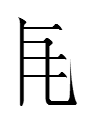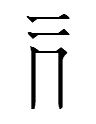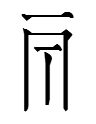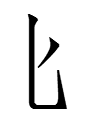





alphacodes: cin (548), cok (223), dal (81), fak (45), dom (27), gix (8)
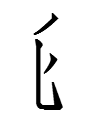




10.6.5.23:39: TANGRAPHIC RADICALS 4: WHAT'S THE DEAL WITH THE DOT, DIR?
The radical cox in my last post is just one out of two dozen similar-looking radicals that can only occur in (bottom) right position (with at least one exception - see LFW2307 below, a mirror version of LFW5312). Here are eleven that I found in Andrew West's Tangut radical font. Numbers in parentheses indicate the number of tangraphs containing them according to David Boxenhorn's Tangut Search tool.
alphacodes: cin (548), cok (223), dal (81), fak (45), dom (27), gix (8)
alphacodes: cox (10), dir (14), dau (5), fil (11), heu (72)
These radicals alone appear in one out of six tangraphs. See Kychanov (2006: 5-6) for a full list of these radicals (B256-B279*). Some only appear once (gia, hao, vax).
A couple of analyses imply that cok and cox are equivalent:
Are there similar analyses for cox and dir? Here are all 14 dir tangraphs:
| Tangraph | LFW # | Reading | Gloss | Function of dir | Source of dir | Derivatives |
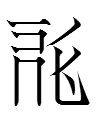 |
0485 | 2swiə | felt; rug | part of semantic 0488 | probably |
 and maybe   |
|
0488 | 2ləu | part of semantic 0485 | probably |
possibly (circular!) |
|
 |
0609 | 1zi | other; that; it | ? |  |
|
 |
0610 | 2kwə | to burst; to break | part of semantic 5308? | probably |
|
 |
1167 | 1twe | lame | part of semantic 5308 | |
? |
 |
2307 | 1kwæ | first half of 1kwæ-1kwʌ 'to step on; to burst; to split' | |||
|
2453 | 2swiə | first half of the surname 2swiə-2rieʳ | part of phonetic 0485 | probably |
|
 |
2522 | 1lɨə | first half of 1lɨə-2lɨu 'slow; tardy' | part of semantic: those who take years to come? | |
|
|
2530 | 2si | second half of 1khiã-2si 'enemy; foe' | part of phonetic 0485 or semantic: enemies as those who break? | possibly |
|
 |
3886 | 2dʒææ | lameness | part of semantic 5308 | |
|
|
5308 | 2kwə | convulsion; spasm; lame; bent | part of semantic 0610 | |
 |
|
5312 | 1kwʌ | second half of 1kwæ-1kwʌ 'to step on; to burst; to split' | part of semantic 5308 | |
? |
 |
5583 | 1tsə̣ | chopsticks | ? |  |
|
|
5878 | thirt | classifier for threads and trees (Jacques 2007: 165) | |
|
|
|
5879 | 2si | second half of 2si 'year'; if from Chn 歲 *swi (Li Fanwen 2008: 927), why is -w- missing? But note possible phonetic 0485 does have -w-. | contrary to Tangraphic Sea, part of phonetic 0485? | but I suspect actually |
|
I was expecting to see derivations with cox (= dotless dir) as input or output, but didn't find any. No dir tangraphs are derived from or derive non-dir tangraphs. This implies that dir is a distinct radical and not a variant of another radical.
I wonder if dir in 0485 and 0488 is from Chn 毛 'hair; fur' as in 毯 'rug'. The dot would be a distortion of the second horizontal stroke. That would account for dir in those two tangraphs and their derivatives (0609?, 2453, 2522?, 2530?, 5583?, 5878?, 5879?). But dir in 5308 'lame' and its derivatives could have a different origin.
*Does B274 really exist? It only appears at the bottom right of LFW4738 in Kychanov (2006: 74, 662):
Li Fanwen (1986: 331, 709) has B274, but Han Xiaomang (2004: 306) and Li Fanwen (2008: 751) have B273 instead. The reproductions of its entry in the two editions of Homophones in Sofronov (1968 II: 186) appears to have B273, but I'm not sure.
10.6.4.23:36: TANGRAPHIC RADICALS 3: COX
Tangraphy sometimes seems like one endless eye exam. Only one stroke distinguishes the radical 'high' (< half of Chinese 高?) from the radical 'before' (< top and left of Chinese 前?):
But more familiar writing systems also have their lookalikes. I've known the differences between E and F, 大 'big' and 犬 'dog', and Ш sh and Щ shch for most of my life. (I learned the Russian alphabet in childhood long before I studied Russian.) However, Tangut also has lookalike radicals with the same number of strokes. One of them (alphacode: cox) appeared in line 15 of the Golden Guide last night. It has a slanted stroke corresponding to a horizontal stroke in the radical cok:
cok appears in 223 tangraphs but cox is only in ten. Both only occur in right-hand position.cox and cok
Grinstead (1972: 58) proposed that "non-typical elements" (his term) like cox were created to distinguish what would otherwise be duplicate tangraphs. For example, suppose two tangraphs, one consisting of radicals A and D and another consisting of radicals B and cok, formed Acok:
AD + Bcok = Acok
Now suppose one wants to create a tangraph out of AE + Fcok:
AE + Fcok = Acok
The result would be indistinguishable from the previous combination unless cox were used as a substitute for cok:
AE + Fcok = Acox
Grinstead's proposal predicts that at least one cox tangraph
- has its cox derived from a cok tangraph
- has a lookalike with cok instead of cox
However, none of the ten cox tangraphs have lookalikes with cok. Moreover, only one of the known derivations for a cox graph contains cok (LFW5259). Two derivations are circular (LFW5258, LFW5261).
| Tangraph | LFW # | Reading | Gloss | Function of cox | Source of cox | Derivatives |
 |
0017 | 2paʳ | white-hooved horse (0017 is a variant of 0486) | ? | ? |  |
 |
0486 | |||||
 |
0535 | 1ʃɨe | according to | differentiate 0535 from phonetic 1871 1sie without cox; why not use cok? |  |
|
 |
2452 | 2lɨị | second half of 2bi-2lɨị 'before; formerly'; 'eternal' by itself | why is 0535 a component? because 'according to X' implies X existed before? | |
? |
 |
4102 | 2ʔɔ̣ | garden; yard (< extended use of 5258 with rising tone from *-H suffix?) | part of phonetic 5258 | probably |
|
 |
4110 | 2paʳ | awning; shed | part of phonetic 0486 | probably |
|
|
5258 | 1ʔɔ̣ | round; ring; courtyard; all | differeniate 5258 from 4743 without cox; why not use cok? |  |
|
 |
5259 | 1liew | transcription character | left side is unique and in theory doesn't need cox to disambiguate it; if a right side was needed, why not use cok? |  |
? |
|
5261 | 1kwə̣ | unfired brick (contra Li Fanwen 2008: 830, cannot be from Chinese 墼 *ki < *kek; the rhymes are too different) | were 1kwə̣ bricks round? | |
|
|
5267 | 1liẽ | transcription character | represents the rhyme of 0535 | |
? |
In some cases, cox is part of a phonetic (4102, 4110) or the abbreviation of a phonetic (5267) or semantic element (2452). In others (0535, 5258), cox distinguishes a tangraph from another tangraph without cox. I don't understand what it's doing in the remaning four tangraphs.
If one were to simpify tangraphy, one could replace all instances of cox with cok and no ambiguities would result. 5259 could lose its right side entirely and its unique left side could stand by itself.
10.6.3.22:48: THE GOLDEN GUIDE: LINES 17-18: TANGRAPHS 81-90
I wish to thank Alan Downes for providing the Tangut indexes that have enabled me to write these last few posts much more quickly.
And I also thank Andrew West for introducing me to Alan.
I hope they don't mind tonight's translations. I am uncertain about them and would appreciate help.
| Tangraph number | 81 | 82 | 83 | 84 | 85 |
| Tangraph |  |
 |
one | |
 |
| Li Fanwen number | 2440 | 5168 | 5981 | 0535 | 2221 |
| My reconstructed pronunciation | 2niəə | 2ʔiə | 0ʔa | 1ʃɨe | 1vəə |
| Tangraph gloss | sun; day | past; last | one; upward directional (perfective) prefix | according to | to own; to have; to belong to |
| Word | all together; as a whole; consistently; uniformity | ||||
| Translation | Previous days have uniformity, | ||||
81: Cognate to Chinese 日 'id.'; cf. 6 'sun'.
82: Contains a phonetic on the left (< Tangut period northwestern Chinese 羊 *jõ) plus 'before' (semantic) on the right.
82-81 means 'yesterday', but what does 81-82 mean? Following Nishida (1966: 274, 574), I regard apparent adjective-noun sequences as compound nouns and noun-adjective sequences as true phrases. My guess is that 81-82 'day past' (noun adjective) refers to past days in general whereas 82-81 'past-day' (noun) refers to a more specific day (yesterday).
83: A distortion of Tangut period northwestern Chinese 阿 *ʔa? Gong (2003: 608; Li Fanwen 2008: 942) now reconstructs this as ʔja, but both the Chinese and Tibetan transcriptions point to ʔa without j-.
0- indicates an unknown tone.
84 1ʃɨe contains the phonetic 1sie 'thin, tiny' (< Tangut period northwestern Chinese 細 *sjej) plus a right-hand radical of unknown function (alphacode: cox):
+
cox only appears in ten tangraphs. I've made GIFs for seven of them over the past 4 1/2 years of Tangut blogging. I just made GIFs for the remaining three which I'll blog about in my next entry.
83-84 'uniformity' could be regarded as 'one accordance'. Nie Hongyin and Shi Jinbo translated it as 一律 'uniformity', literally 'one regulation'.
85 might be cognate to Old Chinese 有 *wəʔ 'to have; to exist'. Its analysis is
+
'to own' = 'ruler' (possessor?; semantic?) + 1vəə 'soft; tender' (phonetic)
'Ruler' contains 'person' and a radical of unknown function over 'sage'.
| Tangraph number | 86 | 87 | 88 | 89 | 90 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 2712 | 3583 | 4088 | 4024 | 5625 |
| My reconstructed pronunciation | 1vɨi | 1tia | 2lɨõ | 2ziə̣ | 1thwəəu |
| Tangraph gloss | year | topic marker | pair | two | same; alike |
| Word | both; together | ||||
| Translation | Years are both [?] alike. | ||||
86 has a three-part analysis in Tangraphic Sea:
+
+
'year' = 'year' + 'flow' + 'moon'
1vɨi may be from *Ci-pa with a lenited stop initial *p and a high vowel presyllable *Ci- conditioning raising and fronting of *a. gDong-brygad rGyalrong ɯ-xpa 'year' preserves the original *pa root.
87 is a topic marker and is not obligatory. It is not equivalent to, for instance, a nominative case ending. I suspect it may have been inserted here to fill up the line. But if that were the case, could a disyllabic word for 'year' have been chosen instead?
87 has an abstract meaning that has nothing to do with the components in its Tangraphic Sea analysis:
+
+
1tia 'topic marker' = 2tsie 'to realize; to know' + 1dzwiõ 'bird' + 1tsəiʳ 'earth'
What could the real origin of the tangraph be? Its right side (alphacode: biobaegiicok) appears in no other tangraphs.
88 2lɨõ can represent several different similar-sounding Tangut period northwestern Chinese syllables
涼梁糧良亮 *ljõ
隴 *ljũ
but here probably represents 兩 *ljõ 'two; both'.
89 2ziə̣ is reminiscent of Tangut period northwestern Chinese 二 *ʒi 'two', but its initial and vowel do not match, and the tenseness implies a lost preinitial or presyllable absent in Chinese. Moreover, although Sofronov (1968 II: 291) reconstructed it as z̀i̭ə̣, my equivalent of his z̀- (ʒ-) cannot be the initial since it was transcribed in Tibetan with z- rather than zh-: ziH, gzi. Tangut z- may be from a lenited
*ts- *tsh- *dz- *s-
as well as *z-, so 2ziə̣ could be from *Cɯ-(t)s(h)əH or *Cɯ-(d)zəH and have nothing to do with Chinese *ʒi.
́́88-89 with 'two' (twice!) corresponds to 83-84 with 'one'. I don't understand why 'both' is used instead of 'all'.
Both 88 and 89 have the left radical of 1niəə 'two'. Although the Tangraphic Sea derived 1niəə from 89,
=
1niəə 'two' = 2ziə̣ 'two' + 2lọ 'two' (also borrowed from Chn 兩 'two; both'?)
I suspect the actual direction of derivation was the opposite:
90 1thwəəu is a loanword from Tangut period northwestern Chinese 同 *thə̃w. The medial -w- is not from Chinese and reflects a Tangut prefix *P(ʌ)-.
I don't understand what 'flourishing' has to do with 'same':
+
1thwəəu 'same' = 1veʳ 'flourishing; luxuriant' + 1swəu 'similarity'
Nor do I understand how previous days have uniformity or years are both alike. The point of this couplet is lost on me.
10.6.2.23:52: TANGUT GRADE II: THE UVULAʁ LINK
I proposed three sources for Grade II rhymes in Tangut nearly a month ago:
1. Pre-Tangut uvular initials (*Q-): e.g.,
1ɣʊ < *Cʌ=Qu 'head'
(equal sign indicates a presyllable that conditioned lenition of the following initial)
2. Pre-Tangut medial *-r- in 'low' class syllables (syllables with *e *a *o and/or presyllables with *ʌ): e.g.,
1phɔ̃ < *phroN 'white'
3. Pre-Tangut alveopalatal initials (*Sh-) in 'low' class syllables: e.g.,
1ʃ ɨõ < *ʃoN 'iron'
How did these different sources lead to the same result? And why didn't medial *-r- have the same retroflexion effect as initial *r- or final *-r?
*rV > rVʳ
*CVr > CVʳbut *CrV > CV rather than CVʳ
For some time I've wondered if pre-Tangut (and Tangut?) alveopalatal initials were really retroflexes and hence developed like *Cr-clusters. That might be the missing link between 3 and 2.
Last night, I realized the missing link between sources 1 and 2: medial *-r- became a uvular *-ʁ- that conditioned vowel lowering like uvular initials.
But not all words with *-r- became Grade II: e.g.,
2bie < *Cɯ-breH 'high'
(cf. Mu'erzong rGyalrong bre, Caodeng rGyalrong nbriʔ, Puxi Shangzhai bri 'id.' [Sun 2000: 227]; gDong-brgyad rGyalrong kɯ-mbro < *-aŋ 'id.' [Jacques 2006])
is Grade IV. So this morning I refined my solution further: medial *-r- in 'low' syllables became a uvular *-ʁ- that conditioned vowel lowering like uvular initials (*C- = any consonant; any nonuvular consonant in initial position; the relative chronology of stages may be different):
| Original syllable class | Syllable class subtype | Stage 1 | Stage 2: Presyllable-syllable vowel harmony | New class | Stage 3: Presyllable loss | Stage 4: *-r > *-ʁ- in low syllables | Stage 5: lowering after *Q, *ʁ | Stage 6: Medial loss | Stage 7: *Q- > K- | Final Grade |
| Low (*a, *e, *o) | Inherent low with or without matching presyllable | *(Cʌ-)Ca | Low | *Ca | Ca | I | ||||
| *(Cʌ-)Q(r)a | *Q(r)a | *Q(ʁ)a | *Q(ʁ)æ | *Qæ | Kæ | II | ||||
| *(Cʌ-)Cra | *Cra | *Cʁa | *Cʁæ | *Cæ | Cæ | |||||
| High (*ɯ) presyllable + inherent low | *Cɯ-Q(r)a | *Cɯ-Q(r)ia | High | *Q(r)ia | *Qia | Kia | III/IV | |||
| *Cɯ-Ca | *Cɯ-Cia | *Cia | *Cia | Cia | ||||||
| High (*ə, *i, *u) | Inherent high with or without matching presyllable | *(Cɯ-)Q(r)i | *Q(r)i | *Qi | Ki | |||||
| *(Cɯ-)Cri | *Cri | *Ci | Ci | |||||||
| Low (*ʌ) presyllable + inherent high | *Cʌ-Q(r)i | *Cʌ-Q(r)əi | Low | *Q(r)əi | *Q(ʁ)əi | *Q(ʁ)ʌi | *Qʌi | *Kʌi > *Kʌɪ > Kɪ | II | |
| *Cʌ-Cri | *Cʌ-Crəi | *Crəi | *Cʁəi | *Cʁʌi | *Cʌi | *Cʌi > *Cʌɪ > Cɪ | ||||
| *Cʌ-Ci | *Cʌ-Cəi | *Cəi | Cəi | I | ||||||
Grade III and IV are generally determined by initials. Grade III is associated with alveopalatals, v-, and, to some extent, l- (when it was phonetically velarized [ɫ]?) and all other initials are associated with Grade IV.
Here's how all the Grade II vowels developed (ignoring consonantal developments):
| Stage 1 | Stage 6 | Stage 7: Grade II | cf. Grade I | cf. Grade III/IV |
| *a | *æ | æ | -a | -ɨa/-ia |
| *e | *ɛ | ɛ | -e | -ɨe/-ie |
| *o | *ɔ | ɔ | -o | -ɨo/-io |
| *ə | *ʌ | ʌ | -ə | -ɨə/-iə |
| *i | *ʌi | *ʌɪ > ɪ | -əi | -ɨi/-i |
| *u | *ʌu | *ʌʊ > ʊ | -əu | -ɨu/-iu |
The diphthongization of *i and *u in Grade II is parallel to their diphthongization in Grade I:
*-i > -əi
*-u > -əu
But maybe Grade II ɪ and ʊ came directly from *i and *u.
I have also considered the possibility that the diphthongization of *i and *u in 'low' syllables involved nonneutral first vowels:
*-i > -ei (Grade I)
*ɛi > *ɛɪ (> ɪ) (Grade II)
*-u > -ou (Grade I)
*ɔu > *ɔʊ (> ʊ) (Grade II)
but there are few Tibetan -e and -o transcriptions for these rhyme categories. Maybe the transcriptions reflect later dissimilation:
*-i > *-ei > -əi (Grade I)
*ɛi > *ɛɪ > -ʌɪ (> ɪ) (Grade II)
*-u > *-ou > -əu (Grade I)
*ɔu > *ɔʊ > -ʌʊ (> ʊ) (Grade II)
Chinese Grade II has similar origins, though *Qa became Grade I, not Grade II. I hypothesize that Tangut sound changes were similar to those in its Chinese neighbor. Perhaps Tangut and northwestern Chinese went through similar changes almost simultaneously (cf. Vietnamese and southeastern Chinese).
10.6.1.23:27: THE GOLDEN GUIDE: LINES 15-16: TANGRAPHS 71-80
After the word list of line 14, it's nice to see a sentence with a subject and a verb:
| Tangraph # | 71 | 72 | 73 | 74 | 75 |
| Tangraph |  |
 |
 |
 |
|
| Li Fanwen number | 3696 | 5124 | 2104 | 1064 | 2474 |
| My reconstructed pronunciation | 1na | 2raʳ | 1ʃɨi | 2mie | 2raʳ |
| Tangraph gloss | (< 'night'?) | (< 'flow'?) | before; former times; the past | not yet | to flow; to leak; to pass |
| Word | tomorrow | ||||
| Translation | Tomorrow has not yet flowed into the past, | ||||
I have written about 71-72 at length in these two posts. They are indivisible halves of a disyllabic word, though they may have originated from two monosyllabic roots, 1na 'night' and 2raʳ 'pass' which is 75.
72 2raʳ and 75 2raʳ share a phonetic
alphacode: dai
73 is clarified by its antonym 78 in Homophones. The resemblance to Chn 先 *siẽ is coincidental.
The right side of 73 is 'before':
(a distortion of Chinese 前 'before'?)
and is said to be from the right side of the second half of
1piə-2nwio 'in former days'
According to Gong (2003: 616), 74 mie2 'not yet' "is used in a negative sentence in reference to [the] future": e.g.,
1thia 2dzwio 1riuʳ 1kha 2mie 1vəəi
'that person world in not-yet born' =
'That person has not been born in the world yet.'
(How did I manage to have a Tangut blog for over four years and not have a GIF for 1kha 'in' until tonight?)
74 resembles Middle Chinese 未 *mujh 'not yet'. Both descend from a common Sino-Tibetan *m-negative. 74 is part of a family of m-negatives in Tangut. The most important of them is
which is tangraph 248 in the Golden Guide.
1mi 'not'
The right side of 74 is
which can be an independent tangraph 1dʒiə 'skin' (derived from 皮 'skin' reversed?).
The functions of the two 'person' radicals surrounding the phonetic raʳ in 75 are unknown.
| Tangraph # | 76 | 77 | 78 | 79 | 80 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 3683 | 2096 | 2503 | 0795 | 3456 |
| My reconstructed pronunciation | 2sia | 2ɣwə | 1kəụ | 2riəʳ- | 1lia |
| Tangraph gloss | day after tomorrow | two days after tomorrow | behind; back; afterwards; subsequent; future; remaining | directional prefix / perfective marker | come |
| Word | |||||
| Translation | The day after tomorrow and the day after that came later. | ||||
76 has the radical that Andrew West discussed here (probably an abbreviation of
2niəə 'sun; day'
cognate to Chinese 日 'id.'; cf. 6 'sun') plus 'pass' (< 戉 < 越).
77 is from 'head' (phonetic?) plus 2jiew 'achievement' (why?).
+
78 is from 1ʃɨa 'buy and sell on credit' < Chn 賒 (no semantic or phonetic relevance?) + 1kwə 'back' (semantic)
+
You can guess most of the analysis for 'buy and sell on credit':
1ʃɨa = 78 + 1ʃɨa 'ten' (phonetic)
1ʃɨa 'ten' sounds like Mandarin 十 shi 'ten' and Tangut period northwestern Chinese *ʃi, but has an -a absent from Chinese.
79 is a verbal prefix. Scholars disagree about its meaning. There is no Tangut grammar written by native Tangut speakers, so modern Tangutologists must figure out Tangut grammar on their own. Here I follow Gong (2003: 608) in regarding it as a directional prefix functioning as a perfective marker. Below is Gong's paradigm of prefixes including optative prefixes derived from the perfectives via a suffix -e (or vowel alternation). 0- indicates an unknown tone.
| Direction | Perfective | Optative |
| upward | 0ʔa- | 1ʔie- |
| downward | 1nia- | 2nie- |
| here, inside | 1kiə- | 1kie- |
| there, outside | 2vɨə- | 2vɨe- |
| towards the speaker | 2diə- | 2die- (with the same tangraph!) |
| away from the speaker | 2dia- | |
| neutral | 2riəʳ- | 2rieʳ- |
I wonder if 2diə and 2dia share a root.
The use of directional marking for perfectives has parallels in English: cf. eat up = 'to eat completely'. More importantly, it has parallels in the Qiang languages that may be Tangut's closest living relatives.
Gong did not identify the direction associated with 79, but Jacques (2007, 2009 - abstract only; I'd love to see the actual paper!) identified it as 'neutral'
79 was analyzed as 1kiə- (the 'inside' perfective prefix) + 1pi (causative auxiliary)
+
Could the choice of 1kiə- 'inside' as the real or supposed source of the left radical imply that 79 was originally a directional prefix meaning 'into' or 'toward the center' (which is the meaning of the Ronghong prefix zV- [Huang and LaPolla 1996: 155)?
1kiə- looks like 'skin' times two (cf. 74 above) and in fact has 'skin' and - you guessed it - 79 in its analysis:
+
80 1lia 'to come' is reminiscent of Mandarin 來 lai but is not cognate since the latter is from Old Chinese *mʌ-rə without *l. Its true cognates may be
The Tangraphic Sea analysis of 80 is dubious:Mawo and Taoping Qiang ly
Ronghong Qiang lu
+
1lia 'come' = first and second halves of 1lɨə̣-1riaʳ 'come!' (an imperative?)
The tangraphs of 1lɨə̣-1riaʳ obviously consist of 80 1lia (with and without mirror-imaging) under the 'wood' radical (similar to Chinese 艹 'grass' which has one less vertical stroke). The analysis of 1lɨə̣ includes 80 1lia plus 1riaʳ:
+
1lɨə̣ has a tense vowel implying an earlier prefix added to 80 1lia plus vowel alternation.
Could r-initial 1riaʳ be the Tangut cognate of Old Chinese 來 *mʌ-rə?
Its analysis surprisingly does not include 80 1lia:
1riaʳ = 1lɨə̣ + 1riaʳ (phonetic), first half of 1riaʳ-2ŋo 'disease'That third tangraph was analyzed as
=
first half of 1riaʳ-2ŋo 'disease' = second half of 1lɨə̣-1riaʳ 'come!' + 2ŋo 'disease'
2ŋo 'disease' can be an independent word. Its tangraph looks like
+
'person' + 'give birth to'
but I bet its lost analysis contains a complex source for the left radical plus the first half of 1riaʳ-2ŋo 'disease'.
10.5.31.23:56: THE GOLDEN GUIDE: LINES 13-14: TANGRAPHS 61-70
Here's the second half of the day - or should I say the night?
| Tangraph # | 61 | 62 | 63 | 64 | 65 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 5444 | 2763 | 5301 | 3925 | 2945 |
| My reconstructed pronunciation | 2lɛ̣ | 1ɣʊ | 2ne | 1məuʳ | 2li |
| Tangraph gloss | - | - | evening; night | dark; dim | west |
| Word | evening; night | evening | |||
| Translation | Evenings [to the] west, | ||||
54, 61, and 63 all contain
which may mean 'night' and be derived from Chn 夜.
I don't understand the difference between 61-62 2lɛ̣-1ɣʊ and 63-64 2ne-1məuʳ, both disyllabic words for 'evening'. Could they refer to 'early evening' and 'late evening'?
I suspect that 61, like 62, contains the right of 64
+
1məuʳ 'dark; dim' = 1məuʳ 'vulgar' + 1ɣʊ (second half of 2lɛ̣-1ɣʊ 'evening')
whose analysis is, as usual, circular.
'Vulgar' contains 64 as phonetic and has 'person' on the left like its Chinese translation equivalent 俗 with 亻 'person'.
62 1ɣʊ consists of 1ɣʊ 'head' (phonetic) plus 64 1məuʳ 'dark; dim' (semantic):
63 contains what looks like
'not' (think of it as a tilted ≠ minus one stroke)
but presumably can't be 'not' here.
64 1məuʳ 'dark; dim' may be cognate to Old Chinese 黑 *hmək 'black', 墨 *mək 'ink'. Pre-Tangut *-k can become -w = -u in Tangut (Gong 1995).
65 has an extremely rare second radical (alphacode dor) that never appears without a vertical line to its left (bae). Maybe 'baedor' is one radical.
| Tangraph # | 66 | 67 | 68 | 69 | 70 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 2085 | 0931 | 0284 | 1158 | 0942 |
| My reconstructed pronunciation | 2jaaʳ | 2lɨuu | 1ʃwɨo | 2riẽ | 1lɨạ |
| Tangraph gloss | to live; to dwell; refuge; lodging; enclosure for cattle | bedding | night | 'watch'; one of five two-hour periods at night | north |
| Word | |||||
| Translation | Bedding, night watch, north. | ||||
I am pretty sure this line is nothing but a list of words.
I don't think 66 can be a verb since it has no preceding subjects or objects.
66-67 may be a compound 'lodging-bedding'.
66 looks like 'earth' + 'horse' + a third radical. The second and third radicals together form ...
2dzị
meaning ... ''daughter-in-law'!?.
67 has the structure (in alphacode)
 fam |
||
 cia |
 bil |
 cor |
cia is usually 'not', but probably not here.
There is no tangraph ciabilcor consisting of the bottom half, so 67 may have
(number of possible sources in parentheses)
4 source tangraphs: fam (145) + cia (272) + bil (262) + cor (21)
3 source tangraphs: fam (145) + ciabil (3) + cor (21)
or cia (272) + fambil (2) + cor (21)
2 source tangraphs: famcia (3) + piabilcor (no other tangraph has bilcor)
piabilcor is
1dʒwɨə 'one who ...; to help; mutual; neighboring'
which has no semantic or phonetic relationship to 2lɨuu 'bedding', so
Could 68 refer to a later time of night than 61-62 2lɛ̣-1ɣʊ and 63-64 2ne-1məuʳ?
69 has the same top radical as 46 'winter', 58 'shadow', and 70 'north' (associated with the 玄武 Dark Warrior):
Could it refer to 'darkness' in these tangraphs? Nishida (1966) has no gloss for it. It appears in a lot of tangraphs with negative semantics (e.g., 'abuse', 'deviant', 'abhor', 'dirty', 'sever', 'fault', 'steal', 'disease', etc.), but it can't be negative in tangraphs like
1siuu 'deer' <> 2gwiã-2tie 'goat' (< first half from 頑 *ŋgwæ̃? - but rhymes don't match!)
<>
(The top of 'deer' is analyzed as being from the top of 2gwiã, and vice versa.)
70 is analyzed as 'shadow' + 'black' (a Tangut noun-adjective phrase; is there any other kind of shadow?):
+
The Tangraphic Sea analysis of 'shadow' is unknown, but it wouldn't surprise me if it was circular and derived the top and bottom left from 'winter'.
The only other tangraph sharing those components with 'shadow' and 'winter' is the first half of
1lɨa-2lɨị 'calamity; disaster'which is presumably a reduplicative word. Both graphs contain
'death'
plus 'north' (according to Tangraphic Sea; homophonous and therefore phonetic) and 'flesh' (why?).
10.5.31.15:15: THE GOLDEN GUIDE: LINES 11-12: TANGRAPHS 51-60
Lines 11-14 cover times of the day and directions:
| Tangraph # | 51 | 52 | 53 | 54 | 55 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 0748 | 3133 | 5453 | 5439 | 5725 |
| My reconstructed pronunciation | 1piə | 1sie | 2bie | 1ɣa | 2vɨə̣ |
| Tangraph gloss | the present | morning | dawn | - | east |
| Word | dawn | ||||
| Translation | This morning, dawn [in the] east, | ||||
51 occurs before time words to form 'this morning', 'this year', and 'today'. Li Fanwen (2008: 128) doesn't list any instances of it standing by itself. Should it be regarded as a prefix?
51 has Nishida's (1966: 243) 'language' radical
(< Chinese 言 'words'?)
on the left, though it has nothing to do with language. Its analysis is part of a circular chain:
1piə 'the present' = 1piə(-2nwio) + 'day'
+
1piə(-2nwio) = 1piə 'the present' + 'day'
One might think that the disyllabic word
1piə-2nwio
means 'this ...' or 'the current ...', but it actually means 'in former days'.
Both characters contain radicals for 'language'plus the radical for 'before':
(the latter from 讠, abbreviation of Chinese 言 'words'?)
(a distortion of Chinese 前 'before'?)
The second syllable 2nwio < *Pɯ-ne-o-H? may be cognate to 2nie < *Cɯ-ne-H 'long ago' from line 1. Could the first syllable be the same 1piə as 1piə 'the present' or be the presyllable that conditioned the -w- and warped vowel in 2nwio: *pə-ne-o-H > 1piə-2nwio?
51 piə may be cognate to Ronghong Qiang pə- in
52 'morning' consists of the first half of 1na 'night' (cognate to 1nɨaa 'black'?) + the first half of 1wəi-2miẹ 'dawn':pə-s 'today' (< -s 'day')
pəsu-quɑ 'this morning' (< 'today' + ətsquɑ ~ otsu̥quɑ 'morning')
pə-maha 'this evening' (< maha 'evening')
Li Fanwen (2008: 866) only has dictionary attestations for
+
1wəi-2miẹ 'dawn'
which may be the ritual language equivalent of the regular word 53-54
2bie-1ɣa 'dawn'
in the Golden Guide.
53 2bie 'dawn' can stand by itself, but Li Fanwen (2008: 858) only cites 54 1ɣa as part of the disyllabic word 2bie-1ɣa. Could the ɣ- of 54 be due to lenition: *Cɯ-be-H-Ka > *2bie-1ga > 2bie-1ɣa?
53 has the
'lightning'radical on the right side of 1
1mə 'heaven; sky'
from line 1.
55 is one of seven tangraphs glossed as 'east', but I have yet to determine how many of these tangraphs are words for 'east' and how many only represent parts of words: e.g., 1nie is really only half of
1nie-1niooʳ 'end; east'
which looks like a reduplication and may be the ritual language equivalent of 55.
The Tangraphic Sea derives 60 'south' from 55 'east':
=
+
1ziəʳ 'south' = 1nie(-1niooʳ) 'end; east' + 2li 'west' + 2vɨə̣ 'east'
Is it likely that the tangraph for the basic word 'south' was devised after the tangraph for half of the nonbasic word for 'east'?
| Tangraph # | 56 | 57 | 58 | 59 | 60 |
| Tangraph |  |
 |
|
 |
|
| Li Fanwen number | 2079 | 0391 | 1067 | 1836 | 4796 |
| My reconstructed pronunciation | 1lɨə | 2lie | 2raʳ | 1tʃiẽ | 1ziəʳ |
| Tangraph gloss | - | noon | shadow; sacrifice; temple; daytime (!?); shape | correct; straight | south |
| Word | noon | ||||
| Translation | [At] noon, shadows due south. | ||||
56-57 1lɨə-2lie 'noon' looks like a reduplication of 2lie 'noon'. Could it be from *lə-leH, with the presyllable conditioning vowel warping?
*lə-leH > *lə-lieH > *lɨə-lieH > 1lɨə-2lie
Although the Mojikyo font has slightly different right radicals for 56 and 57, the three horizontal lines of
should be at the same height in both tangraphs.
58 has a structure I don't understand. It has the same top radical as 46
1tsuʳ 'winter'
in line 10.
58 may represent two unrelated roots:
'shadow' / 'shape'
'sacrifice' / 'temple' (< 'place of sacrifice'?)
I am not sure it really meant 'daytime'. Li Fanwen (2008: 178) gave the example
2raʳ-2piu-2khiuu 'daytime palace guard'
but I wonder if this is literally 'palace guard [against] shadows [during the day]'.
2piu contains
2ʃɨẽ 'sage'
the sort of person who should live in a palace? This tangraph was at the bottom right of its near-homophone 24
1ʃɨẽ 'to accomplish; to achieve; to become' < Chn 成
from line 5.
2khiuu 'see; look at' is written as 'person' plus 2lie 'see', which is the right side of 41
1tsə̣ 'fall; autumn'
59 is a loan from Chinese 正 *tʃiẽ. The expression 1tʃiẽ 1ziəʳ is a calque of Chinese 正南 'correct south' with adjective-noun order.
60: See 55 above.
None of the directions in the Golden Guide are cognate to the Ronghong Qiang names for directions:
| Gloss | Tangut | Ronghong Qiang | RQ literal meaning |
| east | 2vɨə | mujuq-hɑ-lə-s-tɑ or musi-hɑ-lə-s-tɑ | where the sun comes out |
| south | 1ziəʳ | khi-lɑ | downriver |
| west | 2li | mujuq-ə-xɬ-s-tɑ or musi-ə-xɬ-s-tɑ | where the sun goes down |
| north | 1lɨạ | ɲi-lɑ | upriver |
10.5.31.2:48: THE GOLDEN GUIDE: LINES 9-10: TANGRAPHS 41-50
Only two words should surprise anyone who knows the Chinese animal cycle:
| Tangraph # | 41 | 42 | 43 | 44 | 45 |
| Tangraph |  |
 |
 |
|
 |
| Li Fanwen number | 5828 | 2436 | 5303 | 2262 | 0573 |
| My reconstructed pronunciation | 1tsə̣ | 1miaa | 1vɨị | 1dʒwɨõ | 1na |
| Tangraph gloss | fall; autumn | fruit | monkey (month 7) | bird (month 8) | dog (month 9) |
| Word | |||||
| Translation | Fruits [of] fall; monkey, bird, dog, | ||||
41 'autumn' is from the left of 2rəiʳ 'rice; paddy' ('seedling' + filler radical?) + 2lie 'to see' (tangraph < Chinese 見 'to see' with filler radical added to bottom right?): i.e., the time when rice is seen?
42 'fruit' is a noun unlike all the other words in this position (32, 37, 47). Could it be a verb here: 'autumn bears fruit'?
+
The tangraph looks like one 'person' standing on the leg of another, but Tangraphic Sea gives a completely different analysis:
+
'fruit' = 'ripe' + 'to arrive' = 'that which arrives at ripeness'
One must not confuse 'fruit' with other 'double-person' tangraphs:
2riʳ 'before; formerly' (a drawing of a person preceding another person?)
similar in structure but not meaning to Chinese 从 'to follow; from' < 人 'person' x 2
=
+
1ʃɨõ 'villain' = 'person' + 'timid; weak' (a Tangut noun-adjective phrase)
The length of the second stroke distinguishes 'before' from 'villain'
43 'monkey' is derived from, of all things, 2zeʳw 'leopard; panther' in Tangraphic Sea:
+
'monkey' = 'leopard; panther' + 'macaque'
The right two-thirds of 'monkey' and 'macaque' is unique to those two tangraphs.
'Leopard; panther' is a rearrangement of the radicals of 'tiger' (which I presume was designed first):
'Leopard; panther' and 'tiger' both contain a radical
that may be from Chinese 乕 'tiger'. The function of the other radical
is unknown.
44 'bird' contains a phonetic 1dʒɨew 'waist' (< 要 < 腰 'waist'?) plus 'bird' (< 鳥 'bird') sandwiching a radical of unknown function:
+
+
The Tangraphic Sea derives it from a homophone 'mating' plus 'wing'
+
but I suspect 'bird' was created first and then used as a phonetic in 'mating'.
The left side of 'bird' is used as a semantic radical in other tangraphs. See the list titled "Characters Related to Birds and Flying" in this post by Andrew West.
45 'dog' is the tangraph that got me back into Tangutology after a long hiatus right before the year of the dog (2006). It consists of 1khwiə 'dog' plus a phonetic 1nɨaa 'black':
+
I assume that the tangraph for the basic word 1khwiə 'dog' (cognate to Old Chinese 犬 *khwinʔ) was created first and that the Tangraphic Sea analysis
is not entirely accurate. Oddly, the tangraph for the basic word for 'dog' contains the tangraph for the rare (and hence ritual language/) word for 'dog':
The analysis of 2nie is unknown, but Tangraphic Sea derived 1ɣa from it ... and the regular tangraph for 'dog'!
2nie-1ɣa
=
+
I don't know what's going on here, but I am pretty sure that
is the radical for 'dog' (as identified by Nishida 1966: 244) and is derived from Chinese 犬. Note that
2nie-1ɣa 'dog'
doesn't contain that radical. Nishida (1966: ) identified the left radical
of 2nie-1ɣa as 'dog'. Although that radical resembles Chinese 隹 'short-tailed bird', could it be from 句, the right side of 狗 'dog'?
| Tangraph # | 46 | 47 | 48 | 49 | 50 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 1490 | 4746 | 1375 | 3859 | 0125 |
| My reconstructed pronunciation | 1tsuʳ | 1ləu | 1giu | 1xwɨi | 2miuu |
| Tangraph gloss | winter | to hide; to conceal | pig (month 10) | rat (month 11) | ox (month 12) |
| Word | |||||
| Translation | Winter hides; pig, rat, ox. | ||||
46 has a dubious Tangraphic Sea analysis
+
'winter' = 'freeze' + 'cold; frigid'
I bet the analysis of 'freeze' is
'freeze' = (something with 'earth') + 'winter'
'Winter' looks like 'cold' plus a top radical of unknown function.
47 'to hide; to conceal' may contain two-thirds of
1ləu 'storehouse; warehouse'
as a phonetic with some semantic relevance (a warehouse is where things are hidden). Could 'hide' and 'warehouse' be the same word?
The right side of 47 can also be found in nine other tangraphs that I'd like to discuss later. It seems to mean 'hide'.
48 looks like 'dog' (the left third of 'pig') plus a phonetic giu:= +
+
giu is the second syllable of
2lheʳ-2giu 'three'
which is presumably the ritual language word for 'three'. It is one of the definitions for the normal word for 'three'
1sọ
in Mixed Categories of the Tangraphic Sea. I'm surprised that 48 was probably created after the second tangraph for the nondefault word for 'three'. Cf. how 45 was probably created after the second tangraph for the nondefault word for 'dog'.
49 consists of two low-frequency radicals that I'd like to blog about later.
Both Nishida and Arakawa reconstruct f- in Tangut and Arakawa reconstructed 49 as fii (whereas Nishida reconstructed wi). However, I follow Gong in not reconstructing f- in Tangut. I reconstruct 49 with xw- instead of f- or w- since it accounts for how 49 transcribed sinographs with both *xw- and *f-:
If 49 had f-, why would it transcribe *xw-?*xw-: 惠揮徽攜 (惠 is 'grace' - was 'rat' really the best transcription?)
*f-: 肺發飛妃費 (but 發 had *-a, not *-i!)
If 49 had w-, why would it transcribe *xw- and *f-?
49 is in the labiodental chapter of Homophones in spite of its xw-. Perhaps it had a v- in the dialect of the Homophones author. (Cf. English dialects that merge w- and wh- as w-.)
50 shares a top radical with 'elephant', derived from 50 and 'ox; cattle':
=
The top radical is associated with 'above' and 'female' in other tangraphs, but its function is unknown here.
The bottom of 50 consists of a combination of three radicals found nowhere else.
10.5.30.16:27: TANGRAPHIC RADICALS 2: THE RIGHT SIDE OF WHITE
Although I had originally planned to go through the radicals in reverse order of frequency according to a list compiled by David Boxenhorn, from now on I'll just discuss radicals as they come up. I've already been doing this for years, but now I'll number radical-themed entries.
One of the transcriptions I discussed yesterday was
LFW1426 2phọ 'lame' (due to a severed leg)
alphacode: hon
which is the 161st most common radical out of 840 and appears in 19 other tangraphs. It has the analysis
1phɔ̃ 1pha 1tiẹ 1vɨi
'white (left) side remove do'
= 'remove the left side of white'
in Precious Rhymes of the Tangraphic Sea. 'White' in turn is analyzed as
in Tangraphic Sea. And the source of its right side turns out to have ... 'white' as its supposed source:
=
+
1phɔ̃ 'white' = 1phɔ̃ 'two; pair' + 1ʃɪ 'shining white'
alphacodes: feihon = feihul + hontak
=
1ʃɪ 'shining white' = right of 1phɔ̃ 'white' + top and bottom right of 1ɣɛ 'true; real; pure'
alphacodes: hontak (= honbiodim) = feihon + biohoodim
But I doubt that 'shining white' was created before 'white'. I suspect the true sequence of creation was
>
2phọ > 1phɔ̃ > 1ʃɪ
'lame' > 'white' > 'shining white'
I assume the tangraph for the more specific word ('shining white') was derived from the tangraph for the more basic word, though I'm surprised that 'lame' was designed before 'white'.
Since there is no semantic connection between 'lame' and 'white', 'lame' must be phonetic in 'white' and these homophones of 'white':
second half of 1xæ1phɔ̃ 'a kind of grass'
second half of 2kɛw1phɔ̃ 'bow; crossbow'
Phonetic elements can indicate which rhymes sounded similar to Tangut ears: in this case, rhyme 73 of 'lame' and rhyme 57 of 'white' must have been close, though the exact nature of the similarity is uncertain:
| Nishida 1964 | Hashimoto 1965 | Sofronov 1968 | Huang Zhenhua 1983 | Li Fanwen 1986 | Gong 1997 | Arakawa 1999 | This site | |
| Rhyme 73 | -ɔ̣ | -əəwN | -ọ | -ɔn, -ɛn | -uọ | -ọ | -oq | -ọ |
| Rhyme 57 | -ǐõ | -uN | -ôn | -uɔ̃ | -ǐɒ | -iow | -yon | -ɔ̃ |
Where did 'lame' come from? Although it resembles the sinograph 牟 'moo', I suspect it is an elaboration of 丰 *fũ 'flourishing' or an abbreviation of 甫 *fu 'just'. Unlike Nishida or Arakawa, I don't think Tangut had an f-, so the Tangut may have used a Chinese *f-graph as the basis of a ph-graph. (Cf. the Korean borrowing of foreign f- as ph-.) One problem with this hypothesis is that the Tangut borrowed and transcribed Chinese *f- as x(w)-, not ph-. But perhaps 'lame' is an abbreviation of a Chinese *ph-graph containing 甫 like 葡 *phu or 蒲 *phu.
The radical 'lame' has other sound values as a phonetic:
'Lame' for other Po-type syllables'Lame' for PA-syllables
1po 'uncle'
'lame' may also be a semantic element 'male'; see below
2bɔ 'a surname'
1pia 'father' < 1piə 'father' (top from 父 'father'?)
<
with semantic element 'male'; see below
the left radical of 1pia is 'fear' < right of 怖
2bæ 'to mix' (regarded as loan from 拌 *phã < *banʔ by Li Fanwen 2008: 501 but the vowels don't match)
'Lame' for x-syllable
1xəũ 'red' < Chinese 紅 *x-
1xəũ is close to xũ, a Tangut-accented pronuncaition of 丰 *fũ.
'Lame' for 'retroflex' and alveopalatal-initial syllables
1nɨi? 1ɲɨi? 1dʒɨi? 'magic arts' ('retroflex' initial in Homophones)
2nɨi? 2ɲɨi? 2dʒɨi? 'male' ('retroflex' initial in Homophones)
a distortion of 雄 'male'? (I first learned of the sinographic link from Richard Cook.)
bottom right an abbreviated phonetic in 'magic arts'?
and an abbreviated semantic in 'uncle', 'father' above and
1khiə 'brother's nephew'?
1tʃɨə 'hoof
with 'leg' on the left
is not in the 'retroflex' chapter of Homophones, but tʃ- is close to dʒ-.
'Lame' is an abbreviation for 'white' in
=
2jõ 'gray' = 'white' + 'black'
=
+
2la 'clear; obvious; plain' = 'black' + 'white' (black clearly/obviously contrasts with white?)
=
1kwiẹ̃ 'paper' = 'white' + 'pure'
'White' is unabbreviated in
1ʔo 'old man' < Chinese 翁 *ʔoŋ?
with 'head; top' on top (i.e., man with white hair)
2pie 'uncle' (with the same top radical as 1piə 'father'; cf. 父 'father')
Usually there are many tangraphs in which the function of a radical cannot be determined, but I think I've managed to figure out what 'lame' is doing in every single case. If only I could say that about the 839 other radicals ...