13.10.5.23:20: THE OTHER KRA-DAI NUMERALS: 'TWO' THROUGH 'FIVE'
Unlike Proto-Kra 'one', Proto-Kra 'two' through 'five' resemble their Proto-Austronesian counterparts (sources?):
| Gloss | two | three | four | five |
| Proto-Austronesian (Blust 1999 in IPA) | *dusa | *təlu | *səpat | *lima |
| Proto-Kra (Ostapirat 2000) | *sa | *tu | *pə | *r-ma |
| Pre-Proto-Hlai (Norquest 2007) | *luːʔ | *ʈwuʔ | *ʈaːwʔ | *maː |
| Lincheng Be (Liang and Zhang 1997: 282) | vɔn B/C1 | (Chinese loans) | ||
| Qiongshan Be (Liang and Zhang 1997: 282) | bɐn B/C1 | |||
| Proto-Lakkja (L-Thongkum 1992: 86) | *hou C | |||
| Proto-Kam-Sui (Thurgood 1988) | *hra A | |||
I have excluded Tai forms since all of them are loans from Chinese.
Unlike pre-Proto-Hlai *c/ɕɯaʔ which looks like the second syllable of Proto-Austronesian *iça ~ *əça 'one', pre-Proto-Hlai *luːʔ looks like the first syllable of Proto-Austronesian *dusa. If speakers of non-Hlai Kra-Dai languages replaced an original monosyllabified 'one' to avoid (near-)homophony with a monosyllabified 'two', did pre-Proto-Hlai speakers irregularly reduce 'two' to its first syllable to differentiate it from a reduced 'one'? Or are the pre-Proto-Hlai and Proto-Austronesian forms for 'two' simply lookalikes?
(23:35: Mulao ɬu is superficially similar to pre-Proto-Hlai *luːʔ but may be from Proto-Kra *sa.)
L-Thongkum (1992: 86) regarded Proto-Lakkja *hou C as cognate to the Hlai word. Although I would expect a Proto-Lakkja cognate to have *(h)l-, the tone categories match since Kra-Dai tone class C comes from *-ʔ.
The Be words for 'two' are obviously cognate to each other but not to the Austronesian/Kra, Hlai/Lakkja, or Kam-Sui words.
Proto-Kra and pre-Proto-Hlai 'three' look like compressions of both syllables of Proto-Austronesian *təlu. Pre-Proto-Hlai retroflex *ʈ- could be from *tl- just as southern Vietnamese [ʈ] is from Middle Vietnamese tl-. If Pre-Proto-Hlai 'three' were *twu, I could derive *-w- from *-l- (cf. Polish [w] < *l), but would *-l- really condition the retroflexion of *ʈ- and remain as *-w-?
Proto-Kra 'four' ends in a schwa instead of the *-at I would expect. The pre-Proto-Hlai word is unrelated.
Proto-Austronesian, Proto-Kra, and pre-Proto-Hlai 'five' match perfectly if Norquest's (2007: 411) reinterpretation of Blust's *l as [r] is correct (or if the Austronesian source of the Kra and pre-Proto-Hlai words had shifted *l- to *r-).
13.10.4.23:56: BRIGH-'TEN'-ING IN RGYALRONG In "Ten Thousand and Three Warehouses", I wrote,
The pre-Tangut source of 2ɣạ 'ten' is *SʌKaH (cf. Japhug sqi, Zbu sɐʁɐʔ, Caodeng sqeʔ < Proto-rGyalrongic *sqji 'id.' [Jacques 2004: 307]). There is no trace of palatality in the Tangut form. Did rGyalrongic 'brighten' an original *a, or did *i 'darken' in Tangut?
I forgot about Japhug sqa- in the compounds
sqa-ptɯɣ 'eleven'
sqa-mnɯs 'twelve' (cf. ʁnɯs 'two')
sqa-fsum 'thirteen' (cf. χsɯm 'three' with a different vowel)
sqa-prɤɣ 'sixteen' (cf. kɯ-tʂɤɣ 'six')
from Proto-rGyalrongic *sqa- (Jacques 2004: 294). I assume sqa- is also in other Japhug numerals, but I can't find any other examples in Jacques 2004.
I also assume that pre-Tangut *SʌKaH and Proto-rGyalrongic *sqa- share a common ancestor* like *sʌqaʔ**. If so, then is Proto-rGyalrongic *sqji an innovation with 'brightening' of *a to ji? (See Nagano [1979: 42] for other rGyalrongic forms with brightening.) Did *sqa- escape brightening because its vowel wasn't word-final?
*I do not necessarily believe that pre-Tangut and Proto-rGyalrongic are closely related, though I do think they may belong to the same subgroup of Sino-Tibetan as Qiangic which also has qa-type words for 'ten'.
**See the Zbu and Caodeng forms above for final -ʔ.
13.10.3.22:49: THE OTHER KRA-DAI NUMERALS: 'ONE'
By "other" I mean 'one' through 'six' and 'eight' through 'ten' since I covered 'seven' in detail in my last two posts.
Gelao forms like Puding Gelao se 'one' look like retentions of the final syllable of Proto-Austronesian (PAN) *isa ~ *əsa but are actually from Proto-Kra (PK) *tʂəm whose C tone implies a final *-ʔ absent from PAN. PK *tʂəm C does not appear to be cognate to pre-Proto-Hlai (PPH) *c/ɕɯaʔ (Norquest 2007: 590) which lacks *m; the latter may be cognate to PAN *isa ~ *esa (Norquest 2007: 413) and its palatal initial could be a trace of an earlier *i-:
*is- > *isj- > *c/ɕ-
Was a *sa-like original Proto-Kra-Dai word for 'one' replaced with various forms in different branches such as
Proto-Tai *nɯ:ŋ B (Pittayaporn 2009: 358)
Proto-Lakkja *ʔŋin C* (L-Thongkum 1992: 84)
Lincheng Be hə B/C1** (Liang and Zhang 1997: 282)
Maonan tɔ A2, dɛu A2 (Liang 1980)
due to (near-)homophony with 'two' after *isa 'one' and *duSa 'two' lost their first syllables?
*L-Thongkum regarded the Tai and Lakkja forms as related, but the onset and coda nasals don't match, so I think *nɯ:ŋ and *ʔŋin are lookalikes rather than descendants of a form like *ŋ-ŋ whose consonants dissimilated differently in each branch.
**The B and C tonal categories merged in Be (Ostapirat 2000: 55). I don't know of any cognates of hə B/C1 which would point to B or C in some ancestor of Be.
13.10.2.23:50: PROTO-KRA 'SEVEN' AGAIN
Looking at this list of numerals in Kra languages (including many varieties I did not see in Ostapirat 2000) made me realize the problem of 'seven' is even more complicated than I thought.
Looking at Qabiao matu 'seven', it is tempting to reconstruct *mVtu (in spite of the initial consonant's incompatibility with Proto-Austronesian *pitu 'id.'), but *mVt- would not be a likely source for the aspirated th- of Bigong Gelao as well as Laha.
Moreover, Sanchong Gelao has tʂ- which may be from an earlier *tr-. Could the sh- of Zunyi Gelao shao 'seven' also be from *tr-?
Medial *-r- conditions aspiration in Laha (Ostapirat 2000: 166) and if it did the same thing in Bigong Gelao, then both Laha and Bigong Gelao th- are from *tr-.
Could the x- of Moji Gelao xe and the h of White Gelao du-hi (du- is a numeral prefix) be from *r- < *tr-?
th- and x-/h- from *tr- are reminiscent of 德保 Debao th- and Siamese h- from Pittayaporn's (2009: 94) Proto-Tai *tr-.
All of the above makes me think Proto-Kra 'seven' was *mVtru which is even further from Proto-Austronesian *pitu.
Could those two proto-forms still be cognate? Here is a wild scenario. The Austro-Kra-Dai (!) word for 'seven' was *mpitru. Proto-Austronesian speakers moving to Taiwan simplified that to *pitu, while the Kra-Dai staying behind on the Asian mainland reduced it to *mVtru.
I don't really believe that happened, though. I am wary of complex proto-forms concocted to bridge two proposed descendants that are phonetically divergent. Moreover, would a Proto-Kra-Dai *mVtr- be reduced to the simple *t- of Norquest's (2007) pre-Proto-Hlai *tuː? Maybe
Proto-Kra-Dai *mVtr- > Proto-Southern Kra-Dai *N-tr- > pre-Proto-Hlai *t-
given that his Proto-Southern Kra-Dai *N-t- simplified to Proto-Hlai *th- (via pre-Proto-Hlai *t-).
ADDENDUM: For some reason, Mulam (a Kam-Sui language - related to Kra but not Kra) was included in that list of numerals. Mulam sau 'seven' resembles Zunyi Gelao shao 'seven'. Could Mulam s- be from *tr-?
13.10.1.23:59: PROTO-KRA 'SEVEN'
Many Kra-Dai languages have Chinese loanwords for numerals such as 'seven':
Proto-Tai *cet (Pittayaporn 2009: 358)
Sui ɕət (this and other Kam-Sui forms are at ABVD)
Proto-Lakkja *thet (L-Thongkum 1992: 62)
Lincheng Be sit, Qiongshan Be sɔt (Liang and Zhang 1997)
cf. Middle Chinese 七 *tshit
However, Hlai and Kra languages have non-Chinese numerals which I assume are retentions of the original Proto-Kra-Dai numerals.
Norquest (2007: 532) reconstructed pre-Proto-Hlai *tuː 'seven' resembling Proto-Austronesian *pitu 'seven' (which is curiously absent from the online version of Blust's Austronesian Comparative Dictionary; *maCa 'eye' [see "Retroflexion or Lenition?"] is also missing except as a part of another entry).
Ostapirat (2000) reconstructed Proto-Kra 'seven' with initial *C-tj- on p. 214 and as *t-ru on p. 245. If the word was *p-tju, that could be easily derived from *pitu with 'vocalic transfer':
Vocalic transfer is a form of metathesis where the features of a high vowel preceding a stressed syllable are transferred onto the initial of that stressed syllable, in the form of a coarticulation. (Norquest 2007: 30)
Vocalic transfer may be one source of high vowel medials and 'brightening' in Tangut.
However, I think the Proto-Kra word for 'seven' might have been *CV-tru with an *-r- lacking a corresponding consonant in Proto-Austronesian:
*CV-tru > *tru > *thu > Ta Mit Laha tho
*CV-tru > *CV-ðru > Paha ðhuu
(10.2.0:45: The timing of vocalic developments relative to consonantal changes is unknown, so I have simply retained the original *-u except in the attested forms.)
I've been thinking about the Kra word for 'seven' ever since I rediscovered Guillaume Jacques' 2001 review of Ostapirat's book which listed five sources of Paha ðh- (the page numbers are Ostapirat's):
*C-ʈ- (p. 179)
*ʔ-s- (p. 182)
*r- (p. 189)
*k-l- (p. 190)
*C-tj- (p. 214)
I would add two more: *t-r- and *d-r- (p. 215).
The tone of 'seven' in most Kra languages* rules out a source with a voiced initial like *d-r- and nearly all Kra forms other than on p. 245 have initial t- with the exceptions of Paha (ðh-) and Ta Mit Laha (th-). So *k-l-, *ʔ-s-, and *r- can be ruled out, leaving *C-ʈ-, *C-tj-, and *t-r-.
Ostapirat's *C-ʈ- (my *CV-t-; see "Retroflexion or Lenition?") corresponds to Laha t-, not th- (p. 208).
Ostapirat's medial *-j- has left no certain traces in Kra words for 'seven'. The -j- in Lachi tje 'seven' is due to a shift of *-u to -je (p. 151). *-j- was "usually dropped" in Laha without a trace (p. 167). The only two examples I can find of *-j- corresponding to Laha aspiration are 'seven' and 'sweet' (pp. 213, 237) which might be anomalies that can be explained without *-j-.
That leaves *t-r- (my *CV-tr-) by process of elimination. Or does it? Could aspiration in Laha and Paha be a trace of a lost *p-?
*pit- > *ft- > *ht- > Ta Mit Laha th-
*pit- > *pið- > *fð- > Paha ðh-
However, disyllabic Kra forms for 'seven' in ABVD
Qabiao mə tu
Phó Là Qabiao mơ tu
En ʔam tu
have m, not p! Could *m- have conditioned aspiration?
*mit- > *vt- > *ft- > *ht- > Ta Mit Laha th-
*mit- > *við- > *vð- > Paha ðh-
(10.2.0:07: Cf. *mu- > v- in Hakka.)
And could that *m- be from an even earlier *m-p- with a prefix of unknown function - always a warning sign? (Yes, I admit the above attempts to salvage a link to Proto-Austronesian *pitu are desperate.)
*Buyang has an irregular tone implying a proto-voiced initial.
13.9.30.17:54: TEN THOUSAND AND THREE WAREHOUSES
Today I started to write a Swadesh list for Tangut, and
2lɨọ 'where'* (analysis unknown)
reminded me of the similar-looking character
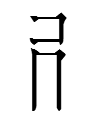
=
+
+
2ɣạ 'ten' = top of 2khiə 'ten thousand' + bottom left of 1sọ 'three' + left of 2vɨẹ 'warehouse'
sharing the same left side (Nishida radical 107; gloss unknown). What is the above analysis supposed to mean? My guess is that 'ten thousand' and 'three' are not the actual sources of
the left side of 'ten'
but are just numeral characters chosen for this analysis because they happened to contain the shapes コ and ㄇ. There are 265 other potential sources for the right side
Nishida radical 211 'sun'
which represented 1dʐɨew 'waist' by itself and can also be an abbreviation of
1dʐwɨõ 'bird'
among others (see Andrew West's post for details).
I am not sure 'warehouse' (from Li 2008: 373) is the correct interpretation of the right-hand source graph which could also be read as 2biu 'a kind of bird' (also not obviously associated with 'ten').
The Mojikyo font has slightly different right-hand components (Nishida radical 255 'mouth') for
2vɨẹ 'warehouse' and 2biu 'a kind of bird',
but they share a single shape and codepoint (U+17F8A) in the latest Tangut Unicode proposal. Although the right side of 2biu may be 'mouth' (so was 2biu the 'mouth bird'?), its function in 'warehouse' is unknown.
The pre-Tangut source of 2ɣạ 'ten' is *SʌKaH (cf. Japhug sqi, Zbu sɐʁɐʔ, Caodeng sqeʔ < Proto-rGyalrongic *sqji 'id.' [Jacques 2004: 307]). There is no trace of palatality in the Tangut form. Did rGyalrongic 'brighten' an original *a, or did *i 'darken' in Tangut? (Matisoff 2004 documented brightening in Tangut, but I have never seen darkening in Tangut.)
2khiə 'ten thousand' could be a loan from Tibetan khri 'id.' It also resembles rGyalrongic forms which are borrowings from Tibetan khri (tsho): Caodeng khro tso, Daofu khʂə, Ergong khʂɯ, Japhug khrɯ tsu, Maerkang khrə tso.
There is no doubt that 1sọ < *S-so < ?*k-som 'three' is the Sino-Tibetan word for 'three': cf. Old Chinese *səm, Tibetan gsum, Written Burmese suṃḥ, etc.
2lɨọ < *Sɯ-LoH 'where' superficially resembles Ergong lau 'id.', and Tangut o might be partly from *au (which is absent from my Tangut reconstruction), but I don't know if there is a real connection.
*The initial consonant of 'where' may have not have been a simple l-. I know of no Tibetan transcription for it and its two homphones (51A75-77), but Nishida (1964: 137) listed the Chinese transcription 浪重 *loheavy. Sofronov reconstructed it as 2ldi̯ọn (Kychanov and Arakawa 2006: 411) and Nishida reconstructed it as 2rõ (1964: 144, 1966: 386).
13.9.29.23:59: GAPS IN THE PROTO-AUSTRONESIAN CONSONANT SYSTEM
I am accustomed to phoneme inventories with a high degree of symmetry: e.g.,
Tangut consonants (Homophones classes in parentheses; problematic class IV consonant[s] omitted)
| p (I) | t (III) | ts (VI) | tʂ (VII) | k (V) | ʔ (VIII) |
| pʰ (I) | tʰ (III) | ts (VI) | tʂʰ (VII) | kʰ (V) | |
| b (I) | d (III) | dz (VI) | dʐ (VII) | g (V) | |
| m (I) | n (III) | |
|
ŋ (V) | |
| |
|
s (VI) | ʂ (VII) | x ~ h (VIII) | |
| |
|
z (IX) | ʐ (IX) | ɣ ~ ɦ (VIII) | |
| |
|
ɬ (IX) | |
|
|
| v (II) | l (IX) | ɮ (IX) | r (IX) | |
|
This doesn't mean I wouldn't reconstruct inventories with gaps. Attested languages do have gaps, and there are even some common gap patterns (e.g., b without p, f without v, j without ch, and k without g as in standard Arabic). Nonetheless, those gaps have historical implications (e.g., standard Arabic f and j are from missing *p and *g), and I would rather not reconstruct a gap if possible.
Robert Blust's (1999) reconstruction as presented in Wikipedia (and reinterpreted here in IPA) has a number of gaps:
| *p | *t | |
|
*k | *q ~ *ʔ | |
| *b | *d | *ɖ | *gʲ | *g | |
|
| *m | *n | |
*ɲ | *ŋ | |
|
| |
*s | |
*ç | |
|
*h |
| |
*ts | |
*cç | |
|
|
| |
|
|
*ɟʝ | |
|
|
| |
*l | |
*lʲ = [ʎ]? | |
|
|
| |
*ɾ | |
|
|
*ʀ | |
| *w | |
|
*j | |
|
|
Bold indicates consonants absent from Wolff's (2010) reconstruction as presented in Wikipedia. (There are no previews of Blust and Wolff's books at Google.)
Retroflex *ɖ and palatalized velar stop *gʲ are both one of a kind without any voiceless counterparts. Conversely, *ts and *q have no voiced counterparts.
Ross' (1995: 57) reconstruction also has a voiced retroflex ɖ without a voiceless counterpart, though it is not the only retroflex:
| *p | *t | *ts | |
|
*k | *q | *ʔ |
| *b | *d | *dz | *ɖ | *ɟ | *g | |
|
| *m | *n | |
|
|
*ŋ | |
|
| |
|
*s | *ʂ ~ *ʃ | |
|
*h | |
| |
|
*z | |
|
|
|
|
| |
*l ~ *ɬ | |
*ɭ ~ *ɽ | |
|
|
|
| |
*r | |
|
|
*ʀ | |
|
| *w | |
|
|
*j | |
|
|
Ross' *ɟ has no voiceless counterpart like Blust's *gʲ, but Ross' *dz balances *ts.
Norquest's (2007: 411) modification of Blust's system "based on a reinterpretation of the Formosan language data" closes some of the gaps by moving *ts into the *ʈ position to serve as the voiceless counterpart of *ɖ (which includes Blust's *gʲ):
| *p | *t | *ʈ | *c (?) | *k | *q ~ *ʔ | |
| *b | *d | *ɖ | *ɟ | *g | |
|
| *m | *n | |
*ɲ | *ŋ | |
|
| |
|
*ʂ | *ç | |
|
*h |
| |
*l | *r | |
|
*ʀ | |
| *w | |
|
*j | |
|
|
Norquest changed Blust's *ɟʝ to *ɟ, so perhaps he reinterpreted Blust's *cç as *c, though he did not specify that. In any case, treating the affricate *cç as a stop *c allows me to delete the affricate rows.
Does any language have ʂ and ç without s? (9.30.0:21: I would reconstruct *s and *ʂ ~ *ɕ. What if original *s became *h as in Greek and Iranian?)
Norquest's *l and *r do not correspond to Blust's liquids:
| Blust | *l | **lʲ | *ɾ |
| Norquest | *r | *l | (secondary) |
Moving *ʀ into the voiced uvular gap as *ʁ (or *ɣ in Wolff's notation) closes a gap that Blust, Ross, and Norquest share.