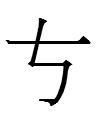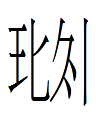
14.5.28.16:52: FROM NAGARA TO ANGKOR
I've long been bothered by the derivation of Khmer អង្គរ <aṅgara> [ʔɑŋkɔː] (the Angkor of Angkor Wat) 'city' from នគរ <nagara> [nɔkɔː] 'id.'. The latter is obviously from Sanskrit and/or Pali nagara- 'city'. But the former has an initial vowel absent from the Indic original. However, if the two words are unrelated in spite of their undeniably similar structure (*nasal-g-r) and semantics, where did the first come from? A disyllabic root is un-Khmer.
Today I think I figured out how nagara- became [ʔɑŋkɔ] after reading this article on newly discovered paintings at Angkor Wat. 1-3 and 7-9 are common changes in Khmer. 6 might be unique to this word.
1. a > ɔ at some point before the words reached Cambodia: nagara- > nɔgɔrɔ-
cf. Bengali নগর nɔgɔr
2. Loss of final vowel: nɔgɔrɔ- > nɔgɔr (the source of នគរ <nagara> [nɔkɔː])
3. Lengthening of stressed final vowel: nɔgɔr > nɔgɔːr
4. Loss of unstressed first vowel: nɔgɔːr > ngɔːr
cf. guru- > guruː > គ្រូ gruː (now [kruː]) 'guru'
5. Assimilation of dental n to velar g: ngɔːr > ŋgɔːr
Could this ŋ have been syllabic [ŋ̍]?
6. Prothetic vowel with obligatory preceding glottal stop to break up un-Khmer initial consonant cluster: ŋgɔːr > ʔɔŋgɔːr
7. Lowering of vowels after voiceless consonants: ʔɔŋgɔːr > ʔɑŋgɔːr
8. Obstruent devoicing: ʔɑŋgɔːr > ʔɑŋkɔːr
9. Loss of -r with compensatory lengthening: ʔɑŋkɔːr > [ʔɑŋkɔː]
I finally got around to using the late Philip
Jenner's online Dictionary of
Old Khmer today. Jenner reconstructed the first vowel of
<aṅgara> as a schwa in Old Khmer and regarded the word as "a
metathesis of Skt and Pāli nagara": i.e., the first consonant
and vowel switched places.
nɔgɔːr > ʔɔngɔːr > ʔəŋgɔːr
I am reluctant to reconstruct a metathesis when there is an
alternative with known parallels. If guruː lost its
unstressed first vowel, perhaps nɔgɔːr did too.
14.5.27.22:57: WHY IS KHITAN RELATED TO MONGOLIC?
In the preface to The Kitan Language and Script, Kane (2009: ix) wrote,
Kitan is a largely undeciphered language [..] it has no known cognate languages [...] some native Kitan words have been tentatively identified on the basis of these [Chinese] transcriptions, possible cognates in other languages, and more often than not, educated guesswork. Nevertheless, even when Kitan words, and whole sentences, are transliterated, they do not yield anything resembling Mongol, Jurchen, Turkic or any other attested language.
[...]
As for cognate languages, some of the numerals, the seasons and the names of some animals are clearly similar to Mongol, wheather through affinity or borrowing we cannot tell. Kitan is indisputably 'Altaic' in the broad sense, with vowel harmony, agglutination, case markers and subject-object-verb syntax.
[...]
And although there is a supposition that Kitan will eventually turn out to be related to some form of proto-Mongol, if only the right readings for the graphs could be determined, and although some words are indeed similar to Mongol, no sense can be extracted from transcribed texts with a knowledge of Mongol.
Kane alternated between total pessimism ("not yield anything", "no sense") and a more moderate attitude that fortunately dominates his book.
I share that latter attitude. We do know quite a bit about Khitan (my preferred spelling), and we can know more. The known corpus is growing. Viacheslav Zaytsev recently identified Nova N176 as a Khitan large script text - the largest Khitan text in either script - just four years ago. More texts will probably be found in the future. Khitan is not the language of the Phaistos Disc. There is hope.
But is there enough to speculate about the genetic affiliation of Khitan? I think there is.
As Kane noted, Khitan belongs to the 'Altaic' area, though instances of modified-modifier order are un-Altaic. (I plan to present more examples in a future post.) Typological similarities do not entail genetic affiliation: e.g., Thai, Vietnamese, Hmong, and Chinese are typologically similar - down to the structure of their tonal systems - but belong to four different language families.
Shared vocabulary also does not entail genetic affiliation: e.g., a qa-type word for a 'leader' (of probable Xiongnu origin) is in Turkic, Mongolic, Jurchen/Manchu (I don't know about the rest of Tungusic), Old Korean, and, of course, Khitan:
<qa> 'khan' (was this word written as 上 <qa> in the large script, and was the shape of Chinese 上 'top' borrowed to write qa because a qa was the top man?)
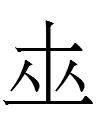
Juha Janhunen is normally skeptical of proposals of genetic affiliation, so I was surprised to see him state that the Khitan small script character
<tau>
was "of importance for the genetic identification of the Khitan language" (1994: 120; emphasis mine) since it represented both 'five' (cf. Mongolian tabun 'id.') and the first syllable of
<tau.lí.a> taulia 'hare'
(cf. Mongolian taulai 'id.' with the final vowels in the opposite order; see here). Although there is no doubt that the Khitan words for 'five' and 'hare' are related to those of Mongolian, that does not necessarily mean the Khitan language is related to Mongolian, since number and animal names can be borrowed: e.g., Korean o 'five' is from Late Middle Chinese *ŋó and thokki 'hare' may be a loanword from Late Middle Chinese 兔 *tʰò 'id'.
Two shared words may be crucial:
Khitan pu- ~ bu- 'to be' : Proto-Mongolic *bü- 'to be' (as reconstructed by Janhunen 2003: 26)
but beware of chance similarity; e.g., Sanskrit has √bhū 'to be'.
Khitan a- 'to be' : Proto-Mongolic *a- 'to be' (as reconstructed by Janhunen 2003: 26)
but beware of chance similarity; e.g., Sanskrit has √as < *ʔes 'to be'.
However, I think shared morphology is the best evidence for the genetic affiliation of Khitan. Here is a list of Khitan suffixes with parallels in Janhunen's (2003) Proto-Mongolic:
K -(V)d 'plural' : PM *-d
K -(V)s 'plural' : PM *-s
K -ər 'accusative/instrumental' : PM *-xAr < *-pAr 'accusative'
coincidence?; did medial *-p- lenite to zero in Khitan?
K -(V)n 'genitive' : PM *-n
K -dV 'dative-locative' : PM *-d
K -c, -j 'perfective converb' ('after') : PM *-jU 'imperfective converb' ('at the same time as')
coincidence?; the semantics don't match!
K -lɣa-/-lgə- 'causative/passive' : PM *-lgA- 'causative'
(Many Khitan suffixes do not resemble anything in Mongolic: e.g., the Khitan masculine perfective -Vr and the feminine perfective -en [which might have allomorphs with other vowels] lack Mongolic cognates.)
Grammatical suffixes are less likely to be borrowed than words. Unfortunately, some of those suffixes are so short that chance similarities are possible: e.g., English also has an -s plural, Finnish has an -n genitive, Korean once had a *-(V)r accusative, and Japanese has a locative -de < -ni-te. So morphology is not absolute proof. The strongest of the comparisons is the causative since it contains more than a single consonant. Longer similar strings with similar semantics are more likely to share common origins. Of course, two consonants and a vowel aren't very long ...
14.5.26.23:59: <AL.L>-OPHONY: L-SEQUENCES IN THE KHITAN SMALL SCRIPT
In "Did Khitan Have Two Laterals?" I proposed that
098 and 261
respectively represented velar ɫ and dental or alveolar l. I thought
- ɫ was to l what uvular q and ɣ were to velar k and g
- backer consonants (ɫ q ɣ) and fronter consonants (l k g) were in complementary distribution
- and respectively associated with lower and higher vowels
In short, I hoped that 098 and 261 were like Old Turkic 𐰞 <ł> and 𐰠 <l>. But in fact the two characters can coexist in the same word, and Andrew West pointed out they can even be next to each other: e.g.,
098-261-151-341 <098.261.ɣ.er>
053-098-261-090-152 <qa.098.261.ó.j>
Qidan xiaozi yanjiu (1985: 227-228) has six more examples of initial 098-261 sequences. I do not know of any other 098-261 medial sequences.
I have also found one example of a 261-261 sequence:
309-261-261-112-341 <ɣó.261.261.ge.er>
I have not seen any 098-098 sequences yet.
How were the three words above pronounced? Here are some approximations using various systems I have on hand. Transcriptions are in italics and transliterations are in roman. Slashes separate multiple possible transliterations. I have rewritten Kane and Wu and Janhunen's <h> as <ɣ>.
| Block | This site | Kane 2009 | Aisin Gioro 2012 | Liu et al. 2009 (in AS 2012) | Wu & Janhunen (in AS 2012) | Pre-2002 (in AS 2012) | Qidan xiaozi yanjiu 1985 |
 |
lalɣər | al.l(e).ɣu.er | al.l.q(a).ər | li.lə.ɣə.li | al.l.ɣu.ri/il/er | ɑl.l.ɣ.wei | ?.l.ɣ.uei |
 |
qa(a)lloj or qalaloj | qa.al.l.ó.j(i) | qa.al.l.o/u.dʒi | xɑli.lə.ʊ.tʂi | qa.al.l.ó.ji | xɑ.ɑl.l.ʊ.su | xɑ.?.l.ʊ.ku |
 |
ɣolləgə(ə)r, ɣoləlgə(ə)r, or ɣolələgə(ə)r |
ɣó.l(e).l(e).ge.er | bə.l.l.gə.ər | u.lə.lə.nie.li | ɣó.l.l.ge.ri/il/er | ?.l.l.g/ɣə.wei | ?.l.l.kə.uei |
Currently I think 098 can be read as al or la (I am now agnostic about whether that l was velar or not) while 262 can be read as l, əl, or lə.
Here is the reasoning behind my readings of the three words (whose meanings are unknown to me):
1. lalɣ-ər '?-ACC/INST':
A block of the first three characters (098-261-151) without 341 is attested and must be the stem.
I assume this is a noun because the accusative/instrumental suffix -er does not change regardless of the vowels that precede it (cf. Altaic invariable accusatives: Manchu be 'ACC' and modern Korean -(r)ŭl*), whereas the masculine perfective suffix -Vr does change. The masculine perfective of a hypothetical verb *lalɣ- would be *lalɣ-ar.
To avoid a root-internal sequence of three consonants which is unlikely in Altaic (allɣ-er) and a disharmonic a-e sequence (laleɣ-er or alleɣ-er), I chose to reconstruct a stem ending in two consonants: lalɣ-.
2. qa(a)lloj or qalaloj '?'
To avoid a disharmonic a-e sequence (qa(a)leloj), I chose to reconstruct a medial cluster of two consonants (qa(a)lloj) or a second a (qalaloj).
3. ɣolləgə(ə)r, ɣoləlgə(ə)r, or ɣolələgə(ə)r '?'
I have not seen the first four characters by themselves, so I do not know whether this is a stem plus the fifth character or a five-character bare root.
To avoid a root-internal sequence of three consonants which is unlikely in Altaic (ɣollgə(ə)r), I chose to break up the cluster with a schwa: ɣolləgə(ə)r, ɣoləlgə(ə)r, or ɣolələgə(ə)r.
*5.27.3:18: In earlier Korean, there were five allomorphs of the accusative suffix:
| stem final \ stem vowel type | yin | yang |
| consonant | -ɯr | -ʌr |
| vowel | -rɯr | -rʌr |
| -r | ||
MK na-r ~ na-rʌr > modern na-rŭl [narɯl] 'me'
MK nu-r ~ nu-rɯr > modern nugu-rŭl [nugurɯl] 'whom' (the -gu is an interrogative ending that became part of the stem)
According to Lee and Ramsey (2011: 188), the -rVr forms are "believed to represent a doubling of the particle". They believe that the -nVn forms of the topic particle have a similar origin. Are there any other cases of such doubling outside Korean?
14.5.25.23:59: <RA>-CONSTRUCTION 7: THE LAST HUR-<RA>
I forgot to mention the following wild notion in part 6, so I'm going to add one more installment to this series.
If
was (1) the Khitan equivalent of 'Liao' and (2) pronounced <xu.ra> (Kane 2009: 162), what if the mysterious036-177 <xu*.?>
261-362-084 <l.iau.ra>
was another spelling of that word?
If Khitan small script characters had multiple dissimilar readings (as opposed to multiple related readings like <ra> ~ <ar> which I proposed for 084; see Kane 2009: 33), could groups of characters be read like nonhomophonous (near-)synonyms? Could 261-362 <l.iau> double as a special spelling of xura with 084 <ra> added as a phonetic clarifier to tell the reader to read 261-362 as xura rather than as the default liau? Such usage has parallels in Japanese jukujikun:
| Reading | Regular (sum of its parts) | Irregular with phonetic clarifiers |
| Khitan |  <l.iau> liau 'Liao' (unattested!) |
 <l.iau.ra> xura 'Liao' (not *liaura) |
| Japanese | 美味 <BEAUTY.FLAVOR> bimi 'good flavor' 流行 <FLOW.GO> ryūkō 'vogue' |
美味しい <BEAUTY.FLAVOR.shi.i> oishii 'delicious' (not *bimishii) 流行る <FLOW.GO.ru> hayaru 'be in vogue' (not *ryūkōru) |
However, there are several problems with this idea:
1. The reading of 036-177 'Liao' is uncertain; 177 may not have been anything like <ra>:
<us> (pre-2002; unattributed in Aisin Gioro 2012)
<lus>, <lij> (unattributed in Kane 2009: 164)
<ris> (Aisin Gioro n.d. according to Kane 2009: 164)
<ulji> (Aisin Gioro 2006)
<li> (Liu et al. 2009)
2. 261-362 is unattested as 'Liao'. Why add <ra> to disambiguate xura from a liau that may not have even existed?
3. Allowing this kind of arbitrary reading opens up a free-for-all Pandora's box. What constraints will prevent scholars from proposing any reading they want for character sequences as well as for single characters?
5.26.1:10: Polyphony is not an impossibility, but it does mean that much of Khitan might be forever out of reach.
Japanese polyphony has been extensively documented. If not for (1) explicit equations of spellings like 流行る with all-kana equivalents はやる in dictionaries and (2) furigana for spellings like 流行る, would it be possible for future scholars to figure out how 流行 was read in 流行る?
Old Korean has spellings of the 流行る type**: e.g., 夜音 <NIGHT.m> for 'night'. That spelling is generally interpreted as *pam, an ancestor of Middle and Modern pam 'night', but in theory it could be an unrelated word for 'night' that also happened to end in *-m.
The situation with single-character Old Korean semantograms without phonetic clarifiers to narrow down possible readings is even worse: e.g., Old Korean 春 <SPRING> is generally interpreted as *pom, an ancestor of Middle and Modern pom 'spring', but in theory it could be an unrelated word for 'spring' that could have been to pom what English fall is to autumn.
*036 is certainly something like <xu> or <hu> because it was used to transcribe Chinese 虎 *xu 'tiger'. Moreover, it may correspond to 和 *xo in Old Mandarin transcription (Kane 2009: 163).
**5.26.1:14: Note, however, that the phonetic clarifiers of Japanese 美味しい and 流行る indicate the final syllables of inflected adjectives and verbs including their endings (oishi-i, hayar-u), whereas the phonetic clarifier of Old Korean 夜音 indicates the end of a noun stem without an ending.