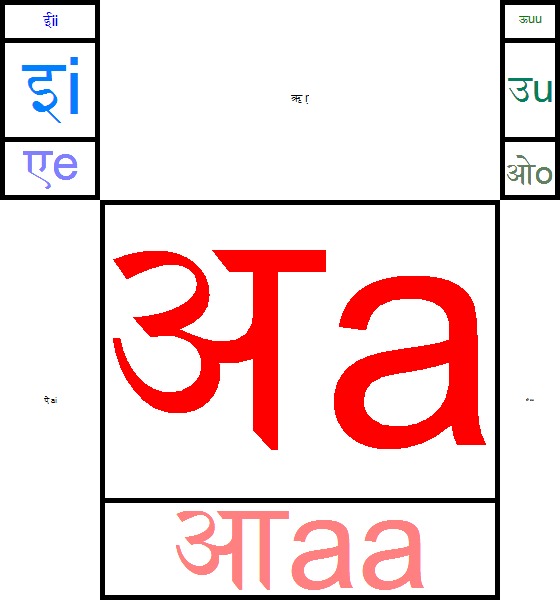
10.10.23.23:57: VISUALIZING SANSKRIT VOWEL FREQUENCY
Today I was discussing vowel frequencies with David Boxenhorn. I showed him the statistics for Sanskrit vowel frequency from Whitney's Sanskrit Grammar, and he pointed out that Sanskrit front vowels were roughly twice as common as back vowels. His observation inspired me to create this table of Sanskrit vowel frequencies. The bigger the vowel, the more frequent it is.
e and o are always long, but are conventionally romanized as short. Original short *e and *o became a.
One out of five Sanskrit phonemes is a. This a is the default vowel of consonant characters in Devanagari and many other Indic scripts: e.g., Skt nagaram 'city' is written as a sequence of four consonant characters
नगरम्
na-ga-ra-ma\
with a subscript \ viraama to indicate the lack of an a in the final character म ma. The character अ only represents a in word-initial position: e.g., अमृतस् amṛtas 'immortal'.
On a Windows Devanagari keyboard, \ viraama is <d>, but अ a is <shift><d>, implying that viraama is more frequent than word-initial a.
Three Sanskrit vowels are so rare that they are (almost) illegible:
ऋ ṛ (syllabic r; a is 27 times more frequent)
ऐ ai (a is 39 times more frequent)
औ au (a is 110 times more frequent)
The image does not contain a complete list of Sanskrit vowels. Two are so rare that they would be invisible.
ॠ ṛṛ (long syllabic r; a is almost 2000 times more frequent)
only in accusative and genitive plurals of ṛ-stems
ऌ ḷ (syllabic l; a almost 2000 times more frequent)
I predict that syllabic consonants are also infrequent in most other languages that have them: e.g., Czech. But I presume they are very common in Liangshan Yi.
10.10.23.15:15: THE GOLDEN GUIDE: LINE 86: TANGRAPHS 426-430
86. I think I started this post on the 9th but never got around to finishing it until today.
| Tangraph number | 426 | 427 | 428 | 429 | 430 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 2872 | 0546 | 0817 | 3628 | 1733 |
| My reconstructed pronunciation | 1vəĩ | 2ʔəu | 1xie | 1ɣwiã | 2tʃɨi |
| Tangraph gloss | the surname 温 Wen (*ʔwə̃) | (transcription of Chinese) | (transcription of Chinese) | (transcription of Chinese) | (transcription of Chinese) |
| Word | the surname 武 Wu (*wɨu) | the surname 邢 Xing (*xie) | the surname 袁 Yuan (*wɨã) | the surname 枝 Zhi (*tʃɨi) | |
| Translation | Vin, U, He, Ghwan, Chi | ||||
10.23.15:30: I don't understand why 2872 and 0546 seem to have each other's initials from a Chinese viewpoint. I would have predicted their readings to be 1ʔwəĩ and 1vɨu. (Tangut v- was the closest equivalent of Chinese w-; Tangut -w- had to follow a consonant.)
426: 2872 has a circular analysis deriving it from two homophones:
+
2872 1vəĩ 'the surname 温 Wen (*ʔwə̃)' (dexboxcirduu) =
3804 1vəĩ 'the surname 文 Wen (*wə̃)' (dexpau) =
2873 1vəĩ 'a place name Vin' (giiboxcirduu)
=
+
2873 1vəĩ 'a place name Vin' (giiboxcirduu) =
2262 1dʒwɨõ 'bird' (giigirwur; semantic?; was Vin known for birds?) +
2872 1vəĩ 'the surname 温 Wen (*ʔwə̃)' (dexboxcirduu)
is homophonous with the first half of
1684-5144 2ʔəu-1ʃɔ̃ɔ̃ 'god' (Ritual Tangut?)
Thus I conclude that jau, the left side of 0546 and 1684, is a phonetic for 2ʔəu.But not all jau tangraphs are pronounced 2ʔəu. I'll look at all seven jau tangraphs in my next post.
428: The analysis of 0817 makes no semantic or phonetic sense:
+
0817 1xie (transcription of Chinese) (fiayikcin) =
1383/1384 1ʃɨe 'to give up, abandon' (fiayik)
(This tangraph has a double listing in Li Fanwen 2008: 231-232. Although 1384 is supposed to be an 訛體 erroneous form of 1384, it looks identical to 1383. According to Sofronov 1968 II: 279, this tangraph has two readings: one with an alveopalatal initial and another with a liquid initial. Sofronov did not reconstruct either reading. Neither initial would match velar x- which was considered to be glottal by the Tangut - and which might have been glottal [h].)
2716 1rieʳ 'skillful, ingenious' (gaedumcin)
Both the supposed source tangraphs have -e-type rhymes, but that is insufficient to identify them as phonetics.
429: 3628 has a cryptophonetic 5258, whose Chinese translation 圓 *wɨã sounds like 1ɣwiã.
+
3628 1ɣwiã 'the surname 袁/元 Yuan' (dexpeo) =
2888 2mə 'surname' (dexpux) +
5258 1ʔɔ̣ 'round, ring, courtyard, all' (peocox)
Perhaps 3628 and others sharing the same fanqie initial speller should be reconstructed with w- instead of ɣw- to more closely match 圓 *wɨã. However, the initial fanqie speller (2681) for the initial fanqie speller (2235) of 3628 was transcribed in Tibetan as brgu(H) (Tai 2008: 225) with -g-, confirming an initial ɣ-. (There was no Tibetan letter for ɣ- in the Tangut period, though the Tibetan letter I transliterate as H- was once [ɣ] [Hill 2005].)
430: I thought 1733 (analysis unknown) might be a fanqie character, but there is no tangraph with hal on the right and the rhyme -ɨi. The only hal tangraph with a similar rhyme is 5750:
+
?
1733 2tʃɨi (transcription of Chinese) (fikhal) =
1354 1tʃɨụ 'to guard, defend' (fikbaeher) +
vaguely like Chn 守 *ʃɨu but the initial doesn't match
5750 2tʃɨii 'finger' < Chn 指 *tʃɨi (pikhal)
The Chinese dialect known to the Tangut probably did not have
distinctive vowel length. Did the Tangut
hear a nondistinctive long vowel in 指 *tʃɨi
?[tʃɨii]?
1354 is the only fik-initial tangraph with initial tʃ-. Its analysis is circular, since 4976 (analysis unknown) is probably based on 1354:
+
1354 1tʃɨụ 'to guard, defend' (fikbaeher) =
4976 2ʔweʳ 'to guard, defend' (biofikbaeher)
(vaguely similar to Chn 衛 *wɨi but neither the initial nor rhyme match; the expected Tangut borrowing would be vɨi)
1756 2ʔɨiu 'to guard, defend' (bouvur; vur = bioher)
I am always interested in how complex writing systems represent abstract words. For example, 'like' (as in 'resemble') doesn't look like anything. The Chinese solution was to write Old Chinese *na 'like' as
如 = 女 *r-naʔ 'woman' (phonetic) + 口 *koʔ 'mouth'
I am not sure what 'mouth' is doing. I am not convinced by explanations which identify 'mouth' as words that a woman is to obey. The semantic link between obedience (acting in accordance with instructions) and resemblance is weak. Could this be a very early use of 'mouth' as an element indicating a grammatical word?
The tangraph 0290 for 2siu 'like', a word which I mentioned in my last two posts
contains three radicals:
干 bel 'surround' < Chn 韦 < 围 < 圍 'surround'?gii, a radical identified as 'sun' by Nishida (1966: 244), but with many other functions described by Andrew West
cok, one of several right-hand ヒ-shaped elements of unknown function
Unfortunately, no analysis for 0290 'like' is known.
The first two radicals (belgii) serve as a phonetic for a few s-syllables:
| Tangraph | Li Fanwen number | Reconstruction | Gloss | Notes |
 |
0309 | 2sju | cousinship | Is 0290 phonetic? |
 |
0586 | transcription tangraph; the Tangut surname Su | ||
 |
2164 | 1swiə | to think | 0290 is phonetic according to Tangraphic Sea; related to Old Chinese 思 *sə 'think'?; -w- < prefix *p-? |
 |
3330 | 1swã | mute; the Tangut surname Swan | 2164 is phonetic according to Tangraphic Sea |
Not all tangraphs with belgii have s-readings:
| Tangraph | Li Fanwen number | Reconstruction | Gloss | Notes |
 |
0538 | 1pia | first half of 1pia-1piu 'butterfly' | phonetic according to Tangraphic Sea is 0537, whose phonetic is 0538 - circular! |
 |
1272 | broad, wide; shallow | 0538 is phonetic according to Tangraphic Sea | |
 |
0805 | 2ʔiew | the place name Yew | analyzed as 'city' + 1dʒwɨõ 'bird'; the latter is a cryptophonetic, since the Chinese word for 'bird' *jɨw sounded like 2ʔiew. |
 |
1381 | 2vəi | curtain; screen | phonetic according to Precious Rhymes of the Tangraphic Sea is 0289 2vəi 'city', whose phonetic may be 干 bel 'surround' < Chn 韦 < 围 < 圍 *wɨi 'surround' |
In three of the four non-s belgii tangraphs (1, 3, 4 below), bel and gii are derived from different tangraphs, so belgii is not a unit:
1.
+
1pia belgiidaaces = 1pia beldexdaaces + giigirwur
10.23.0:46: The above derivation is one half of a circular derivation. The other half is:
0.
1pia beldexdaaces = 1pia belgiidaaces + ciager (ger = dex + bae)
2.
1pia belgiijix = 1pia belgiidaaces + geojixhas belgii as a unit taken from belgiidaaces in which belgii was not a unit.
3.
+
2ʔiew belgiicin = beldexcok + (*jɨw) giigirwur + gaedumcin
4.
+
2vəi belgiiher = 2vəi beldexcok + giifeijiu + pikher
I wonder if anyone asked themselves that question while looking at last night's Liangshan Yi-Tangut comparisons: e.g.,
'like': LY svʷ < ?*su : Tangut 2siu < *su
'six': LY fvʷ < ?*fu : Tangut 1tʃhɨiw < *k-triw (cf. Written Tibetan drug)
What would distinguish Tangut 2siu 'like' from 1siw 'new', besides the tones (2 and 1)?
I am generally not fond of notation like -iu because it is ambiguous. Is it [iw] or [ju]? However, I ended up using -i- as a symbol for Tangut Grade IV:
| Pre-Tangut vowel | Tangut descendants of pre-Tangut vowels | |||
| Grade I (mid) | Grade II (low) | Grade III (high nonpalatal) | Grade IV (high palatal) | |
| *u | əu | ʊ | ɨu | iu |
| *i | əi | ɪ | ɨi | i |
| *a | a | æ | ɨa | ia |
| *ə | ə | ʌ | ɨə | iə |
| *e | e | ɛ | ɨe | ie |
| *o | o | ɔ | ɨo | io |
(10.22.1:11: The vowels are in Tangraphic Sea order. Only now have I realized that they are in a symmetrical sequence: back to front to central to front to back.)
| 2. i | 4. ə | 1. u |
| 5. e | 3. a | 6. o |
I could have written Grade IV with -j- (and Grade III with the exotic glide -ɰ-) but I modelled my notation after that of Axel Schuessler (2007: 120), who wrote Late Old Chinese 'warped' vowels as diphthongs rather than as glide-vowel sequences.
The glide at the end of 1tʃhɨiw 'six' and 1siw 'new' did not originate as part of a warped vowel. In those cases, it is a remnant of an earlier *-k (cf. Written Tibetan drug 'six' and Written Burmese sac < *-ik 'new').
Perhaps I should write warped vowels with glides. Altered notation is in bold.
| Pre-Tangut vowel | Tangut descendants of pre-Tangut vowels | |||
| Grade I (mid) | Grade II (low) | Grade III (high nonpalatal) | Grade IV (high palatal) | |
| *u | əw | ʊ | ɰu | ju |
| *i | əj | ɪ | ɰi | ji |
| *a | a | æ | ɰa | ja |
| *ə | ə | ʌ | ɰə | jə |
| *e | e | ɛ | ɰe | je |
| *o | o | ɔ | ɰo | jo |
In this glides-for-higher-grades notation, Grade IV 'like' would be 2sju.
The big problem with either of these notations is that the evidence for glides in the higher grades is almost nonexistent.. Like Gong (1995), I reconstructed the Tangut grades by analogy with Middle Chinese grades, since there is a strong correlation between the two systems in loanwords and transcriptions. However, the Tibetan alphabetic transcriptions of Tangut Grade IV syllables generally lack -y-: e.g., 2su 'like' was transcribed in Tibetan as su, zu, or zuH but never as syu. Although sy- is not possible in Tibetan, the Tibetan transcribers of Tangut did not hesitate to write un-Tibetan letter combinations to represent sounds in Tangut that must have been absent from Tibetan.
The absence of Tibetan evidence for Grade III is inevitable since Tibetan has no letters for ɨ or ɰ. The -y- of the transcription -yu for Tangut rhyme 2 -ɨu /-ɰu may be an attempt to transcribe -ɨ-/-ɰ-.
Tibetan also lacks letters for many other Tangut vowels in all grades: e.g., ə, ʊ, ɪ, æ, ʌ, ɛ, ɔ.
At times I am tempted to use a more agnostic notation like 2su4 for 'like', but the final -4 looks like a tone number rather than a grade number. My lay Tangut notation completely avoids indicating tones and grades: e.g., su 'like'.
In the last two entries, I examined vowelless words in Oogami. 凉山 Liangshan ('cool mountain') 彝 Yi (LY), a distant relative of Tangut, has "an astonishingly wide variety of syllabic consonants" and "a wide variety of syllables in which the only segment is a phonetic consonant" (Eatough 1997: 9, 2). See Eatough's list of LY words containing vowelless syllables on p. 3. LY syllabic consonants
- all bear tones
- are either lax or tense: z vs. ẓ
(Cf. Tangut which is often thought to also have a lax/tense distinction. Eatough indicates LY tenseness with underlining whereas Tangutologists use subscript dots for tenseness.)
- can be labialized: m vs. mʷ
- can be palatalized: ʒ vs. ʒʲ
- can form 'diphthongs': m͡l
- can be preceded by a homorganic initial: hmmʷ (initial hm- + syllabic mʷ).- can be prededed by a nonhomorganic initial: pz, phz, bz, fz, vz
LY syllabic -vʷ (lax) and -vʷ (tense) may be preceded by a bilabial or dental stop with bilabial trilling: pᴮvʷ, tᴮvʷ.
Eatough regards LY syllabic consonants as allophones of phonemic high vowels /i/ and /u/. I would be more convinced if native speakers interrhymed syllabic consonants with phonetic high vowels: i.e., demonstrated that they belonged to the same mental (= phonemic) category. Perhaps they do so. I have no idea.
The most likely sources of LY syllabic consonants are high vowels which are more or less retained in Tangut: e.g.,
'wood': LY sz < ?*si : Tangut 1si
'one': LY tshz < ?*thi : Tangut 1lew < *Cʌ-tiw
'leopard': LZ z < ?*zi : Tangut 2zeʳw < *rʌ-ziw
'like': LY svʷ < ?*su : Tangut 2siu < *su
'thousand': LY tᴮvʷ < *?tu : Tangut 1təụ < *Sʌ-tu
10.21.1:48: Not all LY syllabic consonants correspond to Tangut i and u: e.g.,
'seven': LY ʃʒ < *ʃi : Tangut 1ʃɨạ < *Sɯ-ʃa
'nine': LY gvʷ < ?*gu : Tangut 1giəə < *gəə'skin': LY *ndʒʲ < ?*ndʒʲi : Tangut 1dʒɨə < *dʒə
I can't account for these discrepancies.'steal': LY khvʷ < ?*khu : Tangut 2kiiʳ < *r-kii-H
(but cf. Written Tibetan rku-ba, Old Chinese *khos with labial vowels)
LY vʷ < *u sometimes corresponds to Tangut i(e)w:
'year': LY khvʷ < ?*khu : Tangut 1kiew < *Cɯ-kew
'six': LY fvʷ < ?*fu : Tangut 1tʃhɨiw < *k-triw (cf. Written Tibetan drug)
I am not sure the last two are cognate. Although f- : tʃh- looks like an unlikely correspondence, it's not entirely outlandish, since Middle Chinese *tʂh- became pfh- before u in some northwestern Chinese dialects.
10.10.19.23:59: WHERE ARE THE VOWELS ON GREAT GOD ISLAND? (PART 2)
Thanks to Thomas Pellard for immediately answering my questions about Oogami.
In part 1, I reproduced a list of vowelless Oogami words with syllabic voiceless fricatives in bold. Below are their modern standard Japanese cognates and Proto-Japonic sources. Periods indicate syllable breaks. Hyphens indicate morpheme boundaries.
| Oogami gloss | Oogami | Modern standard Japanese | Proto-Japonic |
| nest | ss | su | *su |
| to come | kss | k-i | *k-i |
| day | pss | hi | *pi |
| to fall (rain) | ff | fu.r-i | *pu.r-i |
| to make | kff | tsu.ku.r-i | *tu.ku.r-i |
| to build | f.ks | fu.k-i 'to thatch' (1) | *pu.k-i |
| month | ks.ks | tsu.ki | *tu.ku-i |
| to cut | s.ks | ?ki.r-i (2) | ?*ki.r-i |
| to pull | ps.ks | hi.k-i | *pi.k-i |
(1) and (2) were Identified by Thomas, who hypothesizes that the s- of s.ks may be a prefix. All other identifications are mine.
Oogami f and s originate from PJ high vowels (*u, *i, and the diphthong *ui).
Long vowels in monosyllables became long fricatives:
*pi [pii]? > *pɿɿ > pss
*tu became ks:
*tu > *tsɿ > ks
*pu and *ku merged as *fu which then became f:
*pu.k-i > f.ks
*tu.ku.r-i > kff
(10.20.0:04: Cf. Cantonese 苦 fu < *khu.)
*s assimilated to an adjacent *f:
*tu.ku.r-i > *tsɿ.fu.r-i > *ksf > kff
10.20.1:22: Although the modern standard Japanese forms above are generally more conservative (i.e., more like Proto-Japonic) than their Oogami cognates, Oogami does sometimes preserve PJ *p- which has lenited to h- in MSJ ('day', 'to pull').
10.10.18.23:59: WHERE ARE THE VOWELS ON GREAT GOD ISLAND? (PART 1)
Thanks to Guillaume Jacques for pointing out that Thomas Pellard's PhD dissertation on the language of 大神島 Oogami 'Great God' Island is online.
I never expected to see Berber, Czech, Polish, Georgian, Japhug rGyalrong (a relative of Tangut), and a Japonic language (Oogami) on the same pages (pp. 80-81, 105; 98-99, 123 of the PDF; syllabic consonants in bold).
Chleuh Berber sfqqstə 'annoy him!'
Polish szczekać [ʂtʂe.katɕ] 'to bark'
Czech prst 'finger'
Georgian ცხვირი tsχwi.ri 'nose'
Japhug rGyalrong fskɛr̥ 'to bypass'
Oogami ps.tu 'person'
Oogami even has words without vowels (p. 82 / PDF p. 100)
ss 'nest'
kss 'to come'
pss 'day'
ff 'to fall (rain)'
kff 'to make'
f.ks 'to build'
ks.ks 'month'
s.ks 'to cut'
ps.ks 'to pull'
Yet Oogami is related to Japanese which is full of vowels.
Next: Where did the vowels go in Oogami?
10.10.17.23:59: گلشن زبان GULSHAN-É ZABĀN
is the Persian name of one of the blogs of minus273, a student of Tangut:
گلشن gulshan [golʃan] 'garden'
(unwritten) -é (the اضافه ezāfé suffix) 'of'
زبان zabān 'language'
Although there is no Tangut content there (yet?)*, it's still interesting. This post on French and the Ryukyuan language Oogami really caught my interest:
The [Oogami] word cognate to Japanese つくる [tsɯ̥kɯrɯ] is pronounced thus: [kfː]
... with no vowel! I presume kff is all that's left of an earlier *tukur- and that the ff is from *u. (10.19.0:36: No.)
*10.18.0:18: There is Tangut content at minus273's blog 发生之月.







