




10.7.3.23:01: THE GOLDEN GUIDE: LINES 43-44: TANGRAPHS 211-220
43: I can't figure out a way to make a coherent sentence out of this, so I've split it in two:
Possessor (211-212) + Possessed (213); Noun (214-215)
| Tangraph number | 211 | 212 | 213 | 214 | 215 |
| Tangraph | |
|
|
|
|
| Li Fanwen number | 2975 | 3865 | 3360 | 1558 | 4751 |
| My reconstructed pronunciation | 1tsiiʳ | 2dziə̣ | 3nwə | 2mị | 1se |
| Tangraph gloss | government official | rank of nobility | eloquence | word; speech; to convince | clean; quiet |
| Word | palace secretary | ||||
| Translation | The eloquence of officials and nobles; the palace secretary, | ||||
211: What does 'bird' have to do with 'government official?
2975 1tsiiʳ 'government official' (jeogii)
3865 2dziə̣ 'rank of nobility' (voejeo = cuehanjeo) +
2262 1dʒwɨõ 'bird' (giigirwur)
212: This analysis and the one before it are circular.
=
3865 2dziə̣ 'rank of nobility' (voejeo = cuehanjeo) =
3819 2ləu 'seat; status' (cuehan = voe; cf. the 广 of 座 'seat') +
2975 1tsiiʳ 'government official' (jeogii)
jeo is a rare radical that should not be confused with gai 'high' and jel 'before':
<>
<>
jeo <> gai <> jel
213: The analysis of 3360 'eloquence' is unknown. It has a common left side (dex 'person') plus a right side that only occurs in 3384 2lõ 'throat; neck' (the source of sounds > eloquence?):
I have written the tone of 3360 as 3 to indicate that it belongs to the mysterious 'entering tone' category in Precious Rhymes of the Tangraphic Sea. This category only contains 11 syllables.
214: The reconstruction of 1558 is uncertain. It has no homophones. It looks like fun 'correct' (inspired by Chinese 正?) plus cun 'language' (< Chn 讠).
The Tangut title 'palace secretary' is literally 'quiet speech'.
+
4751 1se 'clean; quiet' (biociagoscen) =
5057 1ɣɛ 'true' (biohoodim; semantic - true = clean?) +
2931 1se 'to calculate' (ciagoscen; phonetic)
44: A noun phrase: (Possessor (Possessor (216-217) + Possessed (218)) + Possessed (219)) + Adjective (220)
| Tangraph number | 216 | 217 | 218 | 219 | 220 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 1531 | 0764 | 4916 | 3248 | 4922 |
| My reconstructed pronunciation | 1gia | 1rieʳ | 1ɣwe | 2riẽ | 2dwəəu |
| Tangraph gloss | army; soldier | horse | to struggle, to fight | scheme; strategem | secret |
| Word | |||||
| Translation | The secret strategem of army horse combat. | ||||
216: 1531 has 'military' on top (somehow derived from Chn 軍 'army'?) but so does 1535 for some unknown reason. The bottom of 1535 is 2541 2dzwio 'person'.
+
1531 1gia 'army' (puefeodex) =
1535 1lo 'to gather' (pueqaldex) +
2539 1kiạ 'fear' (feodex)
217: 0764 has 'horse' plus the filler radical cin. This simple tangraph probably predates the more complex tangraphs in its derivation:
+
0764 1rieʳ 'horse' (hincin) =
1115 1gie 'horse of the Earthly Branches' (hintol) +
5445 1rieʳ 'to play chess' (pikhincin; same word as 0764 written with pik 'hand' added to left)
218: I don't see what a surname (4835) has to do with 4916 'to struggle', unless 4835 was a combative clan.
+
4916 1ɣwe 'to struggle' (biozoocok) =
4835 ʔieʳ 'a surname' (biobaezoo) +
5205 ɣạ 'sword' (zoocok)
219: 3248 is a rearrangement of the radicals of 0572:
+
3248 2riẽ 'scheme' (dexbeeduu) =
0572 1tʃɨẽ 'scheme' (beeduudex) +
0797 1phi 'meaning; idea' (beeduucin)
0572 is of course derived from 3248:
+
And 0797 is derived from 0572 plus the right two-thirds of the homophone 0749 1phi 'to make':
220: The analysis of 4922 'secret' is unknown. It consists of a bio 'horned hat' (just a nickname; real function unknown) atop 3786 2reʳ 'shield' (dilqun; semantic; that which is shielded is secret):
+
10.7.3.2:22: THE GOLDEN GUIDE: LINE 42: TANGRAPHS 206-210
42: Locative (206-207) + Object (208-209) + Verb (210)
| Tangraph number | 206 | 207 | 208 | 209 | 210 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 0968 | 0289 | 5875 | 5613 | 5173 |
| My reconstructed pronunciation | 1riuʳ | 2vəi | 2ʒɨị | 2ziẹ | 0dʒɨị |
| Tangraph gloss | all; everyone | wall; city; castle | to sell | tax; duty | to pull up; to rescue |
| Word | |||||
| Translation | Sales taxes are extracted from all cities. | ||||
206: 0968 has a straightforward semantic + phonetic analysis:
+
0968 1riuʳ 'all' (fambaebilcin) =
0497 2ŋeʳw 'number' (windex; win = fam + dos) +
4713 1riuʳ 'world' (dulbaebilcin)
1riuʳ 'all' could be the same root as 1riuʳ 'world' (= all there is).
207: The phonetic 干 of 0289 could be based on Chinese 韦. Is 'amass' in 'wall' because walls consist of things that are piled up?
+
0289 2vəi (beldexcok) =
1768 2vəi 'black; 戊, the fifth Heavenly Stem' (belbaedexgon; phonetic) +
2063 1dziew 'to amass' (dexcok; semantic)
208: 5875 'to sell' consists of cur 'sell' + dex 'person'.
Li Fanwen (2008: 926) regarded 5875 2ʒɨị as a loanword from Chinese 市 'market' (a verb in early colloquial northwestern Chinese?). The tense vowel indicates a lost Tangut prefix: *S-ʒi > 2ʒɨị.
209: 5613 has 'hand' (pik) on the left plus a radical of unknown function (dim).
5613 ziẹ looks like Sino-Japanese 税 zei < Middle Chinese *ɕwiejh (the voicing of the SJ initial is irregular). However, if ziẹ were borrowed from Chinese, it should have a alveopalatal initial ʒ- followed by a medial -w- rather than an alveolar initial z- without a following glide.
ziẹ is from a pre-Tangut *Sɯ-(T)SeH with an *S- conditioning tension, a *ɯ conditioning the raising of *e, a *(T)S (= *ts, *tsh, *dz, *s, or *z) that lenited in medial position, and a final glottal conditioning the second (= 'rising') tone:
*Sɯ-(T)SeH > *Sɯ-(d)zeH > *Sɯ-zieH > *S-zieH > *zzieH > *zziẹH > 2ziẹ
210: 5173 is ter '?' + zax, which by itself is 0002 1lo 'filter'. I'll examine these radicals later.
In "A Roi-sonable Reading", I tried to explain why 理, normally read ri, represented roi < *rəwi in the Japanese name 物理 Motoroi/Modoroi. I proposed that the use of 理 for *rəwi reflected a nonstandard Late Old Chinese or Early Middle Chinese reading *ləiʔ as opposed to a standard LOC *lɨəʔ or EMC *lɨʔ.
Since Proto-Japonic *əi becomes Old Japanese *ɨ(y) after labial and velar stops and *i elsewhere, I briefly wondered if the normal reading ri could also be based on a LOC/EMC *ləiʔ, just as the native word ki 'tree' is from Old Japanese *kɨ(y) < Proto-Japonic *kə-i. (The original root *kə- became the ko- of modern 木陰 kokage 'tree shade', etc.) A *-w- between *-ə- and *-i blocked this monophthongization, so 理 *rəwi became modern roi rather than ri.
But then I realized why 理 ri can't be from LOC/EMC *ləiʔ. LOC/EMC *-əi corresponds to Go-on (= early Sino-Japanese) -e (early layer) and -ai (later layer), not Go-on -i. The Go-on -e readings were borrowed before a Japanese-internal shift of *-ai to *-əi (> later -e) and the Go-on -ai readings were borrowed after the shift and were not affected by it:
Why would LOC/EMC *-əi be borrowed as *-ai if Japanese also had *-əi? Late Middle Chinese *-əi was borrowed into Korean as *-ʌy rather than as *-əy. Perhaps LOC/EMC/LMC *-əi was phonetically *[ʌj] in the dialects known to Koreans and Japanese*. The Japanese thought *[ʌ] sounded more like their *a than their *ə, and borrowed it as *a.
| MC original | Pre-Old Japanese | Pre-Old Japanese vowel shift | Old Japanese | Later Japanese | |
| Early borrowing | *-əi [ʌj] | borrowed as *-ai | *-ai > *əy | *-əy | *-əy > -e |
| Late borrowing | none; was not borrowed yet | borrowed as *-ai | -ai | ||
Example of a doublet from Myougishou: 魁 クヱ kwe < *kwai (early borrowing), 火イ ~ 火以 kwai (later borrowing).
(Japanese -Vi is disyllabic whereas Japanese *-Vy was monosyllabic. The choice of -i or -j in Chinese depends on phonemic analysis or orthographic taste. Chinese -Vi is never disyllabic.)
If the Japanese heard 理 pronounced as *ləiʔ [lʌjʔ] (probably with a Paekche accent), they would have borrowed it as *rai which would have become modern re or rai depending on when it was borrowed.
I conclude that the use of 理 LOC/MC *ləiʔ [lʌjʔ] for Old Japanese *rəwi is doubly irregular:- A sinograph for *CVi without *-w- was used to write OJ *CVwi (any other examples?)
- LOC/MC *[ʌ] corresponds to OJ *ə instead of *a (any other examples?)
*The Chinese rhyme *-əi may have been *[əj] rather than *[ʌj] in the southern LOC/EMC dialect underlying the early strata of Sino-Vietnamese since it corresponds to SV -ơi [əəj]: e.g.,
代 LOC/EMC *dəih : SV đời [ɗəəj] but Sino-Korean tʌy (now tae), Sino-Japanese dai < *dʌjh from a different Chn dialect
亥 LOC/EMC *ɣəiʔ : SV hợi [həəj] but Sino-Korean hʌy (now hae), Sino-Japanese gai < *ɣʌjʔ from a different Chn dialect
10.7.2.3:06: SƏ-TI-VƏ, MƏ-VƏƏI NIƏƏ BƐƐ-RER!
I wish
Sə-ti-və
a
mə-vəəi niəə bɛɛ-reʳ
lit. 'birth day happy'
in Tangut.
Sə, pronounced 'suh', is a phonetic symbol. I use it to represent s.Ti, pronounced 'tee', can mean 'to remain' but can also represent a foreign syllable 'tee'.
Və, pronounced 'vuh', means 'husband'. I use it to represent v.
John Bentley asked me about the bizarre Japanese name 物理 Motoroi/Modoroi which is normally read as butsuri 'physics'.
The reading moto < *mətə for 物 'thing' reflects a southern Late Old Chinese *mɨət or *mɨt (cf. Colloquial Amoy mĩʔ).
In Early Middle Chinese, *ɨ(ə) rounded to *u after labials: *mɨ(ə)t > *mut.
In Late Middle Chinese, *m- generally shifted to *mv- before *u: *mut > *mvut. The normal Japanese reading butsu for 物 is from an Old Japanese *mbut, an approximation of LMC *mvut. Old Japanese had no *(m)v-, so *mb- was the closest available substitute.
The reading modo for 物 may reflect a dialect which had Korean-style intervocalic voicing of voiceless obstruents. Japanese -d- normally comes from *-nd-, but neither 物 nor 理 contain an *n. Perhaps the voicing of *-t- to -d- postdates the creation of the spelling 物理.
The reading roi < *rəwi for 理 'reason' is very strange at first glance. Almost no Sino-Japanese readings end in -oi. and none end in -oi < *-əwi. (The sole exception I know of is the late borrowing 焙 hoi < Early Middle Japanese *ɸoi.) The *rə is not entirely unexpected since 里 Late Old Chinese *lɨəʔ, the homophonous phonetic of 理, was used to write pre-Old Japanese *rə. But how can the *-wi be explained? Was 物理 an abbrevation of an earlier trisinographic spelling like 物理韋 with 韋 for wi? Maybe, but here's another solution:
理 was *mʌ-rəʔ in Early Old Chinese. This sesquisyllable was simplified in three ways:
1. Nearly all descendants of *mʌrəʔ have lost the presyllable *mʌ-without a trace:
*mʌ-rəʔ > *rəʔ > *lɨəʔ > *lɨʔ > *li > Mandarin li, etc.
2. In at least one dialect of southern Late Old Chinese, the presyllable lost its vowel and fused with *r-:
*mʌ-rəʔ > *mʌ-rəʔ > *mʌ-rəʔ > *mrəʔ > *mrəɨʔ > *mrəiʔ > *mrɛʔ > *mlɛʔ > borrowed into Vietnamese > Middle Vietnamese mlẽ [mlɛ] > modern Vietnamese nhẽ ~ lẽ 'reason' (cf. Sino-Vietnamese lý from Late Middle Chinese *li with no trace of the presyllable)
埋 *mʌ-rə, a near-homophone of 理, still has m- today:
*mʌ-rə > *mʌ-rə > *mʌ-rə > *mrə > *mrəɨ > *mrəi > *mrɛ > *mɛ > *mæj > Mandarin mai, etc.
3. The presyllable was lost after it conditioned emphasis (pharyngealization indicated by underlining) and vowel bending in the following syllable:
*mʌ-rəʔ > *mʌ-rəʔ > *mʌ-rəʔ > *rəʔ > *rəɨʔ > *ləiʔ
The *ləiʔ resulting from this third method of simplification may be the reading underlying the choice of 理 for Old Japanese *rəwi.
Kanjigen (2002 ed.) also lists three other unusual uses of 物 in Japanese:
物相, 盛相 mossou 'container for measuring rice'
物袋 Motte物生山 Mushiyama
The first two contain mot- (with assimilation to -sou in mossou) from southern Late Old Chinese *mɨət or *mɨt.
The reading mos- for 盛 is unusual. 盛 is normally mo- of mor- 'to pile up high, fill' (e.g., rice in a container) or mor-i. I can't think of any other cases in which a graph for CVrV is also read CVs- before a graph for s-.
The third at first seems to involve Early Middle Chinese *mut, but I don't know of any other cases in which 物 is read as mu and 生 as shi. I think 物生 'things grow' is a semantographic representation of mushi from the archaic root mus- 'to grow', normally written with 生.
Sagart (1999: 56) and Schuessler (2007, 2009) reconstructed Old Chinese (OC) without rhymes consisting of labial vowels followed by labial consonants: e.g., *-um, *-up, *-om, *-op. However, there are some old loans in southeast Asian languages suggesting that such rhymes might have existed: e.g.,
染 OC *namʔ(-s) 'to dye' : Proto-Tai *ɲuɔm C2 'to dye', Viet nhuộm [ɲuəm] 'to dye'
written as 氵 'water' + 九 'nine' (why?) + 木 'tree'; none of these elements are phonetic
南 OC *nəm 'south' : Viet nôm 'Vietnamese (i.e., southern) demotic script', nồm 'southern (of wind)'; part of old transcription 扶南 for OId Khmer ភ្នំ *bhnɔm 'mountain, hill' (> first syllable of modern Khmer ភ្នំពេញ Phnom Penh)
But these words could reflect innovations in southern OC dialects absent from other dialects: e.g., *-am > *-ɨam > *-ɨom > *-uom and *-əm > *-om. OC poetry lacking *-UM type rhymes could be more conservative than the sources of these borrowings into Tai and Vietnamese. OC rhyming keeps *-am and *-əm distinct whereas these southern dialects seem to have merged them into a single *-om category at one stage which then split when emphasis was lost:
| Emphasis | OC | Southern OC stage 1: before loss of emphasis | Southern OC stage 2: after loss of emphasis |
| - | *-am | *-om | *-uom (e.g., Proto-Tai, Viet 'to dye') |
| + | *-am | *-om | *-om (any examples?) |
| - | *-əm | *-om | *-uom (any examples?) |
| + | *-əm | *-om | *-om (e.g., Viet 'southern script; southern') |
There could have been a transitional stage *-ɔm between *-am and *-om.
Old Khmer *-nɔm may have been transcribed as OC *nəm ~ *nom ~ *nom with an (upper) mid vowel because there was no late OC *nam ~ *nɔm with a low or lower mid vowel.
Nonemphatic *n- palatalized to *ɲ-: *nom > *ɲuom but *nom > *nom.10.6.30.22:40: BÒ U
Why is 'zebu' bò u in Vietnamese instead of something like dê bu [ze ɓu]?
Bò is 'cow; ox; bull'*, but what is the u that modifies it? That u can't be any of these u (from Nguyễn 1966 and Bui 1992):
Native u:1. 'mother' (rural); (wet) nurse; 'I' (used by mother to child)
2. excrescence; swelling, swell; tumour; to swell
Sino-Vietnamese u:
幽 'to be dark; to be quiet, secluded'
*The similarity of bò < *bɔ to Latin bos and Greek bous is coincidental, as the latter come from Proto-Indo-European *gʷeHus with a totally different initial consonant.
Beekes (1995: 148) reconstructed the *H (his *H3) of 'cow' as a labialized pharyngeal *ʕʷ. Does any living language have such a segment? UPSID doesn't contain any.
10.6.30.8:24: MÁC-SAN
The title looks like what a Mac would be called in Japanese (マックさん) but is the Vietnamese name for a country. What is the country's name in English? Hints:
1. See my previous post on Gioóc-đa-ni.
2. Vietnamese s is pronounced like sh (and s is spelled x in Vietnamese: e.g., Xy-ri 'Syria' < French Syrie).
3. Vietnamese syllables cannot end in -l.
4. The full name of the country is Cộng hòa Quần đảo Mác-san. 共和 cộng hòa is 'republic' (note the absence of 國 quốc 'country' unlike Chinese 共和國 'republic') and 群島 quần đảo is 'islands' (literally 'herd').
Click here for the answer. More below (select the blank space):
The name of the country in Marshallese is Aolepān Aorōkin M̧ajeļ. I am surprised Marshallese has a native word for 'republic' (which must be either the first or second word). The Vietnamese word is non-Western but is a borrowing from Chinese.
Macrons on vowels indicate rounding:
a [ɑ] vs. ā [ɔ]
o [ɤ] vs. ō [o]
The cedilla indicates velarization.
Marshallese has a very complex phonetic inventory unlike its distant relatives Indonesian and Hawaiian. Its vowels are identical to the basic vowels in my reconstruction of Tangut if one rewrites my central vowels ɨ ə a as back vowels ɯ ɤ ɑ. Tangut may turn out to have diphthongs as complex as those of Marshallese.
The last tangraph of line 41 of the Golden Guide has an unusual radical hok that is in only three other tangraphs (1600, 1133, 1663):
Grinstead (1972: 112) glossed 3985 as '(camel)'!
=
+
1600 1thəu 'to set up; to build' (hokpak) =
1133 1thəu 'to mix' (hokpok; phonetic) +
3985 1kiaa 'foundation' (jorpak; semantic? something that has to be set up or built?)
1133 1thəu 'to mix' (hokpok) =
1600 1thəu 'to set up' (hokpak; phonetic) +
3078 1lwəu 'to mix; to blend' (circiapok; semantic)
=
1663 1lɔ̣ 'to mix; to stir' (hokyao; cognate to 3078 1lwəu and 4850 1lwəụ?) =
1600 1thəu 'to set up' (hokpak; why?; error for 1133 1thəu 'to mix' which would be semantic?) +
4850 1lwəụ 'to mix; to blend' (biocirciapok; bio + pok = yao; cognate to 3078 1lwəu)
hok represents the syllable 1thəu in 1133 and 1600 and is probably an abbreviation for 1133 'to mix' in 1663 'to mix'. Either 1600 or 1663 was probably created first, as 1133 seems to be the bridge between the two:
1600 > homophone 1133 > synonym 1663
1663 > synonym 1133 > homophone 1600
Is hok a distortion of a sinograph pronounced like 1thəu or meaning 'mix'? I can't think of any Chinese prototype. There are 'mix' tangraphs that don't contain hok (e.g., 3078 and 4850 above with cir 'water') and 1thəu tangraphs that don't contain hok such as 3565:
=
3565 1thəu 'to count' (dexpak) =
0497 2ŋeʳw 'number' (windex)
3576 1swie 'clear' (dexduupak)
which has pak like 1600 hokpak. Why create a radical for only some 1thəu and/or some 'mix'?
10.6.29.0:19: GIOÓC-ĐA-NI
Why is 'Jordan' Vietnamized as Gioóc-đa-ni [zɔk ɗa ni] instead of, say, Gio-đa-ni?
Generally, Vietnamizations of foreign names are irrecognizable if they were filtered through Chinese: e.g., Pháp [faap] 'France', the Sino-Vietnamese reading of 法 Mandarin Fa < Late Middle Chinese *fap. (I don't know what Chinese language was originally the basis of 法 Fa < 法蘭西 Falanxi 'France', but it must have been a language like Mandarin in which the *-p of 法 was lost.) Some names have multiple versions: e.g., 'Paris':
巴黎 Ba Lê (filtered through Chinese; the name of my favorite fast food franchise in Hawaii)
Pa-ri (directly from French with an un-Vietnamese p-; original Vietnamese *p- shifted to b-)
Paris (the French spelling as is)
Any cases of Cantonese -k : foreign -r? I assume that Cantonese 柏林 Baaklam 'Berlin' was coined by a Mandarin speaker since Md 柏林 Bolin is closer to the original. (Japanese 伯林 Berurin 'Berlin' with a slightly different first character may be based on an earlier Mandarinization of Berlin, since the Sino-Japanese reading haku for 伯 sounds nothing like Ber-.)
I was surprised to learn that the standard Arabic name for Jordan has no j- or y-: الأردن al-Urdunn. Where does the J- come from?
10.6.28.3:36: THE GOLDEN GUIDE: LINE 41: TANGRAPHS 201-205
41: Location (201-202) + Object (203-204) + Verb (205)?
| Tangraph number | 201 | 202 | 203 | 204 | 205 |
| Tangraph |  |
 |
 |
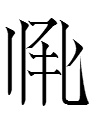 |
|
| Li Fanwen number | 1136 | 0785 | 5979 | 2708 | 1600 |
| My reconstructed pronunciation | 2gəu | 2bɨu | 1be | 1riaʳ | 1thəu |
| Tangraph gloss | middle; among | border; side | to tie; to arrest; to detain | to manage; government ministry | to set up; to build |
| Word | |||||
| Translation | At the middle border, the ministry of arrests was established. | ||||
My translation must be wrong. What is a 'middle border'?
I can't find 5979 2708 as a compound in Kychanov (who has extensive experience translating Tangut legal documents), so I doubt such a ministry existed. It may be an error for a homophonous verb 5979-5913 'to connect; to unite' which may be a noun and hence the object of 1600: 'The middle border connection was built.' But that doesn't make much sense either.
201: 1136 looks like 'horse' + 'person' + 'tiger' (< Chn 馬, 人, 乕) - a person among animals?
202: 0785 has beu ('see' in Nishida 1966: 244, 'pierce; eye' in Grinstead 1972: 15) plus the common right-hand radical cin.
+
0785 2bɨu 'border' (beucin) =
0335 1phia 'border' (beubaebeu; is bae a vertical line representing a separator?)
0026 2ŋwəu 'territory' (baagaicin; gai = 'high')
0785 2bɨu is a rare example of a Grade III labial-initial syllable. It contrasts with Grade IV 1119 2biu 'elephant'.
203: 5979 looks like 5810 'belt; girdle; ribbon' (which of course has a circular analysis) plus 'hand'.
+

5979 1be 'to tie' (parpik) =
3782 2zəu 'to tie up' (gerpas; 'person' on left) +
5472 2be 'cord; rope; string' (pikheu; < *beH 'cord' derived from1be 'to tie'?)
=
5810 adsfa 'belt; girdle; ribbon' (par) =
top right of 3782 2zəu 'to tie up' (gerpas) +
bottom left of 5979 1be 'to tie' (parpik)
The analysis of 5810 is highly improbable. 5810 must predate 3782 and 5979.
204: 2708 looks like 'not' + 'tiger' + the mysterious radical cin.
+
2708 1riaʳ '' (ciafalcin)
1910 2tiẹ̃ 'ceremony' (ciabaapikcin)
5913 1riaʳ 'at a distance' (curfalcin; phonetic)
falcin is also a phonetic in other 1/2riaʳ tangraphs.
205: 1600 has a rare left radical hok. I'll discuss the analysis of 1600 and other hok tangraphs in a separate entry.
10.6.27.23:59: CELEBRATING THE 200TH TANGRAPH: TYPEABLE TANGUT
I am uncomfortable with the reconstruction I've been using over the past two years or so because I keep changing my mind about some of the phonetic details. Moreover, typing the IPA symbols is time-consuming and slowing down my output. So I've been thinking about switching to a more phonetically agnostic reconstruction after I'm done with the Golden Guide which should be consistently romanized. I can't switch to a maximally agnostic reconstruction because it would be nothing more than a Homophones chapter number, Homophones group number, and tone.rhyme number. For a while I considered indicating the grades with diacritics, but more recently thought of using numbers like Arakawa*. Here's rhyme groups II and III in three types of notation:
| Rhyme group | Cycle | Grade | Rhyme | Current notation | Diacritic notation | Number notation |
| II: oral -i | plain | I | 8 | -əi | -ì | -i |
| II | 9 | -ɪ (or -ʌɪ?) | -î | -i2 | ||
| III | 10 | -ɨi | -ï | -i3 | ||
| IV | 11 | -i | -í | -i4 | ||
| I | 12 | -əə | -ì' | -i' | ||
| II | 13 | -ɪɪ (or -ʌʌɪ?) | -î' | -i'2 | ||
| III | 14 | -ɨii | -ï' | -i'3 | ||
| IV | -ii | -í' | -i'4 | |||
| tense | I | 68 | -əị | -ìq | -iq | |
| II | 69 | -ɪ̣ (or -ʌɪ̣?) | -îq | -iq2 | ||
| III | 70 | -ɨị | -ïq | -iq3 | ||
| IV | -ị | -íq | -iq4 | |||
| retroflex | I | 82 | -əiʳ | -ìr | -ir | |
| II | 83 | -ʌɪʳ (or -ʌɪʳ?) | -îr | -ir2 | ||
| III | 84 | -ɨiʳ | -ïr | -ir3 | ||
| IV | -iʳ | -ír | -ir4 | |||
| I | 99 | -əəʳ | -ìr' | -ir' | ||
| III | 101 | -ɨiiʳ | -ïr' | -ir'3 | ||
| IV | -iiʳ | -ír' | -ir'4 | |||
| III: nasal -i | plain | I | 15 | -əĩ | -ìn | -in |
| III | 16 | -ɨĩ | -ïn | -in3 | ||
| IV | -ĩ | -ín | -in4 |
The notation for other rhymes is similar. The other base vowels are u, a, y (cf. the romanization of Russian ы; equivalent to Arakawa's capital I), e, and o.
There are no grade II long retroflex or nasal -i rhymes: *-ir'2, *-in2.
Now that I see the diacritics in small type on a computer screen instead of atop giant letters in my head, I realize that they are almost indistinguishable. A shame, because they are more meaningful than mere numbers:
Grade I: grave (representing lowered vowels)
Grade II: circumflex (a carryover from Sofronov's notation; also indicates that II shares characterstics of the lower and higher grades: vowels even lower than those of I and alveopalatal initials which also occur in III and IV but not in I)
Grade III: diaeresis (short for ï = IPA ɨ)
Grade IV: acute (representing raised vowels)
Other characteristics of rhymes:
-': an unknown distinction (carried over from Arakawa who also uses this for initial glottal stop, so I presume he uses it for final glottal stop after vowels)
-q: tenseness (carried over from Arakawa)
-r: vowel retroflexion (carried over from Arakawa)
-n: vowel nasalization (carried over from Sofronov and Arakawa)
Initial consonants would be written more or less as in Arakawa's notation.
Here's the reconstruction of the readings of tangraphs 191-200 of the Golden Guide in my current notation, number grade notation and lay notation without numbers:
191-195:
I think I'll stick to my current notation.2mieʳ 2dza 2ʔiu 2khie 1mi
2mer4 2dza1 2'u4 2khe4 1mi4
mer dza 'u khe mi
196-200:
2kõ 2ni 2zəuʳ 1ŋwəəu 1vɨạ
2kon1 2ni4 2zur1 1ngwu'1 1vaq3
kon ni zur ngwu' vaq
*6.28.2:06: Arakawa differentiates between a few rhymes with final numerals which unlike mine do not correspond to grades:
| Rhyme | Arakawa grade | Arakawa | My grade | Current notation | Number notation |
| n/a | I | (-eq) | n/a | ||
| 76 | -eq2 | II | -ɛ̣̃ | -enq2 | |
| n/a | (-eq') | n/a | |||
| 78 | -eq'2 | II | -ɛʳ | -er2 | |
| 63 | II | -yeq | -ɛ̣ | -eq2 | |
| 77 | -yeq2 | I | -eʳ | -er | |
| n/a | (-yeq') | n/a | |||
| 79 | -yeq'2 | III/IV | -ɨeʳ, -ieʳ | -er3, -er4 | |
| 94 | -yer | IV | -iʳw | -iwr4 | |
| 101 | -yer2 | III/IV | -ɨiiʳ, -iiʳ | -ir'3, -ir'4 | |
| 73 | I | -oq | I | -ọ | -oq |
| 102 | -woq2 | -ooʳ | -or' | ||
In some cases, there is no non-2 rhyme corresponding to an Arakawa -2 rhyme: e.g., Arakawa has no -eq, but has an -eq2.
I more or less follow Gong's grades, vowels, and rhyme groups which differ considerably from Arakawa's. I would like to investigate these differences and determine which reconstruction, if any, best fits the evidence.


































