'sound'
11.10.8.23:59: SINOGRAPHIC ALLOPHONES
I had hoped to find something resembling the tangraph (Tangut character) element
'sound'
in the Taiwanese government's dictionary of 106, sinographic (Chinese character) variants but I found four different variants of 音 'sound' instead - the "allophones" (other-sounds) of the title:
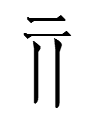
1. 十 overlapping 口 atop 冂 enclosing 缶 'jar' atop 木 'tree/wood'
十 + 口 + 冂 doesn't occur by itself
2. 亻 'person' + 丨 + 支 'branch' atop 金 'metal'
亻 + 丨 + 支 doesn't occur by itself
3. 立 atop 白 with 白 'white' instead of what looks like 日 'sun' on the bottom*
4. 糸+音 with (why? what does that have to do with sound?)
The first two are baffling combinations of seemingly random elements, none of which have any semantic or phonetic relationship with 音 'sound'. They almost remind me of Khitan or Jurchen large script characters, though they contain too many strokes (see Andrew West's statistics) and mostly consist of recognizable Chinese elements. How were they identified as variants of 音 'sound'? Context?
The third is pretty close to 音.
The fourth has an added radical whose function is unknown.
I'm surprised none resemble 言 'speech' even though Shuowen states that 音 is from 言 plus an additonal stroke 一.
*10.9.1:01: 音 'sound' looks like
立 'stand' atop 日 'sun'
though it is not related to either of those graphs.
Reversing those elements results in the spelling 日立 for the Japanese brand name Hitachi 'sun-standing'.
Inverting those elements results in 昱 'sunlight': 日 'sun' is semantic and 立 'stand' is phonetic and/or semantic (it's bright when the sun is 'standing': i.e., visible). 立 is li in Mandarin, which doesn't sound like 昱 yu at all. For my attempts to explain how 立 li could be phonetic in 昱 yu, see
10.9.1:49: I'd like to compare the sinographs for 'sound' with the graphs for its Khitan and Jurchen translations, but I don't even know what the Khitan word for 'sound' was, and I can only guess that the Jurchen word was similar to Manchu jilgan 'sound'.
The Tangut word for 'sound' is
=
+

1586 2ɣɪ̣ < *Sɯ-KriH or *Sɯ-QiH =
cf. Written Tibetan sgra (did the Tangut form undergo 'brightening': *sɯ-gra-H > 2ɣɪ̣?)
or Ronghong Qiang qəi and Mawo Qiang qɛj; see STEDT for more
'sound' = left of 1010 2ɣɪ 'breath'
+ right of 1685 1khĩ (transcription graph: e.g., for 琴 *khĩ 'stringed instrument' - something that makes sound)
I doubt the graphic analysis above from the Precious Rhymes of the Tangraphic Sea is correct because I presume that 'sound' was created before 'breath' (containing the element 'sound') and a transcription graph. I suspect that 'breath' was created after 'sound'. The Tangraphic Sea analysis of the transcription graph derives it from 'sound':
+
1685 1khĩ = 0269 1khiə 'to collect' (phonetic) + 1586 2ɣɪ 'sound' (semantic; also phonetic?)
Next: What's on the Right Side of 'Sound'?
11.10.7.23:40: A SOUND ORIG-YIN?
I've been assuming that the tangraph (Tangut character) element
'sound'
was somehow derived from the Chinese character 音 'sound' (now pronounced yin in Mandarin):
音 - 日 = 立; subtract the top dot of 立 and move the middle strokes to the bottom: 亓*.
On September 28, I found some cursive forms of 音 vaguely resembling the tangraphic element 'sound'. The closest match is one by 米芾 Mi Fu (1051-1107), who was born not long after tangraphy was said to be invented in 1036. Could similar simplifications have existed at least a few decades before Mi Fu's birth? So maybe I was on the right track even though I got the details wrong. The tangraphic element may be based on 音 as a whole, not just its top half.
*10.8.1:42: 亓 is also a Chinese simplification of 其 'its' (originally a drawing representing a word for 'basket'; recycled to write an abstract homophone). Other variants here.
10.8.1:48: I can't find a Tangut simplification of 'sound' in Kolokolov and Kychanov's (1966: 128-133) list of cursive forms. It would be interesting to see how this already simple shape could be reduced even further.
11.10.6.21:15: *GRUK TO GROK
I just realized that Old Chinese 學 *gruk 'to learn' sounds like Robert A. Heinlein's neologism grok (which turned 50 this year).
學 *gruk has a suffixed derivative 學 *gruk-s 'to teach'.
I wonder if these words are cognate to 教 *kraw-s 'to teach' which Schuessler (2007: 310) related to 效 ~ 傚 *N-kraw-s 'to imitate'.
Another possible cognate is 校 *graws < *N-kraw-s 'school'. Schuessler 2007: 536 rejected a connection between 教 and 校, deriving 'school' from an earlier homophone 校 'enclosure for animals'. These two etymologies
'school' < 'to teach'
'school' < 'enclosure for animals'
are mutually exclusive since 'to teach' cannot be derived from 'enclosure for animals' or vice versa.
The *gr- of 學 could be derived from a prefixed *N-kr. The emphasis in the syllable (indicated with underlining) could have been conditioned by a low vowel in the nasal prefix:But the rhymes *-uk and *-aw don't match. Or do they? What if *-uk is the zero- or schwa-grade counterpart of a-grade -aw plus a suffix -k?*Nʌ-kruk > *Nʌ-kruk > *N-kruk > *Ngruk > *gruk
*-(ə)w-k > *-u-k?
Are there other word families with *-u (< *-(ə)w) ~ *aw alternations?
Are there any word families with parallel *-i (< *-(ə)j) ~ *aj alternations?
What does the *-k do in 學 *gruk? I don't know. Schuessler (2007: 69) wrote,
So far, no perceptible function or meaning has been identified for this velar suffix [...] This addition may for the time being be referred to as 'k-extension'.
Is *-k real, or is it just a modern device to relate nearly homophonous words?
I suspect that a lot of Old Chinese affixes have no obvious simple function because they are mergers of earlier affixes with distinct vowels: e.g.,
*-k < *-ka, *-ki, *-ku, etc.
So *-k in one word may be from *-ka, *-k in another word from *-ki, etc. Similarly, the prefix *N- may be from *ma-, *ni-, *ŋu-, etc. If such massive mergers had occurred, these affixes may have already been fossilized in Old Chinese.
The heights of vowels in prefixes (but alas, not suffixes) may be recoverable from the presence or absence of 'emphasis' in the root syllable:
|
|
Low vowel root | High vowel root |
| Low vowel prefix | emphatic | |
| High vowel prefix | nonemphatic | |
| Prefix without vowel | emphatic | nonemphatic |
Prefixes that lost vowels or never had vowels match the (non)emphasis of the following root syllable.
The above table is also applicable to pre-Tangut which may have developed (and lost) an emphatic-nonemphatic distinction under the influence of its neighbor Chinese.
11.10.6.21:03: WHAT'S THE BIG DEAL ABOUT AN OLD CHICKEN? (OR, WHEN 'OLD' ISN'T OLD)
Tai languages used to be considered Sino-Tibetan in the West because they contain Chinese-like vocabulary. However, this Chinese-like vocabulary is generally not basic, and is almost wholly absent from their distant relatives, the Kra languages.
Nonetheless, let me suppose that Kra-Dai, the family containing both Kra and Tai, is Sino-Tibetan. Then
- its Chinese-like words should look extremely archaic (i.e., should lack innovations that occurred after Kra-Dai split off from Proto-Sino-Tibetan)
- Kra-Dai as a whole replaced its Sino-Tibetan basic vocabulary (with words from ... where?)
- Kra must have replaced even more Sino-Tibetan vocabulary (with words from ... where?)
But as I demonstrated in my last post, two Chinese-like words found through Kra-Dai, 'old' and 'chicken', contain Chinese innovations and hence are not "extremely archaic". They indicate that Proto-Kra-Dai and/or its later daughters borrowed the words in the early centuries AD. I think this scenario is more likely than the one I outlined above:
- the Chinese-like words in Kra-Dai contain innovations that occurred long after Chinese split off from Proto-Sino-Tibetan
- Kra-Dai as a whole retained its native basic vocabulary
- Kra kept even more native basic vocabulary than other branches: e.g, it retained the original Kra-Dai numerals whereas most other Kra-Dai languages (Lakkja, Kam-Sui, Be, and Tai but not Hlai) replaced them with Chinese numerals.
Does this necessarily mean that Chinese and Kra-Dai are unrelated? Not necessarily. Laurent Sagart proposed a Sino-Austronesian family containing Kra-Dai:
| Sino-Austronesian | ||
| Sino-Tibetan | Austronesian | |
| Chinese, Tibetan, Tangut, etc. | Kra-Dai | Other Austronesian languages |
This diagram is highly simpified. More details here.
My syntax professor, the late Stan Starosta, proposed an 'East Asian' family containing Austroasiatic and Hmong-Mien as well as Sino-Tibetan, Kra-Dai, and Austronesian. Although Tangut is often regarded as Qiangic, Starosta placed Tangut and Qiangic in separate subgroups of his 'Tibeto-Burman' (= Sino-Tibetan in conventional usage):
| Tibeto-Burman | ||
| Sino-Bodic | Himalayo-Burman | |
| Sinitic | Tangut-Bodish | Qiangic, etc. |
I have not yet read the 2005 volume in which Sagart and Starosta presented these proposals, though I did write an article critical of Sagart's 90s version of Sino-Austronesian. I am particularly curious about Starosta's decision to group Tangut and Tibetan (presumably part of his 'Bodish') together. As far as I know, no scholars other than Sagart and Starosta have adopted these macrophyla.
I am hesitant to support macrophyletic hypotheses like those in table 0.2 in the itntroduction to Sagart et al. (2005) because our knowledge of their component languages is still sketchy. Much remains to be done* and sadly much can never be done. Some aspects of language are lost without a trace: e.g., no one could reconstruct Latin declension on the basis of the modern Romance languages. Dixon (1987: 45) wrote,
Suppose that at some time in the future linguists try to reconstruct English, on the basis of a number of latter-day descendant languages (with no direct information on present-day English, or other historical records, and no information on other IE [Indo-European] languages). Would these linguists reconstruct a single form, unspecified for number, for second person, while first and third person pronouns have distinct singular and plural forms?
Irregularities in verbal and nominal inflection are at the present time steadily being eliminated (dreamed in place of dreamt, oxes rather than oxen); would any of these irregularities be retrievable [in the future]?
The incomplete information at hand - and within reach - may or may not enable us to find higher-level connections between established phyla.
*E.g., I would like to fully work out my reconstructions of Old Chinese, Tangut, and pre-Tangut.
11.10.5.23:45: DATING PROTO-KRA-DAI: THE CLUE OF THE OLD CHICKEN
When I was in elementary school, I was a fan of Nancy Drew mystery books with titles like The Clue of the Broken Locket. Nowadays I don't read about mysteries; I try to solve them.
The ages of proto-languages are generally a mystery to me. A lot of linguists give dates for proto-languages. I don't: e.g., I don't know when pre-Tangut was spoken. I take RMW Dixon's (1997: 48) stance:
Surely, the only really honest answer to questions about dating a proto-language is 'We don't know.'
However, the age of Proto-Kra-Dai might be an exception. In his 2000 dissertation, Weera Ostapirat listed 40 etyma shared throughout the Kra-Dai family. 2 etyma could be borrowings from Chinese:
'old': Early Old Chinese (Baxter & Sagart 2011) 舊 *N-kʷəʔ-s > Late Old Chinese *guh
root 久 *kʷəʔ 'long time'?
an LOC variant sans prefix *kuh (< EOC *kʷəʔ-s) borrowed into Proto-Kra-Dai? >
Proto-Kra (Ostapirat 2000: 236) *ku B
Proto-Hlai (Norquest 2007: 400) *khəwɦ (B)
Proto-Kam-Sui *kaai B
Proto-Tai (Li Fang-Kuei) *kəu B
also cf. Vietnamese cũ < *guh
Peiros derived the Kra-Dai forms from Starostin's Old Chinese 古 *kaaʔ (= my *kaʔ) but the vowel and final consonant do not match.
'chicken': Old Chinese 雞 *ke > Southern Late Old Chinese *kai
. borrowed into Proto-Kra-Dai? >
Proto-Kra (Ostapirat 2000: 224) *ki A
Proto-South Kra-Dai* (Norquest 2007: 401) *kəy (B)
Proto-Hlai (Norquest 2007: 401) *khəy (A) (not *khəyɦ (B)!)
All pre-Proto-Hlai word-initial consonants except for glottal stops (including nasals!) were aspirated: e.g., pre-PHL *k- > PHL *kh-.
Proto-Kam-Sui (Thurgood) *kaai B
Proto-Tai *kəi B
The B tones of Kam-Sui and Tai could be a Proto-Kam-Tai innovation (a suffixed fricative?)
also cf. Proto-Hmong-Mien (Downer 1982) *kai (tone not given in Schuessler 2007: 292)
but Schuessler (2007: 292) regarded these words and Proto-Viet-Muong *r-ka 'chicken' as onomatopoetic
The Kra-Dai forms have innovations absent from Early Old Chinese:
'old': Early OC *-ə > Late OC *-u after labiovelars and labials
occurred by the 3rd century AD judging from the rhyming data in Starostin (1989: 626)
Starostin's table (1989: 676) indicates this occurred after the Eastern Han (25-220 AD)
'chicken': breaking of 'emphatic' (pharyngealized) Early OC *-e [ɛˁ] to Southern Late OC *-ai
occurred by the 6th century AD judging from Sanghabhara's Sanskrit transcriptions
If the borrowings took place at the Proto-Kra-Dai level, then they tell us that Proto-Kra-Dai must postdate the aforementioned innovations and must be contemporary with Southern Late OC: i.e., be around 1500-1800 years old. But the Proto-Kra-Dai family is very diverse. Could such diversity have developed in less than two millennia? Maybe not.
Is it possible that 'old' and 'chicken' were borrowed multiple times into different Kra-Dai languages long after the breakup of Proto-Kra-Dai? But what are the odds that so many languages would borrow the same two words?
Proto-Kra *ki A is closer to EOC *ke than to SLOC *kai (which could have been borrowed as Proto-Kra *kai). Perhaps this *ki is an early loan and *kai-type forms are later loans.
Could the Chinese-internal sound changes in 'old' and 'chicken' have occurred much earlier than I thought? Or do the Kra-Dai forms actually reflect very early Chinese? Pulleyblank (1991: 47) reconstructed *-aj for the rhyme of 'chicken' at the earliest Old Chinese level. His *-əɰ for the rhyme class of 'old' (disregarding final consonants) is close to -əw and could have been borrowed into Proto-Kra-Dai as *-u.
*10.6.00:54: Norquest (2007: 16) grouped Hlai with Be and Tai, whereas Ostapirat (2000: 1) regarded Hlai as a separate branch:
Norquest's (2007) Kra-Dai family tree
| Kra-Dai | |||||
| North Kra-Dai | South Kra-Dai | ||||
| Northwest | Northeast | Southwest | Southeast | ||
| Kra | Kam-Sui | Lakkja | Tai | Be | Hlai |
Ostapirat's (2000) Kra-Dai family tree
| Kra-Dai | ||||
| Kra | Hlai | Kam-Tai | ||
| Be | Tai | Kam-Sui | ||
I don't know how Ostapirat would have classified Lakkja in 2000.
Be and Tai are together in both proposals and Kra is always apart from them, but the placement of Hlai and Kam-Sui differ. The shift of 'chicken' from tone category A to B could be an innovation distinguishing Kam-Tai from Kra and Hlai as in Ostapirat's hypothesis. However, the tone of a single word is not sufficient to define such a large subgroup.
11.10.4.20:54: LIMITED KNOWLEDGE ONLY GETS YOU *SO FAR
In my last entry, I had difficulty understanding why Ostapirat (2000: 8) regarded Proto-Kra *k-so 'to laugh' as a cognate of other Kra-Dai forms with different initials:
Baoding Hlai r-
Sanchong Sui k-
Thai h-
The key might be Li Fang-Kuei's Proto-Tai *xr- which is like both Sanchong Sui k- and Baoding Hlai r-. r- is like ʂ- which in turn is like the *-s- that Ostapirat reconstructed for Proto-Kra. Did medial Proto-Kra-Dai *-s- become *-r-?
The shift of intervocalic -s- to -r- occurred in Latin: e.g., arbosem (archaic) > arborem. Oscan remained at a -z- stage: e.g., O -azum : L -arum (Sihler 1995: 172).
Just now I discovered that both Thurgood and Peiros reconstructed Proto-Kam-Sui *kru 'to laugh' with an initial like the *kV-r- I proposed for Proto-Kam-Tai below:
Initials of 'to laugh' in Kra-Dai (?* = my uninformed reconstruction)
| Proto-Kra-Dai ?*kV-s- | |||
| Proto-Kra (Ostapirat) *k-s- | Proto-Hlai (Norquest) *ɾj- | Proto-Kam-Tai ?*kV-r- | |
| Proto-Kam-Sui (Thurgood, Peiros) *kr- | Proto-Tai (Li) *xr- | ||
| Baoding Hlai r- | Sanchong Sui k- | Thai h- | |
Norquest's (2007) Proto-Hlai *ɾjaaw has lost the presyllable.
Ostapirat reconstructed 'know' as Proto-Hlai *so, a near-homophone of *k-so 'to laugh'. Hlai and Kam-Tai languages have r in their words for 'to know'. Is the table below valid?
Treating s- and r-forms for 'to know' as a single Kra-Dai word family
| Proto-Kra-Dai ?*Cu-sU | |||
| Proto-Kra (Ostapirat) *so A | Proto-Hlai (Norquest) *Curɯɯ (A) | Proto-Kam-Tai ?*rU C | |
| Proto-Kam-Sui (Peiros) *ro C | Proto-Tai (Li) *ruo C, (Peiros) *ru C | ||
| Thai ruu C2 | |||
A represents tone class A (from final sonorants).
C represents tone class C (probably from final *-ʔ) and C2 is a subclass of C conditioned by earlier *voiced initials.
In this scenario, the presyllable *Cu- was retained in Proto-Hlai but lost in the other two branches.
Two problems:
1. Was *so A really Proto-Kra?I can't find any descendants of Proto-Kra *so 'to know' in the Central-Eastern Kra languages (Paha, Buyang, Pubiao) in Ostapirat (2000). If *so 'to know' is limited to the other branch of Kra (Ostapirat's 'South-Western'), then it can be reconstructed at the Proto-South-Western-Kra level but its presence at the Proto-Kra level is less certain:
| Proto-Kra ?*so A | |
| Proto-South-Western Kra *so A | (no Proto-Central-Eastern Kra descendant) |
If PSWK *so A is cognate to the Kam-Tai words, then *so A (with or without presyllables that would have left traces in Paha and Buyang) must have existed in Proto-Kra.
2. TonesPK *so A and sonorant-final Proto-Hlai *Curɯɯ belong to tone class A whereas the Kam-Tai forms belong to tone class C:
| Proto-Kra-Dai *? | ||
| Proto-Kra *A | Proto-Hlai *A | Proto-Kam-Tai *C (< ?*-ʔ) |
To complicate matters further, Vietnamese rõ [rɔɔ] 'to know', possibly a borrowing from a Tai language, has a tone implying Tai tone class B (probably from final *-h).
Clashing tone classes do not necessarily invalidate cognate status, but they do require an explanation. Perhaps the Proto-Kam-Tai form incorporated a suffix *-ʔ absent from the other two branches. If so, then I would reconstruct the Proto-Kra-Dai 'tone' class as A. (If Proto-Hlai had segments instead of tones, then PKD also had segments instead of tones. Hence the quotes around 'tone' when referring to PKD.)The unusual Vietnamese tone may reflect a fricative suffix (or a breathy tone) in the source Tai language. Another possibility is that at the time of borrowing, the Vietnamese ngã tone (< *-h) happened to resemble the *C tone (< *-ʔ) in the source Tai language. The latter is plausible since ngã has become a glottalized tone and the source Tai language could have had a glottalized reflex of the *C tone that originated from a final glottal stop.
Next: How 'Old' Is Proto-Kra-Dai?
11.10.3.22:05: WHAT'S *SO FUNNY ABOUT KNOWLEDGE?
In my last entry, I compiled a list of 18 words that Tangut shared with two Qiang languages and found that only one or two ('fish' and 'third person pronoun') were unique to their subgroup; the rest were generic Sino-Tibetan vocabulary.
In his 2000 PhD dissertation Proto-Kra, Weera Ostapirat compiled a list of
thirty etyma found exclusively in the Kra languages. The list is selected to include only etyma which have reflexes in at least three of the four subgroups [of Kra ...] While there is a possibility that future research may suggest some of these etyma as non-exclusively Kra, we believe that the majority of them will stand as valid subgrouping criteria. Note that the other branches [of the Kra-Dai family: Hlai and Kam-Tai] do not necessarily have the related forms among themselves for these etyma." (p. 9)
I would like to see a similar list of etyma found exclusively in Qiangic languages. Perhaps 'fish' would be on that list. STEDT lists th-words for third person pronouns in Tamangic (its group 2) and its group 6 (Lolo-Burmese and Naxi) and perhaps those words in turn are related to t- and tɕ- (from *t-?) forms elsewhere: e.g., Old Chinese 之 *tə 'this; third person object pronoun'.
Ostapirat also compiled
a list of 40 selected Kra-Dai etyma (including seventeen items from the Swadesh 100 basic word-list) to demonstrate that the Kra languages and the other Kra-Dai languages [e.g., Hlai, Sui, Thai] belong to the same linguistic stock. (p. 2)
I was initially puzzled by item 39 ('to laugh') on p. 8. The Kra words don't seem to be related to the non-Kra words, so why isn't 'to laugh' in Ostapirat's list of Kra-only etyma?
| Branch | Language | Form |
| Kra | Wanzi Gelao | sa |
| Lachi | ɕu | |
| Laha | sɔ | |
| Paha | ðɦɯɯ | |
| Buyang | θoo | |
| Pubiao | θaau | |
| Hlai | Baoding Hlai | raau |
| Kam-Tai | Sanchong Sui | kuu |
| Thai | hua |
Ostapirat's Proto-Kra reconstruction of 'to laugh' is doubly puzzling. Not only does it still not resemble any of the non-Kra forms but it also has a *k- whose basis is unknown to me:
| Proto-Kra *C-so (p. 209) or *k-so (p. 241) | |||||
| Proto-South-Western Kra *so (pp. 162, 170) | Proto-Central-Eastern Kra *ʔ-soo (pp. 182, 195) | ||||
| Proto-Western Kra *so (pp. 147, 152) | Laha sɔ | Paha ðɦɯɯ | Proto-Eastern Kra *? | ||
| Proto-Gelao *so (pp. 109, 127) | Lachi ɕu | Buyang θoo | Pubiao θaau | ||
| Wanzi Gelao sa | |||||
Some sort of voiceless obstruent preceding *s- can be reconstructed on the basis of Paha and Buyang:
| Proto-Central-Eastern Kra | Paha | Buyang |
| *s- | θ- | θ- + series 1 tones |
| nasal + *s- | dh- | |
| *ʔ- (voiceless obstruent) + *s- | ðɦ- | |
| *ɦ- (voiced obstruent) + *s- | ?ðɦ- | ?θ- + series 2 tones |
(22:54: Ostapirat did not list any examples of PCEK *ɦ-so-. Hence the last row is by analogy with other cases in which PCEK *ɦ- conditioned series 2 tones in Buyang.)
Paha has voiced reflexes of earlier *s- preceded by consonants. Ostapirat's *ʔ- and *ɦ- could be cover symbols for unknown voiceless and voiced obstruents:
*ns- > *nθ- > *nth- > *ndh- > dh-
*ʔVs- > *ʔVθ- > *ʔVð- > *ð- > ðh-
*ɦVs- > *ɦVθ- > *ɦVð- > *ð- > ðh-
The voicing of an obstruent preceding *-s- can be determined by Buyang tonal series. 'laugh' has a Buyang series 1 tone so the obstruent preceding *-s- must have been voiceless. But how was Ostapirat able to specify this preceding obstruent as *k- at the Proto-Kra level? Did he have the k- of Sui kuu or some similar form in mind?
Let's suppose that the Proto-Kra-Dai word for 'to laugh' had initial *k-s-. How did that develop into the initials of its daughter languages? Here's my guess:
PKD *k-s- >
Proto-Kra *k-s- (no change?)
Pre-Hlai *k-ʂ- > *ʂ- > Baoding Hlai r-
Proto-Kam-Tai *k-ʂ- >
Samchong Sui k-
Proto-Tai *xr- > Thai h-
*k-s- > kʂ- occurred in Sanskrit and may have also occurred in Old Chinese (Pulleyblank 1991).
Ostapirat (2000: 241) reconstructed Proto-Kra 'to know' as *so sans preinitial:
Reflexes of these two roots ['to know' and 'to laugh'] are identical in most [Kra] languages. It is in fact undetermined whether the former etymon ('know') should be reconstructed as *s- or *-s-, since the crucial Paha form is lacking.
If Paha had a cognate for 'to know' like ðɦɯɯ < *C-s- rather than θɯɯ < *s- or or dhɯɯ < *N-s-, then one could reconstruct *obstruent-s-. But one couldn't determine whether the preinitial obstruent was voiced or voiceless without reference to the Buyang tonal series. Unfortunately, Buyang also doesn't have a cognate for this word, so we'll never ... know.
11.10.2.23:59: IS TANGUT QIANGIC ... AND DOES QIANGIC EVEN EXIST? (PART 2)
Katia Chirkova (2011: 4) wrote:
The Qiangic hypothesis essentially relies on shared lexical items and typological similarities, of which directional prefixes (topography-based spatial deixis) is de facto the essential feature probative of Qiang[ic]-ness (e.g. Matisoff 2004:105).
Tangut does have directional prefixes. But are those enough to qualify Tangut for membership in the Qiangic subgroup?
After Sun (2001:166- 170), a complete list of Qiangic features probative of the membership in this subgroup includes:
... twenty features excluding brightening (see my last post). Which of these twenty can be found in Tangut?
(1) shared vocabulary
When I first got into Tangut, I compared Tangut and Qiang (not Qiangic) basic vocabulary and easily found similar-sounding items that might be cognates in Sun (1981): e.g.,
| Gloss | Taoping Qiang | Mawo Qiang | Tangut | STEDT Proto Tibeto-Burman | Old Chinese |
| black | ɲiɲi | ɲiq | 1nɨaa | *nak | (no cognates) |
| blood | sɑ | sɑ | 1sie | *s-hwiy ~ s-hywəy-t | |
| to die | ʃe | ɕi | 2si | JAM 2003: *səy | 死 *siʔ |
| dream | χmu | rmuʁe | 2miee | *(s/r)-ma(ŋ/k) | 夢 *məŋs |
| to eat | dzɿ | dzə | 1dzi | *dz(y)a-k | (no cognate) |
| eye | mi | (no cognate) | 1me | *smik | 目 *muk |
| fire | mi | mə | 1məə | *mey | 火 ?*hməjʔ |
| fish | dzɿ | dzə | 2ʒɨu < *Cɯ-Tʃu-H | (none) | (no cognate) |
| I | ŋɑ | (no cognate) | 2ŋa | *ŋa | 我 *ŋajʔ |
| name | χmə | rmə | 2miee | *r-miŋ | 名 *meŋ |
| new | tshi < *khsi | khsə | 1siw < *sik | JAM 2003: *g-sik | 新 *sin < *siŋ |
| not | mi | ma | 1mi | JAM 2003: *ma | 無 *ma |
| red | χɲiɲi | (no cognate) | 1nie | *r-ni | (no cognate) |
| 3rd p. pron. | thalə | tha | 1thia | (none) | (cf. Mandarin 他 ta [tha]) |
| thou | no | (no cognate) | 2nia | JAM 2003: *na-ŋ | 汝 *naʔ |
| tooth | suə | ʂə | 1ʃwi | JAM 2003: *swa | (no cognates) |
| water | tsuə | tsə | 2zɨəəʳ < *rɯ-(T)Səə-H | *tsyu | |
| white | phʐi < *phri | phi | 1phɔw < *phroC | *plu | 白 *brak < ?*N-phr- |
(10.2.00:41: I have added a column of Proto-Tibeto-Burman forms from the top frame of STEDT search results and James A. Matisoff (= JAM) 2003. Although I am not certain about the existence of a Tibeto-Burman subgroup or proto-language, the presence of a reconstruction in this column indicates that the word has cognates outside Qiangic. Reconstructions are from JAM 2003 whenever STEDT does not list a reconstruction in its top frame. The JAM 2003 and STEDT top frame reconstructions reflect the same philosophy and are hence compatible. I am surprised that several key words do not appear in the STEDT top frame and that forms from Matisoff 2003 are not in the STEDT bottom frame.)
Some of the words in the Chinese column are questionable:
- the initial of 火 ?*hməjʔ 'fire' may have been *x-; Baxter and Sagart reconstruct it as *qʷʰˁ-, an extremely exotic consonant in only one language in UPSID (Rutul)
- the resemblance of Qiang and Tangut forms for the third person pronoun to the Mandarin third person pronoun [tha] may be coincidental
- I know of no Chinese-internal evidence for deriving *b- in 'white' from *N-ph-, though *NC-clusters are one source of voiced obstruents
Nonetheless, the presence of words in the Chinese column indicates that these words only indicate membership in Sino-Tibetan (assuming they are not loans) rather than a Qiangic subgroup.
Words lacking Chinese cognates generally have cognates in other Sino-Tibetan languages: e.g., the Qiang and Tangut words for 'black' are cognate to Written Tibetan nag-po 'black'.
The only words in the above list unique to Qiangic might be 'fish' and '3rd person pronoun'.
Next: The Concept of 'Qiangic' Gets Fishier
{kind=link}