' has not yet been found in small script texts, perhaps it is in plain sight as
<pu> ~ < fu>.
~
Pulleyblank (1991) reconstructed 佛 'Buddha' in Old Mandarin as *fɔ with an irregular *-ɔ as well as the regular *fu. The modern standard Mandarin reading fo is a descendant of *fɔ. If this *fɔ already existed in Liao Chinese, perhaps LW 187 (and 188?) was something like <fo> ~ <po> and would not have been written as LW 22 <fu> ~ <pu>.
I wonder if the irregular vowel of *fɔ is due to the influence of *ɔ in the second syllable of the disyllabic word for 'Buddha':
佛陀 *fu tʰɔ > *fɔ tʰɔ?
Tangut
1tha 'Buddha'
was borrowed from that second syllable's northwestern Chinese counterpart before its vowel raised and rounded to *ɔ.
13.11.25.23:54: 'PERSON' OVER 'KING' = 'BUDDHA' OR 'PAGODA'?
Andrew West questioned the equation of the Khitan large script character
resembling Chinese 全 'complete' (in turn resembling* Chinese 人 'person' over 王 'king') with <bor> 'Buddha' for two reasons.
First, the 靜安寺 Jing'an Temple inscription mentions 佛山 *fu ʂan 'Buddha Mountain' (lines 12-13 of Liu & Wang 2004: 97) and the Chinese epitaph of 耶律昌允 Yelü Changyun's wife mentions 塔山 *tʰa ʂan 'Pagoda Mountain' (line 16 of Liu & Wang 2004: 94). (The Liao Chinese reconstructions are my own and the line numbers refer to modern printed texts, not the original inscriptions.) Liu and Wang equate those Chinese names with
<bor śan> and <ta śan>
in the Khitan large script epitaph for Yelü Changyun. (I have rewritten Liu & Wang's IPA in Kane 2009's transcription.) But what if the identifications are reversed?
Second, the reading <bor> is Liu and Wang's educated guess - a compromise between Daur barkan 'Buddha' and bologu 'complete'. There is no known Khitan small script spelling or Chinese transcription to back up this interpretation. Daur is not to Khitan what Manchu is to Jurchen, so a Daur-based guess is even shakier than my Manchu-based guess of
~
*putihi > *futihi 'Buddha'
in Jurchen. There is no guarantee that Manchu fucihi is a direct descendant of the written Jurchen word for 'Buddha'; cf. how Jurchen
<tai.ra(.an)> taira(n) 'temple'
might have been phased out by other words in Manchu. (anakv.com lists taira 'temple' as a Manchu word, but Norman's 2013 dictionary does not. This implies that the word survived into the Qing Dynasty but had become marginal.)
I wonder if Liu and Wang's <bor> was actually read <fu> or <pu>, a transcription of Liao Chinese 佛 *fu 'Buddha', just as <ta> may be a transcription of 塔 *tʰa 'pagoda'. The Khitan word for 'Buddha' could have been distinct from <fu> or <pu>, just as Korean puchhŏ is distinct from Sino-Korean 佛 pul and Japanese hotoke is distinct from Sino-Japanese 佛 butsu.
It is even possible that the Khitan had a native word recycled for the foreign concept of 'pagoda'. And Tibetan 'Buddha' demonstrates that even 'Buddha' does not have to be a borrowing.
In Tangut, 'Buddha' is
1tha < Northwestern Tangut period Chinese 佛陀 *fu tʰa 'Buddha'
which sounds like Liu and Wang's <ta> 'pagoda' (?). It is also interesting that the Tangut character has 'person' on the left and a 王-like element on the right. I have long considered the Tangut graph to be derived from Chinese 佛 which has Chinese 亻 'person' on the left, but ever since I saw Liu and Wang's identification of 全 as 'Buddha' some time ago, I've wondered if the Tangut partly translated and rearranged the components of 全 to create the graph for 1tha.
(The Tangraphic Sea explains that Tangut graph as 'a person penetrating the three worlds' - a reference to the vertical line intersecting the three horizontal lines of the right-hand element 丰 whose Boxenhorn code is ... bor!)
Could the two Khitan characters
be variants of each other? They both share an arrow-like shape 个 in common. The first two horizontal strokes of the first graph correspond to the four diagonal strokes of the second. Could they both be pictographs of pagodas?
11.26.3:10: ADDENDUM: If I understand the logic of Liu and Wang (2004: 68) correctly, the identification of <bor> and <ta> was made on chronological grounds.
Yelü Changyun died in 1061, only a year after the construction of Jing'an Temple and its pagoda had begun. The temple would be completed in 1072. A reference to 1084 in line 29 of.the Khitan inscription indicates that it was written at least 23 years after the death of Yelü Changyun. (Why so long? His ethnic Khitan wife died in 1091. Was his inscription written around the same time as hers? Why was hers in Chinese rather than Khitan? And why was his in the Khitan large script rather than the small script?)
<bor śan>
appears on lines 19 and 20 between references to 1061 on line 18 and 1062 on line 19. Therefore it should not represent 'Pagoda Mountain', a name that dated after the erection of the pagoda. (The assumption seems to be that the pagoda could not have been finished within a year or two.)
On the other hand,
<ta śan>
appears on line 22, so it represents the later name 'Pagoda Mountain'. Or does it? There is no reference to a year after 1062 before <ta śan>; the next reference to a year is on the aforementioned line 29. So it's not clear that <ta śan> is a much later name. Does dative-locative <de> after <ta śan> have a translative function? Could line 22 mean something like 'It (i.e., Buddha Mountain) became Pagoda Mountain'? Or are
really just two spellings of the same word (as opposed to two words with the same referent)?
*The character 全 is actually derived from 入 'enter' over 玉 'jade'.
13.11.24.22:18: 'BUDDHA' IN MANCHU, JURCHEN, AND KHITAN
When writing my previous post, I looked up burqan 'Buddha' (< 'Buddha-khan') in Clauson's An Etymological Dictionary of Pre-13th Century Turkish, but I didn't notice the following passage in that entry until I saw it quoted in Drompp (2005: 232; emphasis mine):
This word [burqan], corresponding properly to some [Indic] phr[ase] like Buddharājā ['Buddha-king'], was the one chosen to represent Buddha in the earliest Turkish translation of Buddhist scriptures
Drompp identified Chinese characters now read as Fuyun in Mandarin as a transcription of burqan. What are those characters?
I think 'Buddha-khan' also underlies Manchu fucihi 'Buddha', which probably goes back to Jurchen
*putihi (> Ming Jurchen *futihi)
I have no idea what the origin of that character is; it does not resemble either Chinese 佛 'Buddha' or the Khitan large script character <bor> 'Buddha' (see below).
There is no phonetic transcription of these characters, so I have guessed their readings using known correspondences between Manchu and Jurchen.
*putihi in turn probably goes back to Parhae Jurchen *putiki, a borrowing from Old Korean *putke.
Note that Jurchen and Japanese have different epenthetic vowels (*-i- and -ə-) between the two parts of the compound; this may indicate those vowels were indepedently added. (Another possibility incorporating Frellesvig and Whitman's hypothesis of pre-Old Japanese *ɨ lowering to ə in Old Japanese is that the Japanese word was originally *potɨ-ka-i with a *-ɨ- corresponding to Jurchen *-i-.) The earliest Koreanic version of the word might have been *putɨ-ka-i, and the second vowel dropped out in what eventually became Middle Korean 부텨 puthyə.
Jurchen final *-i was the closest equivalent of Old Korean *-e since Jurchen had no mid front vowel *[e]; the vowel letter e in Jurchen transcription is phonetically [ə]. If the word were borrowed after *e broke to yə in Korean, it might have been borrowed into Jurchen as *putikiye or *putike which would become Manchu *fucihiye or *fucihe.
I do not know if the Khitan also had a 'Buddha-khan'-type word for 'Buddha'. Kane (2009) lists no Khitan word for 'Buddha'. Has anyone found it in Khitan small script texts? Liu and Wang (2004) identified
as the large script character <bor> 'Buddha', 'complete' (the meaning of the Chinese word represented by its sinographic lookalike 全). <bor> is obviously borrowed from northern Late Middle Chinese 佛 *bvur 'Buddha'. I wonder if <bor> ever occurs in a compound like *bor-qa 'Buddha-khan'. In 北大王墓誌, <bor> appears three times:
<bor bor en er er ? ? po> '... time'
<bor ? ? ? in de> '... (dative-locative)'
I don't know what these phrases mean or even where to divide words. Both are preceded by what look like case markers at the ends of phrases (genitive <in> and and dative-locative <de>), so I assume <bor> is word-initial.
The reduplication of <bor> and <er> in the first phrase may not be coincidental.
I assume <in> before <de> in the second phrase indicates an -in at the end of a noun rather than the genitive case unless this phrase has double case marking.
I wonder if <bor> was read as bor for 'complete' and as bur for 'Buddha'. If 'Buddha' was bor in Khitan, its mid vowel is reminiscent of the mid vowel in Old Japanese 保止氣 potəkəy.