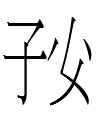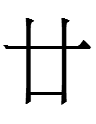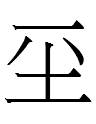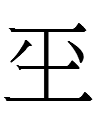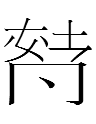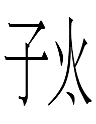
<149.ung> (郎君 5-29 etc.), <149.ung> (蕭仲恭 22-56)
14.5.17.23:57: PHILIAL PHONETICS
Andrew West asked me for the logic behind the reading <ju> for the Khitan small script character 149 子 from "That Year ... the Prince of ... ?". Here goes:
A lof of Khitan small script character readings have been identified on the basis of correlations between Khitan small script character blocks and Liao Chinese character readings*. 149 is no exception. It appears in the transcriptions
<149.ung> (郎君 5-29 etc.), <149.ung> (蕭仲恭 22-56)
for Liao Chinese 中 *tšuŋ. Hence Qidan xiaozi yanjiu (1985: 152) reconstructed 149 as <tʃ>, corresponding to <j> in the Kane (2009)-based transcription system on this site.
Qidan xiaozi yanjiu also reconstructed the similar-looking 150
as <tʃ> = my <j>. If 149 and 150 represented the same consonant, why add a vertical consonant every once in a while? And why would there be seemingly little overlap between the environments of 149 and 150? The closest match between the two I can find is in these words:
<149.ɣa.ai.l.ɣa.a.ar> (仁懿 29-21) and <150.ɣa.ai.l.ɣa.a.al> (耶律撻不也 10-11)
Those words consist of a verbal root
<jV.ɣa.ai> (zero-suffix finite imperfective?; 許王 29-3)
with the causative/passive suffix <l.ɣa> and the masculine perfective <ar> or the converb <al>. (I don't know whether the <a> before the final suffixes indicates a long vowel or is redundant.) I will return to these words later.
While 150 often combines with <a>-type characters (albeit not <a> itself!),
<150.ai 150.ar 150.an 150.as.ii 150.ang 150.án>
149 often combines with <u> characters: e.g.,
in addition to the two spellings of <151.ung> above. This is probably why Kane transcribed 149 as <ju> and 150 as <ja>. I have not found any instances of <150.a>, perhaps because 150 was sufficient to write ja, and Khitan may not have had any open syllable jaa with a long vowel. Conversely, I have not found any instances of <149.u>, possibly for the same reason: 149 was sufficient to write ju, and Khitan may not have had any open syllable juu with a long vowel.
It is not clear whether repetitive vowel sequences in the small script represent long vowels: e.g., did <ju.un> 'summer' represent juun with length lost in Mongolian jun 'id.'? Or was <ju.un> simply jun?
For completeness, here are all the other 149-initial words listed in Qidan xiaozi yanjiu:
1. <ju.ɣa.a.ai> (仁懿 30-8)
may be a variant of the verb <ju.ɣa.ai> above.
The same root may be in
2. <ju.ɣ.ai.ún> (興宗 18-21)
3. <ju.ɣ.e> (蕭仲恭 2-7)
The former has a perfective participle suffix; the latter is unusual because it contains both <ɣ> and <e> which are not expected to go together if Khitan had harmony similar to Mongolian and Manchu. Could <e> be a contraction of <ai> in the other forms of the root?
Kane (2009: ) read the latter as a noun
corresponding to the name 术里者 *šuliče ~ *juliče in Liao Chinese transcription. (The reading *ju is based on Hphags-pa ꡄꡦꡟ <cÿu> which Coblin 2006: 131 interpreted as *dʐy.)
术 *šu may undedrlie Aisin Gioro's (2012: 12) reading of os for 149. Aisin Gioro would read <149.177.348> above as <os.ulj(i).ə>. Her <os> for 149 is hard to reconcile with the use of 149 to transcribe Liao Chinese *tš-. Even reversing <os> as <so> in
would result in <so.ung> which is not close to Liao Chinese 中 *tšuŋ.
Given how CV graphs can double as VC graphs, I wonder if
4. <ju.mú>
was read as jum.
220 <mú>
may be a variant of
224 <mu>
though Aisin Gioro (2012: 13) reconstructed 220 as <om(o)> and 224 as <um>/<mu>.
5.18.0:30: I forgot to explain the title and address the question of why the shape 子 would have been chosen for ju.
子 'son' (hence "Philial" in the title, a deliberate misspelling of filial for purposes of visual alliteration with "Phonetic") may have been *tsɿ in Liao Chinese: i.e., identical to modern standard Mandarin zi [tsɿ] except for its tone (whose shape we may never know).
Khitan had no native ts and may not have had any voiceless unaspirated plosives, so its j might have been the closest equivalent of Liao Chinese *ts. Similarly, j represents [ts] in the Yale romanization of Cantonese.
Khitan also had no native ɿ, so its u might have been a rough equivalent of Liao Chinese *ɿ. Similarly, ŭ with a breve represents [ɿ] in the Wade-Giles romanization of Mandarin.
So ju might be what Liao Chinese 子 *tsɿ 'son' might have sounded like to Khitan ears. Hence the shape of 子 was borrowed to represent Khitan ju. The resemblance of ju to Jurchen/Manchu jui 'child' may be coincidental.
Liao Chinese 子 *tsɿ was transcribed precisely in the Khitan small script transcription of Chinese as
<dz.ï>
rather than as 子 <ju>.
*Unfortunately, many Khitan small script characters are not used in Chinese transcription: e.g., all three characters in
<qa.ɣa.as> 'tiger'
They presumably contain phonemes and/or phoneme sequences absent from Chinese. They pose the biggest challenge for the decipherment of the Khitan small script.
**The reading <umu> for 092 is from Aisin Gioro (2012: 9). Kane (2009: 45) is agnostic.
***The reading <ulji> for 177 is from Aisin Gioro (2012: 12).
Kane (2009: 164) read 177 as rả. (The superscript question mark presumably
reflects a degree of uncertainty rather than an arbitrary mnemonic,
since Kane seems to believe that 177 might have been read as ra. Some of the other transcriptions with question marks in his book are not meant to
be taken seriously as possible readings: .e.g.,
061 <BURY>
has the transcription kẻ only because it resembles the Chinese character 可 which is pronounced ke [kʰɤ] in modern standard Mandarin. At present there is no evidence for reconstructing the reading of 061 as anything like ke. I prefer to use numbers or glosses whenever possible in lieu of such Chinese-based transcriptions.)
14.5.16.23:56: THAT YEAR ... THE PRINCE OF ... ?
Last night when looking for 斡特剌 Wotela in vain in the Khitan small script epitaph for the 許王 Prince of Xu, the fourth word caught my eye in line 38.
| Line.block | Khitan small script | Transliteration | Gloss | QXY | Frequency | Notes |
| 38.1 | 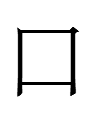 |
qi | that | 442 | 31 | Reading apparently a guess based on the ethnonym <qi.ii.ń> 奚 Xi which may have had a long vowel or a superlong vowel (cf. Estonian). In any case, <qi> is not cognate to Mongolian and Manchu tere 'that'. Could the Manchu word be a loan from a Khitanic language (i.e., a relative of Khitan rather than Khitan itself or at least the prestige dialect in the inscriptions)? |
| 38.2 | 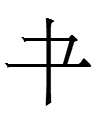 |
ai | year | 237 | 59 | Graph derived from Chinese 年 'year'? |
| 38.3 | 
|
au.a.iú | (noun)-LOC | 277 | 2 | The noun <au.a> occurs by itself earlier
in line 19 of the same inscription. <iú> is the odd allomorph of the locative suffix after <a>-stems; one might expect its reading to be <da> to match the other allomorphs with <d>. |
| 38.4 |  |
ju.i | ? | 264 | 1 | Given that 38.4 is followed by 'prince' and the formula 'X prince' (in which X is a Chinese name) = 'prince of X', this hapax legomenon* should be a Chinese name. But I can't identify it.** |
| 38.5 | 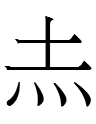 |
ong | prince | 212 | 32 | Borrowing from Liao Chinese 王 *oŋ 'prince'; graph may be derived from 王. 38.4-5 may be the subject of the verb of this sentence which may be 38.6 or a word lost after 38.6. |
| 38.6 |  |
p.ul.b.úr | ? | 421 | 1 | Hapax legomenon* which is either an unmarked object of a lost transitive verb or an unmarked (i.e., finite imperfective) intransitive verb. |
| 38.? | Lost characters | |||||
| 38.7 | 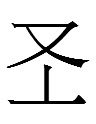 |
TWO | two | 254 | 30 | Reading unknown. Nonfeminine. |
| 38.8 |  |
saiir | month | 217 | 37 | Nonfeminine? See this post on the long vowel. |
| 38.9 | |
TWO | two | 254 | 30 | Reading unknown. Nonfeminine. |
| 38.10 |  |
neir or ńeir | day | 275 | 39 | Nonfeminine? The vowels are hard to reconcile with those of Mongolian naran 'sun' unless the common ancestor of both words was something like *niaira-. |
See my previous post for 38.11-14.
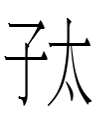
**I originally had planned to write a post about the small script character 子 <ju> which appears in
<o.ju.ɣa.ai> 'caused to close, and ...'/'was closed, and ...'
an example of an ambiguous causative or passive that I mentioned in part 2 of my series on double causatives (or causative passives or passive causatives).
I wonder if the choice of the shape of the Chinese character 子 'son' for <ju> might have been inspired by some word cognate to Jurchen/Manchu jui 'child'. Since I don't think the Khitan would stoop to borrowing from their Jurchen subjects, perhaps they knew of a similar word in a Tungusic language spoken in Bohai.
The only known Khitan word for 'child' is
<b.qo>
which doesn't sound like <ju>.
The small script character for <j>
~
may be derivatives of 子 <ju>.
Qidan xiaozi yanjiu identified
<ju.i>
as 冀 Ji [tɕi], a short name for 河北 Hebei 'North of the (Yellow) River', but 冀 was *Ki in Liao Chinese and would have been transcribed as
<k.i> or <g.i>
in Khitan, not <ju.i>. Northern Chinese *k did not palatalize and affricate before *i until centuries after the fall of the Liao.
I can't think of any Liao Chinese name that sounded like <ju.i>. Even if <ju.i> were an error for
~
<j.i>,
that would be an unusual transcription of the closest Liao Chinese name *tsʰi which is attested in the Khitan small script as
<s.i> or <ts.i>.
(5.17.0:30: Khitan had no native *ts- or *tsʰ-; <ts> was only for transcribing Chinese words. The Khitan use of <s> for Chinese dental affricates is reminsicent of how the Japanese borrowed Chinese *ts(ʰ)- as s-.)
Could <ju.i> be a native Khitan equivalent of a Chinese place name?
14.5.15.23:50: SEVENTY + DOT = EIGHTY?
This article got me thinking about errors in Khitan texts.
According to Kane (2009: 71), Ji Shi (1996) regarded Khitan small script character 301
as an error for Khitan small script character 300
which Kane glossed on that page and on pages 95 and 304 as 'eighty' but glossed elsewhere as 'seventy' (pp. 91, 92, 115, 116, 128, and 177). The table of Khitan numerals on p. 177 lists no Khitan small script character for 'seventy'. (I assume "50~80" in the column of glosses should be "50".)
Did the Khitan small script have only a single character for both 'seventy' and 'eighty'? I doubt it because the two numerals are distinct in the large script:
'sixty' and 'eighty'
They are part of a set of 仒-characters for tens also including
'fifty' and 'seventy'.
but not 'ten' through 'forty' or 'ninety':
'ten', 'twenty', 'thirty', 'forty', 'ninety'
'Ten' and the variant of 'twenty' above look exactly like the Chinese characters 十 and 廿 for those numerals and 'ninety' looks exactly like the Chinese anti-fraud character 玖 for 九 'nine'. Oddly the large script variant of 'forty' above looks almost like the Khitan small script character 007
for nonmasculine 'eight'!
Back to the 'seventy' or 'eighty' problem: Kane glossed 300 as 'seventy' with two exceptions:
First, Kane pointed out that 300 in 耶律仁先 Yelü Renxian correlates with 'eighty' 里 li 'Chinese miles' in the Chinese-language biography of Renxian in the History of the Liao Dynasty from over two centuries later:
塔里干復來寇,仁先逆擊,追殺八十餘里。
'Taligan returned to plunder, Renxian counterattacked him; he pursued him, killing, for more than 80 li.'
(The translation is Kane's.)
Second, Kane (2009: 71) wrote,
Wotela, the subject of the inscription*, was appointed court attendant at the beginning of the Xianyong period, and died [at an age indicated by the character 301] in the fifth year of the Qiantong period, a period of 40 years.
But is it possible that 斡特剌 Wotela was only thirty at the time of his appointment?
My guess is that 300 is 'seventy' (as in the majority of cases) but 301 with the dot is 'eighty' (assuming Wotela was court attendant since age thirty), and 300 in 耶律仁先 is an error for 301 or reflects a variant - and possibly correct - version of the story in which Renxian pursued Taligan for seventy instead of eighty li. (The History of the Liao Dynasty is not necessarily reliable.)
*Kane quoted 301 from 許王 Prince of Xu 38.11-14:
<eu.úr.EIGHTY xa.315.de s.em.ii.er tu.úr.bun>
However, I can't find any mention of Wotela in 許王, and Wotela has his own inscription. 'Died at age eighty' is so generic that it might be in Wotela's inscription as well. So I'm not sure which inscription Kane is referring to: the Prince of Xu's or Wotela's.
14.5.14.23:50: DID KHITAN HAVE DOUBLE CAUSATIVES? (PART 5)
Here's the second double causative (or causative passive or passive causative?) in context from the 1101 epitaph for Empress 宣懿 Xuanyi (1040-1075):
| Line-block | Khitan small script | Transliteration | Gloss | QXY | Frequency | Notes |
| 8-X | (none) | honorific space | ||||
| 8-7 |  |
BURY.er | bury-PAST-M | 203 | 15 | finite masculine past verb; end of sentence |
| 8-8 |  |
co.do.er | ?-PAST-M/ACC-INST | 424 | 2 | <co.do> appears with both the verbal suffix <én> and the genitive suffix <i>, so <co.d.er> could be a one-word sentence consisting of a masculine past verb, an object, or an instrument. |
| 8-9 |  |
190 | (noun?) | 311 | 4 | no case suffix |
| 8-10 |  |
eu.ul.g.en | (noun?) | 208 | 1 | hapax
legomenon* and therefore maybe not the second half of a
compound noun? <en> is a genitive suffix, but <eu.ul.g> is not attested, so 8-10 is probably not a genitive of <eu.ul.g>. |
| 8-X | (none) | honorific space | ||||
| 8-11 |  |
ś.iá.aɣ | goodness, well? | 182 | 12 | not attested with case suffixes; adverb as well as noun? |
| 8-12 |  |
s.ún.g.l.ge.l.g | ?-CAUS/PASS-CAUS/PASS-Ø | 345 | 1 | zero ending indicates a finite nonpast verb; end of sentence |
I have added two new columns to the format from part 4:
QXZ: page number of entry for word in Qidan xiaozi yanjiu
Frequency: frequency of word in texts discovered up to c. 1985 in Qidan xiaozi yanjiu; these numbers should be higher three decades later, and some hapax legomena
My logic is like that of part 4: I chose to start with 8-7 because I wanted to see where the sentence ending with 8-12 began. The arguments for 8-12 are within that sentence and/or implied. 8-8 might either be an argument for 8-12 or another sentence. 8-9 and 8-10 are likely arguments for 8-12. 8-11 might be an adverbial measure adjunct: i.e., it could be deleted without any harm to the structure required by 8-12 (albeit of course such deletion would reduce the information in the sentence). Out of the three possible structures (in English translation):
'X causes Y to cause Z to <s.ún.g> (A)' (double causative; 3-4 arguments)
'X is caused by Y to <s.ún.g> (Z)' (causative passive; 2-3 arguments)
'X causes Y to be <s.ún.g>-ed (by Z)' (passive causative; 2-3 arguments)
All three might fit
if 8-8, 8-9, 8-10, and maybe even 8-11 are all objects:
'(X) causes 8-8 to cause 8-9 (and) 8-10 to <s.ún.g> well.' or
'(X) causes 8-8 to cause 8-9 (and) 8-10 to <s.ún.g> goodness.'
if 8-8 is an instrumental and 8-9 and 8-10 are a compound noun object 9 or a pair of compound noun objects):
'(X) is caused by 8-8 to <s.ún.g> 8-9 (and?) 8-10 well.' or'(X) is caused by 8-8 to <s.ún.g> 8-9 (and?) 8-10 and goodness.'
If 8-8 is not an argument of 8-12:
'8-9 causes 8-10 to be well <s.ún.g>-ed.' or
'8-9 (and) 8-10 causes goodness to be <s.ún.g>-ed.'
In any case, I doubt that 8-8 is the subject of 8-12. Khitan subjects have zero marking.
I have been translating verbs with zero marking as presents, but all of the events described in the epitaphs presumably occurred in the past relative to the moment of inscription. If Khitan writers did not freely mix historical presents with past forms, perhaps what I've describing as 'nonpast' and 'past' is really an aspectual distinction between imperfective and perfective.
I don't understand the functions of the honorific spaces here. I presume the space before 8-7 'buried' is to venerate the object (Empress Xuanyi). Does the space before 8-11 indicate that 'goodness' belonged to the empress, or that the action (8-12) was performed well (8-11) by some other noble (8-9 or an unstated subject)? The usage of spacing in Khitan small script texts deserves its own study.
14.5.13.23:56: DID KHITAN HAVE DOUBLE CAUSATIVES? (PART 4)
Here's the first double causative (or causative passive or passive causative?) in context from the 1055 epitaph for Emperor 興宗 Xingzong (1016-1054):
| Line-block | Khitan small script | Transliteration | Gloss | Notes |
| 32-14 |  |
t.ul.l.g | ?-CAUS/PASS-Ø | zero ending indicates a finite nonpast verb; end of sentence |
| 32-15 |  |
c.ra.l | (noun?) | beginning of sentence; at least 11 other attestations; 3 more in this epitaph alone |
| 32-16 |  |
bú.a | (noun?) | hapax legomenon* and therefore maybe not the second half of a compound noun? |
| 32-X | (none) | honorific space before 'great' | ||
| 32-17 |  |
tai | great (< Liao Chinese 太 *tʰai) | 'at the great temple' |
| 32-18 |  |
m.iau.de | temple-LOC (< Liao Chinese 廟 *miau) | |
| 32-19 |  |
t.ge.l.ge.l.g | ?-CAUS/PASS-CAUS/PASS-Ø | zero ending indicates a finite nonpast verb; end of sentence |
I chose to start with 32-14 because I wanted to see where the sentence ending with 32-19 began. The arguments for 32-19 are within that sentence and/or implied. 32-15 and 32-16 are likely arguments for 32-19. 32-17-18 might be a locative adjunct: i.e., it could be deleted without any harm to the structure required by 32-19 (albeit of course such deletion would reduce the information in the sentence). What is that structure? Here are some possibilities in English translation:
'X causes Y to cause Z to <t.ge> (A)' (double causative; 3-4 arguments)
'X is caused by Y to <t.ge> (Z)' (causative passive; 2-3 arguments)
'X causes Y to be <t.ge>-ed (by Z)' (passive causative; 2-3 arguments)
In Khitan, all the arguments would precede the verb. The higher number of arguments is for a transitive verb; the lower number is for an intransitive verb or for a transitive verb with an unstated object (A or Z) or instrumental adjunct ('by Z').
Since Khitan has subject-object-verb order, 32-15 may be the subject (X) and 32-16 may be the unmarked object (Y) of a passive causative 32-19. (Khitan direct objects may take the accusative suffix <er>. See 郎君 4 for another unmarked object ['wine']). If 32-16 were 'by Y' in a causative passive construction, I would expect an instrumental suffix <er>. So 32-15-19 may mean 'X causes Y to be <t.ge>-ed at the great temple.'
14.5.12.23:54: DID KHITAN HAVE DOUBLE CAUSATIVES? (PART 3)
Before going on, I'd like to outline what little is known about the structure of the Khitan verb mostly according to Kane (2009). In short, it can be divided into one to four parts: a root followed by one or two passive/causative suffixes and by a finite or nonfinite suffix.
| Root | |||||||||||
| Passive/causative: <al.ɣa>, <l.ɣa>, <l.g(e)>, <ul.ɣa>, <ɣa>, <ge> | |||||||||||
| Passive/causative: <l.g> (others?) | |||||||||||
| Finite | Nonfinite | ||||||||||
| Nonpast | Past | ||||||||||
| Ø (zero ending) | Masculine | Feminine | No gender? | Past participles | Converbs | ||||||
| <ar>, <er>, <or> | <én> | <l.un> | <b.ń>, <b.ún>, <bun> | <b.ń> | <án>, <én>, <ón>, <ún>, <n>, <ń> | <ɣo>, <ɣu>, <g> | <ai>, <ei>, <i>, <ii>, <oi>, <ui> | <sii> | <al> | <c>, <j> | |
The listing of allomorphs is probably not exhaustive: e.g., I suspect <al> has a variant <l>.
The partial overlap between past finite and participial suffixes may indicate a shared origin.
It is not yet possible to precisely define the converbs.
14.5.11.23:31: DID KHITAN HAVE DOUBLE CAUSATIVES? (PART 2)
Yesterday I proposed that
<t.ge.l.ge.l.g> (興宗 32-19) and <s.ún.g.l.ge.l.g> (宣懿 8-12)
were examples of double causatives in Khitan. I had intended to look at each of them in context in this post and the next, but before I do that, I want to point out that they could also be interpreted as causative passives like those of Japanese (or passive causatives?):
'X was caused to <t.ge>/<s.ún.g>' (causative passive) or
'X caused Y to be <t.ge>/<s.ún.g>-ed' (passive causative)
Khitan <l.g> can be passive as well as causative. Compare:
<t.em.er> (masculine past active 'awarded'; 道宗 24-34)
<t.em.l.ge.er> (masculine past active 'was awarded'; 興宗 11-14)
This double function of <l.g> is reminscent of the double function of the Korean causative/passive suffix: e.g.,
읽- ilk- 'to read' > 읽히- ilk-hi- 'to cause to read/to be read' (see Martin 1992: 222 for more examples)
Manchu also has a causative/passive suffix (from bu- 'to give'): e.g.,
ᠸᡝᡳᠯᡝ- weile- 'to work, to make' > ᠸᡝᡳᠯᡝᠪᡠ- weile-bu- 'to cause to make/to be made' (see Gorelova 2002: 248 for more examples)
See Schulze (2011) for more examples of causative/passive homophony both inside and outside the Altaic zone.
Kane (2009: 148) listed one example of an ambiguous Korean-like causative/passive in Khitan with <ɣa> sans <l> (cf. the Mongolian causative [but not passive!] -ɣa-/-ge-):
<o.ju.ɣa.ai> ('caused to close, and ...'/'was closed, and ...'; 仁懿 16-6, 宣 懿 9-12, 蕭仲恭 27-23)
whose base form is in the past participle (?)
<o.ju.ún> 'closed' (仁懿 18-18, 蕭令公 15-11, 蕭仲恭 18-14, 19-44)
(I have replaced his stems <o.ju> and <o.ju.ɣa> with forms from texts. Line and block numbers are from Qidan xiaozi yanjiu. I do not have all texts on hand and cannot confirm all meanings in context.)
Perhaps Khitan <l.g>-verbs were also ambiguous.