10.11.13.15:39: THE GOLDEN GUIDE: LINE 91: TANGRAPHS 451-455
91. Three surnames (2780, 3669, 4769) are written with tangraphs for common nouns: one native and two borrowed. One (2074) is defined as a surname in Tangraphic Sea. 5925 was created to transcribe Chinese *tsɨ, a syllable absent from Tangut. Oddly, Tangut had six *tsə̣ tangraphs with tense vowel readings implying *Sʌ-tsə but no native *tsə with a lax vowel reading from *Cʌ-tsə (*C ≠ *S).
| Tangraph number | 451 | 452 | 453 | 454 | 455 |
| Tangraph | |
|
|
|
|
| Li Fanwen number | 2780 | 3669 | 4769 | 5925 | 2074 |
| My reconstructed pronunciation | 2kɔ̃ | 1na | 1tshe | 1tsə | 1kew |
| Tangraph gloss | valley | south < Chn 南 | property; wealth; < Chn 財 | (transcription of Chinese) | the surname 高 Gao (*kaw) |
| Word | the surname 江 Jiang (*kɔ̃) | the surname 南 Nan (*nã) | the surname 蔡 Cai (*tshe) | the surname 子 Zi (*tsɨ) | |
| Translation | 江 Kon, 南 Nan, 蔡 Tshe, 子 Tsy, 高 Kew. | ||||
451: How is a valley made out of slanting earth?
+
2780 2kɔ̃ 'valley' (geshercin) =
2627 2lɨə̣ 'earth' (gesgir; ges = 'earth') +
0779 1lhwie 'to slant' (hercin)
452: The borrowed word for 'south' is written as 'earth' plus the native word for 'south' minus one stroke:
3669 1na (gesbiobaxhae) =2627 2lɨə̣ 'earth' (gesgir; ges = 'earth') +
4796 1ziəʳ 'south'(biobaecaihae)
Why does 3669 end in an oral vowel if its Chinese source was *nã and Tangut had nasal vowels? Perhaps it was borrowed at a time when Chinese had nasal *ã and Tangut had not yet developed it, so oral -a was the closest Tangut equivalent of Chinese nasal *ã.
453: 4769 represents both a borrowing of Chinese 財 *tshe < *tsɦ- < *dz- 'wealth' and the Chinese surname 蔡 *tshe < *tsh-. It indicates that the initials of 財 and 蔡 were (nearly) homophonous when the Golden Guide was composed.
+
4769 1tshe 'wealth' (borrowed word) (biobuigeo) =
5050 2riʳ 'wealth' (native word) (biogeodexceu) +
0481 1ʔiʳ 'emolument' (buigeo)
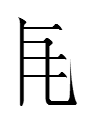
454: 5925 is a fanqie tangraph:
+
5925 1tsə (transcription of Chinese) (qunweu) =
3788 2tsəu 'to stand up' (dexqun) +
1073 1kə (first half of 1kə-1lã 'aerolite') (famdaidex)
455: 2074 contains 1890 as a semantic/cryptophonetic radical:
Tangut had no rhyme -aw, so -ew was the closest equivalent of Chinese *-aw.
+
2074 1kew 'the surname 高 Gao (*kaw)' (dexgak) =
2888 2mə 'surname' (dexpux) =
1890 2bie 'high' (gak)
Last night, I asked,
Did Tangut really have 36 initials?
The short answer is 'no'.
The Tangut list of 36 initials was an attempt to map a list of 36 Chinese initials onto Tangut. The dialect underlying the Chinese list is unknown, but the Tangut presumably interpreted the list in terms of the northwestern Chinese dialect that they did know. For example, the initial 見 in the Chinese list had initial *k- in Tangut period northwestern Chinese and was equated with the Tangut initial k- represented by the tangraph
The Tangut equivalents of the Chinese initials 溪 and 羣 are less straightforward:
2264 1kio
3094 1khie and 2877 2khio
Notice that they both have the same initial in my Tangut reconstruction. They also have the same initial in Nishida, Li Fanwen (1986), and Gong's reconstructions. (Sofronov 1968 II: 403 has 2ki̭o for 2877 which may be a typo for 2khi̭o.)
In Middle Chinese, 溪 had initial *kh- and 羣 had initial *g-. Gong (1981: 4) reconstructed the Tangut period northwestern Chinese initials of both 溪 and 羣 as *kh-. In his view, the Tangut author of the 36 Tangut initials converted the lost 溪 *kh- : 羣 *g- distinction (now only present in sinography) into an arbitrary division of Tangut kh-syllables. For instance, in the table for Tangut rhyme 1 in one copy of Dissected Rhymes of the Five Sounds,

0153 1khəu 'turquoise'
is associated with initial 3094 whereas
3415 1khəu 'surfeit'
is associated with initial 2877. But in reality, both are homophones according to Nishida's, Li's, Gong's, and my reconstructions. Or were they?
If they were truly homophones, I would expect them to
- be in the same homophone group in Tangraphic Sea- have the same fanqie in Tangraphic Sea (each homophone group has its own fanqie)
- be in the same homophone group in Homophones
But 0153 and 3415 are in separate though adjacent homophone groups in both Tangraphic Sea and Homophones. They have different fanqie:
0153 1khəu = 2782 2khi + 0415 1tsəu
3415 1khəu = 4807 1khi + 3044 1ʔəu
2782 and 4807 in turn belong to different fanqie chains, so there is no fanqie evidence to indicate that they shared the same initial. (But the lack of overlapping fanqie does not necessarily indicate different initials.)
One edition of Homophones lists both initial spellers (2782 and 4807) in the same homophone group, whereas another places them in separate homophone groups since they have different tones.
What's going on here? I don't know for sure, but I suspect the answer involves multiple Tangut dialects. The apparent 'contradictions' between different Tangut phonological works may reflect dialect variation.
What might have been the difference between 0153 and 3415? Nishida (1983: 136) suggested it might have been register, but left the question open and wrote their readings as kh1u and kh2u, deriving the latter from *gu.
Pulleyblank (1984) reconstructed the Late Middle Chinese initial of 羣 as *kɦ- (< Early Middle Chinese *g-) in opposition to 溪 *kh-. Could Pulleyblank's solution be adapted to Tangut?
| Chinese initial name | 溪 | 羣 |
| Pulleyblank's LMC | *kh- | *kɦ- |
| Tangut period NW Chinese | *kh- | *kɦ- |
| Tangut initial name |  3094 |
 2877 |
| Tangut initial | *kh- | *kɦ- (*kh- in some dialects) |
| Examples | 0153 *khəu |
 3415 *kɦəu (*khəu in some dialects) |
Let's suppose that Tangut syllables with lax, tense, and retroflex rhymes all had lax, tense, and retroflex consonants: e.g.,
lax: ta
tense: ttạ
retroflex: ʈaʳ
(But what would 'retroflex' versions of noncoronals be like? Would they be velarized: e.g., mˠ and gˠ?)
If this hypothesis is correct, I would expect distinct fanqie initial spellers for each type of consonant. If all three types of rhymes are frequently preceded by the same speller, then any phonetic differences among consonants before different rhyme types would be subphonemic (nondistinctive).
Tai Chung Pui (2008) examined the fanqie of the tangraphs transcribed in Tibetan. He grouped tangraphs into fanqie chains: e.g., dental initial fanqie chain 1:
| 3678 2to < | (2247 1təu) < | (5300 1tiə) < | (1899 2tiu) |
| 3583 1tia < | |||
| 5319 1tiẽ < |
(This is not a complete list of chain members. Parentheses indicate tangraphs in the chain which are not in Tibetan transcriptions and hence not in Tai 2008.)
The above table indicates that 1899 was the initial speller of 5300, which in turn was the initial speller of 2247 (initial speller of 3678), 3583, and 5319. All six have lax rhymes and are reconstructed with the same lax initial t-.
Although Tai, Gong, and I reconstruct only four dentals (t-, th-, d-, n-), Tai identified 18 different dental initial fanqie chains. Are these chains redundant: i.e., do some or even all dental initials have more than one chain? Or could some of the seemingly redundant chains actually represent tense and retroflex initials? Most would regards chains 8, 9, 11-14 as n-chains, but one might argue that chains 11 and 12 contained syllables with tense nn- and retroflex ɳ-:
| Dental initial fanqie chain | Initial | Rhyme types in tangraphs from each chain listed in Tai 2008 |
| 1, 7 | t | Lax only |
| 5 | th- | |
| 8, 9, 13, 14 | n- | |
| 4 | t- | Lax and tense |
| 6 | th- | |
| 3, 18 | d- | |
| 11 | n- | Tense only |
| 17 | d- | Lax and retroflex |
| 12 | n- | Retroflex only |
| 2, 10, 11, 15, 16 | ? | (No data; not in Tai 2008; these chains presumably contain t-, th- before retroflex rhymes) |
However, there are no other 'pure' chains whose members contain only one rhyme type. Moreover, the 'purity' of 11 is an illusion. Tai (2008: 180) only lists one member of 11: 3898 1nẹ. But looking at other members reveals that 11 is a mixed chain:
3898 1nẹ < (3864 1nəụ) < (0050 1nii) (lax!)
12 does not appear to be a mixed chain, but it may turn out to be mixed if more chain 12 fanqie are found. We still lack the rising tone volume of Tangraphic Sea which would enable us to have fanqie for nearly all tangraphs.
Even the 'pure' lax chains (1, 5, 7-9, 13-14) may turn out to be mixed if more fanqie in those chains are examined and found.
Mixed chains can also be found with nondental initials: e.g., alveopalatal initial chain 13 contains all three types of rhymes (T = Tibetan transcription):
lax: 5782 1dʒwɨa (T: H-jwa, b-jaH)
tense: 3844 1dʒɨẹ (T: g-jeH)
retroflex: 2180 1dʒɨəəʳ (T: g-jiH)
I would analyze all three as having the same initial phoneme /dʒ/ which may or may not have had allophones dependent on the following rhyme:
/dʒ/ before lax rhyme: [dʒ]?
/dʒ/ before tense rhyme: tense [ddʒ]?
/dʒ/ before retroflex rhyme: retroflex [dʐ]?
In any case, the Tibetan alphabet is insufficient to indicate such distinctions. All three syllables were transcribed with j. (The b- indicates medial -w-, g- may be a level tone indicator, and H- may indicate prenasalization.)
20:51: Each dental initial has at least two chains:
t-: 1, 4, 7
th-: 5, 6
d-: 3, 17, 18
n-: 8, 9, 11-14
Suppose the redundancy were lower: e.g., 'pure' 5 was for th- but 'mixed' 6 was for tense tth-. The chain 6 lax rhyme syllable 0369 1thiuu would then be reinterpreted as tthiuu with a tense initial and a lax rhyme. In theory, Tangut could then have nine types of syllables:
| Initial type | Final type | ||
| lax | tense | retroflex | |
| lax | CV | CṾ | CVʳ |
| tense | CCV | CCṾ | CCVʳ |
| retroflex/velarized? | CˠV | CˠṾ | CˠVʳ |
I have never heard of a language with so many syllable types. Hence I would rather continue to reconstruct 1thiuu with a lax initial that might have a tense allophone before tense rhymes: e.g., in the chain 6 syllable 3368 thwị [tthwị]. I think Tangut only had three phonetic syllable types at most:
| Initial type | Final type | ||
| lax | tense | retroflex | |
| lax | CV | ||
| tense | CCṾ | ||
| retroflex/velarized? | CˠVʳ | ||
On a phonemic level, there was only one initial type:
| Initial type | Final type | ||
| lax | tense | retroflex | |
| lax (with tense and retroflex/velarized allophones?) | /CV/ | /CV/̣ | /CVʳ/ |
If the Tangut really had many more initials, would they have tried to force their initials into a Chinese paradigm lacking tense and velarized initials, denying the existence of dozens of non-Chinese initials to create a Chinese-like list of 36 initials (see Nishida 1964: 25)? I doubt it, for the Tangut certainly did not force their 105 rhymes into a Chinese paradigm. The extant Tangut lists of 36 initials and 105 rhymes suggest that the Tangut had a Chinese-like inventory of initial phonemes but had a very un-Chinese inventory of rhymes. We may never know how much allophony Tangut initials had. Some details will always elude historians.
Next: Did Tangut really have 36 initials?
The title refers to a minimal pair in Korean:
대 [tɛ] 'bamboo' (lax consonant and vowel)때 [ttɛ̣] 'time' < Middle Korean *pstʌy (tense consonant and vowel)
Although the vowels of the two words are different, they are written identically as ㅐ in the Korean alphabet. However, the tense consonants are written with doubled letters for lax consonants:
ㄸ tt- < ㄷ t- x 2
One might assume based on hangul evidence alone that 'bamboo' and 'time' have different consonants (ㄷ, ㄸ) preceding the same vowel (ㅐ). But that is not phonetically true, and I am not sure it is phonologically true. Do Korean speakers really think of the ㅐ in 'bamboo' and 'time' as the same vowel? I bet that all but phoneticians would say yes under the influence of hangul spelling. But orthography is not necessarily an accurate guide to phonology: e.g., one cannot conclude that Hebrew and Arabic spellings with missing vowels directly reflect phonology. I suspect that tenseness is like Arabic emphasis: both are indicated in writing with consonantal symbols but in speech, those features are also in the following vowel.
Perhaps tenseness could be treated as a property of some Korean syllables rather than their segmental components. From the viewpoint of J. Marvin Brown's 'control' phonology, a Korean speaker can 'turn on' tenseness at the start of a syllable, shutting it off before a pause or a nontense syllable. Tenseness is associated with initial consonants because they are pronounced directly after the decision to 'switch on' tenseness. This analysis could also apply, mutatis mutandis, to Arabic emphasis.
But does such an analysis apply to Tangut? Was tenseness a syllable-level feature in Tangut? Many fanqie for tense rhyme syllables could imply that, since they have the structure
If tenseness were exclusively or primarily a feature of rhymes, one might expectC1V2 = C1Ṿ1 + C2Ṿ2
C1Ṿ2 = (C1V1 or C1Ṿ1) + C2Ṿ2
with a random mix of syllables with tense and nontense vowels as fanqie initial spellers.
However, last night I found one tense rhyme fanqie of the type
C1Ṿ2 = C1Ṿ1 + C2V2
with a nontense fanqie final speller.
I would need to do a statistical analysis of all extant Tangut fanqie to determine what is going on.
Fanqie for Tangut syllables with retroflex vowels seem to have the pattern
C1Vʳ2 = (C1V1 or C1Ṿ1 or C1Vʳ1) + C2Vʳ2
with a tendency toward both spellers having retroflex rhymes. I can't be sure without numbers. Examples:
C1Vʳ2 = C1V1 + C2Vʳ2
3131 1saaʳ = 1447 1siu + 4597 1thaaʳ4597 1thaaʳ = 0369 1thiuu + 3131 1saaʳ
4853 1gaaʳ = 0775 1giuu + 3131 1saaʳ
5796 1taʳ = 2247 1təu + 4643 1ɣaʳ
C1Vʳ2 = C1Ṿ1 + C2Vʳ2
5592 1kaaʳ = 3255 1kiị + 0697 1taaʳ
4378 1maaʳ = 0166 1mị + 0697 1taaʳ
0697 1taaʳ = 0166 1tiə̣ə + 3131 1saaʳ
C1Vʳ2 = C1Vʳ1 + C2Vʳ2
0045 1zaʳ = 3838 1zəiʳ + 0177 1raʳ
0177 1raʳ = 0285 1rəiʳ + 5796 1taʳ
(Why can't I find any -aaʳ syllables with fanqie of this final type?)
Is the choice of initial speller significant? Did 0697 have a tense initial unlike the lax initial of 5796, or did both have the same initial? I suspect the latter. Did retroflex rhyme syllables have a distinct class of initials? I doubt it, because I can't imagine what a retroflex labial or velar or glottal would be like, and there is no evidence for Cr-clusters in Tangut (though such clusters existed in pre-Tangut).
I can't find a single example of a retroflex rhyme syllable with a nonretroflex final speller:
C1Vʳ2 = C1Vʳ1 + C2V2 (?)
The absence or at least rarity of such fanqie indicates how strongly retroflexion was associated with rhymes.
The Chinese fanqie that were the model of Tangut fanqie have their own oddities which should be statistically analyzed: e.g., Sanskrit ɖa was transcribed "around the end of the sixth century" as 茶 with the Middle Chinese fanqie
*daʳ [ɖaʳ]? = 徒 *do + 家 *kaʳ (Pulleylbank 1984: 192)
indicating that a retroflex initial could be indicated by a retroflex rhyme.
David Boxenhorn asked me that question. The consensus answer would be no. I have never seen a reconstruction of Tangut with tense consonants. But reconstructions are not necessarily reality.
Last night I reconstructed tense consonants in Late Pre-Tangut, but not Tangut itself. I had assumed that the tense consonants were lost in Tangut proper, resulting in a consonant inventory with five types:
Obstruents: voiceless unaspirated, voiceless aspirated, voiced: e.g., t-, th-, d-
Sonorants: voiced and voiceless: e.g., l- and hl-
All five types may appear before tense rhymes (-Ṿ). Could they have been phonetically tense before tense rhymes: e.g. tt-, tth-, dd-, ll-, hll-?
If such tense consonants existed, I would expect them to have initial fanqie spellers distinct from those of syllables with nontense consonants:
Syllable with non-tense consonant and vowel:
C1V2 = C1V1 + C2V2 (but never CV = CC1Ṿ1 + C2V2)
Syllable with tense consonant and vowel:
CC1Ṿ2 = CC1Ṿ1 + CC2Ṿ2 (but never CCṾ = C1V1 + CC2Ṿ2)
I do not have the time to look at all the fanqie of tense rhyme syllables, but at a quick glance, I see that fanqie components tend to match in terms of tenseness:
However, I did find exceptions of three types:nontense = nontense + nontense
tense = tense + tense
1. nontense = tense (!) + nontense
2766 1kiʳw = 0105 1kiụ + 2208 2ɣiw
2208 doesn't even end in a retroflex rhyme like 2766. Even the rising tone (2-) of 2208 is unexpected since 2766 is listed in the level tone (1-) volume of Tangraphic Sea.
4949 1lə = 1074 1ləụ + 0644 1tə
0458 1koʳ = 0152 1kɛ̣ + 3498 2ɣoʳ
The tones of 0458 and 3498 don't match.
2. tense = nontense (!) + tense
5798 1mə = 4577 1məəi + 0265 1pə̣
3. tense = tense + nontense (!)
2054 1tə̣ = 0359 1təụ + 4949 1lə
I have not yet seen any instances of
4. nontense = nontense + tense (!)
I don't know what to make of such a small sample. Are these just random errors? Could the unexpected fanqie spellers have alternate readings that would make more sense?
Gong (1999) proposed that Tangut tense vowels (Ṿ) were conditioned by a preceding *sC-. I have previously drawn parallels between *sCV > CṾ and Middle Korean sC(C)-clusters as a source of modern Korean tense consonants. I proposed that Tangut went further than modern Korean by losing tense consonants and gaining phonemic tense vowels:
| Stage 1: Early Pre-Tangut | Stage 2: Middle Pre-Tangut | Stage 3: Late Pre-Tangut | Stage 4: Tangut |
| No tenseness | Tense consonant only | Tense consonant and tense vowel | Tense vowel only |
| *sCV | *CCV | *CCṾ | CṾ |
| cf. Middle Korean | cf. standard modern Korean and Yanbian Korean (the tenseness of the vowel is nonphonemic) | (will Korean reach this stage someday?) | |
Yanbian Korean (YK) as described by Ito and Kenstowicz (2008) might resemble stage 3 Tangut. In YK, the tense-lax consonantal contrast is partly signaled by the "voice quality" of the onset of the following vowel. Like Tangut, YK has phonemic tone, so
F0 [fundamental frequency] is unavailable as a resource for enhancing the laryngeal contrast in the [YK] consonants. The [standard] Seoul dialect [of Korean] has lost the lexical tonal contrasts and utilizes F0 as a % LH [low-high] accentual phrase melody (Jun 1993, 1996). Evidently, the melody has taken on a % HH [high-high] variant after the tense and aspirated consonants, suggesting that the enhanced F0 has been phonologized into the intonational, phrasal phonology. Thus, in both dialects VOT [voice onset time] has been supplemented by an enhancing feature in the following vowel in order to signal the three-way contrast postpausally, trading a ternary distinction in one phonetic dimension (VOT) for two (binary) distinctions (VOT and F0 or voice quality).
In the speech of younger Seoul speakers, "neither voice quality (nor VOT) distinguishes the lax from the aspirated series; only F0 does."
Perhaps Seoul Korean could redevelop tones reflecting an earlier lax/nonlax consonantal distinction. 1 and 2 represent the different melodies mentioned above (1 = LH, 2 = HH). Spaces before vowels indicate greater VOT.
| Stage 1: older speakers | Stage 2: younger speakers | Stage 3: future speakers? |
| lax/aspirated/tense consonants; three different VOT; two different F0; tense vowel after tense consonants | lax/aspirated/tense consonants; two different VOT; two different F0; tense vowel after tense consonants | lax/aspirated consonants; two different VOT; two different F0 |
| 1C V (medium VOT) | 1C V | 1C V |
| 2Ch V (long VOT) | 2Ch V (same VOT as 1C V) | 2Ch V |
| 2CCṾ (short VOT) | 2CCṾ | 2CV |
The restricted distribution of the tones is not without precedent: cf. the rarity of the rising tone in Thai after voiceless unaspirated and voiced obstruents. (The Thai rising tone normally developed in syllables with *s- or *voiceless aspirate or *voiceless sonorant initials.)
I merged CC- with C- since tense CC- is a rarer consonant type than aspirated Ch- in East Asia. But a few North and South American languages with a two-way C- vs. CC- contrast without Ch- exist in UPSID: Ashuslay, Jebero, Shuswap, Siona, and Tol. So another possible stage 3 for Seoul Korean might be
1CV vs. 2CV vs. 2CCV
Yanbian Korean, on the other hand, might retain its tones and develop a tense/lax vowel distinction:
| Current Yanbian Korean | Future Yanbian Korean? |
| lax/aspirated/tense consonants; two different VOT; F0 dependent on tone; tense vowel after tense consonants | lax/aspirated consonants; two different VOT; F0 dependent on tone; lax/tense vowel distinction after nonaspirates |
| CV (short VOT) | CV (lax vowel) |
| Ch V (long VOT) | Ch V (lax vowel) |
| CCṾ (short VOT) | CṾ (tense vowel) |
Future Yanbian Korean could develop aspirate-tense vowel syllables (ChṾ) in onomatopoeia and loans.
YK, like Tangut, has a binary tonal distinction. Thus both future YK and Tangut would have the same eight possible syllable types (ignoring a voicing distinction in Tangut obstruents absent from YK):
| Tone | Lax | Tense |
| 1 (YK high, Tangut 'level') | 1CV | 1CṾ |
| 1ChV | 1ChṾ | |
| 2 (YK low, Tangut 'rising') | 2CV | 2CṾ |
| 2ChV | 2ChṾ |
(I have omitted spacing notation for VOT.)
Last night, I asked if
3359 2khɛ̣ < *skhre or *sqh(r)e? 'steps, stairs'
3215 1khee < *kheC? 'house, room'
could be cognate. The problem is that 3359 either has an *-r- or a *qh absent from 3215 *kheC. I'd expect a cognate of 3215 to have one of ten shapes:
| Grade I short | Grade I long | Grade IV short | Grade IV long | |
| Lax vowel | khe | khee | khie | khiee |
| Tense vowel | (khẹ) | khiẹ | ||
| Retroflex vowel | kheʳ | khieʳ |
kh- can normally only occur in Grades I, II, and IV. Grade II kh- would be from *khr- or *qh(r)- which don't match the kh- of 3215.
Why doesn't Grade I khẹ - or any syllable with Grade I -ẹ - exist? Surely pre-Tangut had *S(ʌ)Ce which would become Cẹ. Did *S(ʌ)Ce merge with *SɯCe > Grade III Cɨẹ / Grade IV Ciẹ? It's even stranger that my reconstruction has Grade II -ɛ̃,̣ Grade II -ɨẹ̃, and Grade IV -iẹ̃ with very exotic vowels and diphthongs but not the relatively simpler Grade I -ẹ̃ or any other nasal tense rhymes of the type -ṿ̃. (This distributional oddity is a carryover from Gong's reconstruction.)
If 3215 had short-vowel cognates, that might imply that the length of 3215 1khee originated from a suffix.
Tangut has no long tense vowels, so khẹẹ and khiẹẹ are impossible.
Gong's reconstruction of Tangut has only seven long retroflex rhymes:
| Rhyme group | II | IV | VI | X |
| Grade I | -eeʳ | -aaʳ | -ooʳ | |
| Grade III | -jiiʳ | -jaaʳ | -jɨɨʳ | -jooʳ |
None correspond to -(ɨ/i)eeʳ in my reconstruction (which splits his Grade III into Grades III and IV):
| Rhyme group | II | IV | VI | X |
| Grade I | -əəiʳ | -aaʳ | -ooʳ | |
| Grade III | -ɨiiʳ | -ɨaaʳ | -ɨəəʳ | -ɨooʳ |
| Grade IV | -iiʳ | -iaaʳ | -iəəʳ | -iooʳ |
The absence of retroflex long -(ɨ/i)uuʳ, -(ɨ/i)eeʳ and -əəʳ needs to be accounted for.
The absence of Grade II imply the absence of pre-Tangut *rCrVC, *CrVCr, *CrVrC with
- the medial *-r- that conditioned Grade II
- the preinitial or coda *-r that conditioned retroflex vowels
- the -C that might have conditioned long vowels
10.11.7.1:37: THE GOLDEN GUIDE: LINE 90: TANGRAPHS 446-450
90. I generally reconstruct similar readings for Chinese surnames and their Tangutizations. There was no sɨ in Tangut, so 2460 1sə was the best approximation of 司 *sɨ. Nie and Shi (1995) identified 3909 1pəu as the Chinese surname 薄 Bo (*pho). However, I would expect *pho to be borrowed as Tangut 1pho, not 1pəu with a different initial and rhyme, so I think 3909 could be 卜 or 布 which were both *pəu in the northwestern Chinese dialect known to the Tangut. (But why was 博士 *po ʃɨ borrowed into Tangut as 3909 5442 1pəu 1ʃɨə instead of *1po 1ʃɨə?)
| Tangraph number | 446 | 447 | 448 | 449 | 450 |
| Tangraph |  |
 |
 |
 |
 |
| Li Fanwen number | 2460 | 3537 | 3909 | 0586 | 4348 |
| My reconstructed pronunciation | 1sə | 2thwã | 1pəu | 2siu | 1lew |
| Tangraph gloss | (transcription of Chinese) | the surname 段 Duan (*thwã) | (transcription of Chinese) | (transcription of Chinese) | building; grain-sowing implement |
| Word | the surname 司 Si (*sɨ) | the surnames 卜 Bu (*pəu) or 布 Bu (*pəu) or 薄 Bo (*pho) | the surname 徐 Xu (*siu) | the surname 婁 Lou (*lew) | |
| Translation | Sy, Thwan, Pu (Pho?), Su, Lew | ||||
446: The analysis of 2460 implies that dex is equivalent to its rarer lookalike dii which it outnumbers 1187 to 18:
+
2460 1sə (transcription of Chinese) (diigen) =
0545 1dʒwɨu 'person' (foudex) +
0558 1nieʳ 'wild animal' (belbaegen)
This analysis makes partial graphic sense but makes no obvious semantic or phonetic sense.
3537 2thwã 'the Chinese surname 段 Duan (*thwã)' (cirzukgux: cir 'water', zuk '?', gux 'small')
is the only tangraph with zuk. Is zuk is an error for tex which is in 56 tangraphs like
5037 1biəʳ 'knife, sword' (texgux)?
The functions of the other components are unknown. cir could be a fanqie initial speller abbreviating
3035 2thwəu 'nipple' (cirdumduu)
but zukgux or even gux are not in any tangraphs with readings ending in -wã.
448: gir is obviously phonetic in 3909, but what is the function of jui?
+
3909 1pəu (transcription of Chinese) (girjui) =
3911 1pəu 'pigeon, dove' (girque; phonetic) +
2653 1piẹ̃ 'horn' (dexdoojui)
0586 2siu (transcription of Chinese) (belgiidex)
shares its left two-thirds (belgii) with its homophones
0290 2siu 'like' (belgiicok)
0309 2siu 'cousin' (belgiivan; van is mostly in tangraphs for kinship terms)
belgii must be phonetic in all three, but what are dex and cok doing in 3909 and 0290?
450: 4348 has a very complex analysis. Its top radical box 'wood' corresponds to the 木 of its Chinese translation/source 樓, but what is the rest doing?
+
+
+
4348 1lew 'building' < Chn 樓; 'grain-sowing implement' < Chn 耬 (boxgiibaefea) =
4204 2kəụ 'central room'(boxcirpok) +
3359 2khɛ̣ < *skhre or *sqh(r)e? 'steps, stairs' (giifeijiu) +
3215 1khee < *kheC? 'house, room' (dexceubaedim) +
Could 3359 and 3215 be cognate? If they share a root *khe, are there other examples of zero ~ *-r-infixation (i.e., Grade I ~ II alternation)?
1356 2lhwiə 'among, between' (feabaefea; unclear which fea is intended)