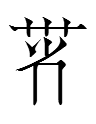
TT2095 swəĩ R15 1.15 'transcription of Sun in Sun Tzu, etc.'
You may have noticed a mismatch between my reconstruction of
TT2095 swəĩ R15 1.15 'transcription of Sun in Sun Tzu, etc.'
and the readings of the sinographs whose readings it transcribes. This problem persists regardless of whose Tangut reconstruction you want to believe:
Reconstructions of TT2095
Reconstructions preceded by '?' are guesses based on those scholars' systems. I have written all nasalized vowels with tildes for consistency. Hashimoto's reconstructed initial is unknown. Only Huang (1983) reconstructed an -n distinct from nasal vowels.
| Sofronov 1963 | Nishida 1964, 1966 | Hashimoto 1965 | Sofronov 1968 | Huang Zhenhua 1983 | Li Fanwen 1986 | Gong 1997 | Arakawa 1999 | This site |
| ?s(w)ẽ | sə̃ | -eN | swẽ | sïæn | sẽ | swẽ | ?s(w)ĩ | swəĩ |
Reconstructions of the sinographs transcribed by TT2095
Data from Gong, "類林西夏文譯本漢夏對音字研究" and "十二世紀末漢語系北方音韻母系统的構擬"
| Sinograph | Middle Chinese | Pre-Tangut period Tibetan transcription | Gong's Tangut period NW Chinese reconstruction (sans tones) | Modern NW Chinese dialect forms |
| 孫 | *son | son | ̣ *swə̃ | suə̃, suẽ, suɛ̃ |
| 遜 | *sonh | n/a | n/a | |
| 巽 | *sonh | |||
| 荀 | *swin | sun | suə̃, suẽ, suɛ̃ | |
| 濬 | *swin | n/a | n/a | |
| 巡 | *zwin | sun | ɕyũ, ɕyə̃, ɕyẽ, ɕyɛ̃ | |
| 送 | *soŋh | song | *sũ | suə̃, soŋ, suŋ |
| 宋 | *sowŋ | n/a | n/a | |
| 松 | *zuowŋ | zong |
Note that the modern NW Chinese dialects are not necessarily descendants of the NW dialect known to the Tangut.
Assuming Gong's Chinese reconstructions are correct, why transcribe Chinese central and back vowels with a tangraph for a syllable with a front vowel? Could the Tangut period NW Chinese readings have been *swẽ and *swẽw or sweŋ instead of *swə̃ and *sũ?
I think rhyme 15 has to be reconstructed with a front vowel because it follows the i-rhymes (R8-14) and is distant from the ə-rhymes (R28-33). Grade I R15 -əĩ is the lowered counterpart of Grade III/IV counterpart R16 *-i.̃ There is no Grade II rhyme -ɪ̃.
Unfortunately, no Tibetan transcriptions of R15 or R16 exist. Neither rhyme was used to transcribe Sanskrit. So these rhymes must be reconstructed using Chinese transcriptive evidence. But the problem is that the only direct evidence for reconstructing Tangut period NW Chinese is ... Tangut.
11.1.0:07: ADDENDUM: Several of the sinographs transcribed with TT2095 have anomalous standard Mandarin readings:
sùn seems to have shifted to xùn in standard Mandarin, even though sun doesn't become xun with other tones.
遜 should be sùn in standard Mandarin but is read xùn.
巽 should be sùn in standard Mandarin but is usually read xùn, which sounds like a compromise between 選 xuǎn and sùn.
荀 should be xūn in standard Mandarin but is actually read xún, presumably by analogy with its phonetic 旬 xún.
濬 should be xùn in standard Mandarin but is usually read jùn, presumably because its variant 浚 has the same phonetic as 俊 jùn.
松 should be sóng in standard Mandarin but is actually read sōng.
These odd readings may not be errors or irregularities. They may be regular reflexes of earlier forms not recorded by the rhyme dictionary tradition: e.g., 遜 xùn could be from an Old Chinese nonemphatic syllable *suns, whereas Middle Chinese *sonh is from an Old Chinese emphatic syllable *suns (from an even earlier *Cʌ-suns with an emphasis-conditioning low-voweled presyllable?).
| Sinograph | Old Chinese | Middle Chinese dictionaries | Standard Mandarin |
| 遜 | *suns | (unattested) | xùn |
| *suns | *sonh | (theoretically sùn) |
11.1.1:39: Schuessler (2009: 339-340) regards 遜 'withdraw; docile' and 巽 'humble; yield' as the same word, so it is not surprising that both graphs have the same 'irregular' reading.
Both have a 'regular' reading sun in Hphags-pa transcriptions of a dialect which is probably not ancestral to Beijing Mandarin.
I wonder what the earliest attestation of xùn is. MacGillivray's 1921 dictionary of Beijing Mandarin lists 遜 as hsün4 = xùn.
09.10.29.23:59: HORN-HATTED MONKEY
After realizing that TT2088 may be based on a sinograph, I noticed a vague similarity between
TT2095 swəĩ R15 1.15 'transcription of Chinese 孫 遜 宋 荀'
(Li Fanwen 1997: 894 lists examples of the first three but not 荀)
and the graph
孫
for the Chinese surname Sun (as in 孫逸仙 Sun Yat-sen or 孫子 Sun Tzu [子 Tzu is a title 'master', not a personal name]).
It seems that the 子 'child' of 孫 was turned into a similar-looking Tangut radical
'temperament' (Kychanov 1964: 128 in Grinstead 1972: 15), 'intention' (Nishida 1966: 244)
and placed on the right instead of the left. Was this reversal influenced by a variant of 孫 like 糸+子?
The left-hand element (Li Fanwen radical 145)
is only on the left side of the homophones
and
and doesn't appear in other positions as far as I know. I have no idea what LR145 means, if anything. LR145 doesn't look like the corresponding Chinese element 系 'tie' in 孫. Could it consist of two horizontal strokes added to a distortion of the 小 'small' in 孙, another variant of 孫?
(But I don't know if 孙 and 糸+子 were used by Tangut period northwestern Chinese. 孙 was in a 1935 ROC Ministry of Education proposal (see p. 14 of this PDF) decades before it was adopted as an official simplified form by the PRC.)
According to Tangraphic Sea,
+
TT2095 is derived from the top of TT2078 jɨə R31 2.28 (whose bottom is a homophonous phonetic TT4979) plus all of TT5317 TT2095 swəĩ R15 1.15 'monkey', possibly borrowed from the second half of Chinese
猴猻 or 猢猻
Could L145
in TT5317 be derived from 犭 'dog' on the right side of the shared second graph 猻 of those disyllabic Chinese words for 'monkey'?
The choice of 'horned hat' to differentiate the transcription tangraph from 'monkey' may be influenced by the 艹 'grass' radical in the sinograph
蓀
'a kind of aromatic plant'
(a homophone of 孫 which could have been transcribed with TT2095!)
Conversely, Tangraphic Sea derived 'monkey' from the transcription tangraph minus its top:
*10.30.4:51: 猴 is attested in Old Chinese, but 猴猻 and 猢猻 are not. 猢 and 猻 are not attested until Middle Chinese. I suspect that 猢猻 represents a Middle Chinese disyllabic word *ɣosun 'monkey' with a variant 猴猻*ɣəwsun influenced by a similar-sounding yet unrelated word 猴 *ɣəw 'monkey'.
I just realized that
TT2088 phə R28 2.25
(mentioned in my last post)
which appears to be
+
'horned hat' + 'horse'
might simply be a distortion of the sinographs
甫 'a name suffix' or 莆 'an auspicious plant'
which were both read as something like *fu in Tangut period northwestern Chinese and which were phonetics in sinographs with aspirated labial-stop initial readings: e.g.,
鋪痡浦
all TPNWC *phu (in Gong's reconstructions; I would prefer *phəu)
If the sinographic origin hypothesis is correct, TT2088 should be treated as an unanalyzable single-element tangraph even though it might have a two-element analysis in the lost second volume of Tangraphic Sea. Perhaps the TS analysis involved extracting TT2088 from a compound tangraph: e.g.,
=
-
TT2088 = TT2093 minus its bottom right component
Unlike Chinese 甫 which is phonetic in
逋晡餔峬鵏庯補捕埔哺簿悑
鵏尃糐旉麱懯傅溥縛榑輔脯
黼簠郙鯆蜅俌盙秿賻圑鋪痡
舖葡蒲莆蒱酺浦圃烳誧豧陠
TT2088 is a low-frequency phonetic.
TT2094 phə R28 2.25, first half of phə ?lia 'overcoat'
may be the only tangraph with it as a phonetic, unless it is also phonetic in

TT2089 bo R51 1.49 'long robe, gown'
borrowed from Middle Chinese 袍 *baw 'id.'
Since TT2088, TT2089, and TT2094 all have to do with clothing, TT2088 may have been regarded as a semantic element for 'clothing' which is why it appears in
But I have no idea why it appears with 'person' in
TT2093 lhwəu R1 1.1 'clothing'
TT2091 tʃæ R18 1.18 'gorgeous' (referring to flowers and bags - not people's clothing - in examples listed by Li Fanwen 1997: 879)
What appears to be TT2088 in TT2092 'fat' is really from two different tangraphs:
=
+
TT2092 na R17 1.17 'fat' =
top of TT2055 na R17 1.17 'deep' (phonetic) +
'Horned hat' appears in four other na(a)-tangraphs, but 274 other 'horned hat' tangraphs were not pronounced na(a).
all of TT5234 tshwəu R1 1.1 'fat' (semantic)
Why is 'horse' in this tangraph?
10.29.0:29: The right side is in other tangraphs meaning 'fat (belly)', 'fertile', 'bear fruit' (Kychanov 2006: 717). I will call it 'fat'.
I don't know what 'fat' is doing in the first half of the surname
TT3813 ʔwĩ R16 1.16 TT2120 ʃæʳ R86 1.81
Did the Winshaer clan have overweight members?
The Tangraphic Sea analysis of TT3813 derives the right half from
TT5350 khɪ R9 2.8 'yak'
I don't know why the vertical line is not always covered by 그.
One might think the Tangut did on the basis of the components of
+
TT2093 lhwəu R1 1.1 'clothing' = 'horned hat' + 'horse' + 'sickness' (?)
'Horned hat' simply describes the shape of an element that occurs in roughly one out of 21 tangraphs. It does not have any obvious single semantic or phonetic function. Removing it results in
=
+

TT5236 ʃɛ̣ R63 1.60 'invalid; lame' =
left side of TT5209 ʃɛ̣ R63 1.60 'wild wind' (phonetic; its right side is 'wind') +
right side of TT1117 dʑɛ̃ R42 2.36 'lame' (semantic; could this also be cognate?*)
which has no semantic or phonetic similarity to lhwəu 'clothing'.
The Tangraphic Sea's derivation of lhwəu 'clothing' doesn't involve ʃɛ̣ 'invalid; lame' at all:
+
TT2093 lhwəu R1 1.1 'clothing' =
frame (top and left)** of TT2094 phə R28 2.25, first half of phə ?lia 'overcoat' +
(bottom) right of TT2581 ziʳ R84 2.72, second half of gwɨə ziʳ 'armor'
which looks like 'metal' atop the phonetic TT3358 ziʳ 'long'
*The two words for 'lame' could share a common root *ʃɛ:
**The frame of TT2094 is its phoneticTT5236 ʃɛ̣ < ?*s-ʃɛ
TT1117 dʑɛ̃ < ?*N-ʃɛ-N
TT2088 phə R28 2.25, first half of phə ʒu 'a kind of gown' (why is 'horse' in it?)
Is phə- a clothing prefix with two different spellings in phə ?lia 'overcoat' and phə ʒu 'a kind of gown'?
10.28.2:33: Could phə- be from Tangut period northwestern Chinese 袍 *pho 'long robe, gown'?
The second half of the Tangut word
xə thwo 'Chinese parasol tree'
sounds like the second half of its Chinese translation
梧桐
modern Mandarin wútóng
Tangut period northwestern Chinese *ŋgothũ (in a Gong-style reconstruction)
but I suspect the resemblance is coincidental for three reasons:
1. 桐 by itself means 'paulownia', not 'Chinese parasol tree'. So why borrow the second syllable 桐 but not the first syllable 梧**?
2. The Tangut period northwestern Chinese rhyme *-ũ normally corresponds to the following Tangut rhymes:
R5 -wəəu
R56 -õ
R104 -əũ
But thwo ends in R51 2.42 -wo which is not in any Chinese loans that I know of. A similar rhyme R51 1.49 -o without a medial glide corresponds to Middle Chinese or Tangut period northwestern Chinese rhymes other than *-ũ:
*-u < *-ok
'read': TT4628 do R51 1.49 < Middle Chinese 讀 *dok(The Tangut period reading of 讀 was *thu, and would have been borrowed into Tangut as thu.)
*-o(w)
'young man': TT1873 lo R51 1.49 < TPNWC 郎 *lo(w)
'lake': TT4297 pho R51 1.49 < TPNWC 泊 *pho(w)
*-ju
'vehicle': TT0683 ko R51 1.49 < TPNWC 車 *kju
(Why wasn't this borrowed as kiu R3?)
In the Tangut transcriptions of Chinese in The Forest of Categories, only one out of 32 transcribed sinographs belonged to the same rhyme as 桐 'paulownia'
TT1642 mo R51 2.42
for 蒙 *mũ, also anomalously transcribed in Tangut as TT0090 mie R37 1.36). So there is some precedent for borrowing Tangut period northwestern Chinese 桐 *thũ as Tangut thwo. But if that were the case, the question of why 梧 wasn't borrowed remains unresolved.
*The 梧桐 wútóng 'Chinese parasol tree' is in a sense my tree since it is also known as a 'phoenix tree' and my totem is the 鳳凰 phoenix.
The graphs for 梧桐 wútóng consist of 木 mù 'tree' plus the phonetic elements 吾 wú 'I' and 同 tóng 'same'. The title asks why the first syllable of xə thwo doesn't match the first syllable of 梧桐 wútóng.
It is unlikely that Md 同 tóng < Old Chinese *loŋ 'same' is cognate to
TT5087 lew R44 2.38 'same'
because the rhymes don't match. Tangut -ew implies *-ek.
Tangut period northwestern Chinese 同 *thũ 'same' was borrowed into Tangut as
TT2834 thwəəu R5 1.5
**教育部重編國語辭典修訂本 lists nine words with Md 梧 wú excluding 梧桐 wútóng 'Chinese parasol tree'. (I am not counting words in which 梧 is read as wù with a falling instead of a rising tone***.) These words fall into three categories:
1. 梧 wú is an abbreviation of 梧桐 wútóng: e.g., 碧梧 bìwú 'green Chinese parasol tree'.
2. 梧 wú represents a syllable in a word that apparently has nothing to do with trees: e.g.,
枝梧 zhīwú < Old Chinese *keŋa 'resist, conflict' (written as 'branch-Chinese parasol tree', though such a combination is an unlikely origin for 'resist')
(OC *keŋa is a nonemphatic-emphatic syllable sequence that violates a strong tendency against mixed emphasis in disyllabic noncompound words.)
23:39: The second syllable of OC *keŋa 'resist, conflict' may be cognate to 牾 Md wǔ < unattested OC *ŋaʔ 'resist, conflict, clash' which I stumbled upon in Xinhua zidian. I don't know why 牛 'ox' is on the left. Does it represent stubbornness? Is it derived from 午 OC *ŋaʔ 'horse' which is in the Shuowen version of the graph 啎? Since 'horse' is not obviously relevant to 'resist', 啎 appears to be a double phonetic (*ŋaʔ + *ŋa) with no semantic element. 教 育部異體字字典 has separate entries for 牾 and 啎, even though I would consider them variants of each other. See Schuessler (2007: 590) for more members of this word family.
梧鼠 wúshǔ < Old Chinese *ŋahnaʔ 'a kind of rodent' (鼠 *hnaʔ is 'rodent'; this could be 'Chinese parasol tree rodent')
3. 梧 wú represents a syllable in a name: e.g., 蒼梧 Cāngwú.
梧 wú in names could either be abbreviations of 梧桐 wútóng or represent syllables that have nothing to do with trees. 蒼梧 Cāngwú is probably a case of the former since it looks like 'green Chinese parasol tree'.
***I initially thought 梧 might be phonetic in 魁梧 kuíwù 'stalwart'. Then I realized that 梧 wù could be related to 梧桐 wútóng 'Chinese parasol tree' via abbreviation and suffixation:
梧桐 Old Chinese *ŋaloŋ > 梧 *ŋa > *ŋa-s > Mandarin wù
(The falling tone of Md wù is a reflex of OC *-s. OC *ŋa without *-s became Md wú)
The phrase 高梧 gāowú 'tall Chinese parasol tree' could indicate that 梧 (which can be twelve meters tall) were associated with height.
魁 kuí is 'stalwart', so 魁梧 kuíwù 'stalwart' could be a semiredundant compound 'stalwart (as a?) (tall) Chinese parasol tree'. But the definition for 魁梧 in 教育部重編國語辭典修訂本 does not refer to Chinese parasol trees.
One could try to interpret 魁梧 kuíwù 'stalwart' as a redundant compound 'stalwart-tall' and 梧桐 wútóng as 'tall paulownia', but 梧 doesn't mean 'tall' by itself and I know of no (near-)homophones meaning 'tall'.
09.10.25.23:59: ALL MINUS TWO IS TO
What do the components of the Tangut characters
to zi 'all' (lit. 'all-all')
mean?
I presume that the tangraph for the native word zi 'all' was created first and that the tangraph for the borrowed word to was derived via the substitution of the top element 二 of zi with a 'horned hat':
-
+
I still have no idea what 'horned hat' represents. It is atop 280 tangraphs that have little or nothing in common with each other and never occurs in bottom position.
二 is atop seventeen tangraphs. Ten have alveolar or palatal fricative initials (z-, (d)ʒ-, (t)ʃ-), so I suspect that it is a phonetic element based on northwestern Tangut period Chinese 二 *ʒi 'two'.
zi 'all' is itself a phonetic element in
zi 'very' (homophonous with zi 'all')
with 'person' on the left (why?)
zi (meaning unknown; homophonous with zi 'all')
with unknown element on the left
zɨ̣ 'both; two' (borrowed from northwestern Tangut period Chinese 二 *ʒi 'two'?; but why is its initial different and its vowel nonpalatal and tense?)
with 'pair' on the left
The bottom elements of zi 'all'
are presumably semantic. They do not combine to form an independent tangraph.
I only know of three tangraphs with the left element on the left:
xə 'first half of the disyllabic word xə lo 'seek; look for'
xə 'first half of the disyllabic word xə thwo 梧桐 Chinese parasol tree'
gwɨəʳ 'rise; grow'
It may be phonetic in the first two tangraphs but I don't know what its function is in gwɨəʳ 'rise' or zi 'all'. It also appears in a second tangraph for 'all':
ŋõʳ 'all' (also reduplicated: ŋõʳ ŋõʳ)
with
dzɨə̣ 'assemble' (cognate to Old Chinese 集 *dzəp 'id.' or borrowed from Middle Chinese *dzip 'id.')
on the lower right consisting of
+
'not' + 'absence' (Nishida 1966: 243)
which isn't quite what I'd expect for 'assemble'.
The bottom right element of zi 'all'
is Kychanov's radical B278 which occurs on the right side of 74 tangraphs* without any obvious shared phonetic or semantic characteristics. B278 never occurs in other positions.
On the basis of
mə 'be born'
with 'not' on the left, one might guess that B278 means 'die'. But in fact none of the B278 graphs mean 'die' (though some represent illness-related words), and what would 'die' or 'illness' have to do with zi 'all'?
10.26.00:34: Although B278 vaguely resembles Chinese 老 'old', I think that sinograph was the basis of Kychanov radical B276 on the right of
naʳ 'old'
*10.26.0:22: Kychanov (2006: 664-675) lists 75 tangraphs under B278, but 4813 should be filed under B272.