
2ʔiẽ 'sock'
12.10.6.23:59: UNRAVELING TANGUT SOCKS
I found a lost
2ʔiẽ 'sock'
this evening.
The analysis of the Tangut character for 'sock' is probably in the lost second volume of Tangraphic Sea. Perhaps it was something like
+
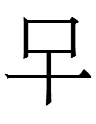
2ʔiẽ 'sock' = 2tʂhɨi 'base' + 2lə 'to cover': i.e., clothing that covers the lowermost part of the body
In any case, 'sock' clearly consists of three parts:
+
+
'base' + 'earth' + 'skin'
Tonight it occurred to me that 'base' could be derived from Chinese 本 'base' (cursive) which also has five strokes.
I thought that 'earth' might be from Chinese 也 (cursive), the right side of 地 'earth', or even 地 'earth' itself (cursive) tilted 90 degrees counterclockwise with an added dot, but I then wondered if it might be a cursive derivative of the Khitan characters
<?> 'yellow (the color of earth)' (in the large script; derived from Chinese 黄?; what's the large script character for 'earth'?)
<neu> 'earth' (in the small script)
which also have 人-like shapes on their bottoms.
The Khitan scripts were over a century old by the time the Tangut script was created c. 1036, possibly by a member of the Khitan Yelü clan. Grinstead (1972: 13) has more on the connection between the Khitan and Tangut scripts. Even if the Tangut element for 'earth' has nothing to do with Khitan, other puzzling un-Chinese elements in Tangut may correspond to Khitan characters.
I proposed that 'skin' could be from Chinese 皮 at least two years ago. Notice how the long left-hand stroke 丿is shortened so the top element resembles 宀 in three of these cursive forms.
I have no idea where the word 2ʔiẽ 'sock' comes from. I can't find any cognates at STEDT. Other Qiangic languages borrowed Mandarin 袜子 wazi 'sock'.
12.10.5.23:57: 'BODHISATTVA' IN TANGUT 4: JUST ADD WATER?
I noted last night that the first character of one of the two Tangut words for 'bodhisattva'
2dʐæ̃ 2tsie
isn't in any native Tangut dictionary. This is surprising given the prominence of Buddhism in the Tangut Empire. This word was so important that it appeared twice in the short Tangut-Chinese textbook The Pearl in the Palm which was written in 1190, long after the dictionaries in the 11th century.
But was it spelled correctly in the Pearl? Li Fanwen (1997: 1071) proposed that
2dʐæ̃
is a variant of its homophone
2dʐæ̃
'all living creatures, blood'
which is in native Tangut dictionaries*.
Kychanov (2006: 559) spelled 2dʐæ̃-1tʂhɨu 'all living beings' with both graphs, though he did not regard them as homophones (and hence presumably did not regard them as variants):
2dʐæ̃-1tʂhɨu = 1tshɪ-1tśhi̭u in Kychanov 2006
2dʐæ̃-1tʂhɨu = 1ndźân-1tśhi̭u in Kychanov 2006
The difference between the two is the absence or presence of the
'water'
radical which is the left-hand radical of
1sie 'blood' (possible Sino-Tibetan cognates at STEDT)
The left-hand element of the two 2dʐæ̃ graphs is an independent character
2reʳw 'ladder, stairs, steps' (one of the few simple Tangut characters - an original pictograph or a modification of the right side 弟 of Chinese 梯 'ladder'?)
and a component defined by Nishida (1966: 244) as 'rise', so they can be analyzed as
=
'ladder/rise' + 'blood' = 'all living creatures, blood'
-
=
'all living creatures, blood' - 'water' = first half of 'bodhisattva'
Is a bodhisattva
(an unattested spelling of 2dʐæ̃ 2tsie)
one who understands (2tsie) the true nature of all living things (2dʐæ̃)?
Next: Hemo-phony and Analyzing in Vein
*10.6.1:50: Han (2004: 268) lists all attestations of both 2dʐæ̃-graphs
in key Tangut lexicographic works. Although the second graph appears in two editions of the Tangraphic Sea, it appears in entries for other graphs. I don't know of any Tangraphic Sea entry for it.
12.10.4.23:56: 'BODHISATTVA' IN TANGUT 3: A 1TSI-COND READING
As if the etymological problems of the two Tangut words for 'bodhisattva'
1po 1tsa
2dʐæ̃ 2tsie
from my last two entries weren't complex enough, Kychanov (2006: 559) listed a completely different reading for
which he defined as 'living being': tshɪ 1.30 (equivalent to my tshiə 1.30). Kychanov's readings are normally in Sofronov's 1968 reconstruction, but Sofronov 1968 does not have a reconstruction or even an entry for this character which does not appear in either the Tangraphic Sea or Homophones. It appears in two editions of The Pearl in the Palm (Han 2004: 347) with the Chinese phonetic glosses
挐精 *næ tsie (20.6.7-8 in Nishida's 1964 edition)
尼盞精 *ndʐi-tʂæ̃ tsie* (36.2.3-4 in Nishida's 1964 edition)
which are closer to
Nishida 1964: ndžɑ̃ tseɦ (no tones given; 2.22 [not 2.23!] and 2.33?)
Li Fanwen 1986**: dʑá̃ ~ ȵã 2.23 tsẽ 2.33
Gong Hwang-cherng 1997 and 2008***: ńiã 2.23 tsjij 2.33
This blog: dʐæ̃ 2.23 tsie 2.33
than to tshɪ 1.30 tshɪ 2.33. I don't know of any other phonetic data for the first syllable. Where did Kychanov get tshɪ 1.30 from? The equivalent of this syllable in Gong's 1997 reconstruction, tshjɨ 1.30, appears in Richard Cook's UniTangut.txt (now offline) in the "tLFW1997Phon" field even though it does not appear in Li Fanwen's 1997 dictionary containing Gong's readings. There is no mention of Kychanov 2006 in UniTangut.txt. Is there a second source pointing to a reading with tsh- and rhyme 1.30? Could
have had two readings, one with dʐ- and another with tsh-?
Next: Just Add Water?
*10.5.00:50: The sequence *ndʐi-tʂ- transcribed a Tangut voiced affricate dʐ- which had no equivalent in northwestern Tangut period Chinese. There was no syllable like ndʐæ̃ in that dialect, so Tangut 2dʐæ̃ was approximated as a fusion of two existing syllables: 尼盞 *ndʐi-tʂæ̃ = *ndʐæ̃.
12.10.3.23:59: 'BODHISATTVA' IN TANGUT 2: 2DZ̢Æ̃ 2TSIE
Tangut has two words for 'bodhisattva'.
As I explained yesterday, the first word
1po 1tsa
superficially resembles the northwestern Chinese word but has unusual consonants.
The second word looks totally alien:
2dʐæ̃ 2tsie (jantse in simplified notation)
Last night I thought it might be a heavily disguised borrowing of some spoken version of Written Tibetan byang chub sems dpaH 'bodhisattva':
- if byang became something like jang early enough (but after *-aŋ became -o in Tangut*), that could be the source of 2dʐæ̃
- the second and third syllables could have been compressed into Tangut 2tsie. The high vowel *u conditioned the partial raising of *e to ie and the final -s became the source of the 'rising' (i.e., second) tone in Tangut:
chub sems > chu-semH > pre-Tangut *tʂhu-semH > *tʂhu-sieH > *tʂ-sieH > 2tsie
But there is no evidence that by- became like j- in the Tibetan transcriptions of Tangut which presumably reflect dialect(s) of Tibetan that the Tangut were in contact with.
Moreover, if Tibetan -s corresponds to the Tangut rising tone, why does -s-less byang correspond to Tangut 2dʐæ with a rising tone?
Lastly, the structure of byang chub sems dpaH is
byang chub 'bodhi' + sems 'mind' + dpaH 'brave'
not
byang + chub sems + dpaH
so to compress it as 2dʐæ̃ 2tsie makes no sense. Deriving 2dʐæ̃ 2tsie from the shorter form byang sems 'bodhicitta, bodhisattva' won't work either because there is no reason for sems to be Tangutized with ts- and -ie instead of -e.
Tonight I realized 2tsie is simply the native Tangut word for 'to realize, know'. It may be cognate to
| Tangraph | Reading | Pre-Tangut | Gloss |
|
|
2sie | *Cɯ-se-H or *sje-H | knowledge, to know |
|
|
2siẹ | *Sɯ-se-H or *S-sje-H | wisdom |
|
|
1swie | *Pɯ-se or *P-sje | clear, obvious |
|
|
2siə | *Cɯ-sə-H or *sjə-H (schwa conditioned by vowel of prefix?) |
to know, to understand |
|
|
2tsi | *t-si-H (zero grade of root *√s-j?) |
enlightenment |
and Written Tibetan sems 'mind' (more cognates at STEDT) or shes-pa 'to know' (more cognates at STEDT). The t- of 2tsie could be the remnant of a presyllable *tɯ- that conditioned the partial raising of *e to ie. Or perhaps there was no raising. The -i- could be a retention of a proto-medial:
*sj- > Tibetan sh- but Tangut si- = [sj]
So perhaps 2dʐæ̃ 2tsie is one who knows 2dʐæ̃. What, then, could 2dʐæ̃ be? It vaguely resembles Sanskrit jñāna- 'knowledge'. Other reconstructions
Li Fanwen 1986**: 2dʑá̃ ~ 2ȵã
even have an initial palatal nasal like Pali ñāna- 'knowledge'. However, if 2dʐæ̃ was an Indo-Tangut (!) word for 'knowledge', why isn't it attested outside the disyllabic word for 'bodhisattva' (not 'jñānasattva'!)? Did 2dʐæ̃ 'knowledge' become extinct outside this compound, or am I on a completely wrong track?
Next: A Tshɪ-cond Reading?
*10.4.0:59: I considered the possibility that
1po 1tsa 'bodhisattva'
could have been borrowed from Tibetan byang chub sems dpaH before *-aŋ became -o in Tangut, but I would expect byang to become 1bio, not 1po, and 1tsa only has an s in common with Tibetan.
**10.4.1:48: Li Fanwen's 1986 book on Homophones lists no reading for
since the character is curiously absent from Homophones (even though 'bodhisattva' was an important word to Tangut Buddhists!) but it does list 2dʑá̃ ~ 2ȵã as the readings for its homophone
'all living creatures; blood'
***10.4.1:52: The actual reconstruction as printed in Li Fanwen 1997 and 2008 is 2ńia which is doubly strange because Gong has never included ń- in his list of Tangut initials (could it be a carryover from Li's 1986 reconstruction system?) and its vowel is oral rather than nasal even though the syllable belongs to rhyme 2.23 - or does it? I have corrected -ia (Gong's rhyme 2.15) to -iã (Gong's rhyme 2.23).
12.10.2.23:52: 'BODHISATTVA' IN TANGUT 1: 1PO 1TSA
The Jurchen clan name Puca from my last entry brought to mind the similar-sounding Tangut word
1po 1tsa 'bodhisattva'
I would expect it to resemble the northwestern Chinese word for 'bodhisattva' which was
菩提 *bo sat > *bo sar > *phou saʔ > *phəu sa
at various points between the seventh and twelfth centuries. There is no reason that the Tangut word couldn't have been *1bo 1sa(ʳ) (if it was an early loan) or *1phəu 1sa (if it was a late loan). Why does the actual word have
- an unaspirated voiceless p- instead of *b- or *ph- in the first syllable?
- an affricate ts- instead of s- in the second syllable?
Tonight it occurred to me that the 1tsa might be a compression of the second and third syllables of the longer Chinese term for 'bodhisattva':
*菩提薩埵 *bo dei sa twá > *1po 1tsa
But the p- remains a mystery.
Next: The even bigger mystery of the other Tangut word for 'bodhisattva'.
12.10.1.23:55: RICH RUSH: JURCHEN LABIAL LENITION
I ended my previous entry with a note about the p-to-f shift in Jurchen. On Saturday while looking for this article on Tangut by Eric Grinstead, I found an article by Hok-lam Chan (1974: 8) mentioning two transcriptions that exemplify the shift:
蒲察官奴 *phu tʃha kɔn nu with 蒲 'rush' for Jurchen Puca ?Gonu
(The clan name 蒲察 is in the Histories of the Song, Jin, and Yuan)
富察官奴 *fu tʃha kɔn nu with 富 'rich' for Jurchen Fuca ?Gonu
(宮 may be an OCR error in the PDF for 官.)(The clan name 富察 is in the History of the Ming Dynasty and the Draft History of the Qing Dynasty)
Empress Dowager Cixi was born to a mother of the Fuca clan six centuries after Puca Gonu's death in 1233.
Today I found a Wikipedia list of Manchu clans which contains names with P-. All of these names appear to be Chinese with or without the suffix -giya added to turn monosyllabic Chinese surnames into quasi-Manchu disyllables. None are Manchu names that escaped the p-to-f shift.
10.2.1:36: One name (Piao = Manchu Piyoo?) could be a Mandarization of Korean 朴 Pak. Was this clan Korean?
12.9.30.23:59: WERE JURCHEN LIONS LITTLE DOGS IN MOUNTAINS ATOP TREES?
Last Friday, I got caught in what the Jurchen would have called
<a.ga> 'rain'
and that made me investigate the Jurchen large script characters for a.
One of them was first attested as a logogram <api> 'lion'* in 女眞字書 (a.k.a. 女眞字文書), "compiled originally by Wanyan Xiyin, the inventor of the Jurchen large script [...] a type of textbook, a basic character list, apparently for beginners learning the Jurchen script" (Kane 1989: 8).
This character later changed slightly and came to be used for a. api 'lion' was then spelled with a phonetic complement <pi> as <api.pi>:
>
>

<api> > <api> > <api.pi> = <a.pi> 'lion'
I suspect that the character <api> is an abbreviation of the left and right-hand components of Chinese 獅 'lion':
犭 'dog' > ナ
帀 > 卞 > 小 (which looks like Chn 小 'little')
But where does the word api come from? It's unlike Turkic arslan 'lion' found in Mongolian and Manchu as arsalan. Lions are not native to Manchuria, so api must either be a native word originally meaning something else or a loanword.
Kane (1989: 221) wrote,
W. Fuchs (1976) suggested that this word might be connected with some form of the name 'Africa'; its derivation, and possible cognates in other languages, however, remains obscure.
Moreover, why does
<pi>
look like Chinese 山 'mountain' atop 木 'tree'?
10.1.2:49: Jin Qizong (1984: 117) proposed that <pi> was from the Khitan large script character
(I hope I wrote it correctly!)
which has what looks like 禾 'grain' with a dot beneath 山 'mountain'.
Given that Manchu fi means 'brush' and must be from a Jurchen pi (whose roots go back much further), could both of these graphs have originally represented words for 'brush'? The problem is that there is already a Jurchen
<pi> 'brush'
whose Khitan large script ancestor may have been
according to Jin Qizong (1984: 121).
Perhaps the non-brush Jurchen <pi> was originally a logogram for a native homophone pi or a polysyllabic word beginning with pi. Or it was once a phonogram for any pi that did not mean 'brush'. The same hypotheses also apply to its Khitan large script near-lookalike.
*10.1.3:10: The phonology of Jin Jurchen - the language as spoken at the time the Jurchen large script was created around 1120 - is obscure, but one thing is certain: it initially had a p that lenited to f by the time Jurchen was transcribed in Chinese during the Ming Dynasty: e.g., 'lion' appears in the Sino-Jurchen vocabulary of the Bureau of Interpreters as 阿非阿 *a fi a (for afiya?; #432) with -f-. (The final -a is unexpected and corresponds to nothing in the Jurchen large script spelling or in the Sino-Jurchen vocabulary of the Bureau of Translators.)



















{kind=link}