11.10.29.20:09: BATTON LASH-DE TUMU AISE!
Today is comics creator Batton Lash's
birthday
so I wish to tell him in Khitan,
Batton Lash-de tumu aise!
'To Batton Lash, ten thousand years (of life)!' = 'Long live Batton Lash!'
Each character represents a word. Three out of the four characters break down into smaller components:
Component cluster 1: Batton
 |
||
Component cluster 2: Lash-de (-de is a Khitan suffix meaning 'to')
 |
||
Single-component character:
represents the Khitan word tumu 'ten thousand'.
Character cluster 3: ai-se (the Khitan word for 'years')
 |
The 'birth' part of 'birthday' also contains a two-component cluster:
| |
(referring to the gender of the person who was born) |
The pronunciation of the Khitan word for 'born' is unknown.
'Day' is a single-component character:
The Khitan word for 'day' was something like neir.
11.10.28.23:58: SHAVKUNOV'S THE PARHAE STATE: BEGINNING AT THE END
Back in 1996, Alexander Vovin lent me his copy of Juha Janhunen's "On the Formation of Sinitic Scripts in Mediaeval Northern China" (Journal de la Société Finno-Ougrienne 85.107-124) which really got me thinking about what Andrew West calls TJK - Tangut, Jurchen, and Khitan. I had known for years about the existence of all three languages and their scripts, but Janhunen brought up issues I haven't seen elsewhere: e.g., why the Khitan large script seems to consist of a random mix of
- standard Chinese characters (occasionally with random unexpected semantic and/or phonetic values!): e.g.,
<reading unknown> 'to write, compose' (looks like std Chn 光 *koŋ 'light')
- modified Chinese characters:
<po> 'time' (looks almost like 㺳, a variant of the first half of std Chn 玫瑰 *muikui 'a beautiful red stone'
- completely non-Chinese characters: e.g.,
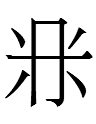
<ai> 'year' instead of std Chn 年 'year'
unlike the Tangut script whose characters are wholly unique or the nonalphabetic scripts of Vietnam, Korea, or Japan which can be described as 'expanded sinographies' including all Chinese characters proper plus transparent local derivatives.
Janhunen proposed that the Khitan - and Jurchen - large scripts were descended from "an old local tradition of writing" from Parhae.
Traditional linear model of descent (no Parhae)
| sinography |
| Khitan large script |
| Jurchen large script |
Janhunen model
| proto-sinography | ||
| mainstream sinography | Parhae sinography | |
| Khitan large script | Jurchen large script | |
He cited the works of EV Shavkunov on Parhae several times, but I have never seen any of them until tonight. I wish to thank Viacheslav Zaytsev for letting me see Shavkunov's 1968 book Государство Бохай и памятники его культуры в Приморье (The Parhae State and the Monuments of Its Culture in Primorye). It ends with these two paragraphs about this long-forgotten** nation:
Thus we can safely say that the emergence of the Jurchen Jin (or Aisin*) empire owes much to the existence of the state of Parhae and the struggle of the population of Parhae against the Khitan people of the Liao Empire. But the significance of Parhae is not limited to its political role in the history of the Far East and Central Asia. Parhae also definitely played a role in the development and formation of the cultures of its neighboring nations.
At the same time, it is clear from the known archaeological material that the development of the Parhae culture did not take the path of blind imitation of foreign standards and patterns; instead it took a path of creative recycling in accordance with its people's tastes and traditions, which allows us to speak of the originality and the characteristic features of the Parhae culture, and of its proper place among the other cultures of the peoples of Central Asia and the Far East during the early Middle Ages.
Was the Parhae script a product of "creative recycling"?
Later: Which Passages of Shavkunov (1968) Did Janhunen Cite?*10.29.12:23: Aisin is Manchu for 'gold' and corresponds to the Chinese name 金 Jin 'gold' for the Jurchen dynasty. The Jurchen name was
alcun <alcu.un> 'gold' (the second spelling is from the Yongning temple inscription)
~
Cincius (1975.1.23) listed aisin and ’an-č‘ūn (= alcun) as cognates, but I am not certain whether they are truly related.
**10.29.12:28: Parhae is certainly not long-forgotten in South Korea, where a TV series about its founder 大祚榮 Tae Cho-yŏng recently aired. But to the rest of the world, Bohai (= Parhae) may just be the name of a sea.
11.10.27.23:59: A FIRST PEEK AT THE PARHAE SCRIPT
I am out of time tonight, so I can only express my thanks to Viacheslav Zaytsev for showing me 李強 Li Qiang's 1982 article 《論渤海文字》 'On the Parhae Script' which contains examples of Parhae writing that mix standard Chinese characters (including some shared with the Khitan large script: 高未天 ...) with unusual sinographic variants. This combination of the familiar with the unfamiliar is reminiscent of the Khitan large script, yet at a glance I see very little that looks Khitan.
(Although I first started working on both Tangut and Khitan in 1996 - also the year I first learned of the possibility of a Parhae script from Janhunen 1994 - I still remain a novice at Khitan at best, and so the obvious eludes me, as my last entry demonstrated. The humiliation continues this weekend.)
Some Parhae graphs are derived from standard sinographs with mirror-imaging and inversion - strategies I don't remember seeing in Khitan*:
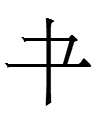
std 于 (with bottom hook pointing leftward) : Parhae モ (with bottom part pointing rightward; there is a similar Khitan large script graph whose meaning/reading is unknown to me)
std 干 (without a bottom hook) : Parhae 士
std 未 : Parhae 半 (but Parhae also has 未!)
The distinctive un-Chinese graph for 'year' that I would expect to be the ancestor of
Khitan <ai> 'year'
Jurchen <aniya> 'year'
is absent, though the standard Chinese graph 年 'year' is present.
This Weekend: Parhae Graphs That I Can't Simulate in Unicode
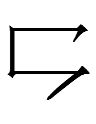
*10.28.2:01: A Jurchen example of inversion is
<ninggu> 'six'
which looks like Chn 六 'six' upside down plus a hook at the bottom.
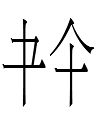
The Khitan large script graphs for 'six' such as
- are quite different from both the Jurchen and Chinese graphs, though they could be ultimately cognate.
Parhae 六 meant 'six' as in Chinese and is unlike both the Jurchen and the Khitan graphs.
The Khitan large script has a graph that looks like Chn 六 'six', but I don't know its reading or meaning.
11.10.26.22:36: OH, HOW THE GODS MOCK ME!: THE BOTTOM OF HEAVEN?
I apologize to Andrew West for missing his latest post on a Khitan manuscript fragment identified ... in 2002!
Alas, I don't have much to say about it and don't even have the time to write about all three lines, so tonight I'm going to confine my remarks to the first line. You can see the whole fragment (an oxymoron?) here.
A.i has what appears to be the bottom right of a 大 shape atop ㅗ. The Khitan large script character<heaven>
first came to mind even though it has 土 on the bottom rather than ㅗ which is not at the bottom of any large script graphs that I've seen. Jurchen
<heaven>
could be derived from a ㅗ-variant of Khitan <heaven>.
The Khitan small script character
<?; not 'heaven'>
is an even better match, but the two Khitan scripts are never mixed in a single text. Was there a variant of the large script 'heaven' graph that was written like this small script graph? Perhaps this graph is a heretofore unknown graph with ㅗ on the bottom. If not, it may translate a Chinese 天 which in turn could also be a translation of Sanskrit deva 'god' or dyo 'heaven, day'
A.ii might be 'north', written almost like Chinese 北 'north'. Since Khitan had adjective-noun order, 'heaven north' is not a possible collocation. Could this fragment be part of a sentence like
... heaven (subject) north ... (object) (unknown verb)?
Is there any Chinese text with a passage like ...天 (verb) 北 ...? This is where an electronic corpus with regular expression searchability would come in very handy. Of course, there is no guarantee that this Khitan text is a translation or commentary on a Chinese original.
Later This Week: Line B23:07: Corrigendum: Looking at a large image, I've now ruled out <heaven> as the first graph. The shape atop ㅗ looks like the bottom of 九 rather than 大. I've seen several different Khitan large script graphs with 九 as a bottom component, but none have ㅗ between the two legs. The closest match I've seen has a dot rather than ㅗ:
<unknown>
If this graph isn't a variant of that graph, it may be wholly unknown. I wonder if Viacheslav Zaytsev has found any Khitan large script graphs with ㅗ on the bottom in the manuscript he's studying.
11.10.25.23:59: THE ANCESTORS OF SOGOR
"The Daozong Dilemma" revolved around the question of why the Khitan large script equivalent of Chinese 宗 'ancestor' was 伋. That Khitan graph was the source of the Jurchen phonogram for gor according to Jin (1984: 236):
Khitan large script <zuŋ>? > Jurchen <gor>?
>
~
<zuŋ?> is Sino-Khitan (i.e., borrowed from Chinese). One might guess that the native Khitan word for ancestor was gor, but Kane transcribed the Khitan small script word for 'ancestor'
as <u.ur.ai>, literally
+
<u.ur> 'first/upper/previous' + <ai> 'father'
Is the resemblance between Khitan small script
2.131 <u> (I'll be using Kane 2009's numbers from now on whenever available)
the first character in the stack for Khitan <u.ur.ai> 'ancestor' and the right side of the Jurchen phonogram

<gor>
coincidental?
Probably. A better match for the shape of the right side of Jurchen <gor> is the Khitan small script character
whose reading is only a slightly better match for Jurchen <gor>.
There is a Khitan small script character that is a near-perfect match for Jurchen <gor>:
>
2.232 <?> > <gor>?
Could the unknown reading of 2.232 have been <gor>?
In any case, the phonogram <gor> was used to write the Jurchen name for Korea
<so.gor> (in Jin Qizong's reconstruction; found in the Beiqing inscription from 1218 or 1338 [what rules out 1278?]; see Kane 1989: 63)
corresponding to Manchu Solho rather than *Sogor. How can these two names be reconciled? Although Manchu is not the direct descendant of Jurchen, it is a 'niece' of Jurchen and the two languages share a common ancestor. Perhaps the two names are from an earlier *Solgor:
Written Jurchen may have lost *-l- ("may", because it is not clear whether <so> could also be read <sol>; Yamaji reconstructed two readings, but others don't.)
Manchu reduced *-gor to -ho
I specified "Written Jurchen" because the spoken Ming Dynasty Jurchen word for 'Korea' was reconstructed as Solo'o in Kane (1989: 108, 335). Perhaps that late Jurchen form was pronounced [sol(o)ɣo] and was not directly descended from the dialect underlying the Jurchen script.
Jin Qizong's <so.gor> is not entirely unexpected according to the correspondences Kane (1989) found between his reconstruction of spoken Ming Jurchen (SMJ) and Manchu:
- Chinese transcriptions of SMJ sometimes do not indicate -l- before consonants, but it is not clear whether this is due to Ming Chinese lacking final *-l or reflecting genuine -l loss in SMJ. Conversely, the 'extra' vowel in SMJ -lVC- corresponding to Manchu -lC- may be a Chinese attempt to transcribe -lC-, a sequence that was impossible in Chinese.
- SMJ -g- generally corresponds to Manchu g, but in some cases SMJ zero, hiatus, or -h- correspond to Manchu -g-, not the other way around!
SMJ ju : Manchu jugun 'road'
SMJ dilu'a : Manchu jilgan 'voice'
SMJ umuha : Manchu umgan 'marrow'
SMJ apparently lenited g unlike the dialect ancestral to Manchu.
- Manchu -h- corresponds to SMJ -h-, hiatus, or zero, not SMJ -g-:
SMJ sil(i)hi ? : Manchu silhi 'liver'
SMJ Sol(o)'o : Manchu Solho 'Korea'
SMJ ila : Manchu ilha 'flower'
Does this mean that Jin Qizong's <so.gor> is incorrect? No, I still think <so.gor>, Solo'o, and Solho represent three closely related yet distinct lineages.
None of those the above Jurchen/Manchu forms resemble any other words for 'Korea' with two exceptions (see below) - or do they?
*Sol- is vaguely like the second half of Old Chinese 朝鮮 *drewserʔ 'Korea' and Late Old Chinese 斯盧 *siela, a transcription of Old Korean *sera 'Shilla'
*-gor is reminiscent of Late Old Chinese 韓 *gan < *gar 'Korea' (a transcription of the same word underlying Jpn Kara) and the *kore underlying 句麗 ~ 高麗 ~ 高禮 (early names for Koguryo) and Japanese Kure.
Could *Solgor be a compound of two names for Korea? One problem is that the one of the two non-Jurchen/Manchu words resembling *Solgor, Written Mongolian Solungɣus 'Korea', has a medial nasal -ng- and a final -s instead of -r. Solɣo, the other WM word for 'Korea', is much more like the Jurchen and Manchu words.
*10.26.00:55: Could the reading of the Khitan small script character
2.186 <o>
resembling Chn 及 'to reach' be derived from the first syllable of some para-Japonic cognate of Old Japanese əyəmb- 'to reach'? I doubt it, but if there were para-Japonic language(s) in Koguryo, such languages might also have been spoken in Parhae and reflected in the hypothetical Parhae script.
**10.26.1:26: Jurchen <so> has two variants:
~
~
Jin (1984: 76) derived <so> from Chn 屬 *ʃiu.
11.10.24.23:59: THE DAOZONG DILEMMA
I wish I could have been in St. Petersburg today to attend Viacheslav Zaytsev's presentation "Problems of Decipherment of Khitan Large Script: New Approaches and Possibilities" about the manuscript he identified. I wonder how much of that manuscript would seem recognizable to someone who knew Chinese characters. The relationship between the Khitan large script (KLS) and sinography (Chinese characters proper) reminds me a bit of the relationship between the Cyrillic and Latin alphabets:
Same shape, same phonetic value
Cyrillic А : Latin A
KLS 吾 ŋu (phonogram) : Chn 吾 *ŋu 'I'
Same shape, same semantic value
(no Cyrillic : Latin example since they have no logograms)
KLS 五 tau 'five' : Chn 五 *ŋu 'five'
Same shape, different phonetic value
Shapes in one absent from the otherCyrillic В [v] : Latin B [b]
KLS 上 ɣa ~ qa (phonogram) : Chn 上 *ʃaŋ 'above'
A phrase that exemplifies the semifamiliar, semialien feel of KLS isCyrillic Г Д И : Latin G D I
KLS graphs
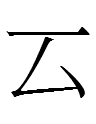
which may or may not correspond to different-looking sinographs
(The first and third KLS graphs represent Khitan suffixes; I don't know what the second graph stands for)
道伋皇帝
dau zuŋ ɣoŋ di (in Kane 2009's transcription style; possibly phonetically *[tau tsuŋ xoŋ ti]?)
'Emperor Daozong' (b. 1032; r. 1055-1101)
corresponding to Chinese
道宗皇帝
*tau tsuŋ xoŋ ti
which is written almost identically except for the second character.
When the KLS was created in 920, over a century before Daozong's birth, why were Chn 道 'road' and 皇帝 'emperor' recycled but not 宗? To put the problem another way, why did the creator(s) feel obligated to recycle Chn 伋 *ki 'name of Confucius' grandson' as a replacement for 宗 'ancestor' (and possibly also its homophones)? Why not just invent completely new shapes for all four syllables as the Tangut did?
Literal Tangut translation of 'road ancestor emperor'
1tʃɨa 2tiụ 1ŋwəʳ 1dzwiə
Those four Tangut characters are not exceptionally un-Chinese. No Tangut characters look like Chinese characters. Like Janhunen (1994), I interpret the partial recycling of KLS as evidence for an 'aunt-niece' relationship between sinography and KLS rather than a 'mother-daughter' relationship:
Aunt-niece model
| Proto-sinography | |
| Mainstream sinography | Northeastern sinography (unattested) |
| Parhae script (hypothesized by Janhunen; unattested) | |
| Khitan large script | |
Mother-daughter model
| Mainstream sinography |
| Khitan large script |
In the aunt-niece model, 道皇帝 would be a common inheritance from proto-sinography, but the use of 伋 for 宗 'ancestor' could have been a Parhae (or earlier northeastern sinographic) innovation* that was inherited by the KLS. Other 'mismatches' between sinography and KLS might generally reflect organic evolution over a long period before 920 rather than arbitrary decisions made in 920 by the creator of KLS. (Of course, the abrupt creation of wholly new graphs on the spot to write Khitan words and syllables cannot be ruled out.) Did the creator really think, 'I like the shapes of 道皇帝 so much that I'm going to keep them as is, but I don't like the shape of 宗, so I'm going to replace it with the prettier shape of 伋, a graph that is semantically and phonetically completely different?'
Next: The Ancestors of Sogor
*10.25.00:48: Some northeasterner unaware that the graph 伋 already existed in sinography could have reinvented it:
亻 'person' (semantic) + 及 'to reach' (did some non-Chinese word for 'to reach' sound like a non-Chinese word for 'ancestor'?)
However, wouldn't literate people know about Confucius' grandson and avoid reinventing 伋?
11.10.23.21:49: LOST IN THE LIGHT
Last week I mentioned the Jurchen graph
on 'how'
resembling Chn 光 *koŋ 'light'. Subtracting a stroke results in the Jurchen phonogram
ya
which Jin (1984: 106) derived from Chn 光 *koŋ 'light' even though I know of no Jurchen or Manchu (or Koreanic or Japonic) word with initial ya- meaning 'light'.
I have already mentioned another Jurchen phonogram for ya with variants:
~
~
Why were two phonograms created for ya? Did these phonograms originally represent different syllables? Did the Jurchen arbitrarily decide that some words should be written with one rather than the other?
yašï 'eye':
but not *
yabu 'to go':
but not *
Are the second spellings in each pair simply unattested (i.e., theoretically possible) or errors?
There is a Khitan large script graph for 'write' that looks exactly like Chn 光 *koŋ 'light':
Kane (2009: 171, 184) lists no reading for this graph, but glossed
as 'composed' and 'wrote, written'. The second graph might be a past tense ending. I wonder if that large script word is equivalent to small script <COMPOSE.a.ar> 'composed' (as interpreted by Kane 2009: 89):
Could
'compose' have been ya(a)- and recycled with slight modification in Jurchen as
ya?
If the endings of the Khitan large and small script words for 'composed' are equivalent
?
their graphs may be cognate and this could be a rare instance of a Khitan small script graph derived from a (less complex!) Khitan large script graph.