




10.6.19.23:55: THE GOLDEN GUIDE: LINE 33: TANGRAPHS 161-165
This line seems totally random because it has nothing to do with line 32. It contains a relative clause (161-162) modifying the compound noun 163-164 (a cloud-shaped hat?).
| Tangraph number | 161 | 162 | 163 | 164 | 165 |
| Tangraph | |
|
|
|
|
| Li Fanwen number | 0055 | 0146 | 2738 | 2529 | 0542 |
| My reconstructed pronunciation | 2tʃɨew | 2tʃɛ | 2diẽ | 2piụ | 2lɨuu |
| Tangraph gloss | top | to wear | cloud | hat; crown | beautiful |
| Word | |||||
| Translation | The cloud hat worn on top is beautiful. | ||||
161: The analysis of 0055 is unknown but it looks like 'top' atop
1976 2bie 'the trigram ☱ = 兌; gold'
No other tangraphs have this combination of components (baebeldexbel) which may originate from parts of two or more tangraphs rather than directly from 1976.
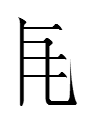
162: 0146 looks like 'top' over 'person'. Its analysis breaks the 'person' at the bottom in two:
+
0146 2tʃɛ 'to wear' =
right of 2292 2tʃɨo 'headgear; hat; cap' (analysis unknown) +
left of 2275 1tʃɨe 'headgear; hat; cap' (a synonym of 2529; see 164 below)
The last two tʃ-words must be cognate and 2tʃɛ 'to wear' may also be related.
2275 looks like 'person' plus 0124 2no < *noH 'brain' (cognate to Old Chinese 腦 *nuʔ 'id.'). It was analyzed as 2292 plus 0124:
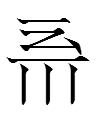
163: 2738 has 'water' on the left and shares a right side with
=
0820 2dʒɨə̣ 'red'
which has 'red' on the right side (from 糸 of Chinese 紅 'red'?). 2738 and 0820 form the phrase
2diẽ-2dʒɨə̣ 'red cloud'; 'snow cloud' (!)
I presume the creator of these tangraphs had that phrase in mind when creating this pair of tangraphs. Tangraphs with shared components often represent halves of single words, but both 2738 and 0820 are independent words.
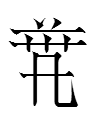
164: 2529 2piụ has a unique right-hand radical (alphacode: gia):
Like all ヒ-shaped radicals, it cannot stand alone. The left-hand radical(s) (alphacode: balbia) may be a phonetic based on a *p(h)u-type sinograph like 不, 步, 甫, or 布. The latter is already the basis of
'fear' < 怖
=
+
3856 1piụ first half of 1piụ-2piaʳ 'incomplete'; partial reduplication of 3855 =
3855 2piaʳ 'incomplete' +
2529 2piụ 'hat; crown' (phonetic)
<
?
3406 2piụ 'palace' (with a right half from 'master' including 'sage'?)
which are (nearly) homophonous with 2529 as well as three nonhomophones:
| Tangraph | Li Fanwen number | Reading | Gloss | Notes |
  |
0202/0162 | 1khiã | transcription of Chinese 犍, 乾, 謙 | 'sound' on left; right from homophone 2178 2khiã 'enemy'; 0162 and 2178 are the only tangraphs with the right-hand radical col |
 |
2527 | 2nee | imperial court | 'sage' on right; < Chinese 內 'inside; imperial court' |
 |
3401 | 2ɣɨa | canopy; curtain; carriage | does the top radical cou symbolize a cover? |
165: In Homophones, 0542 2lɨuu 'beautiful' is clarified by its lookalike 0541 2ʃwɨo 'dignified' and vice versa:
They form a word
2ʃwɨo-2lɨuu
that Grinstead (1972: 28) glossed as 'adornment' (Skt alaṃkaara), Kychanov (2006: 430) glossed as 'honest; straightforward', and Li Fanwen (2008: 93, 369) glossed as 'beautiful'.
Like 2738 and 0820 in 'red cloud' above, both tangraphs share components even though they represent independent words.
Grinstead (1972: 28) regarded both left-hand radicals
bum and fik
as being "connected with 'finery', 'ornament'".
The 'person' on their right in 541 and 542 is presumably from the same tangraphic source.
6.20.2:41: One possible source of 'person' in 541 and 542 is
2228 1pi 'majestic; glorious'
which is defined in Tangraphic Sea as
2ʃwɨo-2lɨuu 2vạ-2lõ
'̣[having] beauty [that is] vast' (?)
10.6.18.23:55: THE GOLDEN GUIDE: LINE 32: TANGRAPHS 156-160
Did the Tangut people really need their government to lecture them about sizes? I'm guessing they didn't. Click on the three-digit tangraph numbers for notes.
| Tangraph number | 156 | 157 | 158 | 159 | 160 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 3830 | 3508 | 3798 | 2893 | 2149 |
| My reconstructed pronunciation | 2nie | 2bi | 1tsẽ | 2khwe | 1dʒɨu |
| Tangraph gloss | king; prince; ruler | minister | small | large | to show; to declare; to clarify |
| Word | size | ||||
| Translation | The ruler and his ministers clarify [matters?] large and small. | ||||
156: 3830 'king' has no known analysis. Its tangraph
alphacode: cuewen
always reminded me of 席 'seat'. Did the Tangut based 3830 'king' on 席 'seat' with 'throne' in mind?
(6.19.11:36: The elements under the 广-like strokes [cue] comprise an independent tangraph
=
+
0151, of course, has an analysis with 4425:4425 1ʃɨu 'cool; cold' (alphacode: boxhoo = wun) =
top of 4250 1si 'wood' (alphacode: boxdexdexcok) +
bottom of 0151 1ʃɨuu 'cool; cold' (obviously cognate; alphacode fexhoo)
=
+
fexhoo = fexbilbabil + boxhoo
The top of 0151 is supposedly from 0124 2lɨụ < *S-luH, possibly cognate to Old Chinese 首 *hluʔ 'head'. 首 was *ʃu in Tangut period northwestern Chinese, so the tangraph for its translation could have been a cryptophonetic for Tangut 1ʃɨuu 'cool; cold'.
4425 and 0151 have no phonetic or semantic relationship to 3830 2nie 'king', so I suspect the line configuration of 4425 was recycled for its vague similarity to the non-广 components of 席 'seat'.
4425 and 0151 may be derived from a sinograph with a *ʃu-like reading: e.g., 束, 尗 = 叔 minus its right side, 㐬 = 疏 minus its left side, 庶 minus 丿 on the left, etc. At the moment I think 㐬 is the most likely candidate with box 'wood' on top as a second phonetic corresponding to the 木 'wood'-like shape of a second *ʃu sinograph 术 or 朮. Removing 'wood' from 4425 results in the radical
alphacode: hoo
which Nishida [1966: 244] identified as 'rare' [derived from 禾 or 希 of 稀 'rare'?]
The tangraph for 'seat'
0150 1giụ
may be another derivative of 席 'seat' minus 广.)
157: 3508 'minister' also has no known analysis. It looks like the tangraph 3485 1lạ 'hand; arm' plus the radical 'hand; arm' - cf. the English expression 'right-hand man'.
+
(6.19.23:56: Replacing the 'hand' radical on the right with 'man' results in
2384 2mieʳ 'minister' [I can't figure out how this is different from 3508 'minister'.]
Political terminology is often borrowed, but I assume 2nie, 2bi, and 2mieʳ are all native words. I'm surprised Chinese terms weren't borrowed. Could these be recycled old tribal titles?)
158: 3798 'small' is 'person' from 0502 1ziəʳ 'small' plus 5815 1tsiə 'small':
+
Could 3798 1tsẽ 'small' and 5815 1tsiə 'small' share a root? 0502 1ziəʳ 'small' may be from *rɯ-tsə with an *r-prefix and root initial lenition.
The nasal vowel of 1tsẽ is dubious. I reconstruct one for rhyme 41 -ẽ only because Gong grouped it with rhymes 42 (my -ɛ̃) and 43 (my -ɨẽ/-iẽ). I cannot find any Chinese or Tibetan transcriptive evidence for nasality. Gong reconstructed R41-43 without nasality whereas Arakawa reconstructed nasality for R42-43:
| Rhyme | My grade | My reconstruction | Gong grade | Gong | Arakawa grade | Arakawa |
| 41 | I | -ẽ | I | -əj | IIIb | -e:' |
| 42 | II | -ɛ̃ | II | -iəj | I | -en |
| 43 | III/IV | -ɨẽ/-iẽ | III | -jɨj | II | -yen |
159: 2893 2khwe 'large' is borrowed from Chinese 魁, which is not the normal word for 'large'. Perhaps it was a colloquial word in Tangut period northwestern Chinese. Its analysis includes its mirror image:
Reversing its radicals results in
(6.19.14:00: 4449 in turn is derived from 4456/4457 plus 2705 2biiʳ 'to help':
+
2893 2khwe 'large =
right of 4456 2tha /4457 2liẹ 'large' +
left of 4449 2miaa 'large'
=
What does the right side of 'help' do besides help distinguish 4449 from 4425 1ʃɨu 'cool; cold'?)
I bet the analysis of 4456/4449 contains 2893 and/or 4449.
4456/4457 has two Li Fanwen numbers for its two readings.
2tha 'large' is borrowed from Tangut period northwestern Chinese 大 *tha. Li Fanwen lists the 2tha reading for the word
2tha-2xa 'wild goose'
(the second half is a phonetic 1xa [water + hand] plus an abbreviation of 2262 'bird'; although 2tha is from Chinese; 2xa is not)
I don't know if 4456/4457 was read as 2tha in other contexts.
(6.19.13:57: There is another 2tha
4455
for transcribing Tangut period northwestern Chinese 大佗 *tha and 道 *thaw. Why not simply write 大 *tha 'large' consistently as 4456 2tha? Was 4455 originally meant to represent Chinese *tha not meaning 'large'?)
2liẹ is the much more common native reading of 4457 used in the name of the Tangut state:
1phɔ̃ 2bie 2lhiẹ 2liẹ 'The Great State of the White and High' (lit. 'white high state great')
3798-2893 'small-large' form a compound
'size'
which is similar in structure to Chinese 大小 'size' (< 'big' + 'small') though the order of roots is reversed.
160: 2149 'to clarify' doesn't contain 'clear' or 'light'. The Tangraphic Sea analyzes it as 2503 1kəụ 'behind' (from line 16) plus 2149 1ʃɨ 'ahead' (from line 15):
+
10.6.18.20:24: STUDY-ING THE TANGUT -ƐW : CHINESE *-ÆW DISCREPANCY
In the previous entry, I noted the vocalic mismatch between
3320 1ɣɛw 'to study'
and its source Middle Chinese 學 *ɣæwk. If Tangut had the vowel æ, why wasn't MC *ɣæwk borrowed as 1ɣæw? Here are two possible answers.
Scenario 1: Imperfect vowel borrowingMy current Tangut reconstruction has no rhymes of the type -Aw. If pre-Tangut had *-aw, that rhyme may have merged with other rhymes: e.g.,
Development of pre-Tangut *-aw
| Grade | Early pre-Tangut | Late pre-Tangut | Tangut |
| I | *(Cʌ-)Caw | *Caw | Cew (and/or Co?) |
| II | *(Cʌ-)Craw | *Cæw | Cɛw (and/or Cɔ?) |
| III | *Cɯ-Caw | *Cɨaw | Cɨew (and/or Cɨo?) |
| IV | *Ciaw | Ciew (and/or Cio?) |
The Grade III/IV split is conditioned by initials: v-, alveopalatals, and (velar?) l- condition Grade III and all other initials condition Grade IV.
The shift of *-æw to *-ɛw also occurred in southern Early Middle Chinese dialects which had no contact with Tangut. A similar shift might have also occurred in northwestern Middle Chinese. This NWMC rhyme was borrowed into Japanese as Kan-on -au but was later transcribed in Tibetan as -eHu.
Tangut -Ew and -O type rhymes may also partly originate from pre-Tangut *-ew and *-o:Development of pre-Tangut *-ew
| Grade | Pre-Tangut | Tangut |
| I | *(Cʌ-)Cew | Cew |
| II | *(Cʌ-)Crew | Cɛw |
| III | *Cɯ-Cew | Cɨew |
| IV | Ciew |
Development of pre-Tangut *-o
| Grade | Pre-Tangut | Tangut |
| I | *(Cʌ-)Co | Co |
| II | *(Cʌ-)Cro | Cɔ |
| III | *Cɯ-Co | Cɨo |
| IV | Cio |
If *-æw had already become -ɛw or -ɔ by the time Chinese *ɣæwk was borrowed, then ɣɛw was the closest matching Tangut syllable. (For simplicity I will assume Tangut had already lost final stops instead of speculating on the relative chronology of stop coda loss and *-æw merger.)
Scenario 2: Perfect vowel borrowing followed by raisingChinese *ɣæwk could have been borrowed before *-æw raised to -ɛw:
Chinese *ɣæwk > Pre-Tangut *ɣæw > Tangut 1ɣɛw
I am just making preliminary hypotheses. It may turn out that the two words for 'study' are not related, or that Tangut 1ɣɛw is actually a borrowing from Chinese
教 *kæw > *kɛw 'to teach'
(Tibetan transcriptions: keHu and even geHu with g-!)
plus a prefix that altered the meaning and conditioned the lenition of *k-.
If 1ɣɛw is from 學 *ɣæwk, it must have been borrowed before the shift of *-ɛw to *-ɔ in northwestern Chinese. A later stratum of borrowings and transcriptions indicate an o-like vowel in that Chinese rhyme: e.g.,
5353 2khɔɔ 'skillful; ingenious' < 巧 *khɔ < Middle Chinese *khæwʔ
(from the previous line; the Tangut long vowel requires explanation)

4196 pɔ 'to burst' < 爆 *pɔ < Middle Chinese *pæwh
transcribed 包苞 *pɔ < MC *pæw and 鮑 *phɔ < MC *bæwh
The nasalized counterpart of that Chinese rhyme also corresponded to Tangut -ɔ(ɔ):
5747 2ʃɔɔ 'twin; pair' < 雙 *ʃɔ̃ < Middle Chinese *ʂæwŋ
(I would expect Tangut short nasal -ɔ̃ instead of long oral -ɔɔ.)
The o-like quality of rhymes 52 and 55 can be confirmed with Tibetan transcriptions:
| Rhyme | Tangut | Tibetan transcriptions (Tai 2008: 218-219) |
| 52 | -ɔ | -uH x 2, -a x 1 (Nishida 1964: 56 and Sofronov 1968 II: 34 also found a transcription -oH) |
| 55 (Grade II) | -ɔɔ | -o x 4, -oH x 1, -a x 1 |
The -a of R52 and R55 may either be an attempt to write ɔ or be the default vowel due to a missing or lost o.
Grade III -ɨo and Grade IV -io are also included in rhyme 55. The reason for this conflation is unclear. Perhaps those higher grade rhymes were phonetically [ɨɔ] and [iɔ] with the second vowel lowering to dissimilate from the first high vowel.
10.6.17.8:45: THE GOLDEN GUIDE: LINE 31: TANGRAPHS 151-155
Once again, I have converted Tangut object-verb sequences into English subject-verb sequences to avoid adding a subject absent in the Tangut original.
| Tangraph number | 151 | 152 | 153 | 154 | 155 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 2937 | 0720 | 1118 | 5604 | 3320 |
| My reconstructed pronunciation | 2lhiẹ | 2mii | 2dziəə | 0dʒɨə | 1ɣɛw |
| Tangraph gloss | country; nation | to administer; to manage | to practice; to exercise; to review; to teach; order; to change | skill; art | to study; to learn |
| Word | |||||
| Translation | State administration is taught; arts are learned; | ||||
151: 2937 has a very similar-looking clarifier* tangraph
2029 2lõ 'country; territory; world'
in Homophones. Could 2029 and 2937 be cognates? Why do they both have
'water'?
Is that radical a reference to the (four) seas? See line 29.
The right side of 2937 is a cryptophonetic
1kwo 'the surname 郭; transcription of Tangut period northwestern Chinese *ku, *kwo, kwõ (Why such a wide range? I'd expect more precision from Tangut scribes who were bilingual in Chinese. The shape of the tangraph may be based on TPNWC 賈 *ku. )
which sounds like Tangut period northwestern Chinese 國 *kwo 'country'.
The right side of 2029 (alphacode qes) resembles 4602 'eight' (alphacode jeu) from line 30 with a line on top:
qes '?' and jeu 'eight'
I can't quickly find any common phonetic or semantic denominator among tangraphs with qes.
152: No analysis of 0720 is known and I have no idea what any of its parts (alphacodes: hix, por, dom) mean. The right two-thirds might be from
2620 2nwi 'to be able'
or
but maybe it is from two tangraphs.
5353 2khɔɔ 'skillful; ingenious' < Chinese 巧
I regard 2937-0720 as a compound noun 'state administration' that is the object of the following verb. Another possibility is that 2937 'state' is the object of a compound verb 0720-1118 'to administer' (?), but I can't find such a compound verb in Kychanov (2006: ) or Li Fanwen (2008: ).
153: Li Fanwen (2008: 187) identified 1118 2dziəə 'to practice' as a borrowing of Chinese 習, but the latter was Middle Chinese *zɨp with *z-, not *dz-. Does Tangut dz- imply that Tangut had *dz- but not *z- several centuries earlier?
1118 also means 令 'order' and 化 'to change'. These may be native Tangut words that are homophonous with the Chinese loanword 'to practice' and were written with the same tangraph.
I follow Kychanov (2006: 381) in translating 1118 as 教 'to teach' instead of 'to practice' since practicing state administration (as opposed to doing it for real) sounds strange. (6.17.19:34: Oddly Kychanov includes 習 'to practice' as a Chinese definition of 1118 even though his Russian and English definitions have no equivalent.)
154: The left side of 5604 (alphacode yax)
should not be confused with
5604 is the source of the right side of
4861 2ziọ 'time' (alphacode yea)
=
+
3949 1thəu 'skill; artistry' whose left side is a phonetic 1thəu 'talk' (with 'language' on the right)
but other tangraphs with that right-hand component (alphacode dei) do not have 'skillful' meanings.
155: Gong identified 3320 1ɣɛw as a loan from Middle Chinese 學 *ɣæwk, though the vowels don't quite match.
It is not surprising that the Tangut borrowed academic words from Chinese since they only had a very short history of literacy. 3320 and 1118 even combine to form a syllable-by-syllable equivalent of Chinese 學習 'to learn':
1ɣɛw-2dziəə 'to learn'
The right side of 1118 is derived from 3320
and the rest is from 0980 1lɨooʳ full; excessive'. (But can anyone ever have an excess of learning?)
+
*In Homophones, each entry tangraph has one or two clarifier tangraphs which give the reader some idea of its meaning.
If there were an English version of Homophones, and each syllable had its own character, the entry for cran would look something like this:
CRAN
RY BER
Cran by itself is meaningless in English, but in context (cranberry) it makes sense. Note that clarifiers are read from right to left. Hence berry appears as RY BER.
2937 'country' appears in Homophones with its clarifier 2029 'country' beneath it:
10.6.16.3:09: THE GOLDEN GUIDE: LINE 30: TANGRAPHS 146-150
141-142 'four seas' in the previous line correspond to 146-147 'eight mountains' in this line. Do 'eight mountains' represent the Tangut people?
| Tangraph number | 146 | 147 | 148 | 149 | 150 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 4602 | 4871 | 0441 | 4950 | 0800 |
| My reconstructed pronunciation | 1ʔiaʳ | 1ŋəʳ | 1swiə | 2riʳ | 1dzee |
| Tangraph gloss | eight | mountain | who | with | to struggle; to fight for |
| Word | |||||
| Translation | With whom do the eight mountains struggle? | ||||
146 has the bizarre analysis
4778 1tʃiạ 'seven' without its top
Since 'eight' and 'seven' nearly rhyme, I long thought the top of seven (alphacode: biozoxzox) represented tʃ-, but it doesn't occur in any other tangraphs. Even the element 人 zox is unique to 'seven'.
Although I think the initial of 'eight' was probably j- rather than ʔ- (cf. Written Tibetan brgyad 'eight'), I have mechanically followed Sofronov and Gong above and will continue to do so until I get around to looking into whether ʔ- is necessary. At the moment I am suspicious of ʔi- = Gong's ·j- and Sofronov's ·i̭- because neither Gong nor Sofronov reconstruct a simple j-. I have never heard of a language with ʔj- but without j- or of a sound change j- > ʔj-.
Tibetan transcriptions cannot resolve this issue since there is no way to write ʔj- in Tibetan. I would expect the Tibetan transcription of 'eight' to be ya, but it was transcribed as rye (with initial r- and -e), na (with initial n- and no -y-), and -e (illegible first consonant).
147 vaguely resembles Chinese 登 'to climb', an action associated with mountains. Although its analysis makes it seem complex
+
4871 1ŋəʳ 'mountain' = 4860 1ʃɨi 'immortal' + 4879 1ŋəʳ 'griddle'
The Tangraphic Sea analysis of 4860 shows that it clearly a calque of Chinese 仙 'immortal' < 亻 'person' + 山 'mountain' and hence must postdate 4871 'mountain'.
4860 1ʃɨi 'immortal' = 4871 1ŋəʳ 'mountain' + 1886 2dzwio 'person'
1ʃɨi resembles Tangut period northwestern Chinese 仙 *sjã < Middle Chinese *sien but the initial and final don't quite match.
4871 'mountain' must be phonetic in 4879 'griddle' rather than the other way around. The Tangraphic Sea derives 4879 from 4871:
=
+
4879 1ŋəʳ 'griddle' = 4814 2riəʳ 'container for cooking' + 4871 1ŋəʳ (phonetic)
148 'who' has 'language' on the left like its Chinese equivalent 誰.
+
0441 1swiə 'who' = 1045 2dạ 'speech; word' + 2082 1ʔiəʳ 'to ask'
The right of 1045 changes slightly when on the left of a tangraph.
1swiə 'who' is vaguely similar to Mandarin shei ~ shui 'who', but the initial and final correspondences are irregular.
2082 has a circular analysis:
=
+
2082 1ʔiəʳ 'to ask' = 0491 lɨọ 'how' + 0441 1swiə 'who'
149 'with' is a postposition forming a phrase with 148 'who': 'who with' = 'with whom'.
149 was analyzed as
+
4950 2riʳ 'with' = 4989 1vɨị 'people one is close to' + 2458 2riʳ 'before' (phonetic; one 'person' before another?)
4989 in turn was analyzed as being from 4950 plus 0456 tiạ 'answer' (why?)
Li Fanwen (2008: 77) derived 0456 tiạ 'answer' from Chinese 答 (Tangut period *ta < Middle Chinese *təp) even though it had no *-i-. Could the -i- be from a presyllable *Sɯ-?
*Sɯ-ta > *Sɯ-tia > *Stia > *ttia > *ttiạ > tiạ
150 1dzee 'to struggle' was analyzed as 1245 ʔie 'self' (why?) + 5455:
+
5455 is the second half of the reduplicative word
2lwɨẹ-2lwɨị 'to strive for':
whose tangraphs contain different arrangements of the same components (bue 'hold', pik 'hand', and ヒ cin).
150 1dzee 'to struggle' may be from *N-tsee and be cognate to Written Tibetan Hdzing-ba 'to struggle' and Old Chinese 爭 *rtseŋ 'to quarrel'. But why doesn't the Tangut word have a nasalized vowel?
10.6.15.8:40: THE GOLDEN GUIDE: LINE 29: TANGRAPHS 141-145
This line is ironic considering that there were no seas in the landlocked Tangut Empire.
| Tangraph number | 141 | 142 | 143 | 144 | 145 |
| Tangraph |  |
 |
 |
|
 |
| Li Fanwen number | 2205 | 0661 | 1326 | 3266 | 0556 |
| My reconstructed pronunciation | 1lɨəəʳ | 2ŋiõ | 1kiə | 2dziu | 2liẹ |
| Tangraph gloss | four | sea | perfective prefix (inward motion) | master | awake |
| Word | the four seas; the whole world | protect | |||
| Translation | The four seas are protected; | ||||
The passive is not in the original and is a copout to avoid specifying the unnamed subject in English.
141-142 is a calque of Chinese 四海, literally 'four seas'.
141 is cognate to Old Chinese 四 *slis 'four'. The boxlike right half may be based on 四. I examined its dubious Tangraphic Sea analysis almost a month ago.
142 'sea' is not a borrowing from Chinese 海 *xej or Written Tibetan rgya-mtsho. Where could this word for a foreign concept have come from?
One might expect 142 to consist of, say, 'water' plus 'big', but it has a partly circular analysis:
+
0661 2ŋiõ 'sea' =
4828 2ŋiõ 'the surname Ngion' (uncertain if it can stand alone) +
2670 2so 'yang principle'
Did the Tangut consider seas to be 'yang' - and mountains (see 147 below) to be 'yin'?
4828 must be derived from 142 rather than the other way around. Its analysis contains 142:
+
4828 = 4940 2ʔiə (transcription tangraph) + 661
The use of the inward motion perfective prefix 143 before the verb 144-145 'protect' contrasts with English keep out: e.g., keeping invaders out. Did the Tangut view protection as keeping in? Keeping something intact? Keeping secrets inside?
The analysis of 143 (which appears to be 1153 1dʒɨə 'skin' x 2 makes no sense:
+
1326 1kiə = 1153 + 0795 2riə 'generic directional prefix'
What is 'skin' doing in 0795, which doesn't even indicate the same direction as 1326?
The optative prefix corresponding to 1326 has a 'skinless' tangraph that looks like 1kie 'insect' (phonetic) plus 'light' (why?):
2219 1kie
144 'master' has 'person' on the left and 'sage' on the bottom right. Its analysis is part of a chain:
+
3266 2dziu 'master' =
3148 first half of 2dziu-2nie 'weapon' +
1293 1və 'master'
3148 first half of 2dziu-2nie 'weapon' =
3266 2dziu 'master' +
2781 second half of 2dziu-2nie 'weapon'
=
+
1293 1və 'master' =
0545 1dʒwɨu 'person' +
3266 2dziu 'master'
144 2dziu looks like the Pinyin romanization zhu for 主 'master' but the two are unrelated. In the Tangut period northwestern Chinese dialect, 主 was something like *tʃy with *tʃ-, not *dz-.
145 has a rare left radical (alphacode qar) that I want to investigate later.10.6.14.3:06: THE GOLDEN GUIDE: LINES 27-28: TANGRAPHS 131-140
These two lines have three words for 'many'. I'll mention even more words for 'many' below.
The first of many names to appear in the Golden Guide is the Tangut imperial surname:
| Tangraph number | 131 | 132 | 133 | 134 | 135 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 2339 | 1903 | 2888 | 3017 | 5414 |
| My reconstructed pronunciation | 2ŋwəi | 1mi | 2mə | 1die | 2reʳ |
| Tangraph gloss | first syllable of at least four surnames | second syllable of the imperial surname | surname; first syllable of at least two surnames | kind; type; group; category; class; section | many; much; more |
| Word | Ngwi-mi | tribe; race; clan | |||
| Translation | The tribes of the Ngwi-mi are myriad; | ||||
The tribes ruled by the Ngwi-mi constitute the Tangut people.
Both 131 and 132 contain
'sage'
which also appeared in
from the previous line.
5306 1dzwiə 'emperor'
The analysis of 131 is unknown but I bet it's
+
2339 2ŋwəi = 2544 ʃɨẽ 'sage' (semantic) + 2139 2ŋwəi 'a kind of bird'
2139 has the analysis
=
+
2139 2ŋwəi 'a kind of bird' = 2262 dʒwɨõ 'bird' (semantic) + 2339 2ŋwəi (phonetic)
I have no idea why the right two-thirds of 2139 and 2339 is associated with the syllable 2ŋwəi. No similar-looking sinograph comes to mind.
132 has a surprising phonetic:
+
The second half of the imperial surname was written as ... 'not sage'?1903 1mi = 1906 1mi 'not' (phonetic) + 2544 ʃɨẽ 'sage' (semantic)
The analysis of 133 is unknown, but both halves ('person' and 'tribe') appear in analyses for other surname tangraphs.
134 'kind; type' is from 1543 1mioʳ 'true' + 1608 2lew 'same':
+
Those of the same type are truly the same. The Tangraphic Sea defines 134 as
1vɨa 2gi 1diẹ 2lew 1swəu
'father son type same similarity'
'the similarity of the same type of fathers and sons'
who belong to the same category (family).
The analysis of 135 'many' is unknown. It shares its right two-thirds (alphacode doecin) with
0747 2miaa, 0790 2ŋa, 2753 lheew
which also mean 'many' and have unknown.analyses.
| Tangraph number | 136 | 137 | 138 | 139 | 140 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 0607 | 3119 | 5049 | 1567 | 2935 |
| My reconstructed pronunciation | 1miəʳ | 1ʔi | 1vɨa | 2gi | 2lạ |
| Tangraph gloss | people; tribe | many; numerous | father | son | many; thick; dense; mass; thicket; dense bushes |
| Word | |||||
| Translation | The people are numerous; fathers and sons are packed. | ||||
136 1miəʳ 'people' has 'sage' on the right and is part of the mi-word family.along with
2344 2mi 'Tangut' and 3818 2mieʳ 'person suffix' from line 25
137 is part of an analytic chain leading back to 135:
+
3119 1ʔi 'many' = 2753 2lheew 'to have; many' + 0930 1diu 'to have'
+
2753 2lheew 'to have; many' = 3234 1phə (second half of phə-biẹ 'rich man') + 5414 2reʳ 'many'
Note that the left side of 2753 (alphacode ger) is not to be confused with 2544 'sage' (alphacode geo). The penultimate stroke of 2544/geo is shorter than that of ger.
138 'father' was analyzed as
+
top and bottom right of 5031 1bə 'father of the black-headed (one of the two tribes of Tangut) +
all of 2544 ʃɨẽ 'sage' +
right of 3671 1nie, half of 1nie-2riaʳ 'father':
But I suspect 138 predates secondary paternal tangraphs like 5031 and 3671 but postdates 'sage'.
The initial of 1vɨa is probably the result of medial lenition:
*Cɯ-pa > *Cɯ-ba > *Cɯ-βa > *Cɯ-βɨa > *βɨa > vɨa
139 'son' has
'child' < Chinese 子 and/or 兒?
on the left and has the analysis
+
1567 2gi 'son' =
2349 1ziə̣ 'son' (of heaven; i.e., emperor; < Chn *tsɨ 'son' with initial lenition and vowel tensing?) +
3300 2diu 'to give birth to; to bear'
140 2lạ 'thick; dense' is a tonal variant of 2700 1lạ 'thick' and its tangraph is probably derived from 2700 plus 0747 2miaa 'many':
+
?
I translated 140 as 'packed' since 'fathers and sons are thick/dense' can mean that they are unintelligent.
10.6.13.20:23: TANGRAPHIC RADICALS 6: SMALLER THAN SMALL
In my previous post, I mentioned the locative suffix 1kha 'in' which has a slightly odd analysis. Notice that the right radicals of 1kha and 1845 (dua and gux 'small') do not match:
=
+
guxbordua = guxges + bosborgux (not bosbordua!)
5993 1kha = 5901 2lo 'hole' (semantic; 'small' + 'earth'; something with an interior?) + 1845 0khạ 'sound' ̣(used in expressions of the type 'no sound')
1845 is obviously phonetic in 5993, but why was it necessary to delete the bottom left stroke of gux 'small' in 5993? The sequence borgux is also in 5803, the first half of
so there is no requirement to change gux to dua after bor.
Moreover, there is also 6074, the last tangraph in Li Fanwen (2008: 952), a variant of 5993 with bor between two gux (not in the Mojikyo font):
+
+
Was 6074 the original tangraph for 'in' (representing something in between two things)? This very basic tangraph guxborgux would then abbreviated into a phonetic borgux in the lower-frequency tangraphs 1845 and 5803. Soon afterward 6074 guxborgux was abbreviated to 5993 guxbordua. Tangraphic Sea has 5993 but at least one edition of Homophones has 6074. (I can't tell whether Precious Rhymes of the Tangraphic Sea and the other edition of Homophones reproduced in Sofronov 1968 has 5993 or 6074.)
There is one other odd thing about 5993/6074. In Tangraphic Sea, it is listed in the surviving level tone volume rather than the missing rising tone volume, but in the mostly complete Precious Rhymes of the Tangraphic Sea, it is listed under rising tone rhyme 14 implying 2kha instead of 1kha. Did 5993/6074 have two readings? Could 2kha be a tone sandhi reading? There is a simpler explanation: Precious Rhymes does not include 5803 2kha, and the scribe accidentally wrote 5993 instead of 5803.
*2kha is probably cognate to Old Chinese 苦 khaʔ < *qhaʔ 'bitter', though I wouldn't expect their vowels to match since I hypothesized that pre-Tangut *a became Grade II æ rather than Grade I a after uvulars:
*qhaH > 2khæ, not 2kha
Did a presyllable or preinitial condition Grade I, or is my hypothesis simply wrong?
10.6.13.18:36: WHAT IS THE MOST GORGEOUS HORSE?
0516 2tshiẹ 'gorgeous' from the previous post is the second half of the phrase or word
2kwɛ(-)2tshiẹ
I don't know if the first half can occur independently or not. I assume that at one point it was a word, but I can't find any instances of it by itself.
Native Tangut dictionaries have definitions for all syllables regardless of whether they were independent words or not. Although no formal definition for 0770 2kwɛ has survived, an annotation added to the D version of Homophones says 2kwɛ is
1rieʳ-1kha 1lwɨẹ
'horse-among ?'
1kha is a locative suffix, so: X-1kha means 'in X; among X'.
Li Fanwen (2008: 131) translated the last tangraph as 良 'good' in his translation of that note, but his definition for 2702 1lwɨẹ is 'ignorant; muddle-headed' (p. 443). The structure of 2702 implies a negative meaning:
=
+
2702 1lwɨẹ = 1918 1mi 'not' + 2784 1dʒwɨo 'bright; clever'
The Tangraphic Sea definition of 2702 is
...

1məuʳ ... 1mi 1bɨu
'stupid ... not bright'.
('stupid' is an extended use of its homophone 'black')
So is a 2kwɛ the best of horses or the dumbest of horses? In spite of the annotation, I assume it's the former because
2kwɛ(-)2tshiẹ
is the Tangut translation of Chinese
麒麟
Although tangraphy is regarded as more complex than sinography, 2kwɛ(-)2tshiẹ contains 11 + 9 = 20 strokes, whereas 麒麟 contains slightly more than twice as many strokes: 19 + 23 = 42.
The sinographs for 'qilin' have the radical 鹿 'deer' plus the phonetics 其 qi and 粦 lin, whereas the tangraphs have
on the left plus radicals of unknown function. None of the other tangraphs sharing the non-'horse' parts of 2kwɛ sound like it. I cannot find any tangraph with 'person' with a reading like tshie or tshiẹ.
'horse' (< Chinese 馬)
10.6.13.12:41: TANGRAPHIC RADICALS 5: WORRYING ABOUT WHERE WAR CAME FROM
The last tangraph in line 25 of the Golden Guide was
3678 2to 'to arise'
which had the rare radical
appearing in only two other tangraphs. Do those tangraphs sound or meaning anything like 2to 'arise'?
alphacode: war
=
+
2634 1dʒwɨõ 'to publicize' = 2639 1miee 'name' + 3678
is obviously a semantic compound: to publicize is to raise someone's name.
1miee may be a native word cognate to Old Chinese 名 *meŋ 'name'. If it were a borrowing from Tangut period northwestern Chinese *mjẽ, I would expect a Tangut nasal vowel.
5576 in turn is in the analysis of 3678, which takes us back to where we started from:
=
+
5576 1kiəə 'spotted; striped' = 3678 + the 'horse' half of 0516 2tshiẹ 'gorgeous', whose other half is 'person' which could be an abbreviation of at least 1,186 other tangraphs
+
3678 2to = 3117 2to, second half of 2dzi-2to 'to cry; to weep' (with 'person' + 'water' + ?; phonetic) + 5576
Arising has nothing to do with spots or stripes, so I think 5576 is a derivative of 3678 rather than the other way around.
I suspect that the radical war may mean 'arise' by itself. But why couldn't war be an independent tangraph? Why did war need 'person' on the left? ('Person' is an extremely ambiguous phonetic since it could be from any of almost 1,200 sources.) And where did war come from? Could it be derived from its Chinese translation equivalent 發 or one of its 47 variants? This variant (业 + 丨+攵) is very close to war.

























































{kind=link}