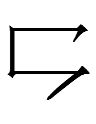
11.10.22.23:59: THE UNDERHANDED
The Khitan and Jurchen large scripts puzzle me because they don't seem to have much structural coherence. Their characters contain recurring components which have no obvious semantic or phonetic function unlike sinographic components.
In sinography, the component 寸, a drawing of a hand, can be semantic, phonetic, or both: e.g.,
- 寸 is a phonetic for Md cun/zun: 寸村忖忖籿吋 cun (with different tones), 尊 zun
- 寸 is a phonetic for Old Chinese *tu-type syllables: e.g.,
肘 *rtuʔ > Md zhou 'elbow' (寸 is probably also semantic)
討 *thuʔ > Md tao 'to ask'
- 寸 is semantic in 導 Md dao 'to guide' - one guides by pointing with the hand and/or taking someone by the hand
I don't understand why 過 guo 'to pass' was simplified as 过, but in general if I see a Chinese 寸-graph, I can generally count on being able to figure out what 寸 is doing in it.
I can't say the same thing for the 'underhanded' graphs of Jurchen
which don't seem to have anything in common other than a 寸-like shape at the bottom:
| Page of Jin (1984) | Jurchen graph | Reading | Meaning | Derivation (Jin 1984 unless marked with A) |
| 3 | |
variant of graph on p. 145 | ||
| 70 | |
beye | body | < Chn 身 'body' |
| 74 | |
variant of graph on p. 159 | ||
| 105 | |
ice | new | < Chn 亲 < 新 'new' |
| 116 | |
mu, šï | (first half of mulu 'complete') | A: does Chn 山 'mountain' on top indicate that this graph was originally devised to write a Jurchen cognate of Manchu mulu 'ridge'? |
| 124 | |
ehe | bad | from Khitan large script |
| 145 | |
i | (none; phonogram) | < Chn 于 *y |
| 159 | |
šao | < Chn 寿 *ʃew | |
| 212 | |
došïn, doko | inside | from Khitan large script |
| 215 | |
mori | horse | right side from a Khitan large script graph uri 'to go' |
| 224 | |
kang | (part of words for 'kowtow') | < Chn 康 *khaŋ |
| 234 | |
aci | holy | < Chn 赤 *tʃhi (A: the component beneath 人 looks like the Khitan large script character for the dative-locative suffix - coincidence?) |
| 251 | |
unknown | ||
| 278 | |
cïn | (none; phonogram) | < Chn 爭 *tʃiŋ, near-homophone of 稱 *tʃhiŋ |
In some cases, the Jurchen dot corresponds to a stroke in the
proposed
Chinese source, but in others it may have been added to differentiate
it from a dotless Chinese source: e.g,
Next: Lost in the Light
11.10.21.23:57: ON-MISSION, OR ONE MORE 'TIME'
As I posted "Getting Back on the Jurchen Track", I realized I had left out what might be yet another variant spelling of Jin Jurchen pon > Ming Jurchen fon 'time'
<po.on>
with the on-graph that is also in the spellings of the imperial surname Onya(n):
<o.on.ya.an>
<o.on.ya>
Jin (1984: 100) glossed
<po.on> = pon
as Chn 刻 'moment' whereas he glossed its homophone
<po.on> = pon
as Chn 時 'time'. Did the Jurchen use different spellings for different senses of pon, or did they perceive both spellings as interchangeable?
Although there was a third on-graph in Jurchen, the spelling
for pon is not attested, presumably because that on was a logogram for 'how'.
Were both of the other on-graphs
pure phonograms not originally intended to represent specific words? When the Jurchen (large) script was invented, why were two phonograms for on created? Was
originally intended for the imperial surname, even though it soon came to be used in other contexts? Surely such an important graph wouldn't be misused. The two graphs were presumably homophonous by the time both spellings
~
were used in the 大金得勝陀碑 inscription of 1185. Were they nonhomophonous only 65 years earlier in the speech of Xiyin, the script's creator? Or does such apparent redundancy reflect an earlier history? If Janhunen (1994) is right about the Jurchen script being a derivative of an (unattested!) Parhae script, perhaps the latter was as complex as Japanese man'yougana: i.e., there were many different ways to write the same syllable. The Jurchen large script could have been an attempt to standardize this chaos (cf. the elimination of multiple kana for the same syllable in Japan in 1900). Homophonous phonograms in Jurchen may be remnants of an earlier diversity.
Next: The Underhanded (finally!)
10.22.1:22: ADDENDUM: Jin (1984: 110) derived the graph for Jurchen on 'how'
from Chn 光 *koŋ 'light'. Although the two graphs are undeniably similar, their readings have little in common and the meanings of the words they represent have nothing in common. I still think that 完 *on is a more likely source (or a graphic cognate of a lost Parhae source graph).
11.10.20.23:59: GETTING BACK ON THE JURCHEN TRACK
I accidentally left out another variant of the Jurchen word for 'time' from "Other 'Times' in Khitan and Jurchen":
<po.on> = Jin Jurchen pon > Ming Jurchen fon
I meant to mention this word in a post I was going to title "The On-derhanded", but I'm going to give 'the underhanded' their own post as I had originally planned.
The phonetic complement
which has even more variants (see Jin 1984: 110) looks like Chinese 小 *siau 'small' plus 又 *yeu 'also' and an additional stroke. Were those Chinese elements chosen and combined at random to form a graph for Jurchen on? Maybe not. If the Jurchen large script is based on a lost Parhae prototype, this graph could be based on a character originally devised to write a Koreanic word like *on. Three candidates come to mind:
*on- 'to come' (as reconstructed in Vovin 2010: 27)
*on 'hundred'
*onV 'all'
The Jurchen on-graph doesn't look like Chn 百 'hundred' or 全 'all'. 百 is clearly a graphic cognate of Jurchen
~

tanggu 'hundred'
and Jurchen gemu 'all' was written as
~
which doesn't look like
That leaves Koreanic *on- 'to come'. Chn 來 'to come' is phonetic in 麥 'wheat' which has a simplified form 麦 vaguely resembling
Is it possible that in the northeast, Chn 'to come' was written as something like 麦* which was then used as the basis of a Parhae graph for *on- 'to come' that was then recycled to write Jurchen on?
Here's a 完 completely different explanation for the shape of on. What Chinese character would have sounded like Jurchen on during the early Jin Dynasty and resembled the shape of on? Could 完 *on 'complete' fit the bill?
- the three strokes of 宀 could be changed to 小
- the 儿 legs of 元 could be changed to 又
But that latter alteration is far-fetched. Or is it? There is yet another Jurchen graph pronounced on
meaning 'how' (without a Manchu cognate?) with 儿 legs instead of 又. Could this graph be the missing link between 完 *on and
?
If the above graph were based on 完, one might expect it to correspond to the 完 used to transcribe the first half of the imperial surname 完顏 Onya(n), but the Jurchen spellings of 完顏 contain yet another on-graph:
<o.on.ya.an>
<o.on.ya>
One might think this last on-graph
was reserved for writing the imperial surname like
the tangraphs devised for the Tangut imperial surname Ngwimi, but it and the other graphs for Onya(n) could be used in other contexts as well.
What was the purpose of having three different graphs (not counting variants)
for on? Only the second one can be identified as a logogram. Were the other two originally devised for two nonhomophonous syllables that merged in later Jurchen?
Next: The Underhanded
*10.21.8:24: Schuessler (2007: 374) wrote,
According to Pulleyblank (EC 25, 2000: 23), 來 is the original graph for mài ['wheat'] while 麥 (with the element 'foot') was originally intended for the more common lái 'come'
and if that is correct, perhaps some variant of 麥 continued to mean 'come' in the northeast.
11.10.19.23:49: WHEN DID POLISH RZ BECOME A FRICATIVE?
Today I realized that Przhevalsky (Пржевальский < Polish Przewalski) has -рж- <rzh> for Polish -rz-. This name would be transcribed as Пшевальский with ш [ʃ] in the system of Cyrillicization of Polish at Wikipedia which reflects modern Polish pronunciation. Is the Cyrillicization рж <rzh> a relic of a period before Polish rz merged with ż as /ʐ/? (This /ʐ/ devoiced to [ʂ] after /p/.) Was рж <rzh> an approximation of a premodern Polish sound like Czech ř which is Cyrillicized as рж <rzh>: e.g., Дворжак <Dvorzhak> Dvořák? Wikipedia agrees with my guess:
This sound [ř] occurred historically in Polish, where it was written rz, but it has since merged with ż [ʐ].[citation needed]
Is it correct? That "citation needed" makes me wonder.
I never understood why Czech (and Polish?) developed such a rare consonant from *rʲ. Not even Czech's sister Slovak has ř.
Could the Tangut initial that Gong reconstructed as ź- (and that I rewrite as ʒ-) have been a trill ike Czech ř? The Tangut categorized this consonant as a liquid even though it was transcribed in Tibetan as (g)zh- (Tai 2008: 201).
10.20.1:45: Tai (2008: 201) reconstructed ʁź-, combining Nishida's preinitial ʁ- with Gong's ź -. This cluster is similar to Russian рж <rzh> (and English [rʒ]) for Czech ř. rzh- is not a possible initial cluster in Classical Tibetan. The closest possible clusters are bzh- and gzh-. Could (g)zh- be an attempt to write a Tangut ř-?
One problem with this hypothesis is that the Tibetan transcriptions of Tangut were not constrained by Tibetan orthographic conventions: e.g., the Tangut initial that Gong reconstructed as w- (and that I rewrite as v-) was transcribed with the un-Tibetan clusters yw- (Tai 2008: 178) and ww- (Nishida 1964: 83; not in Tai 2008). So if Tibetans heard a Tangut consonant that sounded to them like rzh-, they could have transcribed it as an un-Tibetan cluster rzh-.
Let's suppose Tai and/or Nishida are correct and Tangut had initial clusters of the type RZ-:
Tangut R- and Z-type initials (after Tai 2008: 201)
| Tangut liquid fanqie chain | Tibetan transcription | Nishida 1964 | Sofronov 1968 | Gong 1997 | This site | Tai 2008 |
| 12 | r- (17), rd- (1), rh- (1) | r- | r- | r- | r- | r- |
| 13a, 16a, 19a | gz- (35), z-
(9), rdz- (2), Hz- (1) |
ʁ- | z̀- | z- | z- | ʁz- |
| 13b, 16b, 19b | ʁz- | |||||
| 20 | ld- (1) | l- | l- | ld- | ||
| 18 | zl- (1) | l- | ||||
| 14 | ? | ňž- | ź- | ʒ- | ʁź- | |
| 15, 17 | gzh- (8), zh- (1), j- (1) |
What would have been the sources of these initials: e.g., *gl- and *gr- clusters?
*gl- > *ɣl- > *ɣɮ- > *ʁɮ- > ʁz-
*gr- > *ɣr- > *ɣʐ- > *ʁʐ- > ʁʒ- = Tai's ʁź-
The above scenario incorporates my earlier proposal of rewriting Gong's z- and ź- as [ɮ] and [ʐ].
Do Nishida and Tai's RZ-initials correspond to clusters in other languages?
Nishida and Tai did not reconstruct any simple Z-initials. Nishida reconstructed ʁ- but Tai only reconstructed ʁ- as part of the clusters ʁz- and ʁź-. Are there any languages with RZ- but without Z- (or even R-)?Tai reconstructed ld- as the only lC-cluster in Tangut, whereas ld- is one of a series of Written Tibetan lC-clusters:
Written Tibetan lC-clusters (Jacques n.d.)
| lp- | lt- | lc- | lk- |
| lb- | ld- | lj- | lg- |
| (lN- is impossible unless -N- is -ŋ-) | lŋ- | ||
Is there any language with ld- but without any other lC-clusters?
Next: Getting Back *on the Jurchen Track
11.10.18.23:57: OTHER 'TIMES' IN KHITAN AND JURCHEN
This blog would be so much poorer without the help of my readers.
First, I'd like to thank Viacheslav Zaytsev for reminding me that Inner Mongolia Education Press has an image of the 蕭孝忠墓誌 Khitan large script inscription (1090) and that Aisin Gioro Ulhicun typed the inscription much more legibly in her 2009 book. It seems that the inscription has
for po 'time' rather than
as handwritten in Jin (1984: 75).
Notice anything about that first glyph for 'time'?
Second, I'd like to thank Andrew West for his Khitan large script font and much more. The above glyph for 'time' is his. Can you distinguish it from mine?
I've now seen hundreds of different Khitan large script characters for the first time, including variants of the graph for the dative-locative suffix resembling Chn 時 'time':
The horizontal line with a right-hand hook in the second variant is a common stroke in the Khitan and Jurchen scripts that always has a stroke to its left in the Chinese script proper: e.g., 冖, 欠. Moreover, horizontal-right-hook is permissible in the bottom position in Khitan but not in Chinese (and Jurchen?): e.g.,
Khitan large script
(readings and meanings unknown to me)
Khitan small script
<eu>, unknown, <úŋ>, unknown
Was this un-Chinese stroke a Khitan innovation, or was it carried over from Janhunen's hypothetical Parhae script (for a Koreanic language)?
By coincidence, made-in-Korea transcription characters like 㪲 tuk combine Chinese characters (in this case, 斗 Sino-Korean tu) with a similar bottom stroke - the hangul letter ㄱ k. (There was no Chinese character with the Sino-Korean reading tuk, so 㪲 was invented to write the native Korean syllable tuk.)
Un-Chinese strokes like horizonal-right-hook triggered this reaction in Ramsey (1987: 225):
To a Chinese eye, Jurchen characters look odd. Some seem to have a stroke or two in the wrong place, others have a dot that breaks the symmetry. The effect is a little like the pictures that Western artists often produce when they try to imitate Chinese characters.
But only a little. The Jurchen - and Khitan - elite were literate in Chinese as well as their native languages. (Was anyone literate only in Jurchen or Khitan?) They would have known that their graphs for 'time'
~
and
resembled the first half 玫 ~ 㺳 of Chinese 玫瑰 *muikui 'a beautiful red stone'. If questioned about the resemblance, how would Jurchen and Khitan elites have explained it? Was it a coincidence that the creators of their scripts just so happened to devise graphs that looked like an existing Chinese graph with a wholly different reading and meaning?
Janhunen (1994: 4) wrote,
All these systems [of writing: Tangut, Jurchen, Khitan] are undeciphered in the sense that the functonal relationship between graphic form and linguistic substance is not understood.
This statement is too strong, as the structure of all three scripts is partially understood - with emphasis on "partially". In many cases, we still do not know why shape X is associated with reading Y and/or meaning Z - if we know the reading and/or meaning.
Next: The Underhanded
10.19.00:29: All of the Khitan small script characters with horizonal-right-hook resemble other KSS characters without the hook:
| Unhooked | Reading (Kane 2009) | Hooked | Reading (Kane 2009) |
 |
? |  |
<eu> |
 |
<p> | 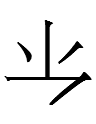 |
? |
 |
? |  |
<úŋ> |
 |
? |  |
? |
Did the hooked and unhooked graphs have similar phonetic values? E.g., were the first three pairs
?<éu> : <eu>
<p> : ?<f> (for Chinese loans?; there was no native Khitan <f>)
?<ûŋ> : <úŋ>
11.10.17.23:24: AT THE TEMPLE OF TIME
In my last post, I asked why the Khitan and Jurchen wrote their words for 'time' with
rather than with graphs resembling Chinese 時 'time' like
and
which looks like Chn 寺 'temple'.
Of course, the Jurchen word for 'temple' is written completely differently:
(
)
<tai.ra.(an)> = taira(n)
which by coincidence resembles the unrelated Japanese name 天草 Amakusa
The Khitan word for 'temple' is apparently unknown but I wouldn't be surprised if Kane (2005: 132) were right about the Jurchen word possibly coming from Khitan. But where did Khitan get the word from?
Vovin (2007: 75) wrote,
there are two problems with his [Kane's] hypothesis: no such Khitan word is so far attested [could it be in the recently discovered Khitan large script manuscript?], and we do know that Buddhism was already present in the Jurchen territory prior to the Khitan conquest of Parhae [= Bohai] in 926 AD. Due to the fact that Buddhism was flourishing in both Koguryo and Parhae, some kind of Old Korean source seems to be more likely. The problem is of course, that the OK word is not attested either [even though much of the OK corpus consists of Buddhist poetry!] so we can only compare Jurchen tairan ~ taira 'Buddhist temple' with MK [Middle Korean] 뎔 tyèr 'id.' (LCT [Yu Chang-ton] 220), ·뎔 tyér 'id.' (Nam 1997: 405-06), (Hankul hakhoy 1992: 4989). The loss of the final vowel in MK can be explained as an apocope of the original *HH or *HL bisyllabic structure (Kim 1973), (Martin 1996: 46-47).
As for the mismatch between
Jurchen ai : Middle Korean ye [jə]
Vovin explained (2007: 77) that
the OK form was likely *tiara, borrowed into Jurchen with metathesis /ia/ > /ai/, since only the latter sequence was possible in Jurchen after /t/.
I'm surprised the Jurchen didn't borrow the word as trisyllabic /ti a ra/ or /ti ya ra/.
If the Khitan had the same word, they could have borrowed it from Parhae or even from Jurchen.
Vovin (2007) lists six other words of possible Koreanic origin in Jurchen and/or Manchu. Given that Parhae was founded by Koguryo elites, if a Koreanic language was spoken by those elites, could the Khitan and Jurchen large scripts be based on adaptations of a local variant of the Chinese script to that Koreanic language? Last week, I hypothesized that
could "be based on a Bohai [= Parhae] 不-based graph for a Koreanic word *an 'not'".-an (resembling the shape of Chinese 不 'not' with a reading like Korean 안 an 'not')
There is some indirect evidence for archaisms in the variety of Chinese once known on the Korean peninsula: e.g., a lack of palatalization:
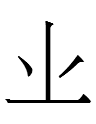
支 Old Chinese *ke > phonogram for Old Japanese *ki (and *ke before that?)
止 Old Chinese *təʔ > phonogram for Old Japanese *tə> but Middle Chinese *tɕie
> but Middle Chinese *tɕɨʔ
Although 時 'time' had a Middle Chinese reading *dʑɨ, did it have an archaic, nonpalatalized, Old Chinese-like reading *də in the early Koreanic world? This *də is not unlike the Khitan dative-locative suffix -de ~ -do ~ -dú (as transcribed by Kane 2009: 136-138) ... and the shape 時 is not unlike the Khitan large script graph for the dative-locative suffix
Here's what might have happened:
時 archaic northeastern Chinese *də (unchanged from Old Chinese?) >
used to write a similar Parhae syllable >
used to write Khitan -de
This scenario is extremely speculative.
A simpler alternative: The Khitan dative-locative suffix (or some Parhae equivalent?) was used after dates, so it was loosely translated as 時 'time', which was then simplified to
This resulting graph was then also used to write the dative-locative suffix after nontemporal nouns: e.g.,
'bandit suppression commisioner-DAT/LOC'
'capital-DAT/LOC'
from the Yongning inscription (Kane 2009: 174-175).
Next: Other 'Times' in Khitan and Jurchen
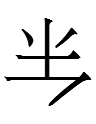
11.10.16.22:36: A TIMELY *MUI-STERY
The Khitan large script graph for po 'time'
looks almost exactly like
and 㺳, variants of the first half of Chinese 玫瑰 *muikui 'a beautiful red stone' (now 'rose').
In fact, the Jurchen graph for po (later fo) 'time'
is identical to Chn 玫 *mui. It has a subtle variant with a different upper right corner:
Why did the Khitan and Jurchen write 'time' with a (near-)lookalike of Chn 玫 *mui? Why not write 'time' with a (near-)lookalike of Chinese 時 'time' instead like
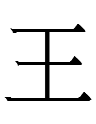
which is a Khitan large script graph that I'll discuss next ... time? Or a (near-)lookalike of a Chinese character pronounced *po? From a Chinese perspective, only the right-hand elements of
might be usable phonetics for writing Khitan/Jurchen po 'time':
王 (< 玉) Chn *ŋy 'jade', *oŋ 'king'
攴 ~ 攵 Chn *phu 'to tap' (a phonetic in Chn *mui-graphs, not *phu-graphs!)
The relevance of the left-hand element 王 is still unknown. Is it irrelevant? Is it an arbitrary addition?
I have yet to see more than ~300 different Khitan large script graphs. Most were in chapter 5 of Kane (2009). Do any other Khitan large script graphs contain one or the other component of 'time'?
(10.17.23:21: I forgot about Khitan 玖 'ninety' which looks like Chinese 玖 'nine'!)
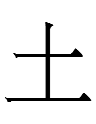
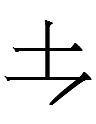
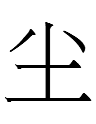
The only other Jurchen graph I know with a left-hand 王 is one of a trio of phonograms for ya:
~
~
Jin (1984: 86) regarded the third form with 土 on the left as basic.
I have no idea why ya was written with those Jurchen graphs. The components 王 土 卜 do not have ya-like Chinese readings and モ is not a Chinese component at all.
However, I do have a wild guess about the origin of the Khitan and Jurchen graphs for 'time'. Could they be recyclings of a Bohai 玫-like graph for a po-word referring to a beautiful red stone? But I can't think of any po-like words for stones in Korean or Japanese that would be potential cognates for such a Bohai word.
Ah, it turns out that the base form of Jurchen ya is identical to Chn 圤, a rare variant of 墣 'clod'. Was there a Bohai ya-word for 'clod'?
Next: At the Temple of Time
as the form of 'time' in 蕭孝忠墓誌 (1090). I can't find a clearly legible copy of the text of this Khitan large script inscription. Can someone confirm how 'time' was written in that inscription?