=
= +
+
13.9.28.23:06: RETROFLEXION OR LENITION?: KRA-DAI 'EYE'
My recent posts about the z- (or ɮ-) in Tangut originating from lenited consonants reminded me of Qiaoshang Gelao whose z- is also from lenited consonants - or is it?
Ostapirat (2000) generally derived Qiaoshang z- and Paha ð- from Proto-Kra retroflexes, but z- and ð- are not retroflex, and none of the other reflexes of his Proto-Kra retroflexes are retroflex or r-like. In 2008, I wrote an 11-part series on these Proto-Kra retroflexes (starting here and ending here). Maybe I should rewrite it as an article. Incredibly I not only recently forgot about that series but didn't even remember it when I wrote this post in 2011.
A key word that Ostapirat reconstructed with a retroflex was *m-ʈa 'eye'. Compare the consonants of its descendants with those of *m-tik 'full':
| Gloss | Proto-Kra | Wanzi Gelao | Qiaoshang | Lachi | Laha | Paha | Ecun Buyang | Pubiao |
| eye | *m-ʈa | tau | ze | tju | taa | daa | taa | tee |
| full | *m-tik | tei | tai | tɦi | tik | dɛɛk | tiak | tek |
I think Paha d- in 'eye' may be from earlier *n-ð- < *mV-ð- < *mV-t- with intervocalic lention of *-t-, whereas Paha d- in 'full' is from earlier *nd- < *Nt- without lenition.
I reconstruct *N- in 'full' since I don't know of any evidence for specifying *m- which is Ostapirat's symbol for any preinitial nasal.
OTOH, the Proto-Kra preinitial of 'eye' was *m- given m-forms like Paha (Li and Luo 2010) mada, Ecun Buyang (Kosaka et al. 1998) ma(k)ta, and Langjia Buyang mata. (Ostapirat only heard monosyllabic forms for 'eye' in his own fieldwork on Paha and Ecun Buyang.) These forms resemble Blust's Proto-Austronesian *maCa 'eye' (C = [ts]) and Proto-Malayo-Polynesian *mata. Whether the Kra word is a true cognate or a borrowing is unclear. (I doubt it's a lookalike.)
I just noticed that Ostapirat's retroflex *ʈ matches a retroflex in Puyuma maʈa 'eye' - coincidence or influence? (How did Proto-Austronesian *C become *ʈ?) Norquest (2007: 411) suggested reinterpreting Blust's Proto-Austronesian *C as *ʈ. (Proto-Austronesian *ʈ becoming C = [ts] in Kulalao Paiwan has a parallel in Middle Chinese *ʈ becoming ts in some modern Chinese languages such as Nanchang Gan.)
Here is Ostapirat's (2000: 1) tree for Kra-Dai with 'eye' for each branch:
| Proto-Kra-Dai *maʈa | ||||
| Proto-Kra *mata | Proto-Hlai (Nordquest 2007: 586) *tʃʰaː < *ʈaː | Proto-Kam-Tai *m.ta | ||
| Proto-Be (Nordquest 2007: 259) *taː | Proto-Tai (Pittayaporn 2009: 323) *p.ta | Proto-Kam-Sui (Peiros) *nta | ||
Unattributed reconstructions are my guesses. In the above scenario, Hlai was the only branch that retained retroflex *ʈ. Ostapirat's retroflex *ʈ in 'eye' happened to come from an earlier retroflex, but many of his other retroflexes probably came from lenited dentals, and I don't see any internal evidence for retention of retroflexion in Kra. If not for Hlai, I would have reconstructed Proto-Kra-Dai *mata.
And here is Norquest's (2007: 16) tree for comparison:
| Proto-Kra-Dai *maʈa | |||||
| North Kra-Dai *mata | South Kra-Dai *P.ʈa | ||||
| Northwest Kra-Dai: Proto-Kra *mata | Northeast Kra-Dai *mta | Southwest Kra-Dai *P.ta | Southeast Kra-Dai: Proto-Hlai *tʃʰaː < *ʈaː | ||
| Proto-Kam-Sui *nta | Proto-Lakkja (Thongkum 1992) *pla | Proto-Tai *p.ta | Proto-Be *taː | ||
In this Norquestish scenario, retroflex *ʈ was retained in South Kra-Dai but lost in North Kra-Dai (though it is possible that the North Kra-Dai branches independently lost it). Hlai is the only lower-level branch that must have retained retroflex *ʈ. Pre-Proto-Hlai *t cannot be reconstructed in 'eye' because it would have become Proto-Hlai *tʰ, not *tʃʰ (Norquest 2007: 336).
If Proto-Kra-Dai had retroflex *ʈ, then it must have acquired the word for 'eye' from a language that had not shifted retroflex *ʈ to dental *t: i.e., Proto-Austronesian or a descendant like Proto-Puyuma but not Proto-Malayo-Polynesian. Is Kra-Dai an offshoot of a Formosan language that spread to the continent? (I doubt that Proto-Kra-Dai speakers crossed the ocean, borrowed Formosan words, and brought them back.) Sagart (2001: 1) wrote that "[t]he AN [Austronesian]-related vocabulary in Kadai [= Kra-Dai] has Malayo-Polynesian features" but a retroflex *ʈ is not such a feature, and its presence indicates an older (inherited?) stratum of Austronesian-related vocabulary predating a layer of loans from Malayo-Polynesian.
13.9.27.23:59: ɮ-ENITION IN TANGUT?
When I first proposed that Tangut z- originated from lenited *ts-, *tsh-, *ndz- back in 2007, I assumed z- was [z]. But I've thought for some time now that z- was actually a lateral [ɮ] which would explain why it was grouped with l- in chapter IX of Homophones rather than with s- in chapter VI. Four days ago, I decided to write that initial as ɮ-. However, would alveolars (*ts *tsh *dz *s in my current pre-Tangut reconstruction) really lenite to ɮ? I could reconcile my theories by having alveolars first lenite to *z which then becomes ɮ. Is there any language in which that happened without *s becoming ɬ? Moreover, none of the Tibetan transcriptions of ɮ- contain l:
| Tibetan transcription | Frequency (Tai 2008: 201) |
| gz- | 35 |
| z- | 9 |
| rdz- | 2 |
| Hz- | 1 |
Maybe I should reconstruct z- again. It might have been grouped with the liquids on the basis of its phonetic similarity to ʐ- which in turn was phonetically similar to r-. If z- wasn't [ɮ], that frees me to reinterpret ld- as ɮ-, the voiced counterpart of ɬ-:
| This site now | l- | ɮ- | ɬ- | z- | ʐ- | r- |
| This site earlier this week (why ld-?) | l- | ld- | ɬ- | ɮ- | ʐ- | r- |
| This site until this week | l- | lh- [ɬ] | z- [ɮ] | ʐ- | r- | |
Next: Retroflexion or lenition in Proto-Kra?
13.9.26.23:31: YOROP GLING-GI RGYALKHAB
I am familiar with Tibetan transcriptions of Middle Chinese (one source of data for my 2003 book) and of course Tangut (since I got ahold of Nevsky 1926 in 1996) but know nothing about how Tibetans transcribe foreign words today, so I looked up "Bosnia and Herzegovina" in the Tibetan Wikipedia and found that its name was rendered as bhosu.niya.dang.har.dze.gho.wi.na. (dang. is 'and'.)
I guess bh and gh indicate [b] and [g] since b and g are now [pʰ] and [kʰ]. (All forms in brackets represent Lhasa pronunciation.)
I was surprised by what appear to be disyllabic sequences (bhosu, niya) before the tsheg (syllable separator transliterated here by a period). Are those typos or orthographic devices to indicate the un-Lhasa syllables [bos] and [nia] with a diphthong? (bhos might be read [bø].)
Looking at the list of yo.rop. gling.gi. rgyal.khab 'countries of the continent of Europe' at the bottom of the page, -su with silent (?) -u also appears in
bhe.la.rasu. 'Belarus'
isu.ṭo.niya. 'Estonia' (is the use of retroflex ṭ a carryover from the Hindi use of ṭ for English alveolar t?)
ayisu.len.ḍa. 'Iceland' (with three vowels before a tsheg!; ḍ due to Hindi influence?; see above)
-u- indicates a consonant cluster inkadz.kisu.gtan. 'Kazakhstan' (with nonetymological g)
khuro.shi.ya 'Croatia' (khro would be read as [ʈʂʰo], not [kʰro])
niya. in 'Bosnia', 'Estonia', and ma.se.ḍo.niya. 'Macedonia' contrasts with ni.ya. for -nia in
A third treatment of -nia is inar.me.ni.ya. 'Armenia'
li.thu.e.ni.ya. 'Lithuania'
ro.ma.ni.ya. 'Romania'
si.lo.we.ni.ya. 'Slovenia' (slo would be read as [lo])
al.ba.nyi.ya 'Albania'
There are no examples of nya [ɲa] for -nia or even for Spanish -ña. 'Spain' is shi.pan.ya (from Mandarin 西班牙 Xibanya?).
There seem to be multiple borrowing styles in this list. Are these the only spellings used, or are these just the ones that various Wikipedia contributors happened to choose?
I've barely scratched the surface of this topic. Why, for instance, does lu.sem.ba'urag 'Luxembourg' have -a'u- instead of -u-? (I assume -rag indicates a final cluster; -rg is not a permissible coda in native Tibetan words, and the onset rg- is pronounced [k].) And where does yo.rop. 'Europe' come from? It doesn't match Hindi Yūrop which is from English Europe. The only word for 'Europe' beginning with [jo] that I can think of is Japanese Yōroppa, and I suspect its Yō- originated from a kana transliteration エウ *eu (pronounced [joː]) that was later phonetically respelled as ヨー <yō>.
13.9.25.23:59: LD- OR DL-?
Try saying the title quickly. Reversing the initials is easier for me, because "Dl- or ld-" rhymes with world.
Last night, David Boxenhorn suggested that Tangut ld- (which I had doubts about) might have been dl-. That reminded me of my late 90s belief in c(ʰ)l- and ɟ(ʱ)l- in Old Chinese (cf. modern Khmer /cl/ < *cl-, *ɟl-) corresponding to Starostin's (1989) lateral affricates before I had read Sagart (1999). If Tangut had dl-, could I reinterpret my ɬ- as its voiceless counterpart tl-? dl- and tl- could also be reintrepreted as affricates dɮ- and tɬ-. Did Tangut (once?) have the following four-way distinction?
|
|
fricative | affricate |
| voiceless | ɬ- | tɬ- (merged with ɬ-?) |
| voiced | ɮ- | dɮ- |
I've been looking at laterals in related and unrelated languages in search of typological models.
The unrelated Mong Leng language (Bruhn 2006: 9) has a somewhat different four-way distinction between TL-type initials:
|
|
nonprenasalized | prenasalized |
| unaspirated | tl̥- | ⁿtl̥- ([ⁿdl] in Smalley et al. 1990: 50) |
| aspirated | tl̥ʰ- | ⁿtl̥ʰ- |
Tangut is often thought to be Qiangic. Here are the lateral inventories of three varieties of Qiang (Sun 1981 and LaPolla and Huang 1996):
| Mawo | l- | ɬ- |
| Ronghong | l- | ɬ- |
| Taoping | l- |
|
(9.26.0:33: Mawo and Ronghong also have Cl-clusters:
| Mawo | sl- | rl- | xl- | ɣl- | χl- | ʁl- |
| Ronghong |
|
|
xl- |
|
χl- |
|
|
|
|
xɬ- |
|
χɬ- |
|
Pre-Tangut must have also had l-clusters, though most of them did not survive into 11th century Tangut:
*Sl- > l- + tense vowel
*rl- (maybe *Tl-?) > l- + retroflex vowel
*Kl- > ɬ-
I don't know what happened to *Pl-, *Ql-, or *lC-clusters.)
Guillaume Jacques has compared Tangut with Japhug rGyalrong which only has two simple laterals, l- and ɬ-, and a large number of Cl-clusters (e.g., βl-) plus the lone lC-cluster ldʑ-. Some proto-rGyalrongic *l have become nonlaterals in clusters (Jacques 2004: 330-334): e.g.,
*tl- > d-
*wl- > ʁd-
*plj- > βɟ-
*pə-lj- > βʑ-
*tlj- > ɟ-
*wlj- > ʁj-
*lj- > j-
*lC- > jC- (except *lʑ- > ldʑ-, not *jʑ-)
All of this looking around was motivated by a desire to look for alternatives to ld-. But perhaps ld- is correct after all. Xun Gong pointed out that ld- (from ld- and zl- - two initials that are interchangeable in Tibetan transcriptions of Tangut) is indeed the only cluster in Tibetan dialects of Kashmir, removing my typological objection to ld- as the only cluster of its type in Tangut.
13.9.24.23:33: DID DZ- AND Z- MERGE IN TANGUT?
Last night I decided to replace z- with ɮ- in my Tangut reconstruction since I've long thought Gong's z- was [ɮ].
All of the class IX initials in my reconstruction are laterals or retroflexes (based on Tai 2008: 201 and Kotaka 2006; major correspondences only):
| This site | l- | ld- | ɬ- | ɮ- | r- | ʐ- |
| Gong 1997 | l- | lh- | z- | r- | ź- | |
| Tai 2008 | l- | ld- | lh- | ʁz- | r- | ʁź- |
| Arakawa 1999 | l- | ld- | lh- | zz- | r- | z- |
| Sofronov 1968 | l- | ld- | lh- | z̀- | r- | z̀- |
| Nishida 1964 | l- | ɫ- | lh- | (ʁ)z- | r- | ňž- |
I am not confident about ld- because it is the only cluster of its type in my system. It was transcribed as ld- in Tibetan, but I do not know whether ld- was [ld] in the Tibetan dialects of the transcribers. It was also transcribed as zl-, suggesting that ld- and zl- had become homophonous in those dialects. Maybe I could write it as ll- and be agnostic about its phonetics. Comparative studies could narrow down possible pronunciations.
My ʐ- might have been like Czech ř.
I started to have doubts about my ɮ- when I saw the following fanqie from the Tangut Studies Association database:
0524 1dzɨu = 1648 1ɮa + 3003 2ʔɨu
This fanqie would make more sense in Gong's reconstruction:
0524 1dzju = 1648 1za + 3003 2·ju
dz- is closer to his z- than to anyone else's reconstruction of that initial. dz- ~ z- merger has occurred in Japanese, Russian, and Shanghai (e.g., 才 ze < *dz-), so it could have happened in Tangut. But I don't think it did, because I checked the Mixed Categories of the Tangraphic Sea and found that its fanqie was actually
+
0524 1dzɨu = 1902 1dziə + 3003 2ʔɨu
with a dz-initial speller as I'd expect. But I can't explain
why a second (i.e., rising) tone tangraph was used as the final speller
for a first (i.e., level) tone tangraph. Nor can I explain why dz-
and dʐ-tangraphs were all placed in the Mixed Categories
volume organized by initial class rather than the first and second
volumes organized by tones.
13.9.23.23:48: IF 'SOUND' IS ON THE LEFT, WHAT'S ON THE RIGHT?
In my previous entry, I wrote about the 'sound'-derived tangraph at the top left of the table for rhyme 44 in text A of Five Sounds. Here is a key to the entire table:
Top half: class III, V, VI, and VIII initials (from right to left)
| 1ɣew [VIII] | 1tsew [VI] | 1kew [V] | 1tew [III] | O |
| O | O | O | 1twew [III] | O |
I have added classes in brackets.
Each possible combination of class and -ew or -wew is indicated by a single syllable: e.g., tew represents all syllables with class III initials plus -ew: tew, thew, dew, new.
I think the empty first column on the right indicates the absence of syllables with class I (labial) and II (labiodental) initials: i.e., there were no syllables like pew, phew, bew, mew (I), or vew (v- is the only class II initial).
There is no column for the mysterious class IV.
Class VI initials could combine with -wew to form the syllables 1tshwew, 1dzwew, and 1swew. (There were no -wew syllables with the second tone.) If the circle under 1tsew is not an error, it may indicate that the author's dialect did not have syllables of the type Swew.
Bottom half: class IX initials
| 1lwew | 1ldew | 1lew |
| 1ɮwew | O | |
This second part is not organized like the first. There is no single character representing all class IX initials. Specific class IX initials have their own cells. -wew syllables are in a column on the left rather than in a row on the bottom.
Gong reconstructed 1lew as the reading of both tangraphs in the top right cells. However, if the two were homophonous, one tangraph should have sufficied to represent them both. The top center tangraph has initial ld- in Sofronov's (1968 II: 285) and Tai's (2008: 201) reconstructions.
I used to reconstruct z- as Gong did, but for a long time I thought z- was actually [ɮ] and now I have changed my notation. If z- were [z], it should have been classified with dz- in class VI, not with liquids in class IX. Sofronov (1968 II: 387) reconstructed z̀- for the initial of the bottom left tangraph. That initial belongs to Sofronov's class IX fanqie chain 13 which Tai (2008: 201) reconstructed with initial ʁz- (cf. Nishida's ʁz- and ʁ-).
The names for the level and rising tone variants of rhyme 44 (1xew and 2xew) are at the very bottom of the page.
13.9.22.23:23: SOUNDS RIGHT, ER, LEFT
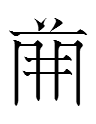
When looking for the tables for Tangut rhyme 99 in various texts of Five Sounds, the character at the top left of the table for rhyme 44 in text A caught my eye:

I initially thought that character was a variant of
4794 1məĩ (transcription character for Chinese 門 mə̃ 'gate'; 1məĩ was the closest possible Tangut syllable)
that I had never seen before, but in fact it was a different character:
=
+
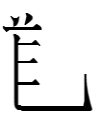
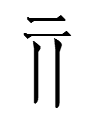
5253 1ɣew (transcription character) = right of 1586 1ɣɪ̣ 'sound' + right of 0304 1ɣa 'thin'
There is no other character with the right side of 'sound'
on the left. 'Sound' was generally abbreviated minus its left side as
(itself an abbreviation of Chinese 音 'sound'?)
though it was also abbreviated minus its right side as
in
1587 2kiew? 'to choke, block'
1685 1khĩ (transcription character)
3723 1tʂʰwɛ 'very fast'
4129 1tʂɨi 'cracking sound'
5695 1tʂʌʳ 'cracking sound'
and perhaps in
3598 2xe? 'grieved, sorrowful'
whose analysis is unknown.
What determined how 'sound' was abbreviated? And what was the logic of combining 'sound' with 1ɣa 'thin' for transcribing 1ɣew? Why not transcribe 1ɣew with a fanqie character like 6063? Or recycle the existing character
2285 1ɣew 'trench'
instead of creating a new phonetic symbol?
According to Tangraphic Sea, 5253 1ɣew was for transcribing (Chinese) classics and (Sanskrit) mantras, yet 5253 1ɣew was not a syllable in Tangut period northwestern Chinese or Sanskrit. Li Fanwen (2008: 829) gave three examples of 5253 1ɣew:
- as a transcription of the first syllable of 漚奢不帝那 (*ʔew ʂɨa pu ti na in Tangut period northwestern Chinese), a transcription of something like Sanskrit *ūṣapuṭena 'with a case of salt' - but that's unlikely in a Buddhist context, so the Sanskrit original must be something else
- as a transcription of the first syllable of 惡揭 (*ʔo kɨa in Tangut period northwestern Chinese), short for 惡揭嚕, a transcription of Sanskrit agaru- 'aloe wood'?
- as a transcription of Chinese 歐 *ʔew
Although it is tempted to revise the reading of 5253 as ʔew, the initial fanqie speller for 5253 is
1ɣʊ 'head'
which belongs to glottal fanqie speller chain 1. Tangraphs with initials spelled with members of that chain were generally transcribed with gh- and various consonant-g-sequences in Tibetan (Tai 2008: 197): e.g., 2750 was transcribed as bgu and dguH. If 5253 were ʔew, I would expect the Tibetan transcription of its initial to be ཨ, which would be transliterated as zero.
Next: If 'sound' is on the left, what's on the right?