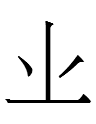
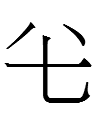...<u.ɣo b.u ja.en> '<ja.en> that is ... <u.ɣo>'
14.6.14.22:36: DID TANGUT HAVE A VOWEL SYSTEM LIKE MARSHALLESE?
Yesterday's post about the history of the glottal stop in Palauan got me thinking about the phonology of Micronesian languages. (Palauan and Chamorro are in Micronesia but are not Micronesian languages.)
Almost exactly four years ago on June 30, 2010, I wrote the following without elaboration:
Marshallese has a very complex phonetic inventory unlike its distant relatives Indonesian and Hawaiian. Its vowels are identical to the basic vowels in my reconstruction of Tangut if one rewrites my central vowels ɨ ə a as back vowels ɯ ɤ ɑ. Tangut may turn out to have diphthongs as complex as those of Marshallese.
(By coincidence, that post was followed by one mentioning Proto-Indo-European *ʕʷ which came up at the end of the previous post.)
Let me expand on that old paragraph. Any parallels between Marshallese and Tangut would have to be phonetic, not phonemic, because Marshallese has a system of only four vowel phonemes distinguished only by height (high, upper mid, lower mid, low) with many allophones. The twelve basic allophones of Marshallese vowels resemble the thirteen basic phonemes that I reconstruct for Tangut plus one of their allophones (in brackets; /a/ is back [ɑ] in Grade I rhymes of group IV: R17, R22, R66, R85, R88).
Green indicates perfect matches in Willson's (2003) description of Marshallese vowel allophones.
Blue indicates partial matches (that might be exact if the Tangut vowels are actually back instead of central).
Red indicates matches in Abo et al. (1976; now online with modifications) but not Willson (2003); Abo et al.'s [æ ɑ] correspond to Willson's [ɛ ɔ].
| i | ɨ | u |
| ɪ | ʊ | |
| e | ə | o |
| ɛ | ʌ | ɔ |
| æ | a | [ɑ] |
That table does not include nasalized, tense, retroflex, and long variants of the basic Tangut vowels.
The parallels may go further. The differences between the four grades of Tangut rhymes are not understood. For the last six years, I have reconstructed them more or less as follows:
| I | mid | əi | əu | ə | ɑ | e | o |
| II | lower | ɪ | ʊ | ʌ | æ | ɛ | ɔ |
| III | higher and less palatal | ɨi | ɨu | ɨə | ɨa | ɨe | ɨo |
| IV | higher and more palatal | i | iu | iə | ia | ie | io |
Here is an alternate reconstruction with more vowels (and Khmer-like breaking of Grade I e and o):
| I | mid | əi | əu | ə | ɑ | ɑe | ɑo |
| II | lower | ɪ | ʊ | ʌ | æ | ɛ | ɔ |
| III | higher and less palatal | ɨi | u | ɨ | ɐ | ɨe | o |
| IV | higher and more palatal | i | y | iɨ | iɐ | e | ø |
But still other interpretations are possible: e.g., one or more grades may have been characterized by complex Marshallese-style diphthongs like the one in jok /tʲɜkʷ/ [tʲɛ͡ɔkʷ] 'shy'. In Marshallese, the diphthongs are allophones conditioned by palatalized, velarized, and labialized consonants, whereas in Tangut, such diphthongs would be phonemes. Tangut consonant phonemes had no secondary articulations.
Three factors complicate my quest for a better reconstruction:
First, I assume the four grades were coherent, transparent, and related to the four grades of Chinese phonology. I don't like my second reconstruction above because the grades are messier. Not all Grade III vowels have ɨ, and not all Grade IV vowels have i. Ideally I'd like each grade to have a signature characteristic in all of its vowels.
Second, neither Tibetan nor Chinese transcription data imply a lot of diphthongs. Either diphthongs were misread or approximated as monophthongs, or diphthongs simply did not exist in the dialects that were transcribed. The prestige dialect of the Tangraphic Sea with 105 rhymes could have been more phonetically complex than the dialects in transcription.
Third, if there were few or no diphthongs, I would have to reconstruct a lot of monophthongs. But does any language have 24 monophthongs that fit the 4 x 6 grid? (The four rows of course are the four grades; the six columns are based on the six vowel categories implied by Tibetan and Chinese transcriptions of Tangut and the Tangut transcription of Sanskrit.) If grades simply equaled heights for monophthongs, I doubt a language could have, say, four heights of i-vowels contrasting with four heights of e-vowels. Hence I reconstructed Grade I (i.e., lower) əi (by analogy with earlier Khmer i whose lowered reflex is əy) and Grade III ɨi (cf. ㅢ ŭi in Grade III Sino-Korean readings), avoiding monophthongs that would be confused with Grade II ɪ (which has no Khmer analogy) or Grade I e.
14.6.13.19:52: WHY DOES CH REPRESENT A GLOTTAL STOP IN PALAUAN?
I have been wondering that for some time, but I never found the answer until today. I had guessed that the spelling reflected an earlier stage when ch was [x], and I was right. According to Sakiyama (1995):
18th-19th century [q] > early 20th century [x] > modern [ʔ] ~ zero
The lenition might have started in the early 19th century since Iwasa has hororo as Iwasa's Japanese transcription of an early 1820s pronunciation of the word that is now Oreor [orɛor] 'Koror'. Perhaps that word had an initial uvular fricative [χ] - a halfway point between a uvular stop [q] and a velar fricative [x]. (The English spelling Koror may reflect an earlier pronunciation with [q]; Hockin's 1797 English-based transcription is Cooroora.)
I'm trying to think of other languages in which
- lenition was followed by fortition
- [x] or [h] hardened into a phonemic glottal stop distinct from phonemic zero
The only example of the former that comes to mind is Proto-Indo-European initial *gʷ- which lenited to Latin v- [w] which in turn hardened to Spanish b-: e.g.,
PIE *gʷíʕʷwoʕ > Latin vīvō > Spanish vivo [biβo]
As for the latter, is Palauan unusual or even unique in this respect, or am I overlooking an obvious example elsewhere?
I wish there were a dictionary of sound changes. I could look up [x] and find [ʔ] (or vice versa) with examples from Palauan.
APPENDIX: Does any living language have a word-medial consonant sequence ʕʷw like PIE *gʷíʕʷwoʕ? The only langauges I know of with ʕʷ are Lillooet and Shuswap; both are Salishan and without /w/.
I learned of Shuswap from Beekes' (1989) survey of "Pharyngeals and laryngeals in the languages of the world".
Maybe *gʷíʕʷwoʕ was phonetically *[gʷýʕwoʕ]; the labialization of */ʕʷ/ could have rounded the preceding vowel.Drifting even further from the original topic, how did Kurdish develop pharygeals in non-Arabic words like ʕawr < Proto-Iranian *abra 'cloud' (from Wikipedia)?
14.6.13.7:52: THE COPULAR CONCLUSION: OR, IS THIS THE END OF THE 'THIRD SERIES'?
After a promising start, my 'third series' hypothesis fell apart quickly, and now I'm going to pummel its final fragments into dust.
Although there are several words with spellings that I thought might indicate 'third series' dentals and palatals (i.e., alternations of <d> ~ <t> and <j> ~ <c>), I only know of a single word with a <b> ~ <p> alternation. If there really were a 'third series' labial, would it be only in a single word - even if that single word was a high-frequency copula? Moreover, the distribution of <b> and <p> spellings does not match the distribution ofspellings earlier in this series:
| Text | Date | <b.u> | <p.u> |
| 興宗 | 1055 | ✓ | |
| 蕭令公 | 1057 | ✓ | |
| 仁懿 | 1076 | ✓ | |
| 道宗 | 1101 | ✓ | |
| 宣懿 | ✓ | ||
| 許王 | 1105 | ✓ | |
| 耶律撻不也 | 1115 | ✓ | |
| 蕭仲恭 | 1150 | ✓ | |
| 萬部華嚴經塔 | 1173+* | ✓ |
<b.u> also appears on an undated yellow-glazed ceramic brush washer, but this may not be the copula since it does not appear in final position. If it is the copula, it may be the end of a relative clause modifying the last word:
......<u.ɣo b.u ja.en> '<ja.en> that is ... <u.ɣo>'
This table summarizes the distribution of supposed 'third series' spellings in the seven inscriptions that had all three types of initials:
| Text | Date | Labial | Dental | Palatal |
| 興宗 | 1055 | p | t | j |
| 蕭令公 | 1057 | p | t | c |
| 道宗 | 1101 | p | t | c |
| 宣懿 | p | t | c | |
| 許王 | 1105 | b | d ~ t | c |
| 耶律撻不也 | 1115 | b | t | c |
| 蕭仲恭 | 1150 | p | d ~ t | c |
No inscription consistently has voiced or voiceless 'reflexes' of the supposed 'third series'.
No inscription has purely voiceless 'reflexes' of the supposed 'third series' dental. Purple represents the coexistence of voiced (red) and voiceless (blue) consonants.
Such chaos is absent from a table of the reflexes of the three series of Proto-Indo-European stops in any single Indo-European language over a short time period (just a century!) or even Indo-European as a whole.
I confess that I don't know what this variation signifies. All I can say is that
- this class of words is mostly written with voiceless characters
- those voiceless characters are somewhat surprising given that their Mongolic cognates mostly have voiced initials: e.g.,
'to be': Khitan <p.u> vs. Proto-Mongolic *bü- (Janhunen 2003: 26)
'fourth': Khitan <t.ur>- vs. Mongolian dörbedüger
'left': Khitan <c.g.en> vs. Mongolian jegün
but <t.em> 'title' matches Mongolian temdeg 'mark'
I should be hesitant to draw conclusions based on a small number of words, but I'll try one more time to salvage the 'third series' hypothesis:
- The ancestor of Khitan and Mongolic had three obstruent series.
- Khitan inherited these three series.
- When Khitan was first written in the small script in the 10th century (why don't we have any 10th century small script texts?), the third series was written like the voiceless series.
But is there any other script like this: e.g., an alphabet with <p t k> invented for a language with [p b t d k g]? I can understand an alphabet with <p t k> originally invented for a language with [p t k] being recycled for a language with [p b t d k g].
- This convention was sporadically violated in later texts. Voiced series spellings for the third series may reflect how the third series became more like the voiced series (or how it simply merged with the voiced series).
- In Mongolic, the third series generally merged with the voiced series.
Temdeg with t- instead of the expected d- could be an archaism, a borrowing from a language or dialect without that merger, or be influenced by the t- of tamaɣan 'seal' (a borrowing from Turkic tamɣa).
I am far from convinced there was a third series, and I remain open to other explanations.
*The date of the 萬部華嚴經塔 inscription is unknown, but it includes the date
<HEAVEN doro.ɣa.am TEN THREE ai SIX MONTH TWENTY THREE DAY.de>
'on the 23rd day of the sixth month of the 13th year of Dading (i.e., 1173)'
so it must be from 1173 or later.
14.6.11.23:23: 'SECOND'-ARY <C>OMPLICATIONS
Right after I wrote "<d>ialects", I looked up the locations of the two Khitan small script inscriptions with <d> corresponding to <t> in other inscriptions on Andrew West's map. Both 許王 and 蕭仲恭 are near the Bohai Sea, whereas the other two post-1105 inscriptions with <d> are distant from it: 耶律撻不也 is north of the Bohai Sea and 郎君 is far southwest of the Bohai Sea. 蕭令公 with <t> from 1057 is close to where 許王 from 1105 is.
I concluded that there was a Bohai dialect (or '<d>ialect') which shifted the 'third series' dental to a sound written with <d> (possibly merging with d itself) by the beginning of the 12th century, whereas it remained a sound written with <t> (possibly merging with t itself) in other dialects (or '<t>ialects').
However, that conclusion ran into ... 'second'-ary complications when I looked at the distribution of spellings of words which might have had 'third series' palatals: <C.g.en> 'left', <C.ur>- 'second', and <n.ai.C> 'friendly'. I predicted that these words would be written with <c> (in blue) except in the Bohai dialect which would have <j> (in red) after around 1100. But a <j> spelling appears in 興宗 north of my hypothetical Bohai dialect area as early as 1055. 耶律弘用 (a.k.a. 耶律弘辨) from 1100 also has <j> and is north of my hypothetical Bohai dialect area. And no <j>-spellings are in two of the three hypothetical Bohai dialect inscriptions: 許王 and 蕭仲恭. (The nearby 耶律奴 inscription has <j> as I would expect.) If there was a 'third series', why would its dental and palatal develop in different ways in different regions at different times? No text has both <j> and <c> spellings of these three words, though perhaps there are doublets of other words absent from this table.
| Text | Date | <j.g.en> | <j.ur>- | <n.ai.j> | <c.g.en> | <c.ur>- | <n.ai.c> |
| 興宗 | 1055 | ✓ | |||||
| 蕭令公 | 1057 | ✓ | |||||
| 耶律仁先? | 1072 | ✓ | |||||
| 耶律高十 | c. 1076 | ✓ | |||||
| 耶律迪烈? | 1092 | ✓ | |||||
| 耶律智先 | 1094 | ✓ | |||||
| 耶律奴 | 1099 | ✓ | |||||
| 耶律弘用? | 1100 | ✓ | |||||
| 道宗 | 1101 | ✓ | ✓ | ||||
| 宣懿 | ✓ | ✓ | |||||
| 許王 | 1105 | ✓ | ✓ | ||||
| 耶律撻不也 | 1115 | ✓ | ✓ | ||||
| 蕭仲恭 | 1150 | ✓ | ✓ |
I have not seen 耶律仁先, 耶律高十, 耶律智先, 耶律奴, or 耶律弘用. I am relying on Kane (2009: 104, 143) for their spellings of 'left' and 'second'. I do not know if 'left' is in 耶律仁先, 耶律高十, 耶律智先, or 耶律弘用. I also do not know if 'second' is in 耶律奴.
Kane uses abbreviations for texts that are not in his key on pp. 9-12, so I had to make some guesses:
I think Kane's "Ren" is 耶律仁先 since <c.ur>- does not occur in 仁懿.
I think Kane's "Di" is 耶律迪烈 since he calls 韓迪烈 "Han Dilie" and does not include 蕭敵魯 (discovered in 2007) in his list of texts.
I think Kane's "Hong" is 耶律弘用 (a.k.a. 耶律弘辨), as he does not include 耶律弘本 (discovered in 1997) in his list of texts (though he did include 永清, discovered in 2003).
I don't know whether Kane's "Yong" with <c.ur>- is the undated 永清 or 耶律永寧 from 1088, so I have excluded it.
I have left out the undated 海棠山 with <c.ur>-.
Things are looking bad for the 'third series' hypothesis. They're about to get even worse.
Next: The Co<pu>lar Conclusion; or, This Is the End of the 'Third Series'.
14.6.11.12:11: <D>IALECTS AND <T>IALECTS?
If pre-Khitan had three series of obstruents, and if the third series merged with different series in different dialects, we could call dialects in which the third series dental merged with d '<d>ialects' and dialects in which the third series dental merged with t '<t>ialects'. (I use angle brackets since mixing italics and roman letters in the same word is awkward and d and t are written with the Khitan small script characters <d> and <t>. Are there any instances of the same word being spelled with both <da> and <ta>, <du> and <tu>, etc.?)
If <d>ialects and <t>ialects existed, we might expect one to be the standard and be in all the funerary inscriptions. But that's obviously not the case. So lowering our expectations, we might then expect each inscription to be written consistently in one dialect or the other. Was that the case? Let's look at the spellings of the five <d>/<t> words from my last post and <d.iu.er> ~ <t.iu.er> 'met?'* in the data from Qidan xiaozi yanjiu (1985):
| Text | Date | <d.093> | <d.em>- | <d.iu.er> | <d.iu.ir> | <d.p> | <d.ur>- | <t.093> | <t.em> | <t.iu.er> | <t.iu.ir> | <t.p> | <t.ur>- |
| 興宗 | 1055 | ✓ | ✓ | ✓ | ✓ | ||||||||
| 蕭令公 | 1057 | ✓ | ✓ | ||||||||||
| 仁懿 | 1076 | ✓ | ✓ | ||||||||||
| 道宗 | 1101 | ✓ | ✓ | ✓ | ✓ | ||||||||
| 宣懿 | ✓ | ✓ | |||||||||||
| 許王 | 1105 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
| 耶律撻不也 | 1115 | ✓ | ✓ | ✓ | |||||||||
| 郎君 | 1134 | ✓ | |||||||||||
| 蕭仲恭 | 1150 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
There are no <d>-spellings (in red) before 1105 - at least not in texts discovered up to 1985. Could the <d>-spellings of these words reflect an early 12th century innovation in the pronunciation of the prestige dialect of Khitan rather than a <d>-dialect coexisting with a <t>-dialect?
There are only two anomalous spellings (in purple): one in 許王 13.16 and another in 蕭仲恭 20.54. Perhaps the unknown author of the 許王 inscription and <is.g.ún x.ang.n.u>, the author of the 蕭仲恭 inscription, generally recorded their innovative pronunciation apart from two tradition-based lapses, whereas <ng.i x.ie.201>, the author of the 耶律撻不也 inscription, and the unknown translator of the 郎君 inscription used conservative spellings that may not have matched their pronunciation.
Next: Do <j> ~ <c> alternations have the same distribution as <d> ~ <t> alternations?
*The gloss 'met' is my guess based on how <d.iu.er> ~ <t.iu.er> corresponds to 會 'meeting' in the Khitan equivalent of the Jin Dynasty era name 天會 'heaven meeting' (1123-1137). <er> may be the masculine perfective suffix.
14.6.10.9:09: DID PRE-KHITAN HAVE THREE SERIES OF OBSTRUENTS?
Core 'Altaic' languages (Turkic, Mongolic, Tungusic) have two series of obstruents which are conventionally written as voiced and voiceless, though the distinction may in fact be one of aspiration in some cases (e.g., Khalkha Mongolian).
The peripheral 'Altaic' languages (Koreanic and Japonic) do not fit that pattern:
Korean today has three series of phonemic obstruents: unaspirated, aspirated, and tense. The latter two are of secondary origin. Ramsey proposed an earlier voiced series, but this is controversial. Voiced obstruents are allophones of the unaspirated series.
Japanese and Okinawan today have two series of obstruents: voiced and voiceless. However, the voiced series is secondary; it arose from nasal-voiceless clusters. (According to Vovin 2009, such clusters may have become unaspirated obstruents in Korean.) It is not clear whether Japonic had a prehistoric voiced series.
The comparative table below excludes the voiced series that may have been lost in Koreanic and Japonic:
| Core Altaic | - | d | t | - | |
| Koreanic | (*Nt > t?) | (/t/ [d]) | *ht, *th, *kt, *tk > th | pt, st, pst > tt | |
| Japonic | *Nt > d | - | - | ||
Previous reconstructions of Khitan follow the core Altaic pattern; they have two series of obstruents distinguished either by voicing or by aspiration.
Last night I proposed a third series for pre-Khitan to account for variation in certain words in Khitan. Here is a list of non-Chinese words with alternating obstruents in Kane 2009:
1. Labials
<p.u> ~ <b.u> 'to be' (cf. Proto-Mongolic *bü- as reconstructed by Janhunen 2003: 26)
2. Dentals
<t.093> ~ <d.093> 'south, lower'
<t.em> ~ <d.em> 'title' (cf. Mongolian temdeg 'mark')
<t.iu.ir> ~ <d.iu.ir> 'virtue'
<t.p> ~ <d.p> 'upright' (cf. Manchu tob, a loan from Khitan or a relative of Khitan?)
<t.ur>- ~ <d.ur>- 'fourth' (cf. Mongolian dörbedüger)
3. Palatals
<c> ~ <j> (converb)
<c.g.en> ~ <j.g.en> 'left' (cf. Mongolian jegün)
<c.ur>- ~ <j.ur>- 'second'
<n.ai.c> ~ <n.ai.j> 'friendly'
These alternations have a skewed distribution:
Place of articulation: Nearly all examples involve coronals. I can only find one example with labials (though the copula is a major word!) and I have never seen any examples with velars or uvulars.
Position in word: All dental examples have alternations only in initial position, whereas palatal alternations also occur in medial and possibly final position. (Final <c> and <j> may have represented open syllables rather than consonantal codas.)
The absence of back consonant alternations made me wonder if the third series in pre-Khitan was implosive: *ɓ *ɗ *ʄ. (Velar implosives are very rare; they are in only five languages in UPSID.) But labial implosives are more common than palatal implosives, so I would expect more labial than palatal alternations. (In UPSID, labial implosives are in 50 languages, whereas palatal implosives are in only 10 languages.)
Last night I reconstructed the third series as fricatives, but I don't know of any language in which a labial fricative hardened to p. (Of course labial fricatives are borrowed as p all the time: e.g., in Khitan, Korean, and Old Japanese.) Moreover, Khitan clearly had a palatal fricative ś that coexisted alongside the palatal affricates or stops c and j (whereas my proposed *ɸ ~ *β and *θ ~ *ð merged with p ~ b and t ~ d). Even if I reconstruct, say, *ɬ and *ɮ as sources of c ~ j, why would only certain fricatives harden while others (s, ś) remained intact?
I considered the possibility of the third series surviving in Khitan itself but lacking special symbols in the small script. (It would be interesting if syllables with third series consonants had special characters in the large script.) Is there any parallel for such an absence in a script designed for a language (as opposed to an existing script for one language adapted for another: e.g., Linear B)?
Next: <d>ialects and <t>ialects?
14.6.8.23:59: TWO SIX-<T> (PART 3)
According to Kane (2009: 98), there are four forms of 'four' in the Khitan small script:
<FOUR FOUR♂ 260.ur 260.ur>
The last two spellings are duplicates; one may have been intended to be
<t.ur>
since <260> and <t> look similar.
Kane (2009: 66) also glossed <260.ur> as 'fourth', though he did not include it in his list of forms of 'fourth' on pp.143-144:
| stem\gender | masculine -<er> | feminine -<én> |
| <t.ur>- |  <t.ur.er> |
 <t.ur.én> |
| <d.ur>- |  <d.ur.er> |
 <d.ur.én> |
In part 1, I mentioned that <260>
can also occur by itself and may be a variant of the word <t> (see the first example in part 2; the second example there is probably a Khitan name Tocauu):
Could these two words be yet more forms of 'four'?
How can all this variation be explained? I think there are four dimensions of variation. Kane covered the first two and mentioned but did not explain the third. The fourth is my own.
1. Cardinal vs. ordinal
If <260.ur> and <t.ur> are 'four', then the ordinals have gender suffixes absent from the cardinals.
It is also possible that <260.ur> is a neuter ordinal with no suffix or an ordinal in the sense that 一 'one' is an ordinal in Chinese 一等 'first class' (lit. 'one class'): i.e., it is translated as an ordinal in English, but it is not an ordinal in Khitan.
The problem is that I have not seen texts with <260.ur> or <t.ur>; neither is in Qidan xiaozi yanjiu. So I cannot determine for myself what they mean.
2. Masculine vs. feminine
Gender distinctions are indicated by suffixes in the ordinals, but the phonetic difference, if any, between the logograms <FOUR> (neuter as well as feminine?) and <FOUR♂> is unknown. Could the gender distinction be purely graphic for the cardinal numeral 'four' by analogy with other numerals which have graphically and phonetically distinct gender forms? Cf. English blond (m.) and blonde (f.) which are homophones. (Of course the two English words are borrowings from French [blɔ̃] and [blɔ̃d] which are not homophonous.)
Could <260.ur> and <t.ur> represent phonetic spellings of 'four' with two different genders? (6.9.0:24: If so, then maybe <260> and <t> were short forms of 'four' with different genders.)
3. <t> vs <d>
I used to think <t> ~ <d> mixture in Chinese loans was due to the incompatibility of a Khitan voiced : voiceless distinction with a Liao Chinese *unaspirated : *aspirated distinction, but that did not explain <t> ~ <d> mixture in Khitan native words such as 'fourth'. Moreover, Khitan also has <p> ~ <b> and <c> ~ <j> mixture in native and borrowed words: e.g., <p.u> ~ <b.u> 'to be' (Kane 2009: 156) and the converb <c> ~ <j> (Kane 2009: 153).. I considered the possibility that Khitan was like Korean with voiceless obstruents voicing in certain environments, but Khitan does not seem to have <k> ~ <g> mixture.
<t> and <d>
look too different to be variants of each other (see the discussion in Kane 2009: 65).
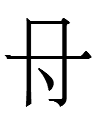
<p> and <b>
are even more different from each other.
These alternations only occur in certain words: e.g., <tau> 'five' is never *<d.au>, and <bo.qo> 'child' is never *<po.qo>. Could alternating words like 'four' and 'to be' have varying reflexes of pre-Khitan fricatives with nondistinctive voicing: e.g., *θ ~ *ð and *ɸ ~ *β? (Nonalternating words had proto-stops.)
4. Short vs. long
If <260> and <t> by themselves are 'four', they could be to <FOUR> <FOUR♂>, <260.ur>, and <t.ur> what Korean nŏ(k) and ne are to the standalone cardinal numeral net: short forms used to count certain items. Or they could be prefixes without gender distinctions like Sanskrit catur- 'four' (as opposed to the longer standalone forms with gender: masculine catvaras, feminine catasras, and neuter catvari).