<xua>
12.9.14.8:07: <XUA>-T SINOGRAPHIC SOURCES?
I wrote yesterday's entry in haste and didn't post my thoughts on the possible origins of the Khitan large script characters I mentioned:
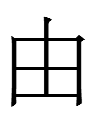
<xua>
looks like 由 Liao Chinese *yeu but may be an abbreviation of 畫 *xua or one of its variants like 画 containing 由-like shapes. (The simpler variants are not in 敦煌俗字典. Too bad I can't find 畫 in the Liao dictionary 龍龕手鑑.)
<ar>
puzzles me. It reminds me of the 夬 in northern Late Middle Chinese 決 *kywer which shares a nonhigh vowel followed by *-r, but the rest doesn't match. Is it a drawing of an object called ar in some language of Parhae?

<ts> ~ <dz>
looks like a merger between the homophones 支 and 之, both Liao Chinese *tʃi.
<im>
looks like an abbreviation of 音 Liao Chinese *im. Compare it to these cursive forms.
12.9.13.7:29: <XUA.AR.DZ.IM>?
Here's my attempt to write Khwārazm with four of the 188 large script characters in Kane (2009):
<xua.ar.dz.im>
I was surprised I was able to even remotely approach the sound of Khwārazm with such a limited selection. Aisin Gioro Ulhicun (2011) "has already reconstructed the phonetic values of [...] 80% of the large script": i.e., roughly 1,400 large script characters. I wish I could see her list of reconstructed readings for the Khitan large script. Ideally I'd like to write the large script equivalent of <xua.a.ra.j.m> in the small script.
12.9.10.23:59: <XUA.A.RA.J.M>?
Having just mentioned الخوارزمي al-Khwārizmī, yesterday I wondered how Khwārazm* and other Central Asian names might have been written in the Khitan scripts. I can't even guess what a Khitan large script version of Khwārazm would be like, but perhaps its small script spelling was something like
<xua.a.ra.j.m>
Khitan has no [z]**, so I chose <j> as the closest possible substitute. (<s> is another possibility: cf. Greek Χορασμία [not *Χοραζμία!])
Perhaps modified small (and large?) script characters were invented for transcribing [z] and other segments and/or syllables in Central Asian names in the Second Khitan Empire (i.e., the Qara Khitai).
The Khitan small script would have been a more flexible tool for dealing with foreign words than the large script or Chinese characters (sinography); one could assemble novel combinations of segmental characters in the small script (e.g., <j.m>) whereas such combinations would be more difficult to transcribe in the mostly syllabic large script*** and could only be approximated in purely syllabic sinography: e.g., Khwārazm appears in the Book of Wei (554 AD) as Early Middle Chinese 呼似密 *xo zɨʔ mɨit. (Is it a coincidence that the first character 呼 was read as *xwa in Late Old Chinese? Could the spelling predate the 6th century AD? This is the earliest Chinese reference to Khwārazm that I know of.)
*Khwārazm is the spelling used by Biran in her 2005 book on the Qara Khitai. Wikipedia prefers Khwarezm.**Khitan <z> in Kane (2009) is a voiceless affricate [ts] as in Pinyin, not a voiced fricative [z].
***The large script did have some segmental characters like 夫 <ś>.
9.11.1:36: Out of 188 large script characters in Kane's (2009) section 5.10 - roughly one-tenth of the 1,765 characters identified by Aisin Gioro Ulhicun as of 2008 - only ten characters exclusively represented single vowels or consonants: 7 [sh], 13 [ŋ], 18 [ts] ~ [dz], 75 [u], 82 [ś], 103 [o] ~ [u], 129 [o], 130 [o], 146 [ś], 166 [u].


