Home
12.5.5.23:59:
SANSKRIT Ṛ IN TANGUT?
Offhand, there are two Tangut things I'd like to see before I die:
- the missing rising tone volume of the Tangraphic Sea
(文海) dictionary
- a corpus, preferably with analysis, of all Tangut transcriptions
of Sanskrit
The first would provide definitions and graphic analyses of thousands
of tangraphs (Tangut characters). Parts of the rising tone volume can
be recovered from other texts, but not the whole thing.
The second would go far beyond what I have now:
- Nishida's (1964) references to rhymes in Tangut transcriptions of
Sanskrit: e.g., some unspecified rhyme 1 tangraph was used to
transcribe Skt pū. There are four different rhyme 1 tangraphs
with p-readings:




I have no idea which one was used. I reconstruct the reading of all
four as 1pəu; there is no 1pū in my reconstruction that
would be a perfect match for Skt pū.
- Nishida's (1964) references to initials and homophone groups in
Tangut transcriptions of
Sanskrit: e.g., the Tangut initials in chapter I of Homophones
were used to transcribe Skt p-, ph-, bh- m- in the Juyongguan
inscription. (But what about Skt b-? Was that absent from the
inscription? According to Whitney 1924: 26, Skt ph is 15 times
less common than Skt b, so I'd be surprising if b- is
missing.) And that at least one of the ten characters in dental
homophone group 18 (but which ones?) transcribed Sanskrit to.
- Grinstead's chart of Sanskrit transcription tangraphs and his
tangraphic transcription index mixing modern Mandarin (! - in lieu of
Tangut period northwestern Chinese) and Sanskrit together.
I don't remember ever seeing Sanskrit syllabic ṛ anywhere in
Nishida 1964 and I don't see it in Grinstead 1972; the closest Sanskrit
entries in the latter are mr and vr which were both
transcribed with

2057 2məəiʳ (= Gong Hwang-cherng's 2meer,
Arakawa's 2mywor, and Li Fanwen 1986's 2buạ)
Why would a consonant cluster be transcribed with a long vowel? Why
not have a short vowel to keep the break between consonants to a
minimum? Are the long vowels in the first two reconstructions and the -yw-
in the third dubious? And why transcribe v- with m- or m-
with Li Fanwen 1986's b-? I suspect 2057 was used to transcribe
some Tangut period northwestern Chinese syllable with *mb-
transcribing Skt vr- rather than Skt vr- itself. I wish
I could see the word(s) that Grinstead found 2057 in so I could assess
the probability of a Chinese intermediary.
If ṛ was ever transcribed in Tangut and if my reconstruction of
Tangut were correct (note the subjunctive - I think I'm wrong,
though less wrong than others), I would guess that ṛ by itself
would be transcribed as rəʳ or rɨəʳ and that it would
be transcribed after consonants as rhyme 90 -əʳ or rhyme 92 -ɨəʳ.
5.6.1:32: I went through Nishida 1964 and could not find a single
example of Sanskrit syllabic ṛ. The closest thing I could find
was Sanskrit m-r (why the hyphen?) on p. 50 which was
transcribed with an unspecified rhyme 31 tangraph of his labial
homophone group 17 which contains the rhymes
| Rhyme |
Possible tones |
Nishida 1964 |
Li Fanwen 1986 |
Gong Hwang-cherng 1997 |
Arakawa 1999 |
This site |
| 28 |
rising only |
-ʉɦ |
-ʉ |
-ə |
-I |
-ə |
| 31 |
level or rising |
-ɨ |
-i |
-jɨ |
-I: |
-iə |
| 90 |
level only |
-ʉr |
-ur |
-ər |
-Ir |
-əʳ |
I would have expected m-r to be transcribed with retroflex
rhyme 90 rather than nonretroflex rhyme 31.
Li Fanwen and Gong reconstructed the rhyme 28 and 90 syllables with b-
and the rhyme 31 words with m-. If they are correct, this group
should be split in two: 17a for b- + rhymes 28/90 and 17b for m-
+ rhyme 31. Nishida split the group into three:
17a. 2mbʉɦ
17b. 1mbʉr
17c. 1mɨ, 2mɨ
His order reflects the order of the subgroups in Homophones
which does not match the rhyme numbering based on the Tangraphic
Sea.
12.5.4.23:59:
VA-RI-ATION
My last post got me thinking about how Sanskrit ṛ is
pronounced in languages other than Hindi.
Descriptions of ऋ <ṛ> in Marathi vary:
Burgess
(1854: 5): "ribald (nearly,) or ru in French rue.":
i.e., "nearly" [rɪ] or [ry]
Navalkar
(1880: 3): "ri in rid": i.e., [rɪ]
Masica
(1991: 115): [rɨ] (if I read him correctly)
Pandharipande
(1997: xlvii) and Pandharipande (2003: 701): a "consonant" r̥:
i.e., syllabic [r̩]?
Wikipedia
(now): [ru]
[ry] is dubious since I don't know of any Indo-Aryan languages with
front rounded vowels.
Do the others reflect social, regional, and/or temporal variation?
Thai ฤ <ṛ> is pronounced differently in different words
(Gedney 1947: 89;
rewritten in my notation):
ฤดู rɨduu ~ raduu 'season' < Skt ṛtu-
I have not seen the ra- pronunciation in other sources.
Is it extinct?
ฤๅษี rɨɨsii (with long ɨɨ!) 'hermit' <
Skt ṛṣi-
also ฤษี rɨsii with a short vowel in Haas (1956:
68)
หฤทัย harɨthay 'heart' < Skt hṛdaya-
สันสกฤต saŋsakrit 'Sanskrit' < Skt saṃskṛta-
ฤ <ṛ> is also in the non-Sanskrit loanword อังกฤษ aŋkrit
'English', presumably spelled by analogy with saŋsakrit.
I assume Thai got its Indic vocabulary as well as its script through
Khmer rather than directly from some Indian language. As far as I know,
in modern Khmer, ឫ <ṛ> is only [rɨ]*, so
I would expect Thai ฤ <ṛ> to only be [rɨ]. Do the various Thai
pronunciations of ฤ <ṛ> reflect borrowing from different strata
of Indo-Khmer with different pronunciations of ឫ <ṛ> that are now
mostly obsolete? Do modern Khmer dialects have non-[rɨ] pronunciations
of ឫ <ṛ>? Is there any evidence for Indic vocabulary coming
through non-Khmer sources: e.g., Mon and Burmese? (How was ၒ <ṛ>
pronounced in Mon and Burmese?** The character is
now obsolete.)
What became of Skt r̥ in Indonesian? Looking at this Wikipedia entry,
I see three kinds of correspondences:
Regweda (presumably [rə-]) or Rigweda
< Skt Ṛgveda
Smrti < Skt Smṛti 'a category of
Hindu scriptures'
But which of these words are old and which are modern adaptations of
Sanskrit?
5.5.00:30: Indonesian re is reminscent of Javanese
[rə]
for <ṛ>.
5.5.1:01: I doubt Smrti is [smr̩ti] since I've
never seen any mention of a syllabic r in descriptions of
Indonesian.
5.5.1:54: The only correspondences I found in Doug
Cooper's list of Sanskrit loans in Indonesian based on De Casperis
(1997) and Mahdi (2000) are
In er : Skt ṛ:
amerta < Skt amṛta- 'nectar'
In ar : Skt ṛ:
kartika < Skt kṛttikā 'Pleiades'
In a : Skt ṛ (doubtful):
swasembada 'self-sufficient' < Skt sva-
'self' + saṃvṛddha 'thriving'
but sembada 'strongly built' by itself is derived from
sambaddha 'joined', so swasembada is probably from
swa- 'self' + sembada 'strongly built'.
*According to Pinnow (1980:
105), Maspero transcribed ឫ <ṛ> as rŭ with a symbol
for a rounded vowel, but I wonder if ŭ is a typo for ư̆
[ɨ].
**5.5.00:43: Back in 1994, I interpreted Burmese
<ui> [o] as formerly representing *[ɨ] or *[ə]. Could ၒ <ṛ>
have been equivalent to ရို <rui> = *[rɨ] or *[rə]?
Wheatley (1987: 845-846) regarded <ui> as "a Mon invention for
representing a mid front rounded vowel and it probably had the same
value in Old Burmese". However, I think such vowels are unusual in
Southeast Asian languages, so I would prefer to reconstruct an
unrounded vowel.
12.5.3.23:59:
A RI-L VOWEL IN HINDI?
The Sanskrit syllabic liquids ṛ, ṝ, ḷ, and the theoretical ḹ
were traditionally regarded as vowels* and written like vowels**. But as
far as I know, no modern Indo-Aryan languages have syllabic
liquids anymore; they seem to have already disappeared in Middle
Indo-Aryan. Nonetheless modern Indic scripts may still contain 'vowel'
symbols for those
extinct liquids.
Yesterday I
mentioned how Khmer ឮ <ḹ> represented the native word lɨɨ
'to hear'; it never stood for a syllabic liquid in Khmer.
Devanagari
has a symbol ऋ <ṛ> for Sanskrit syllabic ṛ which is
pronounced as [rɪ] in Sanskrit loanwords in Hindi. This [rɪ] is the
basis for ri for ṛ in lay romanizations of Sanskrit:
e.g., Rigveda
for Ṛgveda and Amritas for Amṛtas.
[rɪ] is a consonant-vowel syllable, not a syllabic liquid.
So I was somewhat surprised to see ऋ <ṛ> [rɪ] listed as a
vowel in both Kachru (1993) and Shapiro's (2003) descriptions of Hindi.
If I did not know that this syllable arose from a Sanskrit syllabic
liquid, I would not understand why it is distinct from रि <ri>,
the regular Devanagari spelling of [rɪ].
Shapiro transcribed the
consonant of ऋ <ṛ> with an apical tap [ɾ] distinct from his [r]
for र <r>. Can ऋ <ṛ> [ɾɪ] and रि <ri> [rɪ]
be distinguished in Hindi speech? Does Hindi have a phoneme /ɾ/ that
only appears before one vowel in loanwords?
Kellogg's
Hindi grammar (1876: 1) also listed ऋ <ṛ> [rɪ] as a
vowel, but I expect the partial conflation of script and phonology in
earlier
works. Kellogg
(1876: 9) denied that ऋ <ṛ> [rɪ] and रि <ri> [rɪ] were
phonetically distinct.
How should Hindi ऋ <ṛ> [rɪ] be described? As a vowel in
accordance with the script and tradition, or as a special spelling of
[rɪ] in some (but not all) Sanskrit loans with [rɪ]?
*The Sanskrit syllabic liquids ṛ, ṝ, ḷ have
the same distribution as vowels.
ṛ and ḷ undergo strengthening processes similar to
those of vowels: e.g.,
| Basic grade |
Guṇa grade |
Vṛddhi grade |
| ṛ |
ar |
ār |
| ḷ |
al |
(theoretically *āl; unattested) |
| i |
e < *ai |
ai < *āi |
| u |
o < *au |
au < *āu |
i and u in the basic grade can be thought of as
syllabic variants of y and w.
5.4.00:11: Different inflected and derived forms require different
grades in Sanskrit: e.g.,
Basic grade: kṛ-ta- 'did'
Guṇa grade: kar-o-ti 'does'
Vṛddhi grade: kār-a- 'doer'
3:21: Loanwords with all three grades are in Hindi, but I do not
know how
well Hindi speakers understand this system without learning Sanskrit.
**In Indic scripts, vowels typically have special
forms for
word-initial position and are otherwise subordinated to consonant
symbols in other positions: e.g., in Bengali,
ঋ <ṛ> (initial position)
কৃ <kṛ> (subordinate position beneath ক <k>)
An exception is Thai which has no special forms for word-initial
vowels or postconsonantal vowels:
ฤ <ṛ> (initial position)
กฤ <kṛ> (immediately following ก <k> but not
subordinated to it)
Next: Short e and o in Hindi (delayed
but improved)
12.5.2.23:30:
VOWELS IN YATES AND WENGER'S BENGÁLÍ* GRAMMAR
(1885)
Sorry, no Hindi yet. I'd like to wrap up Bengali first.
19th century public domain grammars at Google Books allow me to
easily see how languages (might) have changed over the last century.
"Might" in parentheses because I have no idea how literary or obsolete
the old descriptions are. For instance, Yates and
Wenger (hereafter YW) distinguish between short and long vowels:
they wrote the latter with acute accents. (Kellogg
1876 has the same notation for Hindi long vowels. Were acute
accents common in colonial period works on Indian languages?) Does this
mean
that at least one prestige variety of spoken Bengali still had such a
distinction, or is it just an artifact of transliteration from a script
that retains that distinction? YW's descriptions on p. 3 and 15
indicate that
short a (in their transcription) was [ʌ] "especially
before certain compound consonants" and [ɔ] elsewhere; "for the sake of
uniformity with the custom in other Indian languages it is written a"
á "is the above letter lengthened" which sounds like [ɔː],
but "has the sound of a in father" rules that out, so I
assume it was [aː].
<yā> was "like <e>"or like the first a in the
English affable": i.e., [æ].
the <a> of <bya> was "almost like <e>", implying
that it was distinct from the <yā> of <byā> which was "like
<e>" without any qualification. Perhaps my reconstruction of long
*æ̅ for <yā> and short *æ for <bya> was
correct.
short i varied between [ɪ] and [iː] (so was it on its way
to merging with long í?)
long í was [iː]
short u was [ʊ] without a long variant (so did short i
and long í merge before short u and ú?)
long ú was [uː]
e was short [ɛ], halfway between the [æ] and [e] of modern
Bengali. YW compared it to the short vowel of
English there [ðɛə] rather than the long diphthong of
English Dane [dejn]. I presume <eka> 'one' was
[ɛk] rather
than modern [æk].
o, despite the absence of an acute accent, was a long
[oː]. (I am assuming the comparison with English note [nowt]
was not exact.)
ai was [oj] but au was [aw], not [ow].
So much for
my
assumption of symmetry between the two diphthongs.
short lri**, despite the spelling with lr-,
"is
like li in little" and is transcribed later in the same
line as li, so I think it was [lɪ]. As was the case with a
[ɔ], the
transcription
is not a reliable guide to pronunciation.
long lrí "is the preceding lengthened, lí": i.e.,
[liː].
Yates and Wenger's Bengálí vowels (in my notation)
| Height |
Short |
Long |
Short |
Long |
Short |
Long |
| High |
i |
ī |
|
u |
ū |
| Upper mid |
e |
(none) |
(none) |
ō |
| Lower mid |
æ |
æ̅ |
*ɔ |
(none) |
| Low |
|
(none) |
*ā |
|
Length is nonphonemic for e and o, contrary to my
reconstruction.
YW transcribed final <ya> on p. 8 as -y, not -e.
I reconstruct three stages:
| Early |
19th century |
Modern |
| <-ai> |
-oj |
-oj |
| <-aya> |
-ɔj |
-ɔe |
Next: A Ri-l Vowel in Hindi?
*The acute accents for long vowels in "Bengálí"
reflect the
long vowels of its Hindi source बंगाली <baṃgālī>. Bengali for
'Bengali' is বাংলা <bāṃlā> Bangla.
**lri is for Sanskrit short syllabic ḷ
which only
appears in forms of the root kḷp 'be well ordered'.
lrí is for Sanskrit long syllabic ḹ which never
appears in any real Sanskrit words. It was created "only for the sake
of an artificial symmetry" with short syllabic ḷ (Whitney
1896: 11).
As far as I know, the letter for ḹ is only in common use in
Khmer. ឮ <ḹ> represents the native word lɨɨ 'to hear'.
This is not evidence for a long syllabic l in earlier Khmer; it
indicates that Khmer lɨɨ was the closest possible approximation
of Sanskrit ḹ.
12.5.1.23:59:
RECONSTRUCTING VOWEL LENGTH IN BENGALI
On Monday, David Boxenhorn
asked me about vowel frequencies in the
modern descendants of Sanskrit. I've been trying to find figures in
vain ever since. The closest I've gotten so far was this statement
I found today about Bengali which has no numbers:
In terms of the frequency of occurrence also /æ/ and
/ɔ/ have a lower rate among others, while /o/ and /a/ are
the most frequent ones.
Oh wait, I did find Greenberg
(2005: 18) yesterday:
Ferguson and Chowdhury report a short count on Bengali vowels
in which the ratio of non-nasalized to nasalized vowels was 50:1. I
counted the first thousand vowels in Stendhal's Le rouge et le noir and
found 82.5% oral vowels to 17.5% nasal.
I wish I could see Ferguson and Chowdhury (1960) for more statistics.
I'm surprised /ɔ/, the default vowel of the Bengali script, isn't
the most common vowel, as it corresponds to /a/, the most common
Sanskrit vowel. I wonder if /o/ includes [o] written as both <a>
and <ō>. Assuming that Bengali orthography is etymological, I
suspect that Bengali once had vowel length distinctions in upper mid as
well as high vowels before losing vowel length:
Earlier Bengali vowels: short vs. long with gaps in the system
| Height |
Short |
Long |
Short |
Long |
Short |
Long |
| High |
*i |
*ī |
|
*u |
*ū |
| Upper mid |
*e |
*ē |
*o |
*ō |
| Lower mid |
*æ |
*æ̅ |
*ɔ |
(none) |
| Low |
|
(none) |
*ā |
|
Modern
Bengali vowels: no length
| Height |
Front |
Central |
Back |
| High |
i |
|
u |
| Upper mid |
e |
o |
| Lower mid |
æ |
ɔ |
| Low |
|
a |
|
Correspondences between Bengali spelling and earlier and modern
Bengali vowels?
| Bengali spelling |
Earlier Bengali? |
Modern Bengali |
| <a> |
short *ɔ and short *o |
[ɔ] and [o] |
| <o> |
long *ō |
[o] |
| <ai> |
*oy with short *o |
[oy] |
| <au> |
*ow with short *o |
[ow] |
| <ya> in word-final position |
short *e |
[e] |
| <e> |
long *ē > short *e |
[æ] and [e] |
| <ya> after <b> |
short *æ |
| <yā> |
long *æ̅ |
[æ] |
| <i> |
short *i |
[i] |
| <ī> |
long *ī |
| <u> |
short *u |
[u] |
| <ū> |
long *ū |
This post and the previous one draw heavily upon Dasgupta
(2003) and also rely on Bagchi (1996) and Klaiman (1993) to a lesser
extent. I don't actually know any Bengali, so I've probably made a lot
of mistakes.
I don't see any reason to posit a long *ɔ or a new short *a
(the original became short *ɔ).
I assume short *o developed as a variant of *ɔ. (I
won't go into the environments where *ɔ raised to *o.)
Short and long *o merged in speech as *o but remain
distinct in writing.
Short *e had a very restricted distribution, so the
functional load of the short-long *e distinction was low. Some
long *ē lowered to long *æ̅ in certain environments
(see below), but others merged with short *e.
The different treatment of <bya> and <byā> in modern
Bengali leads me to believe that monophthongization might have preceded
the loss of length. If *bya and *byā merged into *bya
and then monophthongized to *bæ, then it would be
impossible to explain why *bæ from *bya could raise to
upper mid *be before high vowels unlike *bæ from
*byā. I prefer to keep the two syllable types distinct even
after monophthongization as *bæ and *bæ̅. The former
could raise to upper mid be to harmonize with following
high vowels, whereas the latter remained mid-low even after length was
lost.
Short *æ might have been higher than long *bæ̅, just
as short *ɔ and its Sanskrit source a were higher than
long *ā. A higher *æ would be more prone to merger with
*e (already shortened?) than lower *æ̅. The height of
the vowel resulting from the merger of short *æ and *e
is determined by the height of the following vowel: [æ] before nonhigh
vowels and [e] before high vowels.
What is so special about *by as opposed to other *Cy-clusters?
<bya> [bæ]
but <Cya> [Cɔ] if C ≠ <b>
Perhaps the fact that *by- < *vy- and *v-
and *y- are the consonant counterparts of the high vowels that
condition vocalic phenomena is relevant. *by- is the only
cluster that originated from a glide sequence.
Next: Short e and o in Hindi
12.4.30.23:59:
THE A-E-O CYCLE
Sanskrit a is almost as common as all the other vowels
combined in that language. Last night, I was thinking that
post-Sanskrit vowel systems might be headed toward equilibrium: fewer a
and more non-a vowels. However, tonight I realize that the
origins of Sanskrit a indicate that equilibrium is not a
universal destination. The merger of Proto-Indo-European *e, *o,
*n̥, *m̥ ̥ into Skt a (and long PIE *ē and *ō
into Skt ā) went in the opposite direction, flooding the system
with a-vowels (in bold). (But note that short *a-diphthongs
did lose their a-quality.)
| Late Proto-Indo-European |
Sanskrit |
Pali* |
| *a, *e, *o, *n̥, *m̥ |
a |
a |
| *ā, *ē, *ō |
ā |
ā |
| *āi, *ēi, *ōi |
ai |
e, i |
| *āu, *ēu, *ōu |
au |
o, u |
| *ai, *ei, *oi |
ē (no short e
in Sanskrit**) |
e |
| *au, *eu, *ou |
ō (no short o
in Sanskrit**) |
o |
| *i |
i |
i |
| *ī |
ī |
ī |
| *u |
u |
u |
| *ū |
ū |
ū |
| *r̥, *l̥ |
ṛ |
a, i, u |
But judging from spelling, Bengali might have gone full circle by
developing new e and o-like vowels from Sanskrit a-vowels:
| Bengali spelling |
Bengali phonetics |
| <ya> in word-final position |
[e] |
| <bya> |
[bæ]; [be] before a high vowel |
| <yā> |
[æ] |
| <a>, <ya> before any consonant other
than <b> |
[ɔ] and [o] |
| <ai> |
[oj] |
| <au> |
[ow] |
5.1.2:17: These new e and o-like vowels do not
necessarily correspond to Proto-Indo-European *e and *o:
e.g.,
'nine': Bengali <naya> nɔe < Skt nava
< PIE *newn
'hundred': Bengali <śata> ʃɔt < Skt śatam
< PIE *km̥tom
'mind': Bengali <mana> mɔn < Skt man-as
< PIE *men-
*5.1.1:12: Pali /e/ and /o/ are mostly long
[eː] and [oː] but have short allophones before geminate consonants.
**5.1.2:19: Sanskrit ē and ō
are often written as e and o since they are always
long.
12.4.29.23:59:
PHONOSTATISTICS AND GRAPHOSTATISTICS
I never thought that frequencies of consonants and vowels could be
counted until I encountered a
chart of such frequencies in Whitney's Sanskrit Grammar
almost twenty years ago.
Looking at conventional charts of Sanskrit vowels
Short vowels
Long vowels and diphthongs (e and o are
always long, so they are not written with a macron)
one might think that the vowels are all roughly equally common, but
that is not the case: the most common vowel (a) is
one out of every five segments in Sanskrit
1.07 times more common than the next four most common
vowels
combined (ā, i, e, u)
2.4 times more common than its long counterpart ā
(which is 1.07 times more common than the next two most common vowels i
and e combined)
27 times more common than the least common vowel ū
or the most common syllabic
consonant (consonant appearing in the same positions as vowels) ṛ
110 times more common than the least common diphthong au
(āu in Whitney's notation)
1978 times more common than the least common syllabic
consonants ṝ
and ḷ
(4.30.3:09: Here's a graph showing that nearly half the vowels in
Sanskrit are a:
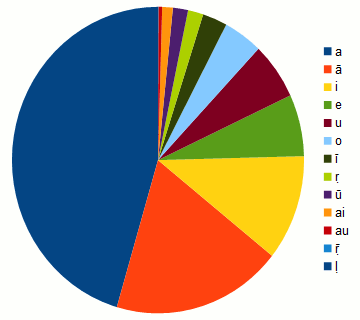
For a graph in a different format, see "Visualizing
Sanskrit Vowel Frequency".)
The development of a system so heavily skewed toward a would
be different from that of a system with no a at all like
Beekes' Proto-Indo-European reconstruction. By observing trends in
languages with different phonostatistical patterns, one might
be able to make predictions about later changes or explain known (and
sometimes baffling) changes.
I am not surprised that Beekes' PIE
developed an a and its descendants all have a, because
I can't remember ever hearing of a language without a (not
counting claims of phonemically - but not phonetically! - 'vowelless'
languages).
Conversely, it
just occurred to me that the monophthongization of the diphthongs ai
and au to e and o in P*ali reduced the
frequency
of a (the first half of those diphthongs) - a step toward
equilibrium? But then again, ṛ sometimes became a in
Pali, increasing the frequency of a.
Years later, I wrote a PhD dissertation based on what I'd now call graphostatistics
(only 20 hits in Google so far - this will be number 21!). I looked at
spelling frequencies in Old Japanese texts to determine the most likely
pronunciations of OJ consonants and vowels.
Whitney compiled his figures by hand in the 19th century, whereas I
used a computer at the end of the 20th century. As more texts are
digitized at Google Books and elsewhere, the opportunities for
phonostatistical and graphostatistical studies are on the rise. But how
many are taking advantage?
Tangut fonts by Mojikyo.org
Tangut radical and Khitan fonts by Andrew
West
Jurchen font by Jason Glavy
All other content copyright © 2002-2012 Amritavision