



08.9.20.23:45: FINGER BOTTOM FANQIE?
In "Who's Who in xʊ?", I proposed that
could be fanqie tangraphs with the structure
+
x- (LFW radical 140; looks like 'finger' over 'below') +
abbreviation of a tangraph chosen for its rhyme
However, I could not find any tangraphs with
and an R4 rhyme like
TT2638 xʊ R4 1.4 (second half of the surname nie xʊ)
other that TT2638 and its derivative
TT0814 xʊ R4 2.4 (a kind of tree)
with 'wood' on top.
What about the other three tangraphs?
1. The surname syllable xwəi
TT2130 xwəi R8 2.7 ([a part of] a surname)
shares its right side with
TT0582 tshwiu R3 1.3 'boil; make cook'
which has a different rhyme.
No -wəi tangraph has LFW radical 374
which only occurs once on the left in
TT4867 dziəə R33 2.29 'practice; exercise; review'
2. 'Han Dynasty'
TT2639 xã R25 2.22 'Han Dynasty'
has a right-hand element
found only in
TT4673 ləu R1 1.1 'stove; furnace' (loan from Chn 爐)
which does not have R25 and has nothing to do with the Han Dynasty.
(9.21.0:27: The only connection I can imagine is the surname of the founder of the Han: 劉 Liu. But this surname was borrowed into Tangut as TT2500 lɨw R46 1.45.)
3. 'hum'
TT2640 xəʳ R90 2.76 'hum'
has the right-hand element
'water'
which could be from\
TT1647 zəʳ R90 2.76 'dew'
or its homophonous derivative
TT0756 zəʳ R90 2.76 'sugar cane'
with Li Fanwen radical 102 'wood' on top
'Hum' may be a fanqie tangraph (which is what I'd expect for a character representing a noise), but the others cannot be purely phonetic (unless Tangut B is real).
TT2638 xʊ R4 1.4 (second half of the surname nie xʊ)
the tangraph used to transcribe Chinese 湖 'lake' and its (near-)homophones* has the unhelpful Tangraphic Sea analysis (1.10B61):
+
TT2638 xʊ R4 1.4 (a surname) =
bottom of TT0814 xʊ R4 2.4 (a kind of tree) +
left of TT5615 rieʳ R79 2.68 (a first or second syllable in several surnames)
It's more likely that TT0814 is a derivative of TT2638 than the other way around. TT0814 has TT2638 as a phonetic beneath Li Fanwen radical 102 'wood':
The 'wood'-like element on the bottom of both TT2638 and TT0814 is LFW radical 189 'below, bottom' (def. from Gong, "Chinese Elements in the Tangut Script", p. 179; cf. Chn 土 'earth'):
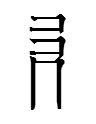
There is no tangraph consisting of the top left and right parts of TT2638 (LFW radical 139 [defined by Nishida 1966: 244 as 'finger'; cf. TT2622 'finger' with a 'filler' vertical line] and LFW radical 063 [meaning unknown]):
Perhaps the top left and bottom parts consitute a unit (LFW radical 140)
also found on the left of
TT2130 xwəi R8 2.7 ([a part of] a surname)
why do Shi et al. (2000: 211) think this might have been pronounced like 红 whose rhyme is nothing like -wəi?
TT2639 xã R25 2.22 'Han dynasty'
TT2640 xəʳ R90 2.76 'hum'
Shi et al. (2000: 310) gloss: 鼻音 'nasal sound'
and the right of
TT5390 kạ R66 2.56 'equality'
All but TT5390 have initial x-. Could LFW radical 140 be derived from a similar-looking sinograph with initial *x-: e.g., 壺? Do the elements to the right of LFW radical 140 represent rhymes? I cannot find any R4 tangraph with LFW radical 140 on the right.
Is TT5390 completely unrelated? It looks like
TT5389 'alike' ka R17 1.17
atop 'below, bottom'.
It's a shame that all the LFW radical 140 tangraphs other than TT2628 have unknown analyses.
Note, however, that TT2638 and TT5390 have LFW radical 139
which has a フ-shaped third stroke whereas LFW radical 140
has a horizontal third stroke. I don't know if this difference is significant.
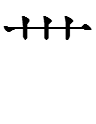
The function of LFW radical 063

in
TT2638 = x- + ?and
the source of the top right of TT2638, is unknown.
TT5615 rieʳ R79 2.68 (a first or second syllable in several surnames)
Is it a coincidence that both tangraphs in the surname
TT0641 2638 nie R37 1.36 xʊ R4 1.4
have radical 139?
*Homophones of 湖 'lake' transcribed by TT2638:
胡瑚蝴葫壺狐斛 (lower level tone)
Near-homophones transcribed by TT2638:
乎 (unclear if this had upper or lower level tone in Tangut period northwestern Chinese)
虎琥 (rising tone)
戶 (departing tone)
鶴鵠霍 (entering tone)
艹+瓠 (tone unknown; is this in Unicode?)
is a pseudoanalysis of the sinograph 湖 'lake' that sounds as meaningful as some tangraphic (mis)analyses:
氵 'water' + 古 'old' + 月 'moon'
The real analysis is
氵 'water' + phonetic 胡 'dewlap' (also used for a number of homophonous syllables: 'how', the first half of 'butterfly', 'northern barbarian', etc.)
and 'dewlap' in turn is
phonetic 古 'old' + 月 'flesh' (abbreviation of 肉 that looks like 月 'moon')
The sound of 湖 'lake' and its phonetic 胡 in Tangut period northwestern Chinese was transcribed by the tangraph
TT2638 xʊ R4 1.4 (a surname)
Li Fanwen (1997: 381) defined
TT4297 pho R51 1.49
as 'lake' in English, but this might be an error, since Li Fanwen, like Gong (西夏語中的漢語借詞, p. 691), regards the word as a loan from 泊 'swamp, marsh'. Nishida (1966: 418) has 泊る 'to stop at a place', 湖 'lake'. Grinstead's (1972: 107) gloss is 'puddle' which is quite different in scale from a lake or marsh. The Tangraphic Sea definition is
pho tia wəiʳ lia
'pho TOPIC rain fall' = pho 者雨降
zɨɨʳ reʳ je jɨ
'water ditch GEN say' = 水溝之謂
i.e., a pho is a ditch for rainwater. I don't think a ditch is very much like a lake or a marsh. A ditch is manmade whereas lakes and marshes are natural. Li Fanwen 1997 has no examples of TT4297 as 'lake' from a text. Nevsky 1960 has no entry for TT4297.
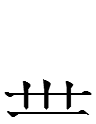
Like 湖 'lake', TT4297 has 'water' on the left side:
=
+
+
TT4297 pho R51 1.49 =
left of TT4282 zɨɨʳ R100 2.85 'water' +
center of TT4296 ʔwɔ̣ R74 1.71 'round' +
right of TT4487 khwị R70 2.60 'circle'
(rhyme in Precious Rhymes of the Tangraphic Sea but absent from Li Fanwen 1997)
is probably derived from Chinese 氵 'water' (Grinstead 1972: 56):
I propose that it [Tangut 'water'] is the same sign [as Chn 氵] with the direction of the last two strokes reversed. The Chinese has two S.E. pushes of short duration, and a longish tick to the N.E. The Tangut has the first S.E. [does he mean SW?] stroke preceded by an approach, then a link with the next S.E., with a lift to NE., then a S.W. hook.
I don't understand why the tangraph for 'water'
isn't 'water' plus a simpler filler element (or why some but not all elements need 'fillers' in the first place). Unfortunately, no analysis of 'water' is known, so the rationale for its complex right side is obscure. Two unwatery (dry?), nonhomophonous tangraphs share the right side of 'water':
TT1472 kɛ R35 1.34 '矮 short' (Kychanov 2006.1949 also has 'низкий, low')
with LFW radical 023 'not' on the left
TT1670 puõʳ R98 2.83 'luxuriant, exuberant' (Kychanov 2006.1950 also has 'расти, grow')
with LFW radical 294 on the left as phonetic?
cf.
TT5814 phəu R1 2.1 'tree'
which is phonetically similar though its horizontal strokes are longer than the left side of TT1670:
Today is the 82nd birthday of Joe Kubert, a great American comic book artist and founder of the Joe Kubert School of Cartoon and Graphic Art. He was born in Yzeran, a name that caught my eye because its initial Y- looked un-Polish. (My Polish dictionary has no entries with y- and this database of Polish surnames has no entries with Yz-.)
It turns out that Yzeran is one of many names for the same place.
One of those names is Озеряни which is quite common in Ukraine. Kubert's birthplace (the Озеряни in Борщівський район) has a very short Wikipedia entry with a long URL.
Another name is Озерная which looks like the feminine of the Russian adjective 'lake'.
Are all the various names ultimately cognate to 'lake': Russian and Ukrainian озеро, Belarusian возера (< *-o), Bulgarian езеро, Old Church Slavonic ѥзеро, Serbo-Croatian, Slovenian, and Czech jezero, Slovak jazero, Lower Sorbian jazor, Upper Sorbian jezor, Polish jezioro, etc.? (Sources: Vasmer and slounik.org, plus some double-checking in print dictionaries.)
9.19.1:50: I don't understand what's going on with the first and second vowels:
| Subgroup | Language | First vowel | Second vowel |
| East Slavic | Russian | o | e |
| Belarusian | |||
| Ukrainian | |||
| South Slavic | Old Church Slavonic | e | |
| Serbo-Croatian | |||
| Slovenian | |||
| Bulgarian | |||
| West Slavic | Czech | ||
| Polish | o | ||
| Upper Sorbian | |||
| Lower Sorbian | ja (presumably < *je) | ||
| Slovak | e |
Eastern languages have o-e* and southern languages have e-e, but there's no single pattern for the western languages.
Meanwhile, in Baltic, LIthuanian has ežeras and Latvian has ezers with e-e.
I would not want my students to try to reconstruct the proto-Slavic (much less Proto-Balto-Slavic) word for 'lake'.
*I am following orthography rather than actual pronunciation. Russian озера is [ózʲɩrə], not [ozera].
9.20.12:28: Here's a revised version of the table for 'lake' based on syllables:
| Subgroup | Language | First syllable | Second syllable (CV- only; codas ignored) |
| East Slavic | Belarusian | vo | ze |
| Ukrainian | o | ||
| Russian | |||
| South Slavic | Bulgarian | e | |
| Old Church Slavonic | je | ||
| Serbo-Croatian | |||
| Slovenian | |||
| West Slavic | Czech | ||
| Polish | zio [ʑo] | ||
| Upper Sorbian | zo | ||
| Lower Sorbian | ja (presumably < *je) | ||
| Slovak | ze |
Polish zio is like a compromise between ze and zo.
08.9.18.8:00: IS CHEMISTRY GEOLOGY?
The etymology of chemistry has its own Wikipedia page!
In East Asia, 'chemistry' is 化學, the 學 study of 化 changes. (The 易經 Yijing 'Book of Changes' has a different morpheme for 'change': 易.)
In Japanese, 化學 kagaku 'chemistry' happens to be homophonous with 科學 kagaku 'science', the 學 study of 科 classes. 化學者 'chemist' and 科學者 'scientist' are also homophonous. (-者 -sha is 'person'.)
At first, I thought a Tangut calque for 化學 'chemistry' could be
TT0391 kiiʳ R101 2.86 化 'change' (Li Fanwen 1997 has no other tangraphs with 化 as a primary meaning)
TT3861 ɣɛw R45 1.44 學 'study' (a loanword from Middle Chinese 學 *ɣæwk 'study')
But Shi et al. (2000: 317) defined TT0391 as 溶 'dissolve' and Kychanov 2006.5683 defined it as 'масло, oil, 油'. I'll try to come up with a safer calque later. If anything, this may show the lack of consensus on Tangut semantics.
I can't find any Tangut equivalent of 科 'class' in Li Fanwen 1997, so perhaps a translation of 類 'kind, type' could take its place in a calque for 科學 'science':
TT4143 diẹ R1.64 1.61 類 'kind, type'
TT3861 ɣɛw R45 1.44 學 'study'
TT4143 corresponds to Chn 類 in the Tangut translation of 類林 The Forest of Classes:
TT4143 diẹ R1.64 1.61 類 'kind, type'
TT2968 bo R51 1.49 林 'forest' (also 隊 'formation, a row of people' < 'a forest of people'? and 榭 'pavilion' [why?])
lit. 'elixir science', has a Sanskrit Wikipedia entry that starts with three English sentences! So why was I upset about a few English loanwords?
I don't know the etymology of rasaayana 'elixir', but it looks like a compound of rasa 'dew' and ayana 'going'*. Monier-Williams lists a meaning 'a canal or channel for the fluids' for feminine rasaayanii: '(where) the fluid (dew) goes'? Cf. raamaayaṇa 'the Ramayana' < 'the goings of Rama'. (The r- of raamayaṇa conditions the shift of -n- to retroflex -ṇ- in -ayaṇa. The -s- in rasaayana blocks the retroflexion of -n-.)
*From ai (vṛddhi grade of √i 'go') + -ana.08.9.17.8:00: ЭЛЕМЕНТЫ С САНСКРИТСКИМИ ИМЕНАМИ
Sanskrit shows up in the most unexpected places:
To give provisional names to his predicted elements, Mendeleev used the prefixes eka-, dvi-, and tri-, from the Sanskrit words for one, two, and three, depending upon whether the predicted element was one, two, or three places down from the known element in his table with similar chemical properties.
The cognates of dvi- and tri- are obvious, but eka (< *aika) is the odd man out. Even Sanskrit's sister Avestan has aeeva instead of aeeka. Neither have the nasal found in Latin unus or English one. The common Proto-Indo-European root was something like *oi-. (I don't understand why Beekes [1995: 212, 214] reconstructed an initial laryngeal *H-.)
08.9.17.7:41: MONIER2 WILLIAMS
I've been using Monier-Williams' dictionary for 16 years, but I knew almost nothing about him until I found his Wikipedia entry yesterday:
Indian studies in England were dominated by the demands of government and Christian evangelism, in ways that might be considered unacceptable in an academic environment today.
"Might"? More like 'would'!
Monier-Williams declared from the outset that the conversion of India to the Christian religion should be one of the aims of orientalist scholarship.
Whoa! That was certainly not true when I took Sanskrit a century later!
... he adopted his Christian name of Monier as an additional surname.
Why did he give himself another surname? I've never heard of any other case of X Y becoming X X-Y.
I forgot to mention one more problem with Sanskrit sorsa in my previous entry: s should become retroflex ṣ after r, so the word should be sorṣa.
Exceptions to the 'ruki rule' are loanwords like Bṛsaya, name of a demon or sorcerer in the Ṛgveda. (Michael Witzel examines such loanwords in "Early Sources for South Asian Substrate Languages".) I could make sorsa yet another exception, but I enjoy Sanskritizing words.
Whoever came up with sorsa probably meant it to be an a-stem. That would be fine, but it would also be boring, since the consonants of the root sors (or sorṣ) would be unchanged throughout the paradigm and most of the forms would have (what else?) -a-:
| Stem sorṣ- (m.) | Singular | Dual | Plural |
| Nominative | sorṣas | sorṣau | sorṣaas |
| Accusative | sorṣam | sorṣaan | |
| Instrumental | sorṣeṇa | sorṣaabhyaam | sorṣais |
| Dative | sorṣaaya | sorṣebhyas | |
| Ablative | sorṣaat | ||
| Genitive | sorṣasya | sorṣayos | sorṣaaṇaam |
| Locative | sorṣe | sorṣeṣu | |
| Vocative | sorṣa | sorṣau | sorṣaas |
The neuter paradigm would be almost identical except for three differences:
1. The nominative/accusative/vocative singular would be sorṣam.2. The nominative/accusative/vocative dual would be sorṣe.
3. The nominative/accusative/vocative plural would be sorṣaaṇi.
I would rather create a new -rṣ subtype of the consonantal declension blending features of the existing -r and -ṣ-stem declensions:
| Stem sorṣ- (m. or f.) | Singular | Dual | Plural |
| Nominative/Vocative | sor < sorṣ-s | sorṣau | sorṣas |
| Accusative | sorṣam | ||
| Instrumental | sorṣaa | sorḍbhyaam | sorḍbhis |
| Dative | sorṣe | sorḍbhyas | |
| Ablative | sorṣas | ||
| Genitive | sorṣos | sorṣaam | |
| Locative | sorṣi | sorṭsu |
sorṣ-s (nom. sg.) is reduced to sor since final consonant clusters are not permitted in Sanskrit. sor then becomes soḥ before a pause or voiceless grave stopes (k, kh, p, ph). This is the only respect in which sorṣ- declines like an -r stem: cf. giiḥ < giir < giir-s 'song'. In all other cases, sorṣ- declines like an -ṣ stem such as dviṣ -'enemy'.
Stem-final ṣ becomes voiceless ṭ before s (to avoid the sequence -ṣs-) and voiced ḍ before bh.
If sorṣ were neuter, only a few forms in the above paradigm would have to be changed:
1. The accusative singular would be identical to the nominative/vocative singular.
2. The nominative/accusative/vocative dual would be sorṣii.
3. The nominative/accusative/vocative plural would be sorṇṣi with an -ṇ- inserted into the stem.
Not 100%, unfortunately.
When I upgraded to a Windows 95 desktop back in 1996, I decided to name my folders in Sanskrit. To this day, the pages on my site are stored in a folder called 'Jala' < Skt jaala 'web'. Other names that I've used over the years are
Bhasha < bhaaṣaa 'language' for linguistics pages
Katha < kathaa 'story' for fiction
Pattra < pattra 'letter' for correspondence
Rupa < ruupa 'image' for art
Shabda < śabda 'sound' for sound files (mostly music)
Since then, I've been wondering how Sanskrit could be adapted to today's world. The Sanskrit Wikipedia embodies one solution: fall back on English and Hindi. For example, view source was translated as सोर्स देखें sorsa dekheṃ 'source see' instead of, say, muuladarśanam 'root-seeing'. sorsa isn't even inflected; it should be sorsaṃ (accusative singular). And dekheṃ is Hindi; dekh- is ultimately from the Sanskrit s-aorist stem dṛk-ṣ- ~ draak-ṣ- (< √dṛś*; Turner, A Comparative Dictionary of the Indo-Aryan Languages, p. 371). I suspect that the Sanskrit Wikipedia is based on the Hindi Wikipedia and that some Hindi placeholders remain untranslated.
*I don't understand how e developed from ṛ ~ raa. The only path I can think of is ṛ > *ri > *i > e. Are there other examples in Hindi?
Although I first mentioned the Sanskrit version of Wikipedia in my last entry, I had meant to introduce it by linking to the first entry I had ever seen:
amuura uttara eśiyaa mahaadviipe ciina deśe ekaa nadii asti.
lit. 'Amur-NOM north Asia continent (lit. 'great island')-LOC China country-LOC one-NOM river-NOM is'
I couldn't help but want to rewrite it with compounding and sandhi:
अमूर उत्तरैशियामहाद्वीपे चीनदेश एका नद्यस्ति.
amuura uttaraiśiyaamahaadviipe ciinadeśa ekaa nady asti.
'The Amur is a river in the country of China on the north Asian continent.'
Notes on sandhi:
1. No change needed in amuura which presumably is from amuuras (masc. nom. sg.); -as becomes -a before another vowel.
2. uttara + eśiyaa = uttaraiśiyaa 'North-Asia'; -ae- is not permissible word-medially
3. The final -e of ciinadeśe becomes -a before a vowel other than a-.
4. The final -ii of nadii becomes -y before a non-i vowel.




























{kind=link}
{kind=link}