 =
=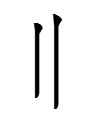 +
+
TT1443 lɛ̣ R63 2.53 = 'not' + TT3881 lhə R? (rhyme and tone unknown) 'full, sufficient, prepared'
In last night's post, I mentioned 생각 saenggak 'thought' as the native Korean equivalent of Sino-Korean 사상 思想 sasang. But is 생각 saenggak < Middle Korean ᄉᆡᆼ각 sʌyngkak (high tone followed by high tone) really native? It sounds like a Chinese loanword. I can't think of any other native Korean words with the syllable 생 saeng < ᄉᆡᆼ sʌyng.
saeng < sʌyng is usually from Chinese 生 'be born' (among many other meanings), though it also corresponds to some less frequent Chinese morphemes.
Vista lists
牲甥笙省眚鉎
as other sinographs for 생 saeng. (All but 省 contain 生 as a phonetic.)
The 15th century Sino-Korean dictionary 동국정운 Tongguk chŏng'un (東國正韻; Correct Sounds of the Eastern Nation; i.e., Korea; visible online for free at memorykorea) lists
8 sinographs for sʌyng (low tone; all with 生 as phonetic)
生笙牲鉎鼪䲼甥猩狌
5 sinographs for sʌyng (rising tone; four with 省 as phonetic; 眚 with 生 as phonetic)
省𨵥眚㾪𩩭
1 sinograph for sʌyng (high tone)
生
in vol. 1, p. 50.
The Korean tones correspond to Middle Chinese tones:
Korean low : MC 平聲 'level'
Korean rising : MC 上聲 'rising'
Korean high : MC 去聲 'departing' and 入聲 'entering'
If Middle Korean sʌyngkak HH has regular correspondences with Chinese, 生 sʌyng H 'be born' has to be the source of the first syllable.
kak H has many possible sources. Tongguk 1:82-83 lists 28 sinographs with that reading. The most likely is 覺 'awake; apprehend, get insight; rouse into understanding; (Buddhist) enlightenment' because it represents the only common kak-morpheme with mental semantics. (23:00: Also cf. modern standard Mandarin 覺得 juede 'feel; think' with 得 de 'get'.)
So is modern Korean saenggak < MK sʌyngkak HH from 生 sʌyng H + 覺 kak H?
(19:47: The Middle Chinese dictionary Guangyun [1008 AD] also defines 覺 as 曉 and 知, both 'know'. Is 生覺 thinking 生 giving birth to 覺 knowledge?)
Wikipedia lists 生覺 as an example of 취음 (取音) chhwiŭm 'taken sounds' or 군두목 kundumok (what's its etymology?*): writing a non-Chinese word with homophonous Chinese characters. This assumes that saenggak is non-Chinese.
That assumption would be easy to dismiss if I knew of a variety of Chinese in which 生覺 meant 'thought' or 'think'. But I don't. Could 生覺 have been a colloquial northeastern Middle Chinese word that was borrowed into spoken Old Korean?
How many other colloquial Chinese words survive only as borrowings into other languages? Could Vietnamese viết 'write' be from a southern Middle Chinese colloquial word *Cə-piət cognate to literary Middle Chinese 筆 pɨt 'brush'? (*Cə-piət could also be a combination of a native Vietnamese verbal prefix and a Chinese root noun.)
*군두목 kundumok can't be 군 kun- 'extra, superfluous' plus 두목 (頭目) tumok 'leader' (lit. 'head-eye').09.11.6.23:18: ČUČCHE
I've been thinking about it lately. What is it?
Its Czech spelling may look odd until one realizes that ch = [x], and that the spelling corresponds to Bulgarian and Russian чучхе. Here are some other spellings I found in Wikipedia:
Arabic الجوتشية al-juutshayah (not sure about the vowels)
Asturian Xuché (x = [ʃ]; why not Chuché?)
Esperanto Ĵuĉe or Ĝuĉe (ĵ [ʒ] is less like the Korean original than ĝ [dʒ])Georgian ჩუჩხე tʃutʃxɛ (presumably loaned via Russian - hence the -x-)
Hungarian Dzsucse (dzs = [dʒ], cs = [tʃ])Polish Dżucze (dż = [dʒ], cz = [tʃ])
Serbian Џуче (џ = [dʒ])
Vietnamese Chủ thể
Vietnamese th- preserves a Middle Chinese *th- that affricated in Korean before j-:MC *thjej > Middle Korean thjəj > Modern Korean tɕhe
Bulgarian, Czech, and Russian have no [h], so their [x] corresponds to Korean aspiration. (Czech h is actually a voiced [ɦ].)
Here's one more clue: it was invented by a man known in Russia as Ким Ир Сен Kim Ir Sen. Russian has no -ng, and the -r may reflect the Koryo-mar* dialect of Korean spoken in the former USSR which has -r instead of -l.
And here's the answer.
누리에 빛나라, 주체사상이여nuri-e pinnara, chuchhe-sasang-iyŏ
world-(locative) light-come-out-(imperative)!, Juche-ideology-(vocative)
누리 nuri is an archaic native Korean synonym for Sino-Korean 세상 (世上) sesang 'world'.
주체사상 chuchhe-sasang 'Juche ideology' is coined from Chinese roots:
主體思想
main/master-body think-think
A native Korean equivalent for chuchhe-sasang might be
임몸생각
im-mom-saenggak
'master-body-thought'
though saenggak may be of Chinese origin. I could substitute maŭm 'thought', resulting in a long sequence of m's:
임몸마음
im-mom-maŭm
*'Korean language' in Koryo-mar. Note the final -r corresponding to standard Korean -l.
09.11.5.22:02: NOT + FULL = ?
Without looking at the last post, can you guess the meaning of TT1443 by looking at its parts?
TT1443 lɛ̣ R63 2.53 = 'not' + TT3881 lhə R? (rhyme and tone unknown) 'full, sufficient, prepared'
The right side of TT3881 (Kychanov 2006's radical B088) never appears on the left. It appears on the right of 12 tangraphs. Unlike other tangraphic elements, it always has an obvious semantic or phonetic function:
| Kychanov tangraph number | Reading | Kychanov's (2006: 198-199) glosses | Function of B088 |
| 0929 | niooʳ R103 1.95 | fill, overflow, abundant | semantic: 'full' |
| 0933 | lew R44 1.43 | full, complete | |
| 0934 | nwew R44 1.43 | full, grown, full-grown, six-year-old sheep/goat | |
| 0935 | ŋii R14 2.12 | prepared; ready; full | |
| 0936 | ʔa R? | full; complete | |
| 0939 | lie R37 2.33 | crammed full; just right, be enough | |
| 0932 | lɛ̣ R63 2.53 | gloss here | semantic: opposite of 'full' |
| 0938 | pə R28 1.27 | first syllable of pə lɛ̣, adjective or adverb derived from K0932 (a verb according to Li Fanwen 1997: 636) | |
| 0931 | lhə R? | full, sufficient, prepared | semantic/phonetic |
| 0930 | ŋii R14 1.14 | ask, demand, beg (< 'to fill oneself?') | semantic?/phonetic (cf. K0935) |
| 0928 | lə R28 1.27 | first half of surname lə ŋwəu | phonetic |
| 0937 | thɛ̣ R63 2.53 | big; great | phonetic (rhyme of K0932) |
However, its origin is obscure. At first I thought it might be a distortion of 㒼, the right-hand phonetic of 滿 'full'. Like B088, 㒼 never appears on the left side. But then I realized that the
'person'
on the left of TT3881 could correspond to the 亻 'person' on the left of 備 'prepare'. Could B088 then be a distortion of 𦯞, the right-hand phonetic of 備 'prepare'? The problem is that B088 only vaguely resembles the phonetics of 滿 'full' and 備 'prepare'. Their similarities could be coincidental.
09.11.4.23:59: DO THE GREAT DRINK GREED?
In two recent posts, I examined tangraphs that may be derived from similar-sounding sinographs:
< 甫 or 莆?
TT2088 phə R28 2.25 first half of phə ʒu 'a kind of gown'
< Tangut period NW Chinese *fu or *fu?
< 孫?
TT5317 swəĩ R15 1.15 'monkey' (< second half of Chinese 猴猻 or 猢猻?)
< Tangut period NW Chinese *sun (with graphic elements reversed)?
Not all tangraphs for Chinese loans look like sinographs: e.g., TT0546 is derived from two other tangraphs representing its initial and final:
=
+
TT0546 thɛ̣ R63 2.53 'big; great' (< Tangut period NW Chinese 大/太 *thej) =
'mouth' = left of TT0510 thi R11 1.11 'drink'
TT0546 is more complex than 大/太 and is more opaque than a composite vietograph I mentioned in my last post:
𢀨 = 巨/郎 sang < *kraŋ 'noble': 巨 cự [kɨ] 'gigantic' over 郎 lang 'young man'
Although I can count on 巨 to represent a *k in vietography, 'mouth' does not necessarily signify th- in other tangraphs. Out of 93 tangraphs with 'mouth' on the left side in Sofronov 1968, only nine have readings with initial th-.
Only two tangraphs with the right side of TT0546 and TT1443 (Kychanov 2006's B088) are pronounced with R63 2.53 -ɛ̣ ... TT0546 and TT1443 (though TT4985 lie R37 2.33 comes close). So B088 is hardly a clear indicator of the rhyme.
11.5.3:09: I have no idea why TT0546 is Grade II thɛ̣ R63 2.53 instead of Grade I the R34 corresponding to.Grade I Tangut period NW Chinese 大/太 *thej. The tense vowel of thɛ̣ implies an earlier prefix (?*s-) that conditioned tension:
*s-thɛ > *tthɛ > *tthɛ̣ > thɛ̣
09.11.3.22:54: TO WRITE IS TO SAY THE SAME THING TWICE
EG Pulleyblank (1981: 284) proposed that Vietnamese viết 'write'* was borrowed from Chinese 筆 'brush', but there are both semantic and phonological problems with this etymology:
- I do not know of any variety of Chinese in which 筆 is a verb 'write'. It is possible that such a meaning did exist but is extinct in Chinese itself though it persists in Vietnamese. It is also possible that the meaning is an Vietnamese-internal innovation.
- The vowel of viết does not match that of the Chinese word during any relevant time period:
Old Chinese *plut > Late Old Chinese *put > Middle Chinese *pɨt
Viet bút < *put 'brush' is a borrowing from Late Old Chinese (that has presumably displaced the expected Late Middle Chinese borrowing *bất as a Sino-Vietnamese reading).
(The initial of viết is not an issue since it was (b [β] in Middle Vietnamese which is from earlier *C-p-. The reduction of an earlier cluster to a fricative must have occurred by the time 曰 viết 'say' was used to represent the unrelated word (biết 'write'.)
15th to 17th century Vietnamese texts contain a disyllabic word for 'write' (verb) and 'writing' (noun), 双曰 song viết (Lê Văn Quán 2004: 14). This cannot be a Chinese loanword because neither 双 'pair, couple, double' nor 曰 'say' have anything to do with writing. Both graphs are simply phonetic symbols for native Vietnamese syllables.
Is viết an abbreviation of an original monomorphemic, disyllabic word song viết, or is song viết a synonym compound? The latter is difficult to believe since I know of no song meaning 'write', though one could propose that it had once been used independently. The former scenario also has problems: e.g., why does the second syllable have a 'softened' initial v- < (b [β]? Did the second syllable originally have a *p that lenited after a nasal? Or did the *p lenite after a lost vowel in an even earlier trisyllabic form?
*Crong(C)Vpiêt > *Crong(C)βiêt > song (biết > song viết
I have never heard of trisyllabic roots in early Vietnamese.
The choice of Sino-Vietnamese 双 song, borrowed from southern Late Middle Chinese ?*ʂɔŋ to represent the first syllable implies that its initial cluster may have been *sr-. A different cluster might have been written as a vietograph combining a CV graph representing the first consonant with a SV long graph such as 龍 'dragon' representing the second consonant, the vowel, and the coda: cf.
sang < *kraŋ 'noble' written as 𢀨 < 巨 cự [kɨ] 'gigantic' over 郎 lang 'young man'
If you see a sinograph combining a nonradical full sinograph (e.g., 巨) with an l-initial sinograph, chances are that it is actually a vietograph that represented an earlier Vietnamese *Cr- or *Cl-syllable. The non-l-initial component may either represent an initial consonant or be semantic: e.g.,
六 lục 'six' in 𦒹 < 六+老 sáu < *Cráw, the native Vietnamese word for 'six' (老 lão 'old' is phonetic)
*The Việt of Việt Nam is an unrelated near-homophone traditionally written as 越 'exceed'. It is ultimately from some non-Chinese name like *awat borrowed into Old Chinese as 於越 *ʔawat and then reborrowed into Vietnamese as 越 Việt.
The same non-Chinese name underlies the name 粵 Md Yue / Cantonese Yut < Old Chinese *wat for 'Cantonese'.
Schuessler (2007: 596) went further and hypothesized that Old Chinese 戉 / 鉞 *wat 'battleax' is related to the name Yue. Were the Yue the 'ax people'?
The first syllable of *ʔawat has a low vowel. My theory of Old Chinese emphasis correlates low vowels with emphasis, so I would predict that *ʔawat should become emphatic *ʔawat. But the word was never emphatic. Perhaps glottal stop is always nonemphatic and syllables of the type *ʔV(C) either originally had low vowel presyllables (*Cʌ-) or had emphatic initials like *q- or *ʕ- (the latter is highly speculative) that later merged with glottal stop:
'Pure' type A phonetic series with Middle Chinese *glottal stop < OC *q- and maybe *ʕ-?
Type A/B mixed phonetic series with Middle Chinese *glottal stop:
Type A members < OC *Cʌ-ʔ-
Type B members < OC *(Cɯ-)ʔ-
sounds like an East Asian abbreviation. Each syllable stands for a word:
National Novel Writing Month
I tried to come up with a Chinese equivalent. It's been translated as
全國小說寫作月
quanguo xiaoshuo xiezuo yue
'all nation small-say write-make month' (in a morpheme-by-morpheme translation)
Oddly, there's nothing small about 小說 novels. Unfortunately, the one syllable-per-word formula results in
全小寫月quan xiaoxie yue
'all small-write month'
i.e., 'all lowercase month', which is not what NaNoWriMo is about.
Other East Asian translations - all unofficial - recycle some of the same Chinese elements (marked in bold):
Jpn: 全国的な小説を書く月
zenkokuteki na shousetsu wo kaku tsuki
national (adjective ending) novel (accusative) write month
Modern Japanese prefers 国 and 説 to 國 and 說. Note the totally different character 書 for 'write'. In Japanese, 寫, now simplified to 写, means 'to copy, photograph'. 月 means 'month' in both translations but represents a native Japanese word tsuki rather than a Chinese borrowing corresponding to Mandarin yue.
Kor: 전국 소설 쓰는 달
chŏnguk sosŏl ssŭnŭn tal
national novel write month
This could also be written with Chinese characters as
Kor: 全國 小說 쓰는 달
Note that the native Korean words for 'write' and 'month' are not written in Chinese characters, unlike Japanese 書く 'write' and 月 'month'.
Vietnamese has a very different modified-modifier word order:
Viet: tháng viết tiểu thuyết toàn quốc
'month write small say all country' = 'month write novel national'
The only native word is tháng 'month'. The translation might have been written as
𣎃曰小說全國
in traditional Vietnam. 𣎃 < 月+尚 is a made-in-Vietnam character for tháng 'month' with 月 nguyệt 'month' on the left (semantic) and 尚 thượng 'still' (phonetic) on the right. The sinograph for 曰 viết 'say' is used to represent the homophone viết 'write'. (Pulleyblank 1981 derived viết from Chinese 筆 'brush', though there are phonological as well as semantic problems I will discuss tomorrow.)
The NaNoWriMo site has official translations of its name in European languages. Note the different word orders of Romance and Germanic languages.
French: Mois National d’Écriture de Roman
'month national of-writing of novel'
Spanish: El Mes Nacional de Escritura de Novela
'the month national of writing of novel'
Dutch: Nationale Romanschrijfmaand
'national novel-write-month' (compare schrijf to scribe)
German: Der National Novel Writing Month
The German translation is disappointing. Month is masculine presumably because its German equivalent Monat is masculine.
In my last post, I proposed that in Tangut period northwestern Chinese
孫遜巽荀濬巡 might have been *swẽ (rather than Gong's *swə̃)送宋松 might have been *swẽw or sweŋ (rather than Gong's *sũ)
But if those reconstructions were correct, those sinographs should have been transcribed in Tangut as swẽ R41 instead of
TT2095 swəĩ R15 1.15 'transcription of Sun in Sun Tzu, etc.'
I've been troubled by R41 for some time now. There is very little evidence for its reconstruction, though something is always better than nothing:
- R41 follows the oral -e rhymes (R34-40) in Tangraphic Sea, so it may be nasal. Cf. how other oral rhymes are followed by nasal rhymes in TS.
- R41 follows a Grade III/IV rhyme (R40 -ɨee/-iee), so it is probably Grade I (contra Arakawa who regards R41 as Grade IIIb). In other words, it does not contain a Grade III/IV high vowel or a Grade II lowered vowel.
- R41 never transcribes anything in Sanskrit, which is not surprising since Sanskrit -eṃ [ẽẽ] is rare or nonexistent.
- R41 was transcribed in Tibetan as -e, -eH, -i (Nishida 1964: 53, Tai 2008: 229).
- R41 has no Chinese transcriptions. This is probably because there are few R41 syllables and I presume that none appeared in Pearl in the Palm. Here is a list of all R41 syllables known to me. All have the 'level' tone.
| Rhyme \ Initial category | I | II | III | VI | IX |
| -ẽ | phẽ, bẽ | vẽ | dẽ | tsẽ, dzẽ | lẽ |
| -wẽ | lwẽ |
Class IV (so-called 'retroflex') initials are rare and class VII (alveopalatal) initials are associated with Grades II and III, so their absence is expected.
I don't know if the absence of class V (velar) and VIII (glottal) initials or the common class VI initial s- is significant.
- R41 tangraphs transcribed the folllowing Chinese sinographs (Li Fanwen 1997: 329 and Sofronov 1968 II: 30*):
| Sinograph | Middle Chinese grade | Middle Chinese | Pre-Tangut period Tibetan transcription | Tangut period NW Chinese (Gong's reconstruction) | Modern NW dialect forms |
| 外 | I | *ŋwajh | Hgwe, gwe, HgoHi | *(ŋg)wej | uɛ, vɛ |
| 𡖦 | n/a | n/a | |||
| 磑 | *ŋwəjʔ/h | ||||
| 隗 | *ŋwəjʔ | ||||
| 偉 | III | *wɨjʔ | *jwi |
(I think 𡖦 [< 外 'outside' + 男 'man'] is a variant of 𠨃 [< 男 'man' + 外 'outside'], itself a variant of 外 'outside' in 外甥 'sister's son'.)
None of the above sinographs have nasal rhymes. So should R41 be reconstructed as an oral rhyme as in most reconstructions I've seen?
| Sofronov 1963 | Nishida 1964, 1966 | Hashimoto 1965 | Sofronov 1968 | Huang Zhenhua 1983 | Li Fanwen 1986 | Gong 1997 | Arakawa 1999 | This site |
| -ɐ | -ǐe | -ɛjN | -ai | -æi, -æĩ | -ɛ | -əj | -ee' | -ẽ |
Maybe a nasal reconstruction is still salvageable. Note that most of the sinographs transcribed by R41 tangraphs had or once had nasal initials. Could the nasality of the (earlier) Chinese initial have spread to the rhyme?
外 *ŋwajh > *ŋwãj > *ŋgwãj > *ŋgwẽj > *gwẽ > *wẽ
外 (Tangut period NW Chinese *wẽ?) was transcribed as
=
+
TT5392 vẽ R41 1.40 'a Tangut surname' =
right of TT0464 khiõ R57 1.56 'give' +
left of TT2840 veʳ R77 1.73 'flourishing; luxuriant'
The right side of TT5392 is an abbreviated phonetic:
<
The use of an R77 phonetic (TT2840) in an R41 tangraph (TT5392) makes sense in reconstructions with similar vowels for both rhymes like Sofronov's 1968 reconstruction or mine:
| Sofronov 1963 | Nishida 1964, 1966 | Hashimoto 1965 | Sofronov 1968 | Huang Zhenhua 1983 | Li Fanwen 1986 | Gong 1997 | Arakawa 1999 | This site | |
| R41 | -ɐ | -ǐe | -ɛjN | -ai | -æi, -æĩ | -ɛ | -əj | -ee' | -ẽ |
| R77 | -ɜ | -ẹ | -ə | -ại | -oĩ | -ụi | -ejʳ | -jeq2 | -eʳ |
(I have left out the ㅓ-shaped symbol from the Sofronov 1963 reconstruction. What does it represent? I have also been mystified by ㅏ. Are these related to the IPA symbols for advanced and retracted tongue root? Are they uniquely Soviet linguistic symbols? I have not seen them in other Soviet linguistic works.)
R77 is transcribed in Tibetan as -e(H) (Tai 2008: 225) which overlaps with the Tibetan transcriptions of R41 as -e(H). The r- in the Tibetan transcription of TT1774 points to a retroflex vowel since all other evidence indicates a nonrhotic initial:
| Tangraph | Homophones chapter | Tangut rhyme | My Tangut reconstruction | Tibetan transcription | Chinese transcription | Middle Chinese | Tangut period NW Chinese (Gong's reconstruction) |
|
|
II (labiodental initials) | R77 2.66 | veʳ | rwe | 嵬 | *ŋwəj | *(ŋg)wej |
My reconstruction has no Grade I retroflex nasalized rhyme -ẽʳ, so I wonder if that rhyme merged with R77:
| plain | plain long | nasalized | tense | tense nasalized (!?) | retroflex | |
| Grade I | R34 -e | R38 -ee | R41 -ẽ | (none) | (none) | R77 -eʳ |
| Grade II | R35 -ɛ | R39 -ɛɛ | R42 -ɛ̃ | R63 -ɛ̣ | R76 -ɛ̣̃ (sic!) | R78 -ɛʳ |
| Grade III | R36 -ɨe | R40 -ɨee, -iee | R43 -ɨẽ, -iẽ | R64 -ɨẹ, -iẹ | R65 -ɨẹ̃, -iẹ̃ | R79 -ɨeʳ, -ieʳ |
| Grade IV | R37 -ie |
I am not confident about the tense nasalized category. I have never heard of tense nasalized vowels. Moreover, the somewhat similar o-rhymes have retroflex nasalized rhymes** but no tense nasal rhymes:
| plain | plain long | nasalized | nasalized long | tense | retroflex | retroflex nasalized | retroflex long | |
| Grade I | R51 -o | R54 -oo | R56 -õ | (none) | R73 -ọ | R95 -oʳ | R97 -õʳ | R102 -ooʳ |
| Grade II | R52 -ɔ | R55 -ɔɔ, -ɨoo, -ioo | R57 -ɔ̃ | R59 -ɔ̃ɔ̃ | R74 -ɔ̣ | R96 -ɔʳ, -ɨoʳ, -ioʳ | (none) | (none) |
| Grade III | R50 -uo, R53 -ɨo, -io | R58 -ɨõ, -iõ | R60 -ɨõõ, -iõõ | R75 -ɨọ, -iọ | R98 -ɨõʳ, -iõʳ | R103 -ɨooʳ, -iooʳ | ||
| Grade IV |
There are also some unexpected gaps: e.g., why is there no -õõ and no nasalized e-rhymes? And why are Grade II rhymes sometimes grouped with Grade III/IV rhymes?
I will have to tackle these problems later.
*Sofronov has a note 'contact with 2.30', but I don't know what that means. I don't see any connection with R34 2.30 tangraphs.
**Kalasha is the only language I know of with retroflex nasalized vowels.


