
13.9.21.23:36: TANGUT RHYME 99 (PART 3)
In parts 1 and 2 (up until the penultimate line), I thought there were only four Tangut characters with readings ending in rhyme 99. That's true for Precious Rhymes of the Tangraphic Sea and Homophones which are almost complete inventories of the Tangut script. Almost. There are characters absent from those texts that are in other works: e.g., the fifth rhyme 99 character
which is at the top right of the phonetic tables for rhyme 99 in the D and E editions of
1ŋwə 1ɣɪ̣ 2vəi 1biu
'five sound ? rhyme'
commonly assumed to be named after the Qieyun 'cut rhymes' (though that Chinese book was a rhyme dictionary, not a set of rhyme tables, and 2vəi does not mean 'cut' - it may mean 'onset'*).
The table for rhyme 99 in the D edition is missing its bottom.
+

6063 2p-...? = 2228 1pi + 2057 2P-...?Character 6063 is a fanqie character in the sense that it is composed of components representing its onset and rhyme. Li Fanwen (2008: 121) gave the following derivation
+
6063 2p-...? = left of 5685 1po + all of 2710 2T-...?
(The source character for the right side was missing, but it's clearly 2710.) I don't know how he knew that the source of the left side was 5685 rather than another p-character with the same left side such as
5212, 5456, 5647
which were all read pị.
Beneath the fanqie is what appears to be the rhyme number followed by 2710 (the name of the rhyme) and the other four characters with that rhyme (including 2710):
1ˀiaʳ 2ɣạ 1lɨəəʳ 'eight ten four' = 'eighty-four(th rising tone rhyme)' = 99th distinct rhyme in Tangut (ignoring tones; not all distinct rhymes occur in both the level and rising tones)
2710 2T ... ? 2057 2P...? 2710 2T...? 3710 2T...? 4055 2T...?
I can't read the two characters to the right of this list. Is the top one 2057?
The table for rhyme 99 in the E edition is complete:
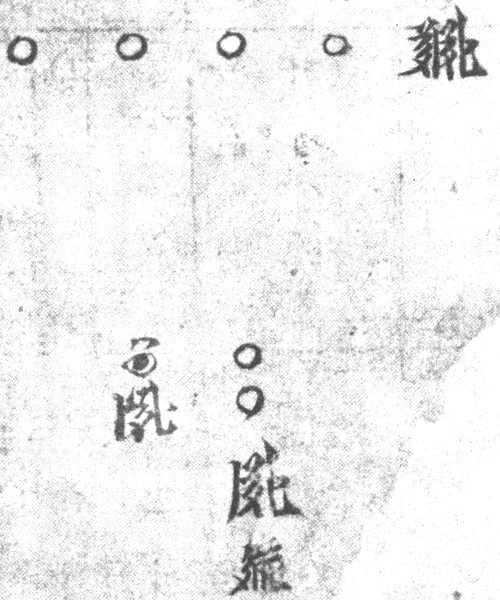
It has the name of the rhyme at the bottom followed by the name of the tone:
2T...? 'to grind' 2phiu 'rising (tone)'
The rhyme tables are intended to indicate all possible syllables in Tangut. There are only two characters in this table (not including the label at the bottom), so its author apparently thought there were only two types of syllables with rhyme 99: 2p...? (represented by 6063) and 2T...? (represented by 2710).
Was 6063 homophonous with 2057? If so, should the reading of 2057 be reconstructed as 2p...? (which would be a poor match for Tangut period northwestern Chinese 跋 *pha and Sanskrit va; see part 2)? If 6063 and 2057 were homophones, why was 6063 created? Fanqie characters are assumed to be transcription characters, but what foreign word would have had rhyme 99? Rhymes from the second cycle onward were not normally used in transcriptions of Chinese or Sanskrit, implying that those rhymes were unlike anything in those languages.
Are the dot inside the circle and the stroke above the circle over 2710 in the table significant?
*Grinstead (1972: 128) defined 2vəi as 'place together', Kychanov and Arakawa (2006: 344) defined it as 'similar, place, time, once, twice', and Li Fanwen (2008: 121) defined it as 'to correspond, place, rhyme, to go'. Kychanov and Arakawa defined the phrase

2vəi 1biu
as 'initial and final of syllable, rhyme'. 1biu is definitely 'rhyme' so 2vəi may be 'onset'.
13.9.20.23:45: TANGUT RHYME 99 (PART 2)
Like Kychanov and Sofronov (1963: 111), Nishida (1964: 67), Sofronov (1968 II: 53), and Tai (2008: 229), I thought there was no transcriptive evidence for the rare Tangut rhyme 99 which only appears in readings for four characters, but according to Li Fanwen (1986: 185), the rhyme 99 tangraph
transcribed Sanskrit va and was transcribed as Chinese 跋. In the Karlgren-style Middle Chinese reconstruction Li used, 跋 ended in -uât [uɑt], so he reconstructed rhyme 99 as -ua (-uạ in his 2008 dictionary). The b- of his reconstruction bua (2008: buạ) may be based on Middle Chinese *b- for 跋 and Sanskrit v-. However,
- I did not find that tangraph in Grinstead's (1972) lists of Sanskrit transcription characters
- Li Fanwen (1994: 200) did not find any rhyme 99 tangraphs in the Chinese transcriptions in the Pearl in the Palm and Kolokolov and Kychanov (1966) and Gong (1991) also did not include it in their lists of Chinese transcription characters in the Tangut translations of Chinese classics and The Forest of Categories
- the Tangut period northwestern Chinese pronunciation of 跋 was *pha, not *buâ(t)
- the Tangut transcription of Sanskrit va may actually be a Tangut transcription of a Chinese transcription 跋 of Sanskrit va
跋 was read as Middle Chinese *bat when it was chosen to transcribe Sanskrit va, but centuries later, that character was read as *pha in the northwest
Perhaps that character's reading could be reconstructed as 2phạʳ with a tense retroflex vowel that might be the defining trait of the fourth cycle - if there is one.
Li Fanwen reconstructed the readings of the other three rhyme 99 characters
as 2nǐɛ with a completely different rhyme. I still don't know of any transcription evidence for this trio, so I suspect that 2nǐɛ is based on the assumption that
glossed by Grinstead (1972: 77) and Kychanov and Arakawa (2006: 134) - but not Li Fanwen! - as 'tweezers', was a borrowing from 鑷 Middle Chinese *ɳɨep 'tweezers'.
(9.21.11:49: 鑷 *ɳɨep would have become *ɳɖʐɨa in Tangut period northwestern Chinese. If 4055 were from *ɳɖʐɨa, it would have had initial ɖʐ- and been placed in Mixed Categories of the Tangraphic Sea along with other Tangut ɖʐ-syllables rather than the second volume of Precious Rhymes of the Tangraphic Sea. Moreover, 4055 and its homophones were placed with dental-initial characters in chapter III of Homophones, not retroflex sibilant-initial characters in chapter VII. So 4055 had initial t-, th-, d-, or n-, not ɖʐ-. Lastly, although 鑷 *ɳɖʐɨa ends in *-a like the transcription data for 2057 - 跋 *pha and Sanskrit va - why would it be borrowed into Tangut with a tense retroflex vowel - if that was the defining trait of the fourth cycle? Retroflex sibilants did not condition vowel retroflexion; they are found in syllables of the first and second cycles whichhad nonretroflex vowels as well as the third and fourth cycles.)
Nishida (1964: 67) took a third approach to reconstructing rhyme 99 (rhyme 96 in his system at that time). He thought it might have been -ɪ̣r, the tense retroflex counterpart of rising tone rhyme 7 which he reconstructed as -ɪ, since he believed that rhyme 99 and rising tone rhyme 7 characters were combined in homophone group 85 of chapter VI in Homophones. However, it turns out that the 'rhyme 99' character in that chapter
was actually a rising tone rhyme 7 character 2səi 'to tighten' resembling the true rhyme 99 character
and that the true rhyme 99 characters in Homophones were an isolated character in chapter I and homophone group 154 in chapter III.
Next: A fifth rhyme 99 character!
13.9.19.23:59: TANGUT RHYME 99 (PART 1)
In Sofronov (1968 I: 137-138), Tangut rhyme 82 (of the second small cycle) and 99 (of the third small cycle) were both listed as -ẹ. I thought this might be a typo that I could correct in my Tangut rhyme database (Excel / HTML), so I checked the reconstructions for the four Tangut rhyme 99 characters in Sofronov's second volume (below) - and found none, though Kychanov and Arakawa (2006: 134, 223, 479, 585) list Sofronov-style reconstructions .
| Tangraph | Li Fanwen 2008 gloss | Kychanov and Arakawa 2006 gloss | Shi et al. 2000 gloss | Grinstead 1972 gloss | Nishida 1966 gloss | Nishida 1966 | Li Fanwen 1986 | Gong 1997 | Kychanov and Arakawa 2006 | This site |
| |
to be frightened | to attack | (none) | 2bua (2008: 2buạ) | 2meer | 2mẹ | 2məəiʳ | |||
 |
to grind | to grind, rub, massage | to mix and grind | (none) | 2nǐɛ (2008: 2nǐɛ̣) |
2deer | 2ndẹ | 2dəəiʳ | ||
 |
to fear, to terrify | to be discriminating | to translate | to choose? | ? | 2nǐɛ (2008: 2nǐɛ̣) | ||||
 |
a unit of measurement | tweezers | a unit of measurement | tweezers | to use both hands | ? | 2nǐɛ | |||
(The reconstructions in Li Fanwen's 1986 system as printed in his 2008 dictionary differ slightly from those in his 1986 book.)
My reconstructions are converted from Gong's system. I am now tempted to reconstruct them as 2P...ʳ and 2T...ʳ because
- their tones can be verified in Precious Rhymes of the Tangraphic Sea
- their initial classes (I/labial and III/dental) can be verified in Homophones, but not their specific initials
- their Homophones groups do not contain any other rhymes which would be similar
- their listing toward the end of Precious Rhymes of the Tangraphic Sea indicates they belonged to the third cycle with retroflex vowels
- I don't know of any Tibetan or Chinese transcriptions for these tangraphs
- I don't know of any instances of these tangraphs transcribing Chinese or Sanskrit
I don't know how the initials were determined by previous scholars*, but I do know the reasoning behind Nishida's (1964) reconstruction of the rhyme as (not used in his 1966 dictionary!), and I'll reexamine it next time.
*9.20.1:16: Now I think I understand how Li Fanwen reconstructed b- for 'to be frightened', and I can guess why the other three words were reconstructed with n-, d-, or nd-. More in part 2.
13.9.16.23:59: HOMOPHONOUS RHYMES IN SOFRONOV (1968)
Sofronov's (1968) reconstruction of late 12th century Tangut has many homophonous rhymes that were distinct in the earlier language of the Tangraphic Sea: e.g.,
| Rhyme | Tangraphic Sea | Late 12th century Tangut |
| 1 | -u | -u |
| 4 | -uC | |
| 5 | -un | |
| 2 | -i̭u | -i̭u |
| 3 | -ʏ | |
| 7 | -i̭un |
The only u-type rhyme of this group that didn't merge with any other rhyme was -ûn which later became -û. (Oddly there is no original -û even though there are other rhymes ending in Grade II monophthongs: -ê, -â, -ə̂, -ô.)
In theory, all 105 rhymes should be distinct in the Tangraphic Sea language, yet this is not the case in Sofronov's reconstruction. Some instances of apparent homophony in his 1968 list of rhymes on pp. 136-138 of vol. 1 are typos if the reconstructions of individual character readings at the back of vol .2 are correct: e.g., rhymes 51 and 52 both appear as -o in vol. 1 but are distinguished as -o and -ô in vol. 2. (I have begun to correct those typos in my Tangut rhyme database: Excel / HTML.) However, yet other rhymes are homophonous even in vol. 2: e.g.,
- rhymes 61 and 80 are both -ụ
- rhymes 66 and 85 are both -ạ
Nishida, Gong, Arakawa and I reconstructed rhymes 80 and 85 with retroflex vowels distinct from the tense vowels of 61 and 66:
| Rhyme | Sofronov (1968) | Nishida (1964) | Gong (1997) | Arakawa (1999) | This site |
| 61 | -ụ | -ụ | -ụ | -uq | -əụ |
| 80 | -Ur | -ur | -ur | -əuʳ | |
| 66 | -ạ | -ɑ̣ | -ạ | -aq | -ạ |
| 85 | -ɑr | -ar | -ar | -aʳ |
Initial r- occurred almost exclusively with the retroflex vowels that it had conditioned.* r- preceded rhymes 80 and 85 but not 61 and 66.
*9.17.0:19: Initial r- could occur before nonretroflex vowels in the rhyme 43 syllable riẽ from pre-Tangut *Cɯ-reN. Perhaps an intermediate stage *-iẽʳ with a nasalized retroflex vowel simplified to -iẽ, losing its retroflexion, whereas other nasalized retroflex rhymes retained their retroflexion but lost their nasalization.
13.9.15.23:30: 105 RHYMES DATABASE UPDATE: SOFRONOV (1968)
My Tangut rhyme database (Excel / HTML) now contains the three most important reconstructions: Nishida (1964), Sofronov (1968), and Gong (1997). I will eventually add Sofronov's reconstructions from 1963 and 2012. Kychanov and Arakawa's 2006 dictionary includes character readings in his 1968 reconstruction. (Alas, it did not also include readings in Arakawa's 1999 reconstruction.)
In 1968, Sofronov reconstructed two sets of rhymes, one for the Tangraphic Sea and another for the late 12th century. Three differences between the two systems:
- Breaking of -ʏ (a vowel occurring only in rhyme 3; lacks a high counterpart -y) to -i̭u
- -C either became zero or -ɯ
- a fronted to e before -i except in -aiC which became -ai, not *-ei
Both systems have four 'cycles' of rhymes: a large cycle (rhymes 1-60) followed by three small cycles (rhymes 61-76, 77-98, 99-105) written with subscript dots.
Within each cycle are rhyme groups whose members have up to four types of grades:
I. non-high front vowel (u, e, a, ə, o)
II. non-high front vowel + circumflex
III. i̭ + vowel
IV. high front vowels: i, ɪ, ʏ
These grades were not in Sofronov's 1968 rhyme list. I have assigned them based on the grades in his 2012 reconstruction.










