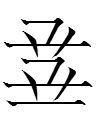
1po 'to report, to reply'
12.9.8.1:15: AL__RI_M
How did الخوارزمي al-Khwārizmī become algorithm?
-g- for -kh- between -l- and a vowel reminds me of how Korean -k- becomes -g- in the same environment:
talk- > talg-i 'chicken' + nominative
However, G- also corresponds to initial kh- in Latin Gazari for 'Khazars'.
Why did wā monophthongize into o?
And why has z (an original ز z as opposed to a
Persian z
for Arabic ذ ð, ض ḍ, or ظ ð̣) become th?
Are g, o, and th (which happen to spell Goth!)
traits of some intermediary language?
12.9.7.23:49: KH_ZAR
I was surprised to see that the Hebrew name for the Khazars was כוזרים Kuzarim. I found four different types of vowels for the first syllable at Wikipedia:
| Vowel | Front | Back |
| High | (Does any language have i in the first syllable of 'Khazar'?) | Hebrew Kuzarim |
| Mid | (Turkish gezer 'mobile' < √ger, thought to be cognate to the source of the name) | Latin Cosri |
| Low | Tatar Xäzärlär | English Khazars, Latin Gazari, Greek Χαζάροι/Χάζαροι, Russian Хазары, Turkish Hazarlar, Persian خزرها Khazarhā |
(One could also use the above table as a key to plural endings in the various languages.)
How can this vocalic diversity be explained? It reminds me of the use of four different vowel symbols (a, i, u, e but not o) in the Tibetan transcriptions of Tangut rhyme 31 which I reconstruct as -iə. (There is no Tibetan vowel symbol for ə.)
By analogy, I might think the Khazars' autonym was something like *Khɨzar or *Khəzar with an achromatic (i.e., neither palatal nor labial) nonlow vowel. However, if it had such a vowel, why aren't the Turkic names/cognates like *Hızarlar? Did the Khazar language undergo a vowel shift absent in its living modern relatives?
12.9.6.23:57: *...SƏʔ-GLASNYE (OR CON-*...SƏʔ-NANTS)
I was looking at the 子路 Zilu chapter of the Analects and that got me thinking about the Old Chinese initial of 子 which is not only part of Zilu's name but also 'Master' (i.e., Confucius). Although it is simplest to project its modern initial ts-* back into Old Chinese, Pulleyblank reconstructed *pʲ- in 1979** and *kʲ- in 1991. I looked up 子 at TLS and eastling.org and found
Pan Wuyun (TLS): *sklɯʔ
I wonder what Pan's reasoning for *-kl- is. Pulleyblank's similar *kʲ- is based on his interpretation of the graphs for the Heavenly Stems and Earthly Branches as an alphabet, and as far as I know no other scholar has adopted that interpretation.
Pan Wuyun (eastling.org): *sɯʔ
Is simple *s- a typo? Probably not. Looking at other entries for words I would reconstruct with *s-, I get the impression that he reconstructed a chain shift:
cluster with *s- and/or liquid > *s- > *ts-
Examples (added 胥, 撕, 嘶, 棲, 糔 9.7.00:29)
Sinograph Middle Chinese (this site) Pan's Old Chinese (eastling.org) Old Chinese (this site) 素 *soh *slaas *sas 桑 *saŋ *sŋaaŋ *saŋ 胥 *sɨə *sŋa *Cɯ-sa 相 *sɨaŋ *slaŋ *Cɯ-saŋ 撕, 嘶 *sej *slee *se 斯 *sie *sle *Cɯ-se 思 *sɨ *snɯ *sə 先 *sen *slɯɯn *Cʌ-sər 私 *si *l̥jil *si 死 *siʔ *ph-ljiʔ *siʔ 棲 *sei *sliil *Cʌ-si 速 *sok *sloog *sok 須 *suo *so (with simple *s-!) *Cɯ-so 糔 *suʔ *squʔ *suʔ 騷 *saw *squu *Cʌ-su 宋 *souŋ *sluuŋs *Cʌ-suŋs Zhengzhang Shangfang (eastling.org): *ʔslɯʔHis OC *so for 須 may be a typo.
What are the advantages of *ʔs- as opposed to *ts-? Is *ʔs- meant to account for phonetic series in which MC *s- alternates with * tsh-?
碎 MC *swəjh < Zhengzhang's OC *suuds = my OC *Cʌ-suts
卒 MC *tsot < Zhengzhang's OC *ʔsuud = my OC *Cʌ-sut
I would account for this alternation by having *Cʌ-
be lost after conditioning 'emphasis' in 碎:*Cʌ-suts > *Cʌ-suts > *suts > *swəjhfuse with *-s- after conditioning 'emphasis' in 卒:
*Cʌ-sut > *Cʌ-sut > *C-sut > *tsut > *tsot
The presence of *ʔs- implies the presence of other *ʔC-initials. Do they exist? Is there a language today that has *ʔs- without other *ʔC-?
Summing up, 子 has been reconstructed with at least six different initials in Old Chinese:
1. *ts-
2. *pʲ-
3. *kʲ-
4. *skl-
5. *s-
6. *ʔs-
This diversity proves Schuessler's (1989: ix) point: the Old Chinese reconstructions of different linguists
sometimes look as different from each other as if they were different languages.
In this case, Pulleyblank's (1991) OC *kʲəɣʔ doesn't even look related to Zhengzhang's OC *ʔslɯʔ. They only share a final glottal stop in common.
**子 has initial ts- in nearly all modern Chinese languages (though this is disguised in Mandarin by the Pinyin spelling ts-) and I do not know of any evidence for any other initial in Middle Chinese dialects. I can only think of three modern exceptions. Are there others?
1. Taishanese du [tu] has [t] like Sino-Vietnamese. Although an initial stop for 子 is unusual in the Sinosphere, this is not evidence for SV being derived from Taishanese. It is not clear that Vietnamese ever had *ts- (though it might have existed only in Chinese borrowings), and it is simpler to assume that the Vietnamese borrowed Chinese *ts- as *s-. Middle Chinese *ts- and *s- both correspond to modern Sino-Vietnamese t-, whereas they have different reflexes in Taishanese:
| Middle Chinese | Taishanese | Sino-Vietnamese |
| *ts- | t- | t- |
| *s- | ɬ- |
2. 漢語方音字匯 (1962) lists the Cantonese reading of 子 as tʃi, though more recent sources like Bauer (2010) and Matthews and Yip (1994) do not mention a palatalized allophone of /ts/ before /i/. Chalmers (1859: 131) has tsze' [tsz̩]. Was an affricate a short-lived early twentieth-century allophone? What does Chao Yuen Ren's Cantonese Primer say about /ts/?
3. Taiwanese has a palatal allophone of /ts/ before /i/: 子 tsi [tɕi] (colloquial) ~ tsu [tsu] (literary).
**9.7.2:05: Pulleyblank (1979: 36) wrote (substituting characters for code letters),
There is in fact some evidence that Middle Chinese dental sibilants go back to labials in some cases. Thus we have the following etymologically related pairs:
鼻 EMC [Early Middle Chinese] bijʰ "nose"
自 EMC dziʰ "self" (the character is derived from a pictogram of a nose and is signific in the [character for the] word for "nose")
膍 EMC bej "navel"
臍 EMC dzej "navel"
The supposition that *pʲ would have been replaced by a palatal stop c, becoming an affricate tś and later a dental affricate ts can easily be supported by examples from other languages. In many modern Tibetan dialects written Tibetan phy-, by-, my- have been replaced by ch-, j-, ny-, except where -y- has dropped out, especially in front of i or e. A very similar palatalization of labials took place in Old French, e.g.,
sachant < sapiente
cage < cavea.
*pʲ is probably not the only source of Middle Chinese *ts-. This is a question that may however be left aside for the present.
If the pairs of words Pulleyblank mentioned are cognates, I would reconstruct them as
鼻 EMC *bih < OC *bit-s
自 EMC *dzih < OC *s-bit-s
膍 EMC *bej ~ *bi < OC *sʌ-bi ~ *bi
臍 EMC *dzej < OC *sʌ-bəj (*ə-grade variant of root √b-j?)
Schuessler (2007, 2009) regarded these pairs as noncognate.
12.9.5.23:59: RAPID RE-*PO-RT
In "A True *-R-emnant?", I mentioned that
1po 'to report, to reply'
was a loanword from Chinese 報 'to report'. I didn't include a reconstruction of the Tangut period northwestern Chinese (TPNWC) reading of 報. I think it would be *po in Gong's reconstruction - a perfect match for Tangut 1po. (Not surprising since he used Tangut data to reconstruct TPNWC, and my Tangut reconstruction is a revision of his. In this particular instance, he and I both reconstruct 1po.)
TPNWC *po corresponds to dictionary Early Middle Chinese (EMC) *pawh [pɑ̤w]. Gong (2002: 375) reconstructed a split in the EMC *-aw rhyme:
> TPNWC *-o after labials
> TPNWC *-aw after all other initials
The Kan-on (Sino-Japanese based on northwestern Late Middle Chinese = NWLMC) data from 長承本蒙求 in Numoto (1995: 219-220) indicates that the split may go back to the seventh or eighth century:
This split is absent from dictionary Kan-on which has been regularized. 報 was not in 長承本蒙求, but its reading would probably have been *pou.Kan-on -ou after labials (only one instance each of -au and -o) < NWLMC *-ɔw?
Kan-on -au only after nonlabials < NWLMC *-ɑw
One might expect the Tibetan transcription of this NWLMC rhyme after labials to be -o(Hu). But Coblin (1994: 247) also lists -eHu:
寶 peHu (cf. Khotanese Brahmi pū, pau)
毛 HbeHu, HboHu
The reading of 報 would presumably have been transcribed as *peHu and/or *poHu.
What did Tibetan e signify? A schwa? Did EMC *-aw become NWLMC *-əw before monophthongizing into TPNWC *-o?
EMC *-əw was transcribed as -iHu, -ɨHu*, -eHu, and -oHu. I wonder if there was a chain shift in NWLMC:I was surprised to see that Jiyun (1037 AD) listed three fanqie for 報:*-aw > *-əw > *-ɨw (*-ɪ̈w? *-ɘw?)
博雅切 (sic; 搜真集韻 has 博耗切) = EMC *pawh 'to report' < OC *Cʌ-pus
博毛切 = EMC *paw 'to advance' < OC *Cʌ-pu (unattested in OC)
方遇切 (with *p-; 搜真集韻 has 芳遇切 with *ph-) = EMC *p(h)uəh 'rapid' < OC *p(h)os
as in 報葬 'rushed funeral' (in in 禮記; now read bàozàng in Mandarin, though in theory it should be *fùzàng); cognate to 'advance' above? - cf. how an English advance report comes out quickly
The third reading may be a rare case of an OC *-u graph used for an OC *-o syllable.
9.6.1:10: What I reconstructed as a possible OC *-u ~ *-o alternation in 'to advance' ~ 'rapid' would be a highly improbable *-əw (< *-əxɥ?) ~ *aɥ alternation in Pulleyblank's (1991) reconstruction.
In theory, MC *p(h)uəh could also be from *Cɯ-p(h)as or even *kɯ-pas, but I don't know of any other cases of an OC *-u graph used to write an OC *-a syllable.
*9.6.2:11: I follow Coblin in transcribing ྀ reverse gi-gu as ɨ, but it is not clear whether i and ɨ represented different vowels in NWLMC.
Sam van Schaik wrote,
This feature, in which the curl of the gi gu vowel is often to the right [ྀ] as well as the left [ི], is found throughout the inscriptions, and indeed appears in manuscripts through to the 11th century and in some cases later. Various attempts by recent scholars to deduce a pattern to the direction of the gi gu have produced no convincing results, with the exception of Laufer’s analysis of the Treaty Pillar, in which he showed that the two forms of the gi gu were used to transcribe two different Chinese vowel sounds. The common consensus is that there may originally have been a phonetic rationale behind the two forms, but it was soon lost, after which the direction of the gi gu was determined by scribal whim.
My impression is that there is a correlation between reverse gi-gu and NWLMC *ɨ, but there are exceptions in both directions: i transcribing NWLMC *ɨ and ɨ transcribing NWLMC *i: e.g.,
宜 as Hgi instead of Hgɨ
是 as shɨ as well as shi
Nishida's (1964) transliteration of Tibetan transcriptions of Tangut contains ï (= ɨ), but I have not seen such a vowel in Nevsky (1926), Sofronov (1968), or Tai (2008). Nishida's Tibetan ï does correspond to my reconstructed ɨ in the Grade III rhymes 10 and 30 which also have non-ï transcriptions:
| Rhyme | Tibetan transcription (Nishida) | Nishida's Tangut | This site's Tangut |
| 10 | -i, -ï | -i | -ɨi |
| 30 | -i, -iH, -ï, -u, -ye | -ɨ | -ɨə |
It is unfortunate that Nishida did not include the Tangut graphs that were transcribed so that I could see how their transcriptions appear in other sources.
12.9.4.23:59: A TRUE *-R-EMNANT?
I've been reading a lot about Tangutologist 史金波 Shi Jinbo lately. Andrew West led me to this long interview in English (more in Chinese here, including photos) and wrote a Wikipedia article about him. So I wondered how his name would be Tangutized. 金波 Jinbo 'golden wave' was easy, but I wasn't sure about 史 Shi 'history'. I chose to render it as a mixture of transcription and translation:
1ʃɨə 'to send, let someone do' (< Chn 使 'id.' with 史 as phonetic)
used in the transcription
1ʃɨə 1sə 1mie
of the surname of 史思明 Shi Siming (703-761 AD) in the Tangut translation of The Art of War; since Shi was born long after Sunzi's death, I presume he must have been mentioned in a commentary
1kɛ̣ < *sqe 'gold'*
not a transcription which would have been
1kĩ (transcription character)
1pa 'wave' (< Chn 波 'id.'; it is not surprising that the inland Tangut would lack a native word)
not a transcription which would have been
1po 'to report, to reply' (< Chn 報 'to report')
I considered Li Fanwen's (2008: 152, 1082) translation of 史 'history'**
1ʒɨəʳ 'solid, true, weight, majestic, elevated region' (< Chn 實 'solid, true')
'weight' and 'majestic' may be extended usages within Tangut
'elevated region' could be an unrelated native homophone
but the Tangut didn't use it as an equivalent of the surname 史, so I decided against it. However, I'm still glad I looked it up because I realized that the retroflexion in its vowel (signified by a superscript ʳ) might be a trace of a northwestern Late Middle Chinese *-r. 1ʒɨəʳ is close to zhir, a Tibetan transcription of 實 from 般若波羅蜜多心經 (Coblin 1994: 367, #0825). The initials ʒ- and zh- also match, though the vowel is a bit of a puzzle. I would have expected the Tangut form to be 1ʒɨiʳ with -i-. (Medial -ɨ- is obligatory between ʒ- and both ə and i.) Are there any other examples of northwestern Late Middle Chinese *-r corresponding to retroflexion in loanwords in Tangut?
*Tangut 1kɛ̣ 'gold' could go back to either *skre or *sqe, but I chose the latter since Qiang words for 'gold' contain q:
Longxi Qiang qú
Mawo Qiang ʂqu (with an initial cluster close to pre-Tangut *sq-)
Mianchi Qiang qa (but -kà in ŋó-ȵà-kà 'treasure' < 'silver-and-gold')
Taoping Qiang χqɑ³³ (preinitial χ- corresponds to Mawo ʂ-)
Qiangic words for 'gold' with back fricative initials may not be related: e.g., the ɣ- and nasalization of Lanping and Qinghua Pumi ɣã⁵⁵ may correspond to the nasal of Taoba Pumi ŋɛ⁵⁵. Qiangic fricative reflexes of an earlier velar nasal remind me of Middle Chinese *x- which is partly from Old Chinese *hŋ-: e.g. (examples added 9.5.1:30),
午 OC *ŋaʔ > MC *ŋoʔ > Md wu 'horse (seventh Earthly Branch)'
許 OC *hŋaʔ > MC *xɨəʔ > Md xu [ɕy] 'to allow'
滸 OC *hŋaʔ > MC *xoʔ > Md hu [xu] 'river bank'
**9.5.1:18: It occurred to me tonight that
1diụ 1diụ 1ʒɨəʳ 2mieʳ
which Li Fanwen (2008: 152) translated as (口+恧)(口+恧) 史官 'Nünü history officer' could be interpreted as 'Truth Minister Dudu'***. Orwell's Ministry of Truth comes to mind. Yikes!
Ah, I see on p. 179 that Li Fanwen also translated 1ʒɨəʳ 2mieʳ as 實官 'truth officer'.
***9.5.1:39: I don't know how to type the character that Li Fanwen used to transcribe 1diụ. Is it in Unicode? I can't see all the images in the Unihan index for the radical 口 plus ten strokes for 恧. I presume 口+恧 is read like 恧 nü, so 'Nünü' may be the Mandarin reading of (口+恧)(口+恧), a transcription of what I reconstruct as 1diụ 1diụ (= Gong's 1djụ 1djụ and Sofronov's 1ndi̯ụ 1ndi̯ụ). 'Dudu' is my lay Tangut romanization of 1diụ 1diụ.
12.9.2.23:59: T FOR *P IN VIETNAMESE
In "A Mismatch-t Stance", I mentioned the Sino-Vietnamese reading thất for 匹 which has a th- corresponding to ph- in Mandarin*, Cantonese, and Korean, and h- < p- in Japanese. Vietnamese has many readings with coronal t- th- d- corresponding to labial p- ph- b- m- in the other languages. Did the ancient Vietnamese mishear Chinese labials as coronals? I doubt that; instead, I think that the coronals are the result of a series of changes between Old Vietnamese (c. the 10th century AD when the last wave of Chinese readings were borrowed) and Middle Vietnamese (the first romanized data from the 17th century AD):
| Class | Old Vietnamese | Devoicing | Sibilantization | Cluster simplification | Thetacism | Middle Vietnamese (IPA): fortition | Modern Vietnamese (IPA): lenition | Modern Vietnamese spelling | Sino-Vietnamese example |
| Labial | *p | ɓ | b | 本 bổn | |||||
| *pʰ | f | ph | 方 phương | ||||||
| *b | *p | ɓ | b | 盆 bồn | |||||
| *m | m | 門 môn | |||||||
| *w | v | v | 王 vương | ||||||
| Intervocalic labial | *C(V)P > *C(V)β | *β | 本 vốn | ||||||
| Palatalized labial or sibilant | *pʲ | *pʲ | *ps | *s | t | t | 比 tỉ | ||
| *s | *s | 絲 ti | |||||||
| *(t)s | 子 tử | ||||||||
| *pʰʲ | *pʰʲ | *pɕ (*psʰ?) | *ɕ (*sʰ?) | *θ | tʰ | th | 譬 thí | ||
| *ɕ | *ɕ (*sʰ?) | 詩 thi | |||||||
| *(t)sʰ | 次 thứ | ||||||||
| *bʲ | *pʲ | *ps | *s | t | t | 鼻 tị | |||
| *z | *s | 徐 từ | |||||||
| *(d)z | 字 tự | ||||||||
| *mʲ | *mʲ | *mʑ (*mz?) | *ʑ (*z?) | *ð | dʲ (spelled d or dĕ) | z ~ j | d | 名 danh | |
| Palatal | *j | *j | *ʑ (*z?) | 遙 dao | |||||
| Intervocalic dental | *C(V)t > *C(V)ð | *ð | (刀) dao* | ||||||
| Dental | *t | ɗ | đ | 刀 đao | |||||
| *th | th | 討 thảo | |||||||
| *d | *t | ɗ | đ | 道 đạo | |||||
The above table was mostly written on 12.3.2; I added the last two rows tonight.
I think it's likely that devoicing was already complete by the 10th century.
*P and *T respectively represent any labial or dental stop in intervocalic position. The lenition of *-T- to *-ð- has a parallel in Paha (Ostapirat 2000: 210):
the Paha spirant /ð-/ has developed from an intervocalic *-d- (cf. PK [Proto-Kra] *-t- > Paha ð-).
9.3.1:39: Similarly, medial palatal and velar stops also lenited in intervocalic position, hardening in Middle Vietnamese and resoftening in Modern Vietnamese:
Old Vietnamese *CV-C- > *-ʑ- > Middle Vietnamese ɟ- > Modern Vietnamese [z] ~ [j] (spelled gi-)
Old Vietnamese *CV-K- > *-ɣ- > Middle Vietnamese g- > Modern Vietnamese [ɣ] (spelled g(h)-)
OTOH, Old Vietnamese medial sibilants did not harden:
Old Vietnamese *CV-S- > *-z- > *-ʐ- > Middle Vietnamese r- > Modern Vietnamese [r] ~ [ʐ] ~ [z] (spelled r-)
Paha has also spirants from nondental intervocalic obstruents (in my interpretation of the data in Ostapirat 2000: 178, 180, 182):
Proto-Kra *ʔV-p- > Paha v- (cf. Vietnamese *-β- > v-)
Proto-Kra *ʔ/ɦV-tʃ- > Paha j- (cf. central and southern Vietnamese *-ʑ- > j-)
Proto-Kra *CV-k- > Paha ɣ- ~ ʁ- (cf. Vietnamese ɣ-)
In a different branch of Kra, Proto-Kra *pj- became Proto-Gelao *c-. This is reminiscent of the *pj- to t- shift in Vietnamese.
*9.3.2:07: Vietnamese dao < *CV-taw 'knife' is not a Sino-Vietnamese reading, but it is indubitably from Old or Middle Chinese 刀 *taw 'knife' plus a presyllable that could have been in the Chinese source dialect or added by Old Vietnamese speakers.
Sino-Vietnamese đao < *taw is a borrowing from a literary dialect of southern Late Middle Chinese which lacked presyllables.