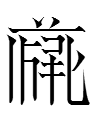
TT3717 (a surname) chyow 1.56
07.10.13.23:57: DID PROTO-KOREANIC HAVE TWO LIQUIDS?
I would say 'yes'.
The idea of two PK liquids has been around for some time.
Yi Kimun (1977) proposed that the Old Korean phonograms 乙 and 尸 represented Old Korean *l and *r. I would prefer reversing his proposed values to match the Old Chinese readings of those sinographs:
| Sinograph | OC | Yi (1977) | AMR |
| 乙 | *'rət | *l | *r |
| 尸 | *hli | *r | *l |
Ramsey (1996) proposed that Middle Korean verb stems ending in -l originally ended in different liquids.
Bentley (2000) looked at Paekche, an extinct Koreanic language, and found that Paekche liquids had three types of correspondences with Middle Korean:
P r : MK r
P r : MK y
P r : MK Ø
He thought the "data strongly suggest Paekche had preserved two liquids" (p. 435). One might even think it preserved three liquids: e.g., *l, *r, and a palatalized liquid. One might also think that both Paekche had a single liquid resulting from a merger of three PK liquids:
PK *L1 > P *r, MK r
PK *L2 > P *r, MK y
PK *L3 > P *r, MK Ø
Looking at the data in Bentley (2000), I think that Paekche either had two liquids, or had merged them into a single liquid. I see only two types of Paekche : MK correspondences. (Like Bentley, I will write all Paekche liquids as *r, even though Paekche may have had two liquids. I have modified Bentley's Paekche reconstructions slightly for reasons I will explain in future posts. Capital letters represent uncertain vowels: e.g., A = uncertain nonhigh, nonpalatal, nonlabial vowel.)
| 1. P *r : MK r | ||
| Gloss | Paekche | MK |
| 'fire' | *pAr | pɯr |
| 'high' | *mora | moro 'mountain' |
| 'mountain' | *mora-i | |
| 'moon' | *tAr | tʌr |
(10.14.6:56: I am not sure that Paekche 古尸 *?kor[i] actually meant 'valley', so I have removed that word from the list.)
I think Bentley's second and third correspondences can be combined into one:
| 2. P *r : MK Ø | ||
| Gloss | Paekche | MK |
| 'belt' | *sItOr(O) | stɯy |
| 'master' | *nIrIm | nim |
| 'stream' | *nari | nayh |
| 'thou' | *nəri | nə |
'Belt' is attested in a Japanese transcription sitoro. The -ro may have been an attempt to represent a Paekche final *-r or *-ro/-rə. Hence I have placed parentheses around the final *(O).
Bentley also cited 'black' and 'iron' as examples of correspondence 2, but I regard both as problematic, and will discuss them in separate posts.
In three of the four remaining examples of correspondence 2, Paekche r corresponds to zero before an MK front vowel or y. One could try to reconstruct a single PK liquid *r that remained in all environments in Paekche but lenited to zero before i and y in MK:
'belt': PK *sitVr > pre-MK *sitɯr-i > MK stɯy
'master': PK *nVrim > MK nim
'stream': PK *nari > pre-MK *nari-k > MK nay-h
But if this were true, we would expect
'thou': PK*nəri > MK nəy
instead of the actual MK nə which has no y. I suspect that Paekche -ri could be a genitive ending. I'll test this hypothesis later.
More problematic is the fact that MK has words with ri: e.g., tsari 'seat' (instead of tsay). There are two ways to explain such words:
1. Their ri comes from an earlier *ti
2. Their ri comes from PK liquid 1 + *i, whereas -i- and -y partly come from PK liquid 2 + *i.
According to Vovin, MK medial -t- comes from earlier clusters, and MK -r- comes partly from original *-t- between vowels. If this is correct, then there surely must have been PK words with a *-ti(-) which became -ri(-) in MK. If I were not aware of Yi (1977) and Ramsey (1996), I would propose that all ri in native MK words* come from *ti. However, if there were two PK liquids, it is possible that one lenited before pre-MK *i and the other did not:
| PK | Environment | Paekche | MK |
| liquid 1 | before any vowel | liquid 1 | r |
| liquid 2 | before all vowels other than *i | liquid 1 (or 2?) | Ø |
| before *i |
Next: Ramsey revisited.
*MK borrowings from Chinese containing ri generally do not come from *ti: e.g.,
tori 'reason' < 道理 Late Middle Chinese *dawli
cannot come from a pre-MK *toti. Such words imply that a pre-MK sound (?*l) similar to Chinese l did not lenite before i. Perhaps the following occurred:
Stage 1: PK *ri, *li, *ti all coexisted.
Stage 2: PK *ri became Old Korean *-i- medially and *-y word-finally, but PK *li and *ti remained intact in OK.
Middle Chinese *li-like syllables were borrowed as OK *li.
Stage 3: OK *li and *ti merged into MK ri.
An example of an MK borrowing from Chinese with ri from earlier *ti is
MK pori 'Bodhisattva' < pre-MK *poti < 菩提 Middle Chinese *bode < ult. Skt bodhi
(10.14.6:07: MK -i suggests a direct loan from Sanskrit. Even if Chinese were not involved, the point is that the ri of pori is definitely from a *ti of foreign origin.)
A similar instance with MK -ry- from earlier *-ty- is
tshʌryəy 'order' < pre-MK *tshʌtyəy < 次第 Late Middle Chinese *tshïdyey
07.10.11.23:54: A MUD-DY MYSTERY (PART 1)
In "Soundalike Surnames at Sea", I noted that Nishida radical 246, the right side of
TT3717 (a surname) chyow 1.56
was phonetic in six tangraphs for nyï-like syllables. r246 also may have had several other phonetic values.
Here is a complete list of all tangraphs containing on their left or right sides. (There may be some tangraphs with r246 in the middle, but I have no easy way to find them.)
r246 on the left:
| TT | Gloss | Gong's reconstruction | Rhyme | Syllable type |
| 2952 | BARBECUE | nywï | 2.28 | NYÏ |
| 2953 | (transcription tangraph) | nụ | 1.58 | NU |
| 2954 | SKILL | thu | 1.1 | THU |
| 2955 | CAMEL | kyaa | 1.21 | KYAA |
| 2956 | (fanqie transcription tangraph) | thwey | 1.33 | THU (left side taken from 2960) |
| 2957 | MOTHER-IN-LAW | nyï | 1.30 | NYÏ |
| 2958 | ?HUSBAND'S-MOTHER | ba | 2.14 | BA |
| 2959 | FATHER'S-SISTER | nyï | 1.30 | NYÏ |
| 2960 | ESTABLISH | thu | 1.1 | THU |
| 2961 | (Chinese surname 騰 ?*thẽ) | thẽ | 2.13 | THE |
| 2962 | (transcription tangraph for Skt ka) | kyaa | 1.21 | KYAA |
| 2963 | 惜 ?CHERISH | ba | 2.14 | BA |
r246 on the right (excluding a tangraph which has no TT [Grinstead 1972: 128.1.4]):
| TT | Gloss | Gong's reconstruction | Rhyme | Syllable type |
| 0039 | 至 REACH | thwo | 1.49 | THU |
| 0050 | PLACE-TOGETHER | we | 2.7 | WE |
| 1278 | EXCELLENT | tyiy | 2.33 | THE |
| 1745 | WEAKEN | dzəy | 1.40 | DZI |
| 1888 | 唆 INSTIGATE | dzyị | 2.60 | DZI |
| 1929 | 至 REACH | kio | 2.43 | KI |
| 1995 | (transcription tangraph for Skt kha) | khyaa | 1.21 | KYAA |
| 2498 | 至 REACH | khyiy | 2.33 | KI |
| 2506 | DRIP | gyirw | 2.79 | KI |
| 2525 | SHORT | wyịy | 1.61 | WE |
| 3168 | 慮 ?THINK | lhẹ | 2.58 | ? |
| 3671 | 至 REACH | nyï | 2.28 | NYÏ |
| 3717 | (a surname) | chyow | 1.56 | ? |
| 4507 | 悅 耳 PLEASING-TO-EAR | dywu | 1.3 | THU |
| 4632 | INFORM | nyị̣̈ | 1.69 | NYÏ |
| 4772 | 皆 至 ALL-ARRIVE | tshyi | 2.10 | DZI |
| 4820 | (plural marker) | nyï | 2.28 | NYÏ |
| 5724 | 高 HIGH / 上 UPPER | dzyị | 2.60 | DZI |
r246 seems to have had nine (!) different archetypal phonetic values (phonotypes) which I will represent in capital italics:
BA, DZI, KYAA, KI, NU, NYÏ, THE, THU, WE
Each phonotype resembles the readings of two or more tangraphs.
The only phonotype that jumped out at me when I wrote the last line of the previous post was DZI. However, after looking at all the readings, it's clear that NYI and DZI are not alone.
Today I
realized that r246 vaguely resembles 尼 Tangut period northwestern
Chinese *ñji 'nun', whose pronunciation
is not far from DZI or NYÏ.
Adding 'water' to 尼 results in 泥 TPNWC *nde 'mud' which is close to THE.
One Tangut word for 'mud' is TT2869 nu 1.1 (not written with r246!). This would explain why r246 had another phonotype NU.
Other Tangut words for 'mud' are TT4256 chior 1.90 and TT4258 chior 2.81 (neither written with r246!). Could r246 be representing a phonotype CHIO in TT3717 chyow 1.56?
TT2525 SHORT wyịy
1.61 was analyzed as NOT + REACH. Therefore it seems to be a
semantic compound, and presumably the right side of TT0050
PLACE-TOGETHER we 2.7 is an abbreviated phonetic
derived from TT2525 SHORT wyịy 1.61.
The
remaining phonotypes defy explanation, and the sheer number of
phonotypes for a single element defies belief. How many of
these convoluted proposals are rooted in reality?
Next: Are tangraphs without phonotypes semantic compounds?
10.12.3:45: r246 might be an extreme distortion of 婆 'old woman', which was read as *ba in Middle Chinese and was probably the source of TT2958 ?HUSBAND'S-MOTHER ba 2.14.
I'll explain later why I think kio, khyiy, and gyirw can be conflated under a single phonotype KI which may be connected to DZI. I'll also explore the possibility of deriving the KYAA phonotype from KI and present an explanation for THU.
07.10.10.23:59: SOUNDALIKE SURNAMES AT SEA
TT4521 (the surname 張) chyow 1.56
TT3831 FIRST-MONTH chyow 1.56
are only two-fifths of a Tangraphic Sea homophone group which also includes
TT2349 長大 GROW-UP (Grinstead: ADULT) chyow 1.56
TT3717 (a surname) chyow 1.56
TT5265 澤 MARSH chyow 1.56
GROW-UP looks like a borrowing from 長 Tangut period northwestern Chinese ?*chõ 'grow up'.
MARSH, on the other hand, couldn't be from 澤 TPNWC ?*chhey 'marsh'.
I presume the second surname chyow 1.56 has nothing to do with Chinese. Why didn't the Tangut write both chyow 1.56 with one tangraph? Perhaps they wanted to graphically distinguish TT4521, a Tangutization of the Chinese surname 張 ?*chõ, from TT3717, an indigenous, homophonous surname.
In any case, TT3717 was used to transcribe TPNWC syllables (中忠鐘衆) that ended in *-ung in Middle Chinese, were transcribed with -ung by Tibetans in the pre-Tangut period, and end in -ong, -əng, or -(u)ə̃ in modern NWC dialects. Tibetan transcriptions of Tangut rhyme 1.56 end in -o(H). All this confirms Gong's reconstruction of o as the vowel for 1.56 and point toward a TPNWC rhyme ?*-uõ that was halfway between the earlier *-ung with a high vowel and the modern rhymes with mid vowels (o, ə).
"Surnames" in the title refers not only to the homophonous surname pair TT4521 and TT3717, but the Tangraphic Sea analysis of TT3717:
+
TT3717 (a surname) chyow 1.56 =
left of TT3890 SURNAME mə 2.25 +
right of TT4820 (plural marker) nyï 2.28
PERSON on the left side makes sense, but why abbreviate a plural marker for the right side? Even if I ignore the Tangraphic Sea analysis, I still do not know what the function of the right side (Nishida radical 246) is.
I briefly speculated that r246 might be a Tangutized version of 長 TPNWC ?*chõ which is in TT4820 to tell the reader that its meaning (plural marker) is related to the similar-sounding 衆 TPNWC ?*chuõ 'multitude'. There are several problems with this idea:
- the resemblance between r246 and 長 is vague at best
- if the left side of TT4521 is also a Tangutization of 長, why would 長 be altered in two different ways? Why not use a single alteration of 長 in both surname tangraphs?
- r246 is not used as a phonetic for other chyow-like syllables. It is, however, used as a phonetic for nyï-like syllables:
TT2952 BARBECUE 燒烤 nywï 2.28
(離 FIRE-TRIGRAM on right)
TT2957 MOTHER-IN-LAW nyï 1.30
(part of MOTHER-IN-LAW on right)
TT2959 FATHER'S-SISTER nyï 1.30
(PERSON on right)
TT3671 至 REACH nyï 2.28
TT4632 INFORM nyị̈ 1.69
(WORD on left)
But the nine other tangraphs with r246 on the left are not pronounced like nyï. Nor are the sixteen other known readings of other tangraphs with r246 on the right.
Next: The other phonetic value of r246.
07.10.9.1:19: A STRANGE STRETCH
In the bilingual Ganton`g tower inscription and in Cixiao (4.6-4.8), the Chinese surname 張, literally 'stretch' (among other meanings), appears in Tangut as
TT4521 chyow 1.56
The Tangut reading clearly resembles the Tangut period northwestern Chinese pronunciation of 張 as ?*chõ.
The tangraph might be a distorted reversed version of 張, with 長 'long' mirror-imaged (Nishida radical 263) next to Nishida radical 185 (意志 DETERMINATION) which resembles Chn 弓 'bow'. (Other meanings of 張 were 'make long; string a bow'; the word is cognate to 長 'long'.)
However, the tangraph's analysis in Tangraphic Sea may only indirectly refer to the Chinese original:
=
+
TT4521 chyow 1.56 =
center of TT3831 FIRST-MONTH chyow 1.56 +
(upper) left of TT5548 (a surname? [Shi et al. 1983: 486]) jyị̈ (rhyme unknown)
Neither FIRST MONTH nor TT5548 appear in the definition for TT4521 which follows the same formula described in "Surnames at Sea".
TT4521 and TT3831 FIRST-MONTH chyow 1.56 are the only two tangraphs containing Nishida radical 263 in any position. They derive each other:
+
TT3831 FIRST-MONTH chyow 1.56 =
(left of) TT3548 YEAR kyiw 1.45
(left of) TT4521 chyow 1.56
right of TT3367 RISE wor 1.89
It is strange that FIRST-MONTH does not contain FIRST, MOON, or MONTH, though YEAR and RISE are not entirely semantically inappropriate. Conversely, Tangraphic Sea defined FIRST-MONTH as SPRING MONTH BEGINNING without mentioning YEAR or RISE.
However, PERSON, the left side of YEAR, hardly symbolizes YEAR (and why would YEAR be written with PERSON in the first place?*).
FIRST-MONTH chyow 1.56 shares an initial consonant with 正 TPNWC ?*chyẽy (< *chyeyng) 'first month' but nothing else. They are probably unrelated, since Tangut -w reflects an earlier *-k (Gong 1995: 55).
TT5548 (a surname? [Shi et al. 1983: 486]) jyị̈ (rhyme unknown)
looks like DETERMINATION x 2 atop BOTTOM. It may be tonally as well as segmentally homophonous with
TT2110 伸 STRETCH jyị̈ (rhyme unknown)
(which looked lie TT5548 with HORNED-HAT and an oversized DETERMINATION on the bottom left)
which in turn might be cognate to
TT2107 jyi (rhyme unknown)
(Nishida [1966: 314] and Li Fanwen [1986: 376] both glossed this as 伸 STRETCH, but Grinstead [1972: 83] glossed it as LOOK-UPWARDS and Shi et al. [2000: 338] glossed it as 仰 LOOK-UPWARDS and 解 ?UNTIE. Nevsky [1960 I: 286] backs up both interpretations: he glossed it as смотреть вверх 'look up' but also quoted it from a text called Nirvana in which it corresponds to Chn 申 for 伸 'stretch'.)
I wonder if TT5548 also meant something like 'stretch'. If it did, then the analysis of TT4521 chyow 1.56 can be intrepreted as
TT3831 FIRST-MONTH chyow 1.56 (phonetic) + TT5548 ?STRETCH (semantic)
Nevsky (1960 II: 196) has an illegible handwritten gloss for TT5548 that looks like тангутская фамилия 'Tangut surname' followed by what may be a disyllabic surname:
TT5548 5672 jyị̈ Gyiw 2.40
His entry for TT5672 (II 321) glosses this combination as одна из танг. фамилий 'one of the Tangut surnames'. TT5672 by itself means CUCKOO. Perhaps the second half of the surname means 'cuckoo'; if it didn't, why not create another tangraph to represent that syllable? Or why not use one of the four other tangraphs pronounced Gyiw 2.40?
Next: Soundalike surnames at Sea.
*PERSON in TT3548 YEAR kyiw 1.45 is derived from the left side of
In turn, the left side of TT3622 YEAR chyịy 1.61 is derived from ... TT3548 YEAR kyiw 1.45.
Both tangraphs for YEAR are the same except for the components between PERSON and SLANT (Nishida radical 230):
TT3548 has HAND (Nishida radical 039) whereas TT3622 has HEAD (Nishida radical 106). I cannot understand how either body part is relevant to YEAR.
1:23: Why isn't YEAR something like
LONG + TIME
TEN + TWO + MONTH
SPRING + SUMMER + FALL + WINTER
instead of
PERSON + (HAND or HEAD) + SLANT?
07.10.8.4:14: SURNAMES AT SEA
In "Onomastic Overflow?" I mentioned the surname
=
+
TT1088 tow 1.54 =
left of TT1087 PERSON jwu 1.2 (not the normal word for PERSON)
right of TT3836 (a surname) lhyịy (tone unknown)
I asked,
What does it mean when the tangraph for one surname is abbreviated within the tangraph for a nonhomophonous surname? Are those two families closely related?
If that were the case, the Tangraphic Sea might mention it. Although Tangraphic Sea entries are very brief, surely it couldn't be too taxing to write "related to the lhyịy" in the entry for tow 1.54. What does the actual entry for tow 1.54 say?
First, the analysis:
jwu 1.12 pha 1.17 lhyịy ? byịy 2.54
"Left of PERSON and right of lhyịy."
Then the definition itself:
tow 1.54 tya 1.20 myïr 1.86 mə 2.25
'As for tow, clan surname ...'
tow 1.54 'yiy 1.36 'yï 2.28 lyï 1.29
'... tow is its meaning*.'
The tangraphs mentioned in the analysis (jwu and lhyịy) do not appear in the definition, which follows a generic formula used for definitions of other surname tangraphs:
'As for X, clan surname X is its meaning.'
The definition does not shed any light on what lhyịy has to do with tow. The right side of lhyịy also has the phonetic value kwo which obviously doesn't sound like tow. All other tangraphs containing this element are pronounced kwo or lhyịy:
kwo tangraphs:
lhyịy tangraphs:
Presumably the left side of tow (Nishida radical 223) from PERSON is semantic. Perhaps the regular PERSON element (Nishida radical 204) without the horizontal stroke on the top because that element had already been used with lhyịy/kwo in the surname tangraph
TT3836 lhyịy (tone unknown)
For a moment, I wondered if the left side of tow could be phonetic because it looked like the right side of these homophonous tangraphs:
TT3278 (a cereal [Grinstead]; a kind of grass [Shi et al. 2000: 130]) tow 1.54
GRASS (Nishida radical 144) is on the left
TT5049 BE-USEFUL; 得 OBTAIN (Shi et al. [2000: 131]) tow 1.54
why is SKIN (Nishida radical 297) on the left?
However, these two tangraphs actually contain Nishida radical 222, not radical 223. The first stroke of 222 is フ-shaped, whereas the first stroke of 223 is a horizontal line 一. The meanings of radicals 222 and 223 are unknown.
*I interpret the structure of the sentence as
(tow TOPIC) (clan surname tow GENITIVE say) (is)
The second part is a comment on the first.
It is tempting to regard 'yï 2.28, which I have loosely translated as 'meaning', as a loanword from Middle Chinese 意 'ï 'meaning'. However, it is really a native Tangut verb 'say' which seems to have been nominalized by the preceding genitive particle. This construction is parallel to Classical Chinese 之謂 which also consists of a genitive particle plus 'say'. A very literal translation of the definition might be,
'As for X, [it] is the saying of the clan surname X' =
'... it is how the clan surname X is said' =
'... it means clan surname X'
07.10.7.13:30: ONOMASTIC OVERFLOW?
In part 3 of "How Many Hats?", I found that the most common source of HORNED-HAT was used to derive 11 surname tangraphs. I don't understand why HORNED-HAT has this function because Tangut already has a element with a similar function (Nishida radical 164) in other surname tangraphs:
HORNED-HAT in the bottom left surname tangraph is part of an abbreviation of EAR, which is homophonous with that surname.
There seem to be a lot of tangraphs for names. Grinstead glossed 76 tangraphs as SURNAME and 61 tangraphs as NAME. If we subtract a few which are words for 'surname' and 'name' rather than actual names, this results in a total of about 130. Note that Grinstead left some surnames (e.g., TT1444, TT2876, TT2924, TT3701, TT5076) unglossed.
Out of the first 200 tangraphs in Precious Rhymes of the Tangraphic Sea (1.4.2302-1.6.2102):11 represented surnames
1 represented a regular word and a surname
1 represented a foreign syllable and a surname
1 represented personal names
2 represented foreign syllables
(Tangraphs for geographic names also exist, but were not in the sample.)
If this is a representative sample, name tangraphs comprise 6.5% of all tangraphs and transcription tangraphs comprise another 1%. (I am excluding tangraphs which can represent both regular words and names or foreign syllables.) That may not seem like much, but 7.5% of c. 6000 tangraphs is 450. I don't think there are 450 sinographs in common use which are reserved solely for names and foreign syllables. Most Chinese names and transcriptions use characters which also have regular meanings: e.g.,
王 'king; the surname Wang' (cf. 'meaningful' surnames like King)
加 'add; foreign syllable ka': e.g., 加拿大 'Canada', 加州 'California'
There are only a few common pure onomastic and transcriptive sinographs: e.g.,
宋 'the name Song'
崑崙 'the Kunlun Mountains'
迦 'the Indic syllable ka'
Maybe the estimate of 450 onomastic and transcriptive tangraphs can be cut down to about 200. According to Kepping (1996), only half the tangraph inventory was in normal texts and the rest was reserved for the ritual language. RL texts focus on indigenous topics and presumably would not require transcriptive tangraphs for foreign words. If RL texts had no special onomastic tangraphs, then the number of onomastic and transcriptive tangraphs was around 225 = 7.5% * 3000 non-RL tangraphs. But 200 still seems like an unusually high number by Chinese standards. Two questions:
1. Why did the Tangut create so many name and transcription tangraphs?
2. If tangraphy is semantocentric, why don't name and transcription tangraphs have consistent semantic components? Why write some surnames with radical 164 (see above), some with HORNED HAT -
- and some without either of those elements: e.g.,
Yes, many surname tangraphs do have PERSON in various positions -
- but PERSON is found in about one of six tangraphs, so its presence doesn't tell the reader much about a tangraph's meaning. Moreover, surnames by definition belong to PERSONs, so why don't all surnames have PERSON?
(The use of PERSON in surname tangraphs is not influenced by Chinese. I know of only two surname sinographs with 亻 'person' in them: 伍 and 倪. Neither is a pure surname sinograph. 伍 means 'group of five' and 倪 means 'young and weak'.)
In part 2 of "How Many Hats", I proposed that tangraphs might be like acronyms: i.e., combinations of components which could abbreviate many different words. I cannot imagine how surnames could be treated like acronyms, unless the components of their tangraphs reflect characteristics associated with a clan. For example,
TT1644 zər 2.76
looks like EIGHT + WATER + PERSON. Are EIGHT and WATER abbreviations of tangraphs describing this family? No analysis has survived for this tangraph, so that hypothesis cannot be tested.
There were two surnames which were homophonous with TT1644 and which also contained WATER:
TT4206 zər 2.76
TT3329 zər 2.76 (TT4206 with SAGE added to the left)
The right-hand element is phonetic for 'ya in other tangraphs, but obviously zər doesn't sound like 'ya. It may be semantic, as it resembles Chn 羊 'sheep' (and its phonetic value ya was probably based on Tangut period NW Chn ?*yõ 'sheep'): cf. surnames like Shepherd. But what kind of families would be associated with WATER as well as SHEEP? Were they shepherds who could swim well?
If homophonous surnames could be written differently, nonhomophonous surnames could be written with the same tangraphic elements: e.g., TT1644 zər 2.76 appears in the analysis of another surname:
=
+
TT4547 kwo 2.14
top of TT4548 遺尿 BEDWETTING kwo 1.49 +
(written as TT4547 [phonetic] + [FLESH + WATER])
left of TT1644 zər 2.76
I cannot help but feel sorry for this family.
TT3836 lhyịy (tone unknown; looks like PERSON + TT4547)
(right side from TT1594 lhyịy [tone unknown] COUNTRY, whose Tangut period NW Chn translation was ?*kwo)
TT1088 tow 1.54 (left side from TT1087 PERSON jwu 1.2)
to sound like TT4547 kwo 2.14, but they don't. The former is cited as the source of the right side of the latter in Tangraphic Sea.
What does it mean when the tangraph for one surname is abbreviated within the tangraph for a nonhomophonous surname? Are those two families closely related?