 =
= +
+
TT2500 lɨw R46 1.45 'the Chinese surname 劉 Liu' (Grade III) =
TT4361 lɨi R10 1.10 'prosperous, flourishing' (Grade III) +
TT2941 jɨw R46 1.45 'oil; fat; grease' (Grade III)
For months I've been deriving the complex Tangut rhyme system from an earlier system with simpler rhymes and presyllables. The four grades of Tangut reflect earlier presyllable and main syllable vowel qualities:
Pre-Tangut vowels
| Height | Presyllable (unstressed) | Main syllable (stressed) | ||
| High | *ɯ | *i | *u | |
| Mid | *ɤ | *e | *ə | *o |
| Low | *ʌ | *a | ||
I propose a similar vowel system for Old Chinese (but without *ʌ).
The presyllabic vowels are reduced versions of the main vowels: e.g., *ɯ < unstressed *i and *u, etc.
The choice of back instead of central vowel symbols for presyllabic vowels is arbitrary and is intended to avoid confusion with stressed *ə and *a.The four grades
Sources of the four gradesI: mid vowel
II: lowered vowel
III: high nonpalatal vowel
IV: high palatal vowel
*I = generic symbol for any high vowel
*E = generic symbol for any mid vowel
*(Cɤ-)CE > primary Grade I (vowel is already mid)*(Cɤ-)CI/a > secondary Grade I (nonmid vowel bends midward)
*(Cʌ-)Ca > primary Grade II (vowel is already low)
*(Cʌ-)CI/E > secondary Grade II (nonlow vowel bends downward)
*(Cɯ-)Cu > primary Grade III (vowel is already high and nonplatal)
*Cɯ-CE/a > secondary Grade III (nonhigh vowel bends upward)
*(Cɯ-)Ci > Grade IV (vowel is already high and palatal)
*(Cɯ-)CjV > Grade IV (*-j- reinterpreted as a high palatal vowel -i-)
(I don't know what happened to *Cɤ/ʌ-CjV: would the presyllable or the *-j- determine the grade?)
Mosf of that information in tabular form:
| Pre-Tangut presyllable | Resulting grade in Tangut |
| None without *-j- | Inherent grade: I for *E, II for *a, III for *u, IV for *i |
| None with *-j- | Grade IV |
| *Cɯ- (< *Ci/u-) | Grade IV if the main vowel is *i; otherwise Grade III |
| *Cɤ- (< *Ce/ə/o-) | Grade I |
| *Cʌ- (< *Ca-) | Grade II |
Presyllables which remained until a late date conditioned lenition of the onsets of main syllables: e.g.,
| Early Pre-Tangut | *Cɯ-te | *Cɯ-te |
| Raising conditioned by high vowel of presyllable | *Cɯ-tie | *Cɯ-tie |
| Early loss of presyllable | *tie | *Cɯ-tie |
| Intervocalic voicing | (no effect; no presyllable to condition this rule) | *Cɯ-lie |
| Late loss of presyllable | tie R37 | lie R37 |
My current scenario makes predictions that turn out to be false. If *Cʌ- conditions Grade II and if some l- are from dental stops, I would expect a lot of Grade II l-syllables because they would have multiple sources:
*Cʌ-l-, *Cʌ-t-, *Cʌ-d-, maybe even *Cʌ-th- and/or *Cʌ-n-?
But if homophones are excluded, there are only 6 different Grade II l-syllables. There are also only 6 different Grade II lh-syllables:
lhɪ R9 2.8
lhææ R23 2.20
lhɔ̃ R57 2.48
lhɔ̃ɔ R59 1.57
lhɪ̣ R69 2.59
lhɔ̣ R74 2.63
If *-th- lenited to lh-, I would expect even more.
I thought those numbers were low, but the figures for other Homophones Chapter IX initials are even lower:
| Initial | l- | lh- | r- | z- | ʒ- |
| Number of distinct Grade II syllables | 6 | 6 | 0 | 0 | 1 |
(Li Fanwen 1997.1437 lists the Gong reconstruction of TT4897 'incomplete; difference' with z-, but Homophones lists this as a homophone of TT2439 ʒɛʳ R78 2.67 'live; reside'. Therefore I reconstruct both with ʒ-.)
The figures for Chapter III initials are also very low:
| Initial | t- | th- | d- | n- |
| Number of distinct Grade II syllables | 3 | 0 | 2 | 7 |
So are the figures for Chapter VI initials:
| Initial | ts- | tsh- | dz- | s- |
| Number of distinct Grade II syllables | 0 | 1 | 1 | 1 |
Compare the above figures with those for Chapter V initials:
| Initial | k- | kh- | g- | ŋ- |
| Number of distinct Grade II syllables | 37 | 22 or 23 | 6 | 4 |
(It's not known whether TT0098 khwʌ R29 'abuse; swear' has level or rising tone. I assume it has rising tone, since it is listed apart from khwʌ R29 1.28 in Homophones.)
Chapter I initials are more common than III/VI/IX initials but not as common as V initials:
| Initial | p- | ph- | b- | m- |
| Number of distinct Grade II syllables | 12 | 9 | 20 | 4 |
(Li Fanwen lists no tone for TT5292 [meaning unknown] but Precious Rhymes of the Tangraphic Sea lists its tone as 2.31.)
Here are the figures for initials from all other chapters except IV which has no unique initials of their own in Gong's reconstruction:
| Chapter | II | VII | VIII | |||||
| Initial | w- | tʃ- | tʃh- | dʒ- | ʃ- | ʔ- | x- | ɣ- |
| Number of distinct Grade II syllables | 7 | 25 | 15 | 23 | 32 | 7 | 10 | 20 |
(Li Fanwen lists TT1329 as w- but Homophones lists it in chapter VIII, so I reconstruct its initial as ʔ-.)
(I have rewritten Gong's 1997 ś, etc. as IPA ʃ, etc. in accordance with his 2003 consonant chart.)
ʒ- (IX) does not pattern like other alveolpalatals (VII) which is why I suspect it might have been an r-like retroflex fricative [ʐ] (cf. Mandarin r which can be pronounced as [ʐ]).
If all initials are arranged in order from most to least associated with Grade II, velars and alveopalatals are at the top and dentals and alveolars are at the bottom:
| Rank | Chapter | Initial | Number of distinct Grade II syllables |
| 1 | V | k- | 37 |
| 2 | VII | ʃ- | 32 |
| 3 | tʃ- | 25 | |
| 4 | dʒ- | 23 | |
| 5 | V | kh- | 22 or 23 |
| 6 | VIII | ɣ- | 20 |
| I | b- | ||
| 7 | VII | tʃh- | 15 |
| 8 | I | p- | 12 |
| 9 | VIII | x- | 10 |
| 10 | I | ph- | 9 |
| 11 | II | w- | 7 |
| III | n- | ||
| VIII | ʔ- | ||
| 12 | V | g- | 6 |
| IX | l- | ||
| lh- | |||
| 13 | I | m- | 4 |
| V | ŋ- | ||
| 14 | III | t- | 3 |
| 15 | d- | 2 | |
| 16 | VI | dz- | 1 |
| IX | ʒ- | ||
| 17 | III | th- | 0 |
| VI | ts- | ||
| tsh- | |||
| dz- | |||
| s- | |||
| IX | r- | ||
| z- |
There are more Grade II syllables with initial alveopalatals (VII) than with labials (I/II), dentals (III), alveolars (VI), and liquids (IX) combined:
| Homophones chapter | I | II | III | V | VI | VII | VIII | IX |
| Number of distinct Grade II syllables | 45 | 7 | 10 | 69 or 70 | 0 | 95 | 37 | 13 |
The correct explanation for Grade II must account for
- why it is so strongly associated with alveopalatals (VII) and velars (V)
- why it is so rare with dentals and alveolars
There is no reason for *Cʌ- to occur more often before alveolpalatals and velars than other initials. Therefore I abandon the *Cʌ-hypothesis.
Arakawa's Grade II -j- is iniitally attractive because one can claim that the large number of alveopalatals partly comes from earlier dental/alveolar-j- clusters: e.g., *tj- > *tʃ-, etc. There is no Grade II r- because *rj- became j-: e.g., TT1632 *rjat > jaʳ 'eight'. (Does the Tibetan transcription rye represent a conservative dialect?) However, there is almost no Tibetan transcriptional support for this -j- (or Gong's Grade II -i-): e.g.,
R9 (Arakawa's -ji, Gong's -ie, my -ɪ): Tib. tr. -i(H)
R23 (Arakawa's -ja', Gong's -iaa, my -ææ): Tib. tr. -arR29 (Arakawa's -jI, Gong's -iə, my -ʌ): Tib. tr. -iH
R35 (Arakawa's -je, Gong's -iej, my -ɛ): Tib. tr. -e(H); only one instance of -ye and -i
R52 (Arakawa's -jo, Gong's -io, my -ɔ): Tib. tr. -a, -uH
If there ever was a -j-, it may have disappeared in the dialect underlying the transcriptions.
Next: A-nother reason why the *Cʌ-hypothesis is wrong.
The phonetic fanqie for the Tangut version of the Chinese surname 劉 Liu is
TT2500 lɨw R46 1.45 'the Chinese surname 劉 Liu' (Grade III) =
TT4361 lɨi R10 1.10 'prosperous, flourishing' (Grade III) +
TT2941 jɨw R46 1.45 'oil; fat; grease' (Grade III)
Both the initial and final spellers are Grade III with high nonpalatal velar vowels.
Was Tangut Grade III l a velarized [ɫ] distinct from a palatal(ized) *[lʲ] or *[ʎ] before palatal vowels in Grade IV? Of course, such fine phonetic details are difficult if not impossible to reconstruct with certainty, but if the two grades had different allophones, then TT4361 should not be an initial speller for Grade IV syllables.
In Tangraphic Sea, TT4361 is the initial speller for the following syllables:
Grade I: l(w)əw R1 1.1, lew R44 1.43
Grade III: lu R2 1.2
Grade III or IV: l(ɨ)ĩ R16 1.16, l(ɨ/i)ẽ R43 1.42
Obviously Grade I and III had the same kind of l, though I am not sure whether the same can be said for Grade I/III */l/ in Tangut period NW Chinese.
It's not clear whether Tangut rhymes with high nasalized vowels belong to Grade III or IV. Since there is no Grade IV li R11*, perhaps R16 was Grade III -ɨĩ before l-, but it's impossible to tell whether l(ɨ/i)ẽ R43 1.42 was the nasal counterpart of Grade III lɨe R35 (only one example - TT2990?) or Grade IV lie R36. I suspect that Tangut once had a four-grade distinction in nearly all rhyme types but that this distinction partly collapsed in less frequent rhyme types with long, nasalized, glottalized, or retroflex vowels.
lɨi R10 1.10 does not have a hekou counterpart lwɨi R10. The closest existing syllable is lwi R11 which is only in
which has a Grade III initial speller even though its rhyme is Grade IV.
=
+
TT1686 lwi R11 1.11 'seed' (Grade IV)=
TT1338 lɨə R30 1.29 'wind' (Grade III!) +
TT2909 twi R11 1.11 'choke' (Grade IV)
lwia R20 1.20
lie R37 1.36
and lw(u/i)o R50 1.48, l(u/i)o R53 1.51, and l(u/i)õ R58 1.56 which may be Grade III or IV. (These rhymes appear in transcriptions of Chinese Grade III syllables in the Tangut translation of Leilin, so I tentatively assume they are Grade III.)
So far it appears that Grades I, III, and IV had the same kind of l-. What about Grade II? It's not clear whether Gong's rhyme group I contains any Grade II rhymes (though I've suspected that R4 is Grade II) and there is no syllable lɪ R9, so the earlier Grade II l-syllable I can find is læ (or laˠ or lɑ?) R18 1.18 which has the fanqie spelling
+
TT4405 ləu R1 1.1 'storehouse; warehouse' (Grade I) +
TT0124 xæ (or xaˠ or xɑ?) R18 1.18 '塞 fill in' (Grade II)
with a Grade I speller.
Another Grade II syllable lɪ̣ (or lɪ̣ˠ?) R69 1.66 has the fanqie spelling
+
TT4552 lɨə R30 1.29 'fall; sink' (Grade III!) +
TT5496 lu R2 2.2 'manager (official title)' (Grade III)
with a Grade III speller.
I cannot find any Grade II l-syllables with definite Grade IV spellers. There are not very many Grade II l-syllables in Tangut (possibly as few as 12**), though they are more common than in Middle Chinese. This may indicate that my proposed origin of Grade II syllables is incorrect. If Grade II is derived from vowels lowering to assimilate to low vowels of lost presyllables
*Cʌ-l- > l- + Grade II
there is no obvious reason why *Cʌ-l- would be rare.
In any case, all four grades seem to have the same kind of l-.
*I am surprised by the distribution of l(h)(w)- in R10 and R11:
| Grade | Rhyme | l- | lw- | lh- | lhw- |
| III | R10 | lɨi | |||
| IV | R11 | lwi | lhi | lhwi |
lɨi R10 is the odd man out. All other lateral-initial syllables belong to R11.
**This figure includes homophones. The number of Grade II syllables excluding homophones is 6:
læ (or laˠ or lɑ?) R18 1.18 and 2.15
lɔ (or loˠ?) R52 1.50
lɛ̣ (or lẹˠ?) R63 1.60
lɪ̣ (or lɪ̣ˠ?) R69 1.66lɔ̣ (or lọˠ?) R74 1.71
The absence of l- + Grade II retroflex rhymes may indicate that Tangut Grade II was conditioned by *r as in Chinese.
(I use Ł as the capital version of IPA ɫ. Ł is [ɫ] as in Belarusian Łacinka rather than [w] as in Polish.)
In "Liu or Lưu?", I wrote,
EMC *-u normally breaks to *-iw, but why would it break to *-ɪw or *-ɨw after *l-? Perhaps northwestern *l was a velarized *[ɫ]. It would be easier to pronounce a less palatal *ɪ or a nonpalatal *ɨ after *[ɫ].
I should have written that northwestern *l might have been *[ɫ] in Grade III, and possibly Grades I and II as well:
| Grade | I | II | III | IV |
| Middle / Tangut Period Northwestern Chinese */l/ allophone | *[l] | *[l] or *[ɫ] or even *[ɭ]? | *[ɫ] | *[l], *[lʲ], or *[ʎ]? |
| Examples from Yunjing table 37 (with 顟 from table 25 since there is no Grade II */l/-initial syllable in 37) | 樓 | 顟 | 劉 | 鏐 |
| My Late Middle Chinese reconstructions | */ləw/ | */læw/, */laˠw/, or */laʳw/ | */lɨw/ | */liw/ |
Grade I was associated with nonpalatal vowels so its allophone was probably neutral *[l].
Grade II might have been associated with velarized vowels preceded by velarized *[ɫ]. But if Grade II was associated with some nonvelar feature (e.g., retroflexion), its allophone could have been neutral *[l] or retroflex *[ɭ].
Grade III was associated with velar vowels *u and *ɨ, so its allophone was probably velar *[ɫ].
Grade IV was associated with the palatal vowel *i, so its allophone was nonvelar and could have been neutral *[l], palatalized *[lʲ], or palatal *[ʎ].Next: Could there have been similar allophony of /l/ in Tangut?
Until last night, I had been mistyping the reading of
TT2500 R46 1.45 'the Chinese surname 劉 Liu'
as liw instead of lɨw.
In my revision of Gong's Tangut reconstruction, R46 -ɨw is Grade III and less palatal than Grade IV R47 -iw.
Other reconstructions of these two rhymes and their relatives within Gong's rhyme group IX are very different:
|
Rhyme |
R44 | R45 | R46 | R47 | R48 | R49 | R93 | R94 |
| Grade (on this site) | I | II | III | IV | I | III | I | III |
| Correspondences with Middle Chinese rhymes organized by grade (Nishida 1964: 54-55; reconstructions mine) | I: *-aw, *-əw, *-ək, *-ok | I: *-ak | I: *-əw | I: *-ək | I: *-ək | I: *-əw | ||
| II: *-æk, *-ɛk | II: *-æ | |||||||
| III: *-ɨæŋ, *-ɨt | III: *-u, *-uk |
III: *-u | III: *-u | III: *-u | ||||
| IV: *-iew, *-u, *-uəj, *-it, *-en, *-ieŋ, *-eŋ | IV: *-iew, *-it | IV: *-it |
||||||
| Tibetan transcriptions (stats from Tai 2008) |
-i (22) -iH (16) -e (2) -a, -o (1 each) |
(none known) | -iH (5) -i (2) -ing, -uH, -eH (1 each) |
-i (9) -iH (9) |
-i (10) -iH (7) -u (1) |
(none known) | -i(13) -iH (1) -ing (1) |
-iH (1) |
| Kychanov and Sofronov 1963 | -ы̂ | -jы̂ | -ê | -jê | -ɘ | |||
| Nishida 1964 | -əw | -ew | -jəw | -jew | -iw | -jəʳ | -jʉʳ | |
| Hashimoto 1965 | -ääw | -äw | -jäw | -jääw | -əw | -jəw | -eew | -ew |
| Sofronov 1968 | -eɯ | -êɯ | -jeɯ | -əɯ | -jəɯ | -ẹɯ | -ə̣ɯ | |
| Huang Zhenhua 1983 | -ɑu, -au | -ia (sic!) | -iau | -eu | ? | -əu | -iəu | -ieu |
| Li Fanwen 1986 | -əw | -jəə (sic!) | -jəw | -iəw | -ə̌w | -jəo | -jəə (same as R45 and LFW's R100!) | -ạ, -jə̣̣ |
| Gong Hwang-cherng 1997 | -ew | -iew | -jiw | -eew | -jiiw | -eʳw | -jiʳw | |
| Arakawa 1999 | -eu | -jew | -eu: ([eeu] or [euu]?) | -eu' | -jeu' | -eʳ | -jeʳ | |
| This site | -ew | -ɛw | -ɨw | -iw | -eew | -iiw | -eʳw | -iʳw |
(9.26.1:13: Added R93-R94. Note the absence of -Vw rhymes with tense vowels in Gong's reconstruction and my revision of it.)
I don't believe in any reconstruction at this point, including my own. None really fit the Chinese or Tibetan evidence very well, even if one keeps in mind that Tangut period northwestern Chinese had fewer rhymes than Middle Chinese. All I can say for sure is that no tangraphs with these rhymes were used to transcribe Sanskrit, so none of these rhymes can be constructed with Sanskrit vowels like -u(u), -o, etc.
If the Chinese surname 劉 were *liw in the northwestern dialect known to the Tangut, the name could have been borrowed as liw R47 1.46. But it wasn't, so I suspect that 劉 was *lɨw in both Tangut and TPNWC; cf. Sino-Vietnamese lưu [lɨw] based on late Tang southern Chinese. (Cantonese law may have a lowered reflex of LTSC *ɨ.)
There is no way to be sure whether *lɨw goes back to the Tang Dynasty. Sino-Japanese Kan-on ryuu < riu could go back to an Old Japanese period *riu or *rɨu.
Coblin (1994: 275-276) lists the Tibetan transcriptions of 劉 and its near-homophones in the pre-Tangut period:
劉 and 柳 lïHu (ï = 'reverse i')
流 liHu
留 leHu
Perhaps the i ~ e variation reflects a *lɪw with a vowel between high i and upper-mid e. Tangut -ɨw could have been an attempt to imitate a NW Chinese *-ɪw.
An *ɪ might have existed in closed syllables in southern Late Middle Chinese: e.g.,
劉 SLMC *lɪw > Sino-Vietnamese lưu, Cantonese law
林 SLMC *lɪm > *ləm > Sino-Vietnamese lâm [ləm], Cantonese lam 'forest'
Most modern NW dialects have mid vowels in those two morphemes (Coblin 1994: 275, 297):
劉 Xining liɯ, Lanzhou ɲiəu (leɯ in Karlgren's time), Pingliang leu, Xi'an liou (leu in Karlgren's time); cf. standard Mandarin liu [ljow]
林 Xining and Dunhuang liə̃, Lanzhou ɲiə̃ (leə̃ in Karlgren's time), Pingliang leə̃, Xi'an liẽ (leə̃ in Karlgren's time); cf. standard Mandarin lin
But it is not clear whether these modern forms really descend from TPNWC ?*lɪw and ?*lɪm or are descendants of (or by) later intruders (*?liw and ?*lim) from the east.
9.26.0:19: In the fifth century, 留 was used to transcribe Sanskrit ra, ru, rva, lu, lo (Coblin 1994: 275). (ra is anomalous, but rva can be thought of as ru-a). These transcriptions imply a northwestern Early Middle Chinese *lu. EMC *-u normally breaks to *-iw, but why would it break to *-ɪw or *-ɨw after *l-? Perhaps northwestern *l was a velarized *[ɫ]. It would be easier to pronounce a less palatal *ɪ or a nonpalatal *ɨ after *[ɫ].
9.26.0:51: The correspondence of TPNWC ?*ɪ and Tangut ɨ is reminiscent of the correspondence between Ukrainian и ([ɪ], not [i]!) and Russian ы: e.g., Uk син : Rus сын 'son'. Of course, the TPNWC-Tangut correspondence involves borrowing, whereas the Uk-Rus correspondence is genetic.
The short answer is no.
I would like to believe that the Tangraphic Sea analysis
+
+
TT2500 lɨw R46 1.45 'the Chinese surname 劉 Liu' =
(top of) TT2505 ʒiẹ R64 2.54 'a surname; alone' +
(bottom of right) TT3659 ɣwiã R27 1.26 'a surname; transcription tangraph' +
right of TT5716 tsəʳi R82 1.77 'land, soil'
is valid, even though it does not seem to make any sense yet. If this is a purely graphic fanqie with no semantic or phonetic significance, I fail to see why such 'analyses' are in Tangraphic Sea. Tangraphs tend to be complex and anyone can take them apart in various ways. Is the breakdown of TT2500 into
+
+
valid: i.e., does it reflect the intent of the character's creator, or is it purely arbitrary?
Let's suppose that the Tangraphic Sea analysis is invalid (which begs the question of why it was included at all) and that TT2500 is really composed of parts from other tangraphs. What might those other tangraphs be?
If I were to design a tangraph for the Chinese surname Liu, I would combine a phonetic element pronounced something like Liu with a semantic element like
'person' or 'clan'
but obviously TT2500 is not such a compound. TT2500 lacks those elements. It also has no exact homophones, and its near-homophones were written with very different components:
| Tangraph | Tangut Telecode | Reconstruction | Rhyme | Tone.rhyme | Gloss (Li Fanwen 1997) | Structural notes |
 |
0687 | lɨw | R46 | 2.40 (not 1.45 like the surname) | gather; mass | why is 'wood' on top and TT3301 ʃiẽ R43 2.37 'sage' (< Chn 聖) on the bottom right? |
 |
3296 | pull; drag | why is 'grass' on the left? | |||
 |
4193 | limit; 盡 to the utmost; 底 bottom | why is 'water' on the top left?; 'earth' on the bottom resembles 皿 in 盡; TT4192 si R11 1.11 'limit end' is similar but lacks 'earth' |
There are no tangraphs pronounced lɛw R45, and none of the 14 lew R44 tangraphs contain any of the components of TT2500.
The left side of TT2500
may be completely unique. If it is derived from other tangraphs, it must be split into
from two different source tangraphs.
Since 劉 Liu has other meanings in Chinese, I wondered if TT2500 could consist of parts taken from tangraphs with those other meanings:
1. 'ax'(TT5347 added 9.25.1:32.)
| Tangraph | Tangut Telecode | Reconstruction | Rhyme | Tone.rhyme | Gloss (Li Fanwen 1997) |
|
|
2600 | wị | R70 | 1.67 | ax; hatchet |
|
|
4315 | tseʳw | R93 | 2.78 | |
 |
5347 | piẹ̃ | R65 | 1.62 | weaponry; a battle ax used in ancient China (鉞) |
The first and second tangraphs contain the element
'metal'
which is inside the left-hand element
TT2599 ʃiõ R58 1.56 'iron'
in TT2600.
The right side of TT2600 is from
TT2409 wɨi R10 1.10 'spend; dispatch; benefit from'
according to Tangraphic Sea.
The meaning of Li Fanwen radical 002
on the left side of TT4315 is unknown, though the top right element is
'wood' (what is cut by an axe?).
2. 'kill'
None of these tangraphs have any components in common with TT2500:
| Tangraph | Tangut Telecode | Reconstruction | Rhyme | Tone.rhyme | Gloss (Li Fanwen 1997) |
 |
0328 | dzɨəʳ | R92 | 1.86 | kill; chop |
 |
0981 | ʃi | R11 | 2.10 | kill |
 |
5016 | sia | R20 | 1.20 | kill; slaughter |
 |
5387 | ʔieʳ | R79 | 2.68 | eliminate; kill (Guillaume Jacques' Cixiao translation also has enlever 'remove' and se répandre 'spread') |
 |
1618 | ʔiʳ | R84 | 2.72 | chip; kill |
The function of Li Fanwen radical 003
in TT1618 is unknown (beyond distinguishing it from TT5387).
劉 Liu has a third non-name meaning: 枝葉稀疏、零落 'branches and leaves being sparse, withered, and fallen' (from dict.variants.moe.edu.tw). I am not going to try to find tangraphic equivalents for that definition. I will simply point out that the tangraphic 'plant' elements
'wood' or 'grass'
do not appear in TT2500.
08.9.23.23:59: LlU: NOT THE ONLY REMAINING EXPLANATION?
Last night I had a hard time expressing why I am skeptical of sinographic explanations for tangraphs. Tonight I realized that such explanations are difficult to disprove. Given enough imagination and the ability to rearrange, mirror-image, or distort sinographic elements at will, a sinographic 'origin' could be devised for any tangraph. An explanation that always 'works' doesn't really work.
No explanation of
TT2500 lɨw R46 1.45 'the Chinese surname 劉 Liu'
satisfies me:
1. My attempt to derive it from a variant of a homophone of 劉 is convoluted, though at the moment I think it's more likely than the other explanations below..
2. The semantic compound analysis implied by Tangraphic Sea makes no sense:
TT2500 lɨw R46 1.45 'the Chinese surname 劉 Liu' =
(top of) TT2505 ʒiẹ R64 2.54 'a surname; alone' +
(bottom of right) TT3659 ɣwiã R27 1.26 'a surname; transcription tangraph' +
right of TT5716 tsəʳi R82 1.77 'land, soil'
What do the Liu have to do with the non-Chinese Zhie (or 'alone'), the Ghwia (< a Chinese surname like 袁? 元? 阮? [all transcribed by TT2505]), and/or 'land, soil'?
The TS analysis cannot be phonetic (without resorting to Tangut B; see below) because TT2500 does not sound anything like these three tangraphs.
Yet I find it hard to believe that TS has a spurious nonsemantic and nonphonetic analysis for TT2500 and many other entries. Unlike Shuowen, TS was written when the origin of tangraphy was still in living memory so I would hope that its analyses would tend to be valid.
3. If Tangut B existed, TT2500 would have a second (nonmonosyllabic?) reading represented by the three graphemes implied by the TS analysis:
But what would this other reading be? A native name somehow associated with Liu - perhaps a translation of one of 劉's other meanings ('axe; kill')? This is not entirely implausible: e.g., the sinograph 林 can represent
- the Chinese surname Lin (and its variants: Korean Im and Vietnamese Lâm)
- the noncognate Japanese surname Hayashi (which means 'forest' like Lin, etc.)
Since there is no transcription evidence for a second reading of TT2500, the only way I could demonstrate that such a reading existed would be to find patterns like this:
In a hypothetical language X attested in or near the lands of the Tangut Empire:
- katas 'axe' and dika 'meaning 1' have a syllable ka in common.
- katas 'axe' and tagu 'meaning 2' have a syllable ta in common.
- katas 'axe' and pibus 'meaning 3' have a final -s in common.
In Tangut:
- the tangraph meaning dika has the first element of TT2500 in second position
- the tangraph meaning tagu has the second element of TT2500 in first position
- the tangraph meaning pibus has the third element of TT2500 in final position
Such correspondences between tangraphic elements and syllables or segments in another language would imply that this other language was a relative of Tangut B, and that TT2500 had another reading cognate to katas in language X.
However, no such correspondences have ever been found (not that anyone has ever really tried to look).
Since tangraphy consists of hundreds of recurring elements - too many for an alphabet - Kwanten and Janhunen concluded that each tangraph represented a polysyllabic word in what I would call Tangut B. The most likely candidate for a relative of Tangut B is Uighur. Although Uighurs lived in the Tangut Empire, I have never heard of Uighur loanwords in Tangut.* Could this be because polysyllabic (para-)Uighur words underlie tangraphic structure? I doubt that.
My worst fears are
- that Tangut B is a genetic isolate with no relatives and no written form other than tangraphy - i.e., no transcriptions
- or that tangraphy really is full of arbitrary line patterns and that I'm wasting my time searching for structure where there is none
If anyone has a more credible fourth explanation of TT2500, I'd love to hear it!
*Nor does there seem to be anything like the Tibetan loanword stratum in rGyalrong. Perhaps some Tibetan loans in Tangut have been misidenitified as native.
08.9.22.23:52: LlU: THE ONLY REMAINING EXPLANATION?
I remain puzzled by
TT2500 lɨw R46 1.45 'the Chinese surname 劉 Liu'
because I refuse to believe that it is a pattern of 11 lines chosen at random to correspond to the sinograph 劉.
I am hesitant to derive it from a sinograph because it is too easy to find vague resemblances between Tangut and Chinese characters: e.g., both TT2500 and 劉 have a complex left element and a simple right element.
TT2500 does not look like any of these variants of 劉. Nor it does resemble any of the sinographs that it transcribed:
留榴流琉 Tangut period NW Chinese ?*liw < Middle Chinese *lu
homophones of 劉
柳 Tangut period NW Chinese ?*liw < Middle Chinese *luʔ
homophonous with 劉 except for its tone
繚 Tangut period NW Chinese ?*liaw < Middle Chinese *lew
Tangut had no syllable liaw, so lɨw was the closest available match
婁 Tangut period NW Chinese ?*ly or ?*ləw
I would not expect either syllable to be transcribed with lɨw; more on this problem later
However, the left side of TT2500 does resemble some variants of 留 TPNWC ?*liw 'remain'. One variant of 留 has ソ on the top like TT2500. The コ of TT2500 could be a 刀 turned 90 degrees clockwise. The bottom is an opened up 田. The right side could be derived from one of the top right elements of some of those variants (乙匕巳). I might be more convinced if I could find a variant of TT2500 with
next to each other atop
But that's unlikely, as I know of no tangraph which has
in the upper right position. With two exceptions
(no TT number)
which has a variant
TT0262 ?paʳ R85 2.73 'piebald horse'
(unknown labial initial; my guess is p- if the word was borrowed from 駁 Middle Chinese *pæwk 'piebald')
(the right-hand dot in the Mojikyo font is absent from Sofronov 1968, Li Fanwen 1997, Han Xiaomang 2004, and Kychanov 2006, so it may be an error)
and their possible homophone
TT0688 ?Pie R37 2.33 (unknown labial initial)
(but listed as ?pæʳ R85 2.73 in Precious Rhymes of the Tangraphic Sea 2.16.1608!)
is always in absolute right position with nothing above or below it.
Although
TT5716 tsəʳi R82 1.77 'land, soil'
has no other known derivatives with
so its E-like element
cannot be analogous to the right-hand element 阝 in names like 鄭 Zheng and 鄧 Deng (but not 劉 Liu 'axe; kill' which has 刀 'knife' on the right!), I did find that the aformentioned
is the source of the bottom of
TT1892 gəəu R5 1.5 'treasure'
according to Tangraphic Sea (1.11A53). Note the nonmatching middle elements:
The top of TT1892 is from
TT1798 kụ R62 1.59 (a surname)
which has a phonetic consisting of 'finger' with a line on top and 'bird'
TT1064 kụ R62 1.59 (second half of dʒuõ kụ 'parrot')
beneath a 'horned hat'.
08.9.21.22:12: LIU: A SURNAME OF THE SOIL?
In "Finger Bottom Fanqie?", I mentioned but did not show the tangraph for the Chinese surname 劉 Liu (also 'axe; kill') which has the following analysis (Tangraphic Sea 1.54.B32):
TT2500 lɨw R46 1.45 'the Chinese surname 劉 Liu'
(top of) TT2505 ʒiẹ R64 2.54 'a surname; alone' +
(bottom of right) TT3659 ɣwiã R27 1.26 'a surname; transcription tangraph' +
right of TT5716 tsəʳi R82 1.77 'land, soil'
None of the three source tangraphs sound like lɨw, so none are presumably phonetic (unless Tangut B exists).
The analysis of the left side into two parts
=
suggests that Li Fanwen radical 292 is not a single unit. LFW radical 292 is apparently unique to TT2500.
This analysis also suggests that LFW radicals 377 and 137 are also not single units:
=

=
+
The right sides of TT2500 and TT5716 do not match:
Is the difference really significant? Are there any minimal pairs which are identical except for the direction of the top right stroke? Kychanov's dictionary distinguishes them as B257 and B258. (B signifies a vertical right-hand element.)
(This post would not be possible without Andrew West's wonderful BabelStone Tangut Radicals font. Andrew's creation can be seen throughout my posts from the past four months, but this post uses it more than any other that I can remember. Thanks, Andrew!)




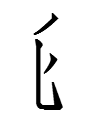


















{kind=link}